
热门标签
热门文章
- 1SpringMVC输出数据_springmvc流式输出数据
- 240%算力训练效果比肩GPT-4,实测DeepMind联创大模型创业新成果
- 3栈和队列(详细版,一看就懂。包含栈和队列的定义、意义、区别,实现)
- 4Flask 使用 JWT(二)
- 5vscode终端加git的方法_vscode添加git终端
- 6Git使用小技巧【修改commit注释, 超详细】_git更改commit描述
- 7web3系列———4.编写第一个智能合约并发布到链上_remixweb3
- 8git优点缺点(简单介绍)
- 9ECharts饼状图中使用点击事件来跳转到新的页面链接_echarts饼图跳转
- 10A*(A-star)算法 定义+特性+原理+公式+Python示例代码(带详细注释)_pythin a星算法源码
当前位置: article > 正文
python实现将深度学习应用于医学图像以辅助医疗_python 医学影像
作者:小丑西瓜9 | 2024-05-14 11:40:00
赞
踩
python 医学影像
转自fc013,仅做学习用
问题导读:
1.怎样利用python处理图像?
1.怎样利用python处理图像?
2.什么是卷积?
3.什么是Keras?
运用深度学习技术进行图像和视频分析,并将它们用于自动驾驶汽车、无人机等多种应用场景中已成为研究前沿。近期诸如《A Neural Algorithm of Artistic Style》等论文展示了如何将艺术家的风格转移并应用到另一张图像中,而生成新的图像。其他如《Generative Adversarial Networks》(GAN)以及「Wasserstein GAN」等论文为开发能学习生成类似于我们所提供的数据的模型做了铺垫。因此,它们在半监督学习领域打开了新世界的大门,也为将来的无监督学习奠定了基础。
尽管这些研究领域处于通用图像层面,但我们的目标是将它们应用于医学图像以辅助医疗。我们需要从基础开始。本文第一部分将从图像处理的基础、医学图像格式化数据的基础以及一些可视化的医疗数据谈起。而后一部分文章将深入探究卷积神经网络,并使用 Keras 来预测肺癌。
基本图像处理(利用 python 实现)
图像处理库有很多,但 OpenCV(开源计算机视觉库,open computer vision)凭借其广泛的支持且可用于 C++、java 和 python 的优点而成为主流。而我更偏向于使用 jupyter notebook 导入 OpenCV。
你可以使用 pip install opencv-python,也可以从 opencv.org 网站直接进行安装。

安装 opencv
现在打开 Jupyter notebook 并确认能够导入 cv2。你还需要 numpy 和 matplotlib 库来在 notebook 内查看图片。

现在来检查能否打开并通过键入下述代码在笔记本上查看图像。

通过 OpenCV 进行图像加载的示例
基本人脸识别
我们来做点有意思的事情吧,比如人脸识别。我们将使用一种最初由 Rainer Lienhart 开发的正面人脸识别器,它使用了基于开源 xml 残基(stump-based)的 20x20 柔和 adaboost 算法。
关于 Haar-cascade 检测的详细范例:
http://docs.opencv.org/trunk/d7/ ... face_detection.html

使用 OpenCV 进行人脸识别
在文档区使用 opencv 进行图像处理的例子不胜枚举。
我们已经了解了图像处理的基础,下面来了解医学图像格式吧。
医学图像数据格式
医学图像以数字成像和通信(DICOM)为存储与交换医学图像数据的标准解决方案。该标准的第一版发布于 1985 年,之后有少许修改;它使用了文件格式和通信协议如下。
文件格式:所有患者的医疗图像都以 DICOM 文件格式进行保存。该格式不仅具有与图像相关的数据(如用于捕获图像的设备和医疗处理情境),还具有关于患者的 PHI (受保护的健康信息,protected health information),如姓名、性别、年龄等。医疗影像设备可以创建 DICOM 文件,而医生可以使用 DICOM 查看器以及可显示 DICOM 图像的计算机应用程序来读取并诊断从图像获得的结果。
通信协议:DICOM 通信协议用于搜索档案中的成像研究,并将成像研究恢复到工作站来显示。连接到医院网络的全部医学成像应用程序都使用 DICOM 协议来交换信息,其中大部分信息是 DICOM 图像,但还包括患者和手术信息。此外还有更先进的网络命令用于控制并跟踪治疗、调整进程、报告状态,并在医生和成像设备之间共享工作负载。
现有篇博文很细致地描述了 DICOM 标准,此处为链接:
http://dicomiseasy.blogspot.com/
分析 DICOM 图像
Pydicom 是一个 python 包,它很适合分析 DICOM 图像。本节将阐述如何在 Jupyter notebook 上呈现 DICOM 图像。
安装 Pydicom 使用:pip install pydicom。
安装 pydicom 包之后,回到 Jupyter notebook 进行操作。在 notebook 中导入 dicom 包以及其他包,如下所示:
我们也能使用 pandas、scipy、skimage 以及 mpl_toolkit 等其他的包来进行数据处理与分析。

你可以在线获得很多免费的 DICOM 数据集,但下述数据集在入门阶段定能有所帮助:
Kaggle Competitions and Datasets:它是我的最爱。请查阅肺癌竞争和糖尿病视网膜病变的数据:
https://www.kaggle.com/c/data-science-bowl-2017/data
Dicom Library:面向教育和科学的 DICOM 库,其提供免费的在线医疗 DICOM 图像或视频文件共享服务。
Osirix Datasets:提供通过各种成像模式获取的大量人类数据集。
Visible Human Datasets:在这里可视化人类计划的一部分数据可以免费利用,这很奇怪,因为获取这些数据既不免费也不轻松。
The Zubal Phantom:该网站免费提供 CT 和 MRI 这两种男性的多个数据集。
请下载 dicom 文件并加载到 jupyter notebook 中。

现在将 DICOM 图像加载到列表中。
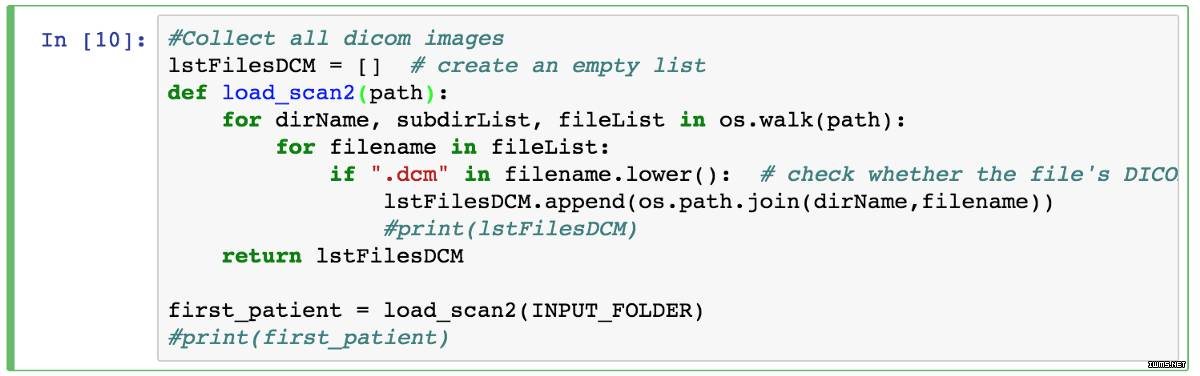
第一步:在 Jupyter 中进行 DICOM 图像的基本查看操作

