
- 1unity右键creat->2d Object没有Tiles_unity2020中新建找不到tile
- 2Oracle dblink连接使用
- 3命令行启动模拟器并以系统级程序方式安装运行launcher_adb 安装并设置为launcher
- 4react中使用swiper_react swiper
- 5SFM三维重建(Python+OpenCV)_sfm算法 python实现
- 6yolov5-训练好的模型部署的几种方式-ONNX_yolo-net-master
- 72021 OWASP Top 10 榜单(初稿)发布,头牌易主
- 8最新office365个人和家庭版下载及功能介绍_免费office365 csdn
- 9usmssosetup 单点登录被禁用_SSO(单点登录)实施中遇到的几个问题
- 10【ChatGLM-6B】清华开源的消费级显卡大语言模型,本地部署与测试_清华大语言模型在哪访问
基于Kafka的nginx日志收集分析平台_nginx日志分析平台
赞
踩
文章目录
项目描述
本项目是基于Kafka的一个日志收集分析平台,用到的主要技术有nginx、filebeat、Kafka、zookeeper、python、mysql等。做完这个项目,你对于技术的整合使用将会有更进一步的体会。大概的流程就是使用nginx集群模拟用户访问网站的行为,让其产生nginx的access日志,然后由filebeat收集这个日志,再统一吐到Kafka中,然后使用python的pykafka模块编写一个消费者,对Kafka的数据进行清洗,解析出日志中IP所属的省份和运营商以及带宽和时间,通过设置阈值,达到每分钟监控、邮件报警,最后再将分析后存到mysql数据库中。
项目目标
项目目标主要防止某个省份的某个运营商的流量突然增大,导致服务器异常,起到监控预警作用。
项目架构
该项目分为以下几个模块:用户—>代理集群—>web集群—>kafka和zookeeper集群—>消费者—>数据库

- 用户可以通过域名或者代理集群的某个IP地址来访问我们的web集群中的web服务。(测试中,可以使用域名也可以使用IP地址)
- 代理集群:用户通过域名访问我们的代理集群中的服务器,nginx的域名解析会随机解析成代理集群中的服务器。然后代理集群中的两台服务器通过nginx的负载均衡,会将用户发送过来的请求,按照某种算法依次转发到web集群上。在这个代理集群中,我们还使用了keepalived,使集群中的1.1和1.2两台服务器互为主备做高可用,提高了资源利用率(服务器1是1.1的master,是1.2的backup,服务器2是1.2的master,是1.1的backup,如果master挂掉了,那么这个IP的master会切换到backup所在的服务器上)
- web集群:web集群的三个服务器上都会产生nginx日志,我们需要将这三个服务器的nginx日志统一收集起来,放到filebeat上,所以,我们在web集群的每个服务器上安装了filebeat,指定了filebeat的输入为nginx日志的存放路径,输出为Kafka的同一个topic中。
- Kafka集群:filebeat发送数据给kafka集群的时候,跟任意一个broker交互都可以,因为如果交互的那个broker里面不是partition的leader,那么follower会返回当前请求副本leader的信息,然后filebeat再跟leader交互。这里所有的partition都加了同一个名为nginxlog的topic中。filebeat将数据随机发送给一个partition的leader之后(该partition的ISR列表中的follower会主动从leader中pull信息),leader会返回一个ack信息,然后filebeat会接着发送下一条数据,从而保证了数据发送的一致性。那么如何保证数据消费的一致性呢?消费者消费数据的时候,引入了High Water Mark机制,也就是木桶效应。Kafka的数据存放在配置文件的制定目录中,本项目是存放在/data/nginxlog-0/00000000.log下。
zookeeper是用来管理Kafka的,Kafka的许多元信息(比如partition、topic、replica)都是交给zookeeper统一管理的,但是数据data是由Kafka自己保存的。zookeeper还会选举Kafka集群的controller,这个controller用来协调partition的leader跟follower的选举。注意,zookeeper本身也有leader跟follower的,它的选举方式是一致性算法(zab),少数服从多数,票数过半的当选leader,所以在zk集群中,机器存活数必须过半,集群才能正常使用,所以我们通过也会将zk集群的节点数设为奇数个,这是为了方便选举。跟filebeat给Kafka传递数据一样,Kafka连接任意一台zookeeper都可以操作,但是数据新增修改等事务操作必须在leader上运行,客户端如果连接到follower上进行事务操作,follower会返回给leader的IP,最终客户端还是在leader上操作,但是可以直接连接follower进行查询操作。 - 消费者组,我在这里只用pykafka模拟了一个消费者来消费数据,所以不存在消费组,但是如果有消费组的时候,需要注意一点,同一个消费组的消费者不能够消费一个topic中一个partition的数据,否则会导致数据混乱,降低了消费者的处理效率。消费者消费的时候,会记录自己的偏移量,消费偏移量可以保存在本地,也可以提交到Kafka的__consumer_offset主题里保存。
我使用pykafka模块来创建一个消费者,然后对于数据进行了清洗,筛选出了IP地址、时间、带宽等字段,然后再通过一个淘宝接口,将IP地址解析成省份和运营商,最后再通过pymysql模块存入数据库中。 - 到此,我这个项目就结束了,运用到的知识点很多,整合知识点更是不易,这需要我们非常细心,以及对知识非常熟练,否则非常容易出错。
