
- 1一文带你读懂深度估计算法
- 2windows 系统安装mysql8.0 及错误问题处理_windowsmysql8配置器错误
- 3mediasoup基础概览_mediasoup ndi
- 4数据结构-Treap(树堆) 详解
- 57 Series FPGAs Integrated Block for PCI Express IP核 Advanced模式配置详解(一)_pcie integrated block for pci express
- 6大模型的 5 月:热闹的 30 天和鸿沟边缘
- 7JDBC之MySQL的URL_mysqljdbc的url怎么写
- 8uni-app 配置编译环境与动态修改manifest,2024非科班生的Android面试之路_manifest 动态编译
- 9struct和class区别、三种继承及虚继承、友元类_class继承struct
- 10图片和16进制 互相转换_图片转16进制
docker使用GPU及linux下cuda安装和更新问题_linux更新cuda版本
赞
踩
1. docker使用GPU
首先介绍几个事实:
- 最初的docker是不支持gpu的
- 为了让docker支持nvidia显卡,英伟达公司开发了nvidia-docker。该软件是对docker的包装,使得容器能够看到并使用宿主机的nvidia显卡。
- 根据网上的资料,从docker 19版本之后,nvidia-docker成为了过去式。不需要单独去下nvidia-docker这个独立的docker应用程序,也就是说gpu docker所需要的Runtime被集成进docker中,使用的时候用–gpus参数来控制。
所以我一直都是直接以--gpus这个参数来使用容器的,直接给容器分配GPU
docker run -it -d --gpus "device=3" --ipc=host -p 10036:22 -v /ws/huangshan:/ws --name "paddle2.1" paddlepaddle/paddle:2.1.2-gpu-cuda11.2-cudnn8 bash -c "/etc/rc.local; /bin/bash"
- 1
详情见参考:
2. 镜像cuda版本和宿主机cuda版本不兼容
2.1 确定问题
下载PaddlePaddle的镜像,一开始使用的是最新的
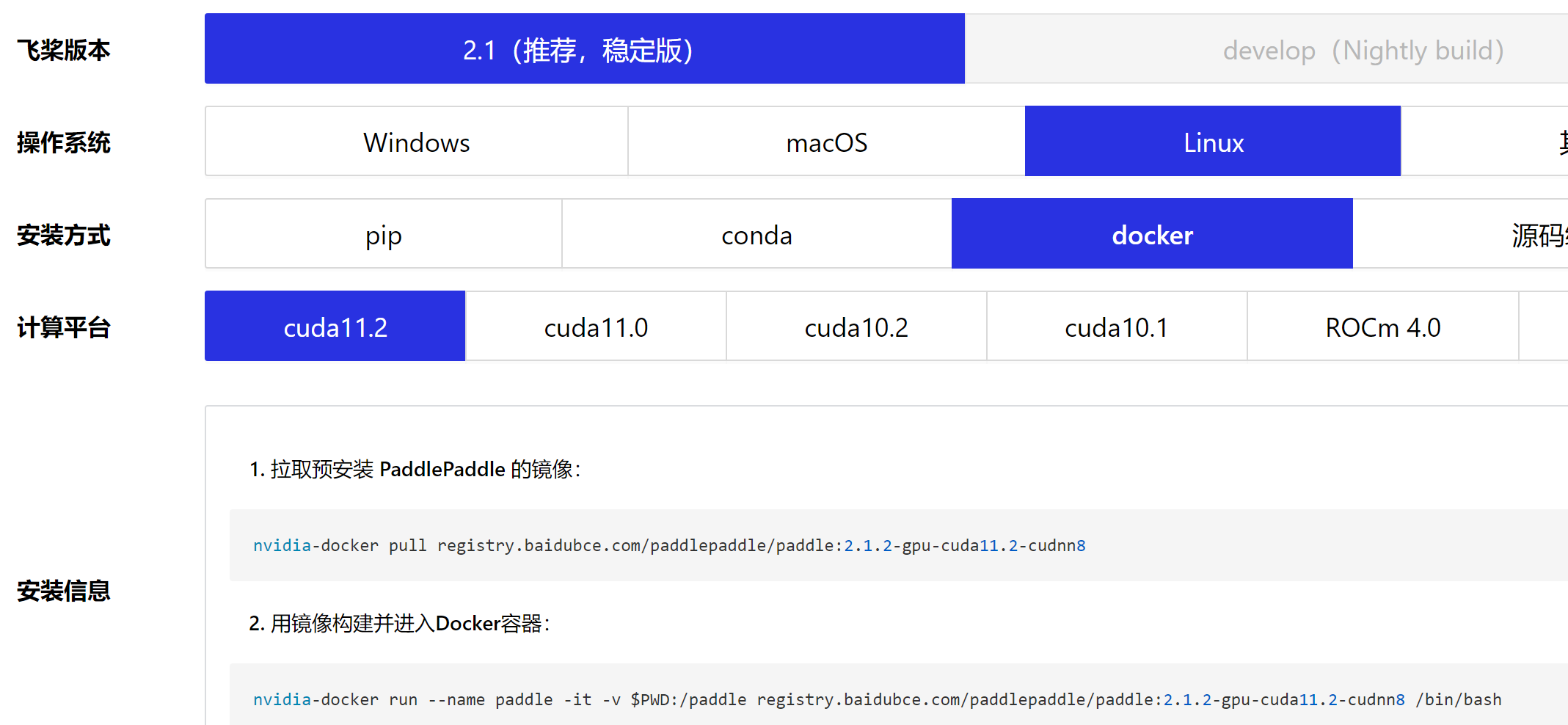
然后就报错cuda版本不匹配

