
- 1uniapp 总结篇 (小程序)_uniapp开发小程序
- 2chatgpt赋能python:用Python画龙:SEO技巧大放送_用python画一条龙
- 3!!!亲测成功:langchain+ChatGLM 大模型部署_chatglm3 如何langchain结合
- 4tf.data.Dataset.map()函数的理解
- 5基于yolov5的目标检测-停车位检测、低矮障碍物、地面标识检测等_yolo算法准确识别车辆,车位划线
- 6微信小程序接入直播_微信小程序如何对接直播
- 7基于本地知识库的大模型搭建教程_python 个人知识库搭建
- 8Gradle下载以及安装教程_gradle-5.5.1-bin.zip
- 9C++异步变化:libunifex实现!
- 10面试知识点梳理及相关面试题(三) -- springcloud_springcloudalibaba面试题
人工智能课程设计毕业设计——基于机器学习的手写汉字识别系统_人工智能文字识别毕业设计
赞
踩
需要完整代码和论文私信我

《机器学习》课程设计实验报告
题目:基于深度学习的手写汉字识别系统
1.绪论............................................................................................................................................................ 1
1.1 研究背景及意义.......................................................................................................................... 1
1.2 国内外研究现状.......................................................................................................................... 1
1.3 研究内容....................................................................................................................................... 2
2.相关技术概述........................................................................................................................................... 2
3.数据准备.................................................................................................................................................... 2
3.1 数据获取....................................................................................................................................... 2
3.2 数据预处理................................................................................................................................... 3
4.数据描述性分析....................................................................................................................................... 5
5.模型选择、训练与测试........................................................................................................................... 6
5.1深度学习与传统机器学习............................................................................................................ 6
5.2卷积神经网络................................................................................................................................. 6
5.3模型训练......................................................................................................................................... 8
5.4模型测试....................................................................................................................................... 14
6.模型性能评估与优化.............................................................................................................................. 15
6.1模型性能评估.............................................................................................................................. 15
6.2模型优化....................................................................................................................................... 16
7.模型部署与使用..................................................................................................................................... 18
7.1模型部署....................................................................................................................................... 18
7.2模型使用....................................................................................................................................... 18
8.总结.......................................................................................................................................................... 20
参考文献...................................................................................................................................................... 21
附录.............................................................................................................................................................. 23
(1) 程序清单............................................................................................................................................. 23
(2) 源代码................................................................................................................................................. 23
1.绪论
在上世纪60年代,美国IBM公司开始进行了对印刷体汉字的模式识别研究工作;1996年Casey和Nag用模板匹配法成功的识别出了1000个印刷体汉字,在全球范围内,基于汉字的识别研究开始展开了。而就在这个时候,研究界对手写汉字识别也掀起了高潮。日本率先开始研究手写汉字识别,到了80年代,国内开始了对手写汉字的研究,因为汉语作为我们的母语,汉字主要在我国广泛使用,对汉字的种类、内涵、造字原理国内的掌握情况较透彻,所以关于手写汉字识别的深入研究主要集中在国内。至今,手写汉字识别已经具备了比较成熟的理论基础和广阔的运用前景,近年来,随着机器学习和人工智能产业的高速发展,手写文字识别更是被广泛运用。
在实际运用中,手写汉字识别被用于汉字扫描、机器自动阅卷、票据识别、证件识别等,提高了汉字的输入效率,降低了手动输入汉字的错误率,极大便利了人们的工作和生活。手写体汉字识别是一个具有挑战性的模式识别和机器学习问题。汉字结构复杂,相似性大、数量大、种类多等特点给汉字识别研究带来很多困难,尤其是手写汉字识别,不同人具有不同的手写风格,在不同的书写环境下容易发生形变,再加上汉字又分为行书、草书、楷书等多种形式,手写汉字识别问题的研究一直困扰着字符识别研究学者的一个关键性难题。
本次机器学习课程设计项目我们小组基于卷积神经网络算法设计了手写汉字识别系统,采用卷积神经网络实现的低成本和快速高效手写汉字图像识别系统,将在日常工作和生活中带来极大的现实意义,同时也有着非常重要的研究意义。
如今在手写字识别领域,存在的识别方法有多种。手写汉字识别由于数据采集方式不同可以划分为脱机手写体汉字识别和联机手写体汉字识别两大类:联机手写汉字识别所处理的手写文字是书写者通过物理设备(如数字笔、数字手写板或者触摸屏)在线书写获取的文字信号,书写的轨迹通过定时采样即时输入到计算机中;而脱机手写文字识别所处理的手写文字是通过扫描仪或摄像头等图像捕捉设备采集到的手写文字二维图片。目前,比较常用的手写汉字识别方法有K最近邻算法、神经网络、隐马尔可夫模型、贝叶斯分类器、支持向量机和改进的二次判别函数等。
特别是最近几年来随着深度学习理论研究的不断深入和运用场景和不断扩大,深度学习理论不断颠覆了传统的识别算法,已经成为模式识别领域研究热点之一,也在影响着字符识别的研究,越来越多的深度学习算法正在被运用在手写字识别领域。深度学习的引入使得手写单字符识别问题已经在某种程度上获得了较好的解决,但相对单字符识别而言,含序列信息的手写文本行识别仍然是此领域还未解决的难点问题之一。
目前,在我国,已经推出了多字体大字符集简繁混识的识别核心,能够识别常见的十几种字体及其变体,识别字符集包括简体中文6763字、繁体中文5401字、香港常用字等1万多字,各种字体的识别率都在99%以上。
本次课程设计主要是针对手写体汉字识别,通过对比采用不同模型所得到的结果,进行从中择优,对其中较好的模型以及其参数进行保留,同时搭建一个简单的GUI界面,最后用上述训练好的模型进行预测,得到识别结果。
2.相关技术概述
本次课程设计的相关代码都是是基于python编写的,其中用到的框架和库有tensorflow、sklearn、OpenCV、numpy等等,而我们此次用到的主要框架也是tensorflow,准确地说是tensorflow -gpu。
TensorFlow:提供Python语言下的四个不同版本:CPU版本(tensorflow)、包含GPU加速的版本(tensorflow-gpu),以及它们的每日编译版本(tf-nightly、tf-nightly-gpu)。TensorFlow就好像一个功能强大的机床,它可以帮助制造出不同的产品(即数学模型),用它来处理大量数据,可以快速建立数学模型,而这些模型可以完成智能功能。用tensorflow-gpu会比CPU版本快上好几十倍以上。
3.数据准备
本次实验采用中国科学院自动化研究所提供的手写体汉字数据集CASIA-HWDB1.1进行实验。CASIA-HWDB1.1数据集包含了3755个常用的GB2312一级汉字,由300个不同的编写者书写,每个汉字的样本库包含240个训练样本和60个测试样本。
以下分别是训练集和测试集的地址:
http://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1trn_gnt.ziphttp://www.nlpr.ia.ac.cn/databases/download/feature_data/HWDB1.1tst_gnt.zip将上述文件解压后可以分别得到HWDB1.1trn_gnt.alz和HWDB1.1tst_gnt.alz ,alz也属于一种压缩文件的格式,需要进行二次解压,再次解压就会得到gnt文件。
3.2.1数据读取
分别读取HWDB1.1trn和HWDB1.1tst两个文件夹中的数据,并最终将数据存储在char_dict字典中,计算该字典的长度,共计3755。


图3-1
3.2.2图片格式转换
将训练集和测试集中的文件格式由gnt格式转换为png(3通道)格式,并分别统计其中的图片数目,得到训练集中有89万余张图片,测试集中则有22万余张图片。

图3-2
选择其中一个文件夹查看一下转换后的效果,如下图:

图3-3
3.2.3查看数据集标签
读取并查看训练集的标签,即汉字和对应编码的位置。

图3-4
3.2.4图像处理
查看解码后的图片,发现其分辨率不统一,有长有短,所以我们统一把数据转成64x64,并做归一化处理,这里调用 cv2 库读入图片,并用resize方法统一像素为64x64 。


