
- 1编程报错:missing 1 required positional argument
- 2python aiml_使用Python AIML搭建聊天机器人的方法示例
- 3Spring Boot项目启动速度优化
- 4开源的页面生成器:拖拽即可生成小程序、H5页面和网站
- 5矩阵分解在自然语言处理中的应用:情感分析和文本摘要
- 6Python - 深度学习系列13- 显卡与CPU计算对比_显卡算法和处理器算法
- 7中文医学大模型“本草”(原名华驼):医学知识增强在中文大型语言模型指令微调上的初步探索...
- 8字节8年经验之谈 —— 聊一聊自动化测试为什么很难落地!
- 9数据库更新两张相关联的表
- 10Asp.Net Core文件上传IFormFile_asp.net core iformfile
ResNet 论文精读 & 残差块的恒等映射 & 网络结构的解析_resnet 恒等映射
赞
踩
论文重要知识:恒等映射、两种残差块、维度匹配和残差学习(层响应标准差)
Deep Residual Learning for Image Recognition
用于图像识别的深度残差学习
目录
(2)Identity Mapping by Shortcuts(快捷连接的恒等映射)
(3)网络架构(Plain Network and Residual Network)
一、摘要
更深层的神经网络更难训练。我们提出了一个残差学习框架来简化那些比以前使用的深度更深的网络的训练。我们显式地将层重构为参考层输入的学习残差函数(恒等映射),而不是学习未参考的函数。我们提供了全面的经验证据,表明这些残差网络更容易优化,并且可以从相当大的深度增加中获得准确性。在ImageNet数据集上评估了深度高达152层的残差网络- -比VGG网络《Very deep convolutional networksfor large-scale image recognition》深8倍,但仍具有较低的复杂度。这些残差网络的集合在ImageNet测试集上达到3.57 %的误差。这个结果赢得了ILSVRC 2015分类任务的第一名。我们还介绍了对100层和1000层的CIFAR - 10的分析。
表征的深度对于许多视觉识别任务具有重要意义。仅仅由于我们的极深表示,我们在COCO目标检测数据集上获得了28 %的相对提升。深度残差网络是我们提交ILSVRC & COCO 2015竞赛1的基础,我们在ImageNet检测、ImageNet定位、COCO检测和COCO分割任务上也获得了第1名。
本文章没有结论,但是有很多实验的数据。
二、Introduction(介绍ResNet)
