
- 1uniapp 总结篇 (小程序)_uniapp开发小程序
- 2chatgpt赋能python:用Python画龙:SEO技巧大放送_用python画一条龙
- 3!!!亲测成功:langchain+ChatGLM 大模型部署_chatglm3 如何langchain结合
- 4tf.data.Dataset.map()函数的理解
- 5基于yolov5的目标检测-停车位检测、低矮障碍物、地面标识检测等_yolo算法准确识别车辆,车位划线
- 6微信小程序接入直播_微信小程序如何对接直播
- 7基于本地知识库的大模型搭建教程_python 个人知识库搭建
- 8Gradle下载以及安装教程_gradle-5.5.1-bin.zip
- 9C++异步变化:libunifex实现!
- 10面试知识点梳理及相关面试题(三) -- springcloud_springcloudalibaba面试题
入门科普:一文看懂NLP和中文分词算法(附代码举例)
赞
踩

导读:在人类社会中,语言扮演着重要的角色,语言是人类区别于其他动物的根本标志,没有语言,人类的思维无从谈起,沟通交流更是无源之水。
所谓“自然”乃是寓意自然进化形成,是为了区分一些人造语言,类似C++、Java等人为设计的语言。
NLP的目的是让计算机能够处理、理解以及运用人类语言,达到人与计算机之间的有效通讯。
作者:涂铭 刘祥 刘树春
本文摘编自《Python自然语言处理实战:核心技术与算法》,如需转载请联系我们

01 什么是NLP
1. NLP的概念
NLP(Natural Language Processing,自然语言处理)是计算机科学领域以及人工智能领域的一个重要的研究方向,它研究用计算机来处理、理解以及运用人类语言(如中文、英文等),达到人与计算机之间进行有效通讯。
在一般情况下,用户可能不熟悉机器语言,所以自然语言处理技术可以帮助这样的用户使用自然语言和机器交流。从建模的角度看,为了方便计算机处理,自然语言可以被定义为一组规则或符号的集合,我们组合集合中的符号来传递各种信息。
这些年,NLP研究取得了长足的进步,逐渐发展成为一门独立的学科,从自然语言的角度出发,NLP基本可以分为两个部分:自然语言处理以及自然语言生成,演化为理解和生成文本的任务,如图所示。
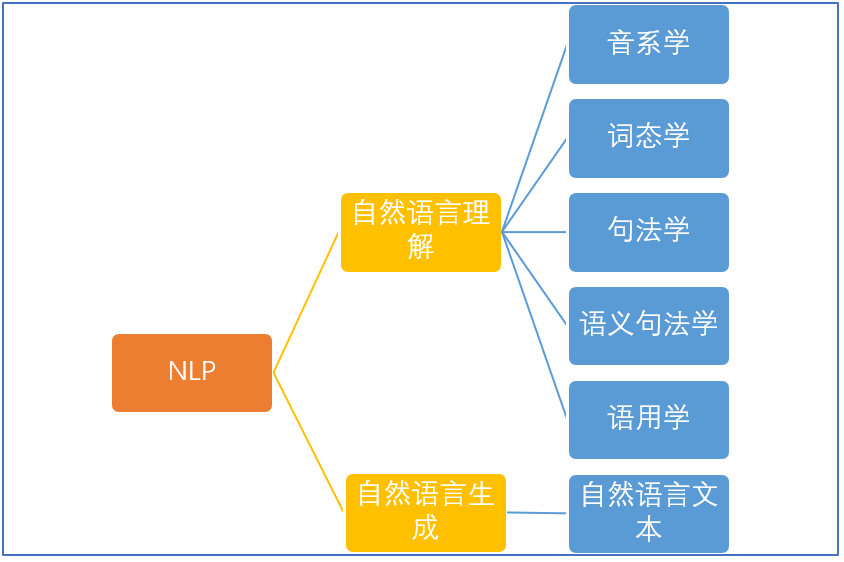
▲NLP的基本分类
自然语言的理解是个综合的系统工程,它又包含了很多细分学科,有代表声音的音系学,代表构词法的词态学,代表语句结构的句法学,代表理解的语义句法学和语用学。
音系学:指代语言中发音的系统化组织。
词态学:研究单词构成以及相互之间的关系。
句法学:给定文本的哪部分是语法正确的。
语义学:给定文本的含义是什么?
语用学:文本的目的是什么?