在第一行加载第一个 DICOM 文件来提取元数据,这个文件将赋值为 RefDs,其文件名会列在 lstFilesDCM 列表的顶端。

然后来计算 3D NumPy 数组的总维度,它等于在笛卡尔坐标轴中(每个切片的像素行数*每个切片的像素列数*切片数)。最后,使用 PixelSpacing 和 SliceThickness 属性来计算三个轴之间的像素间距。我们将把数组维度储存在 ConstPixelDims 中,把空间储存在 ConstPixelSpacing [1] 中。
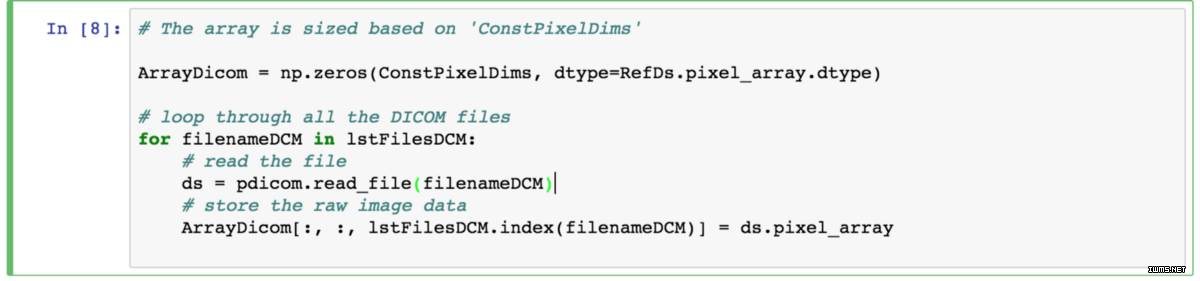
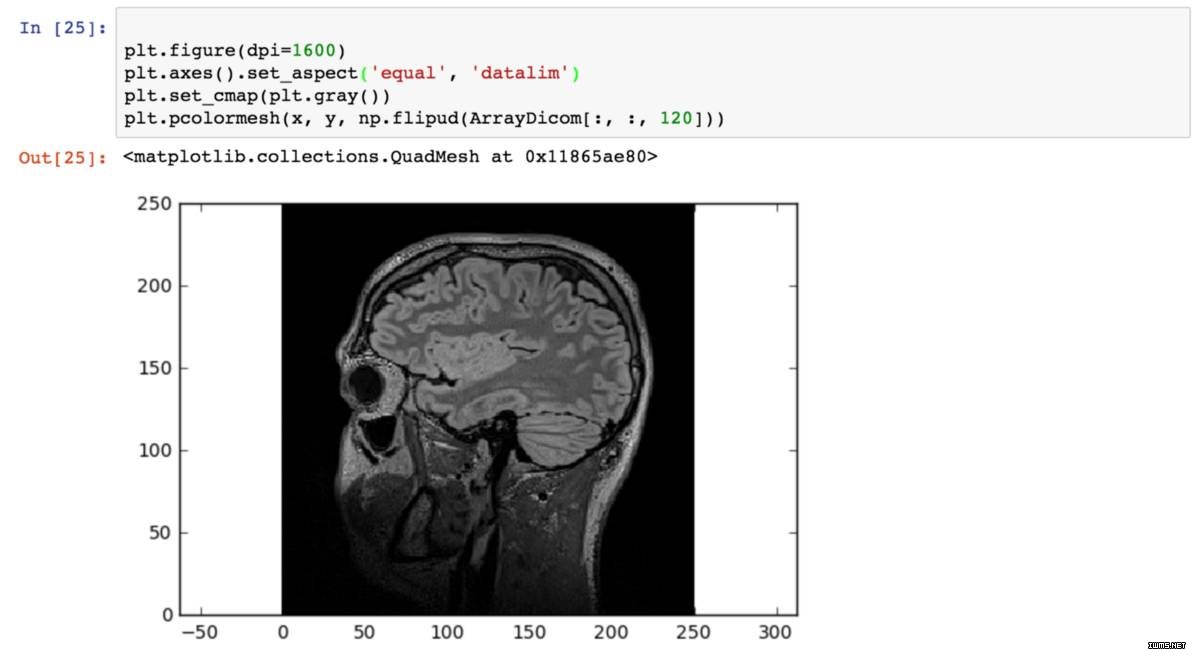

第二步:查看 DICOM 格式的细节
CT 扫描中的测量单位是亨氏单位(Hounsfield Unit,HU),它是辐射强度的度量。CT 扫描仪经过高度校准以精确测量。
每个像素都被分配了一个数值(CT 号),它是包含在相应体素(corresponding voxel)中的所有衰减值的平均数。将这个数字与水的衰减值进行比较,并以任意单位中的亨氏单位(HU)为刻度进行显示。
这个刻度将水的衰减值(HU)标为 0。CT 数量的范围是 2000HU,但一些现代扫描仪具有较高的 HU 范围,最高可达 4000。每个数字表示在光谱的其中一端会出现+1000(白色)和-1000(黑色)的灰色阴影。
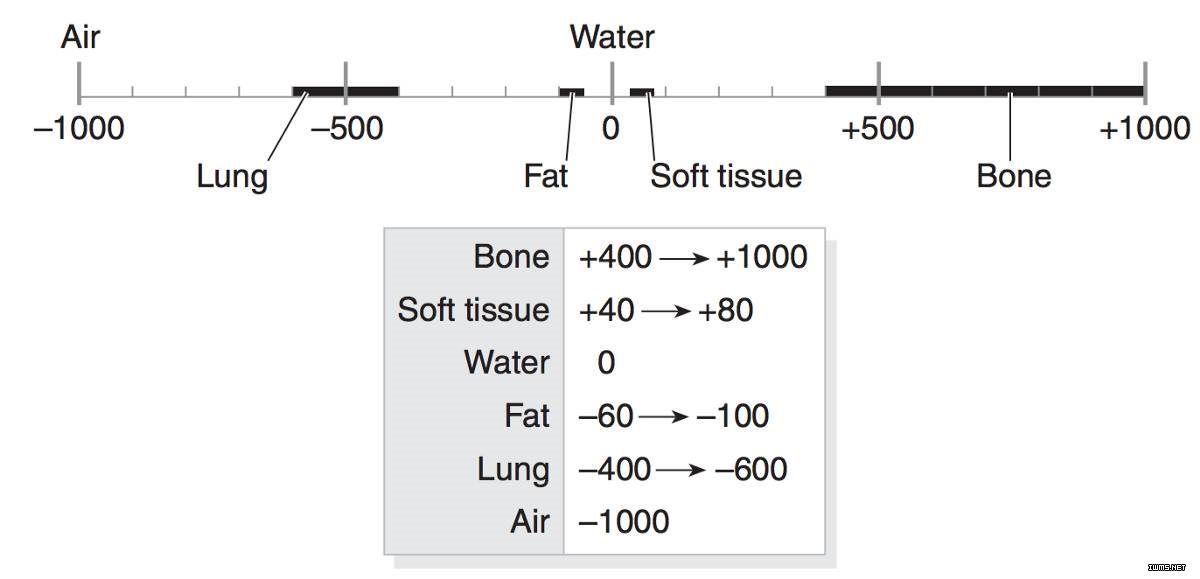
一些扫描仪具有圆柱形扫描范围,但其输出图像却是矩形。落在这些边界之外的像素具有-2000 的固定值。

