
- 1十大开源安卓应用程序的开发框架
- 2Qt控件之显示窗口:QLCDNumber液晶数字控件的使用总结_qtlcdnumber
- 3Linux:Ubuntu/Deepin刚装完系统就无法开机:unable to mount root fs on unknown-block(2,0)_ubuntu unable to mount root fs
- 4IEEE 754标准浮点数转换_ieee754单精度浮点数转换器
- 5思科学院cisco独家整理题库(2023.9月更新)_当使用 eui-64 进程生成接口 id 时,启用 ipv6 且 mac 地址为 1c-6f-65-
- 6CPU—GPU并行处理—CUDA编程从想入门到放弃_gpu并行处理的原理
- 7【YOLOv8改进】BiFPN:加权双向特征金字塔网络 (论文笔记+引入代码)
- 8Faster R-CNN改进篇(一): ION ● HyperNet ● MS CNN_faster rcnn 改进后的hypernet 代码
- 9vue打包下来后打开的index.html页面是空白的_vue3 打包后的html 无法打开
- 10鸿蒙开发之JS工程目录结构介绍(HarmonyOS鸿蒙开发基础知识)_鸿蒙系统目录结构
[云原生] Kubernetes(k8s)健康检查详解与实战演示(就绪性探针 和 存活性探针)_kubernetes健康探针
赞
踩
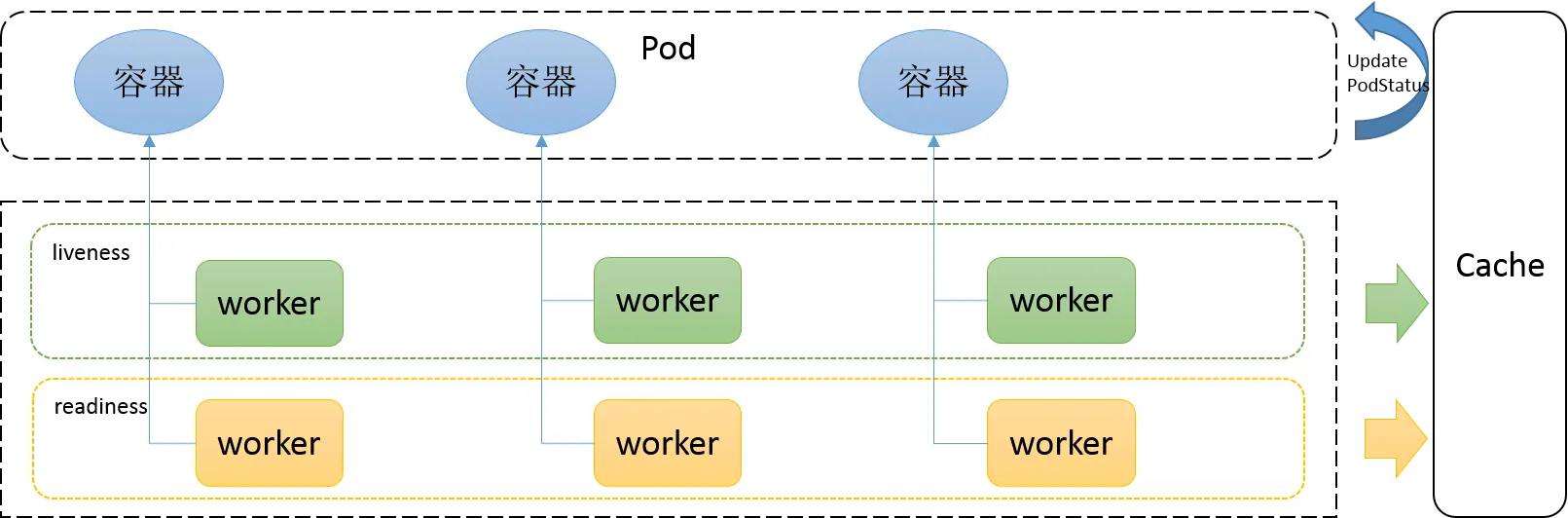
一、概述
Kubernetes中的健康检查主要使用 就绪性探针(
readinessProbes)和 存活性探针(livenessProbes) 来实现,service即为负载均衡,k8s保证 service 后面的 pod 都可用,是k8s中自愈能力的主要手段,主要基于这两种探测机制,可以实现如下需求:
- 异常实例自动剔除,并重启新实例
- 多种类型探针检测,保证异常pod不接入流量
- 不停机部署,更安全的滚动升级
官方文档:https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
Kubernetes(k8s)环境部署可以参考我这篇文章:Kubernetes(k8s)最新版最完整版环境部署+master高可用实现(k8sV1.24.1+dashboard+harbor)
1)k8s中的探针种类
1、就绪检查(readinessProbe,就绪探针)
readiness probes准备就绪检查,通过readiness是否准备接受流量,准备完毕加入到Endpoint,否则剔除。如果容器不提供就绪探针,则默认状态为 Success。
2、存活检查(livenessProbe,存活探针)
liveness probes在线检查机制,检查应用是否可用,如死锁,无法响应,异常时将根据restartPolicy来设置 Pod 状态会自动重启容器,如果容器不提供存活探针,则默认状态为 Success。
restartPolicy有三个可选值:
-
Always:当容器终止退出后,总是重启容器,默认策略。 -
OnFailure:当容器异常退出(退出状态码非0)时,才重启容器。 -
Never:当容器终止退出,从不重启容器。
3、启动检查(startupProbe,启动探针,1.17 版本新增)
