
- 1密集型目标检测网络_目标检测网络之 R-FCN
- 2『Android基础入门』APP打包发布_客户端打包到发布
- 316.图像配准_图像配准算法dssd
- 4mac kali linux u盘安装,怎么在macbook下安装Kali Linux
- 5Spring Security(九)-- 理解HTTP Basic 和基于表单的登陆身份验证_org.springframework.security.authentication.insuff
- 6mysql主从复制
- 7linux端口支持多大,Linux系统支持的最大TCP连接是多少?
- 8S905L3A(M401A)拆解, 运行EmuELEC和Armbian
- 9kubesphere证书过期解决方案
- 10使Xceed.Wpf.Toolkit支持Active X
大语言模型之三 ChatGPT训练过程
赞
踩
大语言模型 GPT历史文章中简介的大语言模型的的发展史,并且简要介绍了大语言模型的训练过程,本篇文章详细阐述训练的细节和相关的算法。
2020年后全球互联网大厂、AI创业公司研发了不少AI超大模型(百亿甚至千亿参数),典型代表是NLP领域的GPT-3,LlaMA,视觉领域的DALL*E2,Stable Diffusion以及V-MoE。现有的生成式AI工具大部分基于大厂研发的预训练模型,用针对特定场景的小数据进行Fine-Tune的模式快速迭代。
DALL-E2:DALL-E2是OpenAI在2021年提出的一种图像生成模型,它基于GPT-3的预训练模型,并使用自注意力机制来处理输入图像。DALL-E2可以生成高质量的图像,并且可以根据文本描述来生成图像。
Stable Diffusion:Stable Diffusion是Facebook AI Research在2021年提出的一种图像生成模型,它基于扩散过程和随机微分方程,并使用自注意力机制来处理输入图像。Stable Diffusion可以生成高质量的图像,并且可以进行无监督学习和控制生成图像的样式。
ChatGPT的训练过程分为如下四个步骤:
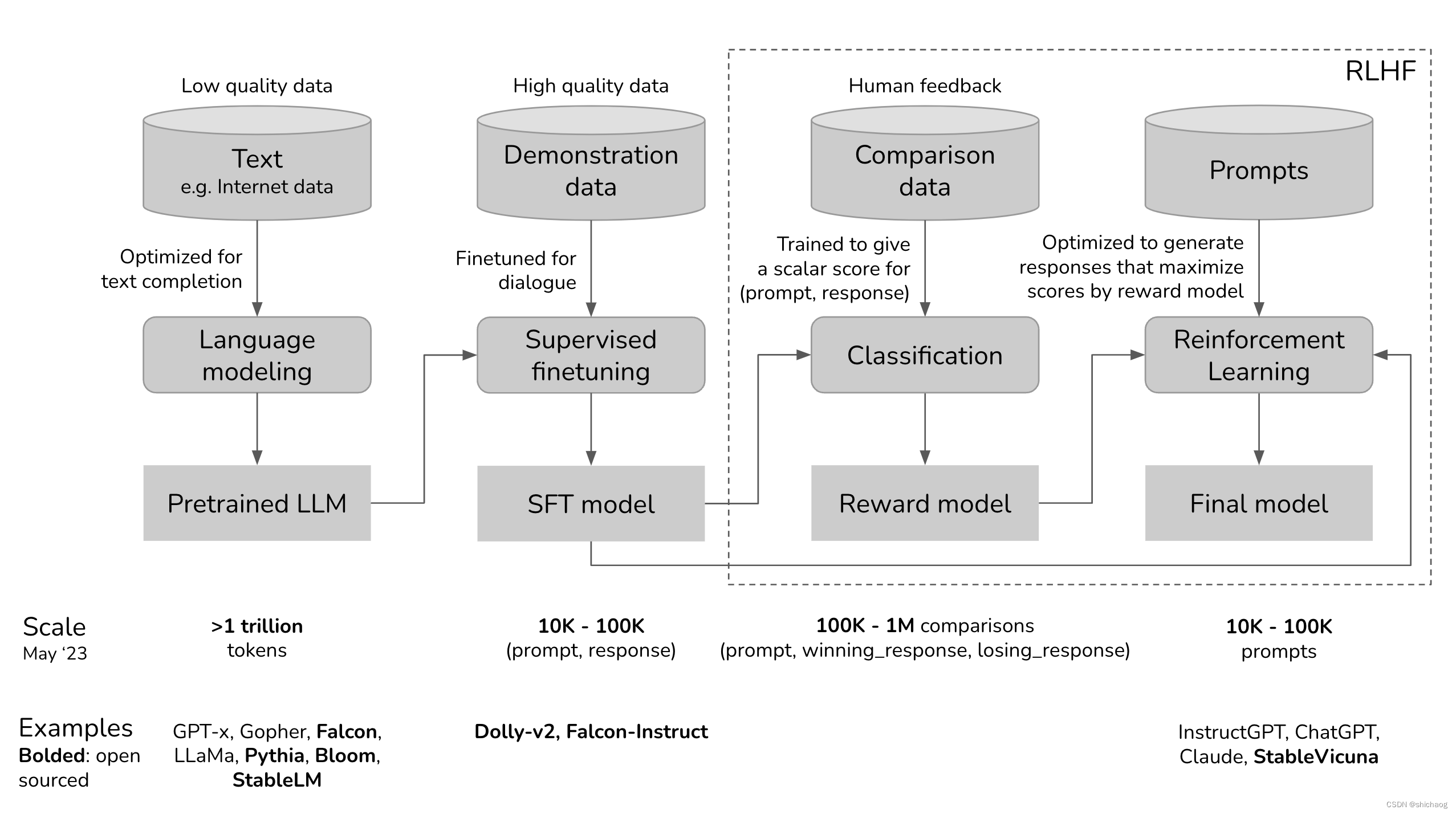
1.预训练(pretrain)模型是基于海量未人工标注的自监督学习模型,因为从互联网上爬虫的数据并没有经过清洗,因而网络上一些虚假信息、阴谋论、偏见以及常识错误都会被模型训练得到,因而通常称这一阶段的模型为预训练模型;
2.然后用更高质量的数据上微调预训练模型,这些高质量的数据,诸如StackOverflow、Quora、Wikipedia、百度百科以及人类标注等,这使得模型尽量少的输出有害、无用的等内容。
3.然后使用RLHF对模型进一步调节,使其更加符合特定的应用需要。
