
- 1Faster R-CNN 较Fast R-CNN的改进之处与第一阶段设计细节_faster r-cnn 较 fast r-cnn改进
- 2数据结构(C语言版)严蔚敏->二叉树(链式存储结构)的构造及其几种遍历方式(先序、中序、后序、层次)和线索二叉树_构造先(根)序线索二叉树构造中(根)序线索二叉树构造后(根)序线索二叉树
- 3关于鸿蒙 DevEco Studio 使用报错 The Huawei Lite Simulator supports only Lite projects_deveco studio 虚拟机打不开
- 4测试岗面试必背的185道技术题,我看还有谁不知道!_测试工程师面试必背题
- 5ChatGPT助力AI办公
- 6Kali Linux虚拟机无法连网_kali虚拟机无法联网
- 7大模型学习笔记(一):部署ChatGLM模型以及stable-diffusion模型
- 8android实战项目开发八---当前的项目为java工程,如何引入第三方项目kotlin工程_android java项目引入kotlin
- 9mac使用命令行连接无线网(切换WIFI)_mac命令行连接wifi
- 10SVN管理工具Cornerstone之:代码合并_connerstone 代码合并
R语言聚类分析、因子分析、主成分分析PCA农村农业相关经济指标数据可视化|数据分享...
赞
踩
全文链接:https://tecdat.cn/?p=35360
随着农业和农村经济的快速发展,各地区之间的经济差异日益显著。为了更好地理解这种差异,并为政策制定提供科学依据,本研究帮助客户采用了聚类分析和因子分析、主成分分析3种无监督学习方法,对多个省份的农业、林业、牧业、渔业以及农村居民家庭的相关经济指标进行了深入研究(点击文末“阅读原文”获取完整代码数据)。
相关视频
通过这两种方法的结合应用,我们期望能够更全面地了解各省份在农业和农村经济方面的特点和差异,为相关政策的制定提供有力支持。
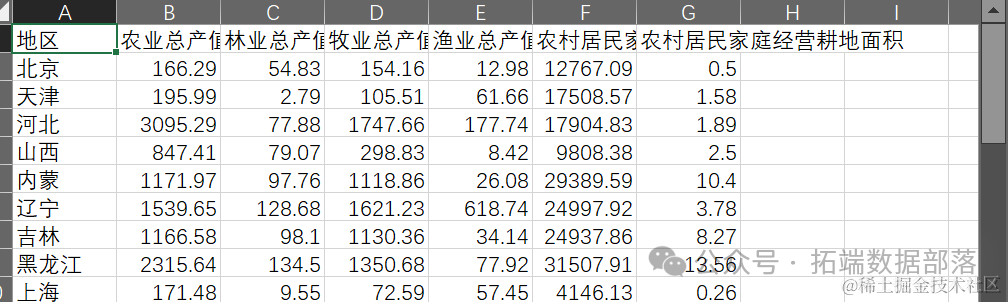
数据
