
- 1iOS开发 - iOS第三方库整理_ios开发 气泡第三方
- 2幂等token-判重_幂等 token
- 3 c程序基本算法百例之八—借书方案知多少_借书方案知多少c语言
- 4element-ui 抽屉组件(el-drawer ) 二次封装 增加resize拖曳改变宽度大小,配合表格实现快捷方式打开抽屉展示详情及操作_element抽屉组件 加宽
- 5http、https、json编程
- 6MySQL数据库 综合项目实战(持续更新)_mysql项目
- 7公司出现这些“高危”征兆,不离职留着过国庆?赶紧走!_下坡路的公司该不该留
- 8解决谷歌浏览器无法正常打开摄像头_谷歌浏览器摄像头权限打开了但还是禁用
- 9四元数与欧拉角(RPY角)的相互转换_rpy角转四元数
- 10图的广度优先搜索和深度优先搜索_图 广度优先 深度优先
数字媒体概论——2D图像图形_二维图像
赞
踩
一:色彩基础
1.1:色彩认知
色彩是能引起我们共同的审美愉悦的、最为敏感的形式要素。色彩是最有表现力的要素之一,因为它的性质直接影响人们的感情。
丰富多样的颜色可以分成两个大类:无彩色系和有彩色系。有彩色系的颜色具有三个基本特性:色调、纯度(也称彩度、饱和度)、亮度。在色彩学上也称为色彩的三大要素或色彩的三属性
- 色调(Hue):人眼看多种波长的光时所产生的彩色的感觉。反应了颜色的种类,是决定颜色的基本特性。
- 饱和度(Saturation):指色彩的鲜艳程度,也称作颜色的纯度
- 亮度(Luminance / Lightness / Grayscale Value):单位是堪德拉每平米(cd/m2)或称nit。是从白色表面到黑色表面的感觉连续体。图像亮度是指画面的明亮程度,图像作用于人眼所引起的明亮程度的感觉。它与被观察物体的发光或反射光强度有关。
色调差异:

饱和度差异:

亮度差异:

1.2:色彩表示
HSV颜色空间(Hue-Saturation-Value):根据颜色的直观特性由A. R. Smith在1978年创建的一种颜色空间,颜色参数为色调H,饱和度S,明度V
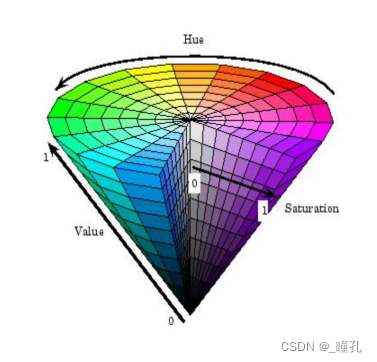
HSI颜色空间 (Hue Saturation Intensity/Lightness), HSL:符合人视觉直观特性的一种颜色空间,用H、S、I三参数描述颜色特性,其中H色调;S表示颜色的深浅程度,称为饱和度;I表示强度或亮度。
CMYK 彩色空间:是彩色印刷和彩色打印行业所用的,利用色料的三原色混色原理,加上黑色油墨,共计四种颜色混合叠加,形成所谓“全彩印刷”。
- 四种标准颜色是:Cyan 青色,Magenta 品红色,Yellow 黄色;black黑色
- 青、品红、黄是印刷三原色,理论上可以混合出黑色,但是现实中由于生产技术的限制,油墨纯度往往不尽人意。为了降低成本更直接的方式是直接使用最常用的黑色油墨
YUV/YIQ 彩色空间:YUV/YIQ/YCrCb是被电视系统、视频产业所广泛采用的颜色空间
- 其中“Y”表示明亮度(Luminance或Luma),也就是灰度值;而“U”和“V” 表示的则是色度(Chrominance或Chroma),作用是描述影像色彩及饱和度,用于指定像素的颜色。
- YUV色彩空间的重要性是它的亮度信号Y和色度信号U、V是分离的。如果只有Y信号分量而没有U、V信号分量,那么这样表示的图像就是黑白灰度图像。彩色电视采用YUV空间正是为了用亮度信号Y解决彩色电视机与黑白电视机的兼容问题,使黑白电视机也能接收彩色电视信号。
- YUV与RGB可以相互换算
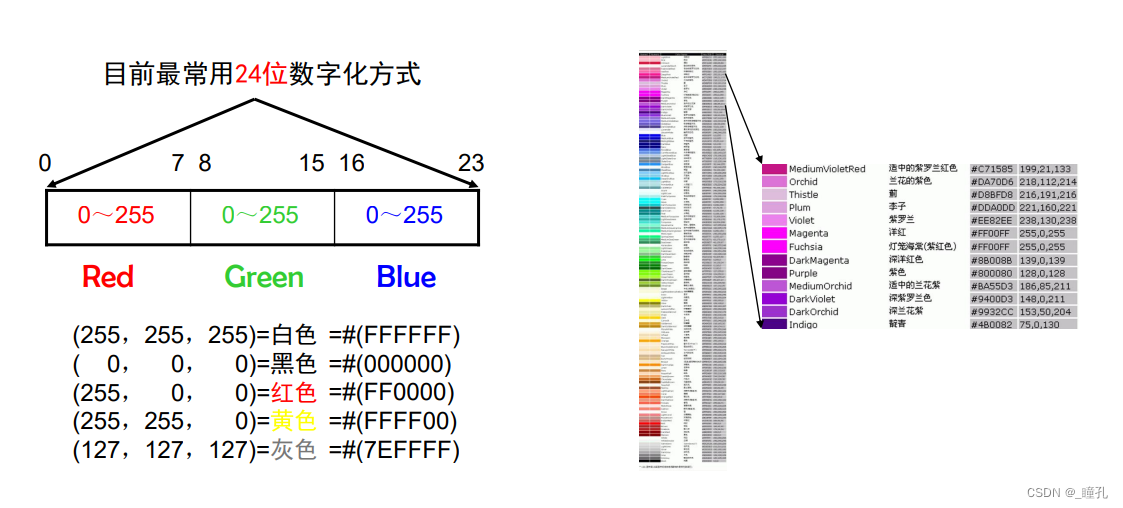
RGB 彩色空间:RGB颜色标准是工业界的一种颜色标准,是通过对红®、绿(G)、蓝(B)三个颜色通道的变化以及它们相互之间的叠加来得到各式各样的颜色的
- 这个标准几乎包括了人类视力所能感知的所有颜色,是运用最广的颜色系统之一。
- 显示器、电脑大都采用了RGB颜色标准。在电脑中,RGB的亮度用整数来表示(例如8bit图像取值范围0-255) 。8bit图像的RGB色彩总共能组合出约1678万种色彩,即256×256×256=16777216。通常也被简称为1600万色或千万色。也称为24位色。
视频中为什么需要这么多的颜色空间?
虽然颜色还是那个颜色,但是不同的颜色空间的适用范围并不相同:
- RGB:面向采集和显示设备
- YUV:面向存储
- HSL:面向人类视觉感知
- XYZ:RGB之间的转换桥梁
从视频采集到视频消费的整个过程,涉及到不同的设备和标准,而不同的设备和标准所支持的色域空间又不相同。正是通过不同的颜色模型转换和不同的色域转换,才得以在不同输入、输出、显示设备上都呈现出最好的颜色,才得以让我们实现以近似相同的观看体验来消费视频。
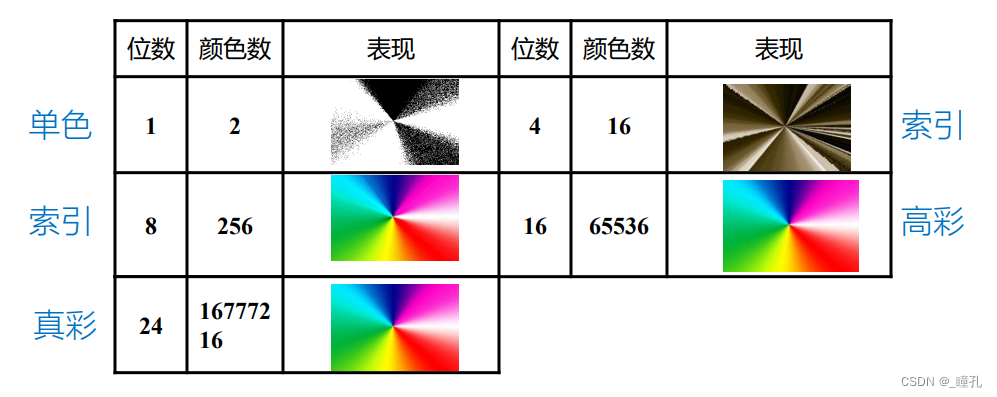
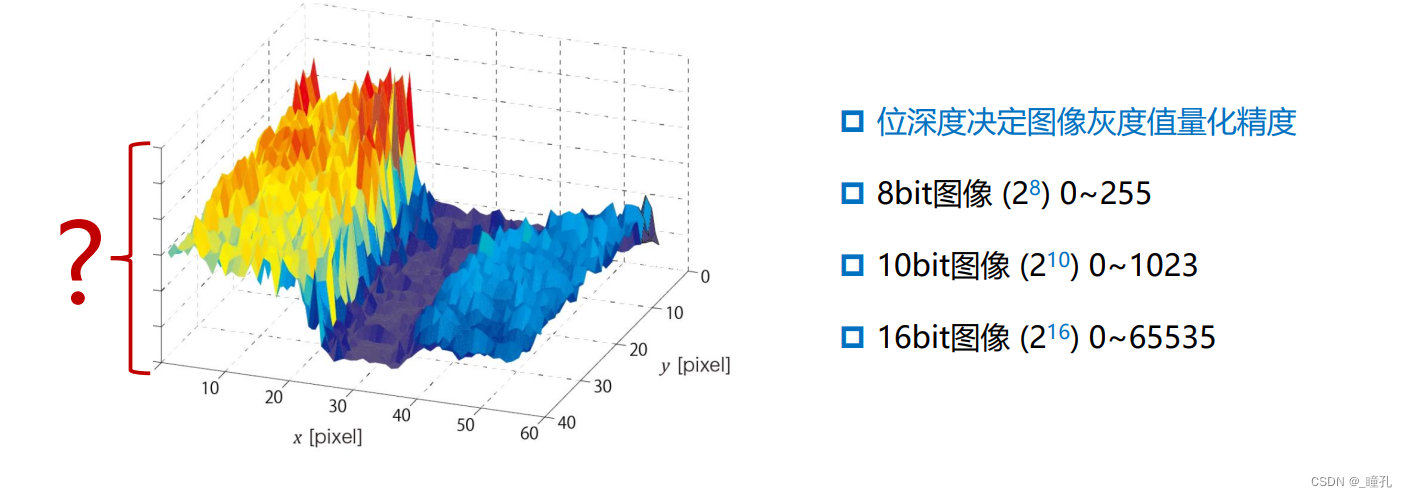
色深度/位深度 Bit Depth:色彩的数字化就是使用数字来代表颜色,计算机使用二进制bit位,如果用n bit表示彩色,则可以表示2的n次方种颜色(范围在0~2的n次方-1之间)
灰度 Grayscale:灰度使用黑色调表示物体。 每个灰度对象都具有从 0%(白色)到灰度条100%(黑色)的亮度值。