在上面模型训练的三个步骤中,第一步的预训练(Pretraining)模型占用了绝大多数的算力和数据,根据OpenAI官网数据,InstructGPT在预训练模型阶段占用了98%(https://openai.com/research/instruction-following)的算力和数据。可以将SFT和RLHF视为解锁预训练模型已经具有但用户很难仅通过提示访问的功能。所以第二步的SFT和第三步的RLHF本质上并没有赋予模型新的能力,而是将不好的能力封印起来,把好的、需要的能力解锁出来。
第一阶段 预训练
预训练模型的产物是大语言模型,比如GPT-x (OpenAI), Gopher (DeepMind), LLaMa (Meta)。
语言模型编码了语音的信息,在一个特定的上下文中,不同字/词出现的概率是不一样的,语言模型的任务是预测下一个词。可以把语音模型看成是填词任务,给定提示(Prompt),补充下文。
Prompt (用户输入):今天天气真好,我打算出去逛街,
补充 (语言模型): 去买买衣服和包包。
- 1
- 2
这看起来是一件很简单的事情,但确实非常强大的功能,其可以完成翻译、总结、写代码、做算术题、写文案等等,比如给定Prompt:How are you in Chinese is …,语言模型的补全会输出 你好吗,这就是实现了翻译功能。
预训练的数学化的表示
训练数据:未标注低质量数据
数据规模:在写这篇文章时,大语言模型使用的训练数据的token在万亿数量级,按照现在大模型预训练数据集的增速,几年之后网上公开的数据大概率可以被头部企业爬完。到那时数据维度的优势将是私有数据带来的。
- GPT-3(OpenAI)数据集token规模,使用的是0.5万亿,GPT-4未公开
- LlaMA-1(Meta)数据集的token规模在1.4亿,LlaMA-2使用了2万亿token预训练。
公式描述:
- L L M ϕ LLM_{\phi} LLMϕ:待训练大语言模型,其中 ϕ \phi ϕ是参数,训练的目标是得到交叉熵损失最小的参数集 ϕ \phi ϕ;
- [ T 1 , T 2 , … , T V ] [T_1, T_2, …, T_V] [T1,T2,…,TV]:词汇表,训练集中token的总数,GPT-2(OpenAI)的词汇表是50257。LlaMA-1和LlaMA-2的词汇表数量都是32000。
- V V V:是词汇表的大小。对于LlaMA-1/LlaMA-2都是32000。
- f ( x ) f(x) f(x):将token映射到其在词汇中的位置,如果token x x x在词汇表的位置为 T k T_k Tk, 则 f ( x ) = k f(x)=k f(x)=k.