第一步通常是将这些值设置为 0。接着,通过与重新缩放的斜率相乘并添加截距来返回到亨氏单位(斜率和截距均很方便地存储在扫描的元数据中!)。
下部分将会用到 Kaggle 的肺癌数据集,并使用 Keras 卷积神经网络进行建模;它将以上文所提供的的信息为基础。
在上一部分文章中,我们介绍了一些使用 OpenCV 进行图像处理的基础知识,以及 DICOM(医学数字影像和通讯)图像基础。下面我们将从卷积神经网络(Convolutional Neural Nets)的视角来谈一谈深度学习基础。在第三部分文章里,我们将以 Kaggle 的肺癌数据集为实例,来研究一下在一个肺癌 DICOM 图像中要寻找的关键信息,并使用 Kera 开发出一个预测肺癌的模型。
卷积神经网络 (CNN) 基础
为了理解卷积神经网络的基础,我们首先要搞清楚什么是卷积。
什么是卷积?
那么在泛函分析中,卷积(Convolution)是通过两个函数 f 和 g 生成第三个函数的一种数学算子,表征函数 f 与 g 经过翻转和平移的重叠部分的面积。所以在简单定义下,设 f(x)、g(x) 是 R 上的两个可积函数,作积分:
则代表卷积。理解这个定义的简单方式就是把它想象成应用到一个矩阵上的滑动窗方程。
有着 3×3 过滤器的卷积。
在上面的图片中,应用到矩阵上的滑动窗是绿色,而滑动窗矩阵则是红色。输出就是卷积特征矩阵。下面的图片显示了两个矩形脉冲(蓝色和红色)的卷积运算及其结果。
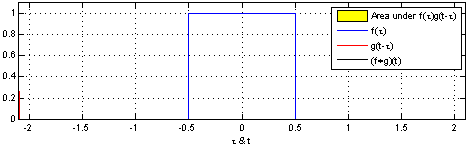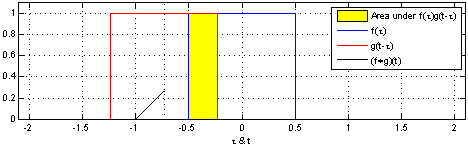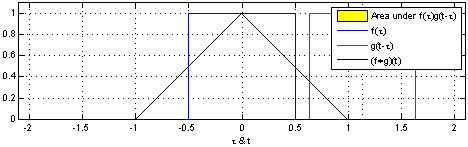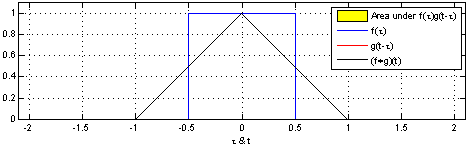
Jeremy Howard 在他的 MOOC 上用一个电子表格解释了卷积,这是理解基础原理的一种很好的方式。现在有两个矩阵,f 和 g。f 和 g 进行卷积运算的结果,是第三个矩阵「Conv layer 1」,它由两个矩阵的点积给出。如下所示,这两个矩阵的点积是一个标量。
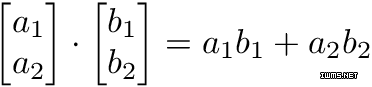
两个矩阵的点积。
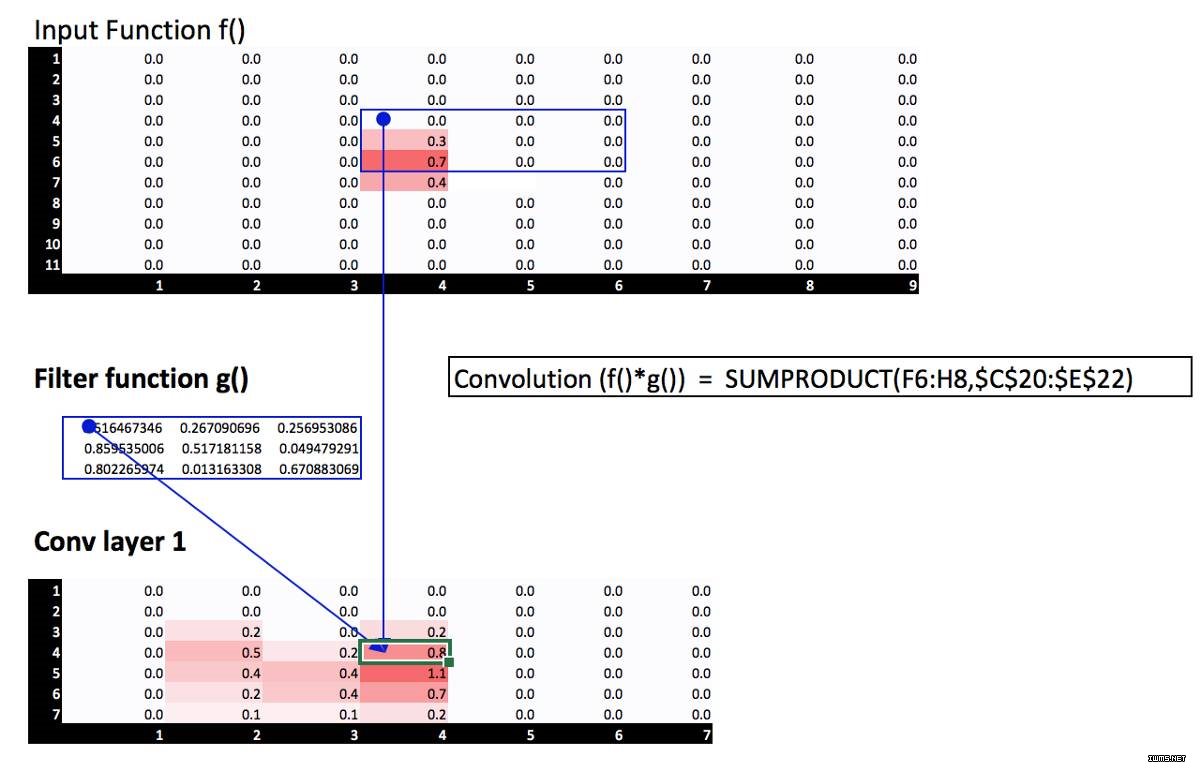
现在让我们按照 Jeremy 的建议用电子表格来演示一下,输入矩阵是函数 f(),滑动窗矩阵是过滤器方程 g()。那么这两个矩阵元素的乘积和就是我们要求的点积,如下所示。
让我们把这个扩展到一个大写字母「A」的图片。我们知道图片是由像素点构成的。这样我们的输入矩阵就是「A」。我们选择的滑动窗方程是一个随机的矩阵 g。下图显示的就是这个矩阵点积的卷积输出。

什么是卷积神经网络 (CNN) ?

在我看来,一个简单的卷积神经网络 (CNN) 就是一系列神经网络层。每一层都对应着一个特定的函数。每个卷积层是三维的(RGB),所以我们用体积作为度量。更进一步的,CNN 的每一层都通过一个微分方程向另一层传递一个体积量的激活。这个微分方程被称为激活函数或传递函数。
CNN 的实体有多种:输入,滤波器(或核函数)、卷积层、激活层、池化层、以及批量归一化层。这些层在不同排列和不同规则下的组合形成了不同的深度学习算法。
输入层:通常一个 CNN 的输入是一个 n 维阵列。对于一个图像来说,就是三个维度的输入——长度,宽度和深度(即颜色通道)。
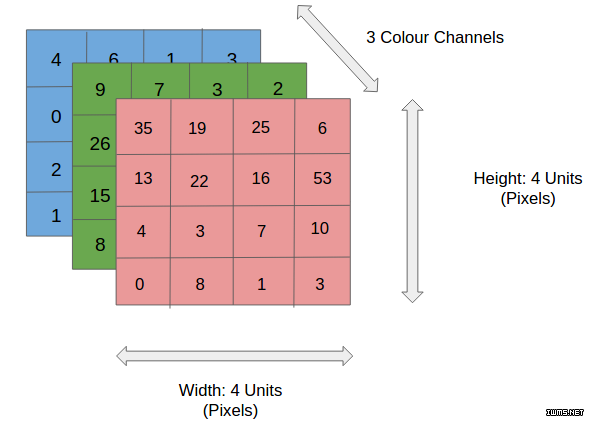
过滤器或核函数:正如下面这张来自 RiverTrail 的图像所示,一个过滤器或核函数会滑到图像的每个位置上并计算出一个新的像素点,这个像素点的值是它经过的所有像素点的加权和。在上面的电子表格例子中,我们的过滤器就是 g,它经过了 f 的输入矩阵。
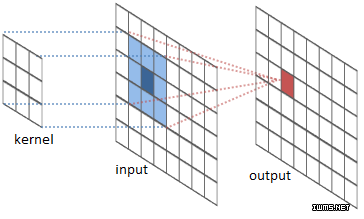
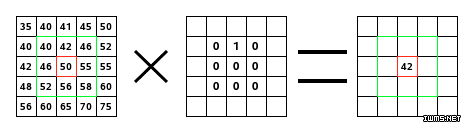
下面的网址中有一个很好的解释填补、跨步和转置是如何工作的视觉图表。

