
- 1VMWare克隆虚拟机之后,IP地址修改_虚拟机克隆后怎么修改ip地址
- 2Git branch && Git checkout常见用法
- 3开源模型应用落地-qwen1.5-7b-chat-LoRA微调(二)
- 4Linux项目自动化构建工具-make/ makefile及其应用:多文件编写第一个linux程序:进度条(懒人学习必备博文!!!)
- 5Javascript基础 86个面试题汇总 (附答案)_javascript面试
- 6《铸梦之路》Untiy高性能自动化UI管理框架ZMUIFramework
- 7spyder安装pyqt5_spyder怎么安装pyqt5
- 81694件AI事件大盘点!2020年12月,哪些让你记忆深刻_最优子集选择问题的多项式算法 王学钦讲座
- 9Matlab怎么计算信号的能量,Matlab小波包分解后如何求各频带信号的能量值? [转]...
- 10朴素贝叶斯(Naive Bayes)_贝叶斯公式小球
NLP深入学习:结合源码详解 BERT 模型(一)
赞
踩
1. 前言
BERT(Bidirectional Encoder Representations from Transformers)是一种预训练的自然语言处理(NLP)模型,由 Google 于2018年提出论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》。BERT 采用 Transformer 架构,具体来说,是通过多层的 Transformer 编码器来实现。与以前的 NLP 模型不同,BERT 的关键创新在于使用双向(bidirectional)上下文来预训练模型,使其能够更好地理解和捕捉句子中的语境信息。
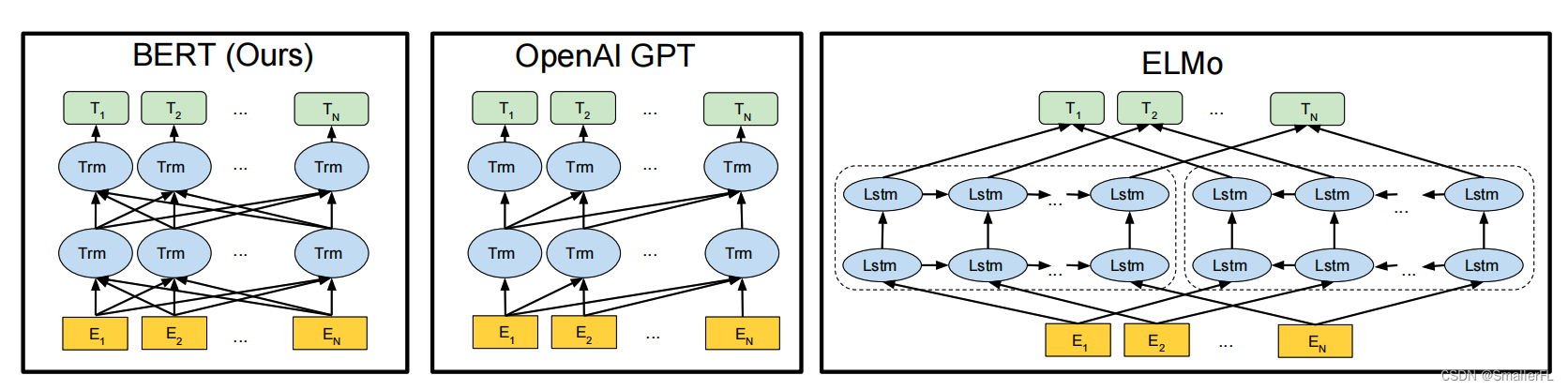
模型架构的差异对比。BERT 使用了一个双向 Transformer。OpenAI GPT使用一个从左到右的 Transformer。ELMo 使用从左到右、从右到左的 LSTMs, 用于为下游任务生成特性。在这三种方法中,只有 BERT 表示在所有层中都共同基于左右+上下文。