在深度重要性的驱动下,一个问题出现了:学习更好的网络是否像堆叠更多的层一样容易?回答这个问题的一个障碍是臭名昭著的梯度消失/爆炸问题《Learning long-term dependen-cies with gradient descent is difficult.》《Understanding the difficulty of trainingdeep feedforward neural networks》,它从一开始就阻碍了收敛。然而,这个问题在很大程度上是通过归一化初始化和中间归一化层来解决的《Batch normalization》,这使得具有数十层的网络能够通过反向传播开始收敛到随机梯度下降( SGD ) 《Backpropagation applied to hand-written zip code recognition. 1989》。
当更深层的网络能够开始收敛时,一个退化问题就暴露出来了:随着网络深度的增加,精度达到饱和(这可能不足为奇),然后迅速退化。出乎意料的是,这种退化并不是由过拟合引起的,在适当深度的模型中增加更多的层会导致更高的训练误差,正如在《Convolutional neural networks at constrained timecost.》和《Highway networks》中报告的那样,并通过我们的实验得到了彻底的验证。图1显示了一个典型的例子。
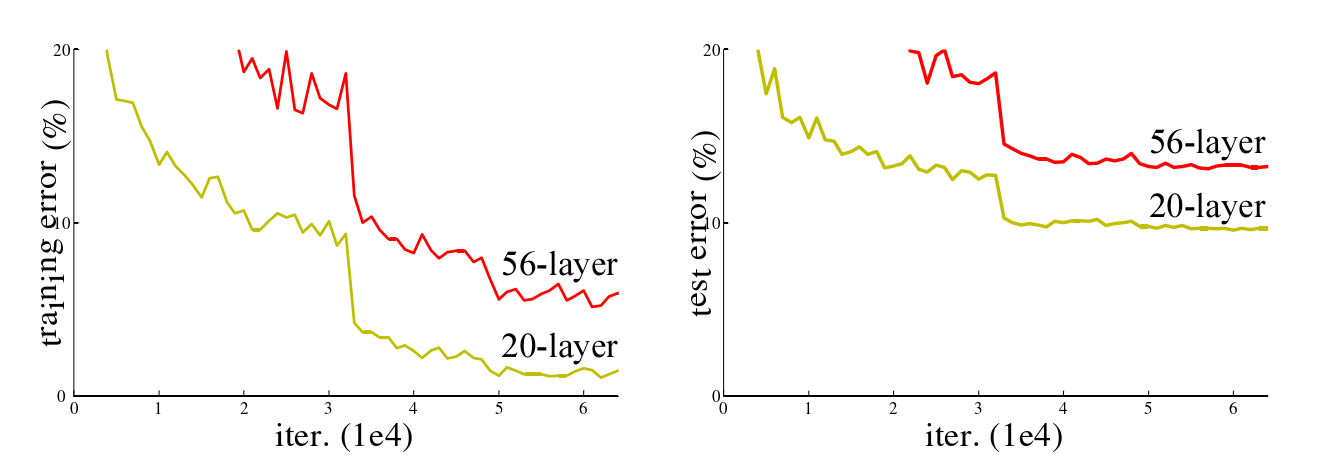
图1 不同深度的神经网络的训练误差和测试误差
如图1 所示,CIFAR-10 在 20 层和 56 层 "plain" 网络上的训练误差(左)和测试误差(右)。较深的网络有较高的训练误差和测试误差。
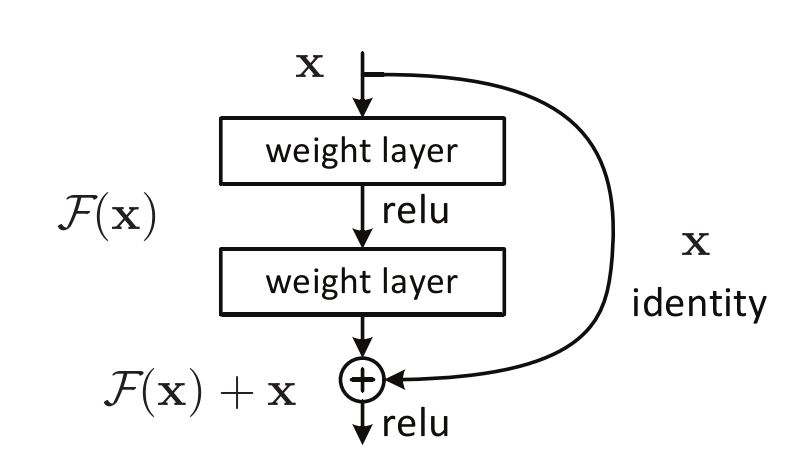
图2 残差块
在本文中,我们通过引入一个深度残差学习框架来解决退化问题。我们不希望每几个堆叠层直接拟合一个期望的底层映射,而是显式地让这些层拟合一个残差映射。
在形式上,我们将期望的底层映射记为 H ( x ),并令叠加的非线性层拟合 F ( x ) 的另一个映射: H ( x ) - x。原始映射被重铸成 F ( x ) + x。
我们假设-优化残差映射-比-优化原始的和未引用的映射-更容易。在极端情况下,如果一个恒等映射是最优的,那么将-残差推到零-比-通过一堆非线性层-拟合一个恒等映射更容易。
补充:对任意集合A,如果映射 f : A→A 定义为 f(a)=a,即规定 A 中每个元素 a 与自身对应,则称 f 为 A 上的恒等映射(identical mapping)。
