
热门标签
热门文章
- 1非常适合自学人工智能大模型的10个公众号号
- 2CNNS:基于AlexNet的分类任务_alexnet实现八分类任务
- 3全国职业院校技能大赛 网络建设与运维 赛题(九)_网络建设与运维 技能大赛题库
- 4神器Ai工具箱全集,不用找了你想要的Ai都在这里。_work.rightbrain.art
- 5时间序列预测实战(十七)PyTorch实现LSTM-GRU模型长期预测并可视化结果(附代码+数据集+详细讲解)_长时间序列预测
- 6一文打尽UCI统一配置接口、UCI配置文件、UCI工具用法、UCI配置脚本、UCI API编程接口(Libubox库、UCI库)_uci add_list
- 7PCL点云处理算法汇总(C++长期更新版)_点云半径滤波器c++
- 8图像修复系列资料_图像修复与图像恢复image inpainting 和 image restoration
- 9前端Vue select 下拉框详解以及监听事件_vue给下拉框加监听
- 10【uni-app小程序开发】实现一个背景色渐变的滑动条slider_uniapp渐变背景
当前位置: article > 正文
ChatGLM系列四:P-Tuning微调_chatglm.cpp p-tuning
作者:小丑西瓜9 | 2024-03-18 04:32:14
赞
踩
chatglm.cpp p-tuning
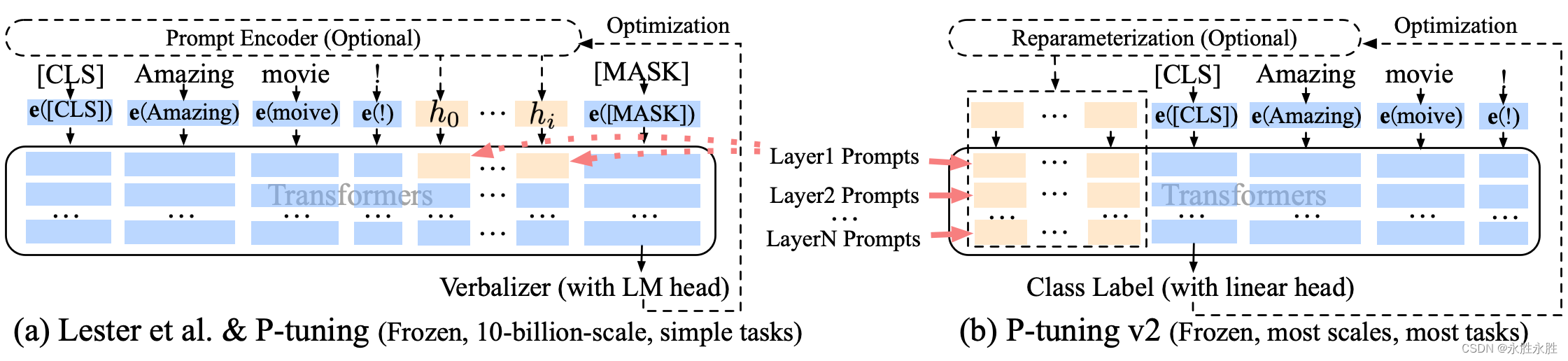
P-Tuning,参考ChatGLM官方代码 ,是一种针对于大模型的soft-prompt方法
P-Tuning: 在输入的embedding层前,将prompt转换为可学习的额外一层embedding层.
P-Tuning,仅对大模型的Embedding加入新的参数。
P-Tuning-V2,将大模型的Embedding和每一层前都加上新的参数。
当prefix_projection为True时,为P-Tuning-V2方法,在大模型的Embedding和每一层前都加上新的参数;为False时,为P-Tuning方法,仅在大模型的Embedding上新的参数。
下载代码
git clone https://github.com/liucongg/ChatGLM-Finetuning
- 1
环境配置
cpm_kernels==1.0.11
deepspeed==0.9.0
numpy==1.24.2
peft==0.3.0
sentencepiece==0.1.96
tensorboard==2.11.0
tensorflow==2.13.0
torch==1.13.1+cu116
tqdm==4.64.1
transformers==4.27.1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
(1)、ChatGLM单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 768 \
--max_src_len 512 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(2)、ChatGLM四卡训练
通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(3)、ChatGLM2单卡训练
CUDA_VISIBLE_DEVICES=0 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
(4)、ChatGLM2四卡训练
通过CUDA_VISIBLE_DEVICES控制具体哪几块卡进行训练,如果不加该参数,表示使用运行机器上所有卡进行训练
CUDA_VISIBLE_DEVICES=0,1,2,3 deepspeed --master_port 520 train.py \
--train_path data/spo_0.json \
--model_name_or_path ChatGLM2-6B \
--per_device_train_batch_size 1 \
--max_len 1560 \
--max_src_len 1024 \
--learning_rate 1e-4 \
--weight_decay 0.1 \
--num_train_epochs 2 \
--gradient_accumulation_steps 4 \
--warmup_ratio 0.1 \
--mode glm2 \
--train_type ptuning \
--seed 1234 \
--ds_file ds_zero2_no_offload.json \
--gradient_checkpointing \
--show_loss_step 10 \
--pre_seq_len 16 \
--prefix_projection True \
--output_dir ./output-glm2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
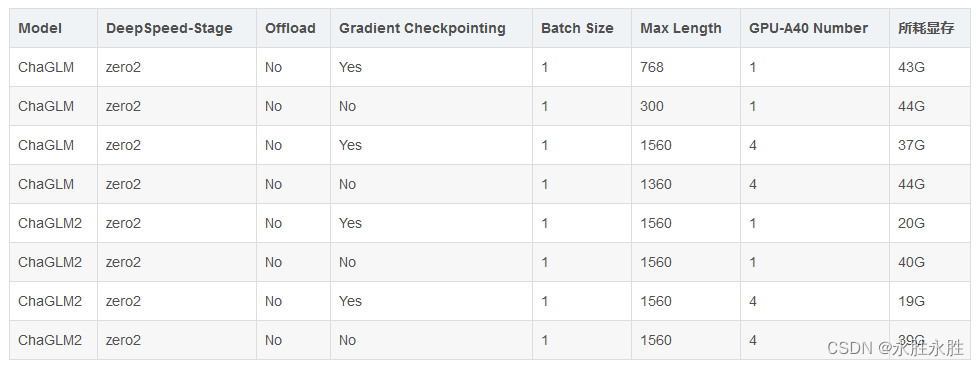
(5)、耗费显存资源占用对比—PT方法:对比ChaGLM和ChaGLM2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/260367
推荐阅读
相关标签

