- 1Redis详解之-集群方案:高可用(使用Redis Sentinel)(三)_rdeis
- 2解决域控服务器时间错误,ntp时间服务器异常_js纠正服务器时间
- 3【YOLOv5】将YOLOv5预测结果由矩形框改为透明mask_yolo mask预测
- 4拼图小游戏
- 52024年百度Android面试真题,,史上超级详细
- 6自然语言处理(NLP)领域的应用和发展历程_语音识别,合成 和自然语言处理最新发展
- 7Multi Query Attention和 Group Query Attention的介绍和原理_分组查询注意力
- 8机器学习|优化算法 | 评估方法|分类模型性能评价指标 | 正则化_智能优化算法性能评估的方法
- 9多种方式实现java读取文件_java 通过接口获取文件
- 10Maven可选依赖与排除依赖_pom排除依赖包
搭建伪分布式并安装scale和spark_scale安装
赞
踩
一 搭建伪分布式前的准备
1.查看id 地址

2、 关闭防火墙
命令来关闭防火墙
![]()
命令查看当前防火墙状态

3、 修改主机名、 添加主机映射
![]()
修改虚拟机hosts文件,将ip地址添加进来


能ping通就修改成功

4、 设置免密(这里是伪分布式不是完全分布式,只需要能免密自己,此步骤也可以忽略)
○1打开SSH远程登录配置文件sshd_config

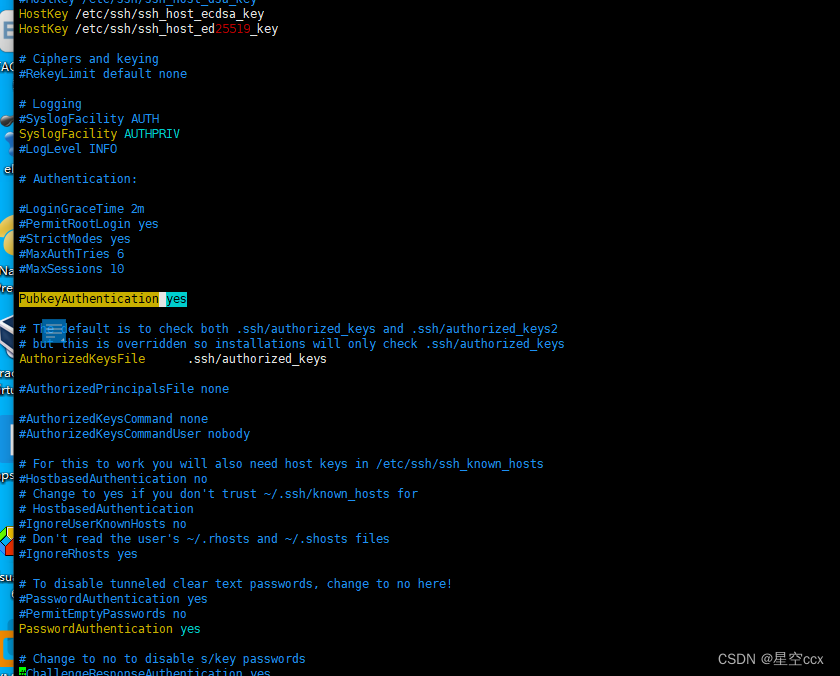
然后重启服务

○2生成密钥
![]()
回车四下

○3authorized_keys文件存放自己和目标的公钥,要自己手动复制文件,命令如下:
![]()
![]()
修改文件"authorized_keys权限
[root@master ~]$ chmod 600 ~/.ssh/authorized_key
二 安装 JAVA 环境
1下载 JDK 安装包
JDK 安 装 包 需 要 在 Oracle 官 网 下 载 , 下 载 地 址 为 :https://www.oracle.com/java /technologies /javase-jdk8-downloads.html,本教材采用 的 Hadoop 2.7.1 所需要的 JDK 版本为 JDK7 以上,这里采用的安装包为 jdk-8u152-linuxx64.tar.gz。
2卸载自带 OpenJDK


查看删除结果再次键入命令 java -version 出现以下结果表示删除功

3安装 JDK
安装命令如下,将安装包解压到/usr/local/src 目录下 ,注意/opt/software目录 下的软件包事先准备好
![]()