F ( x ) + x 的表达式可以通过具有"捷径连接"的前馈神经网络来实现( 图2 )。快捷方式连接是那些跳过一个或多个层的连接。在我们的例子中,快捷方式连接只执行恒等映射(identity mapping),它们的输出被添加到堆叠层的输出中( 图2 )。特征捷径连接既不增加额外的参数,也不增加计算复杂度。整个网络仍然可以通过反向传播的SGD进行端到端的训练,并且可以很容易地使用公共库《Caffe: Convolutional architecture forfast feature embedding》实现,无需修改求解器。
补充:Caffe(Convolutional Architecture for Fast Feature Embeddi)是一个深度学习框架,最初开发于加利福尼亚大学伯克利分校。Caffe在BSD许可下开源,使用C++编写,带有Python接口。是贾扬清在加州大学伯克利分校攻读博士期间创建了Caffe项目。项目托管于Github,拥有众多贡献者。Caffe应用于学术研究项目、初创原型甚至视觉、语音和多媒体领域的大规模工业应用。雅虎还将Caffe与Apache Spark集成在一起,创建了一个分布式深度学习框架CaffeOnSpark。2017年4月,Facebook发布Caffe2,加入了递归神经网络等新功能。2018年3月底,Caffe2并入PyTorch。
我们在 ImageNet 上提供了全面的实验来展示退化问题并评估我们的方法。我们表明:
- 我们的极深残差网络很容易优化,但对应的"普通"网络(即简单的堆叠层数)在深度增加时表现出更高的训练误差;
- 我们的深度残差网络可以很容易地从大幅增加的深度中获得精度增益,产生的结果明显优于以前的网络。
- 类似的现象也出现在CIFAR - 10数据集上,这表明我们的方法的优化困难和效果并不只是类似于特定的数据集。我们在这个超过100层的数据集上展示了成功训练的模型,并探索了超过1000层的模型。
在 ImageNet 分类数据集上,我们通过极深的残差网络获得了极好的结果。我们的152层残差网络是ImageNet上有史以来最深的网络,但仍比VGGnets具有更低的复杂度。我们的集成在ImageNet 测试集上有3.57 %的 top - 5 误差,并在 ILSVRC2015 分类竞赛中获得第一名。极深的表示在其他识别任务上也具有出色的泛化性能,并使我们在 ILSVRC 和 COCO 2015 竞赛中进一步赢得了第1名:ImageNet检测、ImageNet定位、COCO检测和COCO分割。这有力的证据表明,残差学习原理具有一般性,我们预期它在其他视觉和非视觉问题中也适用。
三、深度残差学习
(1)残差学习
