
- 1【鸿蒙开发】配置文件中添加权限_鸿蒙arkts 权限
- 2GitHub如何生成密钥_git hub ssl密钥生成
- 3uniapp开发 h5实现复制到剪贴板功能_h5 粘贴板
- 4宇视 VM 平台通过 onvif 协议添加的相机离线问题_宇视添加海康摄像头显示离线
- 5【大模型--- 量化与微调的原理、区别】_微调之后的模型可以量化吗
- 6多系统引导
- 7【NLP】多标签分类【上】_用br和cc算法进行多标签分类
- 8SRC漏洞挖掘--CNVD国家信息安全漏洞共享平台
- 9Ubuntu20.04下cuda、cudnn、paddle安装的完整过程_ubuntu20.04安装cuda
- 10【Devc++】8款经典小游戏_c++游戏
【大厂AI课学习笔记NO.54】2.3深度学习开发任务实例(7)数据标注和数据集拆分_深度学习数据集标注
赞
踩
数据标注
有时我们会把特征工程和数据集的标注弄混淆,在普通的机器学习项目中,我们需要进行特征工程,但是在深度学习项目过程中,我们需要进行数据标注工作。
标注工具
在本案例中,使用的是开源的标注工具Labelme,生成格式为yolo格式的标准文件。
在人工智能的深度学习项目中,数据标注是一个非常重要的环节,它涉及到将原始数据转化为机器学习算法可以理解和学习的形式。下面是一些常用和重要的开源数据标注工具,以及它们的使用方式、重要步骤和数据格式。
- LabelImg
LabelImg是一个图形图像标注工具,它支持多种标注形式,包括矩形框、多边形、线段、关键点等。使用LabelImg进行标注的步骤大致如下:
(1)导入图像数据:将需要标注的图像数据导入到LabelImg中。
(2)创建标注任务:设置标注任务的名称、描述、标签等信息。
(3)进行标注:使用LabelImg提供的标注工具对图像进行标注。
(4)导出标注数据:将标注数据导出为特定格式的文件,如PASCAL VOC、YOLO等。
LabelImg支持的数据格式包括PASCAL VOC、YOLO、COCO等,这些格式都是深度学习领域常用的数据格式。
- VIA (VGG Image Annotator)
VIA是VGG发布的图像标注工具,它支持对象检测、图像语义分割和实例分割等标注任务。使用VIA进行标注的步骤大致如下:
(1)上传图像数据:将需要标注的图像数据上传到VIA的服务器上。
(2)创建标注项目:设置标注项目的名称、描述、标签等信息。
(3)进行标注:使用VIA提供的标注工具对图像进行标注。
(4)导出标注数据:将标注数据导出为JSON格式的文件。
VIA支持的数据格式为JSON,其中包含了图像的元数据、标注信息和标签等信息。
- CVAT (Computer Vision Annotation Tool)
CVAT是一个高效的计算机视觉标注工具,它支持图像分类、对象检测、图像语义分割、实例分割等多种标注任务。使用CVAT进行标注的步骤大致如下:
(1)上传图像数据:将需要标注的图像数据上传到CVAT的服务器上。
(2)创建标注任务:设置标注任务的名称、描述、标签等信息。
(3)进行标注:使用CVAT提供的标注工具对图像进行标注。CVAT支持多人协作标注,可以提高标注效率。
(4)导出标注数据:将标注数据导出为特定格式的文件,如COCO、PASCAL VOC等。
CVAT支持的数据格式包括COCO、PASCAL VOC、YOLO等,这些格式都是深度学习领域常用的数据格式。此外,CVAT还支持视频数据标注和本地部署,可以满足更多的需求。
对于以上这些工具,使用方式都相对直观,一般都会有详细的用户指南和教程可供参考。在使用过程中,需要注意的是要保证标注的准确性和一致性,这样才能训练出高质量的深度学习模型。同时,对于大规模的数据标注任务,可以考虑使用多人协作的方式进行标注,以提高效率。
此外,有2个标准工具,LabelImg和Labelme,我们常弄混淆。
LabelMe和LabelImg是两个不同的图像标注工具,它们各自具有独特的特点和功能。