激活层:
激活函数可根据是否饱和分为两种类型。
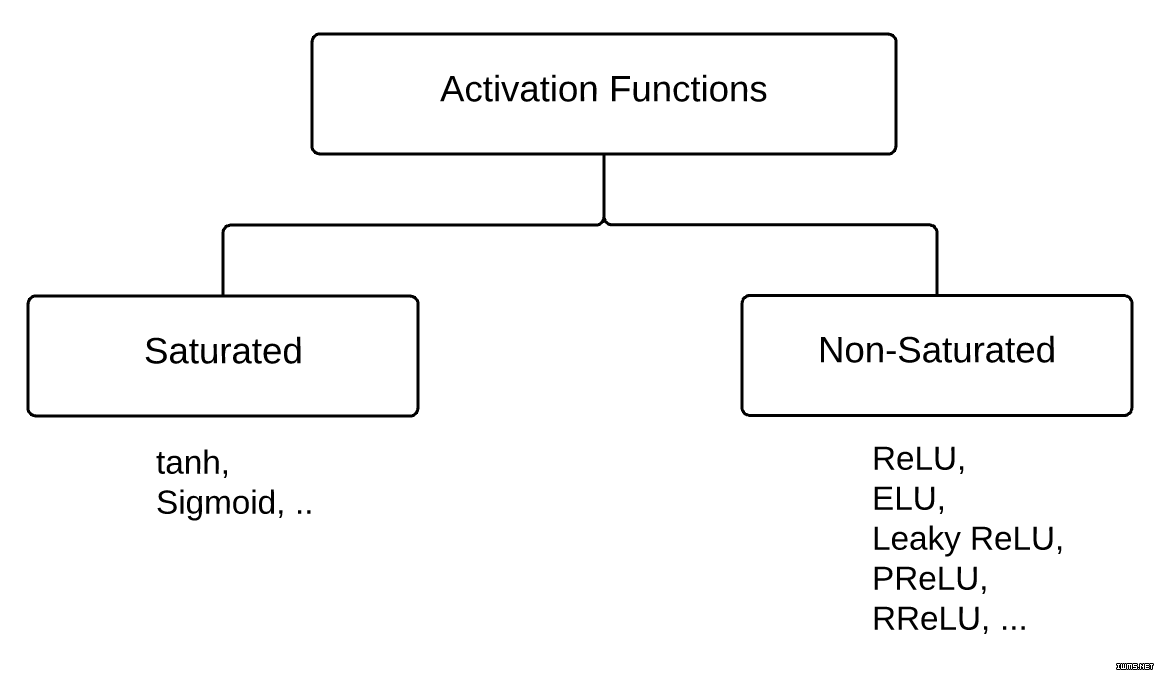
饱和激活函数都是双曲型和双曲正切型,而非饱和激活函数都是修正线性单元(ReLU)及其变体函数。使用非饱和激活函数有两方面的优势:
第一是可以解决所谓的「爆炸/消失梯度(exploding/vanishing gradient)」。
第二是可以加快函数收敛速度。
双曲函数:把一个实数值输入挤压到 [0,1] 区间范围内
σ(x) = 1 / (1 + exp(−x))
双曲正切函数:把一个实数值输入挤压到 (-1,1)区间内
tanh(x) = 2σ(2x) − 1
ReLU
ReLU 代表单调线性单元(Rectified Linear Unit)。它是输入为 x 的最值函数 (x,0),比如一个卷积图像的矩阵。ReLU 接着把矩阵 x 中的所有负值置为零,并保持所有其他值不变。ReLU 是在卷积之后计算出来的,因此会出现一个非线性的激活函数,如双曲正切或双曲函数。Geoff Hinton 在他的 nature 论文里第一次讨论这个问题。
ELUs
指数线性单元(Exponential linear units)试图使平均激活接近于零,这样就能加速学习。ELUs 也能通过正值认定避免消失梯度的出现。研究显示,ELUs 比 ReLUs 有更高的分类准确性。
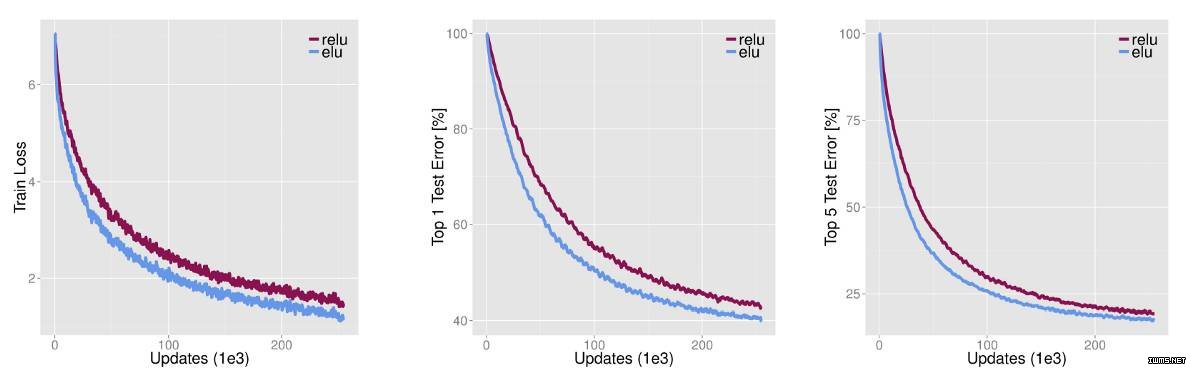
来源:
http://image-net.org/challenges/ ... _Schwarz_poster.pdf [(1×96×6, 3×512×3, 5×768×3, 3×1024×3, 2×4096×FC, 1×1000×FC) 层 × 单元 × 接受域或完全连接(FC)的堆叠构成的 15 层 CNN。2×2 的最大池化,每次堆叠后有 2 步幅,第一个 FC 之前有 3 层的空间金字塔池。]
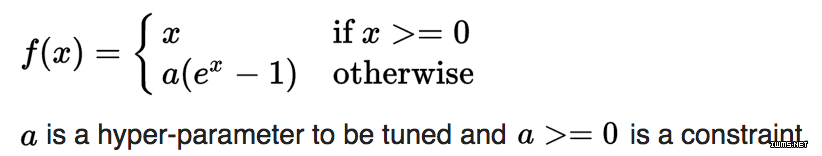
来源:维基百科
渗漏 ReLU
ReLU 中的负值部分完全被抛弃,与之相反,渗漏 ReLU 给负值部分赋了一个非零斜率。渗漏修正线性激活在声子模型(Maas et al., 2013)中第一次被引入。数学上,我们有
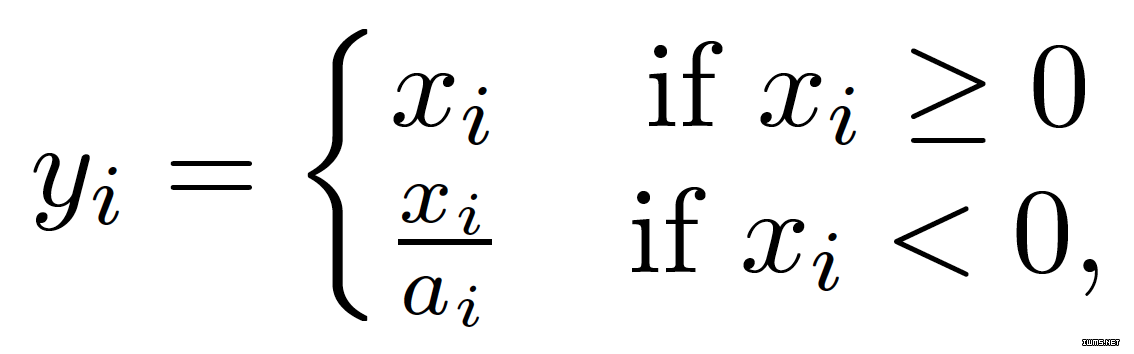
来源:卷积网络中修正激活的经验主义演化
其中 ai 是在 (1, 正无穷) 区间内的固定参数。
参数化修正线性单元 (PReLU)
PReLU 可被视为渗漏 ReLU 的一个变体。在 PReLU 中,负值部分的斜率是从数据中学习得来的,而非预先定义好的。PReLU 的创作者们声称它是 ImageNet 归类(Russakovsky et al., 2015) 任务中(机器)超越人类水平的关键因素。它与渗漏 ReLU 基本相同,唯一的区别就是 ai 是通过反向传播训练学习到的。
随机渗漏修正线性单元 (RReLU)
随机渗漏单调线性单元 (RReLU) 也是渗漏 ReLU 的一种变体。在 RReLU 中,负值部分的斜率是在给定训练范围内的随机取值的,然后在测试中固定下来。RReLU 最显著的特征是在训练过程中,aji 是一个从一致分布 U(l,u) 上取样得到的随机数。正式数学表达如下:
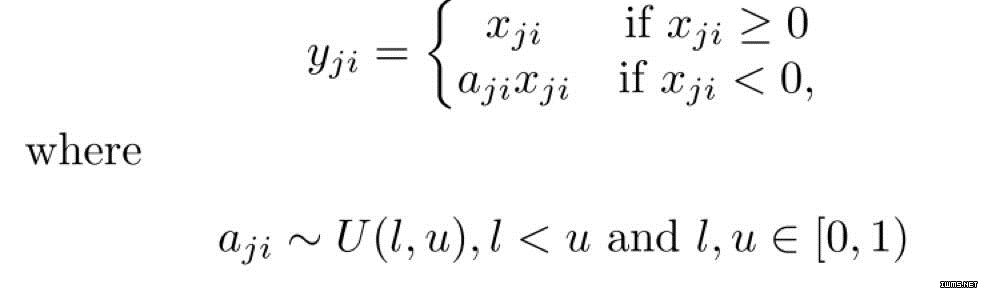
下面显示了 ReLU, 渗漏 ReLU, PReLU 和 ReLU 的对比。

