
- 1win11重置系统之后恢复自己的office服务_win11退回win10后office还在吗
- 2每天学python-盛最多水的容器_盛最多水的容器python
- 3API等级和Android版本对应关系以及历史_api19
- 4pytorch简单新型模型测试参数
- 5Centos7.9 安装配置mysql8.0.33_centos7.9 使用yum安装mysql 8并配置大小写不敏感
- 6scratch编程我的世界3D史蒂夫_用scratch做3d沙盒游戏代码
- 7每日五道java面试题之spring篇(三)
- 8Unity结合HTC Vive开发之射线与UI交互_unity vrtk 射线不显示但是可以点击ui怎么回事
- 9异常详细信息: System.InvalidCastException: 对象不能从 DBNull 转换为其他类型。_+ asbytearray “list2[0].asbytearray”引发了类型“system.i
- 10【JavaEE】idea的smart tomcat插件
ArcGIS_arcgis聚类分析
赞
踩
地形数据获取
地理空间数据云(www.gscloud.cn/search)获得基础地形数据。以SRTM和ASTER的DEM数据最为常用,免费的资源有30m和90m的全球DEM数据。
SRTM:Shuttle Radar Topography Mission航天地形测绘,以人造地球卫星、宇宙飞船、航天飞机等航天器为工作平台,对地球表面所进行的遥感测量。SRTM由多国多机构联合测量,美国“奋进”号航天飞机上搭载SRTM系统完成。测图任务从2000年2月11日——22日,时长11天222小时23分钟,获取60°N-60°S之间总面积超过1.19亿平方公里的雷达影像数据,覆盖地球80%以上的陆地表面。注:下载的压缩包里有img文件,.img文件可以在GIS类软件中直接打开。
卫星影像数据获取
GEE(Google Earth Engine)可以批量处理卫星影像数据的工具。相比于ENVI等传统的处理影像工具,GEE可以快速、批量处理数量“巨大”的影像。可快速计算NDVI等植被指数,预测作物相关产量,监测旱情长势变化,监测全球森林变化等。GEE提供了在线的JavaScript API,同时也提供了离线的 Python API。通过这些API可以快速的建立基于Google Earth Engine 以及 Google云的Web服务。
制作专题地图
“视图”——“布局视图”;
版面设计:空白处右键“页面和打印设置”,设置纸张大小和方向;在数据框空白处右键“分布——调整到页边距大小”、点击放大工具,框选研究区域进行合适的放大(出图时只有数据框中的图像才能显示)
右键工具栏空白处,✔绘图,出现绘图工具条;菜单栏中“插入——标题/文本”,在绘图工具条中修改字体,移动到数据框中的合适位置;“插入——图例”,可以修改图例的标题、字体、大小,0.5磅边框,间距为5;“插入——比例尺”
核密度分析
“Spatial Analyst工具——密度分析——核密度分析”,环境——处理范围,输出像元大小:值越小越细腻,运行时间越长(找合适的);搜索半径:值越大色块越大,需进行尝试设定合适的值实现更好的效果。
掩膜提取:Spatial Analysis工具>>>提取分析>>>按掩膜提取。如果需要具体的数值,“地理处理——结果”。
统计矢量图层面积
目录列表中,右键连接的文件,新建---文件地理数据库;再右键,新建---要素数据集,注意坐标的选择(WGS 1984 UTM Zone 49N);再右键,导入要素类(单个),输入要计算的矢量文件,填写输出的矢量文件名;右键打开新生成的文件的属性表,从属性表中可以看出,多了Shape_Length和Shape_Area两个字段。点击内容列表中相应图层右键属性表,选中Shape_Area列,右键‘统计’。
多距离聚类(Ripley's K)
确定要素在一定距离范围内统计意义显著的聚类或离散。有4条曲线:expectedK(预测K值,预期的随机空间模式)、observedK(观测K值,观测的空间模式)、diffK(观测K值-预测K值,K差值越大说明聚类越明显)、LwConfEnv(低置信区间)、HiConfEnv(高置信区间),。需要投影数据准确测量距离;不同的距离范围,数据的离散、随机、聚集分布状态不同。
1.当observedK>expectedK、HiConfEnv:显著性聚类。
2.当observedK<expectedK、HiConfEnv:显著性离散。
3.其他情况视为随机。
