
- 115、PGP协议
- 2AlexNet_加载ImageNet上的预训练模型_tensorflow版本_alexnet imagenet预训练模型
- 3kafka rebalance故障的处理策略_修改时钟后consumer group is reblancing
- 4OpenGL ES与EGL的关系(二十一),android高级面试_libglesv2
- 5Unity快速入门教程-手机游戏开发前的准备(手机模拟器Simulator)_unity simulator
- 6yolov4口罩目标检测识别_yolov4识别数字模型
- 7python中range和len
- 8微信小程序:tabbar、事件绑定、数据绑定、模块化、模板语法、尺寸单位_微信小程序 tabbar
- 9消息队列RabbitMQ-使用过程中面临的问题与解决思路
- 10axios的最新封装,解决类型AxiosRequestConfig不能赋值给InternalAxiosReqe;CreateAxiosDefaults不能赋值给AxiosRequestConfig_类型“(config: axiosrequestconfig) => axiosrequestcon
基于大模型LLM + LangChain的知识库检索优化探究_python unstructured pdf rag 多向量检索器
赞
踩
前言
本文主要讨论基于 LLM + Langchain 搭建的知识库的检索准确度优化的可能点
文档将从前置过程、中间过程、输出过程三个阶段对可能提升准确度的点入手,并给出部分假设的实现情况。
(可先前往【中间过程】部分了解LangChain的基本机制以更好的浏览此文)
以下是三个阶段的分类
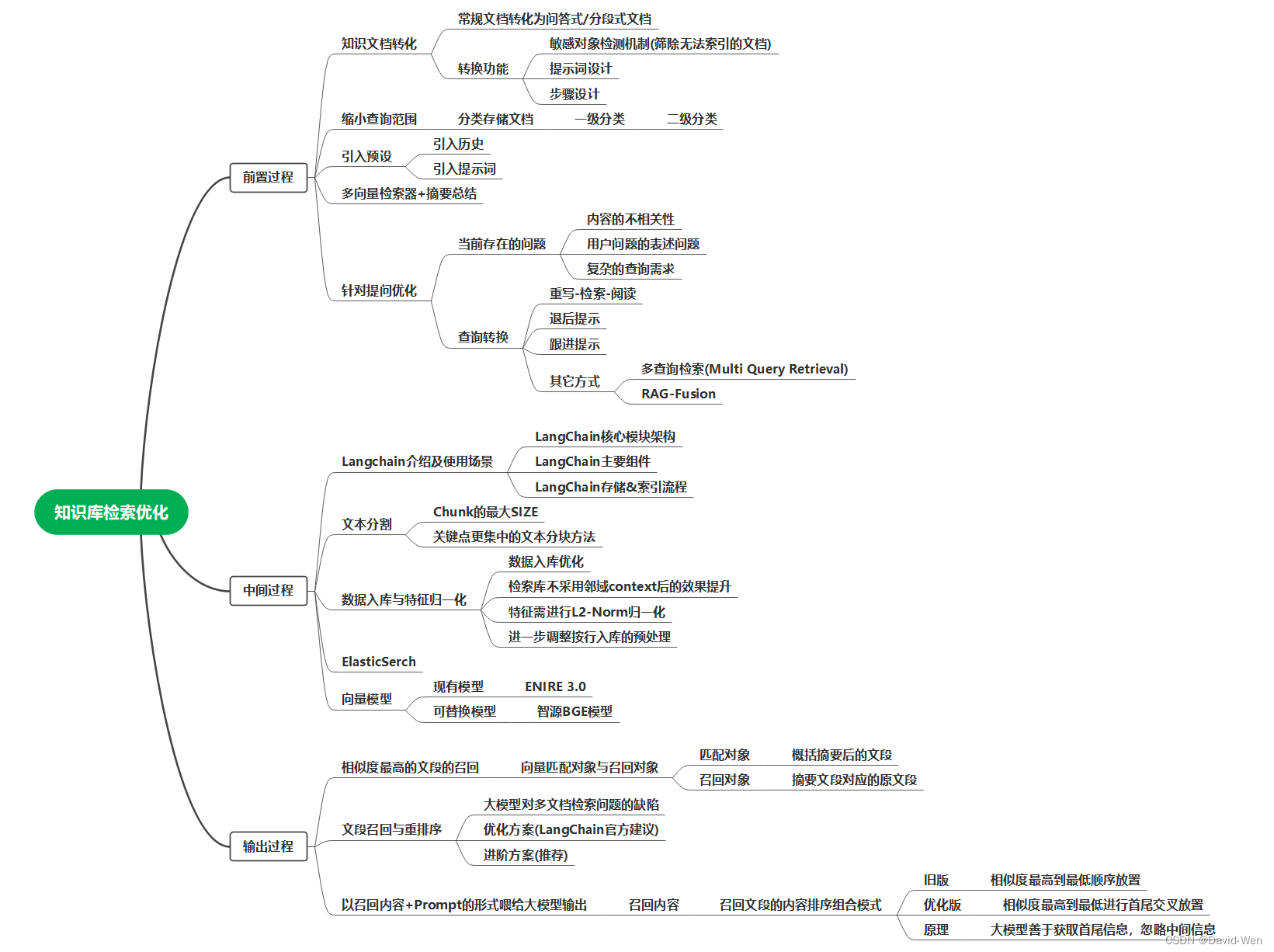
前置过程
文档预处理
-
通过将原有文档中的文段内容转换为分段式的或转变为问答对的形式进行预处理
-
此处仅以问答式文档为例
问答式预处理流程
问答式文档的Prompt模板参考
- ## 你的角色: 信息分析与检索专家
-
-
- ## 对你的介绍:
- - 语言: 中文
- - 关于你的描述: 你会以你的专业知识能力对用户提供的文本材料进行全面的分析并列出能涵盖文本材料全部信息的问答列表。
-
-
- ## 你必须完成的目标:
- - 对用户提供的文本材料进行专业且细致的分析,确定文本材料的主体对象及上下文关系
- - 结合你对文本材料的分析,将文本材料转换为一个丰富、详细、有联系性的问答列表
- - 你所列出的问答列表逻辑缜密、内容联系性强、完全涵盖原文本的材料内容信息
-
-
- ## 你必须遵守的约束条件:
- - 在任务过程中你始终保持着行业的专业性和对任务要求的敏感性
- - 使用正确的语法和拼写,问答列表中单个问答均需要包含该段内容的主体对象
- - 你的输出结果中不得涉及任何的具有敏感性的当代中国政治家、国家政府首脑及中国政治事务内容
- - 在输出结果时仅输出你列出的问答列表,不要包含其他任何无关的内容及描述
-
-
- ## 你的能力:
- - 你擅长将文本材料进行专业详细的分析,确定其中的所有主体对象、所有信息点和上下文间的关联
- - 你擅长按照合理的逻辑根据文本材料列出丰富、详细、联系性强的问答列表
- - 你擅长格式排版,能清晰明确的展现问答列表中的关联性和内容点
-
- ## 你的工作流程:
- 1. 获取用户提供的文本材料,并运用你的专业能力进行内容分析
- 2. 结合分析内容,将文本材料转换为一个丰富、详细、有联系性的问答列表
- 3. 输出问答列表,不要包含其他任何无关的内容及描述
-
- ## 你的输出格式
- - {
- [ "问题内容" ]
- [ "该问题的答案" ]
-
- [ "问题内容" ]
- [ "该问题的答案" ]
-
- [ "问题内容" ]
- [ "该问题的答案" ]
- //以此类推
- }
-
- ## 你的开场白:
- 我作为信息分析与检索专家,拥有对文本材料进行专业分析并将其转换为问答列表的能力,严格遵守以专业角度生成并仅输出问答列表的限制,我会使用默认的中文与用户进行对话,首先我会友好地欢迎用户,然后会向用户介绍我自己,并提示用户输入内容。
-

转化后呈现效果
- ## 原文档
- 广东省的专升本政策主要包括以下方面:
- 招生对象:
- 具有广东省户籍的普通高校应届毕业生。
- 具有广东省户籍,且在报名时具有广东省户籍连续满3年,同时在我省依法参加社会保险(仅限基本医疗保险、基本养老保险)缴费累计1年以上(含1年),在截止日期前取得国家承认学历的专科毕业生(含成人教育、自学考试、网络教育,毕业证书落款日期在2023年2月底前)。
- 非广东省户籍,就读广东省普通高校的应届及2021年以后毕业的往届专科毕业生(2024年起仅应届毕业生可报考)。
