
- 1MQTT协议分析与c语言实现(上)_mqtt-c
- 2超详细解决方案:在与 SQL Server 建立连接时出现与网络相关的或特定于实例的错误。_在与sqlserver建立连接时出现与网络相关的
- 3【华为机试题】华为机试真题附解答(2020.9.16/c++)_事件推送华为机试题
- 4海康威视RSTP摄像头视频数据从内网读取在web用HLS播放_hls插件加载rstp流视频
- 5归一化原理-python实现_python 最大最小归一化
- 6I.MX6ULL_Linux_驱动篇(37) linux系统定时器_linux 硬件定时器应用
- 7socket错误代码
- 8leetcode中级_给定一个元素为非负整数的二维数组matrix,每行和每列都是从小到大有序的。
- 9Java项目:在线服装销售商城系统(java+SpringBoot+Maven+Vue+mysql)_class shoppingcontroller extends basecontroller
- 10Samba常用配置及GUEST访问_guest ok
《深度学习与逻辑回归模型的融合&&TensorFlow多元分类的高级应用》
赞
踩
手写数字识别
说到数字识别问题,这是一个分类问题,也就是我们要探讨的逻辑回归问题。逻辑回归是机器学习算法中非常经典的一种算法。
1、线性回归VS逻辑回归
线性回归和逻辑回归的关系就是:逻辑回归是广义的线性回归。它们就是一个东西,只是范围不同。我在文章《深度学习在单线性回归方程中的应用–TensorFlow实战详解》讲到的预测问题实则是线性回归,本质就是用一堆数据集点去模拟出一个函数,再用这个函数进行预测。逻辑回归是在这个基础上,将得到的函数放在一个 Sigmoid()函数里求出来得到一堆概率值,这些概率值就是在0和1之间的。这个时候我们在设置一个阈值,通过比较概率和这个阈值的关系,我们就能达到分类的效果了。
总结一下就是:
线性回归解决的是回归问题,逻辑回归相当于是线性回归的基础上,来解决分类问题。
线性回归:

逻辑回归:
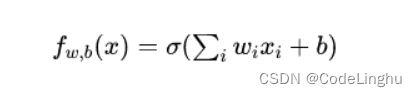
从上面两个公式:逻辑回归可以理解为在线性回归后加了一个Sigmoid 函数。将线性回归变成一个0~1输出的分类问题。
Sigmoid函数
这个函数长成这个样子:
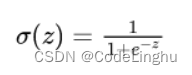
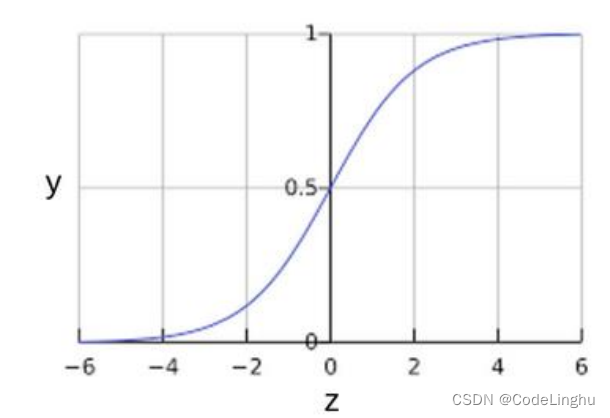
线性回归得到大于0的输出,逻辑回归就会得到0.5 ~ 1的输出;线性回归得到小于0的输出,逻辑回归就会得到0 ~ 0.5的输出;【其实就是上面把Z>0和Z<0两种情况讨论】
他们的联系:线性回归模型试图找到一个线性方程来拟合数据,而逻辑回归模型则试图找到一个逻辑函数来拟合数据。线性回归解决预测问题,逻辑回归解决分类问题。
2、逻辑回归的基本模型-神经网络模型
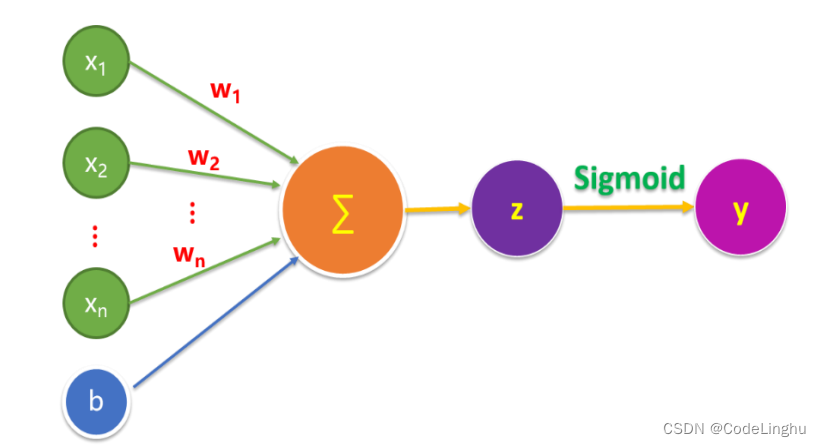
许多问题的预测结果是一个在连续空间的数值,比如房价预测问题,可以用线性模型来描 述:

但也有很多场景需要输出的是概率估算值,例如:
-
根据邮件内容判断是垃圾邮件的可能性
-
根据医学影像判断肿瘤是恶性的可能性
-
手写数字分别是 0、1、2、3、4、5、6、7、8、9的可能性(概率)
这时需要将预测输出值控制在 [0,1]区间内 二元分类问题的目标是正确预测两个可能的标签中的一个 。
逻辑回归(Logistic Regression)可以用于处理这类问题
3、多元分类基本模型
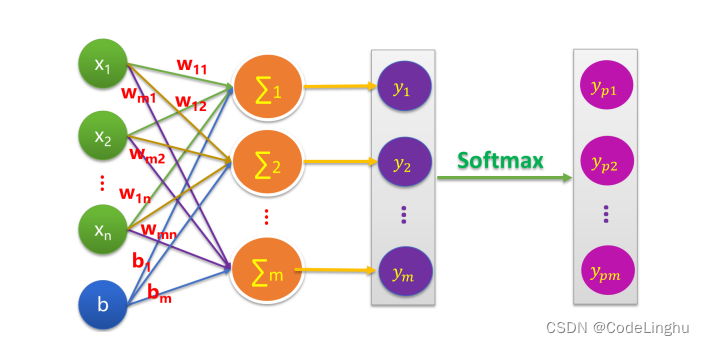
为什么要讨论多元分类呢?因为我们上面引入了逻辑回归的基本模型,我们把逻辑回归基本模型拼成如下图所示就可以得到一个多元分类模型了:
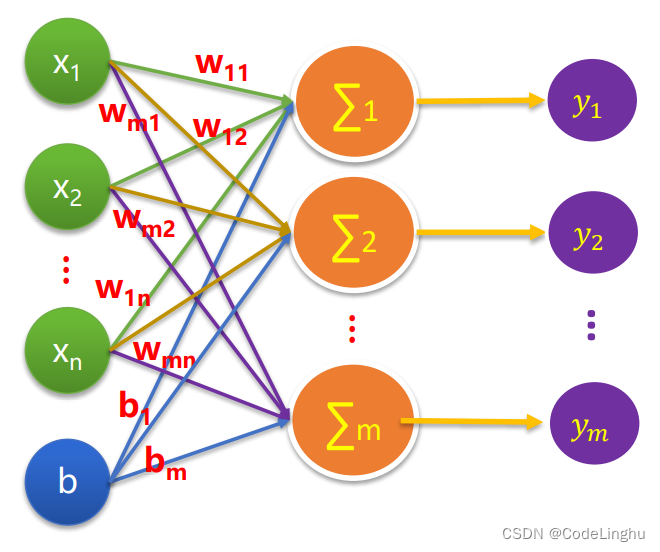
其实这个模型就是一个全连接神经网络。
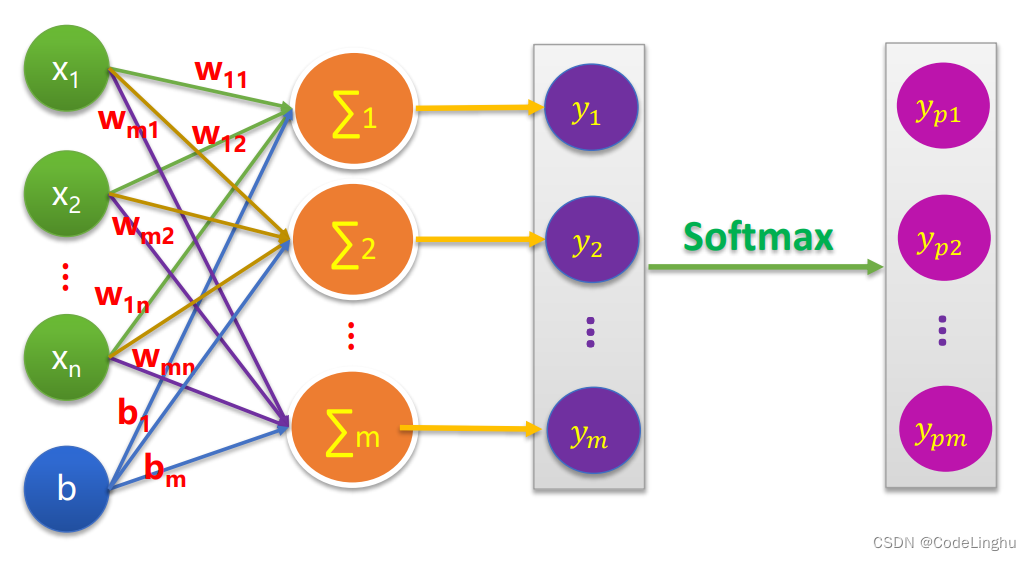
这个Softmax的作用就是让逻辑回归得到的概率值在0-1之间,且概率值相加之和为1!这个Softmax长成这样:
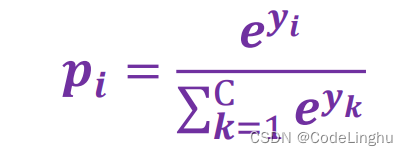
4、TensorFlow实战解决手写数字识别问题