4设置 JAVA 环境变量
在文件的最后增加如下两行:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin

执行 source 使设置生效:
root@wfbs ~]# source /etc/profile
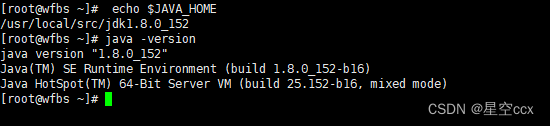
检查 JAVA 是否可用
三 安装 Hadoop 软件
1获取 Hadoop 安装包
Apache Hadoop 各 个 版 本 的 下 载 网 址 : https://archive.apache.org/dist/hadoop /common/。本教材选用的是 Hadoop 2.7.1 版本,安装包为 hadoop-2.7.1.tar.gz。需要先下载 Hadoop 安装包,再上传到 Linux 系统的/opt/software 目录
2安装 Hadoop 软件
安装命令如下,将安装包解压到/usr/local/src/目录下
[root@wfbs ~]# tar -zxvf /opt/software/hadoop-2.7.1.tar.gz -C /usr/local/src/

3配置 Hadoop 环境变量
和设置 JAVA 环境变量类似,修改/etc/profile 文件。
[root@wfbs ~]# vi /etc/profile
在文件的最后增加如下两行:
export HADOOP_HOME=/usr/local/src/hadoop-2.7.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行 source 使用设置生效:
[root@wfbs ~]# source /etc/profile
检查设置是否生效:
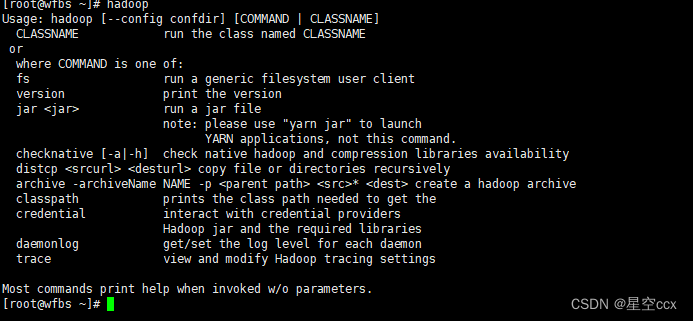
出现上述 Hadoop 帮助信息就说明 Hadoop 已经安装好了。
四 Hadoop伪分布式环境搭建
1、Hadoop文件参数配置
将 hadoop-2.7.1 文件夹重命名为 Hadoop
![]()

配置 Hadoop 环境变量
![]()

执行以下命令修改 hadoop-env.sh 配置文件


修改 core-site.xml将下面的配置参数加入进去修改成对应自己的


修改 hdfs-site.xml 将dfs.replication设置为1
vi hdfs-site.xml #编辑以下内容

修改 mapred-site.xml(将mapred-site.xml.template 复制一份为 mapred-site.xml
命令:cp mapred-site.xml.template mapred-site.xml)
![]()

配置 yarn-site.xml

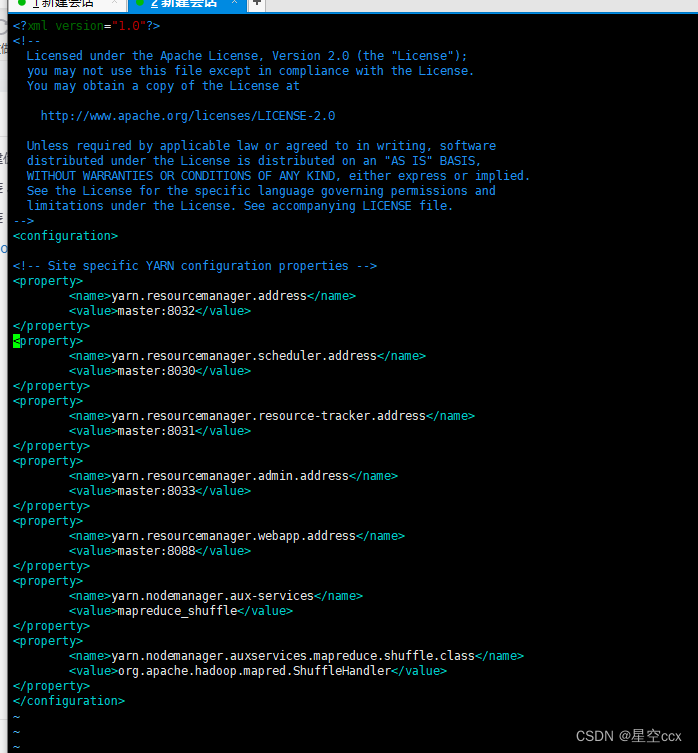
使环境变量生效
source /etc/profile
2 配置 Hadoop 格式化
hadoop namenode -format
到 hadoop 的sbin目录启动hadoop
![]()
验证