图3-5
3.2.5划分训练集和验证集
在训练集中取一部分作为验证集,test_size=0.25,radom_state=7。

图3-6
4.数据描述性分析
数据集一共包含3755类手写汉字,训练集来自240人写的897758个汉字,测试集来自60人写的223991个汉字。而且解码后图片的规格大小也完全不同,从30x42规格到101x54规格不等。
虽然单张图片的大小也就不到几KB,但由于数据集数量庞大,读取速度就会特别慢,而且通过一层层神经网络之后数据的维度就逐渐放大,读取的时候就会占用大量内存,甚至直接爆满。普通电脑或笔记本的CPU根本就跑不了这么多类。100个类可以跑,200个类也还行,到了1000个类,直接十几个小时数据都没读取完,因为估计CPU已经运作不起来了,所以一直卡着。因为电脑配置的限制,最终我们只能选择训练500个类,也就是训练500个汉字,而且还是因为租借了谷歌云服务器才能最终等到跑完这500个类。
5.模型选择、训练与测试
5.1深度学习与传统机器学习
我们都知道,传统的机器学习可以用来做许多的东西,例如模式识别、数据挖掘计算机视觉和语音识别等领域。但传统的机器学习也有自己的短板方面,例如传统的机器学习需要人工去提取特征,然而深度学习不需要。深度学习通常由多个层组成,它们通常将更简单的模型组合在一起,将数据从一层传递到另一层来构建更复杂的模型。通过训练大量数据自动得出模型,不需要人工特征提取环节。这个特点在数据规模比较大的数据集上可以很好的体现出来两者之间的差距,并且深度学习的表达能力仍然要强与传统的机器学习。
传统的机器学习与深度学习性能差距在数据规模上,我们可以看一组对比图,可以看到在不同的数据规模,深度学习与传统的机器学习之间的差距就很明显的体现出来了,如下图所示。

图5-1
5.2卷积神经网络
本次课程设计项目使用的数据是为图片数据,图片数据对于普通的数据而言,它拥有的数据特征数量都是比较大的,并且数据规模也很大。所以传统的机器学习模型已经满足不了我们的需求,所以本次课程设计使用的训练模型是深度学习中的卷积神经网络(CNN)。
CNN由纽约大学的Yann Lecun于1998年提出,其本质是一个多层感知机,它的部分特点在于减少了权值的数量使得网络易于优化,并且还降低了模型的复杂度,也就是减小了过拟合的风险。对于输入数据为图像数据的时候,它的表现的更为明显,因为图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建的过程,在二维图像的处理过程中有很大的优势。所以许多的图像识别分类项目中都被大量使用,其中比较著名的模型有LeNet5 模型、AlexNet 模型、VGG 模型、GoogleNet模型和ResNets模型等,它们都是图像分类任务中被大量使用,可以很明显体现出卷积神经网络对于图像分类的优势。
深度神经网络的基本思想是通过构建多层网络,对目标进行多层表示,以期通过多层的高层次特征来表示数据的抽象语义信息,获得更好的特征鲁棒性。它与普通的神经网络对比,层数更加多,结构更加复杂,下图是普通的神经网络结构图。普通的神经网络结构包括:输入层、隐藏层和输出层,其中隐藏层是可以拥有多层的结构。

图5-2
卷积神经网络结构包括:输入层、卷积层、池化层、全连接层和输出层等。每一层有多个特征图,每个特征图通过一种卷积滤波器提取输入的一种特征,每个特征图有多个神经元。所以除了输入层和输出层,卷积神经网络的其他层都可以拥有多层的结构,与普通神经网络结构对比,它的结构更加复杂,层数更加多,如下图一个经典的汽车识别分类的案例所示。

图5-3
5.3模型训练
模型的训练环境、软硬件如下表:
| 环境 | 版本号、其他信息 |
| 笔记本 | 华硕飞行堡垒7 |
| 操作系统 | Windows 10专业版本 |
| 编程语言 | Python3.7 |
| 模型框架 | Tensorflow2.4.0、Keras2.5.0 |
| 服务器 | Google Colab PRO |
| GPU | Tesla T100 |
表5-1
对于已经进行预处理的图片数据进行随机选取的500个类别进行模型的训练,初步的模型训练只是用于来选取最佳的模型参数,训练出最佳的卷积神经网络模型。500个手写汉字类别,每个类别是240张图片,一共的训练集是120000张图片,验证集一共是30000张图片。每张图片经过初步的图像预处理,使得尺寸统一为64*64,为RGB的三个通道,数据规模非常庞大。
此处需要对图片进行读取,对图片数据转换为数字格式,因为计算机只认识数字类型的数据。对于图片数据的读取,我们使用到了Python的一个OpenCv库,用于图像的读取以及图像的特征提取,如下图所示。主要是使用到了Python的numpy库与opencv库。由于图片数据规模较大,基于Tesla T100的GPU,读取120000张训练图片的时间需要15分钟左右,读取30000张测试图片需要3分钟左右。训练数据的读取方式与测试数据的读取方式一致。

图5-4
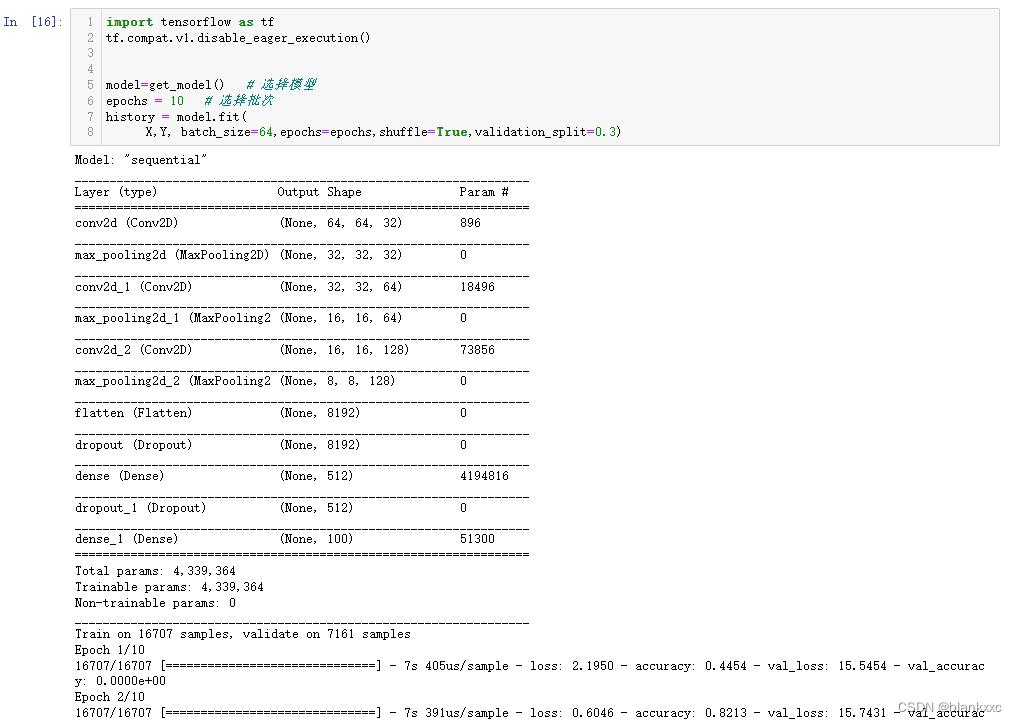
接下来是定义一个卷积神经网络。本次的卷积神经网络是基于tensorflow的一个框架进行定义,如下图代码所示。该模型使用了4个卷积层,每个卷积层后添加了一个池化层,池化层的作用是可以把卷积层增加的大量特征进行缩小。后面还用到了扁平层,用于把数据“拉直”,便于后面的全连接层计算。模型的最后使用了两层全连接层,最后一层使用了softmax激活函数,该函数使用与多分类的模型当中,其中最后的输出类别为500个类别。

