
- 1前后端分离式交互_前后端分离怎么实现交互代码
- 2基于STM32单片机智能家居安防烟雾煤气温度红外主从设计20-221
- 3机器学习--集成学习随机森林算法21_随机森林算法二维数据分析
- 4第二篇 FPGA数字信号处理_并行FIR滤波器Verilog设计_自适应算法数字信号处理fpga
- 5C#后台生成画报(海报)_c# 生成海报
- 6PCIe转28串口8串口CH384设计注意事项
- 7ISCC2022WP--WEB
- 8Pytorch实现基于Transformer、Bert和GPT2的生成式聊天机器人_transformer构建聊天机器人
- 9Flink的简介以及基本概念_flink介绍和基本概念
- 10邮件协议(SMTP)性能测试总结(Foxmail邮箱)
分布式系统一致性与共识算法
赞
踩
分布式系统的一致性是指从系统外部读取系统内部的数据时,在一定约束条件下相同,即数据(元数据,日志数据等等)变动在系统内部各节点应该是一致的。
一致性模型分为如下几种:
① 强一致性 所有用户在任意时刻读到的数据,无论会请求到哪个节点上,都是一致的;
② 单调一致性 有用户在任意时刻读到的数据一定会比之前读到的数据新,也就是说,可获取的数据顺序必是单调递增的;
③ 弱一致性 相比于强一致性,弱一致性要求没那个严格,不同用户在不同时间读到的数据可能是不一致的,但过了一段时间会达到一致。
④ 最终一致性 最终一致性属于弱一致性的一种实例。用户只能读到某次更新后的值,但系统保证数据将最终达到完全一致的状态,只是所需时间不能保障。
实际上一致性还包括顺序一致性、读写一致性、因果一致性等等,这里不做过多讨论。
之前在分布式基础的文章里也有过讨论,对于分布式系统,主要有CAP理论和BASE理论。对于现实的网络来说,BASE理论是比较适用的,即实现最终一致性。
再说下共识,共识是指不同的节点通过某种方法对于某种状态达成一致的过程。分布式一致性强调了多个副本呈现的数据的状态,共识强调多个节点之间对某个提案达成一致的过程。通过共识,实现某种一致性,这种一致性包括某提案的一致性,如选举,下线通知等等,也包括数据的一致性。
共识算法目前有很多种。但根据不同的错误类型可以分为两大类算法:
1、拜占庭问题。恶意伪造导致的错误;
2、非拜占庭。出现故障非恶意伪造。
拜占庭问题:
我觉得一个比较简单明了的解释:
假设有9位将军投票,其中1名叛徒。8名忠诚的将军中出现了4人投进攻,4人投撤离的情况。这时候叛徒可能故意给4名投进攻的将领送信表示投票进攻,而给4名投撤离的将领送信表示投撤离。这样一来在4名投进攻的将领看来,投票结果是5人投进攻,从而发起进攻;而在4名投撤离的将军看来则是5人投撤离。这样各支军队的一致协同就遭到了破坏。
目前存在的算法主要包括PAXOS,RAFT,还有用于区块链的工作量证明、权益证明等等算法。PAXOS,RAFT主要用来解决不存在拜占庭问题的情况,即不存在作弊情况,基本上都是网络抖动,网络出错,系统宕机等问题,因此基本上都是用于系统内部自治,像开源的各种中间件,消息队列,Redis集群等等。而工作量证明,权益证明这些用于区块链等领域的算法就需要考虑拜占庭问题。
共识算法:
- Gossip算法;
- Raft算法;
- ZAB;
- ES选举算法;
一、Gossip算法(论文地址:Gossip论文)
我觉得用一个简单例子来描述gossip比较合适:说一个村里儿,有一家突然有一天发生了一个事儿,女儿嫁给了一个大她20岁的老爷们儿,她邻居先听说了这个事儿,火急火燎地就把这个事儿告诉了和她打麻将的几个人儿,然后这几个人又分别告诉了好朋友,同时第一听说这件事儿的邻居还没闲下来,还再巴巴地和别人说,就这样很快,整个村儿都知道了。一个消息最后所有人都知道了。
Gossip协议就是这样一种,没有中心节点,由最初的一个节点先随机选择几个节点通信,然后知道信息的节点同样再选择几个节点通信,就这样看似杂乱无章地相互通信,最终达到了一致性的一种算法。
这种算法的一个优势是不管是有新节点加入,还是有节点宕机,对现有的网络和在线节点都不会有任何的影响。就算是突然有个新节点加入,也会达到最终一致性。
目前这个算法已经非常成熟了。Redis-Cluster目前采用了这种协议。RedisCluster集群的每个节点都会有两个重要的数据结构,一个是clusterNode,记录了当前节点的状态,一个是clusterState,包含整个集群的状态等信息。clusterState的slots数组存储的是所有槽分配的地址信息,注意和clsuterNode的区别。clusterNode的slots数组记录的就是当前节点的槽分配信息。如果我们想要查某个slot在哪个节点上,直接使用clusterState的slot记录,时间复杂度是O(1)。