LabelMe是由麻省理工学院(MIT)的计算机科学和人工智能实验室(CSAIL)研发的图像标注工具。它主要用于创建计算机视觉和机器学习应用所需的标记数据集,支持多种标注类型,如矩形框、多边形、圆形、多段线、线段、点等,可以用于目标检测、图像分割等任务。此外,LabelMe还可以用于视频标注,生成VOC格式和COCO格式的数据集。它的源代码已经开源,并且可以在服务器上安装使用,是一个在线的Javascript图像标注工具,可以在任意地方使用,不需要在电脑中安装大型数据集。
LabelImg也是一款开源的图像标注工具,它的标签可用于分类和目标检测,其注释以PASCAL VOC格式保存为XML文件。它使用Python编写,并使用QT作为其图形界面。
主要区别如下:
- 开发背景:LabelMe由知名的麻省理工学院(MIT)的计算机科学和人工智能实验室(CSAIL)研发,而LabelImg则可能由不同的开发团队或组织开发。
- 功能和用途:虽然两者都用于图像标注,但LabelMe支持更多的标注类型,并且可以用于视频标注,而LabelImg则更专注于图像分类和目标检测任务。
- 数据格式:LabelMe可以生成VOC格式和COCO格式的数据集,而LabelImg的注释则以PASCAL VOC格式保存为XML文件。
- 使用方式:LabelMe是一个在线的Javascript图像标注工具,可以在任意地方使用,而LabelImg则是基于Python和QT的桌面应用程序。
总的来说,LabelMe和LabelImg虽然都是图像标注工具,但它们在开发背景、功能和用途、数据格式以及使用方式等方面存在一些差异。选择哪个工具取决于具体的项目需求和个人偏好。
这2个文件,都支持使用yolo格式来存储文件,我们在本案例中,也选择这个文件格式。
在YOLO的标注文件中,通常会包含以下几个部分:
-
图像文件:这些是原始的图像文件,通常以JPEG或PNG格式存储。
-
标注文件:对于每个图像,都会有一个与之对应的标注文件,通常以
.txt为扩展名。这个文件包含了图像中每个对象的边界框坐标和类别ID。在YOLO格式中,这个文件的每一行代表一个对象,包含以下信息:对象类别ID、对象的中心点x坐标、对象的中心点y坐标、对象的宽度、对象的高度。这些信息都是相对于图像的宽度和高度的比例值,并且是按空格分隔的浮点数。 -
classes.txt:这个文件包含了数据集中所有类别的列表,每个类别占一行。这个文件用于将类别ID映射到实际的类别名称。例如,如果
classes.txt中的内容是:personbicyclecar...那么类别ID 0就对应着"person",类别ID 1对应着"bicycle",以此类推。
在开源工具中,能够处理YOLO格式的工具很多,但具体哪一个工具生成了包括classes.txt的YOLO格式标注文件并不是由文件格式本身决定的,而是由使用该工具的用户或开发者决定的。许多标注工具都支持导出为YOLO格式,同时附带一个classes.txt文件来指明类别。
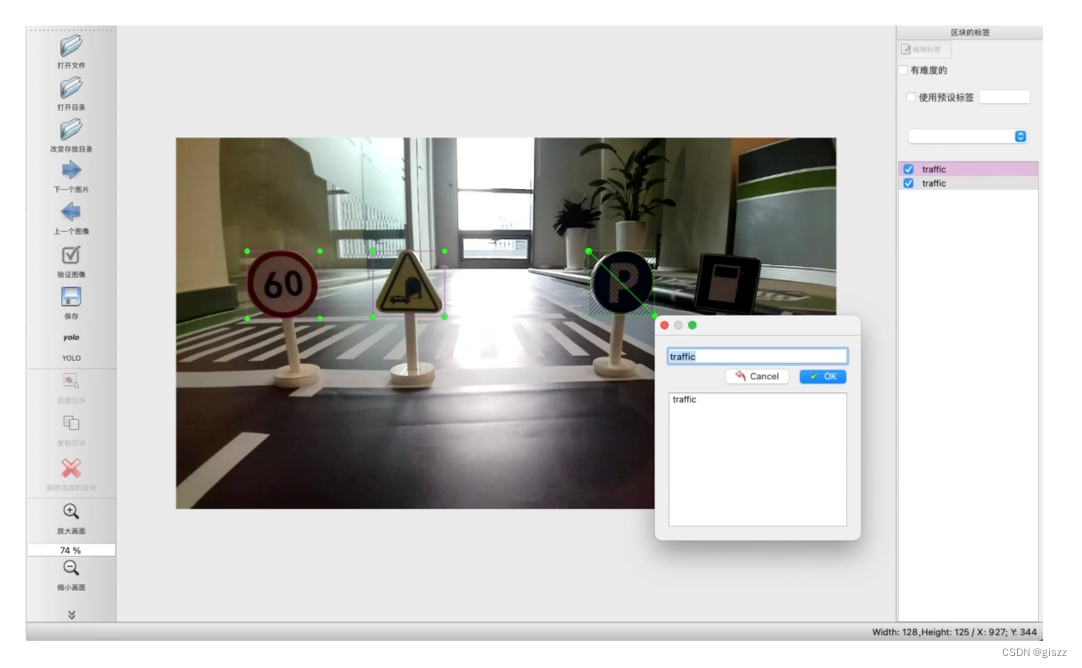
我们存储为的格式是:
 标注文件每行表示一个矩形框;含义分别是:类别编号、中心点x坐标、中心点y坐标、框体宽度、框体高度;数值是根据图片宽高归一化后的数据,所以是0~1之间的小数。
标注文件每行表示一个矩形框;含义分别是:类别编号、中心点x坐标、中心点y坐标、框体宽度、框体高度;数值是根据图片宽高归一化后的数据,所以是0~1之间的小数。
classes.txt:存放标注的所有类别。本案例中,做了简化,就是traffic一个类别。
抽查
抽查比例由具体任务决定,由于本案中的检测任务较为简单,我们抽查1%,即 100 张。
数据集拆分
将所有数据按照8:2的比例拆分为训练集(8000张)与测试集(2000张)。注意标注文件也应当对应拆。
训练集将提供跟算法组用于模型训练,测试集将提供给测试组用于验证数据的泛化效果。
要用随机采样的方式划分,确保独立。
2个集,不要有1张重合的。这是非常重要的概念。本认证考试中,也特意有这样的考题。
(待续)