图5-5
由于模型的训练结果需要展示,此处还自定义了一个可以展示模型训练结果的一个函数,如下图所示,该函数主要是使用到了Python的matplotlib库,可以画出自定义的卷积神经网络训练效果图片。代码设计如下图所示。

图5-6
使用上面自定义的读取图片数据的函数,对图片数据进行一个读取且转化成为一个数值型数据。

图5-7
最后到了模型的训练阶段,此处的模型训练我们使用tensorflow模型框架的fit()函数对数据进行训练,对于训练结果,使用自定义的函数对其进行展示,查看模型的训练效果。如下图所示。对于模型的结构图,我们使用到了一个keras框架的一个特殊功能进行打印,并且需要安装好Python的两个graphviz和pydot2模块才可以进行使用。

图5-8
许多人喜欢使用Tensorflow框架的原因,是因为深度学习模型的训练过程中可以输出模型的详细参数和模型的详细训练过程,如下图所示,展示了自定义的卷积神经网络的各层的详细参数如下图所示。

图5-9
其中最左边的Layer是模型中的各个层的名称,中间的Output Shape是指该层输出的数据类型大小,例如(None,64,64,32)是指图像经过第一层的卷积后输出的数据大小。None指的是图片数量不进行确认,64、64分别是指图像经过第一层卷积之后图像的长和宽为64和64。64和64的由来是因为图片的输入为(64,64,3),通过计算一下卷积公式计算得来,其中O是输出尺寸,K是卷积核大小,P是填充,即是参数padding,S是步长(卷积的移动长度)。该模型的输入图像大小为64,步长为1,卷积核大小为5,所以输出尺寸为(64-5+(5-1)/2)/1+1=64,所以第一层的输入图像尺寸为64*64,输出图像大小也为64*64。
P=(K-1)2

(1)
O=W-K+2PS+1

(2)
最后的一个32,指的是该层的神经元个数,也可以易懂的理解为卷积之后的图片层数(第一层的图片是RGB三个通道,为三层)。我们可以看到最右边Param指的是参数个数,例如第一层的参数个数为2432,计算公式如下,其中K指的是卷积核大小,C1指的是前一层的神经元个数(或者是图片层数,例如一般彩色图片的输入为RGB三层),C2是指自身卷积层的神经元个数(图片层数)。例如第一层,卷积核大小为5,前一层是输入层,输入层的层数为3,该卷积层有32个神经元,所以5*5*3*32+32=2432,最后加上的是一个偏置数,有多少层就需要加上多少个偏置数。其他层的输出大小和参数个数计算与上一致。我们可以查看上图最后输出的参数总和为19907892个,参数量很大。
Param=K*K*C1*C2+C2*1

(3)
Tensorflow框架还可以在模型的训练过程中输出模型的训练过程,如下图所示,Tensorflow框架不仅仅可以输出每一个批次的训练过程的进度条和训练时间,还可以输出每一个训练批次的训练结果,例如训练集的训练损失、验证集的训练损失,还有训练集和验证集的每一个批次的准确率。

图5-10
在此次的模型训练中,除了上述的卷积神经网络,此处还使用了两个传统机器学习模型进行对比,用来对比深度学习与传统的机器学习对于在大规模数据的模型训练效果的差异,如下表和图所示。
| 模型 | 训练集准确率 | 验证集准确率 |
| KNN | 56.69% | 49.83% |
| SVM | 68.67% | 52.23% |
| 自定义CNN1 | 92.77% | 79.34% |
| 自定义CNN2 | 97.89% | 82.12% |
| 自定义CNN3 | 96.58% | 85.56% |
表5-2
由于传统的机器学习模型训练的效果不佳,此处不展示两个传统机器学习模型的训练结果,直接展示自定义的三个卷积神经网络的模型训练结果图,CNN1、CNN2和CNN3的训练结果图依次往下所示。我们很直观的发现,自定义的卷积神经网络训练集的准确率都达到了92%以上,验证集的准确率都达到了79%以上,可以很明显发现在大规模数据下,使用深度学习的效果要明显好于传统的机器学习模型。


图5-11 自定义CNN1 图5-12 自定义CNN2

图5-13 自定义CNN3
5.4模型测试
由于在本次的项目中,传统的机器学习模型的训练效果不佳,所以不对传统的机器学习模型进行测试。对于上述三个自定义的卷积神经网络,使用训练好的模型,对测试集30000张手写汉字图像数据进行预测,得到的测试结果如下图所示。我们可以发现目前最高的模型测试结果已经达到了82.48%,但是结果还达不到我们的期望,还需要对模型进行优化。

图5-14
6.模型性能评估与优化
6.1模型性能评估
对于自定义的三个卷积神经网络模型,我们可以发现模型的训练效果较好,训练集的准确率最高达到了97.89%,验证集的准确率最高为85.56%,但是两个数据集合的最高准确率都不在同一个训练模型中,所以我们需要对自定义的卷积神经网络模型继续修改参数进行优化,使得性能达到我们期望的效果。

图6-1
6.2模型优化
由于卷积神经网络的参数量很大,并且训练时间较长,所以对参数的调整也是一个本次项目中的一个难点。本次项目的参数调整为人为调整,凭借着自己的模型训练经验和当前的训练结果对模型的参数进行修改。
查看了许多优秀的卷积神经网络的项目,里面给出了基于Tensorfolw框架大量有价值需要调整的参数,例如在卷积层当中,可以修改卷积核大小,每层的神经元个数,每层卷积的填充值大小,还有每层卷积的步长(滑动步长)和激活函数等。经过多次的训练对比,训练得出500种手写汉字的卷积神经网络最佳参数如下表所示。
| 参数名称 | 参数大小、其他 |
| 卷积层 | 4层 |
| 卷积核 | (5,5) |
| 每层卷积的神经元个数 | 32,64,128,256 |
| 填充值 | 2 |
| 滑动步长 | 1 |
| 激活函数(除最后一层) | relu |
| 激活函数(最后一层) | softmax |
| 优化算法 | 随机梯度下降(Stochastic Gradient Descent,SGD) |
| Dropout layer | 0.2 |
| batch-size | 64 |
| epochs | 18 |
表6-1
最优卷积神经网络模型结构图如下所示(从左往右),详细展示了各层的输入和输出参数大小。


图6-2
最终得到的最优模型训练和测试的结果如下图所示。

图6-3
模型的最优训练效果如下图所示,我们可以发现模型的收敛性较好,训练集与验证集之间的损失数大小相差不大。最终的模型,无论是在训练集的准确率、验证集的准确率还是测试集的准确率都是最高的,并且从模型的训练效果中可以看出模型的收敛性较好。

图6-4
7.模型部署与使用
7.1模型部署
在模型训练的时候已经把模型的相关训练权重保存为h5文件,可直接通过tf.keras.models.load_model()直接读取该模型,再通过model()方法预测结果。

图4-1
7.2模型使用
这里我们调用PyQt5库,简单地做了一个GUI界面,设置了一个画板来绘画并保存图片,以及将预测结果的方法包装成组件,最后通过点击组件按钮对画板传输过来的图片进行识别,将结果打印在控制台上。运行效果如下:

图7-2
在画板上写字,并点击“开始识别”,得到结果如下:

图7-3
点击“清空画板”,再重新写字和识别,如下图:

图7-4

图7-5

图7-6

图677
从上述测试结果可以看出,当字体居中而且特征明显时,识别结果的可能概率近乎于1;而当字体没有很明显的指向某个字的特征时,识别结果的可能概率就会很低。
8.总结
在本次的机器学习课程设计中,我们组实现了手写汉字识别系统,其中包括对深度学习的卷积神经网络模型的训练还有系统GUI界面的设计。本次课程设计的手写汉字数据来源于中国科学院自动化研究所提供的手写体汉字数据集CASIA-HWDB1.1的前500种手写汉字,每个类别的训练数据为240张手写汉字图片,每一类的测试数据为60张手写汉字图片,数据量是非常的庞大,对电脑硬件上有很大的要求。
我们自定义的卷积神经网络进行参数的修改和其他方面的改变,最终最优的卷积神经网络在500种手写汉字的识别任务上训练集的准确率达到了98.9%,验证集的最高准确率达到了88.14%,测试集的准确率也达到了87.3%,模型的训练效果非常可观。
在本次课程设计当中,我们第一次使用到了深度学习的模型和使用GPU来训练大规模的数据。我们发现在大规模数据上,无论是模型的训练效果上还是模型的训练时间,深度学习模型要比传统的机器学习模型的效果好许多。例如在同一个环境中,传统的机器学习KNN,训练一个模型和预测测试数据需要49分钟左右,而自定义卷积神经网络训练和预测测试数据只需要8分钟左右。
由于本次课程设计选择的数据量很大,仅训练图片就有120000多张,本地笔记本电脑无法实现对数据的读取和模型的训练,所以本次课程设计我们还是用到了Google的一个服务器,利用提供的GPU对数据进行一个读取和模型的训练。我们发现利用GPU对于数据的读取和模型的训练速度是非常快,若没有GPU,对于大量数据的网络训练会非常的耗时。在某种意义上来讲,训练深度网络时,GPU比CPU快40倍左右。CPU适合复杂的逻辑运算,GPU适合矩阵运算,深度学习大部分的模型训练的算法运算都采用了矩阵运算,而且CPU的核心数要比GPU少,模型训练需要很多并行的矩阵运算,GPU在深度学习模型的训练上显得非常的出色。
经过上学期的机器学习课程的学习,和本次课程设计的实践,我们组成员学到了如何利用GPU来训练大规模数据的深度学习模型,并且理解了许多深度学习模型的参数含义,并且可以自己设计自定义的深度学习模型和设计模型识别系统的GUI界面,使得我们对机器学习的认识更进一步。
[1]薛炳如,杨静宇,胡钟山,等. 小类别数手写汉字识别[J]. 计算机研究与发展,2000,37(4):483-492.
[2]李璐璐. 基于弹性网格的手写体识别二级分类器的研究[D]. 广东:华南理工大学,2008. DOI:10.7666/d.Y1384676.
[3]瞿海金. 手写体数字识别方法的研究与实现[D]. 江苏:南京理工大学,2005. DOI:10.7666/d.y763434.
[4]金连文,钟卓耀,杨钊,等. 深度学习在手写汉字识别中的应用综述[J]. 自动化学报,2016,42(8):1125-1141. DOI:10.16383/j.aas.2016.c150725.
[5]高学,王有旺. 基于CNN和随机弹性形变的相似手写汉字识别[J]. 华南理工大学学报(自然科学版),2014(1):72-76,83. DOI:10.3969/j.issn.1000-565X.2014.01.013.
[6]周甲甲. 基于深度学习的汉字识别方法研究[D]. 湖北:华中师范大学,2019.
CNN_1 .ipynb和CNN_2 .ipynb和CNN.ipynb这三个文件主要在模型结构有差异,其它地方类似,所以代码的完整的注释在CNN.ipynb中,而Machine learning.ipynb是传统的机器学习模型,ImageChange.ipynb则是图片格式转换,GuiMain.ipynb则是最终运行界面。