startupProbes启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被前面的探针kill掉。- 判断容器内的应用程序是否已启动,主要针对于不能确定具体启动时间的应用。如果匹配了
startupProbes探测,则在startupProbes状态为 Success 之前,其他所有探针都处于无效状态,直到它成功后其他探针才起作用。 - 如果
startupProbe失败,kubelet 将杀死容器,容器将根据restartPolicy来重启。如果容器没有配置startupProbe,则默认状态为 Success。其实一般主要是设置上面两种即可。
就绪、存活两种探针的区别:
readinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同。
- livenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
- readinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的
EndPoint列表中删除。
2)k8s中的三种探测方式
每种探测机制支持三种健康检查方法,分别是命令行exec,httpGet和tcpSocket,其中exec通用性最强,适用与大部分场景,tcpSocket适用于TCP业务,httpGet适用于web业务。
exec(自定义健康检查):在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。httpGet:通过容器的IP地址、端口号及路径调用 HTTP Get方法,如果响应的状态码大于等于200且小于400,则认为容器 健康。tcpSocket:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
探针探测结果有以下值:
Success:表示通过检测。Failure:表示未通过检测。Unknown:表示检测没有正常进行。
二、readinessProbe(就绪性探针)
- readiness probe 就绪性探针,用于判断容器内的程序是否存活(或者说是否健康),只有程序(服务)正常, 容器开始对外提供网络访问(启动完成并就绪);
- 容器启动后按照
readiness probe配置进行探测,无问题后结果为成功即状态为Success; - pod的
READY状态为 true,从0/1变为1/1。如果失败继续为0/1,状态为 false; - 若未配置就绪探针,则默认状态容器启动后为
Success。对于此pod、此pod关联的Service资源、EndPoint的关系也将基于 Pod 的Ready状态进行设置; - 如果 Pod 运行过程中 Ready 状态变为 false,则系统自动从
Service资源 关联的EndPoint列表中去除此pod,届时service资源接收到GET请求后,kube-proxy将一定不会把流量引入此pod中,通过这种机制就能防止将流量转发到不可用的 Pod 上。 - 如果 Pod 恢复为 Ready 状态。将再会被加回
Endpoint列表。kube-proxy也将有概率通过负载机制会引入流量到此pod中。
三、livenessProbe(存活性探针)
