
- 1数据库MySQL(笔记)_编写mysql语句,创建名为datab1的数据库
- 2工地基坑自动识别摄像机
- 3MySQL——分组查询_select count (*) from group by
- 4GIT合并指定文件
- 5【心电信号】小波变换心电信号去噪【含Matlab源码 956期】_db1小波
- 6Swin Transformer各层特征可视化_transformer 可视化
- 7Linux之进程信号详解【上】
- 8STL-set、map、multiset、multimap的介绍及使用
- 9解决QT的无界面程序,Ctrl+C无法触发析构函数的问题_qt 控制台应用程序关闭进不去析构函数
- 10STM32F429内部FLASH读写擦除操作流程和寄存器配置要点_read-while-write
机器学习之KMeans聚类算法原理(附案例实战)_kmeans算法原理
赞
踩
KMeans聚类
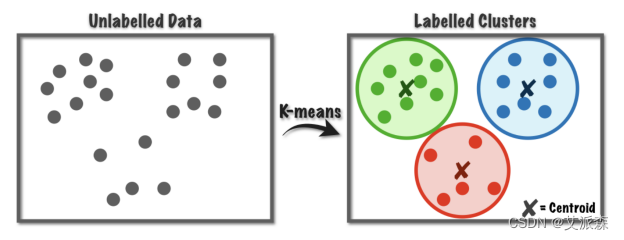
什么是聚类任务
- 1 无监督机器学习的一种
- 2 目标将已有数据根据相似度划分到不同的簇
- 3 簇内样本彼此之间越相似,不同簇的样本之间越不相似,就越好
为什么叫KMeans聚类
- 1 也可以叫K均值聚类
- 2 K是最终簇数量,它是超参数,需要预先设定
- 3 在算法计算中会涉及到求均值
KMeans流程
- 1 随机选择K个簇中心点
- 2 样本被分配到离其最近的中心点
- 3 K个簇中心点根据所在簇样本,以求平均值的方式重新计算
- 4 重复第2步和第3步直到所有样本的分配不再改变
如何计算样本到中心点的距离
1. 欧氏距离测度 Euclidean Distance Measure
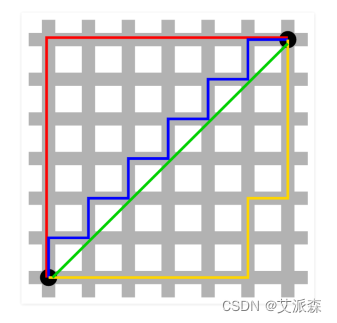
欧氏距离越大,相似度越低

