
- 1斯坦福、Nautilus Chain等联合主办的 Hackathon 活动,现已接受报名_boundless hackathon
- 2小程序配置之全局配置-window与tabBar_app.js tabbar
- 3Ubuntu 18.04 LTS 使用 WordPress 搭建博客 并 部署 CDN 教程_ubuntu搭建cdn
- 42024年软件测试常见面试题100%问必背全套教程_应届软件测试面试
- 5网络学习(12)|性能优化与调试:HTTP性能优化与分析
- 6zynq-7015启动分析及裸机BootLoader编写(未完待续)
- 7搭建个人图书馆!一个简单的在线个人书库_图书管理 docker
- 8unity postProcessing不工作或不生效_unity后处理没反应
- 9Windows+VScode配置与使用git,超详细教程,赶紧收藏吧_vscode git 设置path
- 10UDP对TCP_服务器主备心跳 用tcp 还是udp 好
关于GLOVE 词嵌入方法的理解_glove词嵌入理解
赞
踩
关于GLOVE 原理的理解
前言:
Glove是基于传统矩阵的LSA方法和基于skip-gram,Cbow训练方法的基础上提出的一种效果优于这两者(及其他很多训练方法)的词向量训练方法。本文主要从其与后者的区别与发展来讲。
与skip-gram的区别
skip-gram 是基于context windows 来训练词向量的,即他的目标函数只选取了固定窗口大小(一般为6-8)的词形成词对来进行训练。
这样的问题是只考虑了局部的词义关系,缺乏全局信息
e.g All over the place was six pence, but he looked up at the moon.
选取place作为center word,context window 为2, 那么注意到的信息就只有over the place was sic pence这么多。
而GLOVE就是为了解决这样的问题,采用了基于平方损失的模型,纳入全局信息,得到了很好的结果。
符号表示:
X
i
j
:
X_{ij}:
Xij: 单词 i 出现在 j 的context window中的次数
X
i
=
∑
k
X
i
k
X_{i} = \sum_{k}X_{ik}
Xi=∑kXik 表示所有含有 i 的pair出现的次数
W W W: 语料库中词的总数
模型原理
在skip-gram中,我们通过softmax计算单词 j 出现在 i 的context window中的概率:
P
i
j
=
e
x
p
(
u
⃗
j
T
v
⃗
i
)
∑
w
e
x
p
(
u
⃗
w
T
v
⃗
i
)
(1)
P_{ij} = \frac{e xp(\vec u_j^T\vec v_i)}{\sum_{w}exp(\vec u_w^T\vec v_i)} \tag{1}
Pij=∑wexp(u
wTv
i)exp(u
jTv
i)(1)
那么把整个语料库中pair出现的次数都算在内的话
J
=
−
∑
i
∈
语
料
库
∑
j
∈
c
o
n
t
e
x
t
(
i
)
l
o
g
P
i
j
(2)
J = - \sum_{i\in 语料库} \sum_{j \in context(i)} logP_{ij} \tag{2}
J=−i∈语料库∑j∈context(i)∑logPij(2)
如果理解了这个式子,会发现上式计算的实际上也是全局的cross-entropy。
在整个语料库中,(i,j)这样的pair也许不止出现一次,由上面的符号表示,将(2)可以重写为:
J
=
−
∑
i
=
1
W
∑
j
=
1
W
X
i
j
l
o
g
P
i
j
=
−
∑
i
X
i
∑
j
q
i
j
l
o
g
P
i
j
(3)
J = -\sum_{i=1}^{W}\sum_{j=1}^{W}X_{ij}logP_{ij} \\ =-\sum_{i}X_i\sum_jq_{ij}logP_{ij} \tag{3}
J=−i=1∑Wj=1∑WXijlogPij=−i∑Xij∑qijlogPij(3)
q
i
j
q_{ij}
qij为
X
i
j
/
X
i
X_{ij}/X_{i}
Xij/Xi比例
这样即得到了全局的cross- entropy损失函数,可惜就像skip-gram的缺陷一样,在计算(1)式的分母时,我们需对整个语料库进行计算,这在W足够大时需要极大计算量。
所以,我们考虑用平方损失来替代。
J
=
∑
i
∑
j
X
i
(
Q
^
i
j
−
P
^
i
j
)
2
J=\sum_i\sum_jX_i(\hat Q_{ij} -\hat P_{ij})^2
J=i∑j∑Xi(Q^ij−P^ij)2
其中 Q ^ i j = X i j , P ^ i j = e x p ( u ⃗ j T v ⃗ i ) \hat Q_{ij} = X_{ij}, \hat P_{ij} = exp(\vec u_j^T \vec v_i) Q^ij=Xij,P^ij=exp(u jTv i)
这两个值并非概率值,为了计算方便,取了对数。此时前面的系数
X
i
X_i
Xi也可以用一个weighted参数来替换掉。最后我们得到了最终的loss-func。
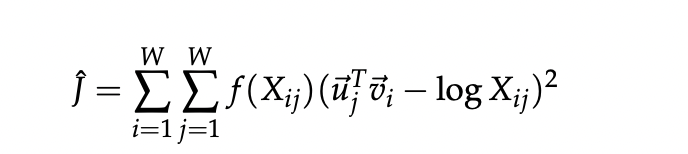
f可以是关于
X
i
j
X_{ij}
Xij的一个函数。
总结
- GloVe 可以使用全局的语料库的数据进行学习,其词嵌入包含全局的信息。
- cross- entropy对于语料库特别大的情况,可能并不是一个很好的选择,这种情况下我们会考虑平方损失。
- 对于Glove来说,center word 和 context word 实际上是地位对等的,因为在全局情况下,一个pair(i,j)i,j 都可以分别作为center和对方的context word
- GloVe 可以用词对的比例来进行理解,同样可以导出本文中的loss-func