- liveness probe存活性探针,用于判断容器是不是健康,如果不满足健康条件,那么 Kubelet 将根据 Pod 中设置的
restartPolicy(重启策略)来判断,Pod 是否要进行重启操作; - LivenessProbe按照配置去探测 ( 进程、或者端口、或者命令执行后是否成功等等),来判断容器是不是正常;
- 如果探测不到,代表容器不健康(可以配置连续多少次失败才记为不健康),则 kubelet 会杀掉该容器,并根据容器的重启策略做相应的处理;
- 如果未配置存活探针,则默认容器启动为通过(Success)状态。即探针返回的值永远是
Success。即Success后pod状态是RUNING。
四、实战演示
常用的探针可选参数:
| 参数名称 | 默认值 | 最小值 | 描述 |
|---|---|---|---|
| initialDelaySeconds | 0秒 | 0秒 | 探测延迟时长,容器启动后多久开始进行第一次探测工作。 |
| periodSeconds | 10秒 | 1秒 | 探测频度,频率过高会对pod带来较大的额外开销,频率过低则无法及时反映容器产生的错误。 |
| timeoutSeconds | 1秒 | 1秒 | 探测的超时时长。 |
| failureThreshold | 3 | 1 | 处于成功状态时,探测连续失败几次可被认为失败。 |
| successThreshold | 1 | 1 | 处于失败状态时,探测连续成功几次,被认为成功。 |
1)exec方式
cat >exec-liveness.yaml<<EOF
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
# 为了测试方便,指定调度机器
nodeName: local-168-182-110
containers:
- name: liveness
image: registry.aliyuncs.com/google_containers/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
EOF
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
解释:
-
initialDelaySeconds字段告诉 kubelet 在执行第一次探测前应该等待 5 秒。 -
periodSeconds字段指定了 kubelet 应该每 5 秒执行一次存活探测。 -
kubelet 在容器内执行命令 cat /tmp/healthy 来进行探测。
-
如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。
-
如果这个命令返回非 0 值,kubelet 会杀死这个容器并重新启动它。
-
当容器启动时,执行如下的命令:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600"
- 1
- 这个容器生命的前 30 秒,/tmp/healthy 文件是存在的。 所以在这最开始的 30 秒内,执行命令 cat /tmp/healthy 会返回成功代码。 30 秒之后,执行命令 cat /tmp/healthy 就会返回失败代码。
创建 Pod:
# 最好先拉取镜像,如果是使用docker,就换成docker就行
crictl pull registry.aliyuncs.com/google_containers/busybox
kubectl apply -f exec-liveness.yaml
- 1
- 2
- 3
- 4
【问题】ERRO[0000] unable to determine image API version: rpc error: code = Unavailable desc = connection error: desc = “transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory”
【解决】原因:未配置endpoints
crictl config runtime-endpoint unix:///run/containerd/containerd.sock
crictl config image-endpoint unix:///run/containerd/containerd.sock
- 1
- 2
查看
kubectl describe pod liveness-exec
- 1
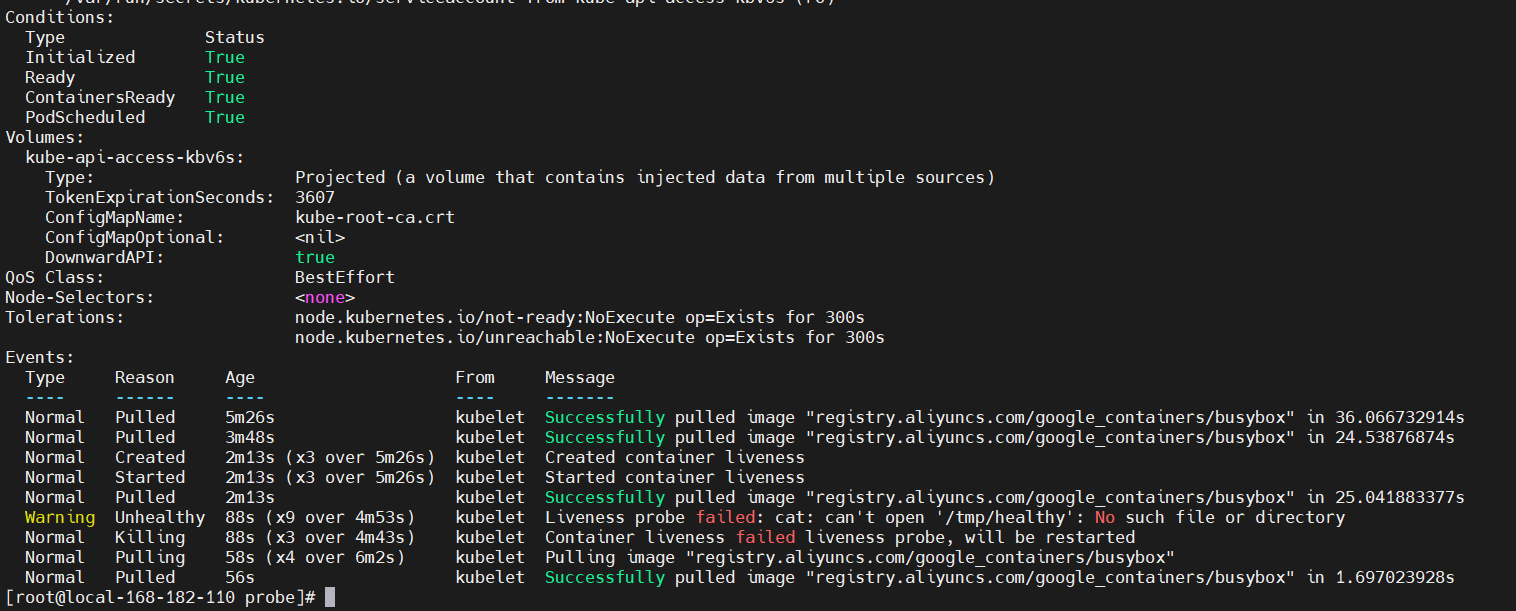
【现象】30s之后检查失败后就重启pod了,又正常了。
2)httpGet 方式
cat >http-liveness.yaml<<EOF
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget
namespace: default
spec:
# 为了测试方便,指定调度机器
nodeName: local-168-182-110
containers:
- name: liveness-httpget-container
image: nginx
imagePullPolicy: IfNotPresent
ports:
- name: nginx
containerPort: 80
livenessProbe:
httpGet:
port: nginx
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
EOF
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
解释:
initialDelaySeconds字段告诉 kubelet 在执行第一次探测前应该等待 1 秒。periodSeconds字段指定了 kubelet 每隔 3 秒执行一次存活探测。- kubelet 会向容器内运行的服务(服务在监听 80 端口)发送一个 HTTP GET 请求来执行探测。
- 如果服务器上
/index.html路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。 - 如果处理程序返回失败代码,则 kubelet 会杀死这个容器并将其重启。
- 返回大于或等于
200并且小于400的任何代码都标示成功,其它返回代码都标示失败。
执行并查看
crictl pull nginx
kubectl apply -f http-liveness.yaml
kubectl describe pod liveness-httpget
- 1