在RedisCluster中有几个比较重要的通信类别:
- Meet 通过,当前集群的节点会向新节点发送握手请求,加入现有集群。
- Ping 节点每秒会向集群中其他节点发送 ping 消息,消息中带有自己已知的两个节点的地址、槽、状态信息、最后一次通信时间等。
- Pong 节点收到 ping 消息后会回复 pong 消息,消息中同样带有自己已知的两个节点信息。
- Fail 节点 ping 不通某节点后,会向集群所有节点广播该节点挂掉的消息。其他节点收到消息后标记已下线。
Gossip的特点就是随机冗余发送,最终达到了一致性。但Gossip协议本身也是存在很多的缺点,比如就是通信的冗余,因为就算一个节点收到了某个消息,那么下次仍然有可能收到的,这样就造成了资源的浪费。
RedisCluster的机制是会每100ms发送一次 ping,这里也不是发送给集群中的所有节点,而是随机选择部分节点。一个clusterSendPing会带上当前节点以及其他部分节点的信息发送出去。
其实上面说的clusterSendPing也不能完全保证每个节点都能收到其他节点的消息。因此集群还会每1秒都会发送随机选择5个节点,并从中选择最久没有接受pong消息的节点,发送消息。
此外,还会遍历当前节点中存储的所有其他节点,选择一个最近接受ping消息时间已经超过了cluster_node_timeout/2的就会发送消息。
上面是RedisCLuster使用Gossip来达到最终一致性的。除此之外在选举过程Redis采用的是Raft算法。
二、Raft算法
Raft算法是基于之前的PAXOS算法优化的一种可行性方案,PAXOS本身比较复杂,本文也不做赘述。Raft目前是很多成熟的分布式系统都采用的算法。如Redis-cluster,Nacos,Rocketmq,以及Kafka2.8开始摘除ZK之后,也采用基于Raft的共识机制。
Raft算法大的策略是将问题分治处理,将整个流程分为选举、日志同步、安全性、日志压缩、成员变更等等。
该算法的前提是为系统定义了三个角色:
1、Leader角色。整个系统只有该角色负责处理客户端的请求,并把日志同步给Follower(也是一个角色);
2、Follower角色。一个系统会有多个Follower,他们会接收Leader的日志,并在Leader通知提交日志的时侯进行提交(持久化)。它只能接收请求;
3、Candidate角色。该角色只有在进行Leader选举的时侯才会存在,每一个Follower都可能临时成为 Candidate 。
一个系统在正常运转的时侯,肯定只有一个Leader和多个Follower存在。
下面是一个示意图,我觉得它描述得非常清晰(图片非原创)。

如果一个Follower超过一定时间没有收到Leader角色的心跳,那么它就会等待一段随机的时间发起Leader选举,并将自己也设置为Candidate角色,且投自己一票(当然,你说要投自己一票,让别人也投你,你应该带上自己的最后一条日志的term和log index)。
如果在超时之前获得了大多数的投票,那么自己就变成Leader;如果收到了其他Leader的消息,证明已经有新的Leader,自己还变成Follower;如果没有获得超过一半的投票,那么就等待该次选举周期超时后再发起选举。
每一次选举的周期被称为term,随着选举的不断发生,term不断增大。而Candidate在选举时只选举term更大,index最新的节点。这个周期是非常重要的,他要确保同一个参与选举的角色在一个Term内只能投一票,避免会出现脑裂的情况。
Redis-Cluster采用的就是基于Raft的选举,当某个Master挂掉之后,多个Slave会在间隔一段随机时间后发出广播消息,希望其他Master投它一票,注意这里的随机时间,避免同时发起选举,导致长时间选不出一个master来,不过这样也不能保证发起选举就在一个周期内就会选举成功,这里导致一个问题是,RedisCluster本身也是CP模式的,Master到Slave数据同步是异步的,可能会出现数据丢失的情况。
Raft日志同步:
Raft算法除了可以用在上面的master选举意外,还可以用于日志同步。
思想: Leader接收客户端的请求后,会并行地向所有Follower以日志的形式发送,当有半数以上的Follower成功提交了日志,那么才会告知客户端成功提交了。每个日志都会包括term和索引index,以及真正要执行的指令。
那么Follower是如何处理Leader发来的日志呢?