BERT 的出现极大地推动了自然语言处理领域的发展,成为了许多 NLP 任务中的基准模型。它的成功也激发了更多基于 Transformer 架构的模型的研发,如 GPT(Generative Pre-trained Transformer)等。
本文主要介绍 BERT 的关键流程。
2. BERT 关键流程
BERT采用了 Transformer,这是一种基于自注意力机制(Self-Attention Mechanism)的架构。Transformer允许模型在处理输入序列时同时考虑到所有位置的上下文信息。关于 Transformer 详细讲解可以阅读:
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
2.1 整体流程
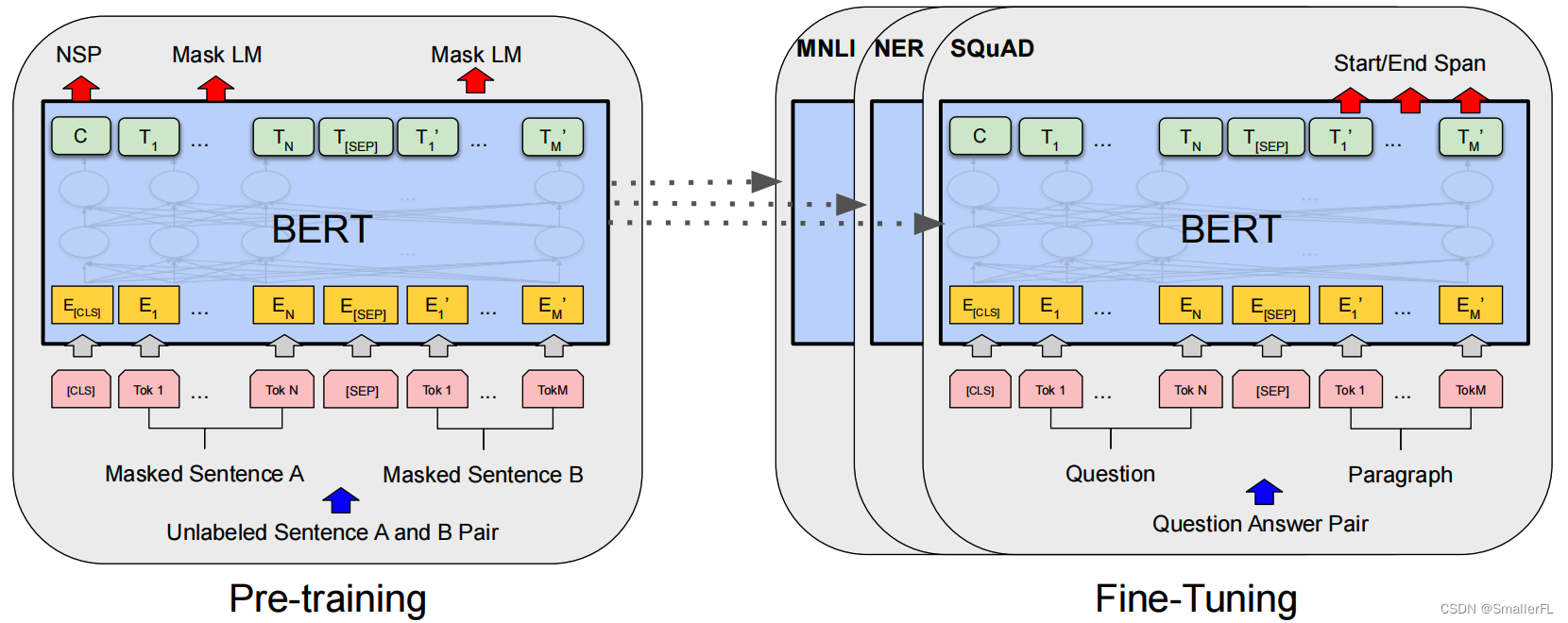
BERT 的整体流程 Pre-training 和 Fine-tuning。除了输出层之外,在 Pre-training 和 Fine-tuning 中都使用了相同的架构。
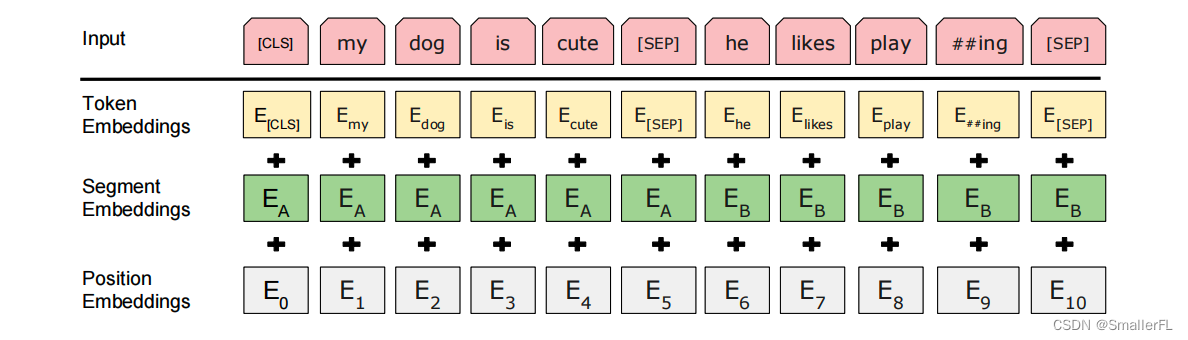
注意图中的输入 Input,
I
n
p
u
t
=
T
o
k
e
n
E
m
b
e
d
d
i
n
g
s
+
S
e
g
m
e
n
t
E
m
b
e
d
d
i
n
g
s
+
P
o
s
i
t
i
o
n
E
m
b
e
d
d
i
n
g
s
Input = TokenEmbeddings + SegmentEmbeddings + PositionEmbeddings
Input=TokenEmbeddings+SegmentEmbeddings+PositionEmbeddings
其中:
- TokenEmbeddings 是单词的字嵌入表示
