
- 1记一次win系统的bat(批处理文件)使用_bat chcp 65001
- 2deepin安装bochs2.6.2_2.kafka安装与使用
- 3SpringMVC的工作原理及组件_springmvc实现原理和常用组件
- 4Docke部署本地私有镜像仓库_docke 修改镜像地址
- 5Yolov1 + Yolov2 + Yolov3 发展史、论文、代码最全资源分享合集 ! ! !_yolov用什么语言
- 6关于微信回调页面域名授权时将文件放到域名的根目录问题_微信域名配置文件放到根目录了,为什么访问不到
- 73D Gaussian Splatting 应用场景及最新进展【附10篇前沿论文和代码】_3d gaussian splatting csdn
- 8关于LaTex 插入图片的方法_latex插入图片
- 9关于SpringCloud的知识点总结(基础版)
- 10js高级—tab栏切换(面向对象做法)_nav tabs js切换
(pytorch进阶之路)U-Net图像分割
赞
踩
概述
在开始u-net用在生物图像分割,细胞电镜图片输入到U-net输出一张细胞组织分割的图像
作者提出了U型的架构做图像分割的任务,照片输入到网络,输出对每个像素点的分类,如分类像素点是目标对象还是背景,给不同的分类对象涂上不同的颜色
总体模型:
输入单通道572×572,输出2通道388×388,2通道是因为做的 像素二分类,572是从388填充而来的,外围做的镜像填充,这样外围的像素点也有上下文信
网络的第一阶段
首先单通道572×572经过3×3的卷积,得到570×570,输出通道数为64
结果再送入3×3的卷积,得到64通道的568×568
第二阶段,将像素面积进行1/2的收缩,对通道数进行2倍的扩张。
首先用的2×2的max pooling层,将568×568缩小为284×284,通道数目不变仍然为64,和第一阶段一样在经过两个3×3的卷积,通道数扩大2倍
第三、四、五阶段和第二阶段结构一致,再次面积压缩1/2,通道数扩增到2倍
第五阶段来到了U型最底层,此时大小为32×32,经过两次3×3卷积变成28×28,通道数为1024
解码器第一阶段:
到有U型右侧为反向过程,面积逐渐放大,通道数逐渐减小,通过反卷积恢复原来的形状如28恢复到56(up-conv 2×2),此时我们把之前的高像素的特征通道512复制过来,之前的空间需要做一步裁剪再做拼接,这步操作被称为skip concatenate,方便复原具体的细节,得到56×56通道数1024,经过两个卷积得到52×52×512
解码器第二三四阶段和第一阶段结构一致,上采样,空间大小变大,通道数拼接后恢复原样
最后变成388×388×64,后接一个分类层1×1conv(MLP)输出388×388×2
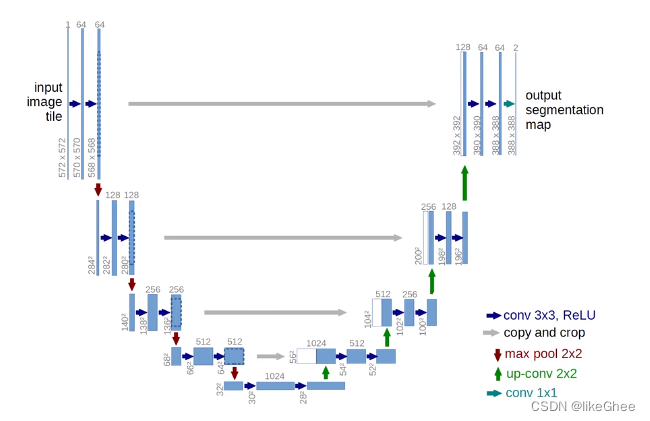
Unet特点:完全是卷积的结构,seq2seq模型,分为编码器和解码器
代码实现
地址
https://github.com/yassouali/pytorch-segmentation
某开源项目里面models文件夹包含了许多分割图像模型
实现仅供参考,有些地方写的不是很规范
完整代码
Unet部分代码如下
from base import BaseModel import torch import torch.nn as nn import torch.nn.functional as F from itertools import chain from base import BaseModel from utils.helpers import initialize_weights, set_trainable from itertools import chain from models import resnet def x2conv(in_channels, out_channels, inner_channels=None): inner_channels = out_channels // 2 if inner_channels is None else inner_channels down_conv = nn.Sequential( nn.Conv2d(in_channels, inner_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(inner_channels), nn.ReLU(inplace=True), nn.Conv2d(inner_channels, out_channels, kernel_size=3, padding=1, bias=False), nn.BatchNorm2d(out_channels), nn.ReLU(inplace=True)) return down_conv class encoder(nn.Module): def __init__(self, in_channels, out_channels): super(encoder, self).__init__() self.down_conv = x2conv(in_channels, out_channels) self.pool = nn.MaxPool2d(kernel_size=2, ceil_mode=True) def forward(self, x): x = self.down_conv(x) x = self.pool(x) return x class decoder(nn.Module): def __init__(self, in_channels, out_channels): super(decoder, self).__init__() self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) self.up_conv = x2conv(in_channels, out_channels) def forward(self, x_copy, x, interpolate=True): x = self.up(x) if (x.size(2) != x_copy.size(2)) or (x.size(3) != x_copy.size(3)): if interpolate: # Iterpolating instead of padding x = F.interpolate(x, size=(x_copy.size(2), x_copy.size(3)), mode="bilinear", align_corners=True) else: # Padding in case the incomping volumes are of different sizes diffY = x_copy.size()[2] - x.size()[2] diffX = x_copy.size()[3] - x.size()[3] x = F.pad(x, (diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2)) # Concatenate x = torch.cat([x_copy, x], dim=1) x = self.up_conv(x) return x class UNet(BaseModel): def __init__(self, num_classes, in_channels=3, freeze_bn=False, **_): super(UNet, self).__init__() self.start_conv = x2conv(in_channels, 64) self.down1 = encoder(64, 128) self.down2 = encoder(128, 256) self.down3 = encoder(256, 512) self.down4 = encoder(512, 1024) self.middle_conv = x2conv(1024, 1024) self.up1 = decoder(1024, 512) self.up2 = decoder(512, 256) self.up3 = decoder(256, 128) self.up4 = decoder(128, 64) self.final_conv = nn.Conv2d(64, num_classes, kernel_size=1) self._initialize_weights() if freeze_bn: self.freeze_bn() def _initialize_weights(self): for module in self.modules(): if isinstance(module, nn.Conv2d) or isinstance(module, nn.Linear): nn.init.kaiming_normal_(module.weight) if module.bias is not None: module.bias.data.zero_() elif isinstance(module, nn.BatchNorm2d): module.weight.data.fill_(1) module.bias.data.zero_() def forward(self, x): x1 = self.start_conv(x) x2 = self.down1(x1) x3 = self.down2(x2) x4 = self.down3(x3) x = self.middle_conv(self.down4(x4)) x = self.up1(x4, x) x = self.up2(x3, x) x = self.up3(x2, x) x = self.up4(x1, x) x = self.final_conv(x) return x def get_backbone_params(self): # There is no backbone for unet, all the parameters are trained from scratch return [] def get_decoder_params(self): return self.parameters() def freeze_bn(self): for module in self.modules(): if isinstance(module, nn.BatchNorm2d): module.eval() """ -> Unet with a resnet backbone """ class UNetResnet(BaseModel): def __init__(self, num_classes, in_channels=3, backbone='resnet50', pretrained=True, freeze_bn=False, freeze_backbone=False, **_): super(UNetResnet, self).__init__() model = getattr(resnet, backbone)(pretrained, norm_layer=nn.BatchNorm2d) self.initial = list(model.children())[:4] if in_channels != 3: self.initial[0] = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3, bias=False) self.initial = nn.Sequential(*self.initial) # encoder self.layer1 = model.layer1 self.layer2 = model.layer2 self.layer3 = model.layer3 self.layer4 = model.layer4 # decoder self.conv1 = nn.Conv2d(2048, 192, kernel_size=3, stride=1, padding=1) self.upconv1 = nn.ConvTranspose2d(192, 128, 4, 2, 1, bias=False) self.conv2 = nn.Conv2d(1152, 128, kernel_size=3, stride=1, padding=1) self.upconv2 = nn.ConvTranspose2d(128, 96, 4, 2, 1, bias=False) self.conv3 = nn.Conv2d(608, 96, kernel_size=3, stride=1, padding=1) self.upconv3 = nn.ConvTranspose2d(96, 64, 4, 2, 1, bias=False) self.conv4 = nn.Conv2d(320, 64, kernel_size=3, stride=1, padding=1) self.upconv4 = nn.ConvTranspose2d(64, 48, 4, 2, 1, bias=False) self.conv5 = nn.Conv2d(48, 48, kernel_size=3, stride=1, padding=1) self.upconv5 = nn.ConvTranspose2d(48, 32, 4, 2, 1, bias=False) self.conv6 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1) self.conv7 = nn.Conv2d(32, num_classes, kernel_size=1, bias=False) initialize_weights(self) if freeze_bn: self.freeze_bn() if freeze_backbone: set_trainable([self.initial, self.layer1, self.layer2, self.layer3, self.layer4], False) def forward(self, x): H, W = x.size(2), x.size(3) x1 = self.layer1(self.initial(x)) x2 = self.layer2(x1) x3 = self.layer3(x2) x4 = self.layer4(x3) x = self.upconv1(self.conv1(x4)) x = F.interpolate(x, size=(x3.size(2), x3.size(3)), mode="bilinear", align_corners=True) x = torch.cat([x, x3], dim=1) x = self.upconv2(self.conv2(x)) x = F.interpolate(x, size=(x2.size(2), x2.size(3)), mode="bilinear", align_corners=True) x = torch.cat([x, x2], dim=1) x = self.upconv3(self.conv3(x)) x = F.interpolate(x, size=(x1.size(2), x1.size(3)), mode="bilinear", align_corners=True) x = torch.cat([x, x1], dim=1) x = self.upconv4(self.conv4(x)) x = self.upconv5(self.conv5(x)) # if the input is not divisible by the output stride if x.size(2) != H or x.size(3) != W: x = F.interpolate(x, size=(H, W), mode="bilinear", align_corners=True) x = self.conv7(self.conv6(x)) return x def get_backbone_params(self): return chain(self.initial.parameters(), self.layer1.parameters(), self.layer2.parameters(), self.layer3.parameters(), self.layer4.parameters()) def get_decoder_params(self): return chain(self.conv1.parameters(), self.upconv1.parameters(), self.conv2.parameters(), self.upconv2.parameters(), self.conv3.parameters(), self.upconv3.parameters(), self.conv4.parameters(), self.upconv4.parameters(), self.conv5.parameters(), self.upconv5.parameters(), self.conv6.parameters(), self.conv7.parameters()) def freeze_bn(self): for module in self.modules(): if isinstance(module, nn.BatchNorm2d): module.eval()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
在class UNet的init函数中定义了所需的所有模块
start_conv定义了一开始的卷积,从通道为1到64的卷积,x2conv
后面是4个down模块,下采样模块从64依次扩充到128,256,512,1024
中间还有一个卷积层1024到1024
后面是4个up模块,上采样从1024依次降维到512,256,128,64
上采样完成最后还有一层分类层1×1卷积MLP
forward中就将这些层连接起来
下面是逐个拆解每个函数
x2conv
包含两个卷积层,核心为nn.Sequential,第一层卷积是一个3×3,padding=1,通道数不变,这样H和W缩小两个像素
第二层卷积,对通道数目变化为out_channel,3×3,padding为1
每个阶段都可以用这两个卷积去构建
def x2conv(in_channels, out_channels, inner_channels=None):
inner_channels = out_channels // 2 if inner_channels is None else inner_channels
down_conv = nn.Sequential(
nn.Conv2d(in_channels, inner_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(inner_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inner_channels, out_channels, kernel_size=3, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True))
return down_conv
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
encoder
包含两层,首先是x2conv模块的2个3×3的padding=1卷积,第二部分maxpool2d,kernel_size=2,空间压缩为原来的一半
class encoder(nn.Module):
def __init__(self, in_channels, out_channels):
super(encoder, self).__init__()
self.down_conv = x2conv(in_channels, out_channels)
self.pool = nn.MaxPool2d(kernel_size=2, ceil_mode=True)
def forward(self, x):
x = self.down_conv(x)
x = self.pool(x)
return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
decoder
和encoder反过来,先做2d的反卷积,做上采样,输入in_channel,输出通道in_channel // 2, kernel_size=2,stride=2,完成2倍的上采样,接着就是x2conv的两层卷积
forward中会把x_copy拿进来,这个x_copy就是从编码器中取出那部分, 和x进行concatenate操作,将拼接起来的x送入x2conv卷积,通道数变小
class decoder(nn.Module): def __init__(self, in_channels, out_channels): super(decoder, self).__init__() self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2) self.up_conv = x2conv(in_channels, out_channels) def forward(self, x_copy, x, interpolate=True): x = self.up(x) if (x.size(2) != x_copy.size(2)) or (x.size(3) != x_copy.size(3)): if interpolate: # Iterpolating instead of padding x = F.interpolate(x, size=(x_copy.size(2), x_copy.size(3)), mode="bilinear", align_corners=True) else: # Padding in case the incomping volumes are of different sizes diffY = x_copy.size()[2] - x.size()[2] diffX = x_copy.size()[3] - x.size()[3] x = F.pad(x, (diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2)) # Concatenate x = torch.cat([x_copy, x], dim=1) x = self.up_conv(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
其他应用:WAVE-U-NET,人声伴奏分离
论文地址:
https://ismir2018.ismir.net/doc/pdfs/205_Paper.pdf
项目地址:
https://github.com/f90/Wave-U-Net
结构图:输入的一维的语音波形,左边是编码器,对1维的波形进行逐步的下采样,右边解码器逐步对波形进行上采样,并且在解码器每个阶段对应编码器的高采样率的特征拼接起来,最后分离多个类别,有K个通道最后分类到C个通道上,每个通道对应的就是不同的波形