数据主要涉及到多个省份的农业、林业、牧业、渔业以及农村居民家庭的相关经济指标(查看文末了解数据免费获取方式)。具体来说,这些数据包括农业总产值、林业总产值、牧业总产值、渔业总产值,这些指标反映了不同省份在各类农业产业上的产出情况,是评估农业发展水平的重要依据。此外,数据还包含了农村居民家庭拥有生产性固定资产原值,这一指标反映了农村居民家庭在农业生产上的投资规模,可以体现其生产能力和发展水平。最后,数据中的农村居民家庭经营耕地面积则直接关联到农业生产的基础资源——土地,这一指标能够反映各省份农业生产的规模和潜力。
这些数据都是量化指标,能够直观地反映各省份在农业和农村经济方面的实际情况。通过对这些数据进行聚类分析,可以进一步挖掘各省份在农业和农村经济方面的相似性和差异性,为政策制定者提供决策依据,以便更好地推动各地区的农业和农村经济发展。
聚类分析
聚类分析是一种无监督学习方法,旨在将数据划分为多个类或簇,使得同一簇内的数据对象尽可能相似,而不同簇间的数据对象尽可能不同。在本研究中,我们采用了层次聚类方法,并利用欧氏距离作为相似度度量。
首先,我们将农业总产值、林业总产值、牧业总产值、渔业总产值、农村居民家庭拥有生产性固定资产原值以及农村居民家庭经营耕地面积这六个指标进行了合并,形成一个新的数据集a。这个数据集将用于后续的聚类分析。
a=cbind(农业总产值 ,林业总产值, 牧业总产值, 渔业总产值, 农村居民家庭拥有生产性固定资产原值, 农村居民家庭经营耕地面积)#接着,我们利用层次聚类算法对数据集a进行了聚类,并绘制了聚类树状图(由于图片链接无法直接显示,请通过提供的链接查看)。树状图展示了各个省份之间基于欧氏距离的相似关系,以及聚类过程中簇的形成和合并过程。
plot(hc1,hang=-2,ylab="欧氏距离",main=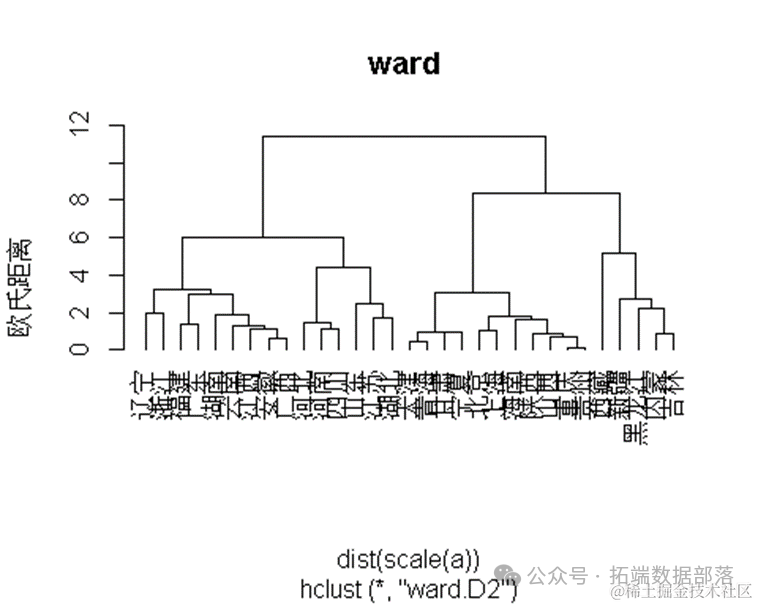
然后,我们使用函数将聚类树切割成3个簇,并输出了每个省份所属的簇编号。从输出结果中可以看出,各个省份根据它们的农业、林业、牧业、渔业以及农村居民家庭的相关指标被划分到了不同的簇中。
cutree(hc1,3)