语言理解涉及语言、语境和各种语言形式的学科。而自然语言生成(Natural Language Generation,NLG)恰恰相反,从结构化数据中以读取的方式自动生成文本。该过程主要包含三个阶段:
文本规划:完成结构化数据中的基础内容规划
语句规划:从结构化数据中组合语句来表达信息流
实现:产生语法通顺的语句来表达文本
2. NLP的研究任务
NLP可以被应用于很多领域,这里大概总结出以下几种通用的应用:
机器翻译:计算机具备将一种语言翻译成另一种语言的能力。
情感分析:计算机能够判断用户评论是否积极。
智能问答:计算机能够正确回答输入的问题。
文摘生成:计算机能够准确归纳、总结并产生文本摘要。
文本分类:计算机能够采集各种文章,进行主题分析,从而进行自动分类。
舆论分析:计算机能够判断目前舆论的导向。
知识图谱:知识点相互连接而成的语义网络。
机器翻译是自然语言处理中最为人所熟知的场景,国内外有很多比较成熟的机器翻译产品,比如百度翻译、Google翻译等,还有提供支持语音输入的多国语言互译的产品。
情感分析在一些评论网站比较有用,比如某餐饮网站的评论中会有非常多拔草的客人的评价,如果一眼扫过去满眼都是又贵又难吃,那谁还想去呢?另外有些商家为了获取大量的客户不惜雇佣水军灌水,那就可以通过自然语言处理来做水军识别,情感分析来分析总体用户评价是积极还是消极。
智能问答在一些电商网站有非常实际的价值,比如代替人工充当客服角色,有很多基本而且重复的问题,其实并不需要人工客服来解决,通过智能问答系统可以筛选掉大量重复的问题,使得人工座席能更好地服务客户。
文摘生成利用计算机自动地从原始文献中摘取文摘,全面准确地反映某一文献的中心内容。这个技术可以帮助人们节省大量的时间成本,而且效率更高。
文本分类是机器对文本按照一定的分类体系自动标注类别的过程。举一个例子,垃圾邮件是一种令人头痛的顽症,困扰着非常多的互联网用户。2002年,Paul Graham提出使用“贝叶斯推断”来过滤垃圾邮件,1000封垃圾邮件中可以过滤掉995封并且没有一个是误判,另外这种过滤器还具有自我学习功能,会根据新收到的邮件,不断调整。也就是说收到的垃圾邮件越多,相对应的判断垃圾邮件的准确率就越高。
舆论分析可以帮助分析哪些话题是目前的热点,分析传播路径以及发展趋势,对于不好的舆论导向可以进行有效的控制。
知识图谱(Knowledge Graph/Vault)又称科学知识图谱,在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。知识图谱的一般表现形式如图所示。
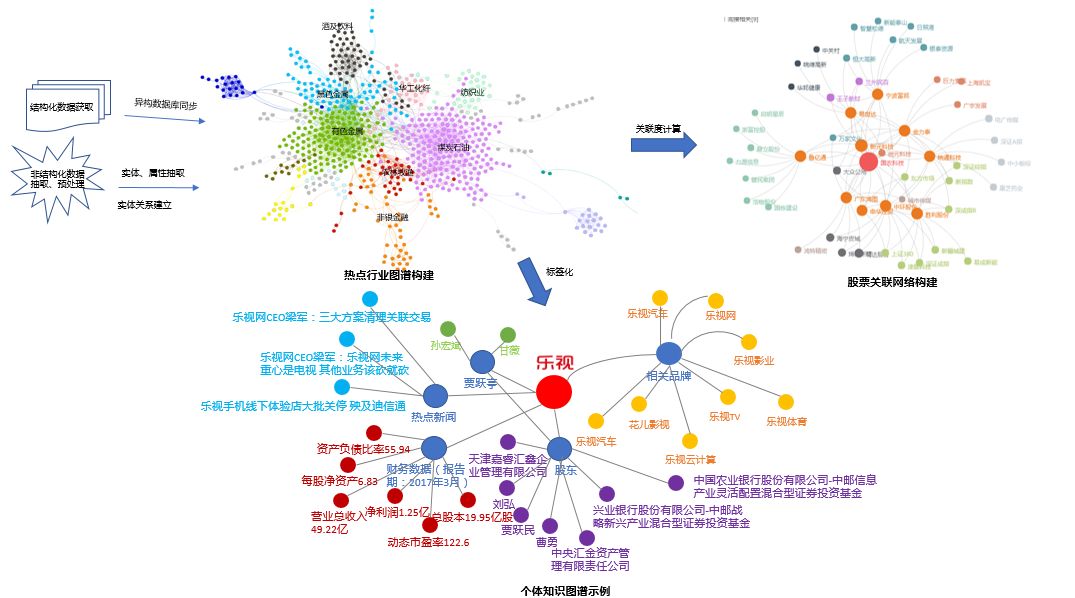
▲知识图谱图示
3. NLP相关知识的构成
3.1 基本术语
为了帮助读者更好地学习NLP,这里会一一介绍NLP领域的一些基础专业词汇。
(1)分词(segment)
词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文分词的基础与关键。
中文和英文都存在分词的需求,不过相较而言,英文单词本来就有空格进行分割,所以处理起来相对方便。但是,由于中文是没有分隔符的,所以分词的问题就比较重要。
分词常用的手段是基于字典的最长串匹配,据说可以解决85%的问题,但是歧义分词很难。举个例子,“美国会通过对台售武法案”,我们既可以切分为“美国/会/通过对台售武法案”,又可以切分成“美/国会/通过对台售武法案”。
(2)词性标注(part-of-speech tagging)
基于机器学习的方法里,往往需要对词的词性进行标注。词性一般是指动词、名词、形容词等。标注的目的是表征词的一种隐藏状态,隐藏状态构成的转移就构成了状态转移序列。例如:我/r爱/v北京/ns天安门/ns。其中,ns代表名词,v代表动词,ns、v都是标注,以此类推。
(3)命名实体识别(NER,Named Entity Recognition)
命名实体是指从文本中识别具有特定类别的实体(通常是名词),例如人名、地名、机构名、专有名词等。