- 在设计领域 “灰”形容饱和度
- 在研究领域 是亮度的一种计算
- 灰度值范围与位深度有关

ALPHA通道(α Channel / Alpha Channel )是指图片的透明和半透明度通道
- 每个像素16比特存储的位图,每5个比特分别表示红绿蓝色,最后一个比特是阿尔法(透明/不透明)
- 使用32个比特存储的位图,每8个比特表示红绿蓝,和8bit阿尔法通道。在这种情况下,阿尔法通道还可以表示256级的半透明度。

- Alpha Channel 指定图像的透明度,在图像编辑中有很多用途,例如蒙版
- 阿尔法通道图像中像素点的像素值计算:

1.3:BMP图像文件格式
BMP格式,又称为Bitmap(位图),是Windows操作系统中的标准图像文件格式。这种格式的特点是包含的图像信息较丰富,几乎不进行压缩
位图文件由4个部分组成:
- 位图文件头(bitmap-file header)
- 位图信息头(bitmap-information header)
- 颜色表(color table)
- 位图数据(Data Bits 或Data Body)

- 颜色表256x4=1024B
- 位图数据
- 每个像素占一个字节,取得这个字节后,以该字节为索引查询相应的颜色
- 24位、32位位图不需要调色板,位图数据区就不是索引而是实际的像素值
- 24位RGB按照BGR的顺序来存储每个像素的各颜色通道的值,32位数据按照BGRA的顺序存储。一个像素的所有颜色分量值都存完后才存下一个下一个像素,不进行交织存储
1.4:色彩属性的应用示例
白平衡:白平衡是描述显示器中红、绿、蓝三基色混合生成后白色精确度的一项指标。反应了白色在不同色温下所体现的视觉感受,人眼可以自动根据环境调节色温,而相机在不同色温下的图像视觉感受差别很大。所以有时候为了艺术效果,有时候为了视频镜头白平衡的一致性,需要对白平衡进行调整/设定

高动态范围:传统记录颜色亮度信息一般是8位(Low Dynamic Range LDR),造成在计算和结果表达中差异范围较少,因此反应不了人眼所能感应的光强度范围(14+)。高动态范围High Dynamic Range HDR图像使用10、12、16、32位等更多bit来表现某一点的光照强度,并且在计算中采用高精度浮点运算减少误差。单张LDR恢复HDR的操作称为逆色调映射(Inverse Tone Mapping ITM)

照相机和摄像机采集光强的传感器精度也是8位,因此无法同时兼顾画面中最亮和最暗的区域

HDR拍摄采用多曝光融合,形成最后亮、暗处都很清晰的画面。

二:图像
2.1:位图
位图:静止的图像是一个矩阵,阵列中的各项数字用来描述构成图像的各个点(称为像素点Pixel )的颜色信息。这种图像称为位图( Bit-mapped Image )
用数码相机拍摄的照片、扫描仪扫描的图片以及计算机截屏图等都属于位图。位图的特点是可以表现色彩的变化和颜色的细微过渡,产生逼真的效果,缺点是在保存时需要记录每一个像素的位置和颜色值,占用较大的存储空间。常用的位图处理软件有Photoshop(同时也包含矢量功能)、Painter和Windows系统自带的画图工具等,Adobe Illustrator则是矢量图软件。