容器对应的镜像要求cuda版本是11.2以上,但是宿主机的cuda版本只有11.1。
docker: Error response from daemon: OCI runtime create failed:
container_linux.go:367: starting container process caused:
process_linux.go:495: container init caused:
Running hook #0:: error running hook: exit status 1,
stdout: , stderr:
nvidia-container-cli: requirement error:
unsatisfied condition: cuda>=11.2,
please update your driver to a newer version, or use an earlier cuda container: unknown.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
参考:Ubuntu 配置docker以及 nvidia-docker
基本可以确定是因为宿主机的cuda驱动版本低导致的,网上大部分的说法是:
保持最新即可,CUDA驱动版本要求和CUDA版本匹配,而CUDA又要求cuDNN/TF是匹配的。不过CUDA驱动版本是向下兼容的,所以保持最新就没事
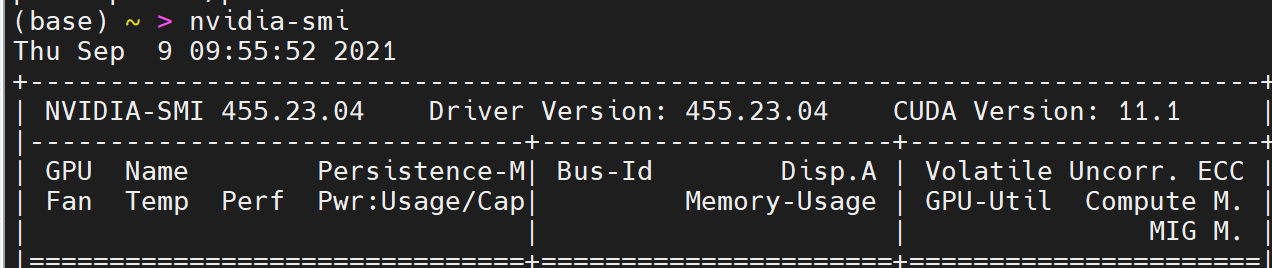
可以看到,nvidia-smi的版本和driver version驱动版本是一致的,cuda版本另算,不过两者之间有一定的对应关系,例如:
CUDA 10.0 containers至少需要cuda驱动版本是410
CUDA 10.1 containers至少需要cuda驱动版本是418
- 1
- 2

2.2 解决方案
很明显只有两条路可以走:
- 更新cuda版本
- 重新下载一个老一点的镜像,对cuda版本要求低一些的
搜索分析可行性和代价:
方案一:更新cuda版本
网上找到的答案大部分都是如何安装,没有更新的,关于更新的也都是建议卸载重装,其实还是属于安装。。。
参考:
- stack-overflow问题:Tensorflow/nvidia/cuda docker mismatched versions
- stackExchange问题:How do I Install CUDA on Ubuntu 18.04?