(4)句法分析(syntax parsing)
句法分析往往是一种基于规则的专家系统。当然也不是说它不能用统计学的方法进行构建,不过最初的时候,还是利用语言学专家的知识来构建的。句法分析的目的是解析句子中各个成分的依赖关系。
所以,往往最终生成的结果是一棵句法分析树。句法分析可以解决传统词袋模型不考虑上下文的问题。比如,“小李是小杨的班长”和“小杨是小李的班长”,这两句话,用词袋模型是完全相同的,但是句法分析可以分析出其中的主从关系,真正理清句子的关系。
(5)指代消解(anaphora resolution)
中文中代词出现的频率很高,它的作用的是用来表征前文出现过的人名、地名等。
例如,清华大学坐落于北京,这家大学是目前中国最好的大学之一。在这句话中,其实“清华大学”这个词出现了两次,“这家大学”指代的就是清华大学。但是出于中文的习惯,我们不会把“清华大学”再重复一遍。
(6)情感识别(emotion recognition)
所谓情感识别,本质上是分类问题,经常被应用在舆情分析等领域。情感一般可以分为两类,即正面、负面,也可以是三类,在前面的基础上,再加上中性类别。
一般来说,在电商企业,情感识别可以分析商品评价的好坏,以此作为下一个环节的评判依据。通常可以基于词袋模型+分类器,或者现在流行的词向量模型+RNN。经过测试发现,后者比前者准确率略有提升。
(7)纠错(correction)
自动纠错在搜索技术以及输入法中利用得很多。由于用户的输入出错的可能性比较大,出错的场景也比较多。所以,我们需要一个纠错系统。具体做法有很多,可以基于N-Gram进行纠错,也可以通过字典树、有限状态机等方法进行纠错。
(8)问答系统(QA system)
这是一种类似机器人的人工智能系统。比较著名的有:苹果Siri、IBM Watson、微软小冰等。问答系统往往需要语音识别、合成,自然语言理解、知识图谱等多项技术的配合才会实现得比较好。
3.2 知识结构
作为一门综合学科,NLP是研究人与机器之间用自然语言进行有效通信的理论和方法。这需要很多跨学科的知识,需要语言学、统计学、最优化理论、机器学习、深度学习以及自然语言处理相关理论模型知识做基础。
作为一门杂学,NLP可谓是包罗万象,体系化与特殊化并存,这里简单罗列其知识体系,知识结构结构图如图所示。

▲知识结构图示
自然语言的学习,需要有以下几个前置知识体系:
目前主流的自然语言处理技术使用python来编写。
统计学以及线性代数入门。
02 中文分词技术
1. 中文分词简介
“词”这个概念一直是汉语语言学界纠缠不清而又绕不开的问题。“词是什么”(词的抽象定义)和“什么是词”(词的具体界定),这两个基本问题迄今为止也未能有一个权威、明确的表述,更无法拿出令大众认同的词表来。主要难点在于汉语结构与印欧体系语种差异甚大,对词的构成边界方面很难进行界定。
比如,在英语中,单词本身就是“词”的表达,一篇英文文章就是“单词”加分隔符(空格)来表示的,而在汉语中,词以字为基本单位的,但是一篇文章的语义表达却仍然是以词来划分的。
因此,在处理中文文本时,需要进行分词处理,将句子转化为词的表示。这个切词处理过程就是中文分词,它通过计算机自动识别出句子的词,在词间加入边界标记符,分隔出各个词汇。
整个过程看似简单,然而实践起来却很复杂,主要的困难在于分词歧义。以NLP分词的经典语句举例,“结婚的和尚未结婚的”,应该分词为“结婚/的/和/尚未/结婚/的”,还是“结婚/的/和尚/未/结婚/的”?这个由人来判定都是问题,机器就更难处理了。
此外,像未登录词、分词粒度粗细等都是影响分词效果的重要因素。
自中文自动分词被提出以来,历经将近30年的探索,提出了很多方法,可主要归纳为“规则分词”“统计分词”和“混合分词(规则+统计)”这三个主要流派。
规则分词是最早兴起的方法,主要是通过人工设立词库,按照一定方式进行匹配切分,其实现简单高效,但对新词很难进行处理。
随后统计机器学习技术的兴起,应用于分词任务上后,就有了统计分词,能够较好应对新词发现等特殊场景。
然而实践中,单纯的统计分词也有缺陷,那就是太过于依赖语料的质量,因此实践中多是采用这两种方法的结合,即混合分词。