2.2:分辨率
分辨率:图像分辨率(Image Resolution): 图像中像素个数,通常用水平垂直两方向上的像素个数来表示
- 图像可以看做矩阵,矩阵中每个元素对应图像中每个像素
- 超分辨率(Super-Resolution): 图像放大、上采样(Upsampling)、上尺度(Upscaling)
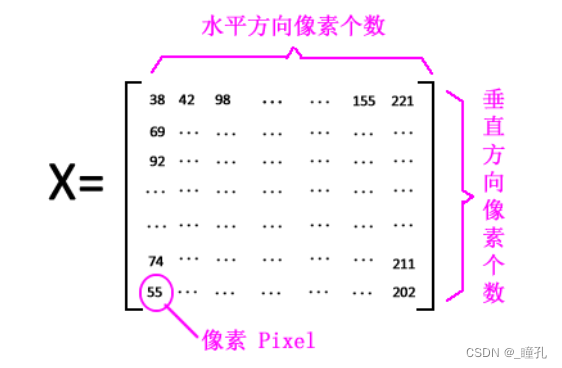
分辨率变化产生的图像失真:
2.3:插值
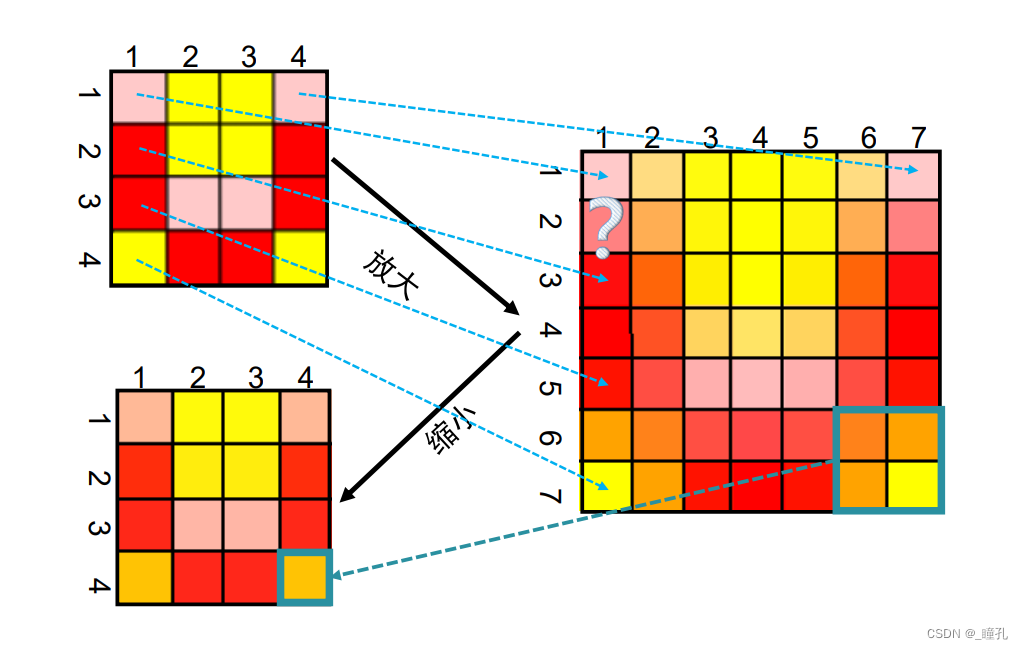
插值 Interpolation:图像插值就是利用已知邻近像素点的灰度值(或rgb图像中的三色值)来产生未知像素点的灰度值,以便由原始图像再生出具有更高分辨率的图像。
插值是对原图像的像素重新分布,从而来改变像素数量的一种方法。在图像放大过程中,像素也相应地增加,增加的过程就是“插值”发生作用的过程,“插值”程序自动选择信息较好的像素作为增加、弥补空白像素的空间,而并非只使用临近的像素,所以在放大图像时,图像看上去会比较平滑、干净。不过需要说明的是插值并不能增加图像信息,尽管图像尺寸变大,但效果也相对要模糊些,过程可以理解为白酒掺水。
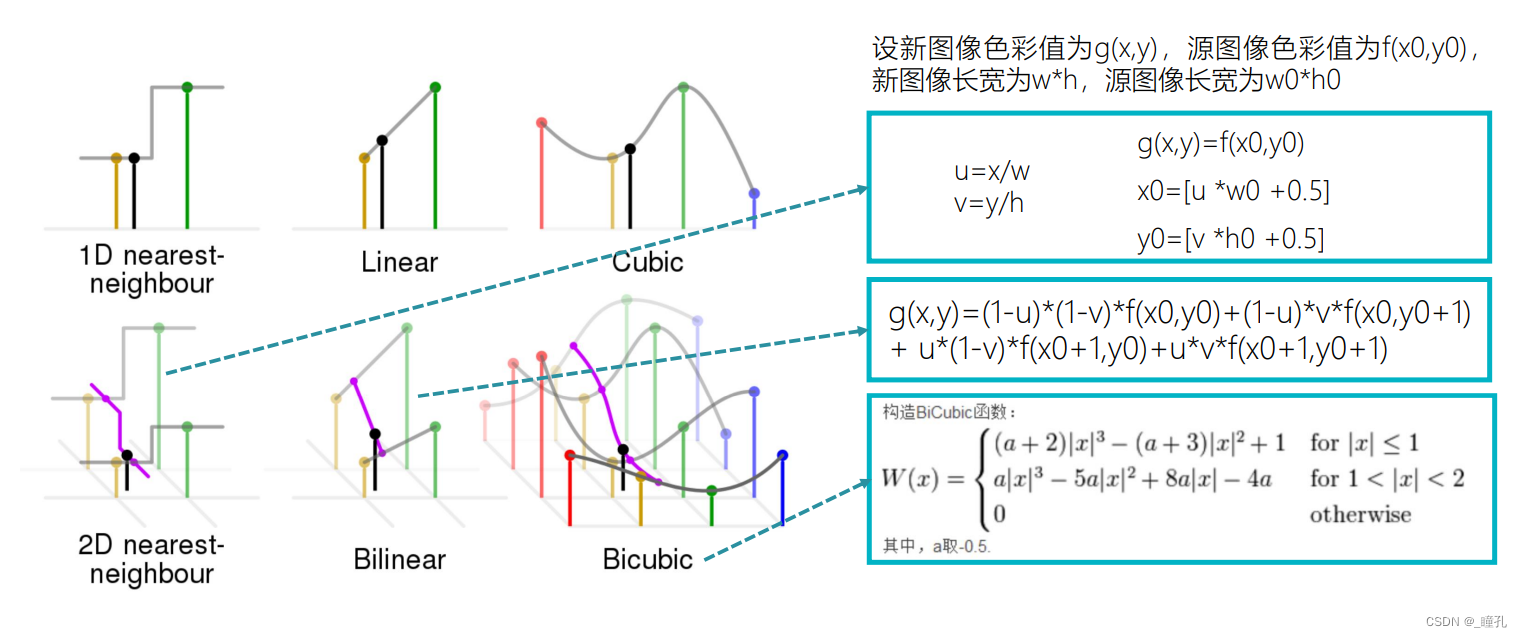
下图从左至右:低分辨率图像;最近邻插值; 双线性插值; 双三次插值; 高分辨率图像

2.4:图像位深度
图像位深度 Image Bit-Depth:是图像中用来表示每一个像素的色彩所用到的二进制位数,与之前色彩的数字化表示是一致的,也常称为色深度。
- 真彩图像(True Color) :真彩色是指图像中的每个像素值都分成R、G、B三个基色分量,每个基色分量直接决定其基色的强度。
- 伪彩图像(Pseudo Color):像素的颜色不是由基色分量直接决定,而是把像素值当作彩色查找表(Color Look-Up Table, CLUT)的表项入口地址,查找相应的R,G,B强度值。也叫做索引图像。
- 灰度图像:把白色与黑色之间按对数关系分为若干等级,称为灰度。灰度目前最高分为256阶——8位。用灰度表示的图像称作灰度图。

图像的数字化:一幅未经压缩的数字图像的数据量大小计算如下:
图像数据字节量大小 = 像素总数×图像深度÷8 = 水平分辨率×垂直分辨率 ×图像深度÷8
一幅640×480的256色图像为:
640×480×8/8 = 307200 bytes/1024=300KB
- 1
- 2
- 3
- 4
图像的色彩属性:
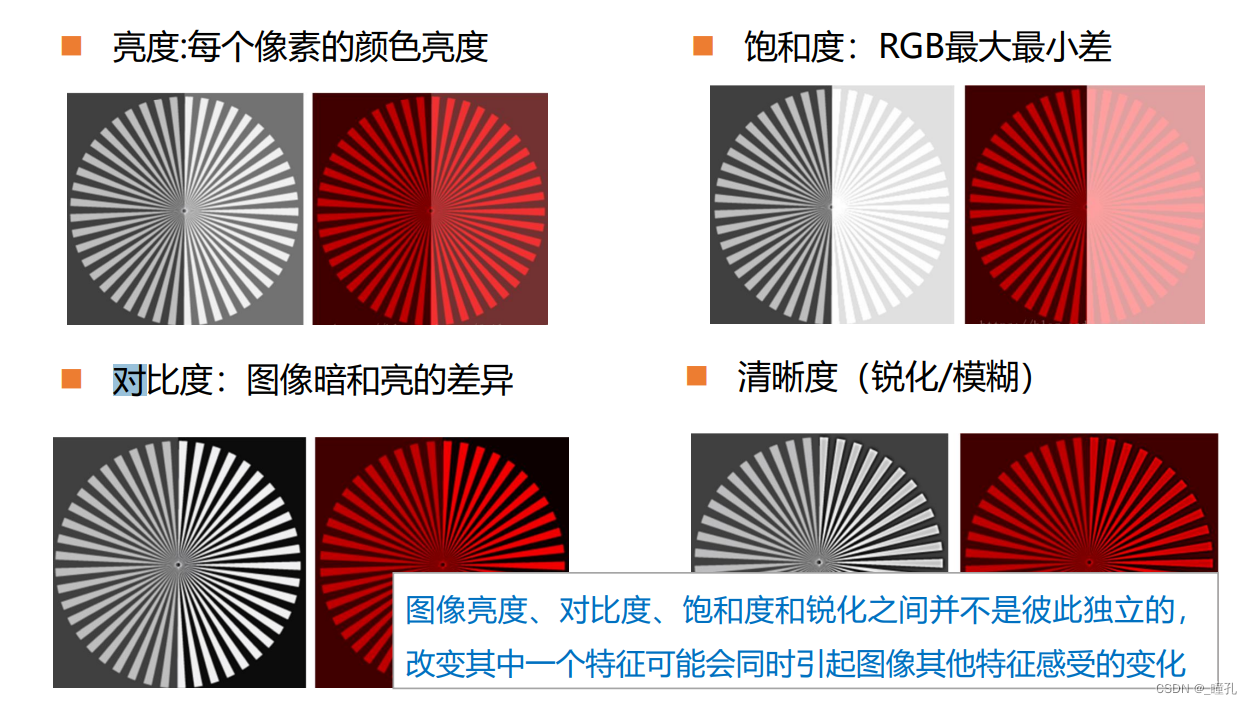
2.5:图像的显示输出属性
图像的显示输出属性:对于显示器、投影机、电视机等以点阵为核心显示方式的输出设备,有与图像分辨率与色彩深度相关联的属性。
- 显示分辨率:显示设备当前可以显示的像素点总数。如高清分辨率可达到1920×1080。
- 色彩深度:显示设备当前可以表示的颜色种类与数量。
2.6:图像的打印输出属性
图像的打印输出属性:对于打印机、大型彩喷、数码冲印等图像输出到实物的输出设备,也有着与图像自身属性类似的输出属性。
- 打印分辨率:以DPI (Dot Per Inch)表示,表示打印精度,一英寸纸面上能够容纳多少墨点。比如100DPI就是一英寸中最多有100个点。在数码冲印中,300DPI是可达到的最好分辨率,而120DPI则是底线。
- 色彩数量:是指输出设备可以表示的色彩种类。HP最新的9色喷墨打印机的色彩变化可达三亿八千八百万种。
打印照片的问题:如何知道一张图像适合打印多大尺寸的照片?
- DPI:打印精度衡量单位,指每英寸上能够绘制的最大像素点数
- 高质量:5寸或7寸、低质量:10寸;需要图像裁剪