(2) 源代码
CNN.ipynb
#对训练数据进行加载并且转换
import os
import cv2
import numpy as np
import matplotlib.image as mi
from sklearn.model_selection import train_test_split
dataset1 = [] # 数据集列表
labels1 = [] # 标签列表
label1 = 0 # 第一个标签
def load_data1(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label1
load_data1(fi_d)
label1 += 1 #图像类别的标签
else:
labels1.append(label1)
img = mi.imread(fi_d[:-1]) #对图像数据进行读取
img2 = cv2.resize(img, (64, 64)) # 对图像数据进行转换,大小为(64,64,3)
dataset1.append(img2) #把读取得到的一个图像数据添加到数组内
# 在训练集中取一部分作为验证集
train_image, val_image, train_label, val_label = train_test_split(
np.array(dataset1), np.array(labels1), random_state=7)
return train_image, val_image, train_label, val_label #返回读取得到的图像数据和图像标签
#对测试数据进行加载并且转换
import os
import cv2
import numpy as np
import matplotlib.image as mi
dataset2 = [] # 数据集列表
labels2 = [] # 标签列表
label2 = 0 # 第一个标签
def load_data2(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label2
load_data2(fi_d)
label2 += 1
else:
labels2.append(label2)
img = mi.imread(fi_d[:-1])
img2 = cv2.resize(img, (64, 64)) # (64,64,3)
dataset2.append(img2)
return np.array(dataset2), np.array(labels2)
#使用tensorflow框架对自定义对卷积神经网络模型结构进行定义
import tensorflow.keras.backend as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D
def get_model():
# 创建一个新模型,使用的是keras框架下的一个Sequential模型
model = Sequential()
model.add(Conv2D(32, (5,5), padding='same', activation='relu', input_shape=(64, 64, 3))) #设计第一个卷积层,卷积核为5*5,32个神经元,激活函数为relu函数,输入图像大小为64*64*3
model.add(MaxPooling2D(pool_size=(2, 2))) #设计一个池化层,对卷积之后的数据进行最大池化处理,池化大小为2*2
model.add(Conv2D(64, (5,5), padding='same', activation='relu')) #第二个卷积层,卷积核一样为5*5,64个神经元,激活函数为relu
model.add(MaxPooling2D(pool_size=(2, 2))) #第二个池化层,池化大小为2*2
model.add(Conv2D(128, (5,5), padding='same', activation='relu')) #与上类似
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten()) #扁平层,类似于把数据“拉直”
model.add(Dropout(0.2)) #防止数据过拟合
model.add(Dense(4096, activation='relu')) #全连接层,大小为4096,激活函数为relu
model.add(Dropout(0.2))
model.add(Dense(500, activation='softmax')) #最后一个全连接层,也为输出层,激活函数选择了softmax函数,输出类别为500个
model.summary() #模型可视化
# 选择优化器和损失函数
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',#categorical_crossentropy,独热编码才用的交叉熵
metrics=['accuracy'])
return model
#也是自定义模型,遇上一致
import tensorflow.keras.backend as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D
def get_model():
# 创建一个新模型
model = Sequential()
model.add(Conv2D(64, (3,3), padding='same', activation='relu', input_shape=(64, 64, 3))) # 64 64 3
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(500, activation='softmax'))
model.summary()
# 选择优化器和损失函数
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',#categorical_crossentropy,独热编码才用的交叉熵
metrics=['accuracy'])
return model
#自定义的模型训练效果绘画函数
import matplotlib.pyplot as plt
def show(epochs_range, train_loss, val_loss, train_accuracy, val_accuracy, name):
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.savefig(name)
plt.show()
#以下代码都是读取数据和对模型进行训练
from keras.utils.vis_utils import plot_model
model = get_model() # 选择模型
epochs = 18 # 选择批次
# 训练, fit方法自带shuffle随机读取
history = model.fit(
train_image, train_label, batch_size=64,epochs=epochs, validation_data=(val_image, val_label))
# 测试, 单用evaluate方法不会自动输出数值,需要手动输出他返回的两个数值
test_scores = model.evaluate(test_image, test_label)
#取出模型的训练结果值,如准确率和损失值,用于绘图
epochs_range = range(1, epochs+1)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
test_loss = test_scores[0]
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
test_acc = test_scores[1]
#使用Python的一个库,画出模型的结构图
plot_model(model, to_file="model11.png",show_shapes=True);
print("model's photo has done!")
# 将模型保存为 HDF5 文件
model.save('./Chinese_recognition_model11.h5')
print("save model: Chinese_recognition_model11.h5")
# 绘制图表
show(epochs_range, train_loss, val_loss, train_acc, val_acc, 'Model_score_v111')
# 打印得分
print('')
print('train loss:', train_loss[-1], ' ', 'train accuracy:', train_acc[-1])
print('val loss:', val_loss[-1], ' ', 'val accuracy:', val_acc[-1])
print('test loss:', test_loss, ' ', 'test accuracy:', test_acc)
print('')
#加载Google云盘
import os
from google.colab import drive
drive.mount('/content/drive')
# path = "/content/drive/My Drive"
path = "/content/"
os.chdir(path)
os.listdir(path)
#获取训练数据
import os
import cv2
import numpy as np
import matplotlib.image as mi
from sklearn.model_selection import train_test_split
dataset1 = [] # 数据集列表
labels1 = [] # 标签列表
label1 = 0 # 第一个标签
def load_data1(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label1
load_data1(fi_d)
label1 += 1
else:
labels1.append(label1)
img = mi.imread(fi_d[:-1])
img2 = cv2.resize(img, (64, 64)) # (64,64,3)
dataset1.append(img2)
# 在训练集中取一部分作为验证集
train_image, val_image, train_label, val_label = train_test_split(
np.array(dataset1), np.array(labels1), random_state=7)
return train_image, val_image, train_label, val_label
#获取测试数据
import os
import cv2
import numpy as np
import matplotlib.image as mi
dataset2 = [] # 数据集列表
labels2 = [] # 标签列表
label2 = 0 # 第一个标签
def load_data2(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label2
load_data2(fi_d)
label2 += 1
else:
labels2.append(label2)
img = mi.imread(fi_d[:-1])
img2 = cv2.resize(img, (64, 64)) # (64,64,3)
dataset2.append(img2)
return np.array(dataset2), np.array(labels2)
#定义卷积神经网络架构
import tensorflow.keras.backend as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D
def get_model():
# 创建一个新模型
model = Sequential()
model.add(Conv2D(32, (5,5), padding='same', activation='relu', input_shape=(64, 64, 3))) # 64 64 3
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(500, activation='softmax'))
model.summary()
# 选择优化器和损失函数
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',#categorical_crossentropy,独热编码才用的交叉熵
metrics=['accuracy'])
return model
#定义绘图函数
import matplotlib.pyplot as plt
def show(epochs_range, train_loss, val_loss, train_accuracy, val_accuracy, name):
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.savefig(name)
plt.show()
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
# 加载训练数据和测试数据
(train_image, val_image, train_label, val_label) = load_data1('train1/')
(test_image, test_label) = load_data2('test1/')
print("数据全部加载完毕!!!------------------------------------------------------------------------")
#模型训练数据
from keras.utils.vis_utils import plot_model
model = get_model() # 选择模型
epochs = 18 # 选择批次
# 训练, fit方法自带shuffle随机读取
history = model.fit(
train_image, train_label, batch_size=64,epochs=epochs, validation_data=(val_image, val_label))
# 测试, 单用evaluate方法不会自动输出数值,需要手动输出他返回的两个数值
test_scores = model.evaluate(test_image, test_label)
epochs_range = range(1, epochs+1)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
test_loss = test_scores[0]
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
test_acc = test_scores[1]
plot_model(model, to_file="model11.png",show_shapes=True);
print("model's photo has done!")
# 将模型保存为 HDF5 文件
model.save('./Chinese_recognition_model11.h5')
print("save model: Chinese_recognition_model11.h5")
# 绘制图表
show(epochs_range, train_loss, val_loss, train_acc, val_acc, 'Model_score_v111')
# 打印得分
print('')
print('train loss:', train_loss[-1], ' ', 'train accuracy:', train_acc[-1])