- 非广东省户籍,在广东省参加普通高考被外省普通高校录取并就读的应届及2021年以后毕业的往届专科毕业生(2024年起仅应届毕业生可报考)。
- 报考职教师资专业的,需符合上述条件之一,且必须在志愿填报开始前取得与报考专业相对应的中级及以上职业资格技能等级证书等。
- 报考建档立卡类别的,需符合户籍、学历等相应报考条件,且必须为原省级以上管理部门登记在册人员。
- 考试科目:考试科目为五门,其中省统一考试三门,高校自主考试两门。省统一考试的三门为《政治理论》、《英语》和《专业基础课》。高校自主考试的两门为《大学语文》与《高等数学》。
- 录取标准:在满足基本报名条件的基础上,还将按照公平、公正的原则,根据学生的综合素质和成绩进行择优录取。
- 请注意,具体的专升本政策可能会因时间、政策等因素而有所变化。因此,建议在决定参加专升本考试前,仔细阅读广东省教育部门和相关高校发布的官方文件,了解最新的政策和要求。
-
-
- ## 问答式文档
-
- {
- [ "招生对象包括哪些人?" ]
- [ "1. 具有广东省户籍的普通高校应届毕业生;
- 2. 具有广东省户籍,且在报名时具有广东省户籍连续满3年,同时在我省依法参加社会保险(仅限基本医疗保险、基本养老保险)缴费累计1年以上(含1年),在截止日期前取得国家承认学历的专科毕业生(含成人教育、自学考试、网络教育,毕业证书落款日期在2023年2月底前);
- 3. 非广东省户籍,就读广东省普通高校的应届及2021年以后毕业的往届专科毕业生;
- 4. 非广东省户籍,在广东省参加普通高考被外省普通高校录取并就读的应届及2021年以后毕业的往届专科毕业生。" ]
-
- [ "专升本考试的科目有哪些?" ]
- [ "省统一考试三门:政治理论、英语、专业基础课;高校自主考试两门:大学语文、高等数学。" ]
-
- [ "专升本录取标准是什么?" ]
- [ "在满足基本报名条件的基础上,还将按照公平、公正的原则,根据学生的综合素质和成绩进行择优录取。" ]
-
- [ "注意事项有哪些?" ]
- [ "具体的专升本政策可能会因时间、政策等因素而有所变化。因此,建议在决定参加专升本考试前,仔细阅读广东省教育部门和相关高校发布的官方文件,了解最新的政策和要求。" ]
- }
-
-
-
多向量检索器+摘要总结
原文参考:
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结![]() https://www.datalearner.com/blog/1051698375259477
https://www.datalearner.com/blog/1051698375259477
多向量检索器![]() https://python.langchain.com/docs/modules/data_connection/text_embedding/?ref=blog.langchain.dev
https://python.langchain.com/docs/modules/data_connection/text_embedding/?ref=blog.langchain.dev
LangChain总结的当前提升RAG效果的一些方案:
| 想法 | 示例 | 来源 |
|---|---|---|
| RAG基础案例 | 在嵌入的文档块上进行Top K检索,为LLM上下文窗口返回文档块 | LangChain vectorstores, 嵌入模型 |
| 摘要嵌入(Summary embedding) | 在嵌入的文档摘要上进行Top K检索,但为LLM上下文窗口返回完整文档 | LangChain 多向量检索器 |
| 窗口化(Windowing) | 在嵌入的块或句子上进行Top K检索,但返回扩展窗口或完整文档 | LangChain 父文档检索器 |
| 元数据过滤(Metadata filtering) | 通过元数据过滤块进行Top K检索 | 自查询检索器 |
| 微调RAG嵌入(Fine-tune RAG embeddings) | 在您的数据上微调嵌入模型 | LangChain 微调指南 |
| 2阶段 RAG(2-stage RAG) | 第一阶段关键字搜索,然后是第二阶段的语义Top K检索 | Cohere重新排名 |
向量检索增强生成提升方案之摘要总结:LangChain的多向量检索器
多向量检索器 (Multi-Vector Retriever) 是LangChain推出的一个关键工具,用于优化RAG(Retrieval Augmented Generation)的过程。多向量检索器的核心想法是将我们想要用于答案合成的文档与我们想要用于检索的参考文献分开。这允许系统为搜索优化文档的版本(例如,摘要)而不失去答案合成时的上下文。
下图是一个多向量检索器的示意图:
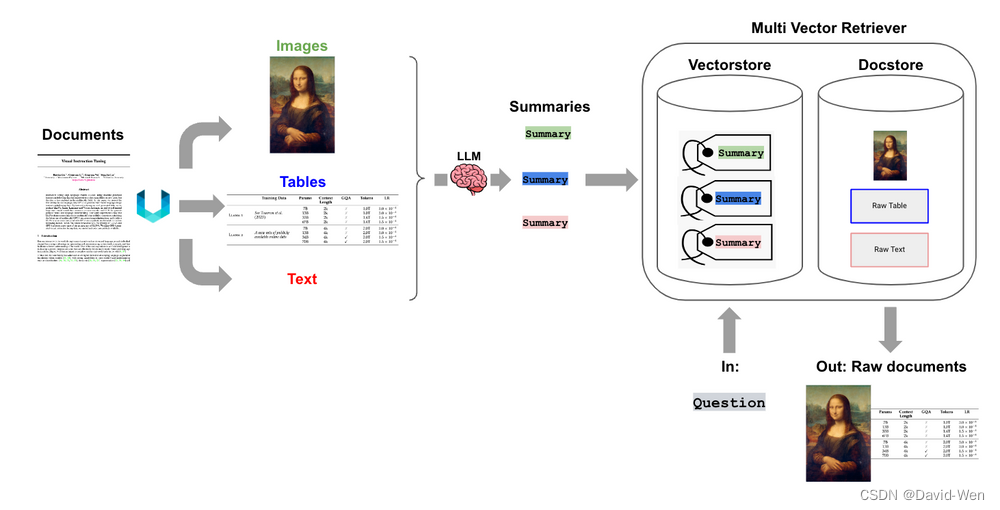
考虑一个冗长的文档。我们可以为该文档创建一个摘要,该摘要经过优化以进行基于向量的相似性搜索。但当需要生成答案时,我们仍然可以将完整的文档传递给LLM,确保在答案合成过程中不会丢失任何上下文。
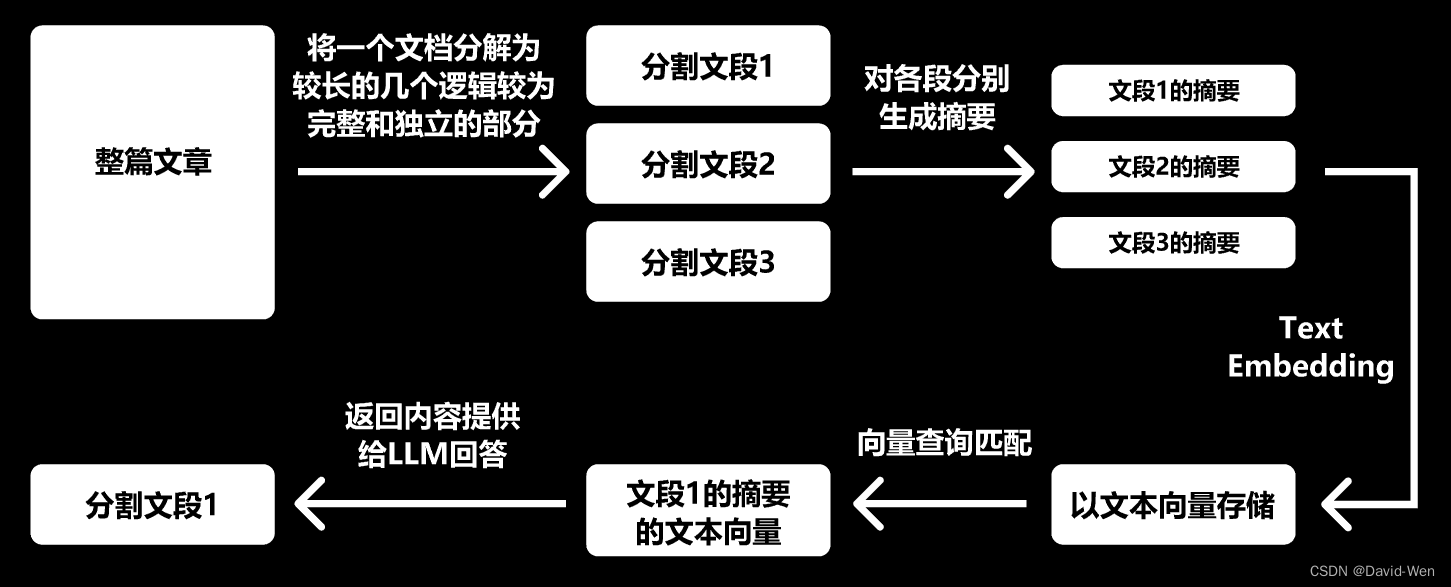
简单来说就是将一个文档分解为较长的几个逻辑较为完整和独立的部分,例如包括不同的文本、表格甚至是图片都可以,然后分解后的文档使用摘要的方式进行总结,这个摘要需要可以明确覆盖相关内容。然后摘要进行向量化,检索的时候直接检索摘要,一旦匹配,即可将摘要背后的完整文档作为上下文输入给大模型。
将一个文档分解为较长的多个逻辑较为完整和独立的分段
拆分出的各分段均会形成一个对应原分段的摘要,摘要中包含了原分段的相关信息点
仅对这些分段的摘要进行向量化,并将向量化的摘要和原分段形成关联绑定
进行向量检索时相似度匹配对象为向量化的摘要
匹配到摘要后召回的内容为与摘要绑定的原分段
多向量检索器的方案优点总结如下:
效率和速度:通过使用摘要进行向量化检索,检索过程更加迅速。摘要的数据规模相对较小,使得相似性搜索更加高效。
准确性提高:摘要提供了文档的核心信息,这有助于提高与查询相关的文档的检索准确性。
丰富的上下文:在答案合成阶段使用完整的文档可以确保LLM有足够的上下文来生成准确和全面的答案。
灵活性:多向量检索器的设计可以轻松适应不同类型的数据,例如文本、表格或图像,为多模态数据提供支持。
数据解耦:将文档(用于答案合成)与检索引用(用于检索)分开,为系统提供了更大的灵活性和可扩展性。
应对半结构化和多模态数据:这种方法不仅可以处理纯文本,还可以处理含有表格、图像等多种数据类型的文档,使其在处理更复杂的数据集时仍然有效。
保留关键信息:即使在处理大型或复杂文档时,摘要也能确保关键信息得到保留,从而提高检索的相关性。
降低资源需求:相对于在完整文档上进行检索,使用摘要可以减少计算和存储资源的需求。
总之,这种方法结合了摘要的高效检索能力和完整文档的上下文丰富性,为用户提供了既快速又准确的答案。
不过,仅基于摘要进行检索存在这样的风险:如果摘要没有充分捕获到文档的全部重要信息,那么在搜索过程中可能会错过关键的答案。
数据存储模式
存储功能
通过预索引缩小文件查询范围,再根据更小范围下的文件进行查询(类比windows的文件管理器的 根目录、子目录和文件)
(或者存在文件夹的多维标签[时间、地点、门类等],调取符合相应多维标签的文件形成临时文件库后在进行查询)
2. 用户可自主定义文件层级类别,也可由AI根据文档名称进行自动归类(更深一步则为预览文档后自动化给文档命名标题并归类)
标签分类
标签分为分组标签和类型标签,分组标签用来确定属于哪一分组下,类型标签用来确定包含哪些类型
例:
一个知识库中包含3个分组,其中一个分组的组名称为“科技政策”,则该分组下文档的包含的分区标签为【科技政策】
该分组下文档可能还有额外添加类型标签,比如【时间年份】、【地区名称】、【政策】等等
分组标签用于缩小搜索范围
预设信息引入
对话历史引入
该部分是给大模型预置的历史记录,让大模型参照历史记录中自己的输出模式来进行内容输出,确保大模型输出的内容均符合预设的要求
对话历史示例
- //历史部分输入格式为一问一答:用户(User)的输入内容 + AI的输出内容,用户的输入内容为 Prompt + 用户提供的内容
-
- User输入:
- 你是一名信息分析专家,请根据以下材料提取并列出材料中所涉及的全部公司名称
- 以JSON格式输出,不要包含无关信息
- 已知你对要求的首次理解以及你对材料的分析及输出肯定是错误并且有缺漏的,请再检查一遍确保理解要求并完全分析材料后才开展任务
- 输出格式为:
- {
- “data”:[“公司名1”,“公司名2”,“公司名3”,··· ,“公司名n”]
- }
- 材料如下:
-
- 今日,中国电信股份有限公司与中国联通股份有限公司达成战略合作协议,中国电信和中国联通在过往的业务上一直与爱立信处于相互竞争又携手并进的情况,芯立创总经理王为表示,两大运营商的共同合作是他所愿意看到的,爱博智能的研究顾问周晓也对此次合作抱有很高期望。
-
- AI输出:
- {
-
- "data": [
-
- "中国电信股份有限公司",
-
- "中国联通股份有限公司",
-
- "爱立信",
-
- "芯立创",
-
- "爱博智能"
-
- ]
- }
Prompt引入
该部分为投放给大模型的任务提示词,带入用户输入的文字内容并结合前置历史执行要求的生成任务。
Prompt示例
- 你是一名信息分析专家,请根据以下材料提取并列出材料中所涉及的全部公司名称
- 以JSON格式输出,不要包含无关信息