下面将详细介绍这些方法的代表性算法。

2. 规则分词
基于规则的分词是一种机械分词方法,主要是通过维护词典,在切分语句时,将语句的每个字符串与词表中的词进行逐一匹配,找到则切分,否则不予切分。
按照匹配切分的方式,主要有正向最大匹配法、逆向最大匹配法以及双向最大匹配法三种方法。
2.1 正向最大匹配法
正向最大匹配(Maximum Match Method,MM法)的基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理。
如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
其算法描述如下:
从左向右取待切分汉语句的m个字符作为匹配字段,m为机器词典中最长词条的字符数。
查找机器词典并进行匹配。若匹配成功,则将这个匹配字段作为一个词切分出来。若匹配不成功,则将这个匹配字段的最后一个字去掉,剩下的字符串作为新的匹配字段,进行再次匹配,重复以上过程,直到切分出所有词为止。
比如我们现在有个词典,最长词的长度为5,词典中存在“南京市长”和“长江大桥”两个词。
现采用正向最大匹配对句子“南京市长江大桥”进行分词,那么首先从句子中取出前五个字“南京市长江”,发现词典中没有该词,于是缩小长度,取前4个字“南京市长”,词典中存在该词,于是该词被确认切分。再将剩下的“江大桥”按照同样方式切分,得到“江”“大桥”,最终分为“南京市长”“江”“大桥”3个词。
显然,这种结果还不是我们想要的。

2.2 逆向最大匹配法
逆向最大匹配(Reverse Maximum Match Method,RMM法)的基本原理与MM法相同,不同的是分词切分的方向与MM法相反。逆向最大匹配法从被处理文档的末端开始匹配扫描,每次取最末端的i个字符(i为词典中最长词数)作为匹配字段,若匹配失败,则去掉匹配字段最前面的一个字,继续匹配。相应地,它使用的分词词典是逆序词典,其中的每个词条都将按逆序方式存放。
在实际处理时,先将文档进行倒排处理,生成逆序文档。然后,根据逆序词典,对逆序文档用正向最大匹配法处理即可。
由于汉语中偏正结构较多,若从后向前匹配,可以适当提高精确度。所以,逆向最大匹配法比正向最大匹配法的误差要小。统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
比如之前的“南京市长江大桥”,按照逆向最大匹配,最终得到“南京市”“长江大桥”。当然,如此切分并不代表完全正确,可能有个叫“江大桥”的“南京市长”也说不定。
2.3 双向最大匹配法
双向最大匹配法(Bi-directction Matching method)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。
据SunM.S.和Benjamin K.T.(1995)的研究表明,中文中90.0%左右的句子,正向最大匹配法和逆向最大匹配法完全重合且正确,只有大概9.0%的句子两种切分方法得到的结果不一样,但其中必有一个是正确的(歧义检测成功),只有不到1.0%的句子,使用正向最大匹配法和逆向最大匹配法的切分虽重合却是错的,或者正向最大匹配法和逆向最大匹配法切分不同但两个都不对(歧义检测失败)。这正是双向最大匹配法在实用中文信息处理系统中得以广泛使用的原因。
前面举例的“南京市长江大桥”,采用该方法,中间产生“南京市/长江/大桥”和“南京市/长江大桥”两种结果,最终选取词数较少的“南京市/长江大桥”这一结果。
下面是一段实现逆向最大匹配的代码。