为了确定最佳的簇数量,我们进一步使用函数进行了聚类有效性分析。该函数基于多种聚类有效性指标,如Calinski-Harabasz指数(CH指数),在不同的簇数量下评估了聚类的质量。通过比较不同簇数量下的指标值,我们可以确定最佳的簇数量。
- res<-complete", index = "ch")
- res$All.index

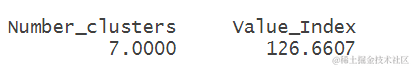

函数的输出结果显示,当簇数量为7时,CH指数达到了最大值126.6607,因此最佳的簇数量为7。此外,函数还输出了簇数量为7时的具体聚类结果,即每个省份所属的簇编号。与之前的3簇聚类结果相比,7簇聚类结果更加细致,能够更好地揭示各个省份在农业和农村经济方面的差异和联系。
综上所述,通过聚类分析,我们可以将各个省份根据其农业和农村经济指标划分为不同的簇,并揭示了它们之间的相似性和差异性。这对于进一步深入研究各个省份的农业和农村经济特点,以及制定针对性的政策措施具有重要意义。
因子分析
因子分析是一种统计方法,用于研究多个变量之间的潜在结构,通过提取少数几个因子来解释原有变量的绝大部分变异。在农业经济学的研究中,因子分析常用于识别不同农业经济指标背后的主要影响因素。
- FA=fac
- FA

输出结果显示:
Uniquenesses是每个变量中无法被因子解释的部分,也可以看作是剩余变异。数值越小,说明该变量被因子解释得越好。从结果来看,牧业总产值和渔业总产值的Uniquenesses非常小,接近于0,表明这两个变量的大部分变异能够被提取的因子解释。而农业总产值、林业总产值和农村居民家庭经营耕地面积的Uniquenesses相对较高,说明这些变量中有一部分变异是因子无法解释的。Loadings是因子载荷矩阵,表示每个变量与各个因子的关联程度。数值越大,说明该变量与对应因子的关联越强。从结果来看,农业总产值和牧业总产值与Factor1的关联较强,渔业总产值与Factor3的关联较强,林业总产值则与多个因子都有一定关联,但关联程度不如前两个变量高。此外,农村居民家庭拥有生产性固定资产原值与Factor2的关联最强。SS loadings是每个因子的方差贡献,即该因子解释的变异量。Proportion Var是每个因子解释的变异占总变异的比例,Cumulative Var则是累积解释的变异比例。