“Spatial Statistics Tools——分析模式——多距离空间聚类”✔以图形方式显示结果距离段数量:默认10,迭代10次,迭代至最大距离值(研究区最小外接矩形的最大范围长度的25%作为最大距离值)
计算置信区间:一般选择9_PERMUTATIONS(90%)或99_PERMUTATIONS(99%)
最大距离值与边界校正方法有关,a.none不应用任何特定的边界校正(超大研究区域钟收集数据但仅需更小的区域),b.simulate_outer_boundary_values校正边附近的点(靠近边界的点和中心的点同样重要,使得靠近边界的点更加精确),c.reduce_analysis_area将区域大小收缩一定距离(靠近边界的点不重要,中心的比较重要),则将最大距离设为最小外接矩形最大范围长度的25%与最小外接矩形最小范围长度的50%之中的较大者。
与起点距离、距离增量有关,若距离段数量设置为10,设置起点距离,不设置距离增量,每次的增量为:(研究范围最大距离的25%-起点距离)/10;若距离段数量设置为10,设置起点距离,设置距离增量,不会采用默认研究范围距离的25%作为最大距离,而是起点距离+距离增量*10;若距离段数量设置为10,不设置起点距离,设置距离增量,起点距离=距离增量。
若要指定研究区域:研究区域方法选择---USER_PROVIDED_STUDY_AREA_FEATURE_CLASS,再选择研究区域的要素类。
深圳的购物中心在34km范围内观测值均位于置信区间和期望值的上方,因此在该范围内为显著聚集,在4km处观测值和期望值差值最大,聚集程度最高。得到表格:
多距离聚类2(Ripley's K)
运用地理空间分析软件Crimestat,下载官网:http://www.icpsr.umich.edu/CrimeStat;步骤:选择数据,shp文件(投影坐标的);X、Y坐标匹对;最近邻分析:“Spatial description>>>Distance Analysis I>>>Nearest neighbor analysis” ;多距离空间聚类分析(Ripley's K函数):“Spatial description>>>Distance Analysis I>>>Ripley's K statistic”,Simulation选99. 但该软件出图效果不理想,可复制或下载数据,用excel画图或者python画图也很快。





- import matplotlib.pyplot as plt
- import numpy as np
- data = np.loadtxt('k.csv',delimiter=',',dtype=float)
- distance = data[:,0]
- lt = data[:,1]
- lcsr = data[:,2]
- ltmin = data[:,3]
- ltmax = data[:,4]
- plt.plot(distance,lt,'orange',distance,lcsr,'gray',\
- distance,ltmin,'blue',distance,ltmax,'green')
- #a = plt.plot(distance,lt,'orange')
- #b = plt.plot(distance,lcsr,'gray')
- #c = plt.plot(distance,ltmin,'blue')
- #d = plt.plot(distance,ltmax,'green')
- plt.xlabel('距离/km',fontproperties='SimHei',fontsize=15)
- plt.ylabel('L(t)',fontsize=15)
- plt.legend(labels=['L(t)','L(csr)','L(t)min','L(t)max'])
- plt.show()
- #plt.savefig('kk.png',bbox_inches='tight')

全局空间自相关(全局莫兰指数)空间分析第一步,必做,数据是否是随机分布?
根据要素位置和要素值来度量空间自相关,在给定一组要素及相关属性情况下,判断是聚类模式?离散模式?随机模式?通过计算莫兰指数、z得分和p值对该指数进行评估。p值是根据已知分布的曲线得出的面积近似值。(一般莫兰指数是算面要素之间的关系,如各省份/市/县的经济联系强度/人口,长沙市望城区和长沙县的GDP会不会互相影响?望城区的GDP比较高,长沙县的GDP是不是也比较高?空间上是否会出现聚集的状态?)