2.7:图像的输入属性
图像的输入属性:
- 数码相机、摄像机、扫描仪等图像采集设备的光学器件CMOS(互补金属氧化物半导体)或者CCD(电荷耦合器件阵列),很大程度决定了输入图像的品质。
- 光学分辨率:直接由传感器转换信号得到的像素值个数。照相机一半是用像素数目表示,如500万像素;而扫描仪是用dpi,如1200dpi。
- 光学传感器色彩位感知:由一个特制的棱镜式分光镜,将影像的成像红绿蓝成分射到三个不同的CCD平面,然后通过软件的对准处理,合成为一幅完整的全彩色画面。相机软件用来记录红、蓝、绿色的位数,体现了其色彩深度。
光场相机 Light Field:
- 光场技术,在1996年由斯坦福的Marc Levoy等人提出,采集光场的手段主要有两种,一种是通过微透镜阵列,这样不但能记录光线的强度信息,还能记录光线的角度信息,另外一种是通过相机阵列技术。前者已经由RenNG成功商业化成Lytro光场相机
- 多相机阵列(Camera Arrays)利用不同空间位置的多个相机来采集不同视角的照片。斯坦福大学的Bennett Wilburn等人用廉价的相机搭建一个高性能的相机阵列
- 当所有的子相机之间的距离比较小时,也就是相机紧挨着放在一起,这时整个相机阵列可以看作一个单中心投影相机(Single-Center-of-Projection Camera)。这时整个相机阵列可以用来产生超分辨率、高信噪比、高动态范围的照片。
- 当所有的子相机之间的距离都很大时,这时整个相机阵列可以看成是一个多中心投影相机(Multiple-Center-of-Projection Camera),整个相机阵列所产生的数据就叫做光场,通过这些数据,我们可以得到物体的多视角信息,为其3D重建提供重要信息。
2.8:深度图 Depth Map/Image
深度图像(Depth image)也被称为距离影像(range image),是指将从图像采集器到场景中各点的距离(深度)作为像素值的图像,它直接反映了景物可见表面的几何形状。

手机图像采集+深度采集:
- ToF Time of flight:TOF是面光源投射,将红外光均匀的投射在物体上,然后使用TOF相机捕捉红外光反射的时间差,通过计算得出景深信息
- LiDAR Light Detection and Ranging,激光探测和测距:苹果iPhone12手机用上了LiDAR激光雷达后,可以实现更快的对焦速度和更加精准的3D建模,但是这颗雷达的探测距离仅为5米,所以和工业用途的激光雷达存在很大的性能差距

三:二维图形
位图图像表示的局限性:
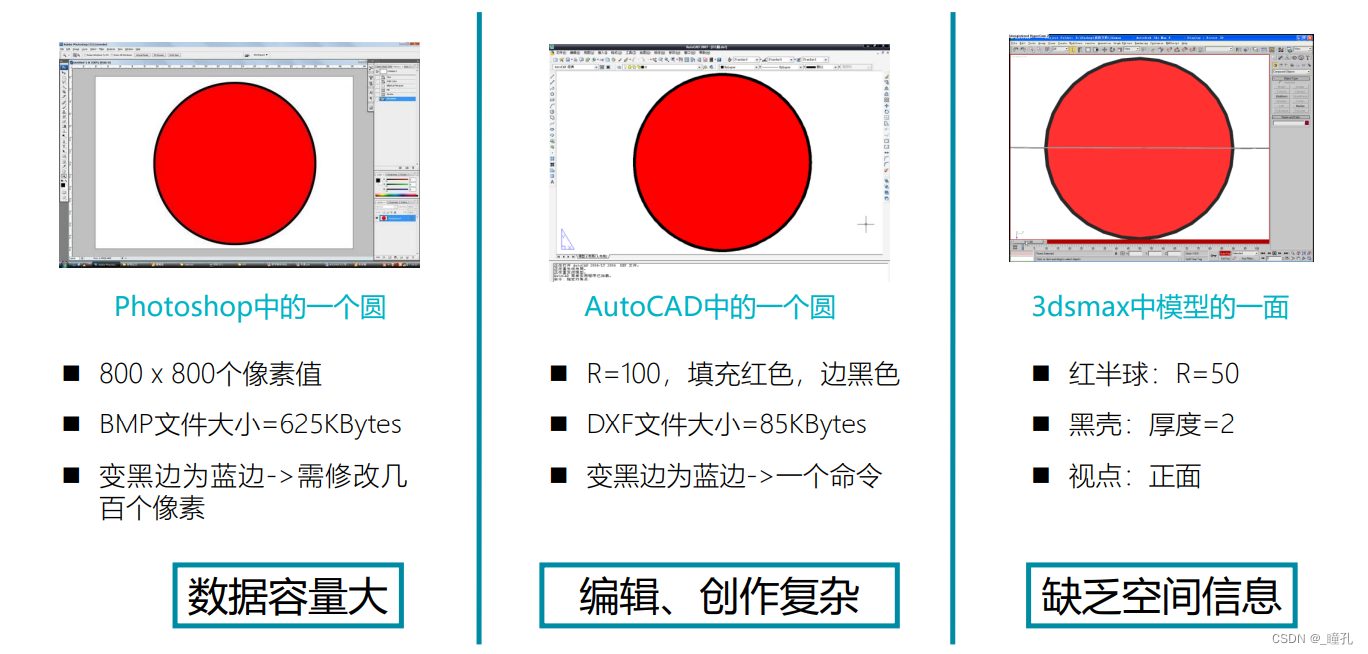
3.1:图元
- 图元指基本图形元素,是最简单的图形,是一组描述点、线、面等几何图形的大小、形状及其位置、维数的指令集合。在图形文件中只记录生成图的算法和图上的某些特征点,因此也称矢量图。
- 任何一个图形表达都是由若干不同的点、线、面图案或相同的图案循环组合而成的,这些基本点线面图案就是图元。
- 图形(Graphic)一般指用计算机绘制的画面,由一些图元组成。

3.2:矢量字体
矢量字体(Vector font)中每一个字形是通过数学曲线来描述的,它包含了字形边界上的关键点,连线的导数信息等。字体的渲染引擎通过读取这些数学矢量,然后进行一定的数学运算来进行渲染。这类字体的优点是字体实际尺寸可以任意缩放而不变形、变色。