项目涉及知识详解
Nginx
nginx是一个高性能的web服务器,但是由于其只能展示静态页面,所以通常我们不会吧一个完整项目部署在nginx上,而是通常用nginx来做负载均衡以及反向代理。
反向代理
反向代理就是代理服务器,为服务器作代理人,站在服务器这边,它就是对外屏蔽了服务器的信息,常用的场景就是多台服务器分布式部署,像一些大的网站,由于访问人数很多,就需要多台服务器来解决人数多的问题,这时这些服务器就由一个反向代理服务器来代理,客户端发来请求,先由反向代理服务器,然后按一定的规则分发到明确的服务器,而客户端不知道是哪台服务器。常常用nginx来作反向代理。(想象一下每个人都是访问www.baidu.com,但是百度绝对不可能只有一个服务器接受访问)
负载均衡
负载:就是Nginx接受请求
均衡:Nginx将收到的请求按照一定的规则分发到不同的服务器进行处理
nginx支持多种不同的负载均衡算法,如轮询、ip_hash、url_hash等
关于nginx的更多知识可以查看我的另外一篇博客:nginx相关内容以及配置文件详解
项目中nginx起的作用
在第一个集群中,我们使用nginx来做负载均衡以及反向代理。
负载均衡是指我们将客户端的访问请求,按照某种nginx指定的算法分配到web集群中的服务器上,这样可以减少某一台服务器的重担,避免所有请求都在一台服务器上,使其分散开来。并且如果某台服务器挂掉了,nginx的负载均衡策略也会帮我们转发到起到服务器上去。
反向代理是指我们使用nginx做了一个转发的功能,不让客户端的请求直接发送到web服务器上,这样可以提高我们服务器的安全性,不让客户端知道我们真实服务器的IP地址,可以避免一些黑客的攻击
之前也有使用DNS做负载均衡的,就是将一个域名(类似于www.sc.com)解析成多个IP地址,一般来说会轮询的方式去解析成各个IP。但是如果其中一个服务器挂了,DNS不会立马将这个IP地址从解析列表中去掉,还是会解析成挂掉的IP,可能会造成访问失败。虽然客户端有重试,但是还是会影响用户体验。
在第二个集群中,我们使用nginx来展示静态页面,并且产生访问日志
Filebeat
filebeat是什么?
filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Kafka中进行索引。
filebeat的工作方式
启动filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到libbeat,libbeat将聚集事件,并将聚集的数据发送到Filebeat配置的输出。
项目中filebeat起的作用
filebeat在整个项目中扮演的是生产者的角色,它主要的作用是用来收集nginx产生的数据。你肯定会想,nginx产生的数据为什么不直接发送到kafka中,而是要经过filebeat这个步骤呢?这是因为,我们有多个web服务器,每个web服务器产生的日志都不相同,如果一个一个的发送给kafka,效率非常低下,而且不方便统一管理,这对于kafka取数据来说也是非常不方便的。
Filebeat如何保证事件至少被输出一次
Filebeat之所以能保证事件至少被传递到配置的输出一次,没有数据丢失,是因为filebeat将每个事件的传递状态保存在文件中。在未得到输出方确认时,filebeat会尝试一直发送,直到得到回应。若filebeat在传输过程中被关闭,则不会再关闭之前确认所有事件。任何在filebeat关闭之前未确认的事件,都会在filebeat重启之后重新发送。这可确保至少发送一次,但有可能会重复。可通过设置shutdown_timeout 参数来设置关闭之前的等待事件回应的时间(默认禁用)。
Filebeat如何记录文件状态
将文件状态记录在文件中(默认在/var/lib/filebeat/registry)。此状态可以记住Harvester收集文件的偏移量。若连接不上输出设备,如ES等,filebeat会记录发送前的最后一行,并再可以连接的时候继续发送。Filebeat在运行的时候,Prospector状态会被记录在内存中。Filebeat重启的时候,利用registry记录的状态来进行重建,用来还原到重启之前的状态。每个Prospector会为每个找到的文件记录一个状态,对于每个文件,Filebeat存储唯一标识符以检测文件是否先前被收集。
Kafka
Kafka是什么
kafka又称为消息中间件:消息中间件利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信。
Kafka是一个分布式的基于发布订阅的消息系统,它是一种消息队列,一般用来做日志的处理。
消息中间件的作用
- 业务的解耦(将模块间的RPC(远程过程调用)改为通过消息队列中转,解除系统间的耦合)
- 日志的收集(通过日志可以跟踪调试信息、定位问题,利用消息队列产品在接收和持久化消息方面的高性能,引入消息队列快速接收日志消息,避免因为写入日志时的某些故障导致业务系统访问阻塞、请求延迟等问题)
- 流量削峰(系统的吞吐量往往取决于底层存储服务的处理能力,数据访问层可以调整消费速度缓解存储服务压力,避免短暂的高峰将系统压垮;使用消息队列先将短时间高并发的请求持久化,然后逐步处理,从而削平高峰期的并发流量,改善系统的性能)
- 异步调用(对于无需关注调用结果的场景,可以通过消息队列异步处理)
消息队列
- 一个典型意义上的消息队列至少需要包含消息的生产者(filebeat)、中间件(kafka)、消费者(python程序)
- 消息队列的通信模式(也就是消息中间件的通信模式)
- 点对点模式(也就是一对一模式,一一对应,不能够重复消费,并且消费完了之后,消息中间件中数据就被删了)