从结果来看,Factor1解释的变异量最大,达到了36.1%,Factor2和Factor3分别解释了23.3%和17.2%的变异,三个因子累积解释了76.5%的变异。The degrees of freedom for the model is 0 and the fit was 0.0338表示模型的自由度以及模型拟合优度。这里的拟合优度较低,可能是因为数据中存在一定的噪音或者模型假设与实际情况存在偏差。
为了更直观地展示因子分析的结果,我们绘制了因子得分和因子载荷的散点图:
bi$loadings)
在这张图中,每个点代表一个省份(或样本),点的位置反映了该省份在三个因子上的得分情况。同时,图中的箭头表示各个变量的因子载荷,箭头的方向和长度反映了变量与因子的关联程度和方向。通过这张图,我们可以直观地看到不同省份在因子空间中的分布情况,以及各个变量与因子的关系。例如,农业总产值和牧业总产值与Factor1正相关,而渔业总产值与Factor3正相关。这些结果有助于我们深入理解农业经济指标之间的潜在结构和关系。
点击标题查阅往期内容

R语言SOM神经网络聚类、多层感知机MLP、PCA主成分分析可视化银行客户信用数据实例

左右滑动查看更多
01
02
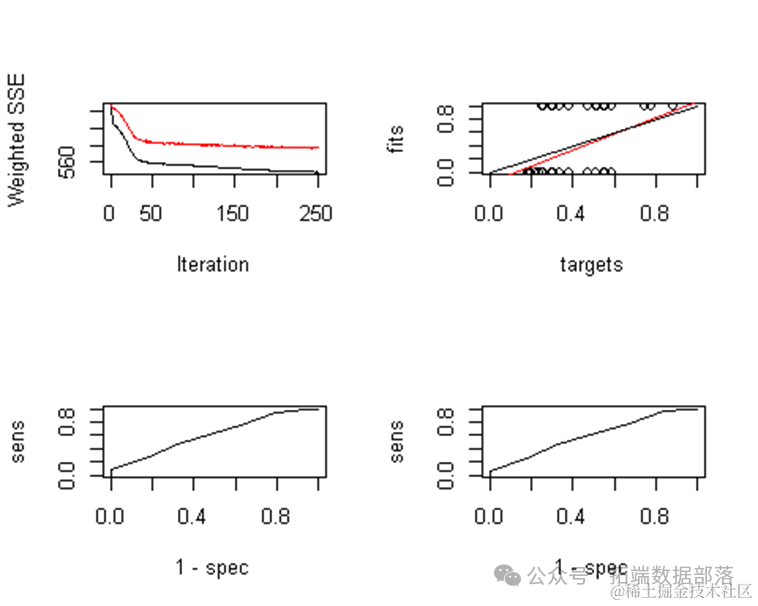
03
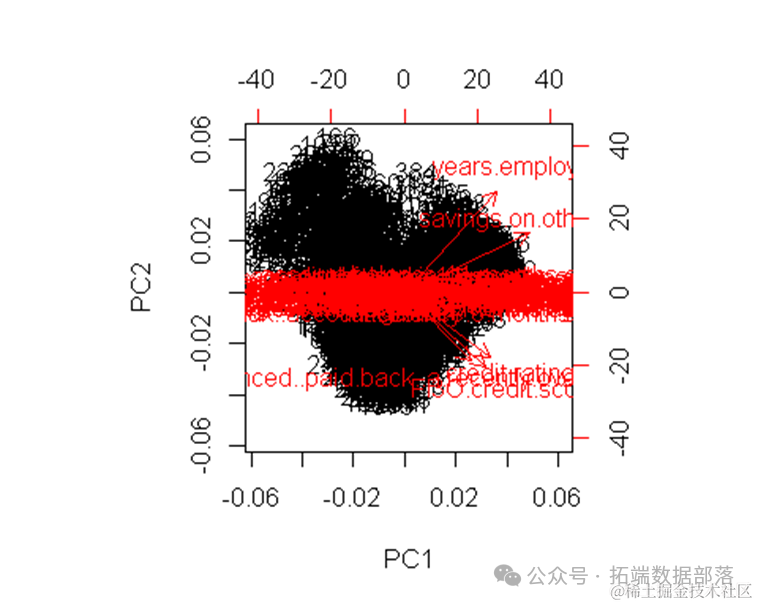
04
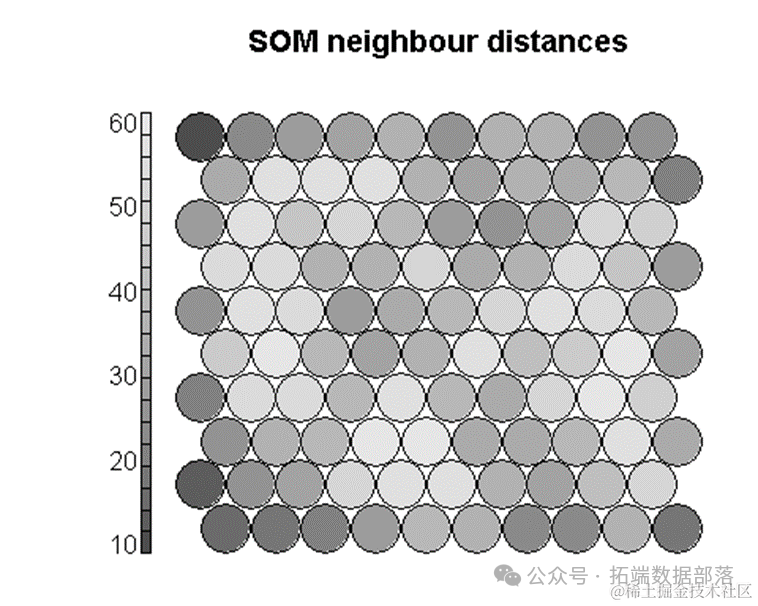
主成分分析
主成分分析(PCA)是一种用于数据降维的统计方法,它可以将原始变量转化为少数几个主成分,这些主成分保留了原始数据的大部分变异信息,同时减少了数据的复杂性。下面是对一组数据进行主成分分析的结果解释:
- incomp(x)# 分分析
- suary(PCA)
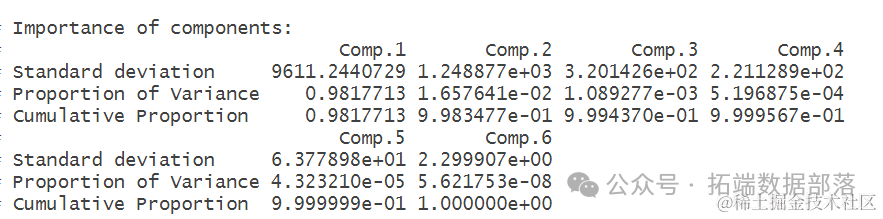
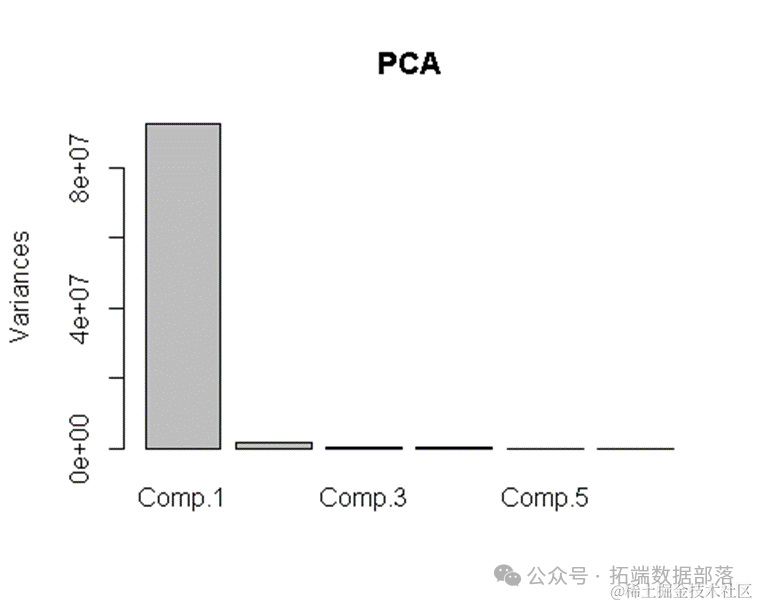