来源::
https://arxiv.org/pdf/1505.00853.pdf。ReLU, 渗漏 ReLU, PReLU 和 ReLU,对于 PReLU,ai 是学习到的;而对于渗漏 ReLU,ai 是固定的。对于 RReLU,aji 是一个在给定区间内取样的随机变量,在测试中保持不变。
噪声激活函数
这些都是拓展后包括了 Gaussian 噪声(Gaussian noise)的激活函数。
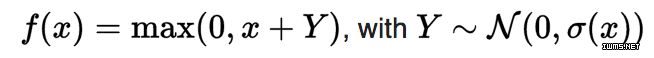
来源:维基百科
池化层
池化层的目标是逐渐地减少矩阵的尺寸,以减少网络中参数的数量和计算,这样也就能控制过拟合。池化层在输入的每个深度切片上独立操作,并使用最大化和平均运算来重置其空间尺寸。最常见的形式,一个采用了步幅 2,尺寸 2x2 过滤器的池化层,同时沿着宽度和高度,以幅度 2 将输入中的每个深度切片向下取样,丢弃了激活值的 75%。在此情况下,每个最大值运算都取了 4 个数字(某些深度切片中的小 2x2 区域)的最大值。深度方向的维度保持不变。更一般的来说,池化层就是:
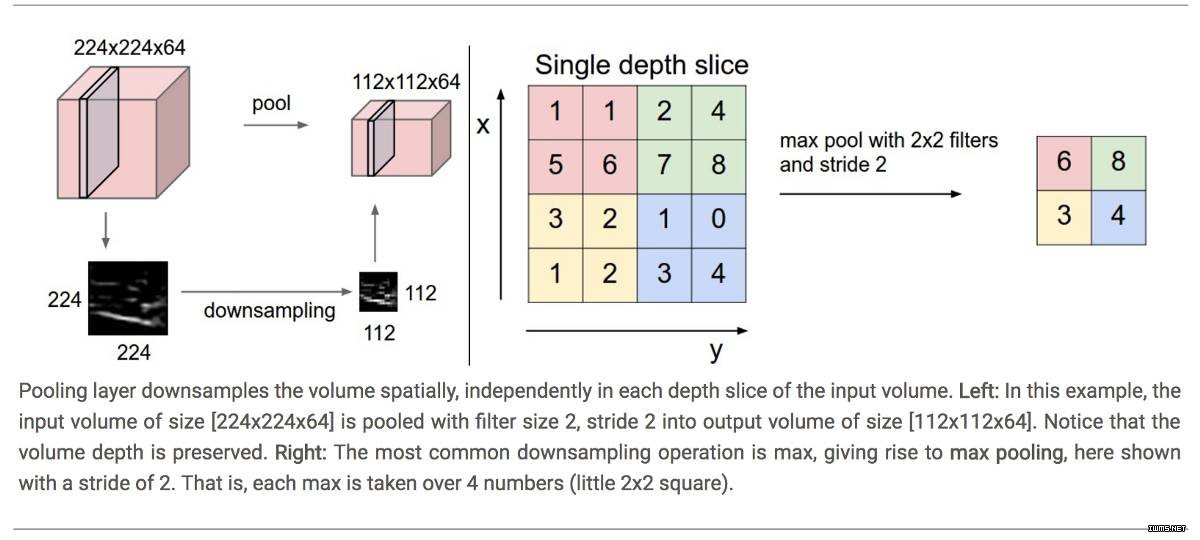
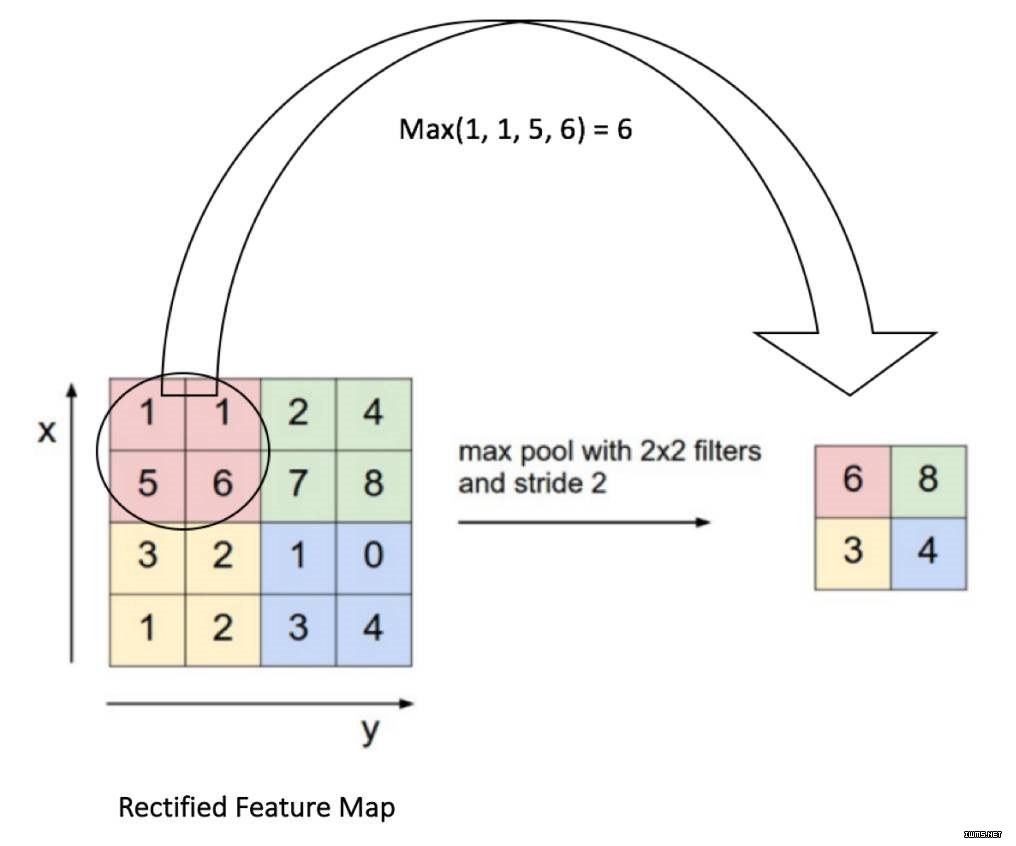
注意:这里我们把 2 x 2 window 滑动了两个细胞(也被叫做步幅),并取了每个区域的最大值。
批归一化层:
批归一化是归一化每个中间层的权重和激活函数的有效方式。批归一化有两个主要的好处:
1. 对一个模型加入批归一化能使训练速度提升 10 倍或更多
2. 由于归一化极大降低了偏远输入的小数字过度影响训练的能力,它也能降低过拟合。
全连接层:
全连接层是一个传统的多层感知器(Multi Layer Perceptron),它在输出层使用了一个Softmax 函数。「全连接」这个术语就说明了前一层和后一层的每个神经元都是连接起来的。Softmax 函数即对数函数(logistic function)的一般化情况,它把一个取值区间为任意实数的K 维向量「挤压」成一个取值区间在(0,1)内且和为1的K 维向量。
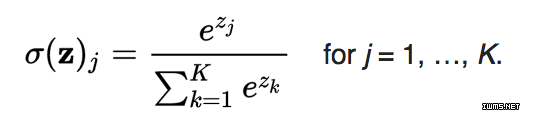
来源:维基百科
Sofxmax 激活一般被用于最终的完全连接层,随着它的值在 0 和 1 之间不停变化,得到概率。
现在我们对 CNN 中不同的层次都有了一定的概念。运用这些知识我就能开发出肺癌探测所需的深度学习算法。
第三部分
在最后一部分中,我们将透过卷积神经网络讨论一些深度学习的基础知识。在本文中,我们将侧重于使用 Keras 和 Theano 的基础深入学习。我们将给出两个范例,一个使用 Keras 进行基本预测分析,另一个使用 VGG 的图像分析简单样例。
我已经意识到这个话题的广度和深度,它需要更多的文章来解读。在之后的文章中,我们将讨论处理中 DICOM 和 NIFTI 在医学成像格式中的不同,进一步扩大我们的学习范围并对如何对 2 维肺分割分析使用深度学习进行讨论。然后转到 3 维肺分割。我们同样会讨论如何在深度学习之前进行医学图像分析以及我们现在可以如何做。我非常开心也非常感谢我的新合作伙伴将这一切聚在一起——Flavio Trolese(4Quant 的合作伙伴)、 Kevin Mader(4Quant 的联合创始人)以及 Cyriac Joshy(瑞士苏黎世联邦理工的讲师)。