print('val loss:', val_loss[-1], ' ', 'val accuracy:', val_acc[-1])
print('test loss:', test_loss, ' ', 'test accuracy:', test_acc)
print('')
#!/usr/bin/env python
# coding: utf-8
# In[ ]:
import os
from google.colab import drive
drive.mount('/content/drive')
# path = "/content/drive/My Drive"
path = "/content/"
os.chdir(path)
os.listdir(path)
# In[ ]:
# import shutil
# shutil.rmtree("/content/drive/MyDrive/Chinese/train1")
# In[ ]:
import os
import cv2
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
import matplotlib.image as mi
import numpy as np
from sklearn.model_selection import train_test_split
a=[]
tr_data=[]
dirth='train1/'
for root, dirs, files in os.walk('train1/'):
for i in a[0]:
path=os.path.join(dirth,i)
label=a[0].index(i)+1
for j in tqdm(os.listdir(path)):
# try:
img=cv2.imread(os.path.join(path,j))
img=cv2.resize(img,(64,64))
tr_data.append([img,label])
# except Exception as e:
# pass
random.shuffle(tr_data)
X_tr=[]
Y_tr=[]
for x,y in tr_data:
X_tr.append(x)
Y_tr.append(y)
X_tr=np.array(X_tr)
X_tr=X_tr/255.0
Y_tr=np.array(Y_tr)
print("--------------------------------------------------------数据读取完成----------------------------------------------------------------")
# In[ ]:
import os
import cv2
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
b=[]
te_data=[]
dirth='test1/'
for root, dirs, files in os.walk('test1/'):
for i in b[0]:
path=os.path.join(dirth,i)
label=b[0].index(i)+1
for j in tqdm(os.listdir(path)):
try:
img=cv2.imread(os.path.join(path,j))
img=cv2.resize(img,(64,64))
te_data.append([img,label])
except Exception as e:
pass
random.shuffle(te_data)
X_te=[]
Y_te=[]
for x,y in te_data:
X_te.append(x)
Y_te.append(y)
X_te=np.array(X_te)
X_te=X_te/255.0
Y_te=np.array(Y_te)
print("--------------------------------------------------------数据读取完成----------------------------------------------------------------")
# In[ ]:
# import tensorflow.keras.backend as k
# from tensorflow.keras.models import Sequential
# from tensorflow.keras.layers import Dropout, Flatten, Dense
# from tensorflow.keras.layers import Conv2D, MaxPooling2D,ZeroPadding2D
# def get_model():
# k.clear_session()
# # 创建一个新模型
# model = Sequential()
# # model.add(ZeroPadding2D(1,1),input_shape=(64,64,3))
# model.add(Conv2D(64, (3,3), padding='same', activation='relu',input_shape=(64,64,3))) # 64 64 3
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(128, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(128, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(256, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(256, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(256, (3,3), padding='same', activation='relu'))
# model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(ZeroPadding2D(1,1))
# model.add(Conv2D(512, (3,3), padding='same', activation='relu'))
# model.add(MaxPooling2D(pool_size=(2, 2),strides=(2,2)))
# model.add(Flatten())
# # model.add(Dropout(0.2))
# model.add(Dense(4096, activation='relu'))
# model.add(Dropout(0.5))
# model.add(Dense(4096, activation='relu'))
# model.add(Dropout(0.5))
# model.add(Dense(500, activation='softmax'))
# model.summary()
# # 选择优化器和损失函数
# model.compile(optimizer='sgd',
# loss='sparse_categorical_crossentropy',#categorical_crossentropy,独热编码才用的交叉熵
# metrics=['accuracy'])
# return model
# In[ ]:
import tensorflow.keras.backend as k
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dropout, Flatten, Dense
from tensorflow.keras.layers import Conv2D, MaxPooling2D
def get_model():
# 创建一个新模型
model = Sequential()
model.add(Conv2D(32, (5,5), padding='same', activation='relu', input_shape=(64, 64, 3))) # 64 64 3
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(256, (5,5), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dropout(0.2))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(500,activation='softmax'))
model.summary()
# 选择优化器和损失函数
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',#categorical_crossentropy,独热编码才用的交叉熵
metrics=['accuracy'])
# tf.optimizers.SGD(learning_rate=0.01)
return model
# In[ ]:
import matplotlib.pyplot as plt
def show(epochs_range, train_loss, val_loss, train_accuracy, val_accuracy, name):
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_accuracy, label='Training Accuracy')
plt.plot(epochs_range, val_accuracy, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.savefig(name)
plt.show()
# In[ ]:
from keras.utils.vis_utils import plot_model
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
model=get_model() # 选择模型
epochs = 10 # 选择批次
# 训练, fit方法自带shuffle随机读取
history = model.fit(
X_tr,Y_tr, batch_size=64,epochs=epochs,validation_split=0.3)
# 测试, 单用evaluate方法不会自动输出数值,需要手动输出他返回的两个数值
test_scores = model.evaluate(X_te,Y_te)
epochs_range = range(1, epochs+1)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
test_loss = test_scores[0]
train_acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
test_acc = test_scores[1]
plot_model(model, to_file="model_1.png",show_shapes=True);
print("model's photo has done!")
# 将模型保存为 HDF5 文件
model.save('./Chinese_recognition_model_1.h5')
print("save model: Chinese_recognition_model_1.h5")
# 绘制图表
show(epochs_range, train_loss, val_loss, train_acc, val_acc, 'Model_score_v1_1')
# 打印得分
print('')
print('train loss:', train_loss[-1], ' ', 'train accuracy:', train_acc[-1])
print('val loss:', val_loss[-1], ' ', 'val accuracy:', val_acc[-1])
print('test loss:', test_loss, ' ', 'test accuracy:', test_acc)
print('')
# In[ ]:
# 拷贝文件到 /content
import shutil
shutil.copyfile('/content/drive/MyDrive/Chinese/test1.zip','/content/test1.zip')
# In[ ]:
# 解压缩文件
import zipfile
file_dir = '/content/test1.zip' # 你的压缩包路径
zipFile = zipfile.ZipFile(file_dir)
for file in zipFile.namelist():
zipFile.extract(file, '/content/') # 解压路径
zipFile.close()
# In[ ]:
import tensorflow as tf
from tensorflow.python.client import device_lib
print(device_lib.list_local_devices())
Machine learning.ipynb
import os
from google.colab import drive
drive.mount('/content/drive')
# path = "/content/drive/My Drive"
path = "/content/"
os.chdir(path)
os.listdir(path)
from google.colab import drive
drive.mount('/content/drive')
import os
import cv2
import numpy as np
import matplotlib.image as mi
from sklearn.model_selection import train_test_split
dataset1 = [] # 数据集列表
labels1 = [] # 标签列表
label1 = 0 # 第一个标签
def load_data1(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label1
load_data1(fi_d)
label1 += 1
else:
labels1.append(label1)
img = mi.imread(fi_d[:-1])
img2 = cv2.resize(img, (64, 64)) # (64,64,3)
img2 = img2.reshape(-1,)
dataset1.append(img2)
# 在训练集中取一部分作为验证集
train_image, val_image, train_label, val_label = train_test_split(
np.array(dataset1), np.array(labels1), random_state=7)
return train_image, val_image, train_label, val_label
import os
import cv2
import numpy as np
import matplotlib.image as mi
dataset2 = [] # 数据集列表
labels2 = [] # 标签列表
label2 = 0 # 第一个标签
def load_data2(filepath):
# 遍历filepath下所有文件,包括子目录
files = os.listdir(filepath)
for fi in files:
fi_d = os.path.join(filepath, fi+'/')
if os.path.isdir(fi_d):
global label2
load_data2(fi_d)
label2 += 1
else:
labels2.append(label2)