# 找到的有用信息就是如何安装,看起来比较简洁,记录下来
#In a terminal, type:
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
sudo ubuntu-drivers autoinstall
# 重启
sudo apt install nvidia-cuda-toolkit gcc-6
nvcc --version
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
如果要更新,需要先卸载所有cuda相关的内容,包括驱动,cuda以及cudnn等;然后再进行安装。
另外,在这个问题下,发现了nvidia的官方链接:NVIDIA CUDA Installation Guide for Linux,详细介绍写在本文第四部分。
结论就是官方文档也说想要安装新的,必须卸载旧的,没有可以直接更新的方式
方案二:重新下载一个老一点的镜像,从风险和耗费时间来看,都是这个比较靠谱!行动,
# 查看当前使用这个镜像的容器有哪些
docker ps -a|grep paddle
# 根据上面筛选出的容器,先关闭再删除
docker stop 容器ID
docker rm 容器ID
# 删除完容器之后再去删除镜像
docker rmi 镜像名称
# 删除镜像之前要先查看 通过这个镜像产生的容器有没有关闭和删除,不然镜像删不干净
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

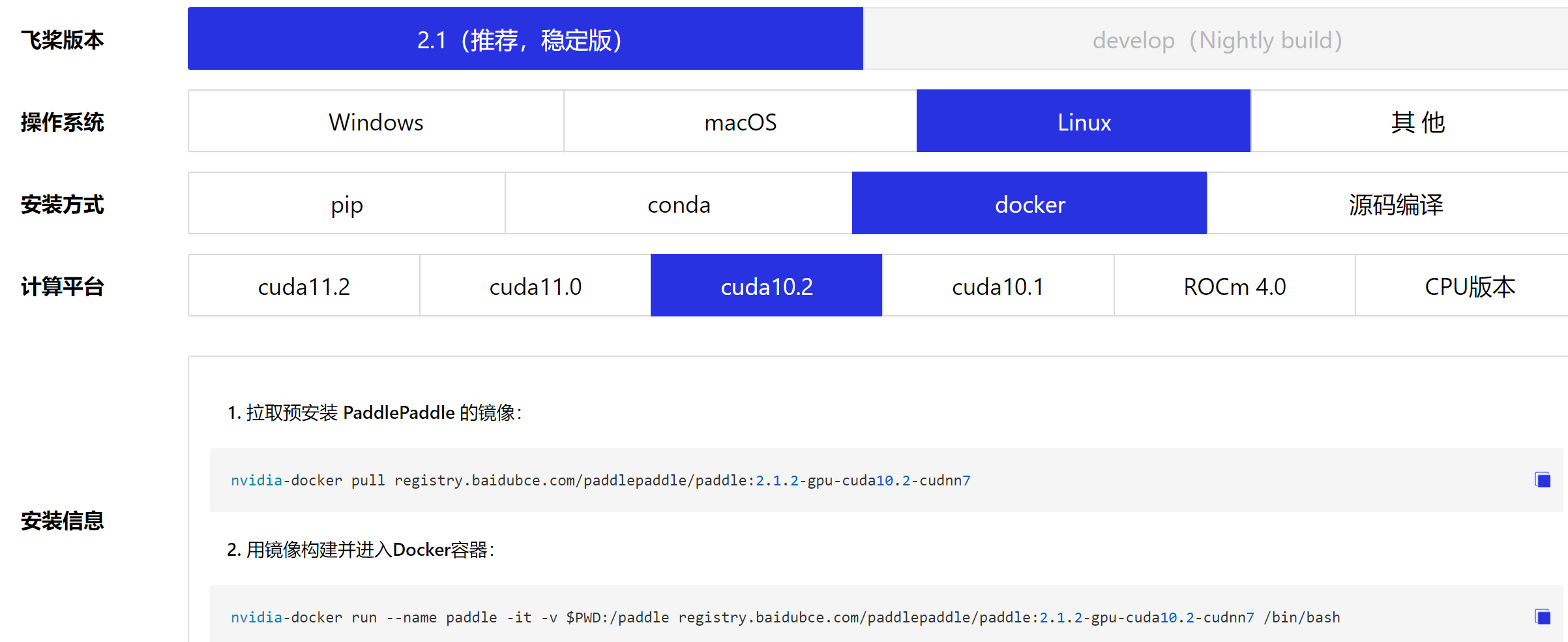
搞一个老版本的
3. ubuntu上安装GPU驱动
参考:谷歌云-安装 GPU 驱动程序
科学上网才可以访问这个网页
主要就是搬运一下,也许以后用得到
# 1. 更新代码库 sudo apt-get update # 2. 搜索最新的 NVIDIA 内核模块软件包或您所需的版本。此软件包包含由 Ubuntu 密钥签名的 NVIDIA 内核模块。运行以下命令以查看最新的软件包 NVIDIA_DRIVER_VERSION=$(sudo apt-cache search 'linux-modules-nvidia-[0-9]+-gcp$' | awk '{print $1}' | sort | tail -n 1 | head -n 1 | awk -F"-" '{print $4}') """ 注意: 如果您要查找早期版本,请更改 tail 命令中的数字以获取早期版本。 例如,将数字指定为 2 可获取下一个早期版本: NVIDIA_DRIVER_VERSION=$(sudo apt-cache search 'linux-modules-nvidia-[0-9]+-gcp$' | awk '{print $1}' | sort | tail -n 2 | head -n 1 | awk -F"-" '{print $4}') """ # 3. 安装内核模块软件包和相应的 NVIDIA 驱动程序: sudo apt install linux-modules-nvidia-${NVIDIA_DRIVER_VERSION}-gcp nvidia-driver-${NVIDIA_DRIVER_VERSION} """ 如果该命令失败,并且显示“找不到软件包”错误,则代码库可能缺少最新的 nvidia 驱动程序。返回到最后一步,以查找早期驱动程序版本。 注意:安装软件包时,系统可能会升级您的内核。 """ # 4. 验证是否已安装 NVIDIA 驱动程序,可能需要重启系统 nvidia-smi # 5. 找到兼容的 CUDA 驱动程序版本。以下脚本确定与我们刚刚安装的 NVIDIA 驱动程序兼容的最新 CUDA 驱动程序版本: CUDA_DRIVER_VERSION=$(apt-cache madison cuda-drivers | awk '{print $3}' | sort -r | while read line; do if dpkg --compare-versions $(dpkg-query -f='${Version}\n' -W nvidia-driver-${NVIDIA_DRIVER_VERSION}) ge $line ; then echo "$line" break fi done) """ 也可以通过运行 echo $CUDA_DRIVER_VERSION 来检查 CUDA 驱动程序版本。输出是一个类似于 455.32.00-1 的版本字符串。 """ # 6. 使用上一步中识别的版本安装 CUDA 驱动程序。 sudo apt install cuda-drivers-${NVIDIA_DRIVER_VERSION}=${CUDA_DRIVER_VERSION} cuda-drivers=${CUDA_DRIVER_VERSION} # 7. 安装 CUDA 工具包和运行时。选择合适的 CUDA 版本。以下脚本确定与我们刚刚安装的 CUDA 驱动程序兼容的最新 CUDA 版本: CUDA_VERSION=$(apt-cache showpkg cuda-drivers | grep -o 'cuda-runtime-[0-9][0-9]-[0-9],cuda-drivers [0-9\.]