让我们考虑H( x )作为一个底层映射,它适合于几个堆叠层(不一定是整个网络),其中x表示这些层中第一个层的输入。如果假设多个非线性层可以渐近逼近复杂函数(注),则等价于假设它们可以渐近逼近残差函数F(x),即H ( x ) -x (假设输入和输出具有相同的量纲)。而不是期望堆叠层接近H(x),我们明确地让这些层接近一个残差函数F ( x ):= H ( x ) - x。因此,原函数变为F ( x ) + x。虽然这两种形式都应该能够渐近地接近期望的函数 (作为假设) ,学习的容易程度可能不同。
注:然而,这一假设仍然是一个悬而未决的问题《On the number oflinear regions of deep neural networks》
这种重新表述的动机是关于退化问题(图1 ,左)的反直觉现象。正如我们在摘要中所讨论的那样,如果所添加的层可以构造为恒等映射,那么更深的模型应该具有不大于其较浅的对应部分的训练误差。退化问题表明,求解器可能在多个非线性层的近似恒等映射中存在困难。通过残差学习重新建模,如果恒等映射是最优的,求解器可以简单地将多个非线性层的权重驱动到零,以接近恒等映射。
在现实中,恒等映射不太可能是最优的,但我们的重新表述可能有助于问题的前提化。如果最优函数更接近恒等映射而不是零映射,那么求解器应该更容易找到与恒等映射相关的扰动,而不是将函数作为新的函数来学习。我们通过实验表明( 下图所示 ),学习到的残差函数通常具有较小的响应,这表明恒等映射提供了合理的预条件。
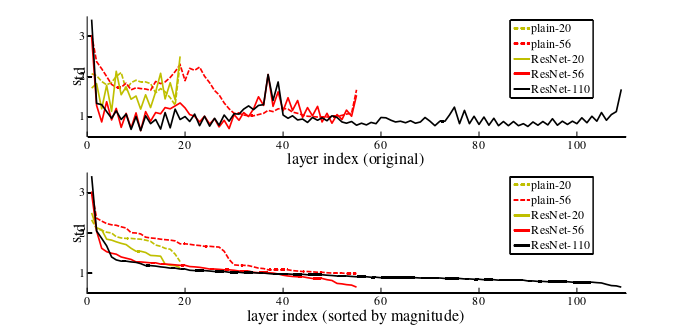
图XXX CIFAR - 10的层响应标准差( std )。响应是每个3 × 3层的输出,在BN之后和非线性之前。
- 顶部:图层以其原始顺序显示。
- 底部:响应按降序排列。
上图显示了层响应的标准差( std )。响应是每个3 × 3层的输出,在BN之后和其他非线性( ReLU / add )之前。对于深度残差网络,此分析揭示了残差函数的响应强度。从上图可以看出,深度残差网络的响应值普遍小于其对应的平原地区。这些结果支持我们的基本动机( 残差学习 ),即残差函数通常比非残差函数更接近于零。我们还注意到更深的ResNet具有更小的响应数量,上图中ResNet - 20、56和110之间的比较证明了这一点。当有更多层时,深度残差网络的单个层倾向于更少地修改信号。
补充:标准差是方差的算术平方根。标准差能反映一个数据集的离散程度。
(2)Identity Mapping by Shortcuts(快捷连接的恒等映射)
图2 残差块(为了方便观察,复制到此处)
我们对每几个堆叠层采用残差学习。a building block 如图2 所示。正式地,在本文中,我们考虑定义为的 a building block:
y =F(x,{Wi}) + x
