
热门标签
热门文章
- 1Payoneer注册、收款、提现常见问题_payoneer提现手续费
- 2PCL库教程_pcl教程
- 3面试题整理_es查看执行计划
- 4李宏毅LLM——生成式学习的两种策略_llm生成式 模板 学习
- 5ChatGPT又多了一个强有力的竞争对手:Meta发布Llama 3开源模型!附体验地址_meta ai llama 3模型下载
- 6Redux详解(二)
- 7Linux部署自动化运维平台Spug_运维自动部署平台
- 8jmeter最大请求数_jmeter 测试某网页最大并发用户数;
- 9【Thunder送书 | 第三期 】「Python系列丛书」_python从入门到精通(微课精编版)怎么样
- 10微信小程序点餐系统的开发与实现_基于微信小程序点餐系统设计与实现
当前位置: article > 正文
OpenAI最新研究:减轻ChatGPT幻觉、更好地对齐,要靠一步一步“过程监督”_chatgpt hallucinations
作者:小丑西瓜9 | 2024-05-19 10:51:50
赞
踩
chatgpt hallucinations
近年来,大型语言模型在进行复杂的、多步推理方面取得了很多进展。然而,即使是最先进的模型仍然会产生逻辑错误,这通常被称为幻觉(hallucinations)。减少幻觉是构建对齐的通用人工智能(AGI)的关键一步。
6 月 1 日,OpenAI 在最新研究中提出了一种减轻ChatGPT幻觉、实现更好的对齐的新方法——通过“过程监督”来提高 ChatGPT 等 AI 大模型的数学推理能力。
更详细一点,“过程监督”通过奖励每个正确的推理步骤,而不仅仅是奖励正确的最终答案(即“结果监督”),在解决数学问题方面达到了最先进水平。

据介绍,除了得到高于结果监督的性能表现外,过程监督或许也有助于解决对齐难题(它直接训练模型产生一个被人类认可的思维链)。
相对于结果监督,过程监督在对齐方面有几个优势。过程监督直接奖励按照对齐的思维链进行推理的模型,因为每个步骤都接受了精确的监督。过程监督更有可能产生可解释的推理,因为它鼓励模型遵循经过人类批准的过程。相比之下,结果监督可能会奖励一个不对齐的过程,并且一般更难审查。
具体到实际问题,OpenAI 的研究人员使用 MATH 测试集中的问题来评估过程监督和结果监督奖励模型。对于每个问题,他们生成了多个解决方案,然后选择每个奖励模型排名最高的解决方案。
图中显示了所选解决方案达到正确最终答案的百分比,作为所考虑的解决方案数量的函数。
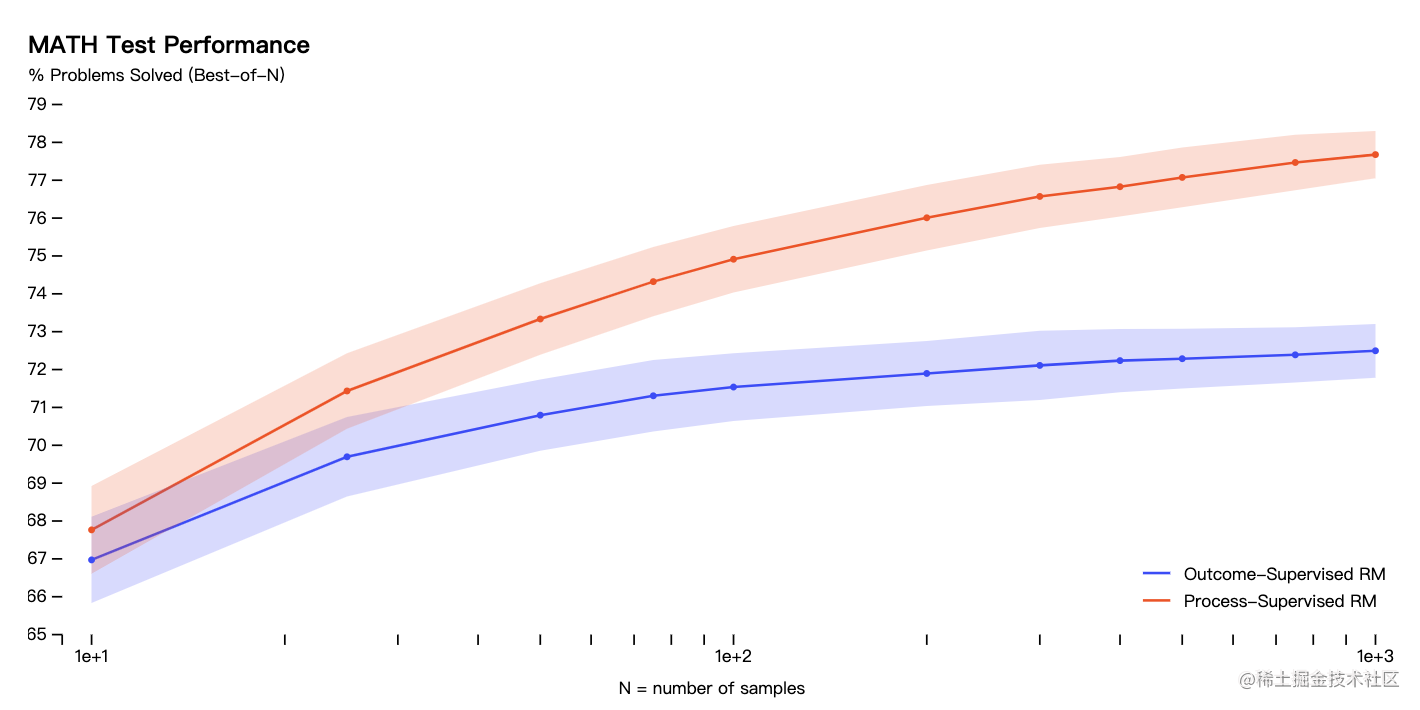
结果表明,过程监督的奖励模型不仅在整体上表现更好,而且随着考虑每个问题的解决方案数量增加,性能优势也在扩大。这表明过程监督的奖励模型更加可靠。
目前,OpenAI 的研究人员尚不清楚这些结果能否应用在数学领域之外,但认为未来探索过程监督在其他领域中的影响的研究将非常重要。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