“Spatial Statistics Tools——分析模式——空间自相关”✔生成报表,
空间关系的概念化:a.inverse_distance反距离(随着距离的增加影响变小,附件的邻近要素对目标要素的计算影响大些,若影响特别大可以选择 b.inverse_distance_aquared反距离的平方)距离范围或距离阈值:个人认为离望城区30km内有影响就可以输入30,也可以不指定,Arcgis会自动计算一个默认阈值,默认的阈值会使每个要素至少有一个相邻要素的最小距离(计算面的质心到另一个面质心的最短距离)c.fixed_distance_band距离范围影响,在一定区域内有影响且影响一样,超过范围没影响,如望城区附件的50km范围内都对它有影响且影响程度一样。d.zone_of_indifference无差别区域,距离范围+反距离法,一定区域内影响程度一致,超过一定距离影响逐渐变小。若用c.d方法,距离范围或距离阈值不能设为0,可默认,可输入正值(设置的阈值即为拐点)。e.contiguity_edges_only,只有共享边的相邻面要素会影响(与Geoda中的Rook邻接相似)。f.contiguity_edges_corners,共享边、共享角的相邻面要素都会有影响(与Geoda中的Queen邻接相似)。g.get_spatial_weights_from_file权重文件,需要确定权重才能对它进行分析(Geoda中的操作:连接数据源输入shp文件,点击‘W’空间权重管理‘创建’>>>创建空间权重文件,选择ID变量---OBJECTID不会重复,Queen邻接,创建,保存)距离法:a.欧氏距离---两点之间的直线距离,b.曼哈顿距离---格子距离(开车,街道)标准化:选择ROW,对面的运算最好进行标准化,可以减少因为要素具有不同数量的相邻要素而产生的偏离(望城区有5个邻接的区域,其他县可能只有3个)
“地理处理——结果”,空间自相关里显示指数(莫兰指数0.670103)、z得分(12.300074)、p值(0)、报表文件(打开也会有莫兰指数、z得分、p值)。z得分、p值的作用是显著性。零假设:是进行统计检验时预先建立的假设,完全空间随机性,其内容是希望证明其是错误的假设。z得分与p值用于判断是否能拒绝零假设,要素或与要素关联的值表现出统计意义上显著性聚类或离散模式,而非随机模式。典型的置信度为90%、95%、99%(要推翻它,要有 %的把握证明零假设是错误的)p值,p-value,probability,表示概率,表示零假设正确的概率,若p值为0.01,则有99%的把握认为不是随机的;z得分,z-score,表示标准差的倍数,需要结合p值一起进行看,(若p值<0.01,z得分>2.58,有99%的把握认为是聚集分布的;若z得分<-2.58,有99%的把握认为是离散分布的;若p值<0.05,z得分>1.96,有95%的把握集聚,z得分<-1.96,有95%的把握离散;若p值<0.05,但z得分<1.96则不可以拒绝零假设,空间模式就是随机分布的)若p值很小,z得分非常大,表示出现了极端值>+-2.58是聚类或离散的,就可以进行热点或冷点的分析。若z得分趋于0表示就是随机分布的故该实验GDP具有空间聚类的效果,即GDP高的区域和GDP高的区域连接在一起(高的在一块,低的在一块)
高/低聚类(Getis-Ord General G)数据是高的和高的聚一块?低的和低的聚一块?不表示聚类程度,名字是两位学者的结合J.Keith Ord和Arthur Getis。工具需要使用投影数据准确测量距离;General G方法对平均数非常敏感,最好先进行直观图探索,数据分布越接近钟形曲线,General G效果越好,极值越多,效果越不明显。
"系统工具箱>>>Spatial Statistics Tools>>>分析模式>>>高/低聚类(Getis-Ord General G)”,“地理处理>>>结果”。高/低聚类里显示General G观测值(0.014804)、z得分(11.400111)、p值(0)、报表文件(打开也会有General G观测值、z得分、p值)。a.z得分和p值 b.General G观测值>General G期望值---高值聚集,General G观测值>General G期望值---低值聚集,有99%的把握不是随机分布的且是的高值聚类。