Importance of components部分显示了每个主成分的重要性。Standard deviation是每个主成分的标准差,它反映了主成分的大小或变异程度。Proportion of Variance表示每个主成分解释的原始数据变异的比例,而Cumulative Proportion则显示了累积解释的变异比例。
从结果中可以看出,第一主成分(Comp.1)的标准差最大,解释了约98.18%的变异,而后续的主成分解释的变异比例逐渐减小。到第五个主成分时,累积解释的变异比例已经非常接近100%,表明前几个主成分已经能够很好地概括原始数据的变异情况。
接下来,我们绘制了主成分的碎石图:
screeplot(PCA,type="lines")#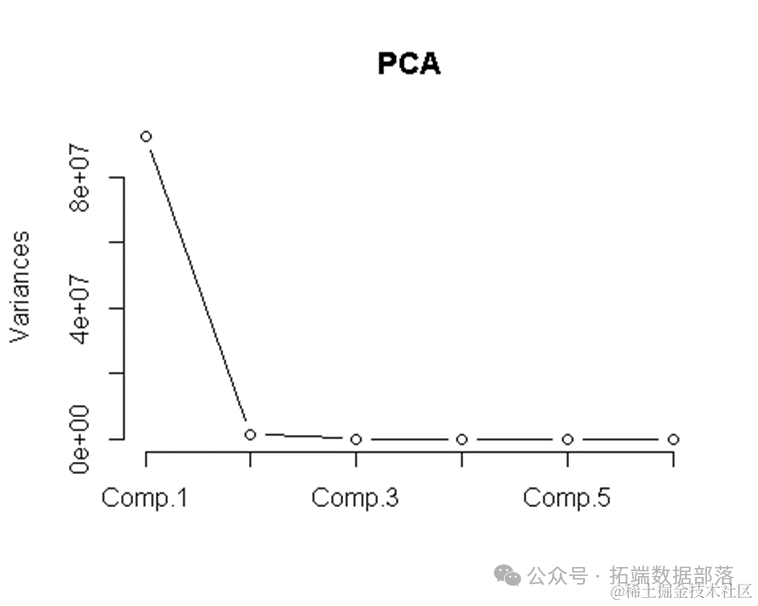
碎石图是一种可视化工具,用于展示每个主成分解释的变异比例。在图中,每个点或线段的高度代表对应主成分解释的变异比例。通过观察碎石图,我们可以直观地看到哪些主成分对数据的解释贡献较大,以及何时达到一个“拐点”,即后续主成分对变异的解释贡献开始显著下降。
在本例中,碎石图显示第一主成分解释的变异最大,随后逐渐减小。在第一主成分之后,曲线的斜率开始明显变缓,表明后续主成分对变异的解释贡献逐渐减小。这进一步支持了之前通过 summary(PCA) 得到的结论,即前几个主成分已经足够概括原始数据的变异情况。
结合 summary(PCA) 和碎石图的结果,我们可以确定保留的主成分数量,以便在后续分析中使用这些主成分代替原始变量,实现数据的降维和简化。在实际应用中,通常选择那些累积解释变异比例达到一定阈值(如85%或90%)的主成分。
主成分分析的结果主要包括了每个主成分对应的载荷系数以及这些主成分解释的变异比例。载荷系数反映了原始变量与主成分之间的相关性,而解释的变异比例则告诉我们每个主成分对原始数据变异的贡献大小。
首先,我们查看PCA$loadings的结果:
PCA$loadings#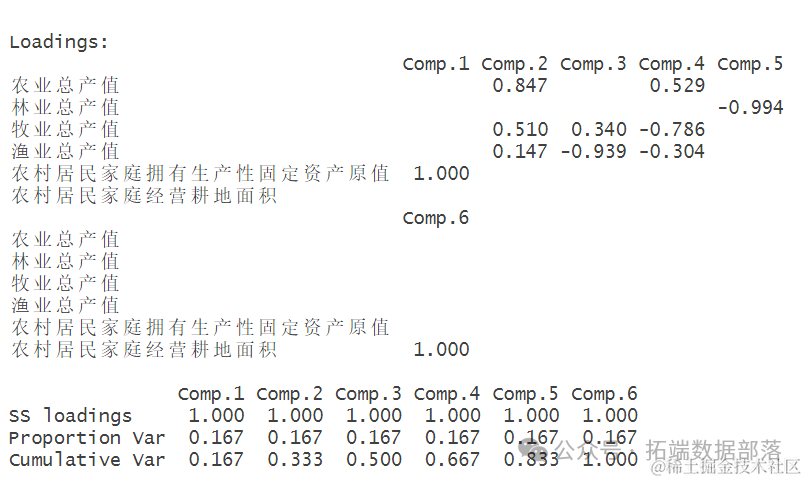