首先Follower会将index-1的内容和Leader的进行对比,如果一致,就返回true.如果不等,就返回false,Leader收到false,会减小index值,重新发送,直到最后内容相同,Follower之后的内容都会被覆盖。
到此为止,可以看到Raft为每个日志都分配了term和index保证唯一性,此外,它也强制Follower必须要和当前的Leader保持一致。
官方描述:
- leader为每个follower维护一个 nextIndex ,表明下一个将要发送给follower的log entry
- 当leader刚上任时,会把所有的 nextIndex 设置成其最后一个log entry的index加1,如上图,则是11
- 当follower的日志和leader不一致时,一致性检查会失败,那么会把 nextIndex 减1
- 最终 nextIndex 会是leader和follower相同log entry的index加1,这时候,再发送
AppendEntries会成功,并且会把follower的所有之后不一致的日志删除掉。
Nacos的CP模式用的就是Raft算法,不过其是用了阿里改造的SOFA-Jraft。
三、ZAB协议
该协议是在zookeeper中应用的一种一致性协议,它有很多和Raft相似的地方。比如都是由leader发起写操作,都采用心跳来检测存活性,在选举过程中也都采用谁先获得多数投票谁就成为Leader。但ZAB又有很多独特的地方。如ZAB的Observer不参与请求,只提供给客户端的读请求。
ZAB全称是Zookeeper Atomic Broadcast,zookeeper原子广播协议,字面意思就可知该协议是基于广播进行的。
Zookeeper主要有两种模式,崩溃恢复和广播模式,它就是在这两种模式下切换。
崩溃恢复和Raft的选举过程也很类似,也是在Leader崩溃之后,Follower选择出一个新的Leader(也是获得超过一半的投票)。但投票条件不同,ZAB要求Follower在投票给一个节点前,必须和该节点的日志保证一致,而Raft没这要求,谁term高就给谁投。ZAB的投票参考因素是ZXID,是一个事务的序号,是不断递增的一个值。ZXID是一个64位数字,高32位表示每一代Leader(epoch),低32位表示事务的ID(count)。
那么可能问了,如果Leader在提交事务后崩溃了或者在把日志复制给Follower时,新Leader会继续处理吗?针对该问题,ZAB协议保证了两点:
1、已经被Leader的事务会被提交;
2、已经被Leader跳过的事务不会再执行;
日志复制和Raft处理方式也是大体一样,也是收到半数以上Follower的Ack后,才会提交事务。区别是ZAB中引入了一个队列,并将带有ZXID的日志按顺序发送给所有Follower,相比于Raft,ZAB实现了解耦。
广播模式的具体流程:
1、不论是zk集群的哪个机器收到了写请求,就算是follower收到了,它首先是将请求转发给leader服务器,leader负责具体的写请求处理;
2、leader生成proposal提案,并生成一个全局的ZXID,在后续的恢复模式中是很重要的一个标识。然后通过与每个follwer的队列(FIFO)发送给follower;ZXID在上面已经提到了,官方的对其的定义:
-
Every change to the ZooKeeper state receives a stamp in the form of a zxid (ZooKeeper Transaction Id). This exposes the total ordering of all changes to ZooKeeper. Each change will have a unique zxid and if zxid1 is smaller than zxid2 then zxid1 happened before zxid2.