在本文中,我们将要讨论 Keras 并使用两个范例来展示如何使用 Keras 进行简单的预测分析任务以及图像分析。
什么是 Keras?
Keras 网站是这么介绍的——Keras 是 Theano 和 TensorFlow 的深度学习库。
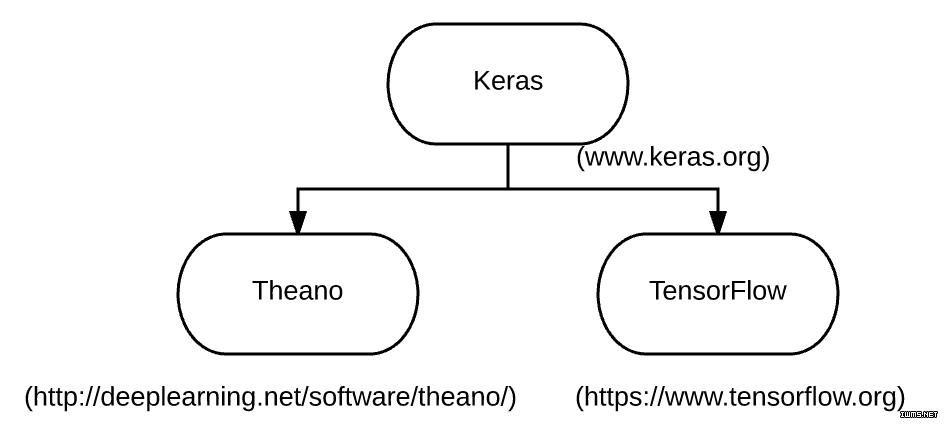
Keras API 在 Theano 和 TensorFlow 之上运行。
Keras 是高级的神经网络 API,由 Python 编写并可以在 TensorFlow 和 Theano 之上运行。其开发目的是使快速实验成为可能。
什么是 Theano 和 TensorFlow?
James Bergstra 博士等人在 Scipy 2010 发布的 Theano 是一个 CPU 和 GPU 数学表达式编译器。它是一个 Python 库,允许你有效地定义、优化和评估涉及多维数组的数学表达式。Theano 由 Yoshua Bengio 等一些高级研究员和蒙特利尔学习算法研究所(MILA)共同完成。在 Scipy 2010 上一个非常棒的 Theano 教程。下图显示了截至 2010 年,Theano 在 GPU 和 CPU 与其他工具的对比。该结果最初在《Theano: A CPU and GPU Math Compiler in Python》一文中发表。
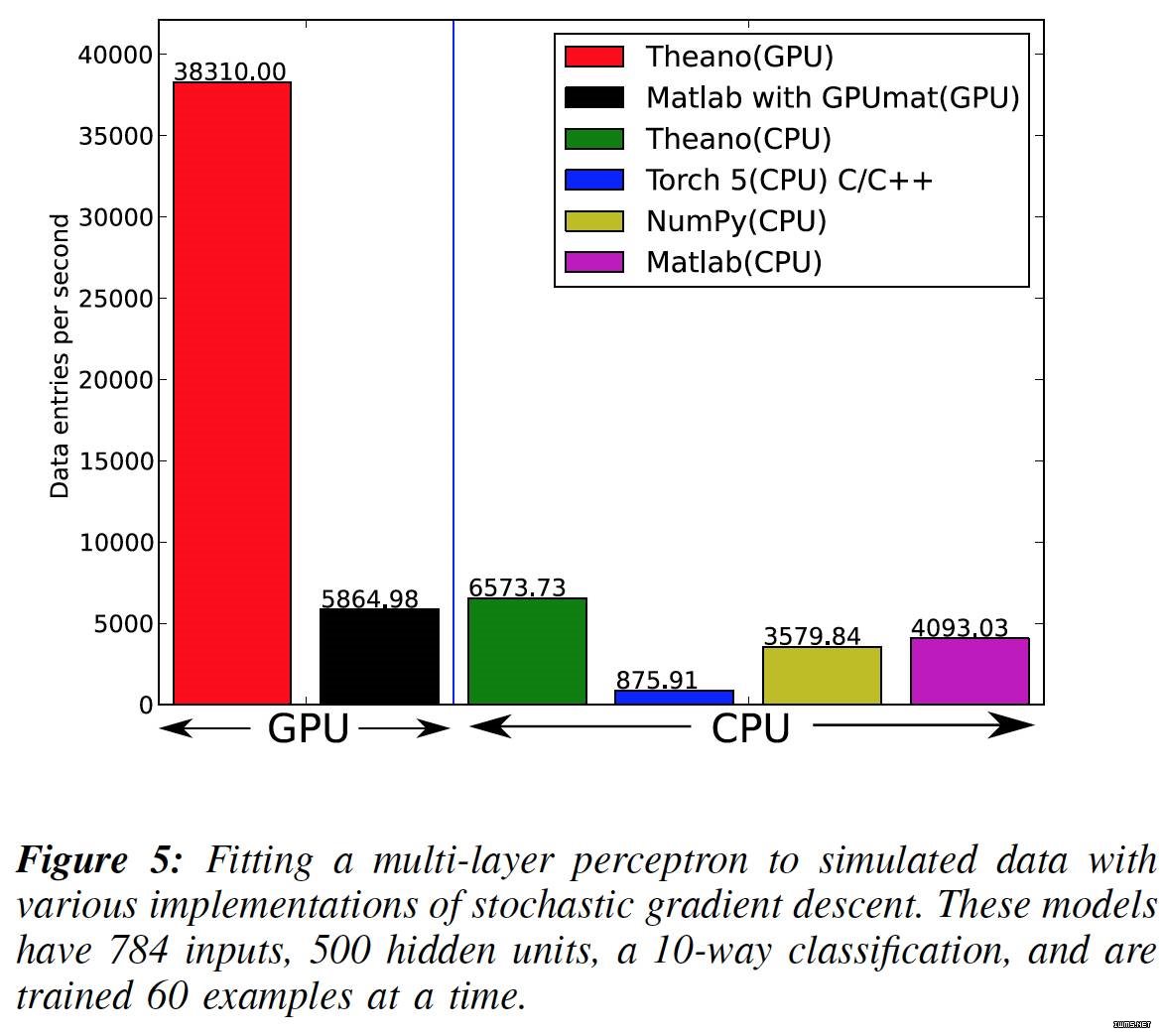
还有一些在 Theano 之上的建立其它的库,包括 Pylearn2 和 GroundHog(同样由 MILA 开发)、Lasagne、Blocks 和 Fuel.
TensorFlow 由 Google Brain 团队的研究员与工程师开发。其被开发用于进行机器学习和深度神经网络研究,但是该系统也足以适用于其它领域。如其网站介绍的那样,TensorFlow 是一个使用数据流图的数值计算开源软件库。图中的节点表示数学运算,图的边表示在其之间传递的多维数据数组(张量)。代码的可视化如下图所示。
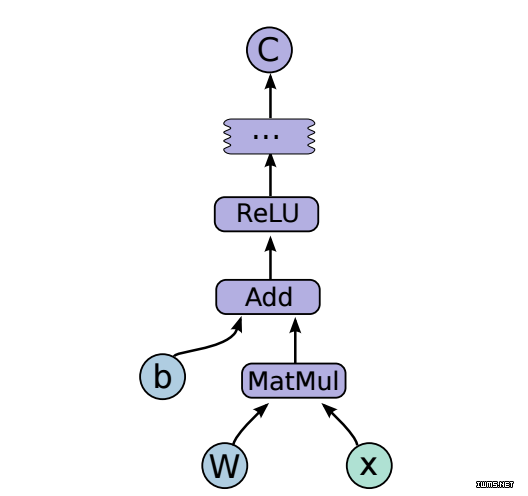
TensorFlow:在异构分布式系统上的大规模机器学习
使用 Keras 的预测分析示例
在这个示例中,我们将使用 UCI 网站的 Sonar 数据集构建一个简单的预测模型。在下面的代码中,我们将会直接从 UCI 网站中得到数据并以 60:40 的比例将其分为训练集与测试集。我们在预测模型中使用 Keras 并在标签编码中使用 sklearn。
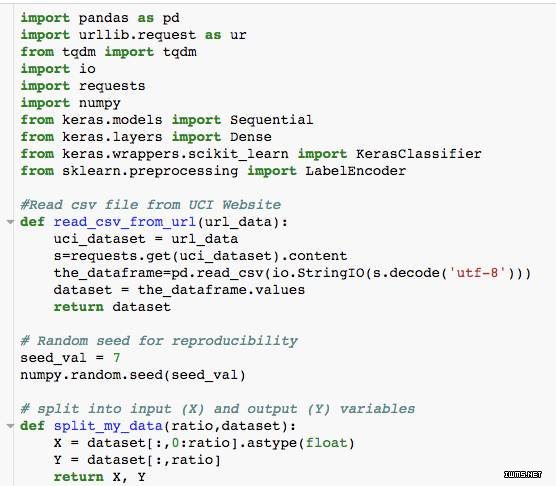
在下一段代码中,我们读取数据集,并使用上面定义的函数查看数据。我们打印数据集,并找出需要编码的因变量。
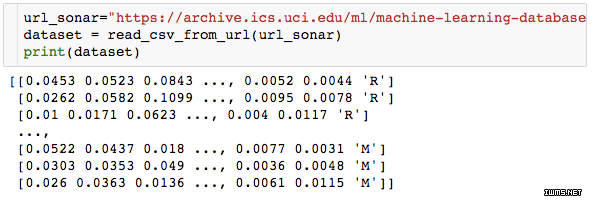
我们使用 scikit-learn 中的 LabelEncoder 进行标签编码,将 R 和 M 隐藏到数字 0 和 1 中。这样的操作被称为 one-hot 编码。one-hot 编码可将分类特征转换为对算法更友好的格式。在这个示例中,我们使用使用「R」值 和「M」值分类我们的 Y 变量。使用标签编码器,它们分别被转换为「1」和「0」。