- 对于长度为n的句子
(
x
1
,
x
2
,
…
,
x
n
)
(x_1, x_2, …, x_n)
(x1,x2,…,xn),按照token拆分成训练模型需要的序列,这会得到n个训练样本。
- 输入x= ( x 1 , x 2 , … , x i − 1 ) (x_1, x_2, …, x_{i-1}) (x1,x2,…,xi−1)
- 预测的词为 x i x_i xi
- 对于每个训练样本
(
x
,
x
i
)
(x,x_i)
(x,xi):
- 令 k = f ( x i ) k=f(x_i) k=f(xi)
- 模型输出: L L M ( x ) = [ y 1 , y 2 , … , y v ] LLM(x) = [y_1, y_2, …, y_v] LLM(x)=[y1,y2,…,yv], ∑ j y j = 1 \sum_j y_j=1 ∑jyj=1
- loss为: C E ( x , x i ; ϕ ) = − l o g y k CE(x,x_i;\phi) = -logy_k CE(x,xi;ϕ)=−logyk
- 目标函数:找到参数集 ϕ \phi ϕ使得所有训练样本的loss最小: C E ( ϕ ) = − E x log y k CE(\phi)=-E_x\log{y_k} CE(ϕ)=−Exlogyk
阶段二:监督预训练Supervised finetuning (SFT)
为什么需要SFT?
因为预训练模型的任务是预测下一个词,所以如果给预训练模型输入:如何制作椒盐明虾
那么预训练模型可能会输出:
1.?需要什么作料、制作的步骤是怎样的?
2.不油腻,酥脆好吃?
3.详细的配料和制作步骤
实际上第三个详细制作的步骤是我们需要的,SFT的目的是为了提高期望输出的概率。
如何才能提高期望场景(如知识问答、总结摘要、翻译等)获得更好输出的概率呢?因为模型是模仿数据集的,所以在预训练模型的基础上,提供一批特定类型样例让模型再模仿,这就是SFT阶段干的事,SFT阶段的示例是通过(prompt, response)方式给出的,OpenAI称之为调用监督微调行为克隆,InstructGPT的示例SFT示例数据集分布情况如下:

其左边一列显示了不同case的占比情况,右边给出了三种情况的prompt例子。
示例数据集
示例数据集可以由人提供(如OpenAI的InstructGPT和ChatGPT做法),和传统的数据标注不一样,示例提供者由通过测试的具有高学历背景的知识分子组成,InstructGPT prompt中90%人有大学学位,三分之一有硕士学位。其详细人员受教育程度如下:

OpenAI雇佣的40位prompt工程师为InstructGPT创建了1万3千条 (prompt, response) 示例,其中一个例子如下:
| Prompt | Response |
|---|---|
| Serendipity means the occurrence and development of events by chance in a happy or beneficial way. Use the word in a sentence. | Running into Margaret and being introduced to Tom was a fortunate stroke of serendipity. |
| ELI5: What’s the cause of the “anxiety lump” in our chest during stressful or disheartening experiences? | The anxiety lump in your throat is caused by muscular tension keeping your glottis dilated to maximize airflow. The clenched chest or heartache feeling is caused by the vagus nerve which tells the organs to pump blood faster, stop digesting, and produce adrenaline and cortisol. |