*' | while read line; do if dpkg --compare-versions ${CUDA_DRIVER_VERSION} ge $(echo $line | grep -Eo '[[:digit:]]+\.[[:digit:]]+') ; then echo $(echo $line | grep -Eo '[[:digit:]]+-[[:digit:]]') break fi done) """ 您可以通过运行 echo $CUDA_VERSION 来检查 CUDA 版本。输出是一个类似于 11-1 的版本字符串。 安装 CUDA 软件包: sudo apt install cuda-${CUDA_VERSION} """ # 8. 验证 CUDA 安装: sudo nvidia-smi /usr/local/cuda/bin/nvcc --version """ 第一条命令输出 GPU 信息。第二条命令输出已安装的 CUDA 编译器版本。 """

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
4. NVIDIA CUDA Installation Guide for Linux
- nvidia的官方链接:NVIDIA CUDA Installation Guide for Linux
其实这个英伟达的文档也是超级详细,以linux环境下安装cuda这个为例,看看(这里版本是11.4.1,如果想看其他版本的,可以点击这里或者cuda-toolkit-archive,加载速度可能会很慢,耐心等待,我以11.2.0为例进行说明):

文档链接地址:
https://docs.nvidia.com/cuda/archive/11.2.1/cuda-installation-guide-linux/index.html
安装需求
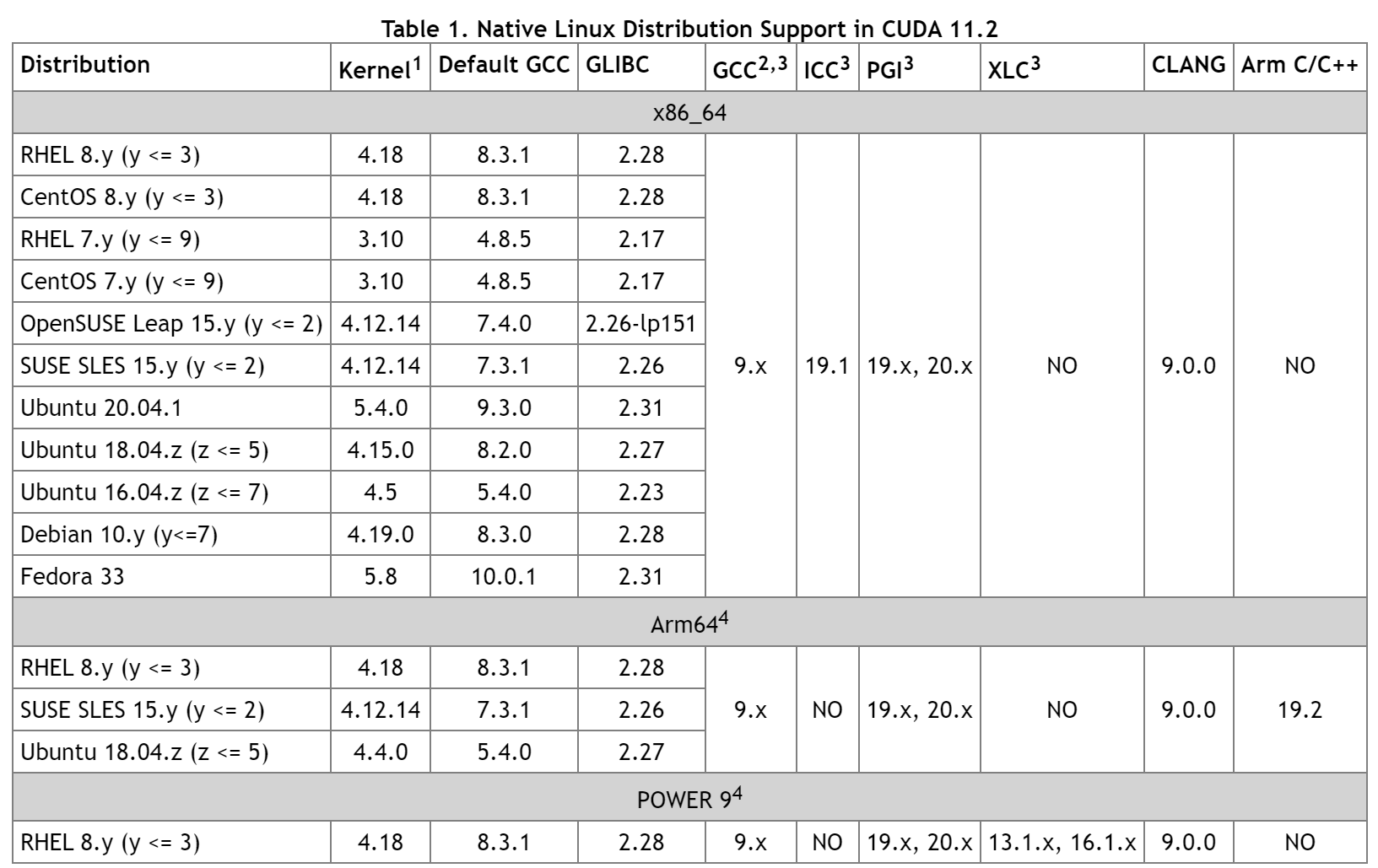
一上来就是一个大表,重点关注其中gcc版本是9.x就好了。
处理安装版本冲突
这就是我一直纠结的地方,
Before installing CUDA, any previously installations that could conflict should be uninstalled. This will not affect systems which have not had CUDA installed previously, or systems where the installation method has been preserved (RPM/Deb vs. Runfile). See the following charts for specifics.