- 2
- 3
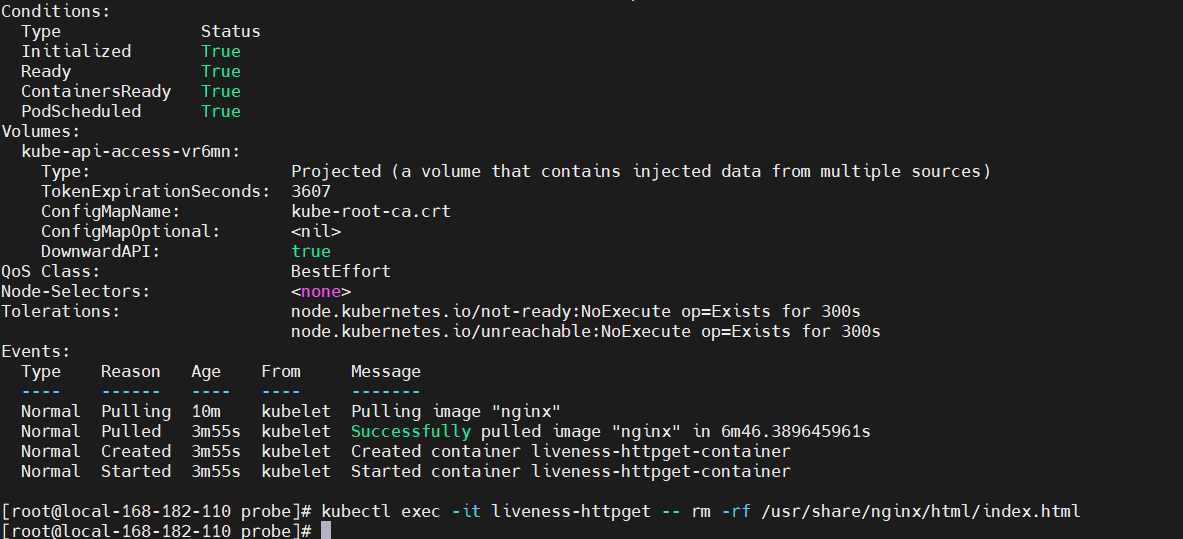
删除 Pod 的 index.html 文件
kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html
# 再查看
kubectl describe pod liveness-httpget
kubectl get pod liveness-httpget
- 1
- 2
- 3
- 4
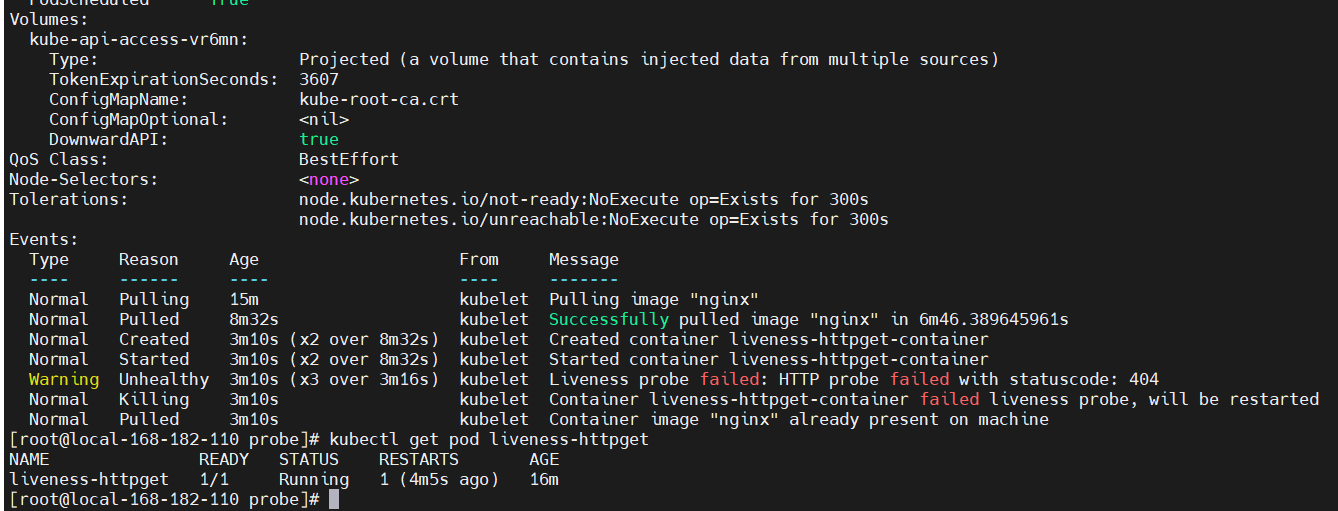
- 重启原因是 HTTP 探测得到的状态返回码是 404,
Liveness probe failed: HTTP probe failed with statuscode: 404。 - 重启完成后,不会再次重启,因为重新拉取的镜像中包含了 index.html 文件。
HTTP Probes 允许针对 httpGet 配置额外的字段:
host:连接使用的主机名,默认是 Pod 的 IP。也可以在 HTTP 头中设置 “Host” 来代替。scheme:用于设置连接主机的方式(HTTP 还是 HTTPS)。默认是 “HTTP”。path:访问 HTTP 服务的路径。默认值为 “/”。httpHeaders:请求中自定义的 HTTP 头。HTTP 头字段允许重复。port:访问容器的端口号或者端口名。如果数字必须在 1~65535 之间。
你可以通过为探测设置 .httpHeaders 来重载默认的头部字段值;例如:
livenessProbe:
httpGet:
httpHeaders:
- name: Accept
value: application/json
startupProbe:
httpGet:
httpHeaders:
- name: User-Agent
value: MyUserAgent
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3)tcpSocket 方式
cat >tcp-liveness-readiness.yaml<<EOF
apiVersion: v1
kind: Pod
metadata:
name: liveness-readiness-tcpsocket
labels:
app: liveness-readiness-tcpsocket
spec:
# 为了测试方便,指定调度机器
nodeName: local-168-182-110
containers:
- name: liveness-readiness-tcpsocket
image: nginx
ports:
- containerPort: 80
readinessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 80
initialDelaySeconds: 15
periodSeconds: 20
EOF
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
解释:
- kubelet 会在容器启动 5 秒后发送第一个就绪探测(livenessProbe)。
- 探测器会尝试连接 goproxy 容器的 80 端口。 如果探测成功,这个 Pod 会被标记为就绪状态,kubelet 将继续每隔 10 秒运行一次检测。