平均最近邻(ANN,Average Nearest Neighbor)
莫兰指数不能用于不同数据之间的比较,如莫兰指数不能比较大湾区交通灯的分布情况和广州市公交站点,哪个更集中些。一般作用于点要素,但平均最近邻可比较多份数据的聚集程度高低,是根据每个要素与其最近邻要素之间的平均距离计算最近邻指数。该方法对“面积”值很敏感,面积值的细微变化会导致z得分和p值结果产生巨大变化,面积为可选可默认。
"Spatial Statistics Tools>>>分析模式>>>平均最近邻”,“地理处理>>>结果”。打开报表文件,最邻近比率(1.310988)=观测平均距离/预测平均距离、z得分(6.571349)、p值(0.000000),若是预测平均距离---随机的,若观测平均距离>预测平均距离---离散的。有99%的把握是离散的。
增量空间自相关
考虑了数据属性,若只需探讨分布聚类程度,可选择多距离空间聚类。如交通灯的空间分布不需要考虑价格等属性,若研究大湾区交通灯价格的聚类情况
"Spatial Statistics Tools>>>分析模式>>>增量空间自相关”打开报表文件,第一个峰值就可以,若无锋值可以把起点距离变大,设置增量距离,或增多距离段。
聚类和异常值分析(局部莫兰指数/Lisa指数)
给定一组要素和一个分析字段,识别具有高值或低值的要素空间聚类及空间异常值。
"Spatial Statistics Tools>>>聚类分布制图>>>聚类和异常值分析”打开报表文件,空间关系的概念化---contiguity_edges_corners,标准化---row,排列数---排列数越高,会提高伪p值的精度,即在空间中聚类的要素越少。p值<0.05,才会显示出来
Geoda可实现,还有一个象限图,双变量相关只能在Geoda做
Python调用高德地图api获取起点终点路线规划距离和预估时长
AK获取:高德地图开放平---右上角的控制台---管理key;运用高德地图中位置经纬度 + 驾车规划路线( https://lbs.amap.com/demo/javascript-api/example/driving-route/plan-route-according-to-Inglat)
创建地理数据库
连接文件夹;右键连接的文件夹下新建Shapefile,右键shapefile,点击“属性-字段”,添加字段及类型,可设置坐标系(shapefile)
右键连接的文件夹下新建土地使用文件地理数据库,右键数据库,新建现状要素数据集,右键数据集,新建shapefile,添加字段及类型、长度|| “导入”||选择要导入的shapefile,“导出”,输入要素和输出要素类是一样的,只是名字不同(geodatabase)
导出CAD文件中部分要素,生成Shapefile 文件
“选择-按属性选择”||打开polyline图层属性表,‘按属性选择’。选择好要素后,右键polyline图层,“数据-导出”!属性选择时,要选择CAD文件下的polyline图层,设置导出的格式为shapefile
复制粘贴图层中的局部区域
在"编辑器"工具栏中单击"编辑器"→"开始编辑";按shift键可多选或框选![]() ;右键复制;选择想要粘贴的图层,右键粘贴。(注意复制、粘贴的图层都要在同一个目录下)
;右键复制;选择想要粘贴的图层,右键粘贴。(注意复制、粘贴的图层都要在同一个目录下)
创建点要素文件
创建点图层,添加字段 :在文件夹下新建Shapefile,右键shapefile,点击“属性-字段”,可增添坐标系!,添加字段及类型||打开属性表—增添字段
矢量化:点击![]() 打开‘编辑器工具条’,开始编辑。点击
打开‘编辑器工具条’,开始编辑。点击![]() ‘创建要素’,在右侧对话框中,选择要创建要素的图层及构造工具。在jpg图片上点击,描点。
‘创建要素’,在右侧对话框中,选择要创建要素的图层及构造工具。在jpg图片上点击,描点。
添加属性内容:点击![]() ‘属性’和
‘属性’和![]() ‘编辑工具’,可通过点击来添加属性内容。||右键图层,点击“打开属性表”,添加内容。保存编辑内容,停止编辑。
‘编辑工具’,可通过点击来添加属性内容。||右键图层,点击“打开属性表”,添加内容。保存编辑内容,停止编辑。
创建线要素文件