- 已知你对要求的首次理解以及你对材料的分析及输出肯定是错误并且有缺漏的,请再检查一遍确保理解要求并完全分析材料后才开展任务
- 输出格式为:
- {
- “data”:[“公司名1”,“公司名2”,“公司名3”,··· ,“公司名n”]
- }
- 材料如下:
-
- //该部分与用户输入的内容拼接
针对提问优化
当前存在的一些问题
内容的不相关性:传统的检索方法可能会返回含有与问题不相关的内容的文档块。这可能会降低检索的质量,因为返回的内容可能不完全符合用户的期望。
用户问题的表述问题:用户提出的问题可能表述不清或用词不准确,这可能导致检索系统无法准确地理解其意图并返回相关的答案。
复杂的查询需求:有时,用户的问题可能需要转换为更复杂的结构化查询,例如用于带有元数据过滤的向量存储或SQL数据库的查询。
查询转换
原文参考:
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结![]() https://www.datalearner.com/blog/1051698375259477
https://www.datalearner.com/blog/1051698375259477
向量检索增强生成提升方案之查询转换:LangChain的Query Transformations
为了解决上述问题,查询转换(Query Transformations)的方案利用了大型语言模型(LLM)的强大能力,通过某种提示或方法将原始的用户问题转换或重写为更合适的、能够更准确地返回所需结果的查询。LLM的能力确保了转换后的查询更有可能从文档或数据中获取相关和准确的答案。
下图是这种方案的展示:
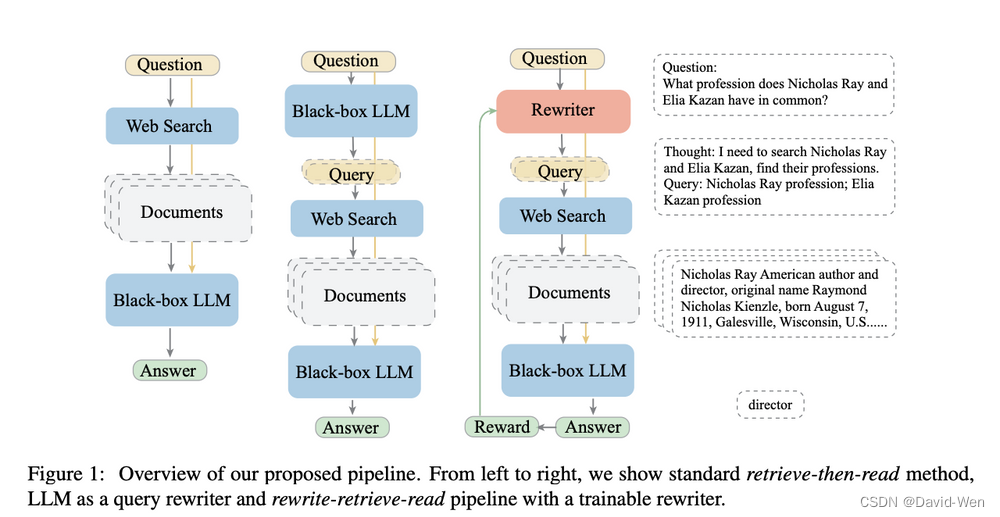
可以看到,查询转换的出发点是为了克服传统检索方法的局限性,利用LLM的能力优化和改进用户问题,从而提高检索的效果和满足用户的需求。
重写-检索-阅读
重写-检索-阅读(Rewrite-Retrieve-Read):
-
目的:直接使用原始的用户查询可能不总是最佳的,因此先使用LLM重写查询,然后进行检索和阅读。
-
执行方式:首先提示LLM重写查询,然后进行检索增强阅读。
-
使用的提示:该方法使用了一个相对简单的提示。如下图所示:
- TEMPLATE
-
- Provide a better search query for web search engine to answer the given question,end the queries with '**'. Question {x} Answer:
退后提示
退后提示(Step back prompting):
-
目的:生成一个“退后”的问题,在使用检索时,将同时使用“退后”问题和原始问题进行检索,然后使用这两个结果来支持语言模型的响应。后退问题是从原始问题派生出来的、抽象层次更高的问题。例如,原始问题是“Estella Leopold在特定时期去了哪所学校”,这个可能很难回答。但如果不是直接询问”Estella Leopold在特定时期去了哪所学校”,我们文一个后退问题会询问她的”教育历史”。这个更高层次的问题涵盖了原始问题的所有信息。很容易得到答案。
-
执行方式:使用LLM生成一个退后的问题。
-
使用的提示如下:
- You are an expert of world knowledge. I am going to ask you a question. Your response should be comprehensive and not contradicted with the following context if they are relevant. Otherwise, ignore them if they are not relevant.
- {normal_context}
- {step_back_context}
- Original Question: {question}
- Answer:
跟进问题
跟进问题(Follow Up Questions):
-
目的:处理跟进问题,尤其是当它们是基于或引用先前的对话时。
-
方法:
-
只嵌入跟进问题:这意味着如果跟进问题是基于或引用先前的对话,它将失去该上下文。
-
嵌入整个对话(或最后k条消息):如果跟进问题与先前的对话完全无关,那么可能会返回完全无关的结果。
-
使用LLM进行查询转换:将整个对话(包括跟进问题)传递给LLM,并要求其生成搜索词。
-
-
使用的提示:需要大量的提示工程。下面是一个例子:
- Given the following conversation and a follow up question, rephrase the follow up \
- question to be a standalone question.
-
- Chat History:
- {chat_history}
- Follow Up Input: {question}
- Standalone Question:
其他方式
多查询检索(Multi Query Retrieval):
目的:使用LLM生成多个搜索查询,尤其是当一个问题可能依赖多个子问题时。
示例:考虑以下问题:“谁最近赢得了冠军,红袜队还是爱国者队?”这实际上需要两个子问题的答案。
RAG-Fusion:
目的:建立在多查询检索的思想之上。不是传递所有文档,而是使用互惠排名融合来重新排序文档。
执行方式:不是将所有的文档传入,而是使用互惠排名融合来重新排序文档。
查询转换的核心思想是,用户的原始查询可能不总是最适合检索的,所以我们需要某种方式来改进或扩展它。使用LLM进行查询转换提供了一个非常有前景的方法来实现这一目标。
中间过程
LangChain-功能发掘
LangChain介绍及使用场景
http://t.csdnimg.cn/07fOH![]() http://t.csdnimg.cn/07fOH
http://t.csdnimg.cn/07fOH
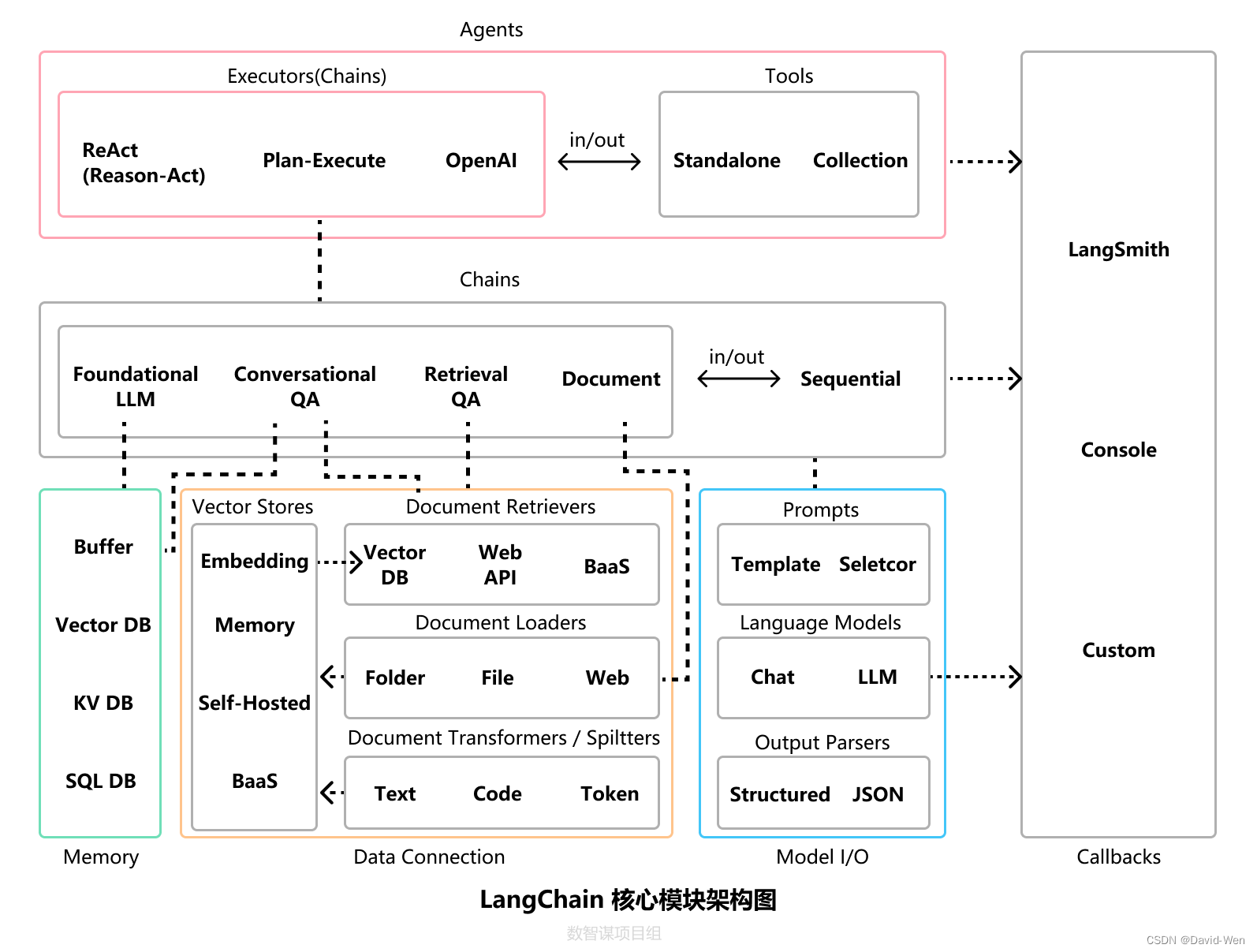
LangChain主要组件
| 主要组件 | 组件介绍 |
|---|---|
| Model I/O | 管理大语言模型(Models),及其输入(Prompts)和格式化输出(Output Parsers) |
| Data connection | 管理主要用于建设私域知识(库)的向量数据存储(Vector Stores)、内容数据获取(Document Loaders)和转化(Transformers),以及向量数据查询(Retrievers) |
| Memory | 用于存储和获取 对话历史记录 的功能模块 |
| Chains | 用于串联 Memory ↔️ Model I/O ↔️ Data Connection,以实现 串行化 的连续对话、推测流程 |
| Agents | 基于 Chains 进一步串联工具(Tools),从而将大语言模型的能力和本地、云服务能力结合 |
| Callbacks | 提供了一个回调系统,可连接到 LLM 申请的各个阶段,便于进行日志记录、追踪等数据导流 |
LangChain存储&索引流程
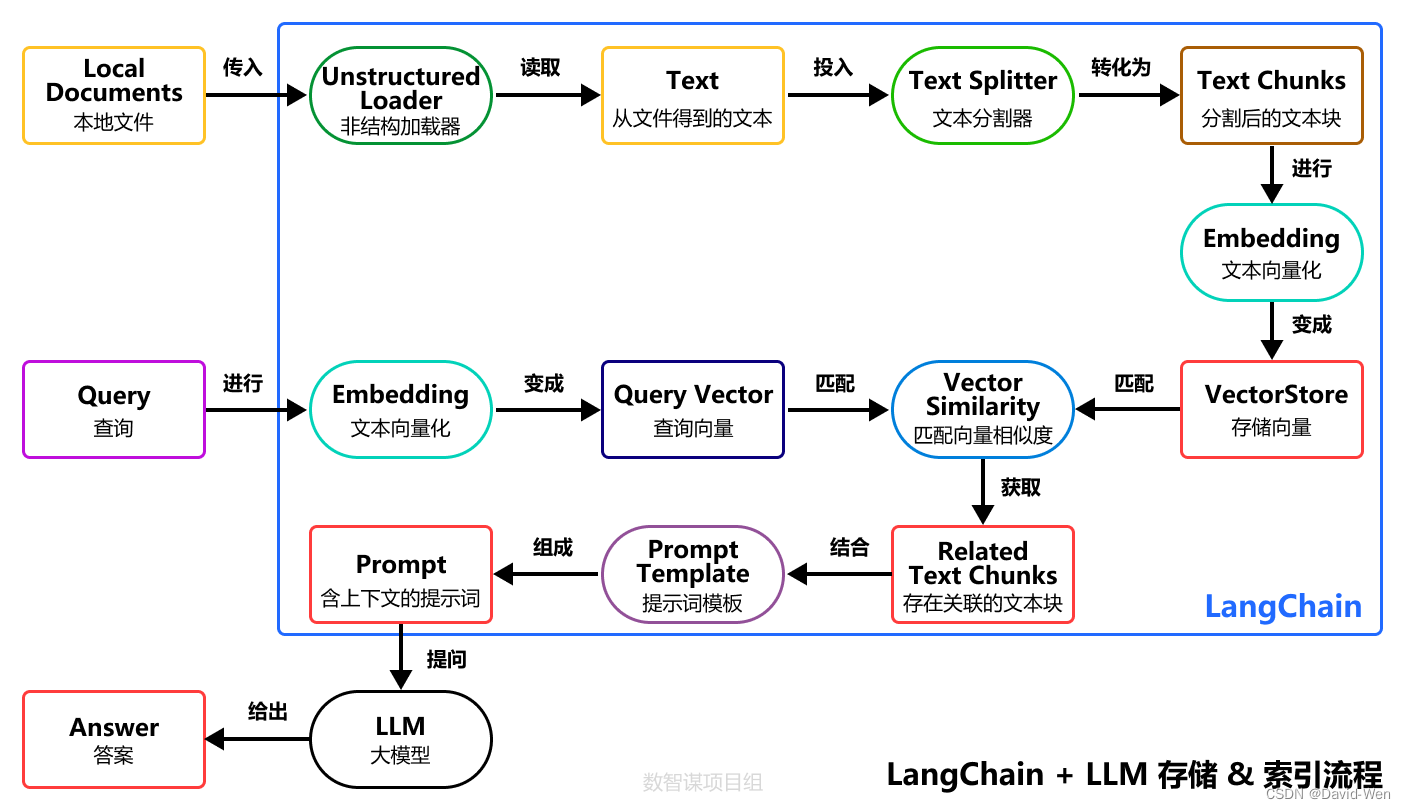
数据入库与特征归一化
【知识库问答】LangChain实战提升指南![]() https://zhuanlan.zhihu.com/p/645807338
https://zhuanlan.zhihu.com/p/645807338
1. 数据入库优化
开源的langchain按照固定的chunk_size=250进行文本切分,当然,代码里可能根据句号,问号,叹号等作为切分点,然后选取不大于250个字的片段作为一个chunk,并且建议chunk_size不能过大。
将数据按照最小内容单元来切分。如文章等,会先解析成标题,段落结构化的形式,对于段落,如果段落长度如果超过512,则切分为不超过512-len(标题)的片段,整文切分为“标题 正文1”,“标题 正文2”,此处标题是复用的。取512为切分的chunk size,是因为所用抽取文本特征的模型bert的输入正是512,实际应根据采用的文本特征抽取模型进行切分范围调整。
将上面切分好的数据每条一行,并在框架中新增“按行“抽取特征入库的方式。
2.检索库是否需要使用邻域context?