我们说机器学习呢算法的套路如下:
- 准备数据集
- 构建模型
- 训练模型
- 进行预测
准备数据集
我们现在去哪里搜集数据集呢?
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
print("TensorFlow2.0版本是:",tf.__version__)
#打印当前的数据集
mnist=tf.keras.datasets.mnist
(train_images,train_labels),(test_images,test_labels)=mnist.load_data()
print("Train images_shape:",train_images.shape,"Train label shape:",train_labels.shape)
print("Test images shape:",test_images.shape,"Test label shape:",test_labels.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
数据集划分
为了高考取得好成绩,你需要 模拟卷 ,押题卷, 真题卷。
其中:
- 模拟卷=训练集
- 押题卷=验证集
- 真题卷=测试集

这样分类,才能更好的对你的大脑进行训练,如果不按章法刷题,你上来就做真题卷,押题卷缺少了系统的训练;如果你不做押题卷,只做模拟卷,那么你缺少了对真题命题规律的判断。这在机器学习中叫做过拟合或者欠拟合,意思是你的大脑泛化能力不够好,模型训练的不大好。
我们建立了如下图的新的工作流程:

total_num=len(train_images)
valid_split=0.2 # 验证集的比例占20%
train_num=int(total_num*(1-valid_split))#训练集的数目
train_x=train_images[:train_num]#前部分给训练集
train_y=train_labels[:train_num]
valid_x=train_images[train_num:]#后20%给验证集
valid_y=train_labels[train_num:]
test_x=test_images
test_y=test_labels
valid_x.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
特征数据归一化
特征数据归一化(特征归一化)是指将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。特征归一化通常将数据映射到[0,1]区间上,常见的映射范围有[0,1]和[-1,1]。这样可以使得不同指标之间具有可比性。同时,特征归一化也可以消除数据特征之间的量纲影响。
例如,分析一个人的身高和体重对健康的影响 , 如果使用米( m) 和千克( kg )作为单位 , 那么身高特征会在 1.6 ~ l.8m 的数值范围内 , 体重特征会在50 ~ 100kg 的范围内, 分析出来的结果显然会倾向于数值差别比较大的体重特征。 想要得到更为准确的结果,就需要进行特征归一化( Normalization )处理,使各指标处于同一数值量级,以便进行分析。
归一化方法
- 线性函数归 化( Min-Max Scaling )
它对原始数据进行线性变换,使结果映射到[0, 1 ]的范围,实现对原始数据的等比缩放。归一化公式如下:
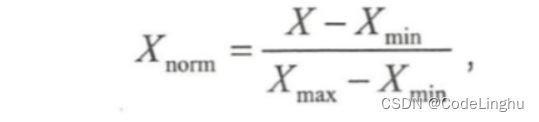
- 零均值归一化( Z-Score Normalization )
它会将原始数据映射到均值为 0、标准差为1 的分布上。 具体来说, 假设原始特征的均值为 μ、标准差为 σ,那么归一化公式定义为
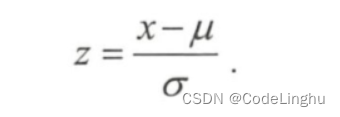
归一化场景
当然 ,数据归一化并不是万能的。 在实际应用中,通过梯度下降法求解的模型通常是需要归一化的 ,包括逻辑回归、线性回归、逻辑回归、支持向量机、 神经网络等模型。 但对于决策树模型则并不适用 , 以C4.5 为例,决策树在进行节点分裂时主要依据数据集 D 关于特征 x 的信息增益比,而信息增益比跟特征是否经过归一化是无关的,因为归一化并不会改变样本在特征 x 上的信息增益。
