
- 1Linux环境使用VSCode调试简单C++代码_linux vscode c++
- 2详解MAC帧、ARP、DNS、ICMP协议_dns帧
- 3添加两个按钮_android如何添加两个按钮
- 4Json解析的三种方式_jsonobject json = new jsonobject();json.entryset()
- 5Python 基于循环神经网络的情感分类系统设计与实现,附可视化界面._基于python的博客情感分析系统的设计与实现
- 6简单的广播发送与接收_编写一个程序,实现无序广播的发送和接收
- 7AI绘图提示词/咒语/词缀/关键词使用指南(Stable Diffusion Prompt 设计师操作手册)_easynegative
- 8win11 环境配置 之 Jmeter(JDK17版本)
- 9文献 | fMRI入门指南_如何自学任务态fmri
- 10Creo 二次开发-尺寸位置排序算法_creo二次开发 招聘
客服机器人源码_快速搭建对话机器人,就用这一招!
赞
踩

问答系统是自然语言处理领域一个很经典的问题,它用于回答人们以自然语言形式提出的问题,有着广泛的应用。其经典应用场景包括:智能语音交互、在线客服、知识获取、情感类聊天等。常见的分类有:生成型、检索型问答系统;单轮问答、多轮问答系统;面向开放领域、特定领域的问答系统。本文涉及的主要是在检索型、面向特定领域的问答系统,通常称之为——智能客服机器人。
在过去,客服机器人的搭建通常需要将相关领域的知识(Domain Knowledge),转化为一系列的规则和知识图谱。构建过程中重度依赖“人工”智能,换个场景,换个用户都需要大量的重复劳动。
随着深度学习在自然语言处理(NLP)中的应用,机器阅读可以直接自动从文档中找到匹配问题的答案。深度语言模型会将问题和文档转化为语义向量,从而找到最后的匹配答案。本文借助Google开源的Bert模型结合Milvus开源向量搜索引擎,快速搭建基于语义理解的对话机器人。
| 整体架构
本文通过语义相似度匹配来实现一个问答系统,大致的构建过程:
- 获取某一特定领域里大量的带有答案的中文问题(本文将之称为标准问题集)。
- 使用Bert模型将这些问题转化为特征向量存储在Milvus中,同时Milvus将 给这些特征向量分配一个向量ID。
- 将这些代表问题的ID和其对应的答案存储在PostgreSQL中。
当用户提出一个问题时:
- 通过Bert模型将之转化为特征向量
- 在Milvus中对特征向量做相似度检索,得到与该问题最相似的标准问题的id
- 在PostgreSQL得出对应的答案。
系统架构图如下(蓝色线是导入过程,黄色线是查询过程):
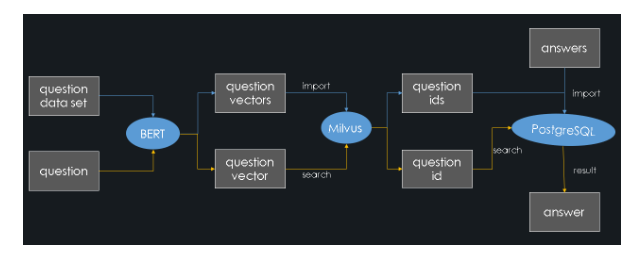
接下来,将手把手教您搭建一个在线问答系统。
| 搭建步骤
在搭建之前您需要安装Milvus、Postgresql,具体安装步骤请参考官网。
1.数据准备
本文中的实验数据来自:https://github.com/SophonPlus/ChineseNlpCorpus。
该项目下的FAQ问答系统中的金融数据集,我们从中一共整理了33万条数据。结合这组数据,我们可以快速搭建一个xx银行智能客服机器人。
2.生成特征向量
本系统使用了Bert已预训练好的一个模型。在启动服务前,需要下载该模型:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
使用该模型将问题库转化为特征向量,以用于后续的相似度检索。更多bert服务相关可参考:https://github.com/hanxiao/bert-as-service

3.导入Milvus和PostgreSQL
将上述产生的特征向量归一化处理后导入Milvus中存储,然后j将Milvus返回的id以及该id对应的问题的答案导入PostgreSQL中。PostgreSQL中的表结构:
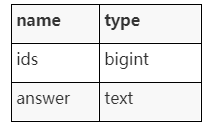

4.获取答案
用户输入一个问题,通过Bert产生特征向量后,在Milvus库中找出与之最相似的一个问题。本文采用的余弦距离来表示两个句子间的相似度,由于所有向量都进行了归一化,因此两个特征向量的余弦距离越接近1表示相似度也高越高。库中可能没有与用户给定问题比较相似的问题,所以在实践中我们可以设定了一个阈值0.9,当检索出来的最相似的距离小于该阈值时,则返回本系统未收录相关问题的提示。

| 系统演示
系统初始界面如下:
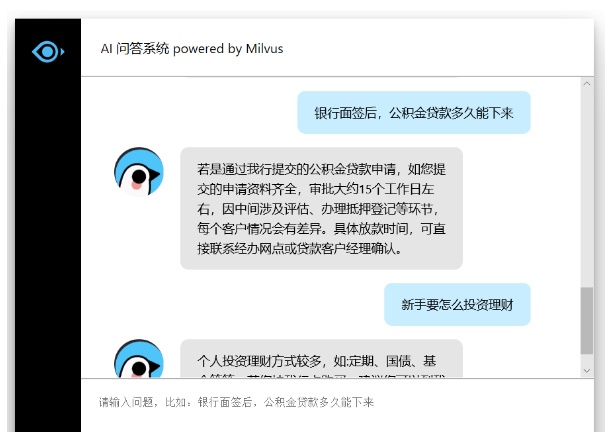
在对话框中输入你的问题,将会收到对应的答案。如图:
| 总结
上述的问答系统搭建是不是很简单?有Bert模型的加持,你根本不需要预先对语料进行分类整理、标签化等工作。同时,得益于开源向量搜索引擎Milvus的高性能和可扩展性,系统可以支撑上亿级别的语料库。Milvus向量搜索引擎已经加入Linux AI (LF AI)基金会进行孵化,欢迎大家加入Milvus社区。让我们一起加速AI技术的大规模落地。
系统演示:https://milvus.io/cn/scenarios
详细步骤(附代码):
https://github.com/milvus-io/bootcamp/tree/0.7.0/solutions/QA_Systemgithub.com*原文来源:https://mp.weixin.qq.com/s/nHsg8Iu8BkMeiRCRoPr7ew
想让 Milvus 手把手教你如何搭建智能问答机器人吗?现在就报名4/23 晚上7点的直播喔!
利用Bert和Milvus快速搭建智能问答机器人 www.huodongxing.com
| 欢迎加入 Milvus 社区
http://github.com/milvus-io/milvus | 源码
http://milvus.io | 官网
http://milvusio.slack.com | Slack 社区
http://zhihu.com/org/zilliz-11/columns | 知乎
http://zilliz.blog.csdn.net | CSDN 博客