#逆向最大匹配class IMM(object): def __init__(self, dic_path): self.dictionary = set() self.maximum = 0 #读取词典 with open(dic_path, 'r', encoding='utf8') as f: for line in f: line = line.strip() if not line: continue self.dictionary.add(line) self.maximum = len(line) def cut(self, text): result = [] index = len(text) while index > 0: word = None for size in range(self.maximum, 0, -1): if index - size < 0: continue piece = text[(index - size):index] if piece in self.dictionary: word = piece result.append(word) index -= size break if word is None: index -= 1 return result[::-1]def main(): text = "南京市长江大桥" tokenizer = IMM('./data/imm_dic.utf8') print(tokenizer.cut(text))运行main函数,结果为:
['南京市', '长江大桥']基于规则的分词,一般都较为简单高效,但是词典的维护是一个很庞大的工程。在网络发达的今天,网络新词层出不穷,很难通过词典覆盖到所有词。
3. 统计分词
随着大规模语料库的建立,统计机器学习方法的研究和发展,基于统计的中文分词算法渐渐成为主流。
其主要思想是把每个词看做是由词的最小单位的各个字组成的,如果相连的字在不同的文本中出现的次数越多,就证明这相连的字很可能就是一个词。
因此我们就可以利用字与字相邻出现的频率来反应成词的可靠度,统计语料中相邻共现的各个字的组合的频度,当组合频度高于某一个临界值时,我们便可认为此字组可能会构成一个词语。
基于统计的分词,一般要做如下两步操作:
建立统计语言模型。
对句子进行单词划分,然后对划分结果进行概率计算,获得概率最大的分词方式。这里就用到了统计学习算法,如隐含马尔可夫(HMM)、条件随机场(CRF)等。
限于篇幅,本文只对统计分词相关技术做简要介绍。更多详细内容请参考《Python自然语言处理实战:核心技术与算法》一书第3章第3.3节。
4. 混合分词
事实上,目前不管是基于规则的算法、还是基于HMM、CRF或者deep learning等的方法,其分词效果在具体任务中,其实差距并没有那么明显。在实际工程应用中,多是基于一种分词算法,然后用其他分词算法加以辅助。
最常用的方式就是先基于词典的方式进行分词,然后再用统计分词方法进行辅助。如此,能在保证词典分词准确率的基础上,对未登录词和歧义词有较好的识别。
关于作者:涂铭,阿里巴巴数据架构师,对大数据、自然语言处理、Python、Java相关技术有深入的研究,积累了丰富的实践经验。
刘祥,百炼智能自然语言处理专家,主要研究知识图谱、NLG等前沿技术,参与机器自动写作产品的研发与设计。
刘树春,七牛云高级算法专家,七牛AI实验室NLP&OCR方向负责人,主要负责七牛NLP以及OCR相关项目的研究与落地。
本文摘编自《Python自然语言处理实战:核心技术与算法》,经出版方授权发布。
延伸阅读《Python自然语言处理实战》
点击上图了解及购买
转载请联系微信:togo-maruko
推荐语:阿里巴巴、前明略数据和七牛云的高级专家和科学家撰写,零基础掌握NLP的核心技术、方法论和经典算法。

据统计,99%的大咖都完成了这个神操作
▼
更多精彩
在公众号后台对话框输入以下关键词
查看更多优质内容!
PPT | 报告 | 读书 | 书单
大数据 | 揭秘 | 人工智能 | AI
Python | 机器学习 | 深度学习 | 神经网络
可视化 | 区块链 | 干货 | 数学
猜你想看
Q: 中文分词技术都有哪些挑战?
欢迎留言与大家分享
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:baiyu@hzbook.com
更多精彩,请在后台点击“历史文章”查看

 点击阅读原文,了解更多
点击阅读原文,了解更多