# 把(28,28)的结构拉成一行 784
train_x=train_x.reshape(-1,784)
valid_x=valid_x.reshape(-1,784)
test_x=test_x.reshape(-1,784)
# 特征数据归一化
train_x=tf.cast(train_x/255.0,tf.float32)
valid_x=tf.cast(valid_x/255.0,tf.float32)
test_x=tf.cast(test_x/255.0,tf.float32)
train_x[1]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
标签数据独热编码
在机器学习算法中,我们经常会遇到分类特征,例如:人的性别有男女,祖国有中国,美国,法国等。这些特征值并不是连续的,而是离散的,无序的。通常我们需要对其进行特征数字化。
考虑以下三个特征:
[“male”, “female”]
[“from Europe”, “from US”, “from Asia”]
[“uses Firefox”, “uses Chrome”, “uses Safari”, “uses Internet Explorer”]
如果将上述特征用数字表示,效率会高很多。例如:
[“male”, “from US”, “uses Internet Explorer”] 表示为[0, 1, 3]
[“female”, “from Asia”, “uses Chrome”]表示为[1, 2, 1]
但是,转化为数字表示后,上述数据不能直接用在我们的分类器中。因为,分类器往往默认数据数据是连续的,并且是有序的。但按上述表示的数字并不有序的,而是随机分配的。
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。

就拿上面的例子来说吧,性别特征:[“男”,“女”],按照N位状态寄存器来对N个状态进行编码的原理,咱们处理后应该是这样的(这里只有两个特征,所以N=2):
男 => 10
女 => 01
祖国特征:[“中国”,"美国,“法国”](这里N=3):
中国 => 100
美国 => 010
法国 => 001
运动特征:[“足球”,“篮球”,“羽毛球”,“乒乓球”](这里N=4):
足球 => 1000
篮球 => 0100
羽毛球 => 0010
乒乓球 => 0001
所以,当一个样本为[“男”,“中国”,“乒乓球”]的时候,完整的特征数字化的结果为:
[1,0,1,0,0,0,0,0,1]
在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。而我们使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。将离散型特征使用one-hot编码,确实会让特征之间的距离计算更加合理。
# 对标签数据进行独热编码
train_y=tf.one_hot(train_y,depth=10)
valid_y=tf.one_hot(valid_y,depth=10)
test_y=tf.one_hot(test_y,depth=10)
train_y
- 1
- 2
- 3
- 4
- 5
构建模型
#构建模型
def model(x,w,b):
pred=tf.matmul(x,w)+b
return tf.nn.softmax(pred)
#定义变量
W=tf.Variable(tf.random.normal([784,10],mean=0.0,stddev=1.0,dtype=tf.float32))
B=tf.Variable(tf.zeros([10]),dtype=tf.float32)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
损失函数
我们在线性回归的实战中采用的损失函数是 平方损失函数。
在逻辑回归中,我们采用的损失函数是 对数损失函数。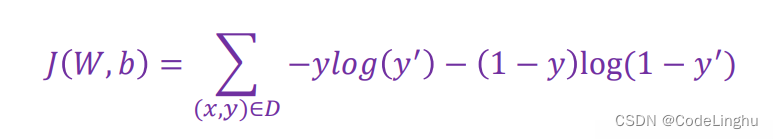
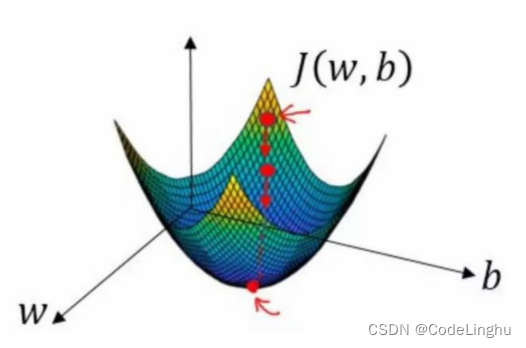
这个函数是一个凸函数,它的图象如下:
在多元分类问题中,我们通常采用交叉熵损失函数:
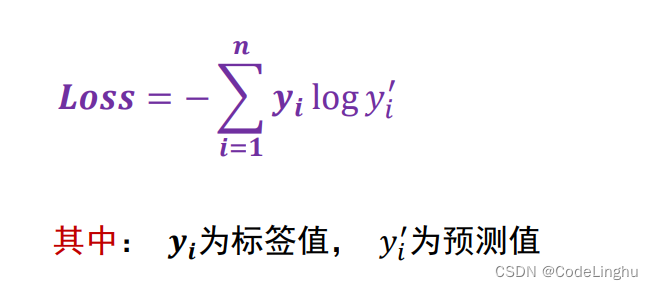
def loss(x,y,w,b):