安装cuda之前,可能造成冲突的任何之前的安装都需要卸载掉,之前没有安装过cuda的系统无所谓,或者是之前的安装是保留的,如下表:
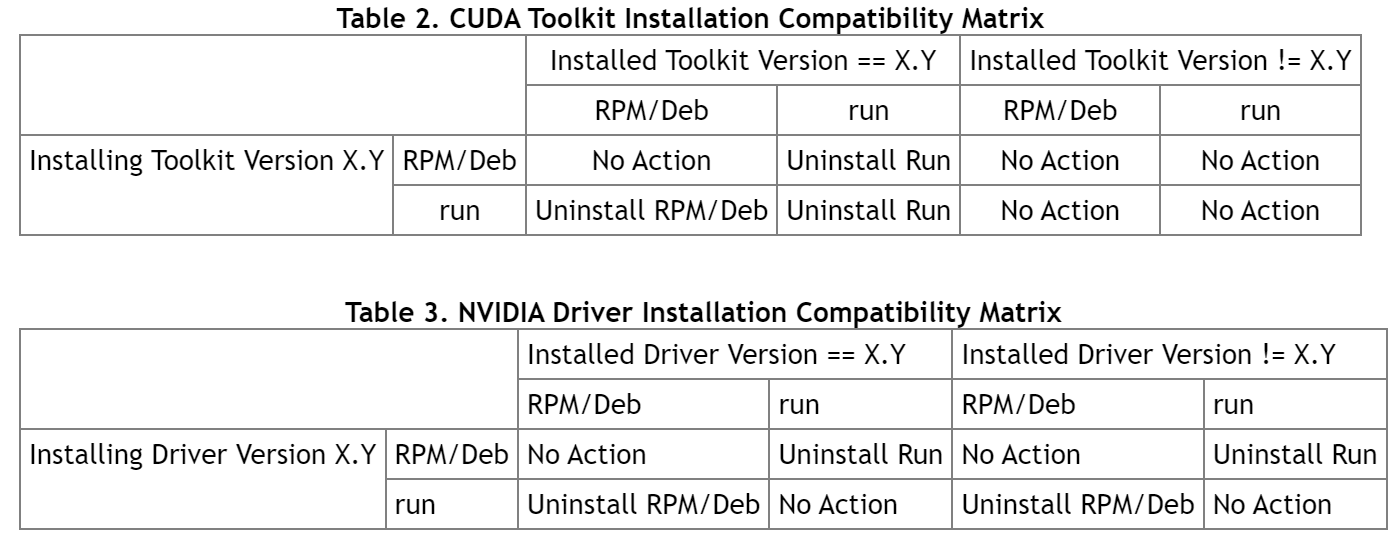
# Use the following command to uninstall a Toolkit runfile installation:
# 使用下列语句卸载一个toolkit runfile的安装
$ sudo /usr/local/cuda-X.Y/bin/uninstall_cuda_X.Y.pl
# Use the following command to uninstall a Driver runfile installation:
# 使用下列语句完成驱动的卸载
$ sudo /usr/bin/nvidia-uninstall
#Use the following commands to uninstall a RPM/Deb installation:
# 使用下列语句完成通过RPM或者Deb安装的卸载
$ sudo dnf remove <package_name> # RHEL8/CentOS8
$ sudo yum remove <package_name> # RHEL7/CentOS7
$ sudo dnf remove <package_name> # Fedora
$ sudo zypper remove <package_name> # OpenSUSE/SLES
$ sudo apt-get --purge remove <package_name> # Ubuntu
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
所以结论就是没有直接更新的方法,如果想要更新到新版本,必须卸载重装!