主流的矢量字体格式有3种:Type1,TrueType和OpenType,这三种格式都是与平台无关的。
- Type1全称PostScript Type1,是1985年由Adobe公司提出的一套矢量字体标准,由于这个标准是基于PostScript Description Language(PDL),而PDL又是高端打印机首选的打印描述语言,所以Type1迅速流行起来。但是Type1是非开放字体,Adobe对使用Type1的公司征收高额的使用费。
- TrueType是1991年由Apple公司与Microsoft公司联合提出另一套矢量字标准。由TrueType 字库产生的字体,这里简称成TrueType 字体,也是Windows 常用的字体,它是一种基于轮廓技术的字体,字体信息是用直线段,二次贝塞尔曲线来描述的,这使得他们比其它矢量的字体更容易处理,保证了屏幕与打印输出的一致性;同时,可以随意缩放、旋转而不必担心会出现锯齿,这也是矢量字体相对于点阵字体无可比拟的优越性。
Type1使用三次贝塞尔曲线来描述字形,TrueType则使用二次贝塞尔曲线来描述字形。所以Type1的字体比TrueType字体更加精确美观。一个误解是,Type1字体比TrueType字体占用空间多。这是因为同样描述一个圆形,二次贝塞尔曲线只需要8个关键点和7段二次曲线;而三次贝塞尔曲线则需要12个关键点和11段三次曲线。然而实际情况是一般来说 Type1比TrueType要小10%左右。这是因为对于稍微复杂的字形,为了保持平滑,TrueType必须使用更多的关键点。由于现代大部分打印机都是使用PDL作为打印描述语言,所以Type1字体打印的时候不会产生形变,速度快;而TrueType则需要翻译成PDL,由于曲线方程的变化,还会产生一定的形变,不如Type1美观。
这么说来,Type1应该比TrueType更具有优势,为什么如今的计算机上TrueType反而比Type1使用更广泛呢?
- Type1由于字体方程的复杂,所以在屏幕上渲染的时候,花费的时间多,解决方案是大部分Type1字体嵌入了点阵字体,这样渲染快,但是边缘不光滑,比较难看。很多ps文档和ps转换的pdf文档都是这样,在计算机上浏览的时候字体很难看,但是打印出来很美观。TrueType则渲染比较快,可以平滑的显示在屏幕上,看上去很美观。
- Type1有高额使用费,使得Type1没有被所有的操作系统所支持。Windows家族只有OS/2和windows 2000及之后的版本从操作系统级别开始支持Type1。由于这个问题,Adobe只好在其所有的产品中嵌入Adobe Type Manager(ATM)作为渲染引擎。
OpenType则是Type1与TrueType之争的最终产物。1995年,Adobe公司和Microsoft公司开始联手开发一种兼容Type1和TrueType,并且真正支持Unicode的字体,后来在发布的时候,正式命名为OpenType。OpenType可以嵌入Type1和TrueType,这样就兼有了二者的特点,无论是在屏幕上察看还是打印,质量都非常优秀。可以说OpenType是一个三赢的结局,无论是Adobe、Microsoft还是最终用户,都从OpenType中得到了好处。Windows家族从Windows 2000开始,正式支持OpenType。打开系统的字体目录(一般是C:\Windows\Fonts\或C:\Winnt\Fonts),可以看到:一个红色A的图标的是点阵字体,两个重叠的T的图标是TrueType字体,一个O的图标就是OpenType字体。
3.3:二维图形的显示输出
由于当前的显示输出装置全部都是点阵方式,因此参数化的图元必须被表达为图像,即逐点颜色表达才能投射到屏幕上。这个从图元到点阵的过程被称之为光栅化(Rasterization),光栅化其实是一种将图形变为二维图像的过程。
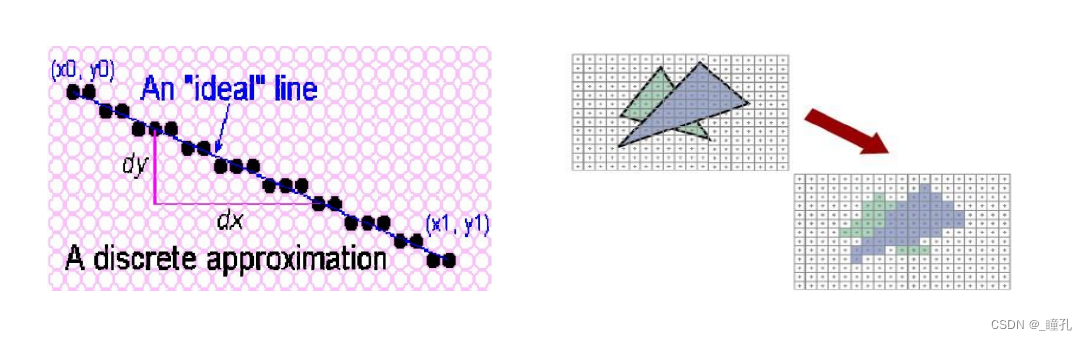
3.4:反走样技术 Anti-Alasing
由于采样不充分重建后造成的信息失真,就叫走样;用于减少或消除这种效果的技术,就称为反走样。
- 基于超采样的方法 Supersampling Anti-Aliasing
- 几何反走样:基于形态学的方法
3.5:图像处理中的图形化表达
图形不擅长表达高频变化的自然纹理;适宜于进行边界表达
边缘检测:
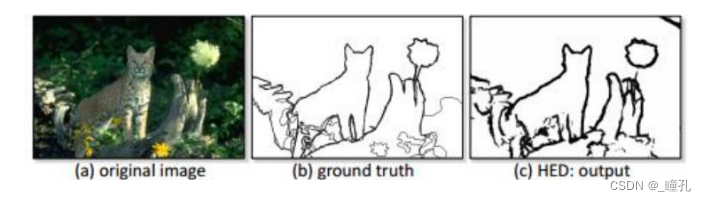
语义分割:

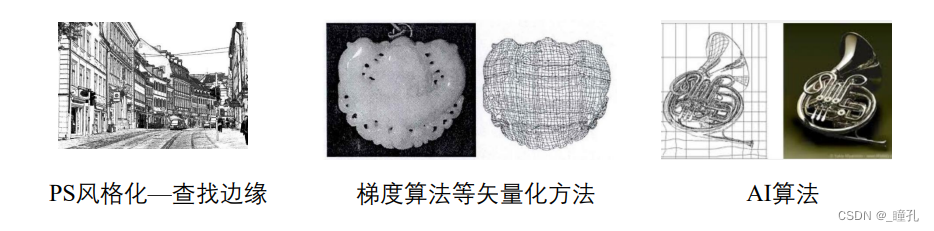
3.6:矢量化研究
非自然图像:
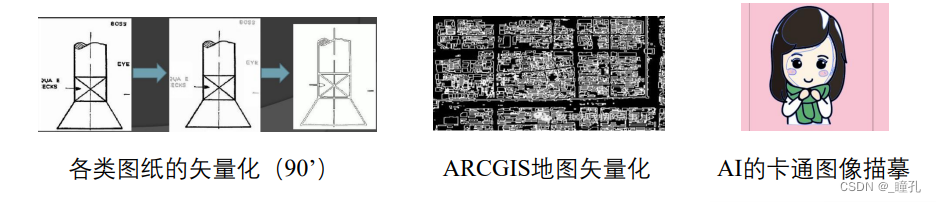
自然图像:
3.7:二维图形的输入
人机交互为主的参数化输入:

图像矢量化(描边):
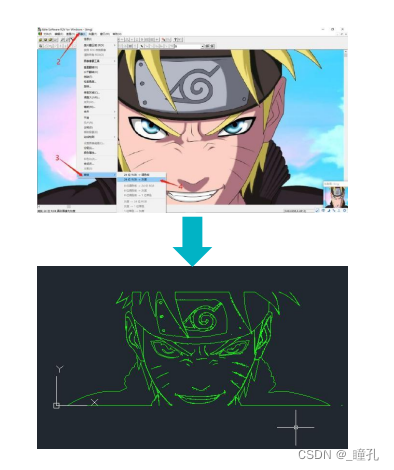
3.8:二维图形的输出
直接输出方式—绘图仪:可将计算机的输出信息以图形的形式输出。主要可绘制各种管理图表和统计图、大地测量图、建筑设计图、电路布线图、各种机械图与计算机辅助设计图等。一般直接与CAD软件连接。
间接输出方式—图像输出:

3.9:2D动画
传统2D动画:
- 逐帧动画(传统手绘)
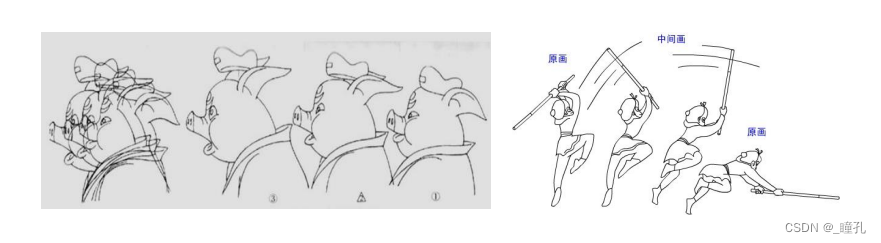
- 动画制作流程:任务划分->原画->中间画->上色->拍摄
计算机技术辅助动画:
- 电脑辅助中间画

- 电脑辅助上色
- 电脑辅助后期
现代动画制作流程:
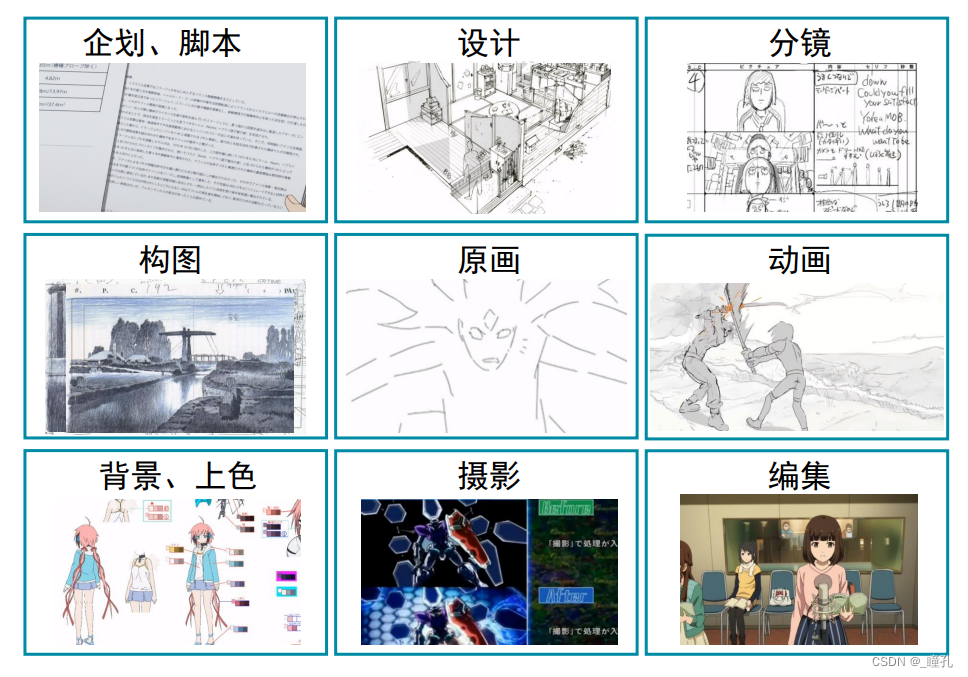
基于AI的2D动画生成:
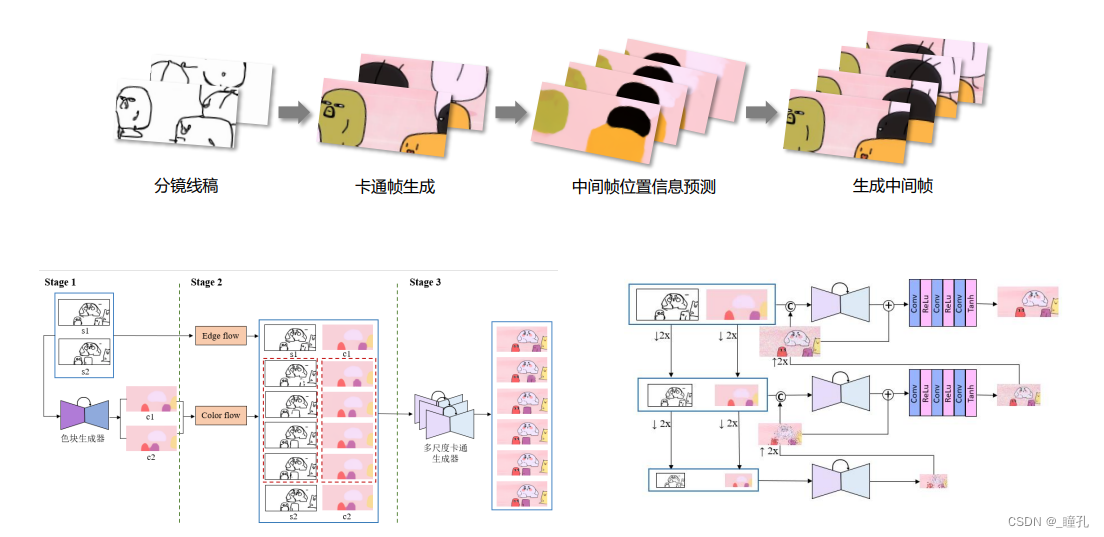
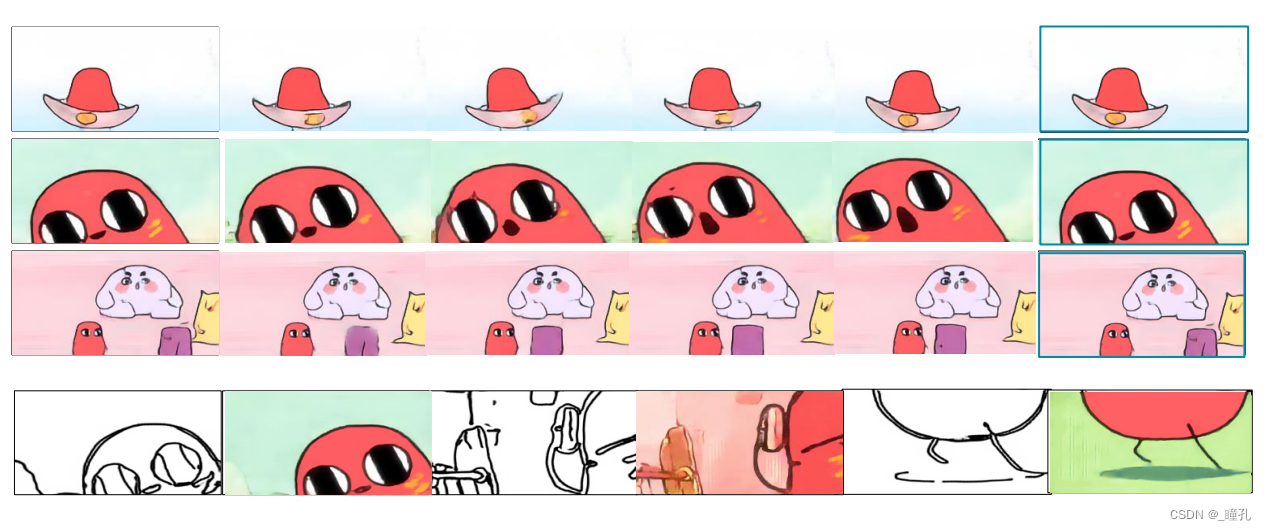
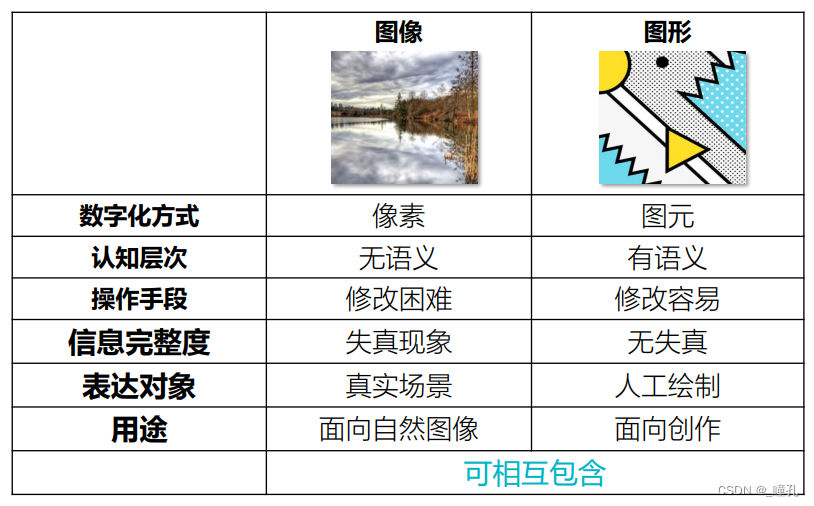
3.10:图像与图形
两者本质是数字化表达方式不同
四:采集与生成
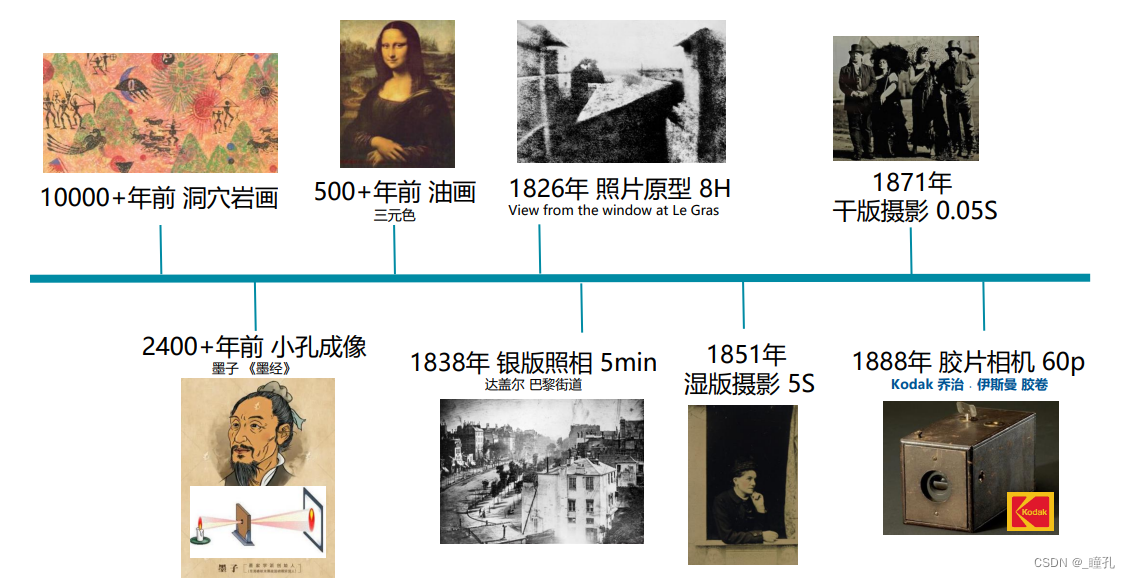
4.1:摄影设备的发展
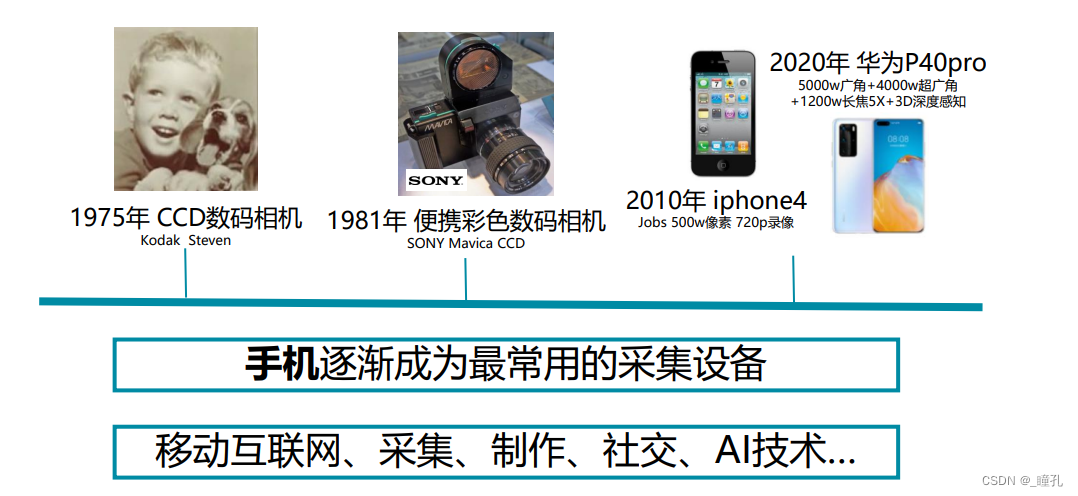
4.2:2D图像图形软件细分
2D图像图形软件工作分为:调色功能、像素处理、图层对象、图形绘制、排版布局
4.3:常见2D格式
- BMP:Windows中最常用的图象格式,有压缩和非压缩两种,存储文件的容量较大,可表现单色到24位的色彩
- DXF:AutoCAD中的图形文件,以ASCII方式存储图形,表现图形的尺寸大小非常准确,是2D图形的通用交换格式
- WMF:微软Windows图元文件,文件短小,图案造型化
- GIF:各种平台的各种图形处理软件上均可以使用的经过压缩的图形格式。存储的色彩数最高只能达到256种,色彩深度低。具有一定的动画效果,所以多用在Web上
- JPG:通过一种有损压缩方案获得的高压缩率的图像文件,色彩最高可以达到24位其“有损性”一般不易被人察觉,广泛应用于Web中,没有alpha通道,压缩率高。
- PNG:一种采用无损压缩算法的位图格式。压缩比高,生成文件容量小。有8位、24位、32位三种形式,其中8位PNG支持两种不同的透明形式(索引透明和alpha透明),24位PNG不支持透明,32位PNG在24位基础上增加了8位透明通道。常用于视频序列图存储以及AI算法研究
- TIF:文件体积庞大,但存储的信息量也是巨大,细微层次的信息较多,支持的颜色数最高可以达到16M,广泛应用在轻印刷行业中。常用于纹理材质贴图、高质量印刷图像
- PSD:Photoshop中的标准文件格式,专门为Photoshop而优化
- CRD:CorelDraw的文件格式
- SWF:FLASH的发布格式,其实是一种多媒体文件的格式
五:图像压缩
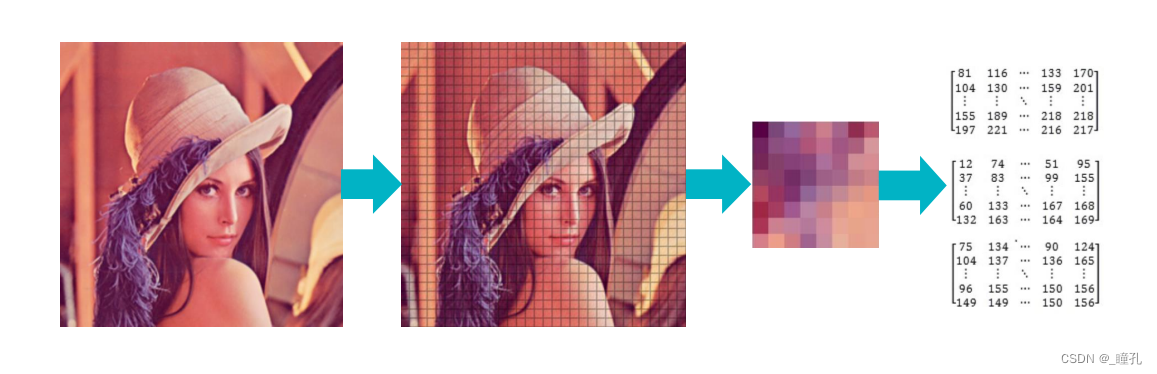
5.1:图像分块
图像被分割成大小为8x8的小块,这些小块在整个压缩过程中都是单独被处理的,最后再同样拼接成最终结果
5.2:色彩空间变换
- RGB三通道同等重要,YCbCr/YUV亮度与色度分离
- 对于人眼来说,图像中明暗的变化更容易被感知到。人眼有两种感光细胞,能够感知亮度变化的视杆细胞,以及能够感知颜色的视锥细胞,由于视杆细胞在数量上远大于视锥细胞,所以更容易感知到明暗细节