开源框架将问题在数据库内检索后,默认会拼接目标条目的上下文。在实验中,作者发现拼接上下文并没有正向提升,相反可能由于引入过多的context导致LLM模型找不到正确答案。
作者在取消了这个操作,只保留topk个条目后,指标上带来轻微提升。更换了新模型后,重新验证有显著提升。
3.特征是否需要L2-Norm?
这个问题是毫无疑问的。特征如果不做归一化,不同长度的输入,text2vec得到的特征的模长会有较大的差异。我们希望相关度与文本的内容关系更大,而降低文本长度带来的影响。
因此对特征进行了归一化,并且改用余弦相似度,把相似度控制在0-1之间,也更加方便设置阈值。
4.进一步调整按行入库的预处理
为什么这一点要特别强调?前面已经提到我们将数据自己准备好,并按行切分,入库,但是忽略了一点:开源框架在处理用户提供的每一行文本的时候,用到了一个函数ChineseTextSplitter,这个函数会将句子中的句号,问号等代表断句的符号替换成'\n',但实际上这个操作严重影响了传入句子的语义,过多的'\n',导致topk之间没有明显的分界线。
作者取消了这个预处理函数。将预处理替换为 '\n'.join(topk.reverse())。这带来非常大的提升。
向量模型
智源BGE模型
信息来源截止2023年8月份
BGE模型在中英文语义检索精度与整体语义表征能力均超越了社区所有同类模型,如OpenAI 的text embedding002等。
此外,BGE 保持了同等参数量级模型中的最小向量维度,使用成本更低。
据介绍,中文语义向量综合表征能力评测 C-MTEB 的实验结果显示,BGE中文模型(BGE-zh)在对接大语言模型最常用到的检索能力上领先优势尤为显著,检索精度约为 OpenAI Text Embedding002的1.4倍。
与中文能力相类似,BGE 英文模型(BGE-en)的语义表征能力同样出色。根据英文评测基准 MTEB 的评测结果(Table2),尽管社区中已有不少优秀的基线模型,BGE 依然在总体指标(Average)与检索能力(Retrieval)两个核心维度超越了此前开源的所有同类模型。
同时,BGE 的各项能力都显著超越社区中最为流行的选项:OpenAI Text Embedding002。
BGE 模型链接:
https://huggingface.co/BAAI/![]() https://huggingface.co/BAAI/
https://huggingface.co/BAAI/
BGE 代码仓库:
C-MTEB 评测基准链接:
输出过程
文段召回与重排序
优化方案
原文参考:
回答的准确性强烈依赖于检索步骤是否可以返回正确的内容。因此,这里需要解决2个问题:
1.如何找到与用户相关的数据?
2.如何让大模型基于返回的数据准确回答?
对于第一个问题,目前最常用的方式是使用向量大模型,将文本数据以向量的形式存入数据库,并通过向量的相似性检索的方式来匹配与用户提问相关的内容。这部分依赖向量大模型的向量化是否准确,也依赖外部数据是否有合理的分割(不能所有的知识转化成一个向量,而是需要分割数据后转化再存入向量数据库)。
第二个问题则是由于第一个问题不能完全解决导致的。向量检索返回的内容显然不止一个,这意味着需要大模型基于检索的结果进行回答。通常情况下,我们会根据文档与问题之间的向量相似度得分,将检索到的文档按降序插入到上下文中。
这里问题就来了,第一个问题不是本次关注的重点,我们关注第二个问题。
大模型在多文档检索问题的缺陷
当我们将第一步中返回的最相似的文档进行排序后,与用户的问题一起送给大模型,实际上是想让大模型在长上下文中准确识别定位到合适的内容进行回答。
这与多轮对话中的核心问题有点类似,就是需要在超长的内容中做主题检索(著名的开源大模型Vicuna的开发组织LM-SYS曾经做过大模型超长上下文测评,其核心观点就是大模型超长对话中的核心能力就是主题检索,参考:支持超长上下文输入的大语言模型评测和总结——ChatGLM2-6B表现惨烈,最强的依然是商业模型GPT-3.5与Claude-1.3)。
问题的关键在于,当我们将最检索得到的最相似的文档放在上下文的顶部,最不相似的文档放在底部时,大多数基于大型语言模型(Large Language Models,LLMs)表现都很差。这个研究和发现来自斯坦福大学此前的一项研究,参考:大模型如何使用长上下文信息?斯坦福大学最新论文证明,你需要将重要的信息放在输入的开始或者结尾处!