创建线图层(是否需添加字段要看情况而定)矢量化:……一段线绘制完毕,双击鼠标左键||点击F2键,停止绘制。(若画线中断:打开‘拓扑工具条’!!!依情况选择点捕捉、端点捕捉、折点捕捉、边捕捉‘捕捉-捕捉到草图’可用于闭合时的连接绘制过程中出现错误:ctrl+z取消输入)。
绘制完出现错误:点击![]() ‘编辑工具’,选中绘制错的线;点击
‘编辑工具’,选中绘制错的线;点击![]() ‘分割工具’,在出错的位置处点击进行分割,选中绘制错的线,delete键,删除。
‘分割工具’,在出错的位置处点击进行分割,选中绘制错的线,delete键,删除。
标注属性:右击县驻地图层,√“标注要素”||“属性-标注”√标注此图层中的要素,标注字段选名称
拓扑检查与修改 !!!拓扑要建在要素集基础上 而不是数据库中
打断相交线:点击![]() ‘编辑工具’,选中所有参与构面的线要素,“编辑器—更多编辑工具—高级编辑器—打断相交线”
‘编辑工具’,选中所有参与构面的线要素,“编辑器—更多编辑工具—高级编辑器—打断相交线”
新建拓扑:新建geodatebase、数据集、导入已打断相交线的shapefile;右键数据集,“新建—拓扑”,规则为:不能自重叠,不能自相交,不能有悬挂点;验证。
查看拓扑错误:将Topolog文件拖到窗口,分三种错误,点错误、线错误、面错误。若有拓扑错误其会在地图显示窗口显示出来||“编辑器—高级编辑器—拓扑—‘![]() 错误检查器’”
错误检查器’”
修改拓扑错误:在拓扑错误检查器中,右击每一行拓扑错误,选择缩放至或者放大至,定位拓扑错误再修改。再删除之前的Topolog文件,新建拓扑,直至无错。
线转面要素
在拓扑修改的线要素的基础上,“Arctoolbox—数据管理工具—要素—要素转面”
影像配准
1.jpg为扫描图,无空间信息!
地理坐标系:经纬度坐标来描述地球上某点的位置,基于一个基准面来定义的。
GCS_WGS1984(基于WGS84 基准面)lGCS_BEIJING1954(基于北京1954基准面)
GCS_XIAN1980(基于西安1980基准面)
投影坐标系:基于X,Y值的坐标系统来描述地球上点的位置。这个坐标系是从地球的近似椭球体投影得到的,它对应于某个地理坐标系。由两个参数确定:地理坐标系(由基准面确定,比如:北京54、西安80、WGS84)和投影方法(比如高斯-克吕格、Lambert投影、Mercator投影)ArcGIS中有几十种常用投影方法对应有地理变换和投影变换。
2.根据栅格数据已知控制点坐标配准。
右击ArcMap工具栏空白处,√“地理配准”工具,添加需要进行配准的影像
输入控制点坐标:去掉√地理配准按钮菜单下的“自动校正”,点击地理配准工具栏上的![]() ‘添加控制点’,精确点击控制点,输入X、Y坐标,点击
‘添加控制点’,精确点击控制点,输入X、Y坐标,点击![]() ‘查看连接表’可对已输入的坐标进行修改
‘查看连接表’可对已输入的坐标进行修改
检查残差是否满足:在“查看链接表”对话框中,将变换方式设置为“二阶多项式”。查看控制点的残差和RMS(总误差),删除残差特别大的控制点并重新选取控制点(选择控制点,delete)
校正:“地理配准—校正”,输出类型为TIFF
设置空间参考:在目录中,右击栅格数据“属性—常规—空间参考”,若为未定义,点击“编辑”,选择与扫描地图相同的投影坐标系。||“Arctoolbox—”
根据栅格数据与其他数据(栅格或者矢量数据)同名控制点坐标配准。
定义投影
Arctoolbox - 数据管理工具 - 投影和变换 - 定义投影
内容列表中,右键图层“属性—源”可查看图层的坐标系
目录列表中,右键图层“属性—X、Y坐标系”可设置坐标
投影变换
Arctoolbox - 数据管理工具 - 投影和变换 - 要素 - 投影(从一个已知的地理坐标系投影到另一个投影坐标系,或返过来)
裁剪提取
Arctoolbox —分析工具— 提取分析— 裁剪输入要素为要分割的对象(云南),裁剪要素为clip
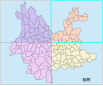
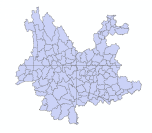
拼接图层
Arctoolbox - 数据管理工具 - 常规 - 追加(将其他图层加到一个图层中,形成一个图层,原来clip3显示1/4云南,追加后clip3显示云南整体。可右键clip3图层“数据—导出数据”)
