
热门标签
热门文章
- 1共享最近邻相似度
- 2基于ROS的机器人机器人导航:掌握机器人在复杂环境中的定位技术_ros机器人
- 3YOLOv8改进主干RTMDet论文系列:高效涨点的单阶段目标检测器主干_yolov8论文
- 4使用FCN进行原始指纹图像分割(Tensorflow)_指纹fcnt
- 5中文停用词表(1893个)_中文停用词表下载
- 6神经网络和深度学习(4)--符号约定_神经网络 公式 符号 详解
- 7极客日报第 33 期:美团回应“大数据杀熟”;Docker开发者预览版支持M1芯片_大数据杀熟神经网络
- 8前端面试题——综合问题(整理)_前端面试题综合编码题
- 9python笔记(5)Numbers(数字)
- 10Redis注解式开发结合SSM项目使用与Quartz框架介绍以及击穿、穿透、雪崩问题解决_com.zking.ssm
当前位置: article > 正文
Self-Attention结构细节及计算过程_自注意力结构图
作者:小丑西瓜9 | 2024-04-01 08:18:49
赞
踩
自注意力结构图
一、结构
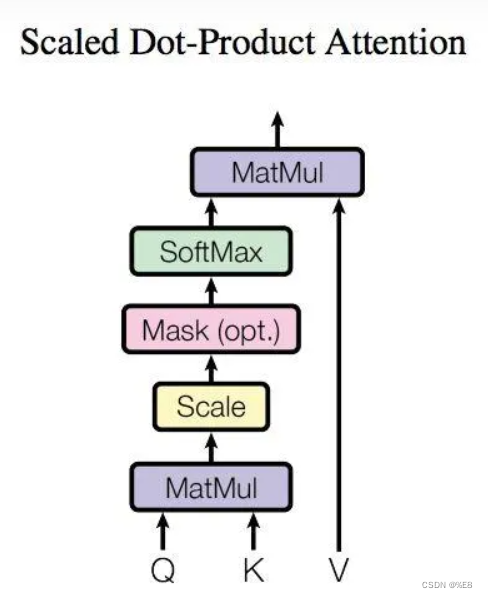
上面那个图其实不是那么重要,只要知道将输入的x矩阵转换成三个矩阵进行计算即可。自注意力结构的输入为 输入矩阵的三个变形 Q(query矩阵)、K(key矩阵)、V(value矩阵)构成,那么Q、K、V是如何得到的呢?
假设输入矩阵是 M*N的一个矩阵,也就是意味着输入有M个单词,则:
1.1 Q矩阵:

1.2 K矩阵:
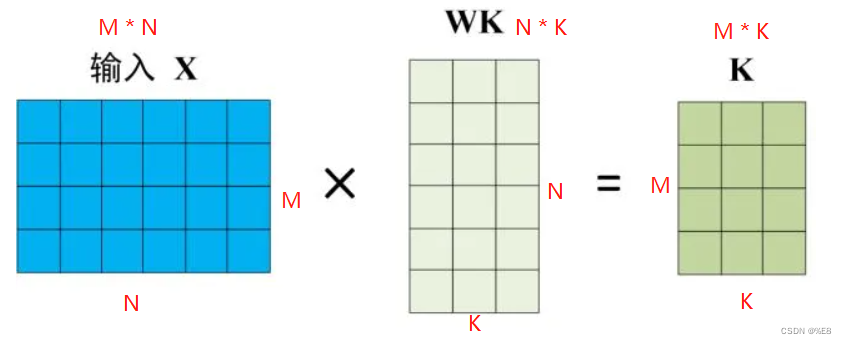
1.3 V矩阵:

注:作为中间矩阵的行数必须是N的,否则不能做矩阵乘法,且Q、K两个矩阵必须行列一致,否则不能保持最后的Q、K、V矩阵行列一致。
二、self-Attention输出
计算公式如下:

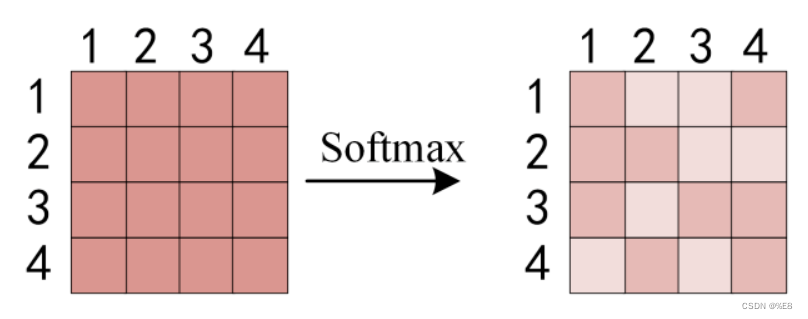
即计算Q矩阵与K矩阵的乘积,得到了一个N * N的矩阵,N为单词个数:

为了避免数值过大,除了向量维度的平方根。
接着计算每个单词对于其他单词的注意力系数,由于是对每一行过Softmax函数,则每行之和为1.
最后将得到的注意力系数矩阵与V矩阵相乘:
注意注意!!这里应该是V矩阵在左边,注意力矩阵在右。
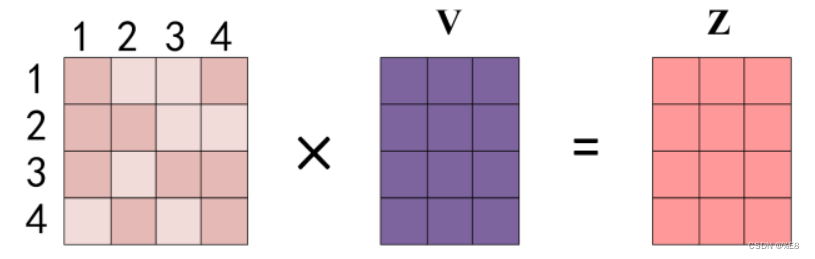
eg:word1如何计算得到z1:
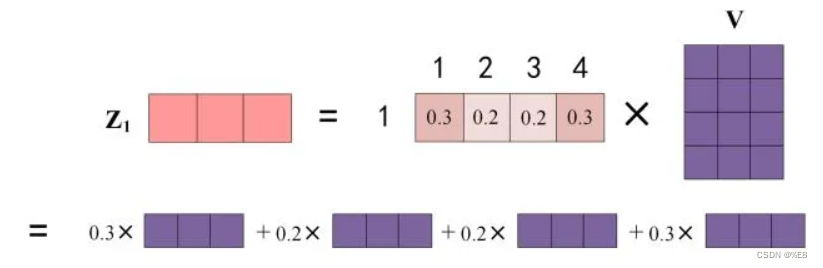
Reference:Transformer模型详解(图解最完整版) - 知乎
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/347899
推荐阅读
相关标签