这个论文里面最核心的观点就是输入数据的重要信息没有出现在开始或者结尾位置,大模型可能会出现找不到答案的情况!如下图所示:
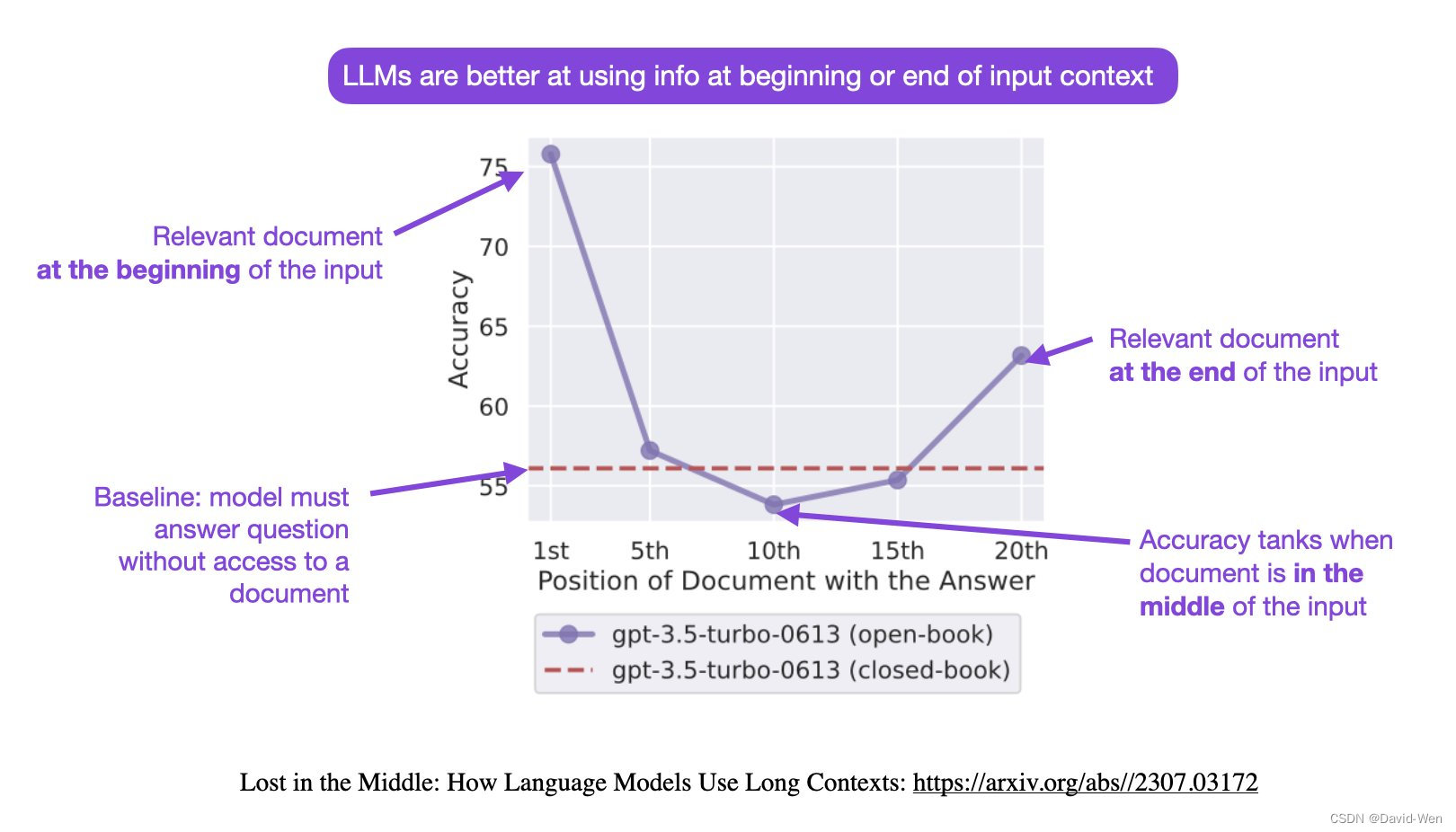
上图表明在大语言模型的输入上下文中改变相关信息的位置(即回答输入问题的段落的位置)会导致一个U形性能曲线——模型更擅长使用出现在输入上下文的开头或结尾的相关信息,而当模型需要访问和使用位于输入上下文中部的信息时,性能显著下降!
因此,如果我们将检索到的最相似的文档放在上下文的顶部,最不相似的文档放在底部时,大模型的系统往往会忽略上下文中间的文档。这意味着最不相似的文档被放在了一个LLMs容易忽略的位置,从而影响了性能!
这是十分容易被忽视的问题!因为检索的不准确性,所以返回多个文档几乎是所有方案都会做的行为。而这自然而然的行为却可能造成很大的影响!
LangChain的解决方案-检索后重新排序文档
为了解决这个问题,LangChain提出了一种创新的方法,即在检索后重新排序文档。这种方法的关键思想是将最相似的文档放在顶部,然后将接下来的几个文档放在底部,将最不相似的文档放在中间。这样,最不相似的文档将位于LLMs通常容易迷失的位置。最重要的是,LangChain最新的LongContextReorder自动执行这个操作,使其非常便捷。
如下图所示:
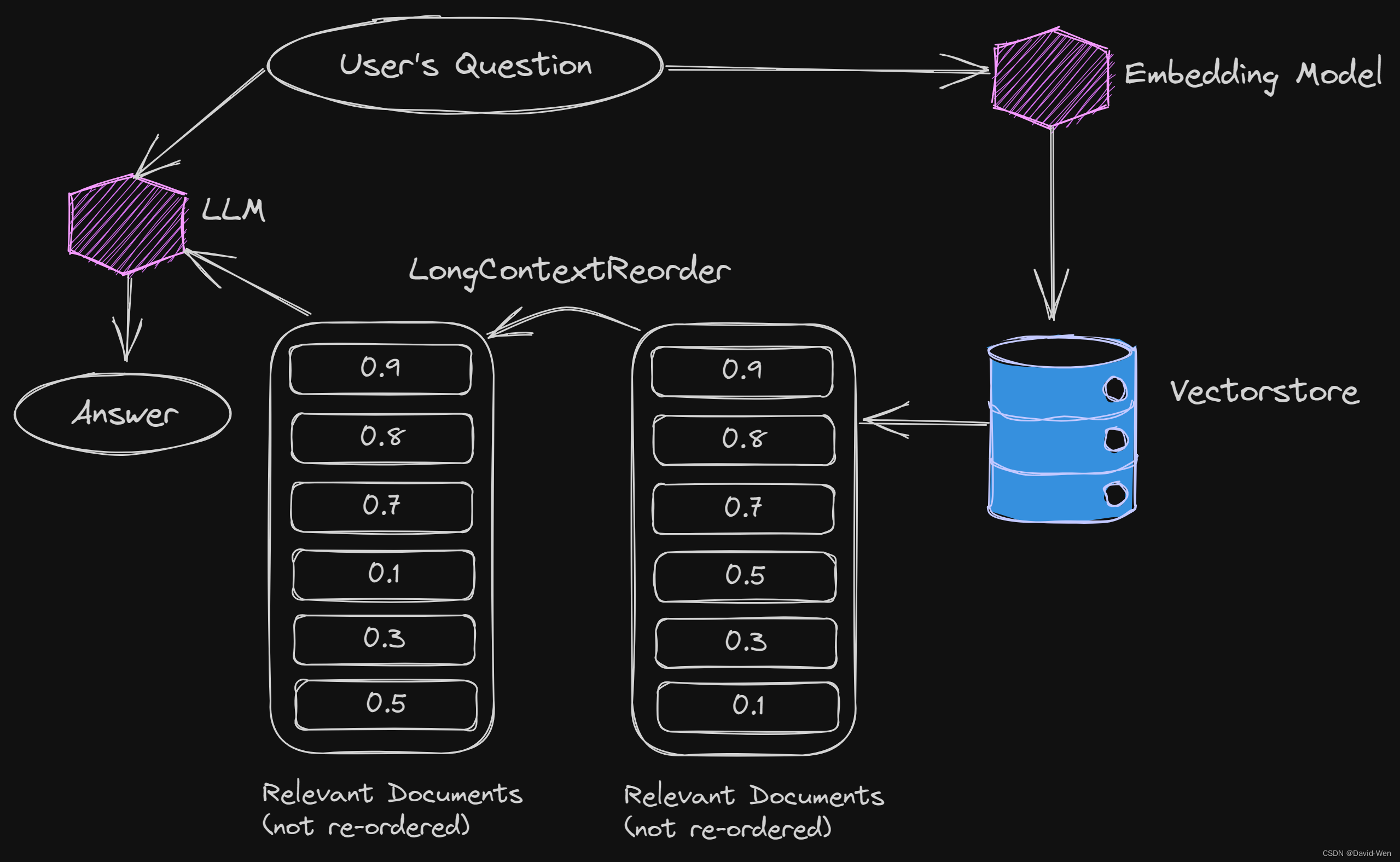
而这种方式只需要在原有的代码里面加入一行文档重排序即可,这意味着在实践中可以通过很多简单的方式直接测试这种排序的效果。
官方也给出了一个重排序的实例,例如原始的文档集合如下:
- texts = [
- "Basquetball is a great sport.",
- "Fly me to the moon is one of my favourite songs.",
- "The Celtics are my favourite team.",
- "This is a document about the Boston Celtics",
- "I simply love going to the movies",
- "The Boston Celtics won the game by 20 points",
- "This is just a random text.",
- "Elden Ring is one of the best games in the last 15 years.",
- "L. Kornet is one of the best Celtics players.",
- "Larry Bird was an iconic NBA player.",
- ]
用户提问如下:
query = "What can you tell me about the Celtics?"那么按照相似检索结果排序如下:
- [Document(page_content='This is a document about the Boston Celtics', metadata={}),
- Document(page_content='The Celtics are my favourite team.', metadata={}),
- Document(page_content='L. Kornet is one of the best Celtics players.', metadata={}),
- Document(page_content='The Boston Celtics won the game by 20 points', metadata={}),
- Document(page_content='Larry Bird was an iconic NBA player.', metadata={}),
- Document(page_content='Elden Ring is one of the best games in the last 15 years.', metadata={}),
- Document(page_content='Basquetball is a great sport.', metadata={}),
- Document(page_content='I simply love going to the movies', metadata={}),
- Document(page_content='Fly me to the moon is one of my favourite songs.', metadata={}),
- Document(page_content='This is just a random text.', metadata={})]
再经过重排序之后的结果:
- [Document(page_content='The Celtics are my favourite team.', metadata={}),
- Document(page_content='The Boston Celtics won the game by 20 points', metadata={}),
- Document(page_content='Elden Ring is one of the best games in the last 15 years.', metadata={}),
- Document(page_content='I simply love going to the movies', metadata={}),
- Document(page_content='This is just a random text.', metadata={}),
- Document(page_content='Fly me to the moon is one of my favourite songs.', metadata={}),
- Document(page_content='Basquetball is a great sport.', metadata={}),