- 发布订阅模式(kafka使用,多对多模式,通过设置偏移量可以重复消费,消费完了数据不会被删除)
Kafka的优点
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,他的延迟最低 只有几毫秒
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份放至数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败
- 高并发:支持数千个客户端同时读写
Kafka如何保证高可用呢?
多个broker,多个partition,多个replica
Kafka为什么要做分区,弄多个partition呢
- 方便扩展,因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松应对日益增长的数据量
- 提高并发,以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率
如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?
- partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
- 如果既没指定partition,又没有设置key,则会轮询选出一个partition。
Kafka的一些基本概念
- Producer:Producer即生产者,消息的产生者,是消息的入口,项目中的生产者是filebeat,收集nginx服务产生的数据
- Broker:是kafka的实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。 每个kaka集群内的broker都有一 个不重复的编号,如broker-0,broker-1等…
- Topic:消息的主题,也就是消息的类别,每个topic可以有多个分区,, kafka的数据就保存在topic. 在每个broker,上都可以创建多个topic。Topic进行消息的分类,比如nginx、mysql,日志给不同的主题,就是不同的类型
- Partition:Topic的分区,每个Topic可以有多个分区。分区的作用是做负载,提高kafka的吞吐量,提高效率,提高并发。同一个topic在不同的分区的数据是不重复的, parttion的表现形式就是一个一个的文件夹!(一般来说,partition的数量跟broker的数量保持一致)。但是多个partition会造成消息顺序混乱,如果对消息顺序有要求就只设置一个partition就可以了,如果对并发有要求就设置多个partition(日志设置多个partition)
- Replica:副本,每一 个分区都有多个副本,副本的作用是做备胎,是Kafka里的高可用。当主分区( Leader )故障的时候会选择一个备胎(Follower工位,成为Leader,在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量, follower和leader绝对是在不同的机器,并且一个partition中leader只能有一个,follower可以有多个,同一机器对同一个分区也只可能存放一个副本 (包括自己)。)如果broker数量和replication数量一致,那么可以坏掉n-1台机器
- Leader:每个分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader
- Follower:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader(controller管理选举,一般从ISR中顺延产生)
- Segment:partition物理上由多个segment组成,Partition的结构:Partition在服务器上的表现形式就是一个一个的文件夹,每个Partition的文件夹下面会有多组segment文件,每组segment文件又包含.index文件、.log文件、.timeindex文件这三个文件,log文件就实际是存储message的地方,而index和timeindex文件为索引文件,用于检索消息。
- Message:每一条发送的消息主体,是通信的基本单位(存放在log中),每个producer可以向一个topic发布消息,partition中的每条message包含以下三个属性:offset、MessageSize、data
- offset:偏移量,它可以唯一确定每条消息在partition内的位置。
- 生产者Offset:消息写入的时候,每一个分区都有一个offset,这个offset就是生产者的offset,同时也是这个分区的最新最大的offset。有些时候没有指定某一个分区的offset,这个工作kafka帮我们完成。
- 消费者Offset:记录消费者消费到哪里了,也可能由于Consumer在消费过程中可能会出现断电宕机等故障,Consumer恢复后,需要从故障前的位置继续消费,所以Consumer需要实时记录自己消费到了哪个offset,以便故障复后继续消费。
- Consumer :消费者,即消息的消费方,是消息的出口。一般来说,消费者的数量跟broker的数量保持一致,consumer的数量要大于或者等于partition的数量最好
- Consumer Group我们可以将多个消费者组成一个消费者组 ,在kafka的设计中同一个分区(partition)的数据只能被消费者组中的某一个消费者消费,如果同一个消费组内的两个消费者同时消费,会出问题;但是不同的消费组可以同时消费一个partition。 同一个消费者组的消费者可以消费同一个topic的不同分区(partition)的数据,这也是为了提高kafka的吞吐量!