这里 x 和 y 是所考虑层的输入和输出向量。函数 F(x, { Wi }) 表示要学习的残差映射。对于有两层的图2 中的例子,,其中 σ 表示ReLU,为了简化符号,省略了偏见(biases)。操作 F + x 通过一个捷径连接和逐元素相加来执行。我们采用加法后的第二种非线性 (即,σ(y), see Fig. 2)。
y =F(x,{Wi}) + x 式中的捷径连接, 既不引入额外参数,也不引入计算复杂性。这不仅在实践中很有吸引力,而且在我们比较普通网络和残差网络时也很重要。我们可以公平地比较同时具有相同数量的参数、深度、宽度和计算成本(除了可忽略的逐元加法外)的普通/残差网络。
在等式 y =F(x,{Wi}) + x 中 x 和 F 的维数必须相等。如果不是这种情况(例如,当改变输入/输出通道时),我们可以执行一个线性投影 Ws 通过捷径连接来匹配尺寸:
y =F(X,{Wi}) + WsX
我们也可以在 y =F(x,{Wi}) + x 中使用方阵 Ws。但是我们将通过实验表明,identity mapping 对于解决退化问题是足够的,并且是经济的,因此 Ws 只在匹配维度时使用。
残差函数 F 的形式是复杂的。本文的实验涉及一个函数F,它有两个或三个层( 图5 ),而更多的层是可能的。但如果F只有单层,则有 y =F(x,{Wi}) + x 类似于一个线性层:y = W1x + x,对此我们没有观察到优势。
(3)网络架构(Plain Network and Residual Network)
Plain Network 我们的普通基线(图3 middle)主要受到VGG网[ 41 ] (图3 left)哲学的启发。卷积层大多具有3 × 3的滤波器,并遵循两个简单的设计规则:( i )对于相同的输出特征图大小,各层具有相同数量的滤波器;( ii )如果特征图尺寸减半,则滤波器的数量增加一倍,以保持每层的时间复杂度。我们通过步幅为 2 的卷积层直接进行下采样。网络以全局平均池化层和带有softmax的 1000-way 全连接层结束。图3 (middle)中总加权层数为34层。
值得注意的是,我们的模型比VGG网络(图3 left)具有更少的过滤器和更低的复杂度。我们的34层 baseline 有36亿FLOPs (multiply-adds),这只是VGG-19 ( 196亿FLOPs)的18%。
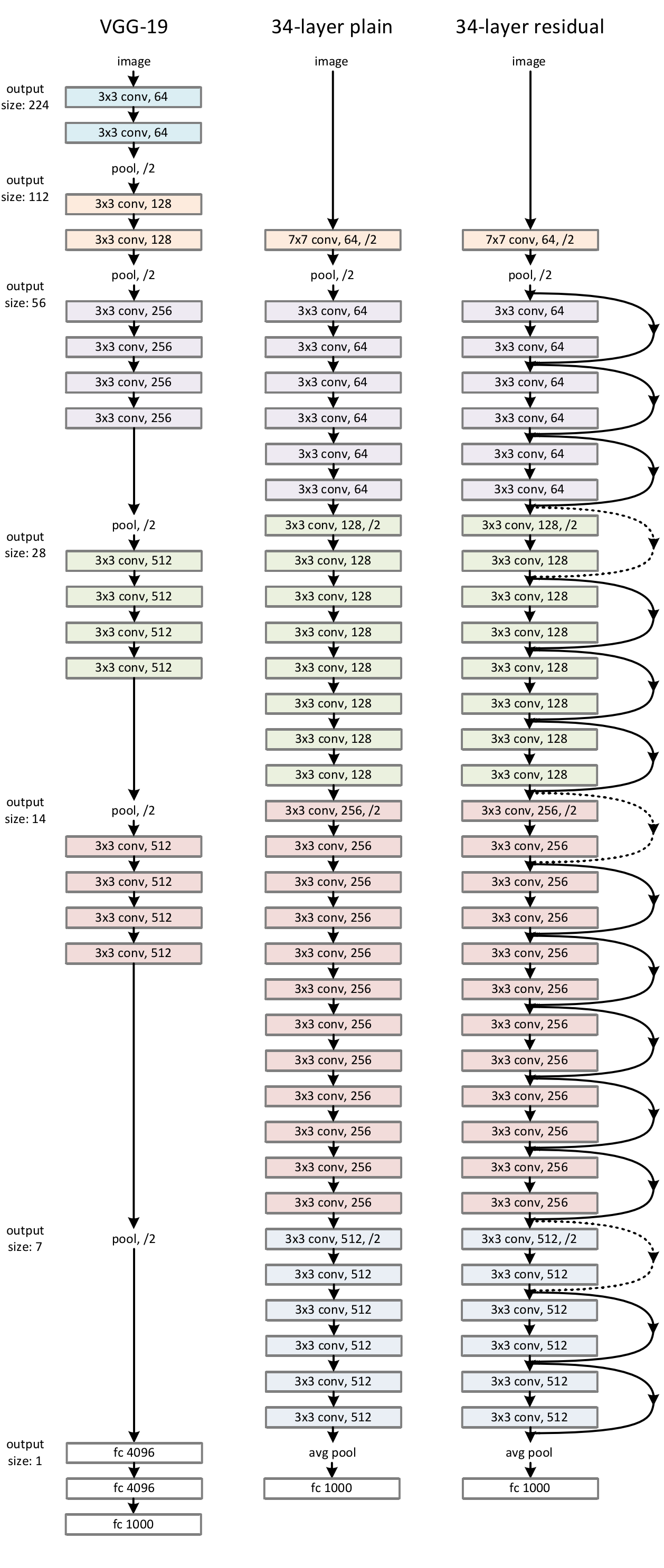
图3 ImageNet的网络架构示例。
- 左:VGG - 19型号( 196亿FLOPs)作为参考。
- 中间:34个参数层( 36亿FLOPs)的平面网络(Plain Network)。
- 右:一个具有34个参数层的残差网络( 36亿FLOPs)。虚线的快捷方式增加了尺寸。
