
热门标签
热门文章
- 1ElementUI之表格组件
- 2git clone时curl 18 transfer closed with outstanding read data remaining_error: rpc failed; curl 18 transfer closed with ou
- 3数据结构之堆_堆分为大根堆和小跟堆
- 4Qt Window Dialog 无标题栏 ,无边框,可拖动_qt dialog创建无标题栏
- 5泊松分布的通俗理解、推导与应用
- 6前端基础汇总_前端 技术
- 7SQL Server数据库简单查询_sql server查询
- 8【C++】STL 容器 - queue 队列容器 ( queue 容器简介 | queue 容器特点 | push 函数 | pop 函数 | front 函数 )_c++ stl中queue中使用push在队尾插入以及使用pop从队首删除
- 9如何获取注册高德Key使用的SHA1值与包名?_s证书sha1值和apk的sha1不一样
- 10文献学习-14-一种用于高精度微创手术的纤维机器人
当前位置: article > 正文
YOLOv9 网络结构 backbone 中的 RepNCSPELAN4 和 ADown 模块
作者:小丑西瓜9 | 2024-06-13 02:48:18
赞
踩
repncspelan4
看了YOLOv9的论文和代码,整理了一下网络中用到的模块,以方便理解和日后参考使用。
yolov9论文:YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
yolov9源码:https://github.com/WongKinYiu/yolov9
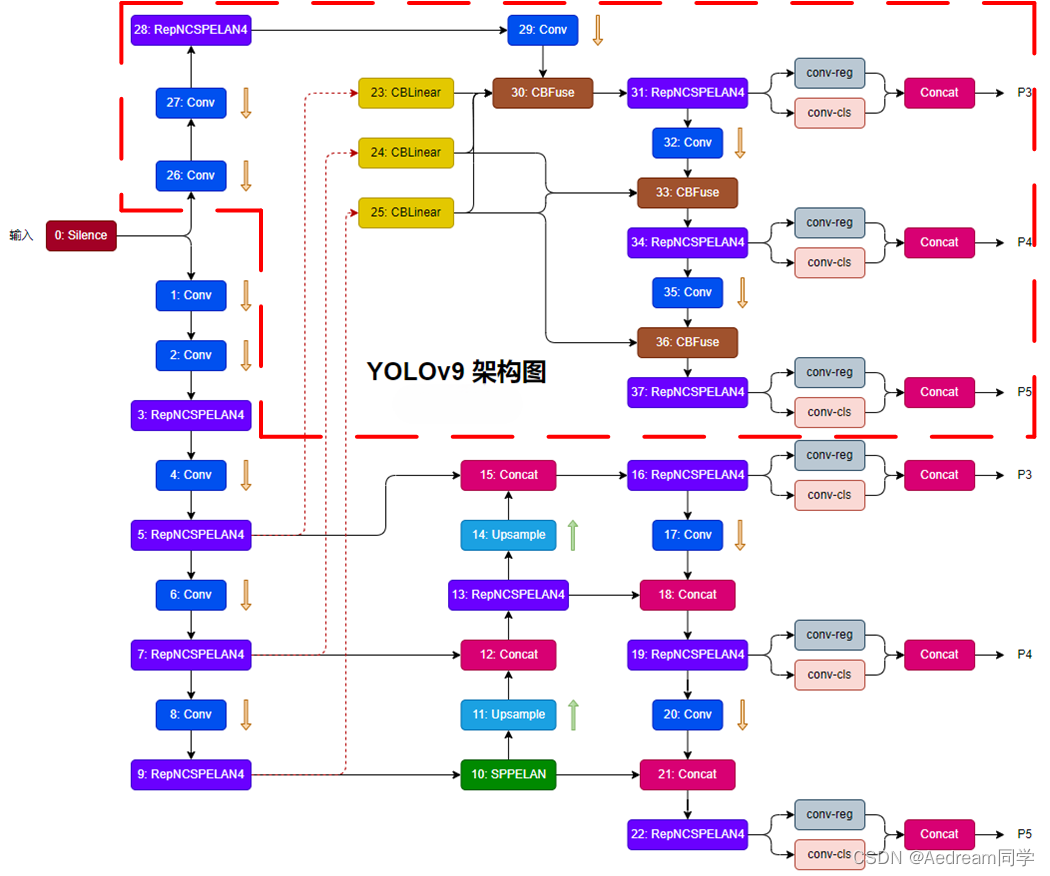
YOLOv9整体网络结构图
这里参考 https://blog.csdn.net/qq_44029998/article/details/136324589
backbone中的 RepNCSPELAN4 模块结构

1、模块的参数输入[c1, c2, c3, c4, c5=1],c1为模块的输入channel(上一模块的输出), c2为模块的输出channel
2、RepNCSPELAN4模块的整体结构,结合了CSP模块和ELAN模块

这两个模块对应的两篇参考文献
《CSPNet: A New Backbone that can Enhance Learning Capability of CNN》
《Designing Network Design Strategies Through Gradient Path Analysis》
3、RepNCSPELAN4 模块代码
class RepNCSPELAN4(nn.Module): # csp-elan def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion super().__init__() self.c = c3//2 self.cv1 = Conv(c1, c3, 1, 1) self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1)) self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1)) self.cv4 = Conv(c3+(2*c4), c2, 1, 1) def forward(self, x): y = list(self.cv1(x).chunk(2, 1)) y.extend((m(y[-1])) for m in [self.cv2, self.cv3]) return self.cv4(torch.cat(y, 1)) def forward_split(self, x): y = list(self.cv1(x).split((self.c, self.c), 1)) y.extend(m(y[-1]) for m in [self.cv2, self.cv3]) return self.cv4(torch.cat(y, 1))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
RepNCSPELAN4 的子模块 RepNCSP

1、RepNCSP 模块的输入参数为(c1, c2, n=1, shortcut=True, g=1, e=0.5)
2、RepNCSP模块模块代码
class RepNCSP(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(RepNBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
RepNCSP中的子模块RepNBottleneck

模块代码
class RepNBottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = RepConvN(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
RepNBottleneck中的子模块RepConvN
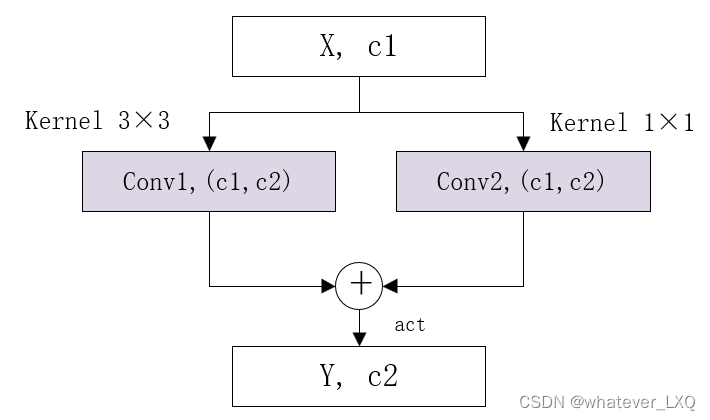
模块代码
class RepConvN(nn.Module): """RepConv is a basic rep-style block, including training and deploy status This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py """ default_act = nn.SiLU() # default activation def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False): super().__init__() assert k == 3 and p == 1 self.g = g self.c1 = c1 self.c2 = c2 self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() self.bn = None self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False) self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False) def forward_fuse(self, x): """Forward process""" return self.act(self.conv(x)) def forward(self, x): """Forward process""" id_out = 0 if self.bn is None else self.bn(x) return self.act(self.conv1(x) + self.conv2(x) + id_out) def get_equivalent_kernel_bias(self): kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1) kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2) kernelid, biasid = self._fuse_bn_tensor(self.bn) return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid def _avg_to_3x3_tensor(self, avgp): channels = self.c1 groups = self.g kernel_size = avgp.kernel_size input_dim = channels // groups k = torch.zeros((channels, input_dim, kernel_size, kernel_size)) k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2 return k def _pad_1x1_to_3x3_tensor(self, kernel1x1): if kernel1x1 is None: return 0 else: return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1]) def _fuse_bn_tensor(self, branch): if branch is None: return 0, 0 if isinstance(branch, Conv): kernel = branch.conv.weight running_mean = branch.bn.running_mean running_var = branch.bn.running_var gamma = branch.bn.weight beta = branch.bn.bias eps = branch.bn.eps elif isinstance(branch, nn.BatchNorm2d): if not hasattr(self, 'id_tensor'): input_dim = self.c1 // self.g kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32) for i in range(self.c1): kernel_value[i, i % input_dim, 1, 1] = 1 self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device) kernel = self.id_tensor running_mean = branch.running_mean running_var = branch.running_var gamma = branch.weight beta = branch.bias eps = branch.eps std = (running_var + eps).sqrt() t = (gamma / std).reshape(-1, 1, 1, 1) return kernel * t, beta - running_mean * gamma / std def fuse_convs(self): if hasattr(self, 'conv'): return kernel, bias = self.get_equivalent_kernel_bias() self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels, out_channels=self.conv1.conv.out_channels, kernel_size=self.conv1.conv.kernel_size, stride=self.conv1.conv.stride, padding=self.conv1.conv.padding, dilation=self.conv1.conv.dilation, groups=self.conv1.conv.groups, bias=True).requires_grad_(False) self.conv.weight.data = kernel self.conv.bias.data = bias for para in self.parameters(): para.detach_() self.__delattr__('conv1') self.__delattr__('conv2') if hasattr(self, 'nm'): self.__delattr__('nm') if hasattr(self, 'bn'): self.__delattr__('bn') if hasattr(self, 'id_tensor'): self.__delattr__('id_tensor')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
ADown
backbone中的ADown是降低feature map的尺寸

模块代码
class ADown(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
self.c = c2 // 2
self.cv1 = Conv(c1 // 2, self.c, 3, 2, 1)
self.cv2 = Conv(c1 // 2, self.c, 1, 1, 0)
def forward(self, x):
x = torch.nn.functional.avg_pool2d(x, 2, 1, 0, False, True)
x1,x2 = x.chunk(2, 1)
x1 = self.cv1(x1)
x2 = torch.nn.functional.max_pool2d(x2, 3, 2, 1)
x2 = self.cv2(x2)
return torch.cat((x1, x2), 1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小丑西瓜9/article/detail/710596
推荐阅读
相关标签