| Create a shopping list from this recipe:Trim the ends off zucchini. Cut zucchini in half lengthwise; scoop out pulp, leaving 1/2-in. shells. Finely chop pulp. In a skillet, cook beef, zucchini pulp, onion, mushrooms and peppers over medium heat until meat is no longer pink; drain. Remove from the heat. Add 1/2 cup cheese, ketchup, salt and pepper; mix well. Spoon into the zucchini shells. Place in a greased 13x9-in. baking dish. Sprinkle with remaining cheese. | Zucchini, beef, onion, mushroom, peppers, cheese, ketchup, salt, pepper |
OpenAI的方法示例数据集质量很高,但是成本和时间代价也很大。因而也有从互联网上通过启发式过滤对话的方式获得示例。Gopher(DeepMind)就是采用这一方法。
LlaMA-2使用了27,540 条(prompt, response) 示例,这是Meta从第三方数据集百万级的标注中筛选出来的高质量(prompt, response) 示例。
SFT的数学化的表示
- 数据集:(prompt, response)标注的高质量的数据集。
- 数据规模:1万~10万条(prompt, response) 示例
- InstructGPT:~14万5千,其中13000来自prompt工程师,1500来自用户
- LLaMA-2 27540条
- 模型输入和输出:
- 输入:prompt
- 输出:对应的response
- 训练的loss函数采用交叉熵准则。
阶段三:RLHF
从经验上讲,RLHF与单独的SFT相比显着提高了性能。Anrowpic对此的解释是:“当人们具有易于引出但难以形式化和自动化的复杂直觉时,我们预计人类反馈(HF)比其他技术具有最大的比较优势。”(Bai et al., 2022)

对话是灵活的。给定一个提示,有许多合理的反应,有些比其他的好。演示数据告诉模型对于给定的上下文,哪些反应是合理的,但没有告诉模型反应有多好或多坏。
这个想法是:如果我们有一个评分函数,如果给出一个提示和一个响应,输出一个响应有多好的分数会怎么样?然后我们使用这个评分函数来进一步训练我们的LLM给出高分的回答。这正是RLHF所做的。RLHF由两部分组成:
1.训练奖励模型作为评分函数。
2.优化LLM以生成奖励模型将给出高分的响应。
RM模型
RM模型的任务是给(prompt, response)打分,训练模型以在给定输入上输出分数是ML中非常常见的任务。可以简单地将其构建为分类或回归任务。训练奖励模型的挑战在于获得可信赖的数据。让不同人对相同的回答给出一致的分数是相当困难的。让人比较两个回答并决定哪个更好要容易得多。
因而打标签的过程就是输出(prompt, winning_response, losing_response)对的过程,这被称为数据比较。接下来的问题是只有这些比较数据对,如何训练模型给出具体的分数?
对于InstructGPT,目标是最大(prompt, winning_response)和(prompt, losing_response)之间的分数差异(详见数学公式部分),从这个思想可以看出来在鼓励winning_response回答同时也压制了奖励模型的losing_response类应答。
RM模型可以使用不同的方式初始化,但从SFT模型作为种子似乎可以获得最好的效果,直觉上是,RM至少应该与LLM一样强大,以便能够很好地对LLM的响应进行评分。
RM的数学化的表示
- 数据集:高质量的(prompt, winning_response, losing_response)
- 数据规模:10万~100万条样本,
- InstructGPT有5万条prompt,每个prompt有49个应答,可以组成636对(winning_response, losing_response)。这意味着其数据规模是30万~180万条示例。
- LlaMA-chat-2除了使用第三方数据,还使用了自建的,和InstructGPT不同的是reponse除了人写,还可以由不同的模型生成。

LlaMA-2 RM训练数据集分布
公式表示:
- r θ r_{\theta} rθ:待训练的RM,参数集用 θ \theta θ表示,训练过程的目标是找到参数集 θ \theta θ使得loss在RM数据集上整体最小;
- 训练数据组织格式:
- x \mathbf{x} x:输入
- y w \mathbf y_w yw:相对较好的模型输出,w 表示 wining response
- y l \mathbf y_l yl:相对较差的模型输出,l表示lossing response
- 对每一个训练样本
(
x
,
y