表1 显示了更多的细节和其他变量。 Building Blocks 显示在括号中,其堆叠的块数在括号外面。降采样由conv3 _ 1、conv4 _ 1和conv5 _ 1以 2 的步长进行。
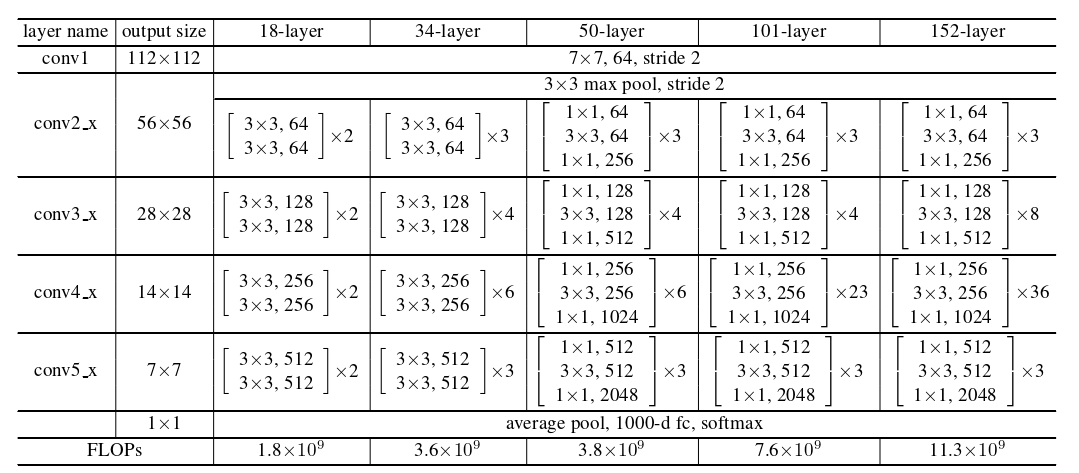
表1 Imagenet架构
Residual Network. 基于上面的普通网络,我们插入快捷方式连接(图3 ,右),它将网络转换成对应的残差版本。The identity shortcuts ( y =F(x,{Wi}) + x ) :
- 在输入和输出具有相同维数 (图3中的实线快捷方式) 时可以直接使用。
- 当维度增加 (虚线快捷方式图3) 时,我们考虑两个选项:
( A )快捷方式仍然执行 identity shortcuts,并添加额外的零项以增加维度。此选项不引入任何额外参数;
( B ) y =F(X,{Wi}) + WsX 中的投影捷径。 用于匹配维度(通过1 × 1卷积完成)。
总结:对于这两个选项,当快捷方式跨越两个大小的恒等映射时,它们以 2 的步幅执行。
即,
实线部分,输入输出维度相同,用公式:y =F(x,{Wi}) + x
虚线部分,输入输出维度不同,选用下面两种方法的一种:
- (A)依然用公式:y =F(x,{Wi}) + x,并添加额外的零项以增加维度。
- (B)用公式:y =F(X,{Wi}) + WsX (通过1 × 1卷积完成)
(4)实现的细节
- 我们对ImageNet的实现遵循了[ 21、41]中的实践。
- 在[ 256、480]中对图像的较短边进行随机取样,以调整图像大小,以进行缩放[ 41 ]。
- 从一幅图像或其水平翻转中随机采样一个224 × 224的作物,并减去每个像素的均值[ 21 ]。
- 使用了[ 21 ]中的标准颜色增强。
- 我们采用批归一化( batchnormalization,BN ),在每次卷积之后和激活之前,遵循[ 16 ]。
- 我们在[ 13 ]中初始化权重,并从头开始训练所有普通/残差网络。
- 我们使用的SGD的 mini-batch size 为256。
- 学习率从0.1开始,当误差平稳时除以10,模型被训练到
个迭代。
- 我们使用0.0001的权重衰减和0.9的动量。
- 遵循[ 16 ]中的做法,我们不使用dropout [ 14 ]。
[13] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into rectifiers:Surpassing human-level performance on imagenet classification. InICCV, 2015.