5.3:JPEG图像格式
JPEG(Joint Photographic Experts Group,联合图像专家小组):此团队创立于1986年,其于1992年发布的 JPEG 标准在1994年获得了 ISO 10918-1 的认定,成为了图片压缩标准。
为什么要压缩:图像的数据量通常很大,所以就给图像的存储、处理和传输带来了很大的问题。为了应对这些问题,就需要对图像进行压缩。
为什么可以压缩:数据中存在空间、视觉、编码等冗余。
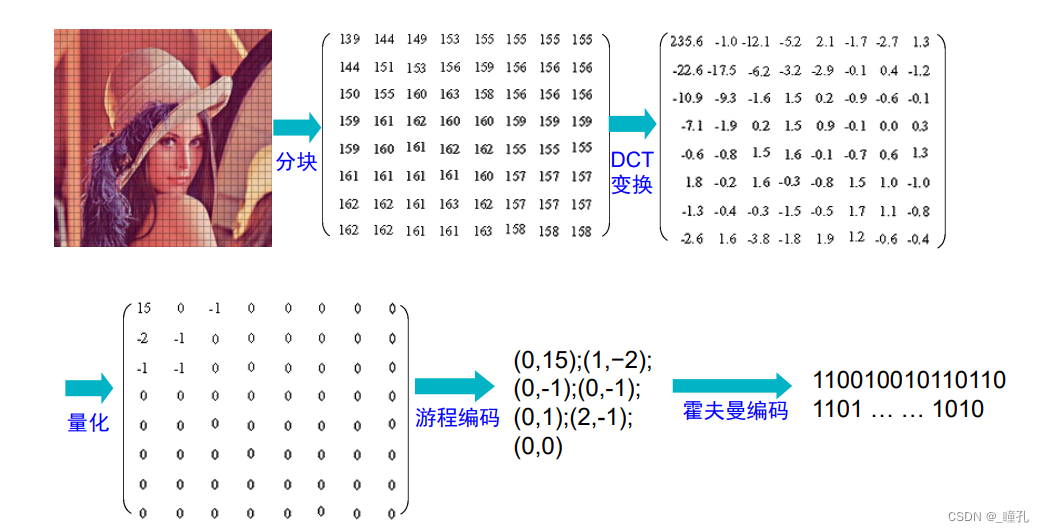
PEG压缩分四个步骤实现:颜色模式转换及采样、DCT变换、量化、编码
1.颜色模式转换及采样:RGB色彩系统是我们最常用的表示颜色的方式。JPEG采用的是YCbCr色彩系统。想要用JPEG基本压缩法处理全彩色图像,得先把RGB颜色模式图像数据,转换为YCbCr颜色模式的数据。Y代表亮度,Cb和Cr则代表色度、饱和度。通过下列计算公式可完成数据转换。 Y=0.2990R+0.5870G+0.1140B Cb=-0.1687R-0.3313G+0.5000B+128 Cr=0.5000R-0.4187G-0.0813B+128 人类的眼晴对低频的数据比对高频的数据具有更高的敏感度,事实上,人类的眼睛对亮度的改变也比对色彩的改变要敏感得多,也就是说Y成份的数据是比较重要的。既然Cb成份和Cr成份的数据比较相对不重要,就可以只取部分数据来处理。以增加压缩的比例。JPEG通常有两种采样方式:YUV411和YUV422,它们所代表的意义是Y、Cb和Cr三个成份的数据取样比例。
2.DCT变换:DCT变换的全称是离散余弦变换(Discrete Cosine Transform),是指将一组光强数据转换成频率数据,以便得知强度变化的情形。若对高频的数据做些修饰,再转回原来形式的数据时,显然与原始数据有些差异,但是人类的眼睛却是不容易辨认出来。 压缩时,DCT使用64个基(Basis)表示任意 8x8 图像块。只要用系数(系数表示每个单独的基对整体图像所做的贡献)对这64个余弦波进行加权,就可以表示出任何的图形。
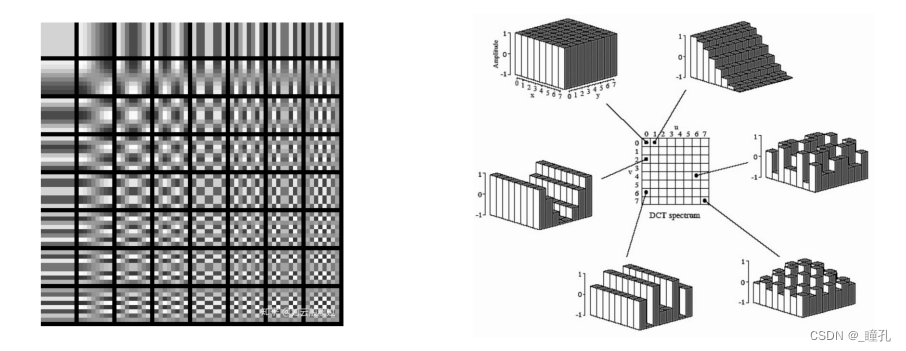
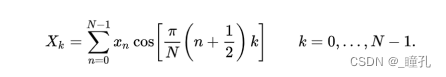
和FFT一样,DCT也是将信号从时域到频域的变换,不同的是DCT中变换结果没有复数,全是实数。每8x8个像素值都变成了另外8x8个权重/系数值(经过取整,取值范围 -1024~1023)。
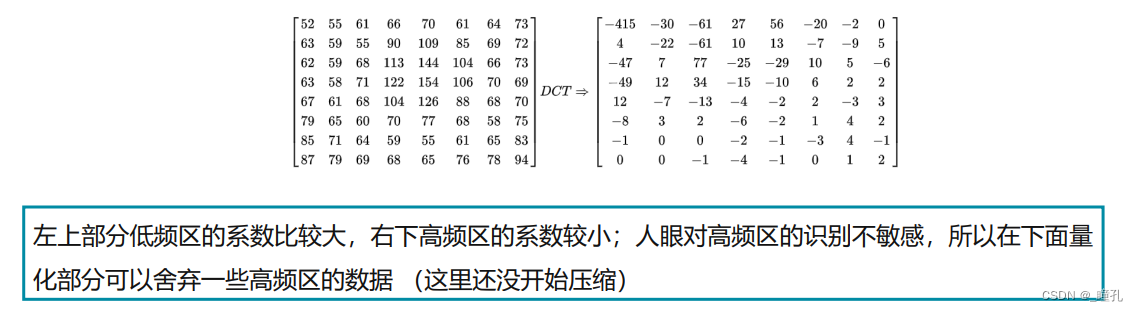
3、量化:图像数据转换为频率系数后,还得接受一项量化程序,才能进入编码阶段。DCT变换后,低频部分集中在每个8x8块的左上角,高频部分在右下角。低频部分比高频部分要重要得多,移除很多高频信息可能对于编码信息只损失了很少信息。量化就是用使用量化矩阵与前面得到的DCT矩阵逐项相除并取整。由于量化表左上角的值较小,右下角的值较大,这样就起到了保持低频分量,抑制或丢掉高频分量的目的
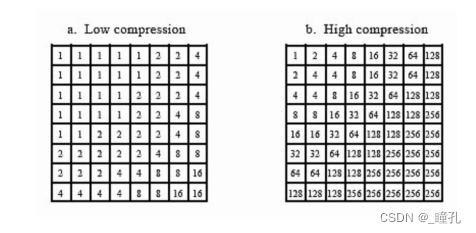
对Y采用细量化,对UV采用粗量化,可进一步提高压缩比。所以上面所说的量化表通常有两张,一张是针对亮度的;一张是针对色度的。
量化表是控制 JPEG 压缩比的关键,是根据人眼对不不同频率的敏感程度的差别所积累下的经验制定的,可以根据输出图片的质量来调整量化表,表中数字越大则质量越低,压缩率越高。

