
- 1openai接口调用-如何接入openai获取 api key_获取 openai key
- 2嵌入式软件开发工程师就业发展前景怎么样?
- 3禁用el-tabs组件自带的键盘切换功能_element-plus 禁止键盘上下左右
- 4机器视觉三维点云分析系统3DPCAgent_3d点云数据测量系统架构
- 5ggplot 图像的保存_error in usemethod("grid.draw") : no applicable me
- 6120款超浪漫❤HTML5七夕情人节表白网页源码❤ HTML+CSS+JavaScript_浪漫网页
- 7Pytorch下查看各层名字及根据layers的name冻结层进行finetune训练;_model = net().cuda() for name, param in model.name
- 8《Python从入门到实践》外星人入侵学习笔记_python外星人入侵 求助 不按play键 一直处于活动状态
- 9Dump分析模式1: Multiple Exceptions(多线程异常)_multipe exceptions
- 10PyQtChart进行柱状图、饼图的基本设置_pyqt5 炫酷饼状图
Stable Diffusion——文生图界面参数讲解与提示词使用技巧
赞
踩
Clip终止层数

什么是Clip
CLIP(Contrastive Language-Image Pretraining)是由OpenAI于2021年开发的一种语言图像对比预训练模型。其独特之处在于,CLIP模型中的图像和文本嵌入共享相同的潜在特征空间,这使得模型能够直接在图像和文本之间进行对比学习。
CLIP模型通过训练使相关的图像和文本在特征空间中更紧密地结合在一起,同时将不相关的图像在特征空间中分开。这种对比学习的方式使得CLIP模型能够理解图像和文本之间的语义关系,并在各种视觉和语言任务上取得优异的表现,如图像分类、文本检索、图像生成等。CLIP的出现对于促进图像和文本之间的跨模态理解和交互具有重要意义。
Clip的作用
CLIP模型的作用是建立标签(关键词)和图像之间的关系,可以理解为SD数据库中的处理模块。当调整CLIP模型中的参数值时,会影响标签和图像之间的关系,具体地说,如果参数值较高,标签和图像之间的关系就会变得越来越低,反之亦然。这种关系是反比例的,因此一般不建议将参数值调得过高。
举例来说,当参数值在0到4之间时,图像的细节已经相当不错了;当参数值增加到6时,图像仍然是可以接受的。然而,当参数值增加到8时,图像可能会变得奇怪,整体标签和图像之间的关系会降低。,当增加到最大的12时,整体生成的图像与标签的关联性会降到最低。在这种情况下,模型可能会更多地依赖于其自身的理解,而忽略输入的标签,导致生成的图像与标签不相符。
可以看下面的例子,正向提示词:1girl,pink hair,upper_body,green_shirt,sky blue eyes
Clip = 1时:

Clip = 4时:

Clip = 8时:

Clip =12时:

因此,建议将CLIP模型的参数值保持在较低的范围内,通常选择1到4之间的数值即可。在大多数情况下,这个范围已经能够满足需求,不需要调整得太高。
提示词
什么是提示词
提示词通常指的是在生成模型中用于指导生成过程的输入信息,它可以是一段文本、一个单词、一个短语,或者是一些标签或关键词。在生成任务中,提示词通常用于定义所需生成内容的方向、主题或特征。提示词的选择和质量直接影响生成结果的准确性和合理性。
举例来说,在图像生成任务中,提示词可以是描述图像内容的关键词或短语,如“树木”、“夏天”、“海滩”等。在文本生成任务中,提示词可以是一段描述待生成文本的开头部分,或者是一个特定主题的关键词列表。在绘画任务中,提示词可以是描述绘画主题、色彩、风格等的关键词或短语。
提示词语的性质
在Stable Diffusion中提示词可以分为两类:正向提示词和反向提示词。正向提示词用于指定希望在生成图片或文本时出现的内容或特征,而反向提示词则用于指定不希望出现的内容或特征。
举例来说,如果您想要生成一张有女孩的图片,那么您可以将“girl”作为正向提示词;同时,如果您不想让图片中出现男孩,您可以将“boy”作为反向提示词。
在AI绘画中,常常会出现一些单人多头,多手指,多脚的现象,这时候,就可以在反向提示词里加“extra hand”“extra leg”以避免生成多头多手指、多脚多腿的情况,或者把手画成脚的,如下图:

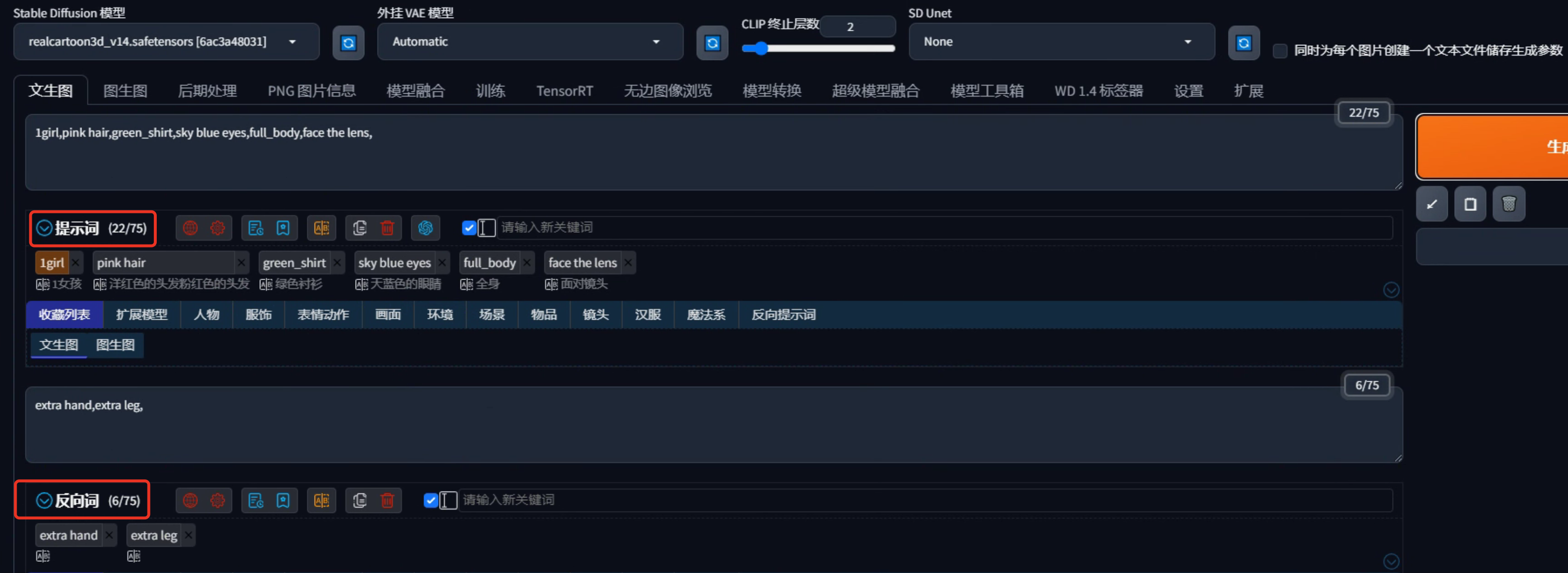
标签格式
标签(tag)的格式可以直接影响到生成结果的质量和准确性。关于标签格式的说明:
-
语言:目前大多数提示词只支持英文,因此英文是必备的。尽管有一些能够将中文转换为英文的插件。如我之前博客里面提到的 “prompt-all-in-one”
-
格式:标签可以以单词、短语或句子的形式输入。推荐使用短句,因为短句更具有上下文和语境,可以帮助模型更准确地理解需求。
-
分割符号:标签之间使用逗号进行分割。这样做有助于区分不同的标签,并告诉系统如何解析和理解标签。
-
关键词顺序:将重要的关键词放在前面,因为它们的权重会更高,系统会优先识别和处理这些关键词。这尤其适用于描述图像主体或重要元素的标签。
-
调整标签顺序:如果发现某些关键词没有得到充分识别,可以尝试将其提前放置,以提高其识别概率。
标签的描述顺序
内容性的tag通常用于描述图像内容特征,具体的描述内容会根据不同的场景和需求而定。例如,在描述人物写实的场景中,可以按照以下顺序进行描述:
- 人物和表情:人物的外貌特征、面部表情等。
- 服装特征:人物所穿着的服装样式、颜色等。
- 场景环境:人物所处的场景背景、环境特征。
- 镜头:图像的拍摄角度、视角等。
- 灯光:图像的光线照射情况。
- 画面细节:画面质量、自动提取的细节(auto details in instant details)。
- 渲染器引擎:Octane Render、Unity的CG渲染。
- 画面的风格:插画风格、油画风格、写实风格
- 其他元素细节:描述与人物或场景相关的其他细节,如道具、背景元素等。
关于tag的中英对照,有国内大神做了个详细的表,对AI绘画或者想要对照表的都可以加:566929147 企鹅群一起学习讨论。