- 除了就绪探测,这个配置包括了一个存活探测(livenessProbe)。
- kubelet 会在容器启动 15 秒后进行第一次存活探测(livenessProbe)。
- 与就绪探测类似,活跃探测器会尝试连接 goproxy 容器的 80 端口。 如果存活探测失败,容器会被重新启动。
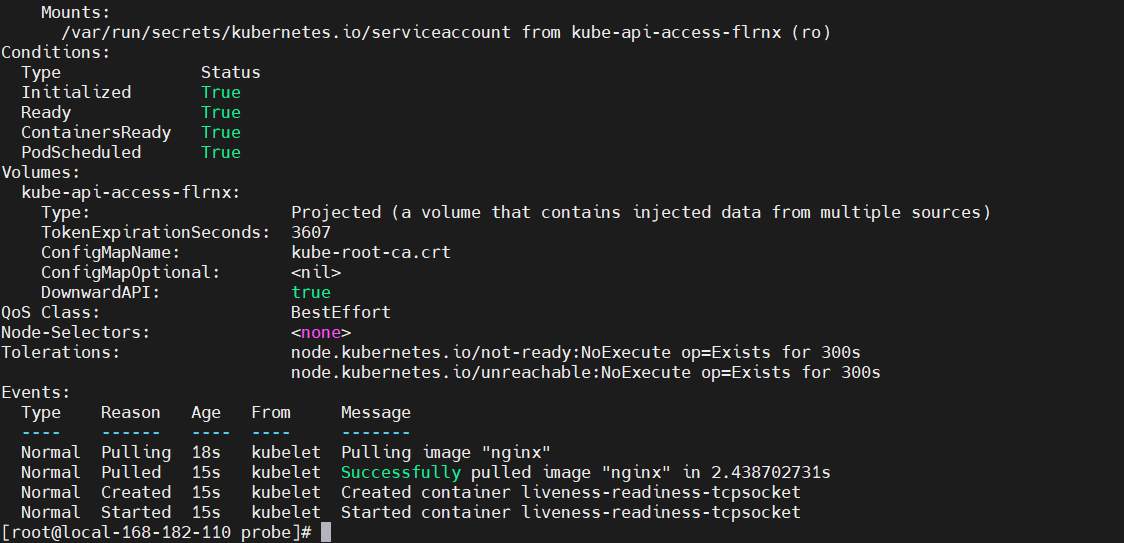
执行
kubectl apply -f tcp-liveness-readiness.yaml
kubectl get pod liveness-readiness-tcpsocket
kubectl describe pod liveness-readiness-tcpsocket
- 1
- 2
- 3
4)使用命名端口
对于 HTTP 或者 TCP 存活检测可以使用命名的 port。
ports:
- name: nginx
containerPort: 80
hostPort: 80
livenessProbe:
httpGet:
path: /index.html
port: nginx
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
完整版配置
ports:
- name: nginx
containerPort: 80
hostPort: 80
# readinessProbe,就绪探针
livenessProbe:
httpGet:
path: /index.html
port: nginx
# 延迟多久后开始探测
initialDelaySeconds: 10
# 执行探测频率(秒) 【 每隔秒执行一次 】
periodSeconds: 10
# 超时时间
timeoutSeconds: 1
# 处于成功状态时,探测连续失败几次可被认为失败。
failureThreshold: 3
# 处于失败状态时,探测连续成功几次,被认为成功。
successThreshold: 1
# livenessProbe,存活探针
livenessProbe:
httpGet:
path: /index.html
port: nginx
# 延迟多久后开始探测
initialDelaySeconds: 10
# 执行探测频率(秒) 【 每隔秒执行一次 】
periodSeconds: 10
# 超时时间
timeoutSeconds: 1
# 处于成功状态时,探测连续失败几次可被认为失败。
failureThreshold: 3
# 处于失败状态时,探测连续成功几次,被认为成功。
successThreshold: 1
# startupProbe,启动探针
startupProbe:
httpGet:
path: /index.html
port: nginx
# 延迟多久后开始探测
initialDelaySeconds: 10
# 执行探测频率(秒) 【 每隔秒执行一次 】
periodSeconds: 10
# 超时时间
timeoutSeconds: 1
# 处于成功状态时,探测连续失败几次可被认为失败。
failureThreshold: 3