4、编码:游程编码(Run-length Encode, RLE)为了保证低频分量先出现,高频分量后出现,以增加行程中连续“0”的个数,RLE采用了“之”字型(Zig-Zag)的排列方法。编码采用EOB(End Of Block)字段,表示从字段开始后面全为0。然后再根据Huffman编码再进行压缩,Huffman编码无专利权问题,成为JPEG最常用的编码方式
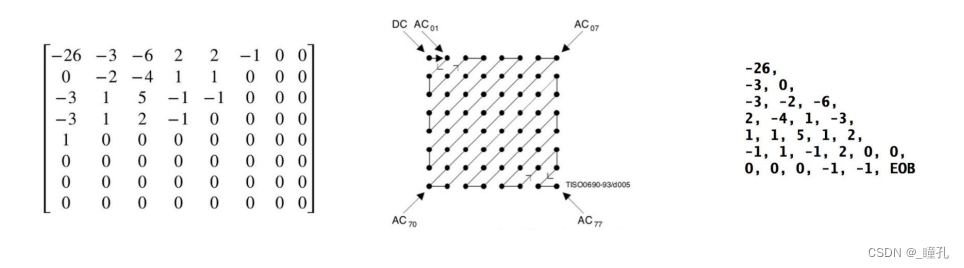
变换、量化、编码过程回顾:
JPEG压缩效果:

如果有兴趣了解更多相关内容,欢迎来我的个人网站看看:瞳孔的个人空间