2. 余弦距离测度 Cosine Similarity Measure

夹角越大,余弦值越小,相似度越低

因为是cosine,所以取值范围是-1到1之间,它判断的是向量之间的 方向而不是大小;两个向量有同样的方向那么cosine相似度为1,两 个向量方向相对成90°那么cosine相似度为0,两个向量正相反那么 cosine相似度为-1,和它们的大小无关。
选择Cosine相似度还是欧氏距离
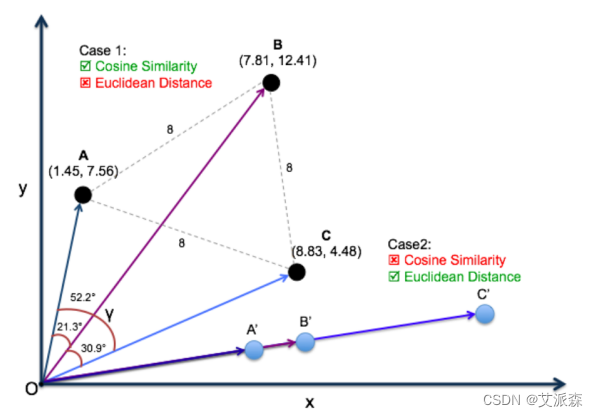
总体来说,欧氏距离体现数值上的绝对差异,而余弦距离体现方向 上的相对差异。
例如,统计两部剧的用户观看行为,用户A的观看向量为(0, 1),用户B为(1,0);此时二者的余弦距离很大,而欧氏距离很 小;我们分析两个用户对于不同视频的偏好,更关注相对差异,显 然应当使用余弦距离。 而当我们分析用户活跃度,以登陆次数(单位:次)和平均观看时长 (单位:分钟)作为特征时,余弦距离会认为(1,10)、(10, 100)两个用户距离很近;但显然这两个用户活跃度是有着极大差 异的,此时我们更关注数值绝对差异,应当使用欧氏距离。
KMeans算法目标函数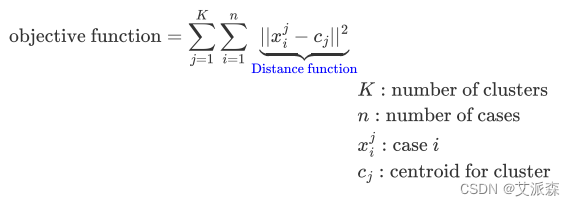
上面的公式既是要去最小化的目标函数,同时也可以作为评价 KMeans聚类效果好坏的评估指标。
KMeans算法不保证找到最好的解
事实上,我们随机初始化选择了不同的初始中心点,我们或许会获 得不同的结果,就是所谓的收敛到不同的局部最优;这其实也就从 事实上说明了目标函数是非凸函数。
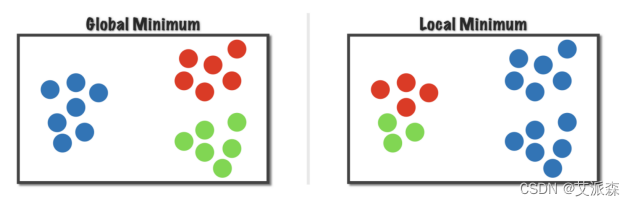
一个通常的做法就是运行KMeans很多次,每次随机初始化不同的 初始中心点,然后从多次运行结果中选择最好的局部最优解。
KMeans算法K的选择
没有所谓最好的选择聚类数的方法,通常是需要根据不同的问题, 人工进行选择的。
肘部法则(Elbow method)
改变聚类数K,然后进行聚类,计算损失函数,拐点处即为推荐的聚 类数 (即通过此点后,聚类数的增大也不会对损失函数的下降带来很 大的影响,所以会选择拐点)。
目标法则
如果聚类本身是为了有监督任务服务的(例如聚类产生features 【譬如KMeans用于某个或某些个数据特征的离散化】然后将 KMeans离散化后的特征用于下游任务),则可以直接根据下游任 务的metrics进行评估更好。
KMeans实战案例-NBA球队实力聚类分析
导包
- from sklearn.cluster import KMeans
- import numpy as np
- import matplotlib.pyplot as plt
- import pandas as pd
- from sklearn.preprocessing import MinMaxScaler
导入数据
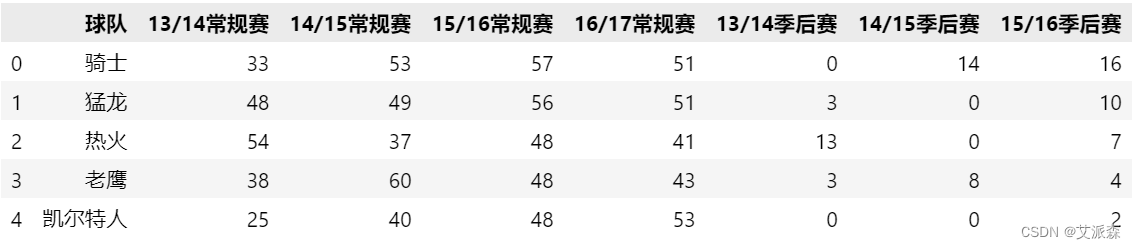
- data = pd.read_csv('nba.csv')
- data.head()
处理数据
- minmax_scaler = MinMaxScaler()
- # 标准化数据
- X = minmax_scaler.fit_transform(data.iloc[:,1:])
使用肘部法则确定聚类的K值
- # 肘部法则
- loss = []
- for i in range(2,10):
- model = KMeans(n_clusters=i).fit(X)
- loss.append(model.inertia_)
-
- plt.plot(range(2,10),loss)
- plt.xlabel('k')
- plt.ylabel('loss')
- plt.show()

使用肘部法则,我们一般选取的是曲线平缓的时候,这里我们选取4作为K值
- k = 4
- model = KMeans(n_clusters=k).fit(X)
- # 将标签整合到原始数据上
- data['clusters'] = model.labels_
- data.head()

查看聚类统计结果
- for i in range(k):
- print('clusters:',i)
- label_data = data[data['clusters'] == i].iloc[:,0]
- print(label_data.values)