scikit-learn 中的 LabelEncoder
然后使用 Keras 创建模型:
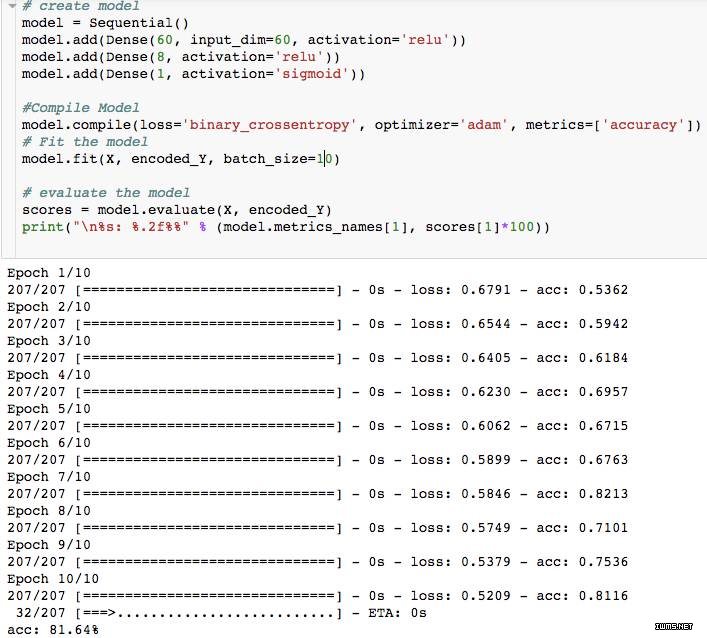
无预处理的简单模型的精确度为 81.64%
使用 Keras 的图像分析示例
为了用 Keras 解释图像处理,我们将使用来自 Kaggle 比赛的数据——狗和猫( https://www.kaggle.com/c/dogs-vs-cats)。该比赛的目的在于开发一种算法以区分图像是否包含狗或猫。这个任务对人、狗和猫来说很简单,但是计算机却很难做到。在该项挑战中,有 25,000 张标记狗和猫的照片可用于训练,并且在测试集中有 12,500 张照片,我们必须在挑战中尝试为其加上标签。根据 Kaggle 网站,当该项比赛开始时(2013 年底):
当前最佳:目前的文献显示,机器分类器在该任务上可以达到 80% 以上的准确度。那么如果我们能够超过 80%,我们将在 2013 年处于最前沿。」
我强烈推荐观看 Fast.ai 的 MOOC 以了解更多的细节,学习下一步和深度学习的前沿研究。我已经在下列代码中引用 fast.ai,这是一个很好的起点,链接: http://www.fast.ai/