[14] G. E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, andR. R. Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv:1207.0580, 2012.
[16] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deepnetwork training by reducing internal covariate shift. In ICML, 2015.
[21] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classificationwith deep convolutional neural networks. In NIPS, 2012.
[41] K. Simonyan and A. Zisserman. Very deep convolutional networksfor large-scale image recognition. In ICLR, 2015.
四、不同网络之间的比较

图4 Training on ImageNet
- 细曲线表示训练误差,粗曲线表示 center crops 的验证误差。
- 左:18和34层的平面网络。
- 右:18和34层的深度残差网络。
- 在这个图中,残差网络与它们的普通网络相比没有额外的参数。
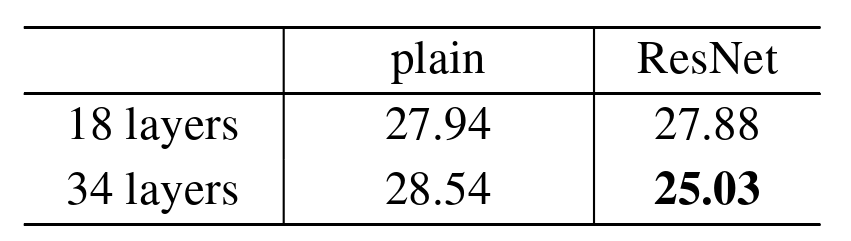
表2 Top-1 error (%, 10-crop testing) on ImageNet validation
