
- 1next 14 appRouter redux数据持久化_nextjs redux 持久化存储
- 2mac与windows服务器 访问和共享
- 3Android 15全面解读:性能飙升、隐私守护与智能生活新纪元_安卓15
- 4标题:怎样通过Dialogflow构建一个聊天机器人?React版。_dialogflow机器人
- 5连接Mongodb数据库的步骤以及注意事项_如何连接mongodb数据库
- 6小程序公告php实现,小程序两种滚动公告栏的实现方法
- 7Git仓库完整迁移全过程_gitee 将a仓库的克隆到b仓库
- 8FP6381AS5CTR原厂SOT23-5 1.2A同步降压IC DC-DC变频器
- 9STM32参考代码,编译时出现“cannot open source input file, no such file or directory"错误
- 10微信小程序用户隐私保护指引设置指南_mp后台-设置-基本设置-服务内容声明-用户隐私保护指引]中声明“剪切板”隐私收集
Hadoop+Spark大数据技术(微课版)曾国荪、曹洁版思维导图第五次作业 第五章 Scala基础与编程
赞
踩

-
第五次作业
-
1. 简述Scala语言的基本特性
-
1. 面向对象:Scala是一种完全面向对象的语言。其每一种数据类型都是一个对象,这使得它具有非常统一的模型。
-
2. 函数式编程:Scala同时支持函数式编程,它拥有高阶函数、闭包、不可变数据结构、递归等函数式编程的关键特性。
-
3. 扩展性:Scala的语法非常灵活,允许开发者自定义运算符和语法糖。也支持模式匹配、类型推断和匿名函数等高级特性,这些都为编写简洁、高效的代码提供了可能。此外,Scala的语法允许在单个文件中定义类、对象、函数等,使得代码组织更加灵活。
-
4. 并发性:Scala支持Actor模型(处理并发的轻量级机制)。通过Actor,可以编写出线程安全的、易于管理的并发代码,有效地利用多核处理器资源。
-
5. 可以和Java混编:Scala运行在Java虚拟机(JVM)上,并兼容Java的API。可以直接使用Java库,或者在Scala代码中调用Java方法,反之亦然。这为已有的Java项目提供了无缝迁移到Scala的可能,也使得Scala成为一个非常实用的工具,可以在不完全重构的情况下逐步引入新的编程范式。
-
-
2. 简述Scala语言的9种基本数据类型。 说明关键字Unit、Nothing、Any的含义。
-
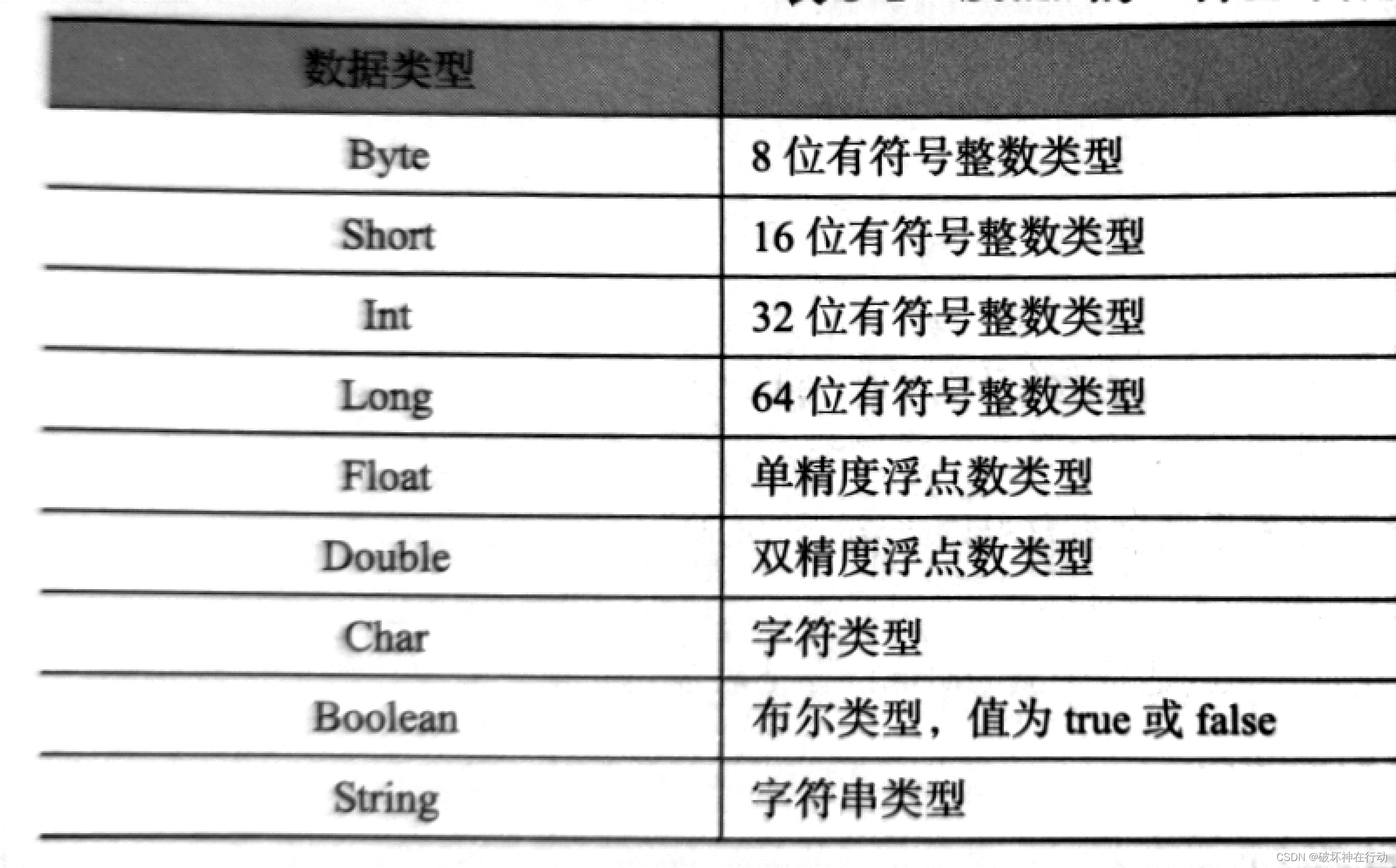
-
Unit无返回值,通常用于不返回任何内容的方法。
-
Nothing是任何其他类型的子类,用于表示永远不会正常终止的程序部分。
-
Any是所有其他类型的超类(父类)
-
-
3. 简述Scala中数组、列表、集合、元组、映射的名称及特点。
-
数组(Array):固定大小的集合,元素类型相同,性能较好但不支持动态修改大小。
-
列表(List):不可变的序列集合,适合于递归处理和模式匹配,但头部插入和删除效率低。
-
集合(Set):无序且不重复元素的集合,分为可变和不可变两种。
-
元组(Tuple):固定长度、不同类型的元素组合,最多支持22个元素,常用于同时携带多种类型信息。
-
映射(Map):键值对的集合,键唯一,分为可变和不可变两种,适合快速查找。
-
-
4. 举例说明匿名函数和高阶函数的含义,
-
匿名函数
-
也称为Lambda函数。箭头“=>”定义,箭头的左边是参数列表,箭头的右边是表达式,表达式的值即匿名函数的返回值。 在代码中直接定义的函数,没有具体的函数名。通常用于一些简单的、一次性的操作。
-
val sum = (x: Int, y: Int) => x + y
-
val result = sum(3, 5) /
-
/ result = 8
-
-
-
高阶函数
-
高阶函数是指使用其他函数作为参数,或者返回一个函数作为结果的函数。
-
val numbers = List(1, 2, 3, 4)
-
val doubled = numbers.map(x => x * 2)
-