img = mi.imread(fi_d[:-1])
img2 = cv2.resize(img, (64, 64)) # (64,64,3)
img2 = img2.reshape(-1,)
dataset2.append(img2)
return np.array(dataset2), np.array(labels2)
# 加载训练数据和测试数据
(train_image, val_image, train_label, val_label) = load_data1('train2/')
(test_image, test_label) = load_data2('test2/')
print("数据全部加载完毕!!!------------------------------------------------------------------------")
#KNN模型的训练和预测
# 导入第三方模块
from sklearn import metrics
from sklearn import neighbors
knn_class = neighbors.KNeighborsClassifier(n_neighbors = 8, weights = 'uniform')
# 模型拟合
knn_class.fit(train_image,train_label)
predict1 = knn_class.predict(train_image)
predict2 = knn_class.predict(val_image)
print('模型的训练集准确率为:\n',metrics.accuracy_score(train_label, predict1))
print('模型的验证集准确率为:\n',metrics.accuracy_score(val_label, predict2))
#决策是模型的训练和预测
# 导入第三方模块
from sklearn import metrics
from sklearn import tree
# 构建分类决策树
CART_Class = tree.DecisionTreeClassifier(max_depth=6, min_samples_leaf = 4, min_samples_split=6)
CART_Class.fit(train_image,train_label)
predict1 = CART_Class.predict(train_image)
predict2 = CART_Class.predict(val_image)
print('模型的训练集准确率为:\n',metrics.accuracy_score(train_label, predict1))
print('模型的验证集准确率为:\n',metrics.accuracy_score(val_label, predict2))
#非线性的SVM模型训练和预测
from sklearn import model_selection
from sklearn import svm
# 选择非线性SVM模型,径向基核函数
nolinear_svc = svm.SVC(C=1.0,kernel='rbf')
nolinear_svc.fit(train_image,train_label)
predict1 = nolinear_svc.predict(train_image)
predict2 = nolinear_svc.predict(val_image)
print('模型的训练集准确率为:\n',metrics.accuracy_score(train_label, predict1))
print('模型的验证集准确率为:\n',metrics.accuracy_score(val_label, predict2))
# 选择非线性SVM模型,多项式核函数
nolinear_svc = svm.SVC(C=1.0,kernel='poly',degree=2)
# 模型在训练数据集上的拟合
nolinear_svc.fit(train_image,train_label)
predict1 = nolinear_svc.predict(train_image)
predict2 = nolinear_svc.predict(val_image)
print('模型的训练集准确率为:\n',metrics.accuracy_score(train_label, predict1))
print('模型的验证集准确率为:\n',metrics.accuracy_score(val_label, predict2))
ImageChange.ipynb
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import os
import numpy as np
import struct
from PIL import Image
data_dir = '/Users/apple/'
train_data_dir = os.path.join(data_dir, 'HWDB1.1trn_gnt')
test_data_dir = os.path.join(data_dir, 'HWDB1.1tst_gnt')
def read_from_gnt_dir(gnt_dir=train_data_dir):
def one_file(f):
header_size = 10
while True:
header = np.fromfile(f, dtype='uint8', count=header_size)
if not header.size: break
sample_size = header[0] + (header[1]<<8) + (header[2]<<16) + (header[3]<<24)
tagcode = header[5] + (header[4]<<8)
width = header[6] + (header[7]<<8)
height = header[8] + (header[9]<<8)
if header_size + width*height != sample_size:
break
try:
image = np.fromfile(f, dtype='uint8', count=width*height).reshape((height, width))
except:
print(struct.pack('>H', tagcode).decode('gb2312'))
#print(image, tagcode)
#image = image.reshape()
yield image, tagcode
for file_name in os.listdir(gnt_dir):
if file_name.endswith('.gnt'):
file_path = os.path.join(gnt_dir, file_name)
with open(file_path, 'rb') as f:
for image, tagcode in one_file(f):
yield image, tagcode
char_set = set()
for _, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')
char_set.add(tagcode_unicode)
#save char list
char_list = list(char_set)
char_dict = dict(zip(sorted(char_list), range(len(char_list))))
print("总共有",len(char_dict),"个汉字")
# In[2]:
import pickle
pickle.dump(char_dict, f)
train_counter = 0
test_counter = 0
print('-----开始提取训练数据-----')
for image, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')
im = Image.fromarray(image)
dir_name = './data/train/' + '%0.5d'%char_dict[tagcode_unicode]
if not os.path.exists(dir_name):
os.makedirs(dir_name)
im.convert('RGB').save(dir_name+'/' + str(train_counter) + '.png')
train_counter += 1
print("一共",int(train_counter),"张汉字图片")
print('-----开始提取测试数据-----')
for image, tagcode in read_from_gnt_dir(gnt_dir=test_data_dir):
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312')
im = Image.fromarray(image)
dir_name = './data/test/' + '%0.5d'%char_dict[tagcode_unicode]
if not os.path.exists(dir_name):
os.makedirs(dir_name)
im.convert('RGB').save(dir_name+'/' + str(test_counter) + '.png')
test_counter += 1
print("一共",int(test_counter),"张汉字图片")
# In[3]:
#读取lable,即汉字和对应编码的dict
import pickle
dict = pickle.load(f)
print(dict)
GuiMain.ipynb
#!/usr/bin/env python
# coding: utf-8
# In[1]:
from PyQt5.QtWidgets import QWidget
from PyQt5.Qt import QPixmap, QPainter, QPoint, QPaintEvent, QMouseEvent, QPen, QColor, QSize
from PyQt5.QtCore import Qt
import cv2
import numpy as np
from PyQt5.QtGui import QPixmap,QImage,QColor
from PIL import Image
#画板类
class PaintBoard(QWidget):
def __init__(self, Parent=None):
super().__init__(Parent)
self.__InitData() #先初始化数据,再初始化界面
self.__InitView()
def __InitData(self):
#self.__size = QSize(480,460)
self.__size = QSize(240,240) #画板大小
#新建QPixmap作为画板,尺寸为__size
self.__board = QPixmap(self.__size)
self.__board.fill(Qt.white) #用白色填充画板
self.__IsEmpty = True #默认为空画板
self.EraserMode = False #默认为禁用橡皮擦模式
self.__lastPos = QPoint(0,0)#上一次鼠标位置
self.__currentPos = QPoint(0,0)#当前的鼠标位置
self.__painter = QPainter()#新建绘图工具
self.__thickness = 8 #默认画笔粗细为8px
self.__penColor = QColor("black")#设置默认画笔颜色为黑色
self.__colorList = QColor.colorNames() #获取颜色列表
def __InitView(self):
#设置界面的尺寸为__size
self.setFixedSize(self.__size)
def Clear(self):
#清空画板
self.__board.fill(Qt.white)
self.update()
self.__IsEmpty = True
def ChangePenColor(self, color="black"):
#改变画笔颜色
self.__penColor = QColor(color)
def ChangePenThickness(self, thickness=8):
#改变画笔粗细
self.__thickness = thickness
def IsEmpty(self):
#返回画板是否为空
return self.__IsEmpty
def GetContentAsQImage(self):
#获取画板内容(返回QImage)
image = self.__board.toImage()
return image
def paintEvent(self, paintEvent):
#绘图事件
#绘图时必须使用QPainter的实例,此处为__painter
#绘图在begin()函数与end()函数间进行
#begin(param)的参数要指定绘图设备,即把图画在哪里
#drawPixmap用于绘制QPixmap类型的对象
self.__painter.begin(self)
# 0,0为绘图的左上角起点的坐标,__board即要绘制的图
self.__painter.drawPixmap(0,0,self.__board)
self.__painter.end()
def mousePressEvent(self, mouseEvent):
#鼠标按下时,获取鼠标的当前位置保存为上一次位置
self.__currentPos = mouseEvent.pos()
self.__lastPos = self.__currentPos
def mouseMoveEvent(self, mouseEvent):
#鼠标移动时,更新当前位置,并在上一个位置和当前位置间画线
self.__currentPos = mouseEvent.pos()
self.__painter.begin(self.__board)
if self.EraserMode == False:
#非橡皮擦模式
self.__painter.setPen(QPen(self.__penColor,self.__thickness)) #设置画笔颜色,粗细
else:
#橡皮擦模式下画笔为纯白色,粗细为10
self.__painter.setPen(QPen(Qt.white,15))
#画线
self.__painter.drawLine(self.__lastPos, self.__currentPos)
self.__painter.end()
self.__lastPos = self.__currentPos
self.update() #更新显示
def mouseReleaseEvent(self, mouseEvent):
self.__IsEmpty = False #画板不再为空
# In[2]:
from PyQt5.Qt import QWidget, QColor, QPixmap, QIcon, QSize, QCheckBox
from PyQt5.QtWidgets import QHBoxLayout, QVBoxLayout, QPushButton, QSplitter, QComboBox, QLabel, QSpinBox, QFileDialog
import cv2
import matplotlib.image as mpimg
import tensorflow as tf
import numpy as np
try:
import tensorflow.python.keras as keras
except:
import tensorflow.keras as keras
class MainWidget(QWidget):
def __init__(self, Parent=None):