在这里,深度残差网络和 Plain 网络相比,没有额外的参数。训练过程如图4所示。
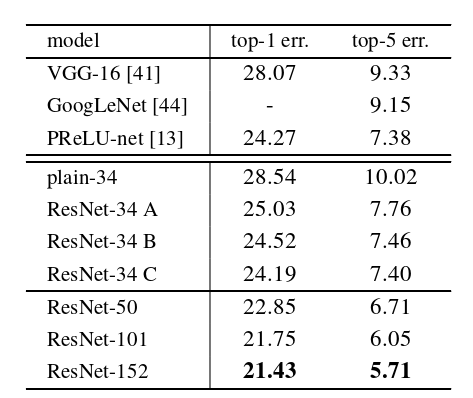
Table 3. Error rates (%, 10-crop testing) on ImageNet validation
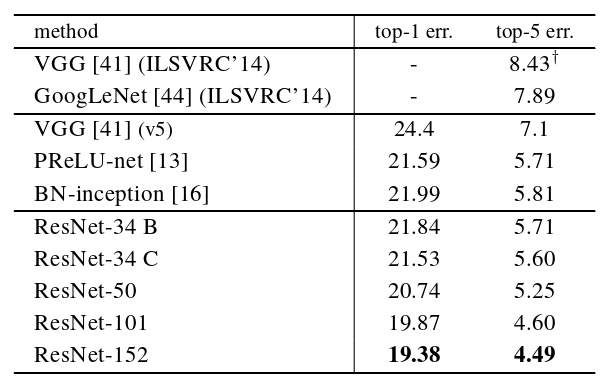
Table 4. Error rates (%) of single-model results on the ImageNetvalidation set
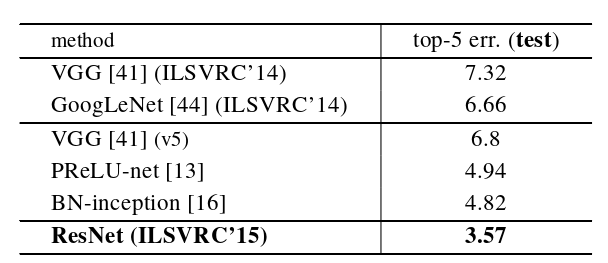
Table 5. Error rates (%) of ensembles
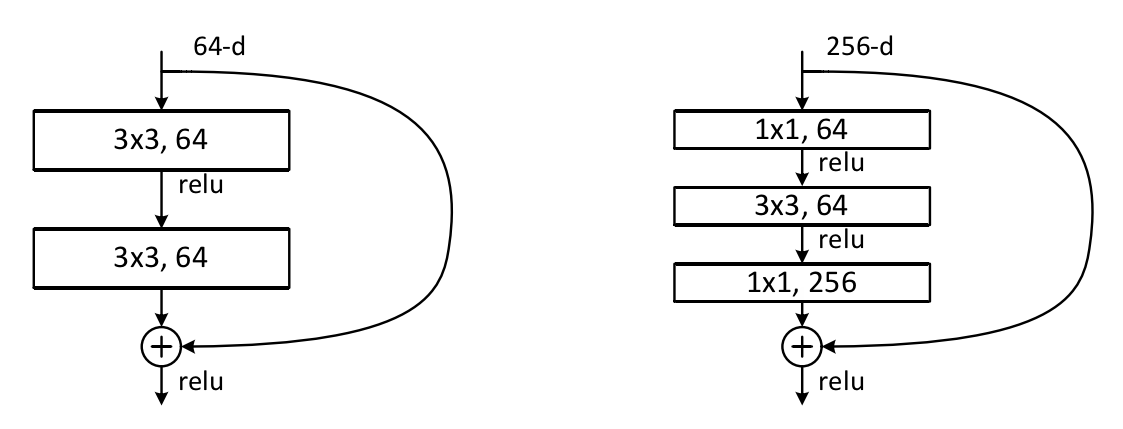
图5 ImageNet的更深层的残差函数 F
- 左边:Buildings stocks(在56 × 56的特征图上),如图3 中的ResNet - 34。
- 右边:ResNet-50 / 101 / 152 的"瓶颈"Buildings stocks。

表6 在CIFAR - 10测试集上的分类误差
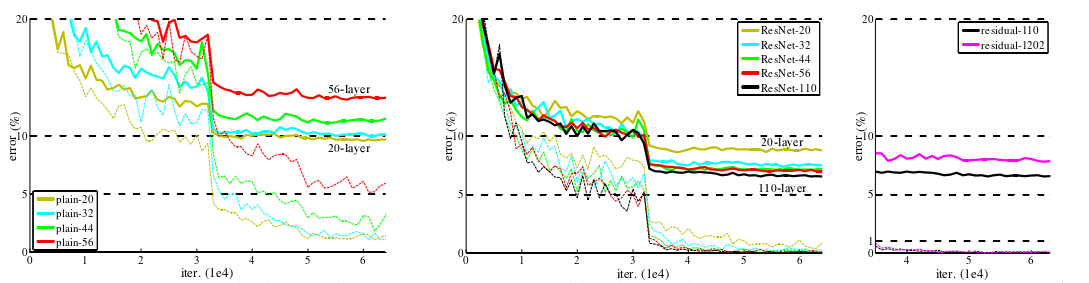
图6 Training on CIFAR-10
虚线表示训练误差,粗线表示测试误差。
- 左:平原网络(Plain Network)。Plain- 110 的误差高于 60% 且未显示。
- 中间:深度残差网络。(一定范围内,网络越深,错误率越低)
- 右:深度残差网络与110和1202层。(证明网络深度也有限度)
>>>day day up!