3、follower收到消息后,会将数据持久化到硬盘,随后向leader发送一个ACK;
4、当leader收到集群一半以上的follower发送的ACK,就会向所有的follower发送commit;
5、follower收到leader发送的commit消息后,就将数据载入内存,供客户端读取。
下面这张图(非原创)比较清晰描述了上个过程,但该图有个问题,就是请求不一定就是发送给leader,可以发送给ZK集群任意一个节点,只不过是如果请求是写请求的话,follower会转发给leader。
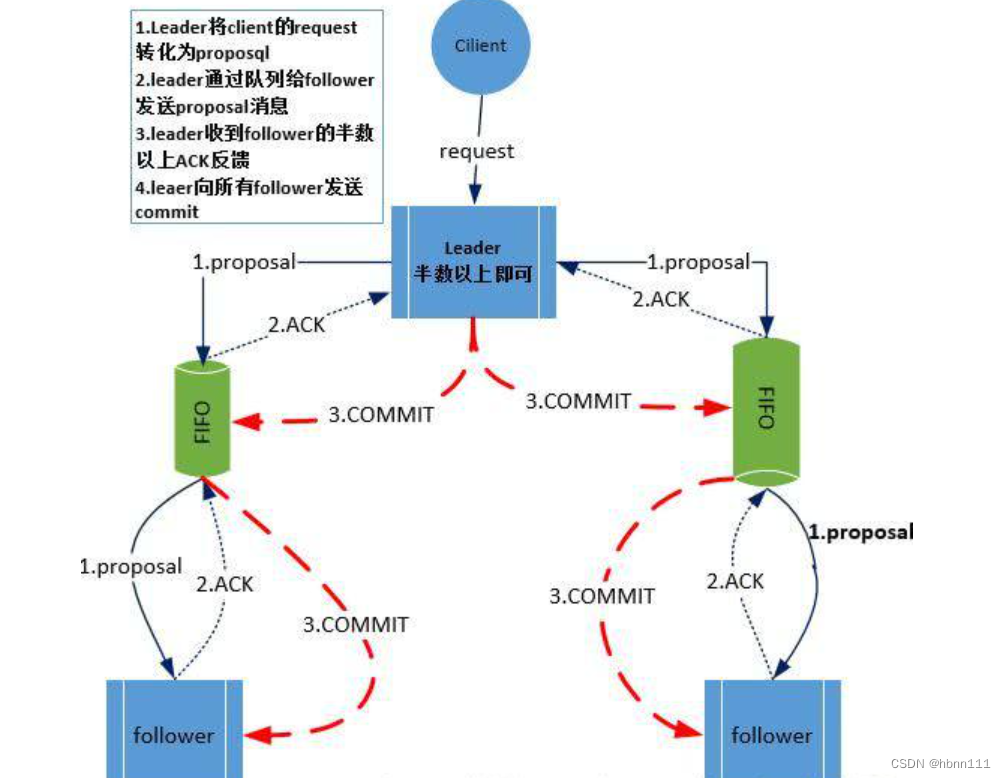
其实上面也是一个分布式事务的实现,通过三阶段提交实现事务。关于分布式事务的介绍可以参见: 分布式事务
四、ES选举Bully算法
ES的选举并没有采用常用的Raft算法,而是使用Bully算法。其基础是为集群的每个节点都分配一个唯一id。ES会为整个集群的每个node分配一个唯一的id,这个id是node在启动时随机分配的。此外,每个节点都会有一个版本号clusterVersion,该字段代表的是状态值,master节点一定是拥有最新版本号的节点。
ES里的节点分成Master节点,Master候选节点和数据节点。角色需要通过配置来做。Master节点对应Raft的Leader,Master候选节点也是对应Follower和Candidate。
那么当发现Master节点下线时,候选节点投票的原则是首先选择版本号更高的,如果版本号都相同,就选择id最小的。和Raft相同的是,同样是要求一半以上投票的节点才可成为Master节点,但和Raft不同的是,ES并没有完全避免脑裂的问题,这也是ES选举过程存在的最大问题,之所以会出现脑裂是因为虽然也是获得绝大多数投票的才能成为master,但是他并没有限制一个节点只能投一票,如果一个节点在投票后迟迟等不到选举的结果,可能又开始投票,此时因为优先级的问题又投票给其他节点了,就意味着这个节点投了两票给不同节点,就会出现问题。这种问题Raft算法解决的就很好,Raft引入了Term的概念,一个Term周期内,一个节点只能投一票。Term大的优先级高。
参考资料:

