
热门标签
热门文章
- 1清华计算机系录取,高考696,全省第8被清华计算机学院录取!自述回忆高考和深圳中学...
- 27种RAG工具,让你的LLMs发挥最大效用_哪个rag比较好用
- 3flask中ORM的使用_flask orm
- 42024不可不会的StableDiffusion之变分自编码器(三)_stable diffusion vae_encoder vae_decoder
- 5Vs code task.json配置文件解读_vscode tasks.json配置详解
- 6python 字典dict修改、新增、删除键值_python 修改dict值
- 7Ubuntu22.04安装Hive3.1.2 metastore远程模式部署MySQL8.0.34_ubuntu安装配置hive3.1.2
- 8AI绘画简述
- 9pod的初始化容器是干什么的_初始化容器的作用
- 10IDEA使用git大致流程_idea git提交
当前位置: article > 正文
CV领域-AI模型推理速度评价指标_ai模型推理性能指标是什么
作者:小丑西瓜9 | 2024-05-13 09:25:09
赞
踩
ai模型推理性能指标是什么
模型大小评估指标
目前常用于评价模型大小的指标有:计算量、参数量、访存量、内存占用等,这些指标从不同维度评价了模型的大小。
- 1
计算量
计算量可以说是评价模型大小最常用的指标了,很多论文在跟 baseline 进行比较时,都会把计算量作为重要的比较依据。
计算量是模型所需的计算次数,反映了模型对硬件计算单元的需求。计算量一般用 OPs (Operations) ,即计算次数来表示。由于最常用的数据格式为 float32,因此也常常被写作 FLOPs (Floating Point Operations),即浮点计算次数。
模型的整体计算量等于模型中每个算子的计算量之和。而每个算子的计算量计算方法各不一致。例如对于 Eltwise Sum 来讲,两个大小均为 (N, C, H, W) 的 Tensor 相加,计算量就是 N x C x H x W;而对于卷积来说,计算量公式为(乘加各算一次):
- 1
- 2
- 3
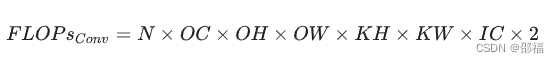 PyTorch 有不少工具可以模型计算量,但需要注意的是这些工具有可能会遗漏一些算子的计算量,将其计算量算成 0,从而导致统计的计算量跟实际计算量有轻微的偏差,不过大多数情况下这些偏差影响不大。
PyTorch 有不少工具可以模型计算量,但需要注意的是这些工具有可能会遗漏一些算子的计算量,将其计算量算成 0,从而导致统计的计算量跟实际计算量有轻微的偏差,不过大多数情况下这些偏差影响不大。
参数量
早期的论文也很喜欢用参数量来评价模型大小。
参数量是模型中的参数的总和,跟模型在磁盘中所需的空间大小直接相关。对于 CNN 来说参数主要由 Conv/FC 层的 Weight 构成,当然其他的一些算子也有参数,不过一般忽略不计了。
参数量往往是被算作访存量的一部分,因此参数量不直接影响模型推理性能。但是参数量一方面会影响内存占用,另一方面也会影响程序初始化的时间。
参数量会直接影响软件包的大小。当软件包大小是很重要的指标时,参数量至关重要,例如手机 APP 场景,往往对 APK 包的大小有比较严格的限制;此外有些嵌入式设备的 Flash 空间很小,如果模型磁盘所需空间很大的话,可能会放不下,因此也会对参数量有所要求。
除了在设计模型时减少参数量外,还可以通过压缩模型的方式降低软件包大小。例如 Caffe 和 ONNX 采用的 Protobuf 就会对模型进行高效的编码压缩。不过压缩模型会带来解压缩开销,会一定程度增加程序初始化的时间。
- 1
- 2
- 3
- 4
- 5
访存量
访存量往往是最容易忽视的评价指标,但其实是现在的计算架构中对性能影响极大的指标。
访存量是指模型计算时所需访问存储单元的字节大小,反映了模型对存储单元带宽的需求。访存量一般用 Bytes(或者 KB/MB/GB)来表示,即模型计算到底需要存/取多少 Bytes 的数据。
和计算量一样,模型整体访存量等于模型各个算子的访存量之和。对于 Eltwise Sum 来讲,两个大小均为 (N, C, H, W) 的 Tensor 相加,访存量是 (2 + 1) x N x C x H x W x sizeof(data_type),其中 2 代表读两个 Tensor,1 代表写一个 Tensor;而对于卷积来说,访存量公式为:
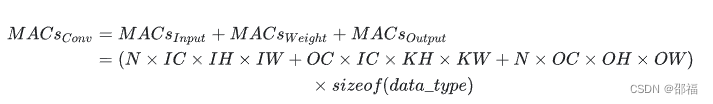
访存量对模型的推理速度至关重要,设计模型时需要予以关注。
- 1
- 2
- 3
- 4
- 5
- 6
内存占用
内存占用是指模型运行时,所占用的内存/显存大小。一般有工程意义的是最大内存占用,当然有的场景下会使用平均内存占用。这里要注意的是,内存占用 ≠ 访存量。
内存占用在论文里不常用,主要原因是其大小除了受模型本身影响外,还受软件实现的影响。例如有的框架为了保证推理速度,会将模型中每一个 Tensor 所需的内存都提前分配好,因此内存占用为网络所有 Tensor 大小的总和;但更多的框架会提供 lite 内存模式,即动态为 Tensor 分配内存,以最大程度节省内存占用(当然可能会牺牲一部分性能)。
和参数量一样,内存占用不会直接影响推理速度,往往算作访存量的一部分。但在同一平台上有多个任务并发的环境下,如推理服务器、车载平台、手机 APP,往往要求内存占用可控。可控一方面是指内存/显存占用量,如果占用太多,其他任务就占用量不会大幅波动,影响其他任务的可用性。
- 1
- 2
- 3
小结
计算量、参数量、访存量、内存占用从不同维度定义了模型的大小,应根据不同的场合选用合适的指标进行评价。
模型推理速度不单单受模型计算量的影响,也与访存量和一些其他因素息息相关。下文将详细讨论影响模型推理速度的因素。
- 1
- 2
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/562967
推荐阅读
相关标签