w
,
y
l
)
(\mathbf x, \mathbf y_w, \mathbf y_l)
(x,yw,yl):
- S w = r θ ( x , y w ) \mathbf S_w=r_{\theta}(\mathbf x, \mathbf y_w) Sw=rθ(x,yw):RM模型的wining response得分
- S l = r θ ( x , y l ) \mathbf S_l=r_{\theta}(\mathbf x,\mathbf y_l) Sl=rθ(x,yl):RM模型的lossing response得分
- loss值是: − log ( σ ( S w − S l ) ) -\log(\sigma(S_w -S_l)) −log(σ(Sw−Sl))
- 目标函数:找到对所有训练样本loss最小的参数集 θ {\theta} θ,即 − E x log ( σ ( s w − s l ) ) -E_x \log(\sigma(s_w-s_l)) −Exlog(σ(sw−sl))最小
可以进步一看看这个loss函数是如何工作的,令
d
=
s
w
−
s
l
d=s_w-s_l
d=sw−sl,
f
(
d
)
=
−
log
(
σ
(
d
)
)
f(d)=-\log(\sigma(d))
f(d)=−log(σ(d))的图如下,对于负的d,loss值将大,这个函数将会使得RM模型为winning response打更高的分数。

使用RM奖励模型微调
在这个阶段,我们将进一步训练SFT模型以生成输出响应,从而最大限度地提高RM的分数。如今,大多数人使用OpenAI在2017年发布的强化学习算法——接近策略优化(Proximal Policy Optimization (PPO))。
微调是基于SFT模型进行的,InstructGPT论文中给出的步骤如下:

在此过程中,提示是从分布中随机选择的——例如,OpenAI可能会在用户提示中随机选择。这些提示中的每一个都被输入到LLM模型中以获得响应,RM会给响应打分。
训练的过程如下,下图中的Initial Language Model就是SFT模型,而Tuned Language Model则是(RL 策略)模型,相关的loss和梯度迭代如下图中所示:

OpenAI还发现有必要添加一个约束:这个阶段产生的模型不应该偏离SFT阶段(数学上表示为下面目标函数中的KL散度项)和原始预训练模型产生的模型太远。直觉是,对于任何给定的提示,都有许多可能的响应,其中绝大多数是RM从未见过的。对于许多未知的((prompt, response) 样本,RM可能会错误地给出极高或极低的分数。如果没有这个约束,模型可能会偏向那些得分极高的响应,即使它们可能不是好的响应。
奖励模型微调的数学化的表示
- 这一步骤采用了强化学习方法
- Action 空间: LLM 词汇使用的token。 采取的动作对应于选择模型输出的token。
- 观测空间: 所有可能 prompts的分布。
- 策略: 在给定观察(prompt)的情况下,要采取的所有行动(又生成token)的概率分布。 LLM构成了一个策略,因为它决定了接下来生成token的可能性。
- 奖励函数: 上述RM模型。
- 训练数据集: 随机选择的prompts
- 数据规模: 1万 - 10万prompts
- InstructGPT: 4万 prompts
公式表示
- RM:RM模型小节所述模型
- L L M S F T LLM^{SFT} LLMSFT:从SFT模型小节获得的指令微调模型,给定prompt x \mathbf x x,模型输出是应答的概率,在InstructGPT论文中, L L M S F T LLM^{SFT} LLMSFT用 π S F T \pi^{SFT} πSFT表示。
-
L
L
M
ϕ
R
L
LLM_{\phi}^{RL}
LLMϕRL:参数集用
ϕ
\phi
ϕ表示的强化学习训练模型。
- 强化学习训练的目标是找到使得RM模型得分最大的参数集 ϕ \phi ϕ
- 给定prompt x \mathbf x x,其输出对应应答的概率分布。
- 在InstructGPT论文中, L L M ϕ R L LLM_{\phi}^{RL} LLMϕRL记作 π ϕ R L \pi_{\phi}^{RL} πϕRL
- x \mathbf x x: prompt
- D R L D_{RL} DRL:RM模型使用的prompt分布
-
D
p
r
e
t
r
a
i
n
D_{pretrain}
Dpretrain:预训练模型的训练数据集分布
