
- 1【STL】reverse_iterator反向迭代器的实现
- 2深入探索MySQL:成本模型解析与查询性能优化
- 3Java8新特性--lambda表达式
- 4IP报文头部详解_ip报文头部字段
- 5nacos注册服务及集成seata踩坑记录(No available service)
- 6动手学深度学习(四十三)——机器翻译及其数据构建_结合机器翻译构建
- 7SLAM的现在与未来_lsd-slam的主要优点
- 8Nginx访问FastDfs的文件_kkfileview fastdfs
- 9如何快速而准确地进行 IP 和端口信息扫描:渗透测试必备技能_ip端口扫描
- 10复旦大学NLP团队发布86页大模型Agent综述_复旦大学《基于大型语言模型的agent的兴起和潜力:综述》
优化AI生命周期:k8s下大模型部署的新选择!
赞
踩
前言
AI 商业化的时代,大模型推理训练会被更加广泛的使用。比较理性的看待大模型的话,一个大模型被训练出来后,无外乎两个结果,第一个就是这个大模型没用,那就没有后续了;另一个结果就是发现这个模型很有用,那么就会全世界的使用,这时候主要的使用都来自于推理,不论是 openAI 还是 midjourney,用户都是在为每一次推理行为付费。随着时间的推移,模型训练和模型推理的使用比重会是三七开,甚至二八开。应该说模型推理会是未来的主要战场。
大模型推理是一个巨大的挑战,它的挑战体现在成本、性能和效率。其中成本最重要,因为大模型的成本挑战在于模型规模越来越大,使用的资源越来越多,而模型的运行平台 GPU 由于其稀缺性,价格很昂贵,这就导致每次模型推理的成本越来越高。而最终用户只为价值买单,而不会为推理成本买单,因此降低单位推理的成本是基础设施团队的首要任务。
在此基础上,性能是核心竞争力,特别是 ToC 领域的大模型,更快的推理和推理效果都是增加用户粘性的关键。
应该说大模型的商业化是一个不确定性较高的领域,成本和性能可以保障你始终在牌桌上。效率是能够保障你能在牌桌上赢牌。
进一步,效率。模型是需要持续更新,这就模型多久可以更新一次,更新一次要花多久的时间。谁的工程效率越高,谁就有机会迭代出有更有价值的模型。

近年来,容器和 Kubernetes 已经成为越来越多 AI 应用首选的运行环境和平台。一方面,Kubernetes 帮助用户标准化异构资源和运行时环境、简化运维流程;另一方面,AI 这种重度依赖 GPU 的场景可以利用 K8s 的弹性优势节省资源成本。在 AIGC/大模型的这波浪潮下,以 Kubernetes 上运行 AI 应用将变成一种事实标准。
--- 节选自《云原生场景下,AIGC 模型服务的工程挑战和应对》
大模型训练和推理
大模型训练和推理是机器学习和深度学习领域的重要应用,但企业和个人往往面临着GPU管理复杂、资源利用率低,以及AI作业全生命周期管理中工程效率低下等挑战。本方案通过创建kubernetes集群,使用kserve+vLLM部署推理服务。适用于机器学习和深度学习任务中的以下场景:
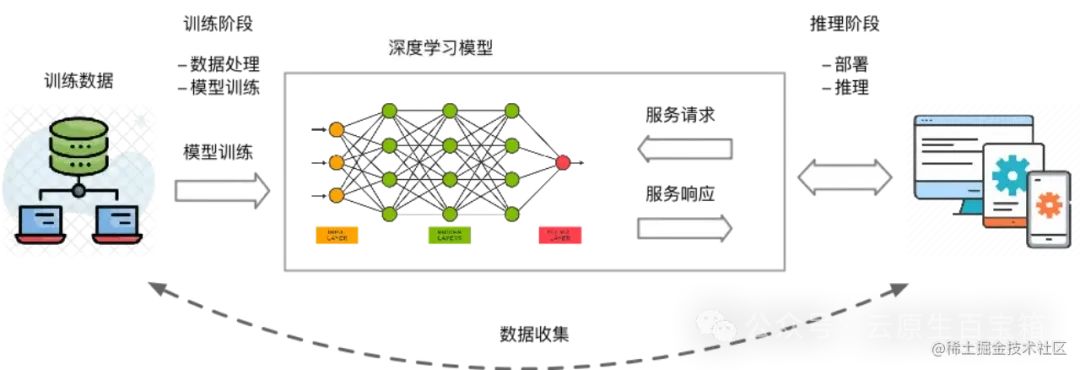
• 模型训练:基于Kubernetes集群微调开源模型,可以屏蔽底层资源和环境的复杂度,快速配置训练数据、提交训练任务,并自动运行和保存训练结果。
• 模型推理:基于Kubernetes集群部署推理服务,可以屏蔽底层资源和环境的复杂度,快速将微调后的模型部署成推理服务,将模型应用到实际业务场景中。
• GPU共享推理:支持GPU共享调度能力和显存隔离能力,可将多个推理服务部署在同一块GPU卡上,提高GPU的利用率的同时也能保证推理服务的稳定运行。
VLLM介绍
即使在高端 GPU 上,提供 LLM 模型的速度也可能出奇地慢,vLLM[1]是一种快速且易于使用的 LLM 推理引擎。它可以实现比 Huggingface 变压器高 10 倍至 20 倍的吞吐量。它支持连续批处理[2]以提高吞吐量和 GPU 利用率, vLLM支持分页注意力[3]以解决内存瓶颈,在自回归解码过程中,所有注意力键值张量(KV 缓存)都保留在 GPU 内存中以生成下一个令牌。
vLLM 是一个快速且易于使用的 LLM 推理和服务库。
vLLM 的速度很快:
• 最先进的服务吞吐量
• 使用PagedAttention高效管理注意力键和值内存
• 连续批处理传入请求
• 使用 CUDA/HIP 图快速执行模型
• 量化:GPTQ[4]、AWQ[5]、SqueezeLLM[6]、FP8 KV 缓存
• 优化的 CUDA 内核
vLLM 灵活且易于使用:
• 与流行的 HuggingFace 模型无缝集成
• 高吞吐量服务与各种解码算法,包括并行采样、波束搜索等
• 对分布式推理的张量并行支持
• 流输出
• 兼容 OpenAI 的 API 服务器
• 支持 NVIDIA GPU 和 AMD GPU
• (实验性)前缀缓存支持
• (实验性)多lora支持
kserve介绍
KServe是一个针对 Kubernetes 的自定义资源,用于为任意框架提供机器学习(ML)模型服务。它旨在为常见 ML 框架(如TensorFlow、XGBoost、ScikitLearn、PyTorch 和 ONNX)的提供性高性能、标准化的推理协议,解决生产模型服务的使用案例。
KServe提供简单的Kubernetes CRD,可用于将单个或多个经过训练的模型(例如TFServing、TorchServe、Triton等推理服务器)部署到模型服务运行时。
KServe封装了自动扩展、网络、健康检查和服务器配置的复杂性,为 ML 部署带来了 GPU 自动扩展、零扩缩放和金丝雀发布等先进的服务特性。它使得生产 ML 服务变得简单、可插拔,并提供了完整的故事,包括预测、预处理、后处理和可解释性。
KServe中的ModelMesh 专为高规模、高密度和频繁变化的模型使用场景设计,智能地加载和卸载 AI 模型,以在用户响应和计算资源占用之间取得智能权衡。
KServe还提供基本API原语,可轻松构建自定义模型服务运行时。你也可以使用其他工具(例如BentoML)来构建你自己的自定义模型服务镜像。
• ⚙️ KServe的诞生背景:Kubeflow Summit 2019后,从Kubeflow分离出的KF Serving,最终发展为KServe。在2022年由Nvidia贡献了V2标准化推理协议,引起行业广泛关注。
•
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/373173?site
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