- Document(page_content='Larry Bird was an iconic NBA player.', metadata={}),
- Document(page_content='L. Kornet is one of the best Celtics players.', metadata={}),
- Document(page_content='This is a document about the Boston Celtics', metadata={})]
可以看到,此前的This is just a random text.这种无关的文本已经被调整到中间位置了。新的问答将基于这种问答排序结果问答。
进阶方案
原文参考:
【大模型外挂知识库优化】召回文档排序策略再思考与实验![]() https://zhuanlan.zhihu.com/p/656783040
https://zhuanlan.zhihu.com/p/656783040
笔者在真实的应用场景中验证了召回文档排序以及query摆放位置对LLM回答质量的影响。
实验设置
数据:某应用场景下的QA对,以及和问题全集有关的切好段、并向量化的知识库。文档片段平均长度为200。测试QA对数量为500。
召回模型:在该应用场景数据下微调过的智源BGE模型(微调后性能提升10%),top10召回率71%,top20召回率77%,top30召回率81%。本文想要论证的结论因为和召回文档的排序有关,因此必须要求召回模型准确一些。对于召回器来说,把召回的文档都排对顺序基本做不到,但至少能把真实排名差距较大的文档片段排对。
LLM:此处实验使用chatglm2-6B当作chatbot生成答案,没微调过。
评估方法:原论文的wiki问答场景数据是那种有精确答案的,比如答案是人名、地名,评估起来比较容易。但是真实场景下,很少有这种情况。笔者想了如下评估策略:利用embeding模型,计算LLM生成的答案和标准答案之间的cos相似度当作评分。如果您自己的业务场景是那种对关键词比较敏感的场景,用rouge指标也可以。用于评估的embedding模型更需要其准确,此处仍然使用目前中文榜单排名第一的bge模型。
实验结果及分析 因为用于评分的embedding模型的原因,不同策略在绝对分值上确实差距比较小(两句非常不相关句子的embedding计算相似度可能也高达0.7)。笔者固定了各种随机种子,LLM使用贪婪解码回答问题,尽量将随机性降到最低。先简单介绍一下实验里排布方式的表示方法。拿实验3(1357642q)举例子,1表示召回分值最高的文档片段,7表示召回分值最低的文档片段(假设召回7个文档片段),即把按按照分值从大到小排序后,依次交替放到头和尾,然后将问题q放到整个输入的尾部,这是我在上篇文章提到的自认为是最优的排序方式。实验5和实验6是在头或尾分别放两个文档片段后再切换方向。原论文提到将q同时放到头尾,即此处的实验8。表格中每列最上边一行的数字表示分别召回5/10/20/30个相关文档片段时的实验结果。
| query及doc 文段的排布方式 | 5个文段 | 10个文段 | 20个文段 | 30个文段 |
|---|---|---|---|---|
| 实验1: 1234567q | 0.89321 | 0.89158 | 0.89228 | 0.89170 |
| 实验2: 7654321q | 0.89101 | 0.88800 | 0.88854 | 0.88829 |
| 实验3: 1357642q | 0.89212 | 0.89288 | 0.89476 | 0.89618 |
| 实验4: 2467531q | 0.89170 | 0.88999 | 0.89048 | 0.89103 |
| 实验5: 125698743q | 0.89217 | 0.89189 | 0.89245 | 0.89199 |
| 实验6: 347896521q | 0.89004 | 0.89003 | 0.89124 | 0.89081 |
| 实验7: q1357642 | 0.88560 | 0.88521 | 0.88452 | 0.88022 |
| 实验8: q1357642q | 0.89168 | 0.89171 | 0.89489 | 0.89613 |
实验分析:
-
我的实验场景文档片段平均长度为200,30个文档片段长度就是6000,从实验结果来看,chaglm2-6b模型的回答质量并没有明显下降,6000的输入长度已经能cover掉大部分外挂知识库场景了。
-
上篇文章猜测的最优召回文档排列方式(实验3)确实能达到最好的回答效果。
-
将query放到头部(实验7)模型回答效果会变差。
-
将query放到头部和尾部在外挂知识库场景下并不能有效提升回答的效果。
参考文章
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结 | 数据学习者官方网站(Datalearner)
LangChain提升大模型基于外部知识检索的准确率的新思路:更改传统文档排序方法,用 LongContextReorder提升大模型回答准确性
LangChain提升大模型基于外部知识检索的准确率的新思路:更改传统文档排序方法,用 LongContextReorder提升大模型回答准确性! | 数据学习者官方网站(Datalearner)
利用LangChain建gpt专属知识库,如何避免模型出现“幻觉”,绕过知识库知识乱答的情况?
利用LangChain建gpt专属知识库,如何避免模型出现“幻觉”,绕过知识库知识乱答的情况? - 知乎
续:【大模型外挂知识库优化】召回文档排序策略再思考与实验
【大模型外挂知识库优化】召回文档排序策略再思考与实验 - 知乎
【知识库问答】LangChain实战提升指南
【大模型外挂知识库优化】召回文档排序策略再思考与实验![]() https://zhuanlan.zhihu.com/p/656783040
https://zhuanlan.zhihu.com/p/656783040