这里的Loadings部分给出了主成分与原始变量之间的相关性。例如,农业总产值与第一主成分(Comp.1)的相关性为0.847,表明第一主成分与农业总产值有较强的正相关关系。类似地,林业总产值与第五主成分(Comp.5)的相关性为-0.994,表示第五主成分与林业总产值有较强的负相关关系。
SS loadings是每个主成分载荷的平方和,反映了主成分对原始变量方差的解释程度。Proportion Var是每个主成分解释的原始数据变异的比例,而Cumulative Var则是累积解释的变异比例。
接下来,我们看手动计算得到的主成分载荷系数:
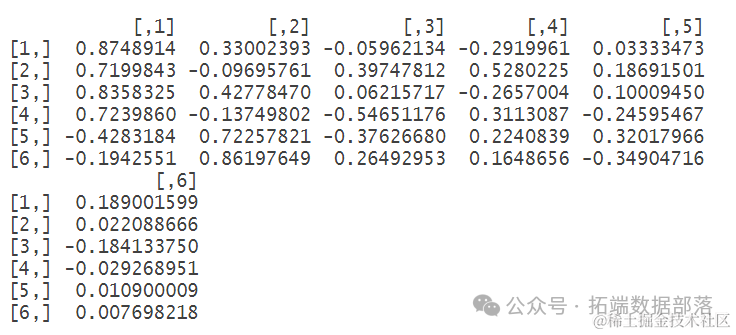
输出主成分分析(PCA)的载荷系数(loadings)。载荷系数表示原始变量与主成分之间的相关性,可以帮助我们理解每个主成分是由哪些原始变量驱动的。
print(-loadings(PCA),cutoff=0.001)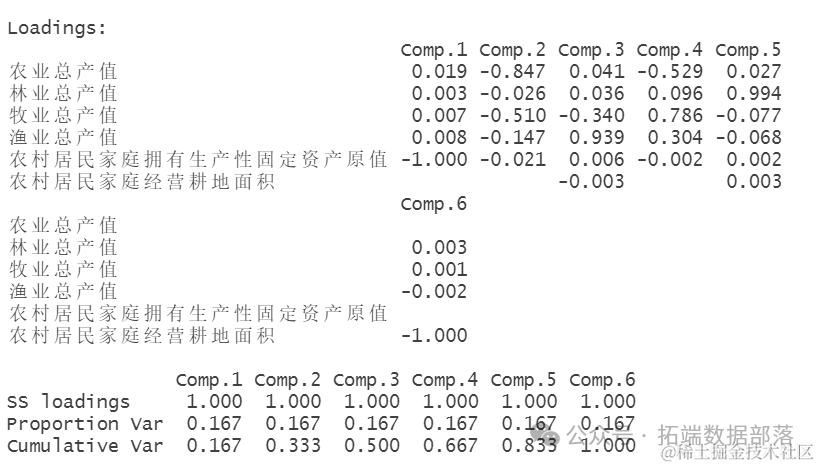
让我们详细解释一下输出内容:
Loadings 部分:
这部分列出了每个原始变量(如“农业总产值”、“林业总产值”等)与每个主成分(如“Comp.1”、“Comp.2”等)之间的载荷系数。载荷系数可以是正数或负数,表示原始变量与主成分之间的正相关或负相关关系。
例如,“农业总产值”与“Comp.1”的载荷系数是0.019,而与“Comp.2”的载荷系数是-0.847。这意味着“农业总产值”与第二个主成分有很强的负相关关系。
注意,“农村居民家庭拥有生产性固定资产原值”在“Comp.1”上的载荷系数是-1.000,这意味着它与第一个主成分有很强的负相关关系。同时,“农村居民家庭经营耕地面积”在“Comp.6”上的载荷系数是-1.000,表示它与第六个主成分有很强的负相关关系。
SS loadings 部分:
这部分给出了每个主成分的方差(即载荷的平方和)。在这里,每个主成分的方差都是1.000,这意味着每个主成分解释了相同数量的原始变量方差。
Proportion Var 部分:
这部分显示了每个主成分解释的原始变量总方差的比例。由于每个主成分的方差都是1.000,并且总共有6个主成分,所以每个主成分解释的方差比例是1/6,即大约0.167(或16.7%)。