对于每一步训练,从 D R L D_{RL} DRL中选择一个batch size的样本,记为 x R L \mathbf x_{RL} xRL,以及从 D p r e t r a i n D_{pretrain} Dpretrain中选择一个batch size的样本,记为 x p r e t r a i n \mathbf x_{pretrain} xpretrain。这两种数据来自不同的样本集,因而目标函数是有区别的。
1.对于每个RM模型输入 x R L \mathbf x_{RL} xRL,则使用强化学习模型 L L M ϕ R L LLM_{\phi}^{RL} LLMϕRL得到该prompt下的输出,记为 y ∼ L L M ϕ R L ( x R L ) y \sim LLM_{\phi}^{RL}(\mathbf x_{RL}) y∼LLMϕRL(xRL),则目标函数按照如下方式计算,
O 1 ( x R L , y ; ϕ ) = R M ( x R L , y ) − β log L L M ϕ R L ( y ∣ x ) L L M S F T ( y ∣ x ) O_1 {(\mathbf x_{RL},y;ϕ)=RM(\mathbf x_{RL},y)−β \log \frac{LLM^{RL}_ϕ(y|x)}{LLM^{SFT}(y|x)}} O1(xRL,y;ϕ)=RM(xRL,y)−βlogLLMSFT(y∣x)LLMϕRL(y∣x)
其中第二项是为了RL模型不要和SFT模型偏离太大而引入的KL散度。
2.对每一个 x p r e t r a i n \mathbf x_{pretrain} xpretrain,目标函数应该是得RM模型在该prompt下输出不应该比预训练模型差:
O 2 ( x p r e t r a i n ; ϕ ) = γ log L L M ϕ R L ( x p r e t r a i n ) O_2(\mathbf x_{pretrain}; \phi) = \gamma \log LLM_{\phi}^{RL}(\mathbf x_{pretrain}) O2(xpretrain;ϕ)=γlogLLMϕRL(xpretrain)
最终的目标函数是二者的和,在RL设置中,最大化目标函数。
o b j e c t i v e ( ϕ ) = E x ∼ D R L E y ∼ L L M ϕ R L ( x ) [ R M ( x , y ) − β log L L M ϕ R L ( y ∣ x ) L L M S F T ( y ∣ x ) ] + γ E x ∼ D p r e t r a i n log L L M ϕ R L ( x ) objective (ϕ)=E_{x \sim D_{RL}}E_{y∼LLM^{RL}_ϕ(x)}[RM(x,y)−β\log\frac{ LLM^{RL}_ϕ(y|x)}{LLM^{SFT}(y|x)]}+γE_x∼D_{pretrain}\log LLM^{RL}_ϕ(x) objective(ϕ)=Ex∼DRLEy∼LLMϕRL(x)[RM(x,y)−βlogLLMSFT(y∣x)]LLMϕRL(y∣x)+γEx∼DpretrainlogLLMϕRL(x)
与之一样意义的InstructGPT文章的目标函数写法是:

大语言模型虚构生成内容
我发现有两种假说可以解释LLM产生构生成内容:
Pedro A.Ortega等人于2021年10月在DeepMind首次提出的第一个假设是,LLM虚构生成是因为他们“对自己行为的因果缺乏了解”(当时,DeepMind将“妄想”一词用于“幻觉”)。他们表明,这可以通过将反应产生视为因果干预来解决。
第二种假设是,虚构生成是由LLM的内部知识和贴标者的内部知识不匹配引起的。OpenAI联合创始人兼PPO作者John Schulman在加州大学伯克利分校的演讲中(2023年4月)提出,行为克隆会导致虚假生成。在SFT期间,LLM被训练成模仿人类写的反应。如果我们用我们所掌握但LLM所没有的知识做出回应,我们就是在教LLM虚构。
2021年12月,另一位OpenAI员工Leo Gao也很好地阐述了这一观点。理论上,人类标注者可以在每次提示时包括他们所知道的所有上下文,以教导模型只使用现有知识。然而,这在实践中是不可能的。
舒尔曼认为,LLM知道他们是否知道一些事情,这意味着如果我们找到一种方法迫使LLM只给出包含他们知道的信息的答案,虚构就可以得到解决。然后他提出了几个解决方案。
- 验证:要求LLM解释(检索)它从哪里得到答案的来源。
- 强化学习。RM模型只使用比较进行训练:反应A比反应B好,没有任何关于A好多少或为什么好的信息。舒尔曼认为,我们可以通过拥有更好的奖励功能来解决幻觉,例如,惩罚一个虚构的模型。
2023年4月舒尔曼给出的RL方法解决虚构的观点截屏如下:

然而,InstructGPT的论文表明RLHF实际上使虚构更加严重。如下图所示:


