
- 1CLOUD 云计算进阶(十一)-Zookeeper Kafka集群_d1ykcogya1zkir cloudfront net
- 2ace2005中文数据集_好的数据集能让生成的对话配的上你的才华-------知识驱动的中文多轮对话数据集KdConv...
- 3第七讲:7.2 spring AOP后置-环绕_aspect doafter
- 4如何编写一个高效的Testbench?_testbench编写
- 5selenium关于selenium.common.exceptions.StaleElementReferenceException异常处理_message: stale element reference: stale element no
- 6ftp同步工具,十款超高人气ftp同步工具测评
- 7quatrus_quartus nmos
- 8利用辗转相除法求最大公约数和最小公倍数_利用辗转相除法计算两个正整数 a 和 b 的最大公约数,过程如下: ① 令 c=a%b
- 9码点(code point)和代码单元(code unit),以及String对象中操作码点和代码单元
- 10Linux服务器怎么分区_linux boot分区怎么配置
AI学习和实战_comfyui ollama
赞
踩
一、人工智能分类
判别式人工智能:通过分析输入数据和对应的输出标签之间的关系来进行决策和分类。
生成式人工智能:AIGC(Artificial Intelligence Generated Content)是人工智能1.0时代进入2.0时代的重要标志。
二、人工智能发展史
1、2016年3月15日,google旗下机器学习(AlphaGo)首次战胜人类职业围棋冠军。
2、人工智能技术在各个领域的应用不断拓展。自动驾驶、智能家居、智能医疗。
3、2018年,OpenAI公司开发了GPT-2模型,大规模预训练语言模型(LLM)。
4、2022年,人工智能在多模态、跨领域、泛知识等方面取得了重大突破。微软发布了MUM,一种能够理解多种语言和多种媒体的多模态通用模型;阿里巴巴发布了ET城市大脑4.0,利用人工智能优化城市治理和服务。
5、2023年,人工智能大爆发,OpenAI发布了GPT-4,微软推出new Bing,百度推出文心一言,DeepMind发布了AlphaGo Zero 2.0,一种完全自主学习的围棋程序,能够超越任何人类或计算机对手;IBM发布了Neuro-Symbolic Concept Learner,一种能够从图像中学习概念并用自然语言表达的神经符号模型。
6、2024年2月15日,OpenAI发布的人工智能文生视频大模型sora。llama3
三、国内人工智能平台
1、阿里云:阿里灵杰
提供ai代码生成器:通义灵码。
2、百度AI开放平台:百度AI开放平台-全球领先的人工智能服务平台
四、人工智能模型部署工具
1、Stable-Diffution-WebUI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
是个开源的AI绘画模型框架,可实现文生图、图生图。
使用方法:AI绘图工具:分分钟搞定Stable-Diffution-WebUI界面与生图参数配置 - 知乎
2、comfyui
https://github.com/comfyanonymous/ComfyUI
文生动图
ComfyUI文生动图-ComfyUI-AnimateDiff-Evolved(官方直译)详细部署与使用 - 知乎
workflow工作流大全
https://openart.ai/workflows/all
3、Langchain-Chatchat
Home · chatchat-space/Langchain-Chatchat Wiki · GitHub
4、modelscope
参考:AI:ModelScope(一站式开源的模型即服务共享平台)的简介、安装、使用方法之详细攻略-CSDN博客
5、AI模型下载地址
6、aliyun的dsw
可以使用试用版:阿里云免费试用 - 阿里云
配置方法参考:【AI】阿里云免费GPU服务资源领取方法_阿里云天池免费gpu-CSDN博客
踩坑:dsw不能直接访问huggingface等模型下载网站。
解决方案:
1)官网介绍可以通过下载到本地,再同步到ali云盘。
2)安装模型网站插件工具。
3)通过git方式上传。但是需要使用lfs,git大文件模式。(亲测可用)
mac安装lfs:brew install git-lgs
新建git仓库文件夹使用lfs:git lfs install
4)修改huggingface_hub下载源为国内镜像https://hf-mirror.com/
huggingface连不上的解决方案_huggingface offline mode-CSDN博客
7、google colab
https://colab.research.google.com/notebooks/intro.ipynb
使用方法
安装comfyui
- !nvidia-smi
- %cd /content/drive/MyDrive/ComfyUI
- !pip install -r requirements.txt
- !pip install accelerate
- !pip install einops
- !pip install torchsde
- !pip install kornia
- !curl -Lo /usr/bin/cloudflared https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64 && chmod +x /usr/bin/cloudflared
- from pathlib import Path
- import subprocess
- import threading
- import time
- import socket
- import urllib.request
-
- !wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-amd64.deb
- !dpkg -i cloudflared-linux-amd64.deb
-
- def iframe_thread(port):
- while True:
- time.sleep(0.5)
- sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
- result = sock.connect_ex(('127.0.0.1', port))
- if result == 0:
- break
- sock.close()
- print("\nComfyUI finished loading, trying to launch cloudflared (if it gets stuck here cloudflared is having issues)\n")
-
- p = subprocess.Popen(["cloudflared", "tunnel", "--url", "http://127.0.0.1:{}".format(port)], stdout=subprocess.PIPE, stderr=subprocess.PIPE)
- for line in p.stderr:
- l = line.decode()
- if "trycloudflare.com " in l:
- print("This is the URL to access ComfyUI:", l[l.find("http"):], end='')
- #print(l, end='')
-
-
- threading.Thread(target=iframe_thread, daemon=True, args=(8188,)).start()
- %cd /content/drive/MyDrive/ComfyUI/
- !python main.py --dont-print-server

五、常用模型库
1、huggingface
2、modelscope
地址:魔搭社区
3、civitai
六、实战
1、项目来源:一款构建AI数字人项目开源了!自动实现音视频同步! - 知乎
3、部署过程:
1)下载源码
git clone https://github.com/vinthony/video-retalking.git2)安装conda
Mac 安装 miniconda_mac安装miniconda-CSDN博客
3)安装pkg-config
4) 安装pytorch
pip install pytorch
5)安装numpy
pip install numpy
Running `gfortran --version` gave "[Errno 2] No such file or directory: 'gfortran'"
Running `gfortran -V` gave "[Errno 2] No such file or directory: 'gfortran'"
Running `flang --version` gave "[Errno 2] No such file or directory: 'flang'"
Running `flang -V` gave "[Errno 2] No such file or directory: 'flang'"
Running `nvfortran --version` gave "[Errno 2] No such file or directory: 'nvfortran'"
Running `nvfortran -V` gave "[Errno 2] No such file or directory: 'nvfortran'"
Running `pgfortran --version` gave "[Errno 2] No such file or directory: 'pgfortran'"
Running `pgfortran -V` gave "[Errno 2] No such file or directory: 'pgfortran'"
Running `ifort --version` gave "[Errno 2] No such file or directory: 'ifort'"
Running `ifort -V` gave "[Errno 2] No such file or directory: 'ifort'"
Running `ifx --version` gave "[Errno 2] No such file or directory: 'ifx'"
Running `ifx -V` gave "[Errno 2] No such file or directory: 'ifx'"
Running `g95 --version` gave "[Errno 2] No such file or directory: 'g95'"
Running `g95 -V` gave "[Errno 2] No such file or directory: 'g95'"
文档:SDXLControlnetTileV2:高清分辨率更灵活可控图像增强模型(ComfyUI使用指南)
模型地址:TianYa/ai-models
实现功能:
1、使用RealVisXL写实模型(RealVisXL V3.0:照片级AI绘图模型)
yellow Clothes,sunglasses, 1 chinese girl|
|
|


pink Clothes,pink background, 1 chinese girl|
|
|


2、AI绘图模型|HelloWorld SDXL:已融合字节SDXL-Lightning模型技术)
purple dress,gold Pendant, outdoor,1 chinese girl3、Samaritan 3d Cartoon:优秀3D卡通动漫模型
red Clothes, 1 chinese girl|
|
|

部署文档:Llama3:开源LLM新里程碑,Ollama和OpenWebUI本地部署指南
1、下载ollama
-
• MacOS:下载安装包:https://ollama.com/download/Ollama-darwin.zip
-
• Window:下载安装包:https://ollama.com/download/OllamaSetup.exe
-
• Linux:运行安装命令:
curl -fsSL https://ollama.com/install.sh | sh
2、启动Ollama
ollama serve
3、部署模型
如:
ollama run llama3:instruct
ollama run qwen
技术文档:Transparent Image Layer Diffusion:透明图层生成,ControlNet作者新作,设计应用大利好
可实现项目:GitHub - huchenlei/ComfyUI-layerdiffuse: Layer Diffuse custom nodes
https://github.com/kealiu/ComfyUI-Zero123-Porting/blob/main/README_CN.md
技术文档:阿里DDColor:黑白老照片图像上色开模型,开源附推理指南
comfyui:GitHub - kijai/ComfyUI-DDColor: ComfyUI node for DDColor
模型地址:https://huggingface.co/piddnad/DDColor-models/tree/main
效果展示:
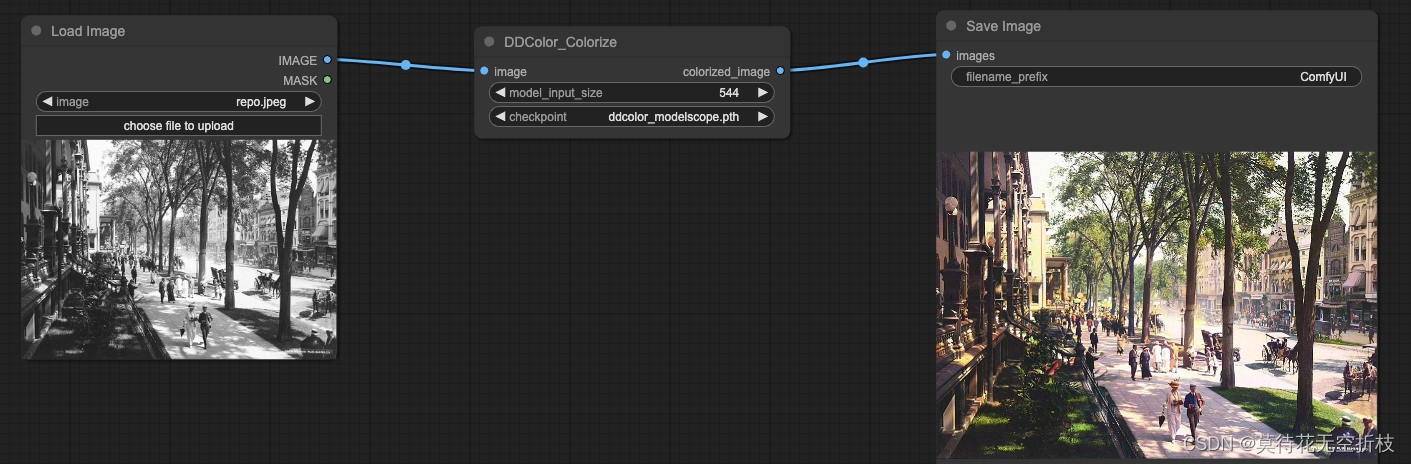