Cumulative Var 部分:
这部分显示了累积解释的原始变量总方差的比例。从输出中可以看出,前三个主成分累积解释了50%的方差,前四个主成分累积解释了66.7%的方差,以此类推,直到所有六个主成分累积解释了100%的方差。
柱状图
对农业总产值创建一个水平柱状图(horizontal barplot)。
bar(pv,col=col,horiz = TRUE,xlim=c(-8000.00,5000))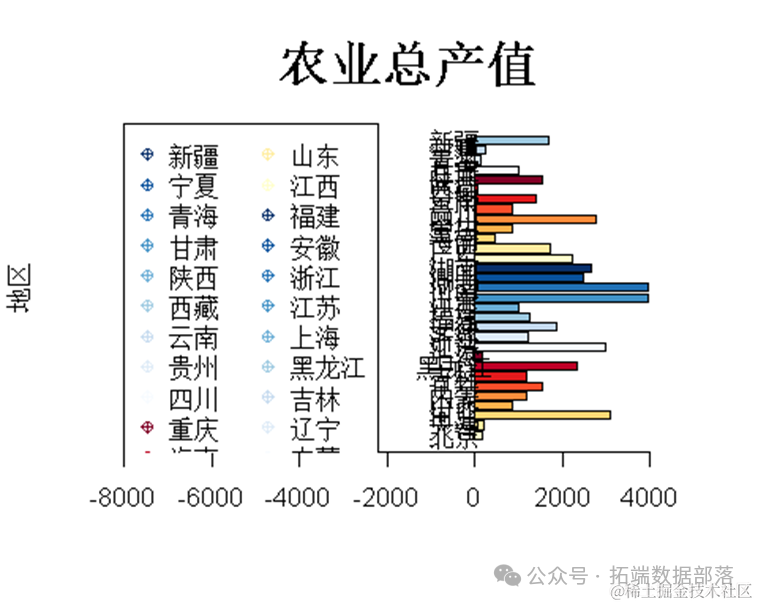
数据获取
在公众号后台回复“农业数据”,可免费获取完整数据。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言聚类分析、因子分析、主成分分析PCA农村农业相关经济指标数据可视化》。


点击标题查阅往期内容
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
R语言逻辑回归、Naive Bayes贝叶斯、决策树、随机森林算法预测心脏病
R语言中贝叶斯网络(BN)、动态贝叶斯网络、线性模型分析错颌畸形数据
R语言中的block Gibbs吉布斯采样贝叶斯多元线性回归
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言和STAN,JAGS:用RSTAN,RJAG建立贝叶斯多元线性回归预测选举数据
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言随机搜索变量选择SSVS估计贝叶斯向量自回归(BVAR)模型
R语言实现MCMC中的Metropolis–Hastings算法与吉布斯采样
R语言贝叶斯推断与MCMC:实现Metropolis-Hastings 采样算法示例
R语言使用Metropolis-Hastings采样算法自适应贝叶斯估计与可视化
R语言MCMC:Metropolis-Hastings采样用于回归的贝叶斯估计
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化

![]()