- Zookeeper : kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性。
其中,partition和broker和replica和leader和follower的关系可以如图所示:
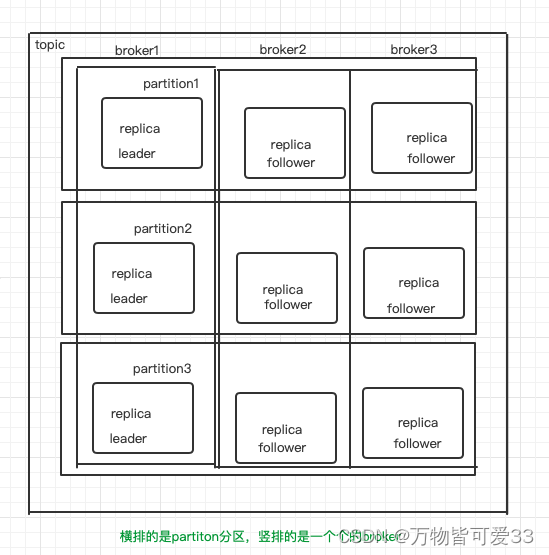
replica的含义包括follower和leader,以上broker1并不是绝对包含leader,broker2和broker3中绝对包含的是follower
为什么使用Kafka做日志统一收集?
- 故障发生时方便定位问题(如果直接收集nginx上的日志,如果中途发生故障,那么还需要一台一台登录nginx机器才能排查错误,而kafka集群可以统一管理)
- 日志集中管理,后续需要日志的程序直接从Kafka获取日志即可,尽可能的减少日志处理对nginx的影响(如果将日志收集的程序跟产生日志的nginx绑定在一个服务器上,那么一旦程序躲起来,很可能对服务器上的nginx服务造成影响)
producer发送数据给Kafka集群的流程
- Producer先从kafka集群中获取分区的Leader
- Producer将消息发送给Leader
- Leader将消息写入本地文件
- Followers从Leader上Pull消息
- Followers将消息写入本地后,向Leader发送ACK来确认
- Leader收到所有副本的ACK后向Producer发送ACK
分成多个segment的好处
方便数据清理,Kafka可以按时间或者按数据大小两个维度清理数据(任意一个条件满足,都可以触发日志清理),不会永久保存,定期保存,默认是保存七天(可修改Kafka的配置文件server.properties 中的log.retention.hours这个参数)
[root@nginx-kafka01 data]# ls
nginxlog-0
__consumer_offsets-11
[root@nginx-kafka01 data]# cd nginxlog-0/
[root@nginx-kafka01 nginxlog-0]# ls
00000000000000000000.index 00000000000000000000.timeindex
00000000000000000000.log leader-epoch-checkpoint
- 1
- 2
- 3
- 4
- 5
- 6
- 7
*.log文件存放的真正的kafka的数据,*.index存放的是索引
log.segment.bytes=1073741824 (可以通过Kafka配置文件server.properties中的log.segment.bytes设置的每个段的大小)
Zookeeper
Zookeeper在Kafka中的作用
- zookeeper是用来管理Kafka集群的,它可以保存Kafka的元信息,topic、partition、replica信息都保存在zookeeper中,但是Kafka不会将topic本身的数据发送到zookeeper上的。
- 选举Kafka集群的controller,这个controller来协调副本的leader、follower选举(现在3.0Kafka自己选举controller,我们使用的2.12),通过抢占的方式来选出controller
选举出的Kafka的controller管理Kafka副本的leader和follower,同步、选举(leader挂掉了顺延)
Kafka可以挂掉n-1台(broker、partition、replica数量一致的情况下)
zookeeper必须存活集群节点数的一半以上 - Broker端使用zookeeper来注册broker信息,以及监测partition分区leader的存活性。
Kafka3.0版本已经脱离zookeeper,Kafka自己实现zookeeper功能,通过KRaft进行了自己的集群管理
目前我使用的zookeeper版本是3.6.3版本,Kafka是2.12版本
一键安装nginx、filebeat、Kafka、zookeeper的脚本
pykafka生成消费脚本
mysql数据库中的表需要自己先建好