'''
Constructor
'''
super().__init__(Parent)
self.__InitData() #先初始化数据,再初始化界面
self.__InitView()
def __InitData(self):
'''
初始化成员变量
'''
self.__paintBoard = PaintBoard(self)
#self.__picture = Picture(self)
#获取颜色列表(字符串类型)
self.__colorList = QColor.colorNames()
def __InitView(self):
'''
初始化界面
'''
self.setFixedSize(600,330)
self.setWindowTitle("手写汉字识别")
#新建一个水平布局作为本窗体的主布局
main_layout = QHBoxLayout(self)
#设置主布局内边距以及控件间距为10px
main_layout.setSpacing(10)
#在主界面左侧放置画板
main_layout.addWidget(self.__paintBoard)
#新建垂直子布局用于放置按键
sub_layout = QVBoxLayout()
#设置此子布局和内部控件的间距为5px
sub_layout.setContentsMargins(10, 10, 10, 10)
splitter = QSplitter(self) #占位符
sub_layout.addWidget(splitter)
self.__btn_Recognize = QPushButton("开始识别")
self.__btn_Recognize.setParent(self)
self.__btn_Recognize.clicked.connect(self.on_btn_Recognize_Clicked)
sub_layout.addWidget(self.__btn_Recognize)
self.__btn_Clear = QPushButton("清空画板")
self.__btn_Clear.setParent(self) #设置父对象为本界面
#将按键按下信号与画板清空函数相关联
self.__btn_Clear.clicked.connect(self.__paintBoard.Clear)
sub_layout.addWidget(self.__btn_Clear)
self.__btn_Quit = QPushButton("退出")
self.__btn_Quit.setParent(self) #设置父对象为本界面
self.__btn_Quit.clicked.connect(self.Quit)
sub_layout.addWidget(self.__btn_Quit)
self.__btn_Save = QPushButton("保存")
self.__btn_Save.setParent(self)
self.__btn_Save.clicked.connect(self.on_btn_Save_Clicked)
sub_layout.addWidget(self.__btn_Save)
self.__cbtn_Eraser = QCheckBox("橡皮擦")
self.__cbtn_Eraser.setParent(self)
self.__cbtn_Eraser.clicked.connect(self.on_cbtn_Eraser_clicked)
sub_layout.addWidget(self.__cbtn_Eraser)
self.__label_penThickness = QLabel(self)
self.__label_penThickness.setText("画笔粗细")
self.__label_penThickness.setFixedHeight(20)
sub_layout.addWidget(self.__label_penThickness)
self.__spinBox_penThickness = QSpinBox(self)
self.__spinBox_penThickness.setMaximum(20)
self.__spinBox_penThickness.setMinimum(2)
self.__spinBox_penThickness.setValue(8) #默认粗细为4
self.__spinBox_penThickness.setSingleStep(2) #最小变化值为2
self.__spinBox_penThickness.valueChanged.connect(self.on_PenThicknessChange)#关联spinBox值变化信号和函数on_PenThicknessChange
sub_layout.addWidget(self.__spinBox_penThickness)
self.__label_penColor = QLabel(self)
self.__label_penColor.setText("画笔颜色")
self.__label_penColor.setFixedHeight(20)
sub_layout.addWidget(self.__label_penColor)
self.__comboBox_penColor = QComboBox(self)
self.__fillColorList(self.__comboBox_penColor) #用各种颜色填充下拉列表
self.__comboBox_penColor.currentIndexChanged.connect(self.on_PenColorChange) #关联下拉列表的当前索引变更信号与函数on_PenColorChange
sub_layout.addWidget(self.__comboBox_penColor)
main_layout.addLayout(sub_layout) #将子布局加入主布局
def __fillColorList(self, comboBox):
index_black = 0
index = 0
for color in self.__colorList:
if color == "black":
index_black = index
index += 1
pix = QPixmap(70,20)
pix.fill(QColor(color))
comboBox.addItem(QIcon(pix),None)
comboBox.setIconSize(QSize(70,20))
comboBox.setSizeAdjustPolicy(QComboBox.AdjustToContents)
comboBox.setCurrentIndex(index_black)
#画笔颜色
def on_PenColorChange(self):
color_index = self.__comboBox_penColor.currentIndex()
color_str = self.__colorList[color_index]
self.__paintBoard.ChangePenColor(color_str)
#画笔粗细
def on_PenThicknessChange(self):
penThickness = self.__spinBox_penThickness.value()
self.__paintBoard.ChangePenThickness(penThickness)
#图片储存
def on_btn_Save_Clicked(self):
savePath = QFileDialog.getSaveFileName(self, 'Save Your Paint', '.\\', '*.png')
print(savePath)
if savePath[0] == "":
print("Save cancel")
return
image = self.__paintBoard.GetContentAsQImage()
image.save(savePath[0])
print(savePath[0])
#橡皮擦
def on_cbtn_Eraser_clicked(self):
if self.__cbtn_Eraser.isChecked():
self.__paintBoard.EraserMode = True #进入橡皮擦模式
else:
self.__paintBoard.EraserMode = False #退出橡皮擦模式
#识别预测
def on_btn_Recognize_Clicked(self):
image = self.__paintBoard.GetContentAsQImage()
savePath = "/Users/apple/text.png"
image.save(savePath,"PNG",100)
img = mpimg.imread('/Users/apple/text.png')
img2 = cv2.resize(img, (64, 64))
img3 = np.zeros((1, img2.shape[0], img2.shape[1], img2.shape[2])) # (1, 64, 64, 3)
img3[0, :] = img2
model = tf.keras.models.load_model('/Users/apple/Chinese_recognition_model11.h5')
#pre = model.predict(img3)
pre = model(img3)
predicted_label1 = np.argmax(pre[0])
class_names = ['卧', '典', '俄', '亩', '刺', '举', '卑', '佬', '儒', '五', '勤',
'仆', '吃', '半', '侄', '伯', '冒', '劈', '仗', '司', '亨',
'住', '中', '俏', '协', '厕', '化', '具', '书', '单', '兼',
'凿', '倍', '依', '伏', '剩', '凯', '丸', '变', '亲', '亢',
'刃', '加', '凭', '右', '严', '凌', '冬', '伪', '侦', '佣',
'兰', '乒', '冷', '上', '党', '兆', '副', '侗', '冠', '免',
'充', '剁', '召', '冻', '判', '个', '叁', '允', '俘', '事',
'却', '卓', '井', '削', '凶', '丰', '与', '发', '伤', '使',
'凄', '付', '匀', '压', '则', '仅', '亚', '亏', '低', '今',
'匈', '偶', '业', '偷', '伎', '写', '危', '你', '仕', '券',
'丘', '人', '只', '动', '丢', '卸', '募', '凉', '傈', '九',
'傀', '历', '伙', '于', '侧', '倪', '勉', '利', '众', '卫',
'倒', '台', '份', '兴', '厄', '冕', '介', '卞', '便', '亭',
'健', '册', '佐', '刑', '佩', '俯', '仓', '亥', '交', '三',
'卯', '受', '劣', '之', '傅', '兵', '再', '储', '价', '仑',
'傻', '兜', '也', '净', '倘', '丙', '为', '催', '借', '关',
'吗', '号', '华', '侯', '刨', '且', '似', '保', '促', '主',
'冯', '仔', '乓', '匪', '厂', '刁', '卤', '凰', '即', '叠',
'各', '取', '助', '另', '勾', '印', '又', '专', '伞', '减',
'丝', '二', '去', '全', '僵', '僚', '匣', '决', '侣', '修',
'厉', '佛', '乞', '冗', '下', '亿', '俐', '乖', '串', '冶',
'凳', '刮', '办', '匝', '体', '优', '合', '叶', '僻', '勋',
'佃', '值', '倡', '乾', '凡', '匆', '东', '一', '乡', '列',
'产', '余', '叭', '传', '偏', '兄', '剔', '习', '么', '凑',
'吓', '励', '兹', '丑', '剧', '医', '出', '佑', '偿', '克',
'力', '侠', '名', '军', '古', '冕', '刚', '叔', '万', '冉',
'京', '任', '部', '卵', '义', '劫', '卉', '兑', '劲', '及',
'会', '伍', '企', '乘', '买', '包', '仰', '原', '兽', '区',
'侈', '别', '分', '刊', '丽', '儡', '侥', '八', '别', '佰',
'击', '云', '倔', '卡', '兢', '叙', '丫', '叉', '叛', '刻',
'吕', '后', '向', '什', '丧', '吏', '互', '伐', '争', '丁',
'剪', '升', '剿', '何', '剑', '仟', '厚', '傣', '傍', '反',
'初', '其', '像', '卜', '光', '千', '令', '乏', '久', '厨',
'伴', '停', '丛', '匡', '侵', '农', '休', '可', '俗', '卒',
'丈', '吁', '乱', '仲', '佳', '南', '乐', '临', '划', '仇',
'做', '伊', '双', '厘', '凸', '勇', '乔', '几', '六', '佯',
'势', '丹', '代', '冰', '凛', '伶', '侨', '剂', '位', '匠',
'僧', '两', '倚', '他', '叹', '匿', '创', '切', '僳', '卖',
'乃', '勿', '件', '勃', '删', '伟', '刷', '伸', '卢', '函',
'刽', '卿', '厌', '候', '厦', '匹', '准', '亡', '仁', '仿',
'凹', '刹', '但', '侮', '例', '北', '凋', '世', '参', '勘',
'同', '勒', '俩', '兔', '叫', '伦', '俺', '厢', '乎', '债',
'匙', '叨', '卷', '俭', '割', '侍', '劝', '公', '养', '吐',
'从', '友', '剃', '们', '劳', '口', '凝', '乍', '乳', '供',
'冲', '了', '冀', '伺', '乌', '厩', '内', '刘', '不', '到',
'况', '冈', '吉', '侩', '些', '假', '入', '努', '亦', '享',
'仍', '剥', '信', '倶', '先', '县', '制', '元', '七', '仪',
'亮', '俊', '作', '乙', '倾', '占', '前', '吊', '史', '句',
'功', '俞', '十', '凤', '估', '午', '傲', '勺', '以', '仙',
'共', '博', '予', '倦', '务', '厅', '儿', '叮', '刀']
print("识别结果:",class_names[predicted_label1],"\n可能概率:",1*np.max(pre[0]),"\n")
#关闭
def Quit(self):
self.close()
# In[3]:
#from MainWidget import MainWidget
from PyQt5.QtWidgets import QApplication
import sys
def main():
app = QApplication(sys.argv)
mainWidget = MainWidget() #新建一个主界面
mainWidget.show() #显示主界面
exit(app.exec_()) #进入消息循环
if __name__ == '__main__':
main()