步骤 1:设置
从 Kaggle 网站下载狗和猫的数据,并存入你的笔记本电脑。本文中的示例均在 Mac 上运行。

基础设置
Jeremy Howard 在他的班上提供了一个实用的 Python 文件,该文件有助于封装基本函数。对于开始部分,我们将使用此实用文件。点击下载: https://github.com/fastai/course ... rning1/nbs/utils.py。当我们深入到更多细节时,我们将解压该文件并查看其背后的内容。

步骤 2:使用 VGG
我们的第一步简单地使用已经为我们创建好的模型,它可以识别许多类别的图片(1,000 种)。我们将使用『VGG』,它赢得了 2014 年 ImageNet 比赛,是一个非常简单的创造理解的模型。VGG ImageNet 团队创造了更大、更慢、准确性略有提高的模型(VGG 19)和更小、更快的模型(VGG 16)。我们将使用 VGG 16,因为 VGG 19 过慢的性能与其在准确度上的微小提升不对等。
我们创建了一个 Python 类,Vgg16,这使得使用 VGG 16 模型非常简单。Vgg 16 同样可从 fast.ai 的 GitHub 中获得: https://github.com/fastai/course ... rning1/nbs/vgg16.py

步骤 3:实例化 VGG
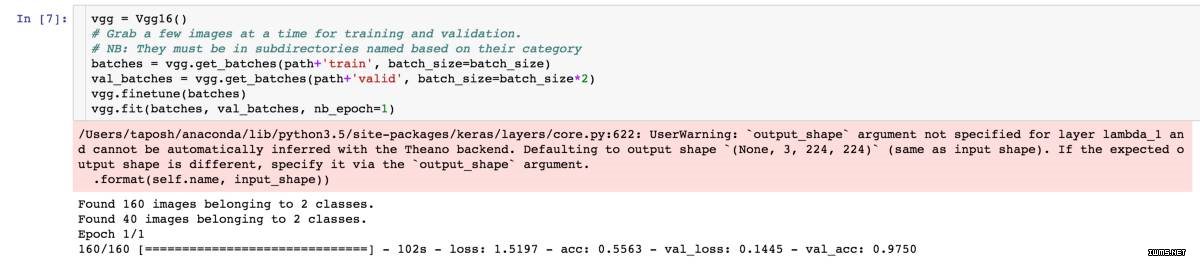
Vgg16 构建在 Keras 之上(我们将在短时间内学到更多内容),Keras 是一个灵活易用的深度学习库,该软件库是基于 Theano 或 Tensorflow 的一个深度学习框架。Keras 使用固定的目录结构在批量读取图像和标签组,每个类别的图像必须放在单独的文件夹中。
我们从训练文件夹中获取批量数据:
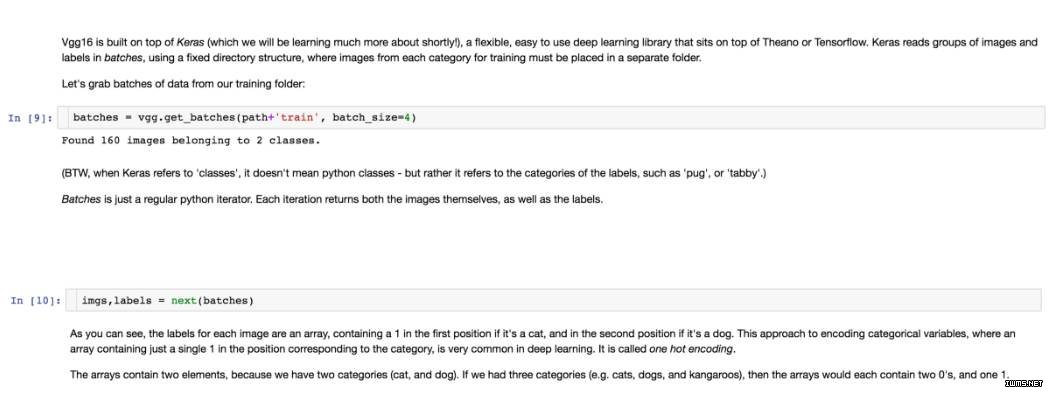
步骤 4:预测狗 vs 猫

步骤 5:总结并编码文件
总结一下这篇文章,我推荐的狗和猫分类方法为:
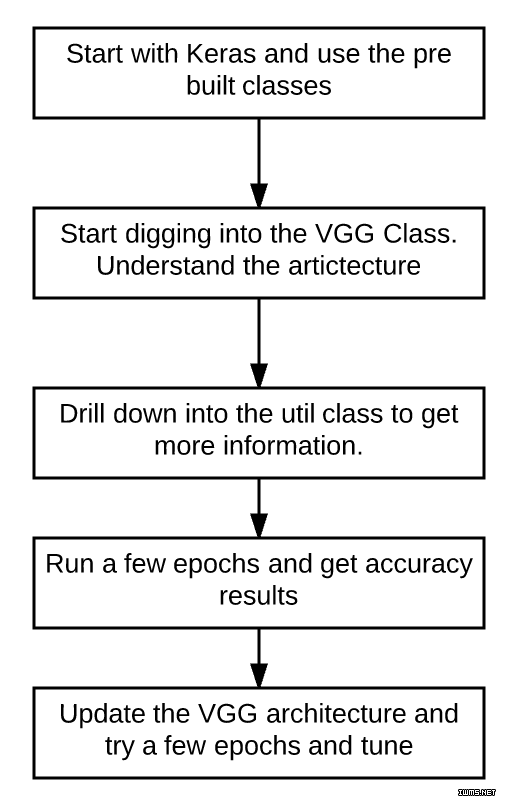
总结
如果读者跟着我们走到了这一步,那么其实已经实现了上一部分文章中讨论过的理论,并做了一些实际的编程工作。如果读者们按照上述说明实现了这两个案例,那么就已经完成了使用 Keras 的第一个预测模型,也初步实现了图像分析。由于代码的长度,我们不在这里讨论细节只给出了链接。如果你查看链接有任何疑问,请联系 fast.ai。
至此,我们从最开始的数据库安装到医学图像数据格式的解释,已经有了医学影像处理的基本知识。随后我们从卷积的定义到 CNN 的详细构架与原理,进一步实践的理论基础已经完成了累积。最后一部分对前面的理论知识进行实践,用 Python 实现了这一令人激动的模型。因此,我们希望读者朋友能在这一循序渐进的过程中真正感受到医学影像处理的乐趣。
参考原文:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/568542
推荐阅读
相关标签