查看到有 NameNode 和 SecondaryNameNode 两个进程,就表明 HDFS 启动成 功。
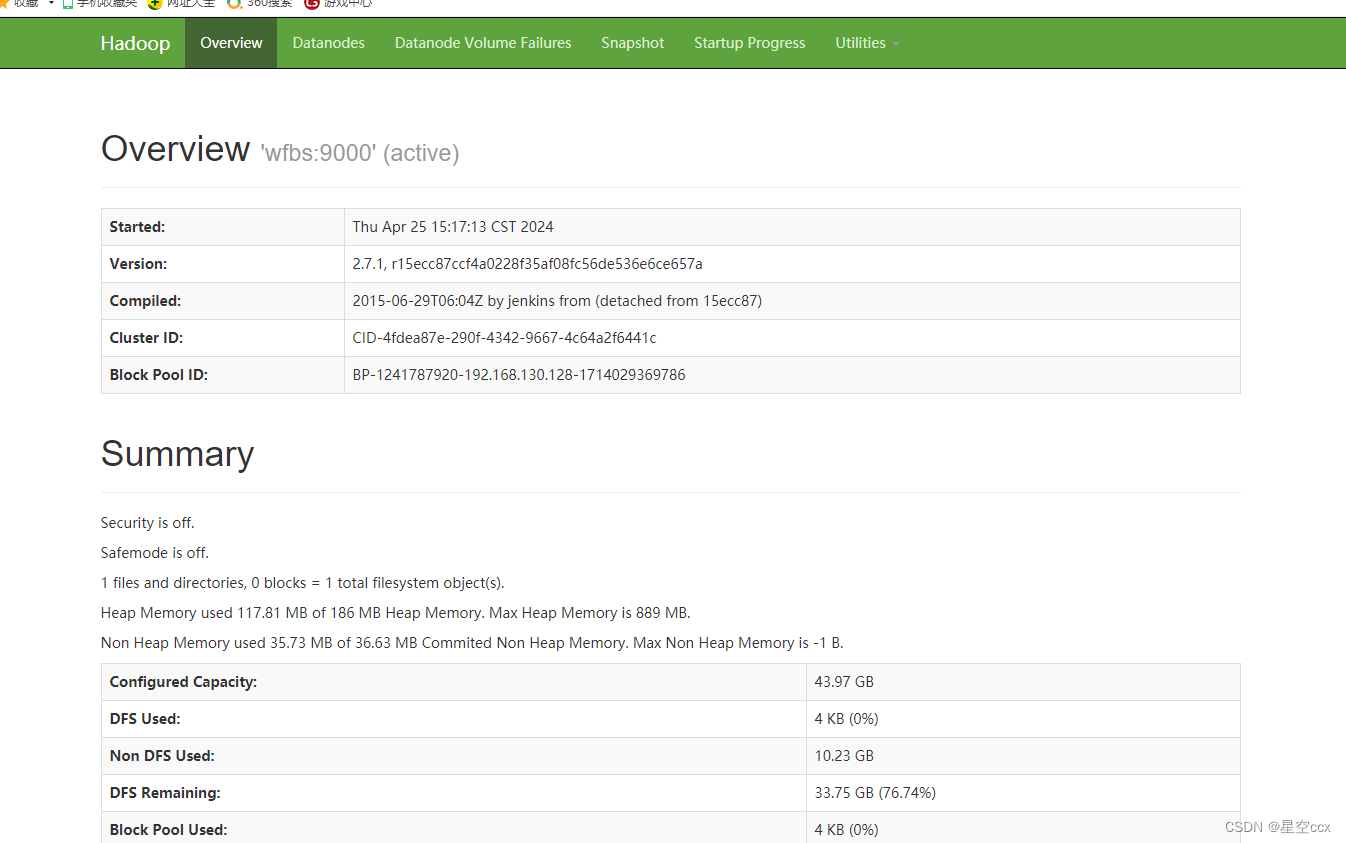
使用浏览器查看节点状态
在浏览器的地址栏输入http://192.168.130.128:50070,进入页面可以查看NameNode和DataNode 信息,如图所示:
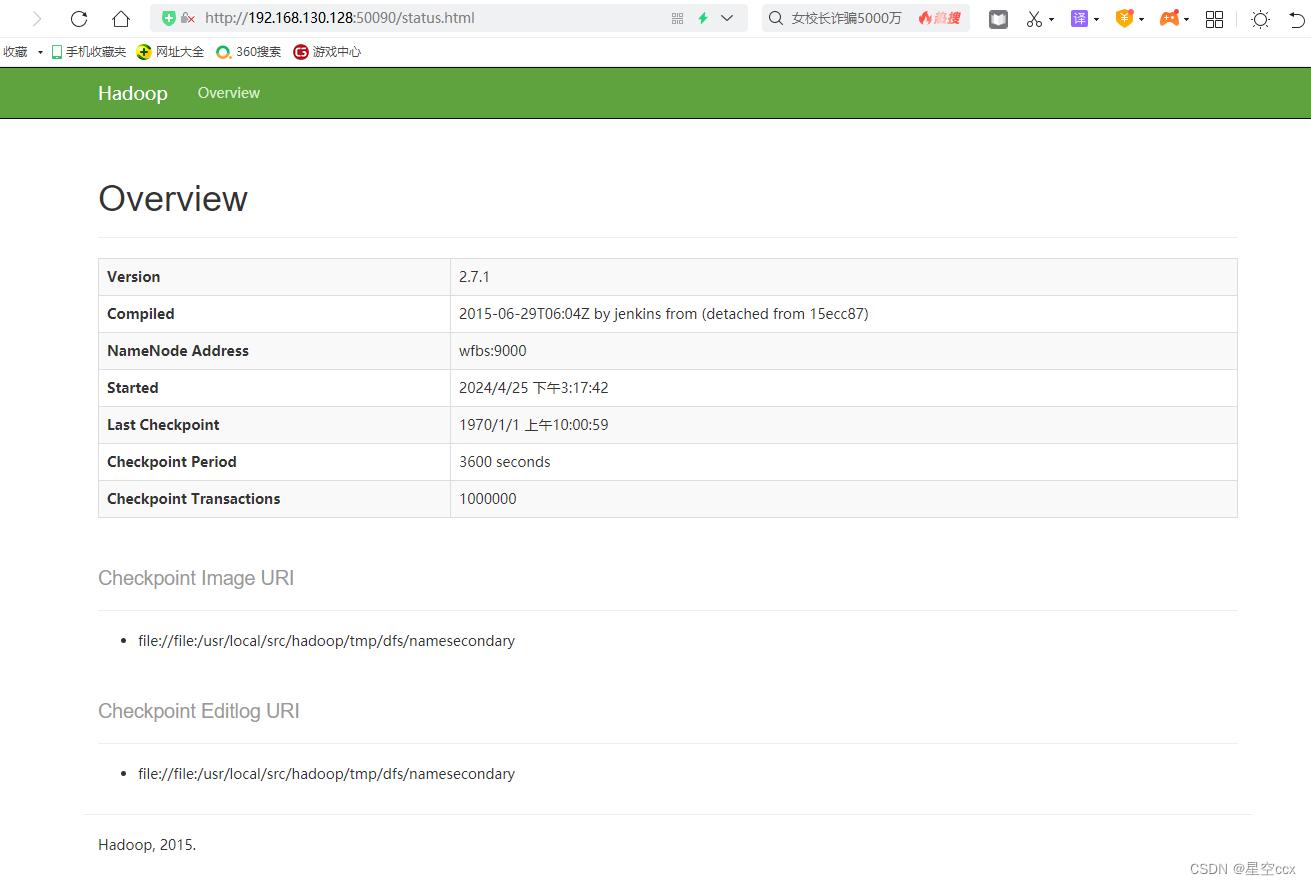
在浏览器的地址栏输入 http://192.168.130.128:50090,进入页面可以查看 SecondaryNameNode信息,如图所示:
五 安装scala
在官网下载Scala安装包为再上传到 Linux 系统的/opt/software 目录
安装命令如下,将安装包解压到/usr/local/src/目录下
[root@wfbs ~]# tar -zxvf /opt/scala-2.11.8.tgz -C /usr/local/src/
4设置 JAVA 环境变量
在文件的最后增加如下两行:
export SCALA_HOME=/usr/local/src/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin

执行 source 使设置生效:
root@wfbs ~]# source /etc/profile
验证

六 安装spark
在官网下载Spark安装包为再上传到 Linux 系统的/opt/software 目录
安装命令如下,将安装包解压到/usr/local/src/目录下
[root@wfbs ~]# tar -zxvf /opt/spark-2.0.0-bin-hadoop2.7.gz -C /usr/local/src/
1安装 Spark
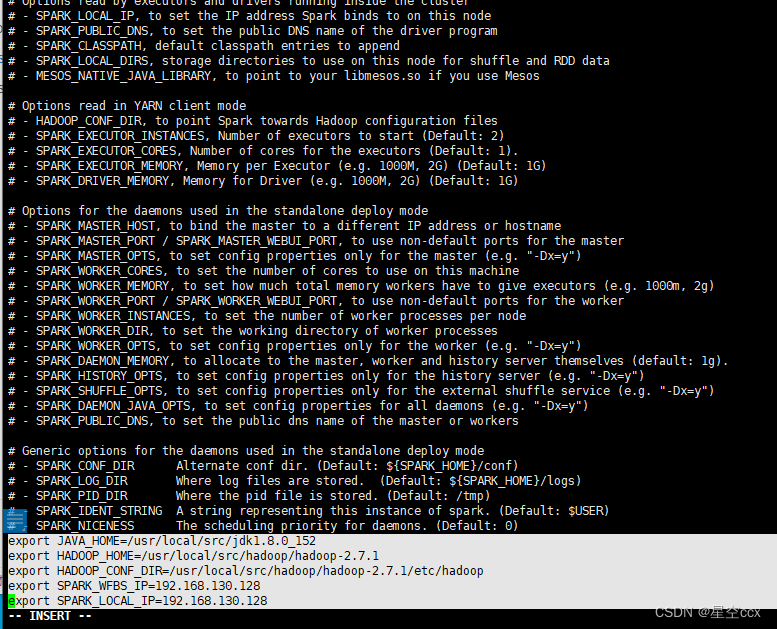
将〈Spark 解压路径〉/conf/spark-env. sh.template 复制为 conf/spark-env.sh,在 spark-env.sh文件末尾添加如下所示的内容:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.7.1
export HADOOP_CONF_DIR=/usr/local/src/hadoop/hadoop-2.7.1/etc/hadoop