输入数据集为clip0、clip1、clip2,目标数据集为clip3
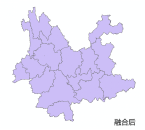
要素融合
Arctoolbox - 数据管理工具 - 制图综合 - 融合,将属性表中xxx(所属州)字段相同的融合到一起
图层合并
Arctoolbox - 分析工具 - 叠加分析 - 联合
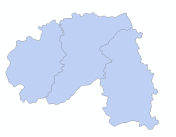
图层相交(矢量数据)
Arctoolbox - 分析工具 - 叠加分析 - 相交
 打开空间分析许可:自定义窗口》拓展模块》spatial analyst
打开空间分析许可:自定义窗口》拓展模块》spatial analyst
掩膜提取(栅格数据)
Spatial Analysis工具>>>提取分析>>>按掩膜提取(先新建面要素,再提取图层中对应面要素的内容)
提取面图层中的点数据或线数据
 “选择”——“按位置选择”,目标图层选择线要素(目标是提取部分线要素),源图层为面要素,会高亮显示面图层中的点数据或线数据,有键线要素图层,“数据”——导出选中的数据。
“选择”——“按位置选择”,目标图层选择线要素(目标是提取部分线要素),源图层为面要素,会高亮显示面图层中的点数据或线数据,有键线要素图层,“数据”——导出选中的数据。
重分类
Spatial Analysis工具>>>重分类>>>重分类(重分类字段为value,旧值为数字区间,新值为数值)输出栅格的位置需为地理数据库,重分类和面转栅格时都需注意环境-处理范围的设置!
栅格重分类操作可以将连续栅格数据转换为离散栅格数据(连续栅格数据没有属性表)
判断栅格是否满足条件
空间分析>>>地图代数>>>栅格计算器
“Slope1”<=25 符合条件则栅格图层的value值返回为1,否则为0)输出栅格的位置尽量不变
交叉面积数据表
Spatial Analysis工具>>>区域分析>>>面积制表

连续栅格数据slop坡度数据重分类后分成离散数据5段,连续栅格数据landuse,虽没有属性表,但可查看属性表-符号系统-唯一
分区统计
Spatial Analyst Tools>>>区域分析>>>以表格显示分区统计

不同粮食产区(value1-5)(先将连续栅格数据重分类)土壤有机质含量(MEAN)
缓冲区分析
分析工具>>>邻域分析>>>缓冲区[只能建立单个缓冲区,若要设定多层缓冲区,则选择多环缓冲区缓冲区域的颜色相同],有缓冲范围,原始数据不能是栅格数据,只能是矢量数据.融合类型选择all
叠加分析
分析工具>>>叠加分析>>>相交/擦除.
离城市主要交通线路50m以内,以保证商场交通的通达性。保证在居民区100m范围内,便于居民步行达到商场。距停车场100m范围内,便于顾客停车。叠加距已经存在的商场500m范围以外,减少竞争压力。擦除
区位分析
1.属性赋值:打开四个缓冲区文件,添加字段,开始编辑,赋值为1/-1(商场)
2.区域叠加:分析工具>>>叠加分析>>>联合取两个图层的并集,合二为一
添加停车场、居民地、主要街道、已存在商场缓冲区四个文件,输出四要素缓冲区联合.shp
3.分级:在联合.shp中添加字段>>>字段计算器[othermarke] + [stops] + [mainstreet] + [residentia].class值为3为第一等级。class值为2为第二等级。第三等级:class值为1。第四等级:class值为0。第五等级:class值为-1。
4.图层属性>>>唯一值缓冲区分析:Spatial Analyst Tools>>>距离分析>>>欧氏距离[自动划分不同类型的缓冲,缓冲区内距离不同颜色不同]原始数据为栅格/矢量数据,无设定缓冲范围,可有研究区域限定,缓冲后为栅格数据!若只选中图层中的某些要素,则缓冲区分析只对选中的要素进行;否则,对整个图层的所有要素进行。 环境设置中的处理范围选择与显示相同!



无环境设置/默认/与图层point相同(以端点做边的矩形)/与studyarea相同(有研究区域)
!!!矢量数据缓冲区分析能用Spatial Analyst Tools中的距离分析欧式距离,能用空间分析的邻域分析的缓冲区。栅格数据(含有value值)只能用欧式距离