# 处于失败状态时,探测连续成功几次,被认为成功。
successThreshold: 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
一般使用控制器去创建管理pod,对k8s 控制器不清晰的小伙伴,可以参考我之前的文章:Kubernetes(k8s)Deployment、StatefulSet、DaemonSet、Job、CronJob五种控制器详解
下面是一个完整版的示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-probe
spec:
replicas: 3
selector:
matchLabels:
app: deployment-probe
template:
metadata:
labels:
app: deployment-probe
spec:
containers:
- name: nginx
image: nginx:1.17.1
# readinessProbe,就绪探针
readinessProbe:
httpGet:
path: /index.html
port: nginx
# 延迟多久后开始探测
initialDelaySeconds: 10
# 执行探测频率(秒) 【 每隔秒执行一次 】
periodSeconds: 10
# 超时时间
timeoutSeconds: 1
# 处于成功状态时,探测连续失败几次可被认为失败。
failureThreshold: 3
# 处于失败状态时,探测连续成功几次,被认为成功。
successThreshold: 1
# livenessProbe,存活探针
livenessProbe:
httpGet:
path: /index.html
port: nginx
# 延迟多久后开始探测
initialDelaySeconds: 10
# 执行探测频率(秒) 【 每隔秒执行一次 】
periodSeconds: 10
# 超时时间
timeoutSeconds: 1
# 处于成功状态时,探测连续失败几次可被认为失败。
failureThreshold: 3
# 处于失败状态时,探测连续成功几次,被认为成功。
successThreshold: 1
# startupProbe,启动探针
startupProbe:
httpGet:
path: /index.html
port: nginx
# 延迟多久后开始探测
initialDelaySeconds: 10
# 执行探测频率(秒) 【 每隔秒执行一次 】
periodSeconds: 10
# 超时时间
timeoutSeconds: 1
# 处于成功状态时,探测连续失败几次可被认为失败。
failureThreshold: 3
# 处于失败状态时,探测连续成功几次,被认为成功。
successThreshold: 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
执行查看
crictl pull nginx:1.17.1
kubectl apply -f deployment-probe.yaml
kubectl get pod,deploy
- 1
- 2
- 3
Kubernetes(k8s)健康检查详解与实战演示就先到这里了,健康检查会伴随所有k8s编排任务,所以非常重要,其实也不难,小伙伴有什么疑问,欢迎给我留言哦~