标签权重
在生成图像时可以通过调整不同标签的权重来影响生成结果的内容和特征。每个tag的权重初始值都为1,但越靠前的tag权重相对高一些,以下是关于更改权重的几种常见用法:
-
括号法则:使用大括号、中括号和小括号来调整权重。在标签周围添加括号可以增加其权重。例如,使用一个括号会使权重增加1.1倍,两个括号会使权重增加1.1的平方倍,依此类推。不过,添加过多的括号可能会使权重变得难以控制和理解,因此建议谨慎使用。
() :增加1.1倍
{} :增加1.05倍
[] : 减少1.1倍(0.9)
例子:当减少tag的权重“halfling”没有减少时,生成的图像:
1girl,pink hair,(sky blue eyes),{face the lens},white shirt,jeans,halfling

当减少tag的权重"[[halfling]]"减少时,生成的图像时会减少半身一个tag的权重,如下图,它已差不多画出全身:
1girl,pink hair,(sky blue eyes),{face the lens},white shirt,jeans,[[halfling]],

-
数字法则:使用数字来表示权重。在标签后面加上一个数字(例如1.3)可以增加其权重,而使用小于1的数字可以减少其权重。这种方法相对简单明了,更容易掌握和调整。
(tag:1.2):增加1.2倍
(tag:0.6):减少0.6倍 -
AND方法:通过使用AND连接不同的标签来实现它们的混合。例如,将“girl”和“boy”用AND连接起来,生成的图像会混合展现男生和女生的特征。这种方法能够产生有趣的混合效果,但需要注意保持标签的适度和协调。
**tag1 AND tag2 ** : 不同元素与主体混合
例子:生成中性的人物,注意AND必须是大写的
girl AND boy,pink hair,(sky blue eyes),{face the lens},white shirt,jeans,halfling,

-
混合:使用中括号和竖线来指定标签的交替渲染顺序。通过在标签之间使用中括号和竖线“|”,可以实现不同标签在渲染过程中的交替出现,从而实现标签的混合效果。这种方法能够产生更加复杂和多样化的图像效果。
[tag1 | tag2 ] : 会隔一步渲染tag
例子:生成狐狸女孩
[girl | fox],pink hair,(sky blue eyes),{face the lens},white shirt,jeans,halfling,

5.BREAK隔开Tag
使用BREAK来隔绝提示词之间的相互污染,特别是颜色之间的污染。
1 girl,green hair,white skirt,
这里会出现衣服的颜色与头发的颜色互相污染的问题如下图:

这里可以使用BREAK隔开提示词:
1 girl,green hair BREAK white skirt,

- 下划线
下划可以将两个Tag连成一个tag来理解。
迭代步数

采样步数指的是在生成图像时模型所进行的迭代步数。这个值的范围通常是从1到150。调整这个值会影响生成图像的细节程度以及生成速度。
-
增加采样步数:增加采样步数会增加生成图像的细节,使其更加清晰和精细。然而,这也会导致生成过程变慢,因为模型需要更多的迭代来生成更精细的图像。如果采样步数设置得太高,生成图像可能需要较长的时间,特别是对于性能较低的设备。
-
减少采样步数:减少采样步数会降低生成图像的细节,可能导致图像模糊或含有噪点。然而,生成速度会更快,因为模型需要较少的迭代来生成图像。
一般建议在制作图像时将采样步数控制在20到40之间,这样可以在保持一定细节的同时,保持生成速度较快。如果采样步数设置得太高,可能会导致生成时间过长,因此需要根据设备性能和需求来进行调整。
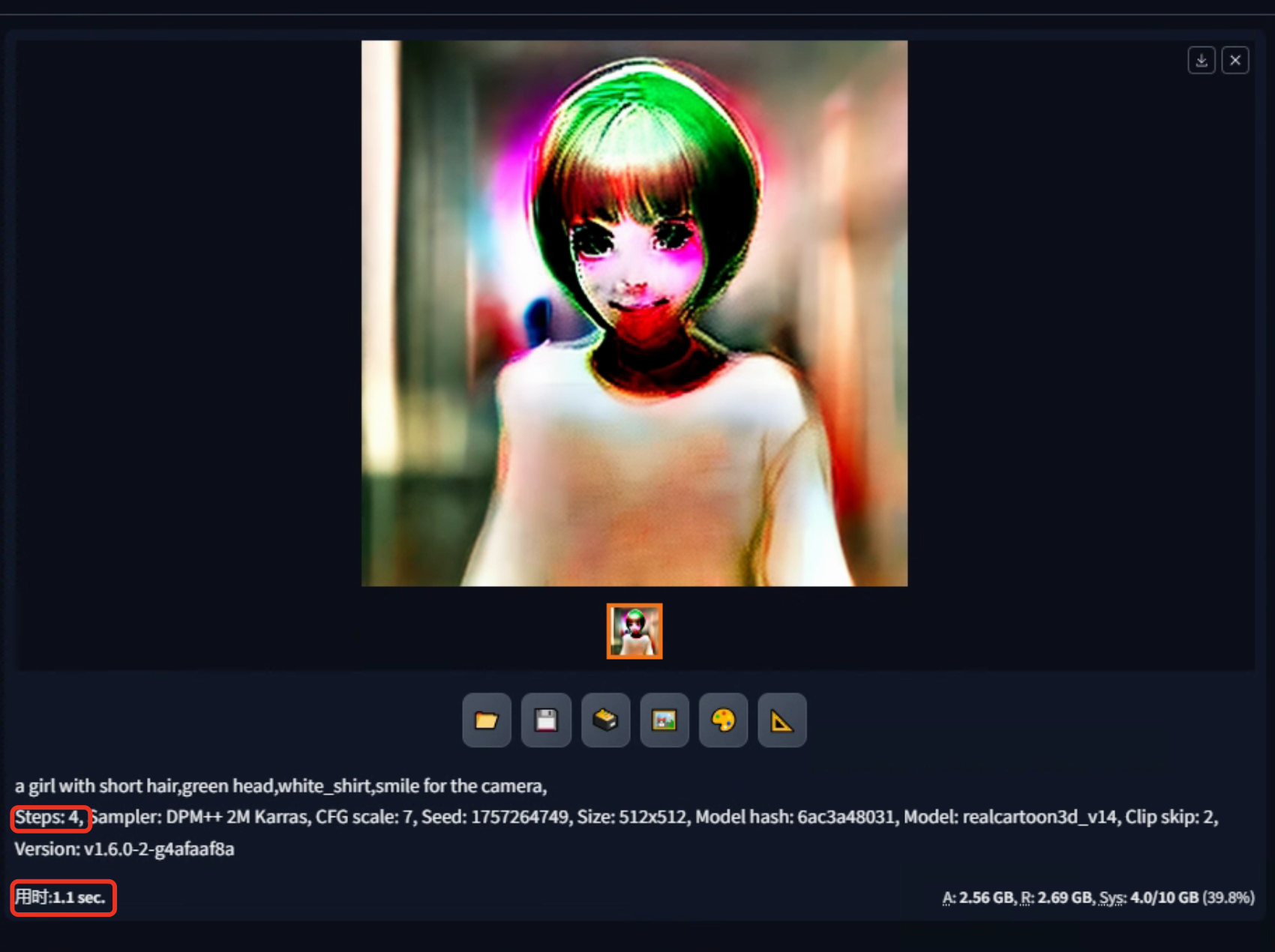
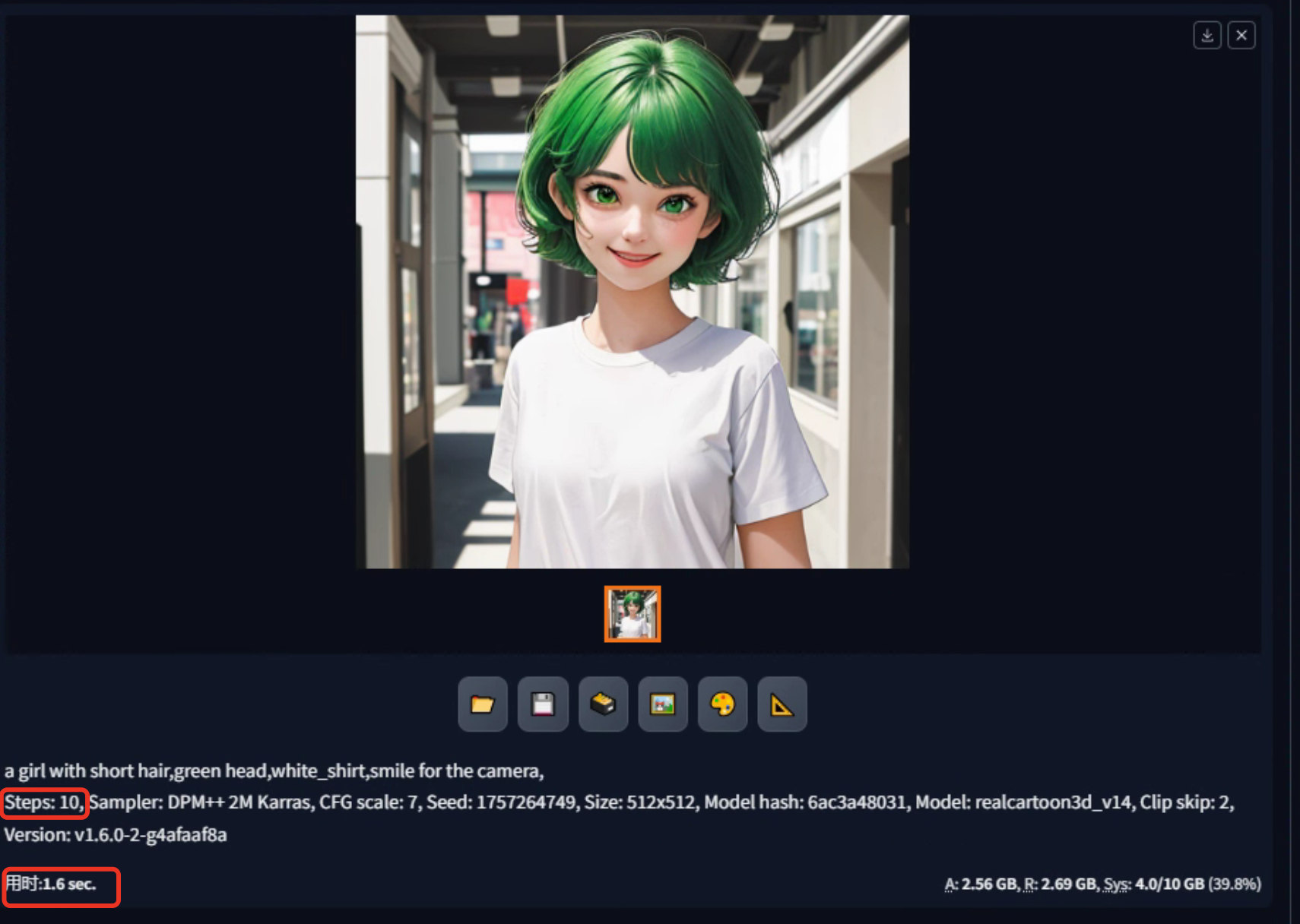
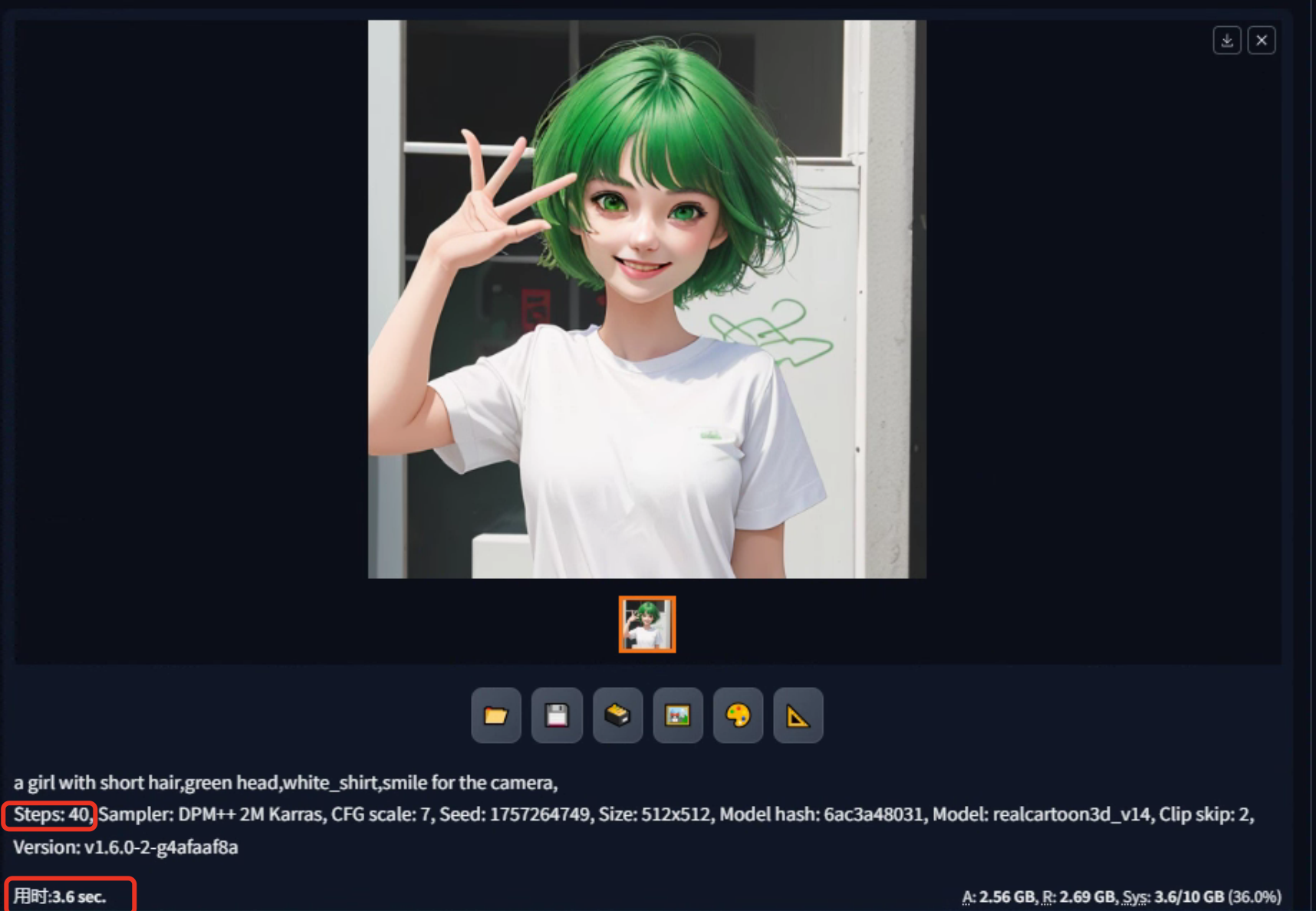
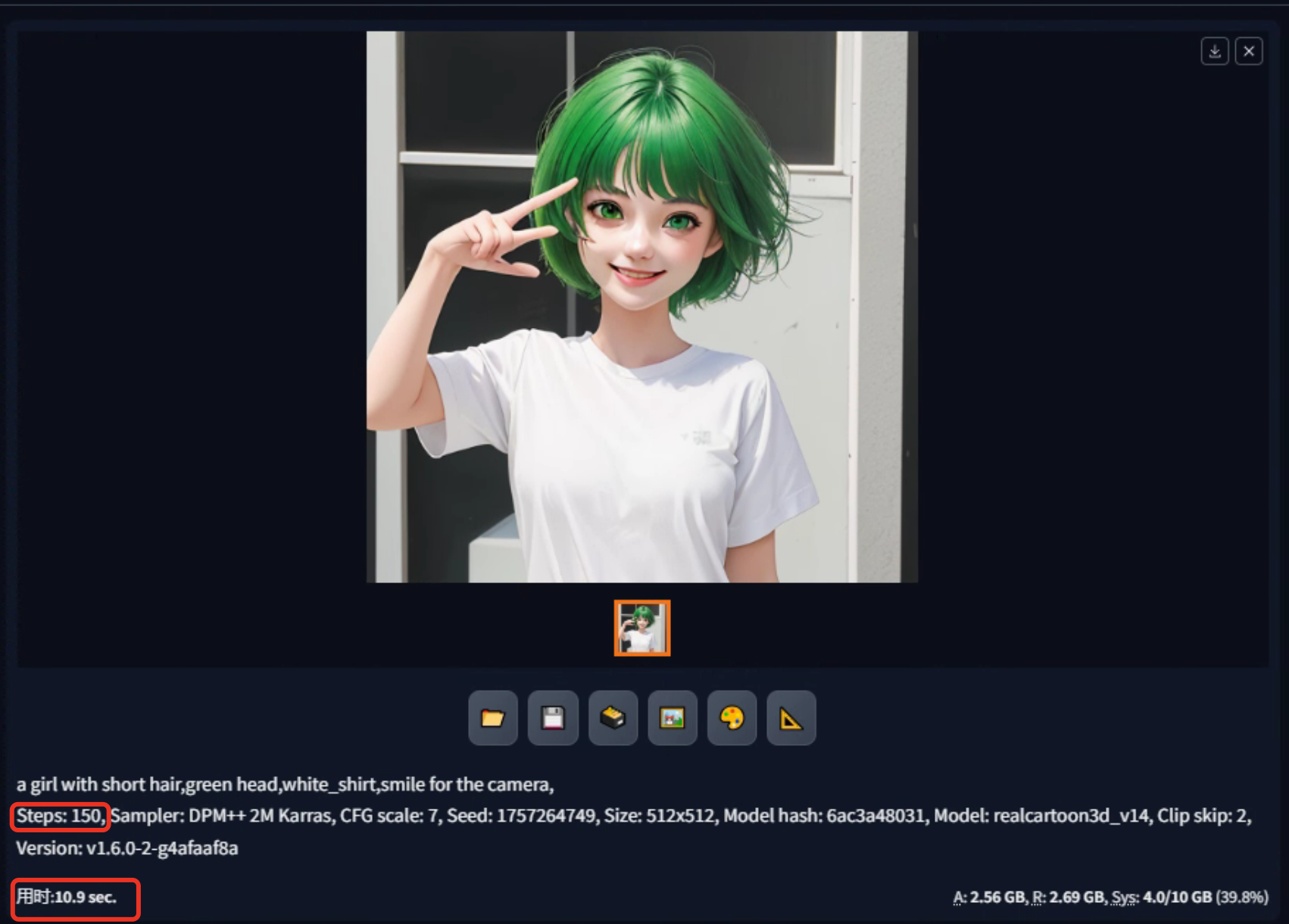
观察生成图像的不同采样步数所带来的效果变化,可得看出:
-
第二步到第八步:在这个阶段,图像经历了一个去噪的过程。这意味着模型在这些步骤中尝试去除图像中的噪点,使图像变得更清晰、更干净。
-
第十步:在第十步时,图像已经成型,意味着在此时点图像已经具备了基本的清晰度和可用性。虽然一些细节可能还不够完善,但整体效果已经可以接受。
-
第25步到第40步:在这个阶段,细节变化开始变得更加显著。采样步数在这个范围内通常足以生成具有足够细节的图像。
通常情况下,采样步数在20左右已经足够生成具有合理细节的图像。如果希望图像更加清晰和精细,可以将采样步数适度增加到40左右。然而,超过40步可能会带来较小的收益,但会增加生成时间,因此需要权衡时间和图像质量之间的关系。