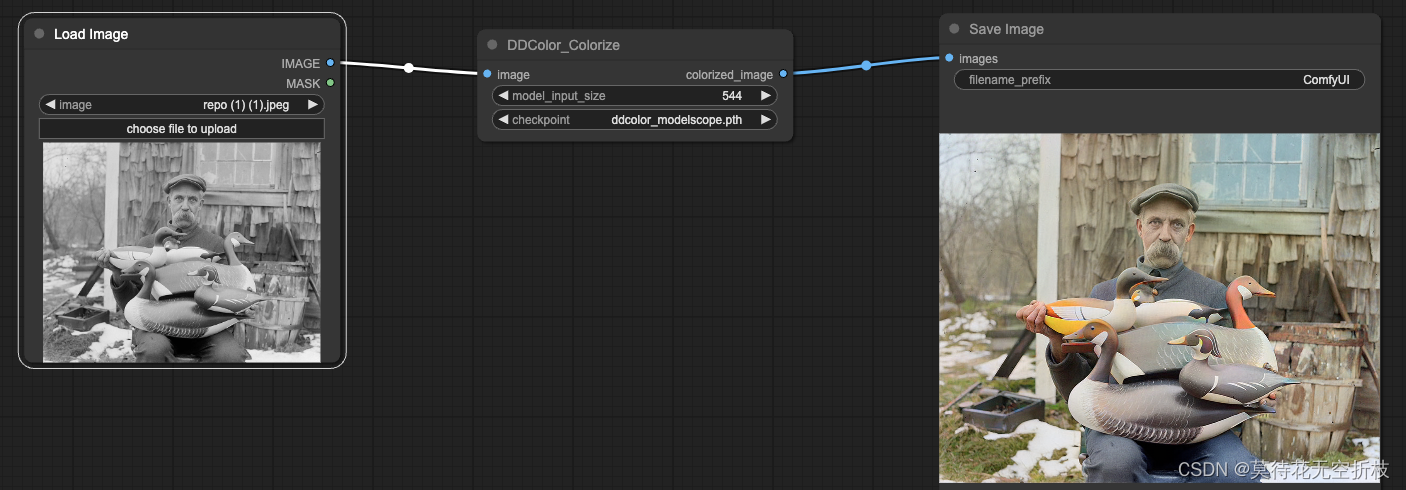
项目地址:【comfyui】AI绘画一键换脸工作流,学会你也可以实现随时换脸啦~~
【Stable Diffusion】Reactor AI换脸详细教程,简单好用,秒杀Roop_哔哩哔哩_bilibili
踩坑:dsw环境comfyui安装comfyui-reactor-node时报错Network is unreachable
梳理原因是下载安装过程中需要下载模型,但是dsw无法连接模型所在网站。
下面是解决方案
- Place the model files in the corresponding folders under ComfyUI/models:
-
- deepbump256.onnx
- Location: deepbump
-
- detection_mobilenet0.25_Final.pth
- detection_Resnet50_Final.pth
- parsing_parsenet.pth
- Location: facedetection
-
- inswapper_128.onnx
- Location: insightface
-
- buffalo_l.zip
- Extract the files to: insightface/models/buffalo_l
-
- GFPGANv1.3.pth
- GFPGANv1.4.pth
- Location: facerestore_models
-
- 131_--QrieM4aQbbLWrUtbO2cGbX8-war
- Location: FILM
- --如果不使用该模型可以mkdir 一个空目录
GitHub - A719689614/ComfyUI-WorkFlow: 一些我自己的工作流参数
字节PuLID:高效身份ID特征定制,ComfyUI使用指南
GitHub - cubiq/PuLID_ComfyUI: PuLID native implementation for ComfyUI

项目地址:IC-Light:图像打光控制和背景融合生产力工具,最全ComfyUI操作指南
GitHub - kijai/ComfyUI-IC-Light: Using IC-LIght models in ComfyUI
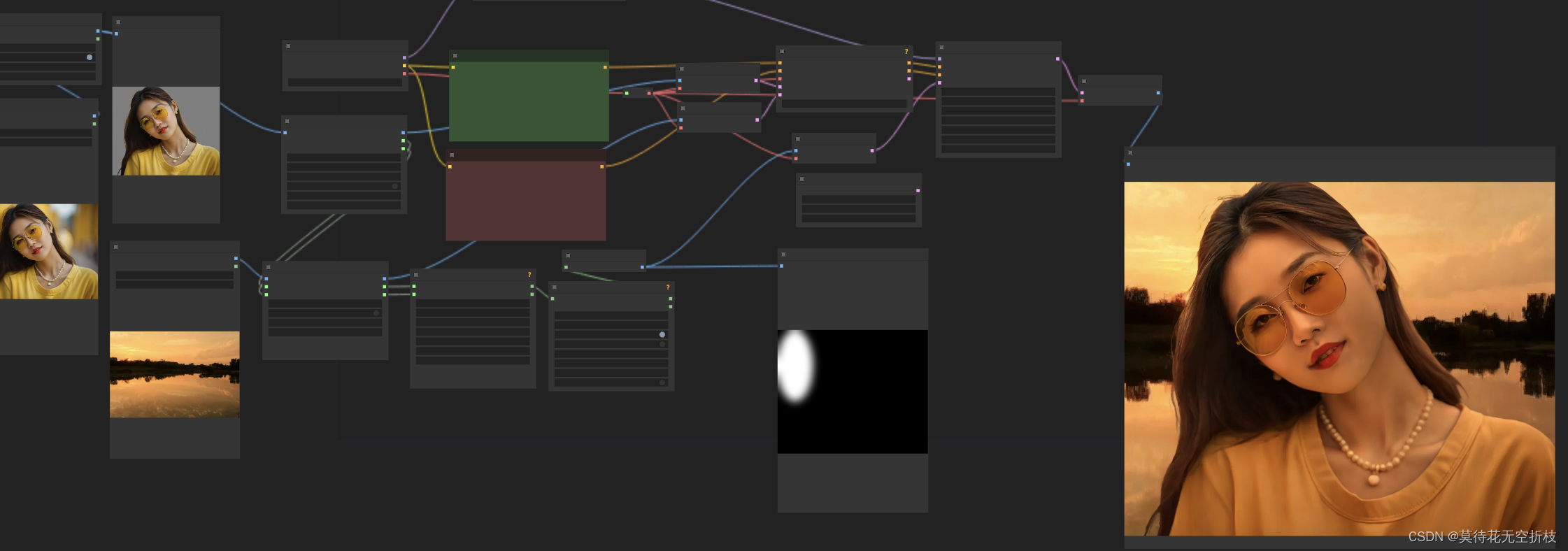
项目地址:Open-Sora全面开源升级:支持16s视频生成和720p分辨率
GitHub - chaojie/ComfyUI-Open-Sora
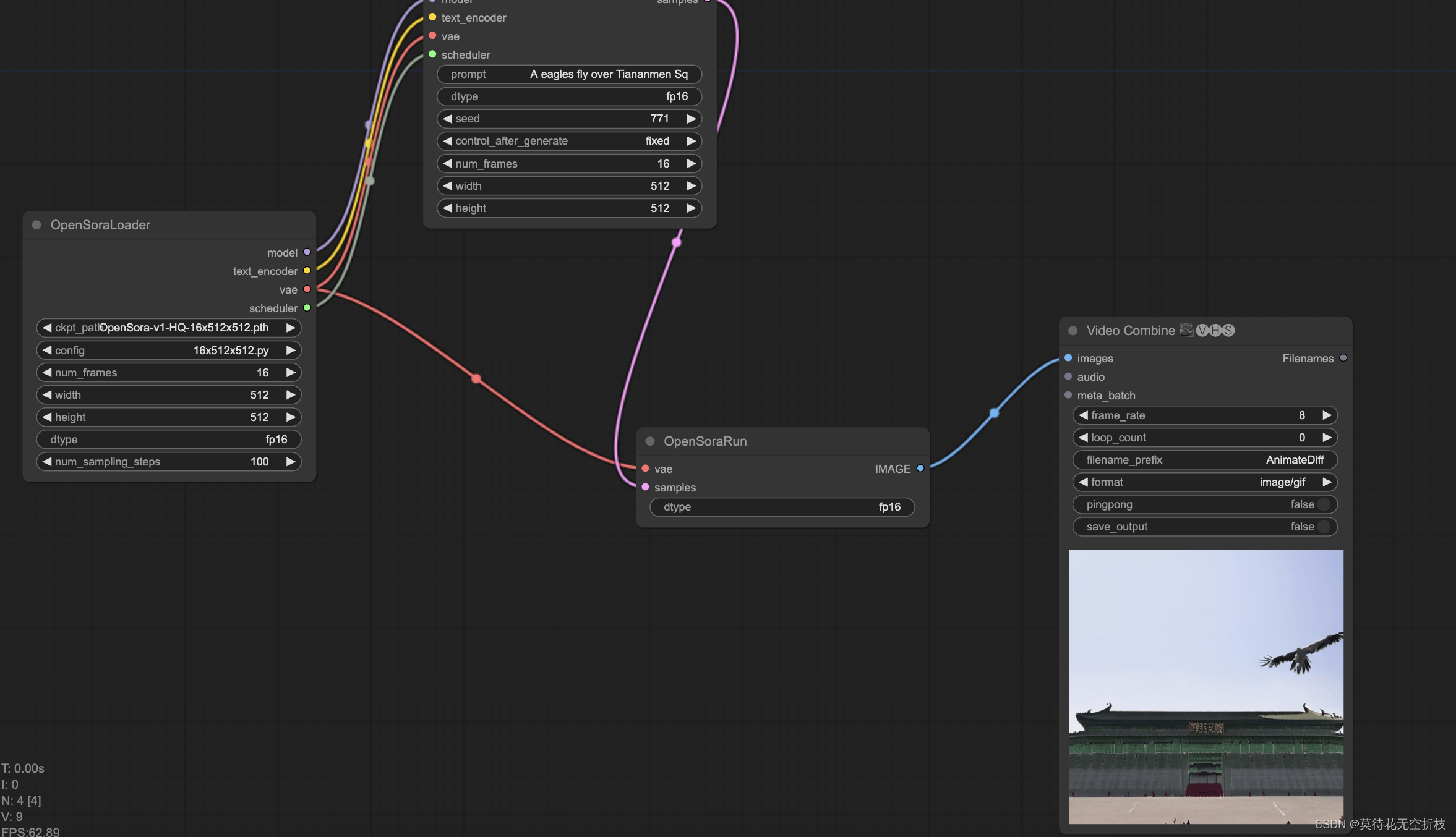
GPT-SoVITS-WebUI实测: 目前最好的中文声音克隆工具
项目地址:https://mp.weixin.qq.com/s/Z1kZ_maMb2pcPTns9956DQ#/
参考使用视频:你的声音,现在是我的了!- 手把手教你用 GPT-SoVITS 克隆声音!_哔哩哔哩_bilibili
使用步骤
1、声音提取
2、语音切分
3、语音识别
4、标注
5、格式化
6、训练新模型
7、推理
很多python包需要c++环境
c++环境安装
#GCC,GDB安装
sudo apt update
sudo apt install build-essential gdb
# 通过以下命令安装编译器和调试器
sudo apt install cmake