pred=model(x,w,b)#计算模型预测值和标签值的差异
loss_=tf.keras.losses.categorical_crossentropy(y_true=y,y_pred=pred)# 官方的交叉熵损失函数
return tf.reduce_mean(loss_)#求均值,得到均方差
- 1
- 2
- 3
- 4
训练超参数
training_epochs=20#训练轮数
batch_size=50#单次训练样本
learning_rate=0.001 #学习率
- 1
- 2
- 3
梯度函数
#计算样本数据在[x,y]在参数[w,b]点上的梯度
def grad(x,y,w,b):
with tf.GradientTape() as tape:
loss_=loss(x,y,w,b)
return tape.gradient(loss_,[w,b])#返回梯度向量
- 1
- 2
- 3
- 4
- 5
Adam优化器
#Adam优化器
optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate)
- 1
- 2
常用的优化器有:
- SGD
- Adagrad
- RMSprop
- Adam
准确率
#定义准确率
def accuary(x,y,w,b):
pred=model(x,w,b)#计算模型预测和标签值的差异
# 检查预测类别tf.argmax(pred,1)与实际类别tf.argmax(pred,1)的匹配情况
correct_prediction=tf.equal(tf.argmax(pred,1),tf.argmax(y,1))
#准确率
return tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
模型训练
total_step=int(train_num/batch_size)#一轮训练有多少批次 loss_list_train=[]#用于保存训练集loss值的列表 loss_list_valid=[]# 用于保存验证集loss值的列表 acc_list_train=[]# 用于保存训练集Acc的值的列表 acc_list_valid=[]# 用于保存验证集Acc值的列表 for epoch in range(training_epochs): for step in range(total_step): xs=train_x[step*batch_size:(step+1)*batch_size] ys=train_y[step*batch_size:(step+1)*batch_size] grads=grad(xs,ys,W,B)#计算梯度 optimizer.apply_gradients(zip(grads,[W,B]))#优化器根据梯度自动调整变量w和b loss_train=loss(train_x,train_y,W,B).numpy() #计算当前轮训练损失 loss_valid=loss(valid_x,valid_y,W,B).numpy() #计算当前轮损失验证 acc_train=accuary(train_x,train_y,W,B).numpy() acc_valid=accuary(valid_x,valid_y,W,B).numpy() loss_list_train.append(loss_train) loss_list_valid.append(loss_valid) acc_list_train.append(acc_train) acc_list_valid.append(acc_valid) print("epoch={:3d},train_loss={:.4f},train_acc={:.4f},val_loss={:.4f},val_acc={:.4f}".format( epoch+1,loss_train,acc_train,loss_valid,acc_valid))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
显示训练过程数据
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.plot(loss_list_train,'blue',label='Train Loss')
plt.plot(loss_list_valid,'red',label='Valid Loss')
plt.legend(loc=1)#通过参数loc指定图例位置
plt.xlabel("Epochs")
plt.ylabel("Accuary")
plt.plot(acc_list_train,'blue',label='Train Acc')
plt.plot(acc_list_valid,'red',label='Valid Acc')
plt.legend(loc=1)#通过参数loc指定图例位置
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在测试集完成评估模型
acc_test=accuary(test_x,test_y,W,B).numpy()
print("Test accuary:",acc_test)
- 1
- 2
模型预测
模型建立完成以后并训练完,现在认为准确度可以接受了,接下来可以使用这个模型进行预测了。
# 定义预测函数
def predict(x,w,b):
pred=model(x,w,b)#计算预测值
result=tf.argmax(pred,1).numpy()
return result
pred_test=predict(test_x,W,B)
pred_test[0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
定义可视化函数
def plot_images_labels_prediction(images,# 图象列表 labels,# 标签列表 preds,#预测值列表 index=0,#从第index个开始显示 num=10):#缺省一次显示10幅 fig=plt.gcf() #获取当前图表 fig.set_size_inches(10,4) # 1英寸=2.54cm if num > 10: num = 10 #最多显示10个子图 for i in range(0,num): ax=plt.subplot(2,5,i+1)#获取当前要处理的子图 ax.imshow(np.reshape(images[index],(28,28)),cmap='binary')# 显示第index个图 title="label="+str(labels[index])#构建图上要显示的title信息 if len(preds)>0: title+=",predict="+str(preds[index]) ax.set_title(title,fontsize=10)#显示图上的title信息 ax.set_xticks([])#不显示坐标 ax.set_yticks([]) index=index+1 plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
预测函数可视化预测结果
#可视化预测结果
plot_images_labels_prediction(test_images,test_labels,pred_test,10,10)
- 1
- 2

可以调整训练迭代次数来提高迭代的准确度。
5、完整代码demo
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt %matplotlib inline print("TensorFlow2.0版本是:",tf.__version__) mnist=tf.keras.datasets.mnist (train_images,train_labels),(test_images,test_labels)=mnist.load_data() print("Train images_shape:",train_images.shape,"Train label shape:",train_labels.shape) print("Test images shape:",test_images.shape,"Test label shape:",test_labels.shape) print("image data:",train_images[1]) def plot_image(image): plt.imshow(image.reshape(28,28),cmap='binary') plt.show() plot_image(train_images[1]) total_num=len(train_images) valid_split=0.2 # 验证集的比例占20% train_num=int(total_num*(1-valid_split))#训练集的数目 train_x=train_images[:train_num]#前部分给训练集 train_y=train_labels[:train_num] valid_x=train_images[train_num:]#后20%给验证集 valid_y=train_labels[train_num:] test_x=test_images test_y=test_labels valid_x.shape # 把(28,28)的结构拉成一行 784 train_x=train_x.reshape(-1,784) valid_x=valid_x.reshape(-1,784) test_x=test_x.reshape(-1,784) # 特征数据归一化 train_x=tf.cast(train_x/255.0,tf.float32) valid_x=tf.cast(valid_x/255.0,tf.float32) test_x=tf.cast(test_x/255.0,tf.float32) train_x[1] # 对标签数据进行独热编码 train_y=tf.one_hot(train_y,depth=10) valid_y=tf.one_hot(valid_y,depth=10) test_y=tf.one_hot(test_y,depth=10) train_y #构建模型 def model(x,w,b): pred=tf.matmul(x,w)+b return tf.nn.softmax(pred) #定义变量 W=tf.Variable(tf.random.normal([784,10],mean=0.0,stddev=1.0,dtype=tf.float32)) B=tf.Variable(tf.zeros([10]),dtype=tf.float32) def loss(x,y,w,b): pred=model(x,w,b)#计算模型预测值和标签值的差异 loss_=tf.keras.losses.categorical_crossentropy(y_true=y,y_pred=pred) return tf.reduce_mean(loss_)#求均值,得到均方差 training_epochs=20#训练轮数 batch_size=50#单次训练样本 learning_rate=0.001 #学习率 #计算样本数据在[x,y]在参数[w,b]点上的梯度 def grad(x,y,w,b): with tf.GradientTape() as tape: loss_=loss(x,y,w,b) return tape.gradient(loss_,[w,b])#返回梯度向量 #Adam优化器 optimizer=tf.keras.optimizers.Adam(learning_rate=learning_rate) #定义准确率 def accuary(x,y,w,b): pred=model(x,w,b)#计算模型预测和标签值的差异 # 检查预测类别tf.argmax(pred,1)与实际类别tf.argmax(pred,1)的匹配情况 correct_prediction=tf.equal(tf.argmax(pred,1),tf.argmax(y,1)) #准确率 return tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) total_step=int(train_num/batch_size)#一轮训练有多少批次 loss_list_train=[]#用于保存训练集loss值的列表 loss_list_valid=[]# 用于保存验证集loss值的列表 acc_list_train=[]# 用于保存训练集Acc的值的列表 acc_list_valid=[]# 用于保存验证集Acc值的列表 for epoch in range(training_epochs): for step in range(total_step): xs=train_x[step*batch_size:(step+1)*batch_size] ys=train_y[step*batch_size:(step+1)*batch_size] grads=grad(xs,ys,W,B)#计算梯度 optimizer.apply_gradients(zip(grads,[W,B]))#优化器根据梯度自动调整变量w和b loss_train=loss(train_x,train_y,W,B).numpy() #计算当前轮训练损失 loss_valid=loss(valid_x,valid_y,W,B).numpy() #计算当前轮损失验证 acc_train=accuary(train_x,train_y,W,B).numpy() acc_valid=accuary(valid_x,valid_y,W,B).numpy() loss_list_train.append(loss_train) loss_list_valid.append(loss_valid) acc_list_train.append(acc_train) acc_list_valid.append(acc_valid) print("epoch={:3d},train_loss={:.4f},train_acc={:.4f},val_loss={:.4f},val_acc={:.4f}".format( epoch+1,loss_train,acc_train,loss_valid,acc_valid)) plt.xlabel("Epochs") plt.ylabel("Loss") plt.plot(loss_list_train,'blue',label='Train Loss') plt.plot(loss_list_valid,'red',label='Valid Loss') plt.legend(loc=1)#通过参数loc指定图例位置 plt.xlabel("Epochs") plt.ylabel("Accuary") plt.plot(acc_list_train,'blue',label='Train Acc') plt.plot(acc_list_valid,'red',label='Valid Acc') plt.legend(loc=1)#通过参数loc指定图例位置 acc_test=accuary(test_x,test_y,W,B).numpy() print("Test accuary:",acc_test) # 定义预测函数 def predict(x,w,b): pred=model(x,w,b)#计算预测值 result=tf.argmax(pred,1).numpy() return result pred_test=predict(test_x,W,B) pred_test[0] def plot_images_labels_prediction(images,# 图象列表 labels,# 标签列表 preds,#预测值列表 index=0,#从第index个开始显示 num=10):#缺省一次显示10幅 fig=plt.gcf() #获取当前图表 fig.set_size_inches(10,4) # 1英寸=2.54cm if num > 10: num = 10 #最多显示10个子图 for i in range(0,num): ax=plt.subplot(2,5,i+1)#获取当前要处理的子图 ax.imshow(np.reshape(images[index],(28,28)),cmap='binary')# 显示第index个图 title="label="+str(labels[index])#构建图上要显示的title信息 if len(preds)>0: title+=",predict="+str(preds[index]) ax.set_title(title,fontsize=10)#显示图上的title信息 ax.set_xticks([])#不显示坐标 ax.set_yticks([]) index=index+1 plt.show() #可视化预测结果 plot_images_labels_prediction(test_images,test_labels,pred_test,10,10)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162