- SegmentEmbeddings 是两个句子的区分标识,例如 “[CLS] My name is xx [SEP] How are you [SEP]” 那么对应的 SegmentEmbeddings 就是 0000001111,粗体0后1表示对应的单词
- PositionEmbeddings 是单词所在句子的位置
2.2 Pre-training(预训练)
在预训练阶段,BERT 是通过两个主要任务来学习词汇表示和上下文信息:Masked Language Model(MLM)和 Next Sentence Prediction(NSP)。
2.2.1 Masked Language Model (MLM)
在 MLM 任务中,BERT 通过随机遮蔽输入文本中的一些 token,然后让模型预测这些被遮蔽的 token。这个任务使得模型能够双向(从左到右和从右到左)观察上下文信息,从而更好地捕捉到 token 之间的关系。具体的步骤如下:
-
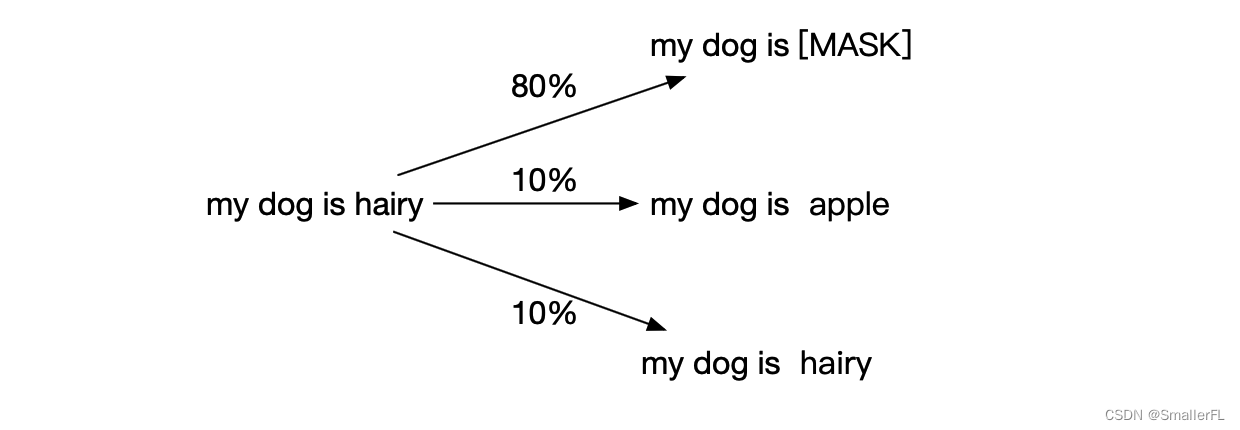
输入处理: 对于输入文本中的每个句子,随机选择15%的 token 进行遮蔽。然后,80%的被遮蔽的 token 被替换成一个特殊的 [MASK] 标记,10%的 token 被替换成其他随机的 token,而剩下的10%则保持原样。这样处理后,输入文本就变成了包含 [MASK] 标记的被遮蔽文本。例如:
-
MLM目标: 模型的目标是根据上下文预测被遮蔽的 token。在训练期间,模型通过比较模型输出和实际被遮蔽的 token 来计算损失,通过反向传播和优化算法来更新模型参数。
2.2.2 Next Sentence Prediction (NSP)
NSP 任务旨在让 BERT 模型理解句子之间的语义关系,以便在后续微调阶段对更复杂的语言任务有更好的泛化能力。
- 输入处理: 对于输入的一对句子,有50%的概率是真实的句子对(IsNext),另外50%是随机抽取的不相关的句子(NotNext)。然后,这一对句子被输入 BERT 模型。例如:

- NSP 目标: 模型的目标是预测这一对句子是否在语义上是相邻的(IsNext)还是不相关的(NotNext)。在训练期间,通过比较模型输出和实际标签来计算损失。
通过这 MLM 以及 NSP 两个任务的预训练,BERT 模型能够学到通用的语言表示,同时捕捉双向上下文信息,使得模型在微调到特定任务时具有更强的泛化能力。这种预训练方法帮助 BERT 成为在各种自然语言处理任务上取得优异表现的基础模型。
2.3 Fine-tuning(微调)
预训练完成后,BERT 模型可以通过微调用于特定的下游任务,如文本分类、命名实体识别等。在微调过程中,可以保持部分预训练的参数不变,也可以调整一些参数以适应特定任务。以下是BERT微调的一般过程:
- 准备数据:
收集与目标任务相关的标注数据。这些数据需要包括输入文本和相应的标签,如情感分类标签、实体识别标签等。 - 数据处理:
将任务相关数据进行适当的预处理,包括 tokenization、添加特殊标记(如[CLS]和[SEP])等,以使其符合 BERT 的输入格式。 - 模型输入:
将微调数据输入 BERT 模型。通常,输入是一个句子或一对句子,具体取决于任务。对于分类任务,可能只需一个句子;而对于问答或文本匹配任务,则需要一对句子。 - Loss计算:
根据任务类型选择适当的损失函数。对于分类任务,通常使用交叉熵损失;对于回归任务,可以使用均方误差等。Loss 计算的目标是使 BERT 模型的输出尽可能接近实际标签。 - 反向传播和优化:
计算损失后,通过反向传播算法更新 BERT 模型的参数,以减小损失。通常采用梯度下降或其变种进行优化。 - 训练过程:
在任务相关数据上进行多轮迭代的训练,确保模型能够充分学习任务特定的模式和特征。可以选择冻结一些层的参数,只微调部分参数,以减少训练时间和资源的需求。 - 性能评估:
使用验证集评估模型的性能。可以根据任务需求选择不同的评价指标,如准确率、精确度、召回率、F1分数等。 - 调整和优化:
根据性能评估的结果进行调整和优化,可能包括调整学习率、选择不同的模型配置,或进一步微调。 - 测试集评估:
使用独立的测试集评估最终模型的性能。确保模型在未见过的数据上表现良好。
下图是论文里展示的 BERT 微调后适合的任务:
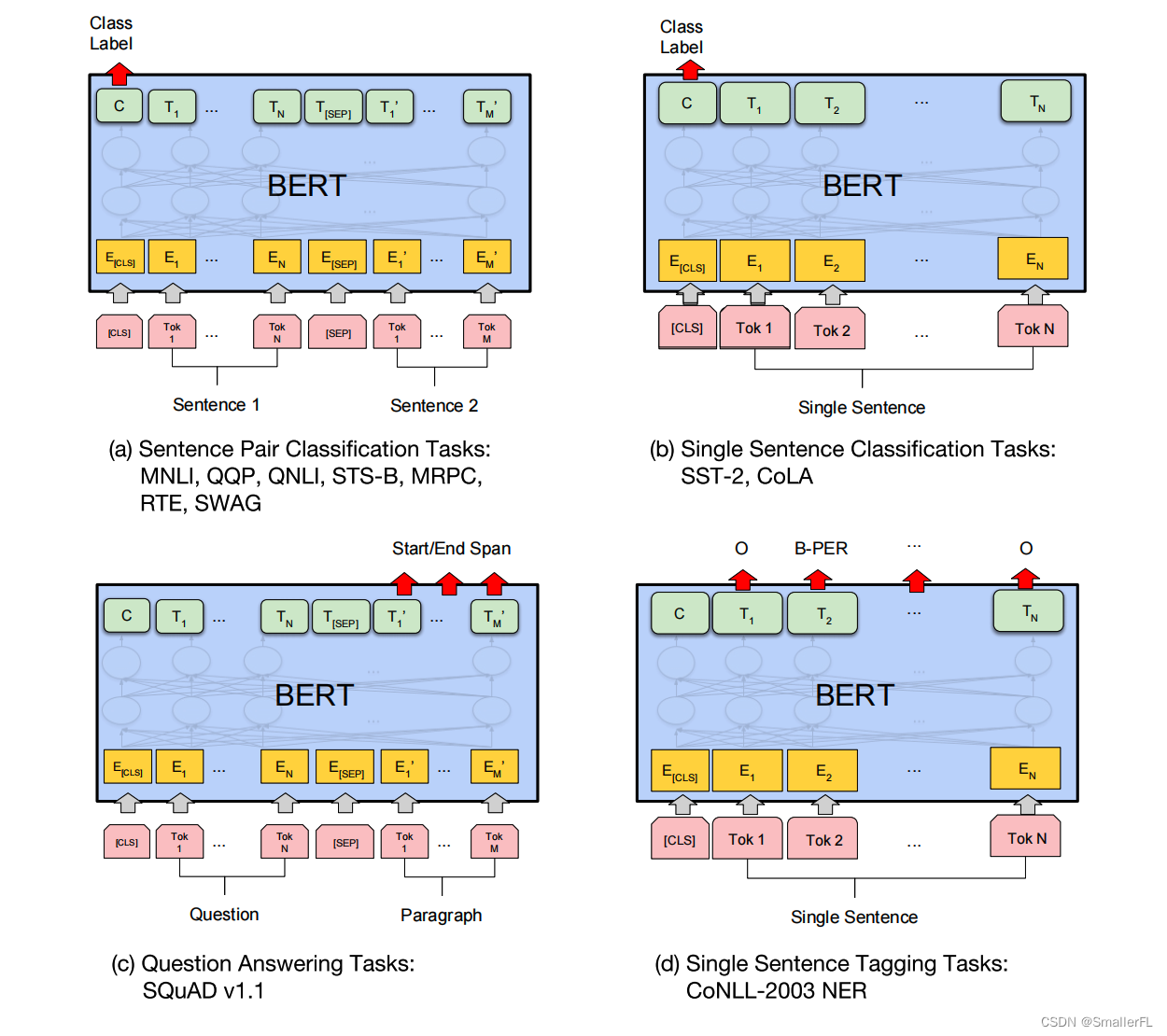
- (a)表示成对句子的分类任务,输出采用 [CLS] 的输出,因为 [CLS] 已经包含上下文信息
- (b)表示单个句子的分类任务,同样输出采用 [CLS] 的输出
- (c)表示问答任务,输出采用问题的回答
- (d)表示词标注任务,输出就是每个单词的标注结果
3. 总结
(1)什么是 BERT
BERT 是一种基于 Transformer 模型的深度双向语言表征模型。模型的输入是文本的token序列,输出是每个 token 的隐含表征。这些隐含表征包含了文本的上下文信息,可以用于各种自然语言处理任务。BERT 模型的发布推动了 NLP 领域的发展,并成为后续许多 NLP 模型的基础。例如,RoBERTa、DistilBERT、XLNet 等模型都是基 于BERT 模型改进的。
(2)预训练
BERT 模型的预训练采用了一种无监督学习方法。模型的输入是大量未标记文本,目标是预测下一个 token 的出现概率。通过这种预训练,模型可以学习到文本的上下文信息,并获得良好的语言表征能力。
(3)应用
- 文本分类
- 语义相似度
- 机器阅读理解
- 问答
- 文本摘要
- 机器翻译
(4)优缺点
优点:
- 可以学习到文本的上下文信息
- 具有良好的语言表征能力
- 可以用于各种自然语言处理任务
缺点:
- 模型参数量大,训练和推理成本高,训练慢
- 对小数据集的性能不佳
4. 参考
《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
未完待续,后文将结合源码介绍 BERT 的训练过程!
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎:SmallerFL;
也欢迎关注我的wx公众号:一个比特定乾坤