// doubled = List(2, 4, 6, 8)
-
-
-
-
5. 阅读、分析下列程序段,并给出运行结果。
- (1)
- var v = 0
- for (i <- 1 to 9) {
- for (j <- 1 to i) {
- v = i*j
- print(f"$j%s*$i%s=$v%-3s")
- }
- println()
- }
- (2)
- val a = Array("Hello Spark","Hello Hadoop","Hello Scala")
- val b = a.flatMap(_.split(" ")).map((_,1)).groupBy(t => t._1).map(t => (t._1,t._2.length)).toList.sortBy(t => t._2).reverse
- b.foreach(x => println(x))
- (3)
- class Person(val namec:String,val agec:Int) {
- var name:String = namec
- var age:Int = agec
- def printPerson() : Unit = {
- printf(f"name:$name%8s, age:$age%-4d")
- }
- }
- object Test2 {
- def main(args:Array[String]):Unit = {
- val x = new Person("zhang",21)
- x.printPerson()
- }
- }
- (4)
- val a = List(("a",85),("b",95),("c",75),("a",95))
- a.groupBy(_._1)
- (5)
- val s = List("Spark","Python","Hadoop","HBase")
- s.foreach(e => print(e+" "))
- print(s.count(e => e.length == 5))

- (1) 九九乘法表
- 这段代码使用嵌套循环打印九九乘法表。外层循环控制行数,内层循环控制每行打印的乘法算式。
- 运行结果:
- ```
- 1*1=1
- 1*2=2 2*2=4
- 1*3=3 2*3=6 3*3=9
- ...
- 1*9=9 2*9=18 3*9=27 ... 8*9=72 9*9=81
- ```
- (2) 单词计数
- 这段代码统计字符串数组中每个单词出现的次数,并按出现次数降序排列。
- 步骤解析:
- 1. `flatMap(_.split(" "))`:将每个字符串按空格分割成单词列表,并合并成一个新的列表。
- 2. `map((_,1))`:将每个单词映射成一个元组,元组的第一个元素是单词本身,第二个元素是 1。
- 3. `groupBy(t => t._1)`:按照单词分组。
- 4. `map(t => (t._1,t._2.length))`:统计每个单词出现的次数。
- 5. `toList.sortBy(t => t._2).reverse`:将结果转换为列表,并按出现次数降序排列。
- 运行结果:
- ```
- (Hello,3)
- (Spark,1)
- (Scala,1)
- (Hadoop,1)
- ```
- (3) 类定义与对象创建
- 这段代码定义了一个 `Person` 类,并创建了一个 `Person` 对象,然后调用该对象的 `printPerson` 方法打印信息。
- 运行结果:
- ```
- name:zhang , age:21
- ```
- (4) 按第一个元素分组
- 这段代码将列表 `a` 按照元组的第一个元素分组。
- 结果:
- ```
- Map(a -> List((a,85), (a,95)), b -> List((b,95)), c -> List((c,75)))
- ```
- (5) 字符串操作
- 这段代码遍历字符串列表 `s` 并打印每个元素,然后统计长度为 5 的字符串个数。
- 运行结果:
- ```
- Spark Python Hadoop HBase 2
- ```
-