export SPARK_WFBS_IP=192.168.130.128
export SPARK_LOCAL_IP=192.168.130.128
JAVA_HOME:Java 的安装路径;
HADOOP_HOME:Hadoop 的安装路径;
HADOOP_CONF_DIR: Hadoop 配置文件路径
SPARK_MASTER_IP:Spark 主节点的 IP 或机器名
SPARK_LOCAL_IP:Spark 本地的 IP 或机器名
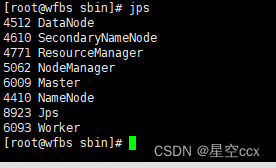
2切换到〈Spark解压路径>/sbin目录下,启动集群
![]()
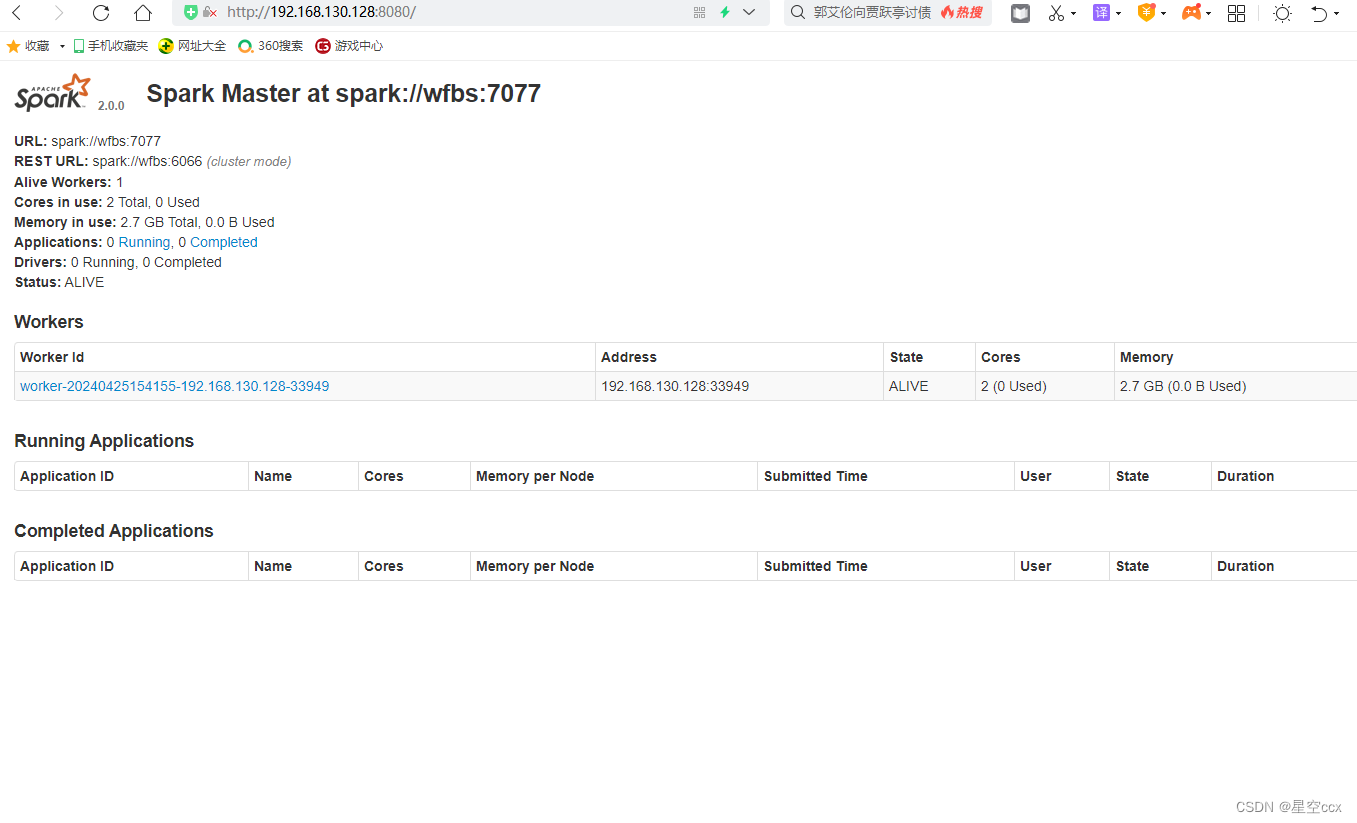
通过 jps 查看进程,即有 Master 也有 Worker 进程,说明启动成功
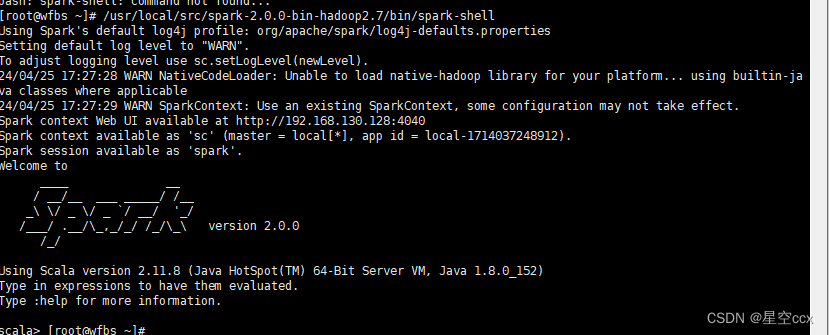
sparl-shell启动成功后,在浏览器的地址栏输入 http://192.168.130.128:8080