
- 1mysql卸载后重装不_mysql卸载后无法重装
- 2Python的http模块requests
- 3【jQuery学习】jQuery内容文本值_jquery 定位元素内容
- 4计算image1和image2之间的LPIPS指标的python代码_计算两个数据集的lpips
- 5乐鑫 SoC 内存映射入门_soc中内存访问客户端
- 6docker 容器防火墙设置_容器内部防火墙
- 7Windows10 下使用 telnet 命令_win telnet返回结果
- 8[Ansible系列]ansible JinJia2过滤器_ansible jinja2 filter
- 9Win10 远程连接 MySQL 防火墙阻止访问的解决办法_客户端访问mssql 被防火墙拦截
- 10C++实现YOLO目标识别图像预处理、后处理_yolo后处理
tensorflow 多GPU编程 完全指南_tensorflow多gpu
赞
踩
人生苦短,我用pytorch, 推荐大家使用 PyTorch分布式训练简明教程
PyTorch分布式训练基础--DDP使用 - 知乎
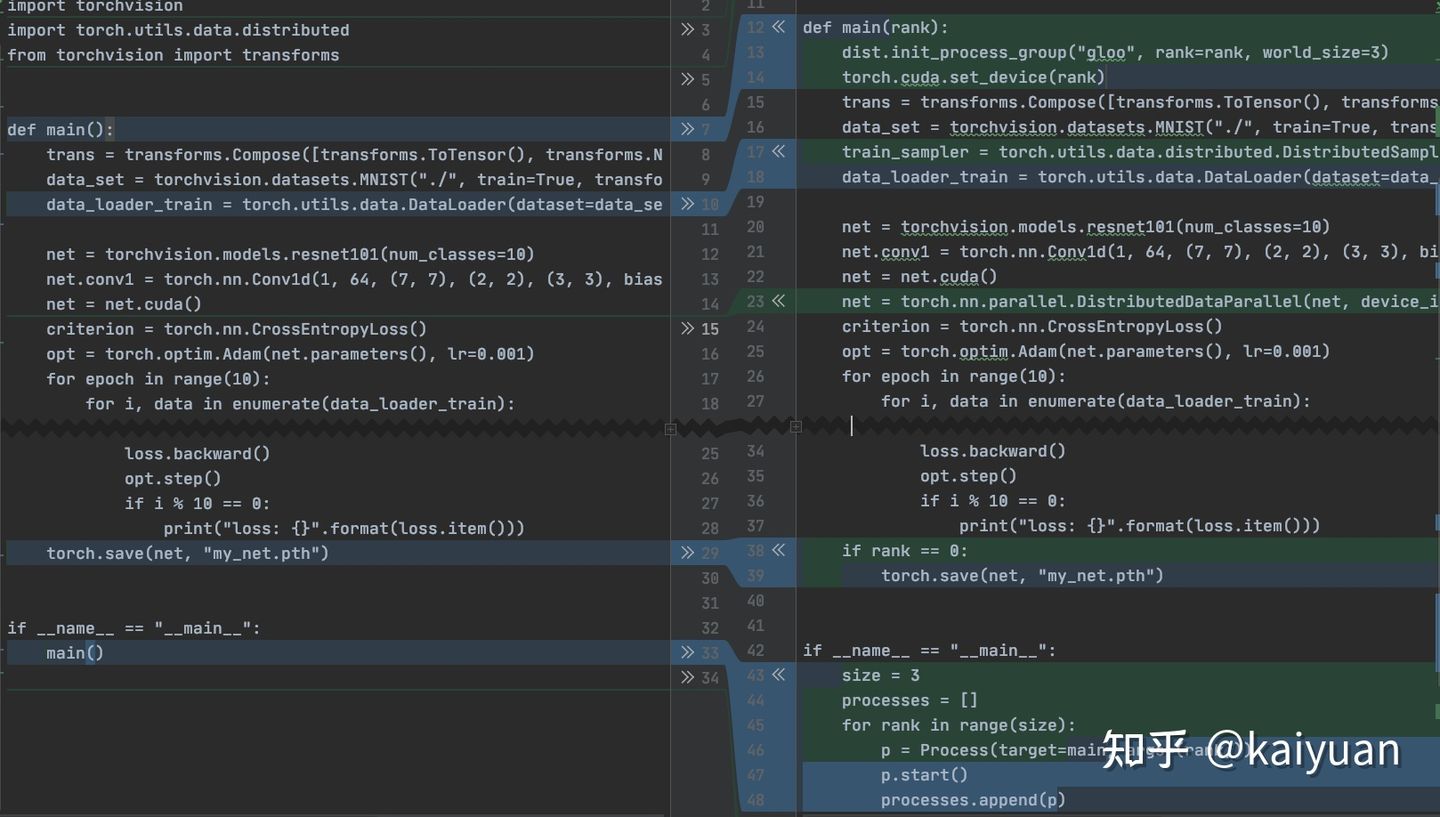
主要变动的位置包括:
1. 启动的方式引入了一个多进程机制;
2. 引入了几个环境变量;
3. DataLoader多了一个sampler参数;
4. 网络被一个DistributedDataParallel(net)又包裹了一层;
5. ckpt的保存方式发生了变化。
目前已有很多介绍tensorflow使用多GPU的文章,但大多凌乱不堪,更有相互借鉴之嫌。笔者钻研数日,总算理清里面的脉络,特成此文以飨读者。
- 缘起
tensorflow使用GPU时默认占满所有可用GPU的显存,但只在第一个GPU上进行计算。下图展示了一个典型的使用GPU训练的例子,虽然机器上有两块GPU,但却只有一块真正在工作,如果不加以利用,另一块GPU就白白浪费了。我们知道,GPU是一种相对比较昂贵的计算资源,虽然正值矿难,相比之前动辄八九千一块1080Ti的价格低了不少,但也不是一般人能浪费的起的,因此如何有效提高GPU特别是tensorflow上的利用率就成为了一项重要的考量。

2.朴素的解决方案
一种经常提及的方法是设置可见的GPU,方法是通过设置CUDA_VISIBLE_DEVICES来完成,如果在shell中运行,每次运行某个shell脚本之前,加上export CUDA_VISIBLE_DEVICES=0#或者是你期望运行的GPU id(0到n-1,其中n是机器上GPU卡的数量),如果是在python脚本,还可以在所有代码之前:
- import os
- os.environ["CUDA_VISIBLE_DEVICES"]="0"
另外为缓解tensorflow一上来就占满整个GPU导致的问题,还可以在创建sess的时候传入附加的参数,更好的控制GPU的使用方法是
- config = tf.ConfigProto(allow_soft_placement=True,allow_grouth=True)
- config.gpu_options.per_process_gpu_memory_fraction = 0.9 #占用90%显存
- sess = tf.Session(config=config)
3.多GPU编程指南
上面的方法确实可以解决一定的问题,比如多个用户公用几块卡,每个人分配不同的卡来做实验,或者每张卡上运行不同的参数设置。但有时候我们更需要利用好已有的卡,来或得线性的加速比,以便在更短的时候获取参考结果,上面的方法就无能无力,只能自己写代码解决了,而当前怎么把单GPU代码转换为多GPU代码好像还没有一篇文章给出示例。
说到tensorflow的多GPU编程,不得不说是一部悲壮的血泪史。用过caffe的用户都知道caffe下的多GPU是多么的简单,从单GPU切换到多GPU你根本不用修改任何代码,只需要在编译选项中把USE_NCCL打开就好,剩下的都是caffe帮你自动完成了。到了tensorflow就不一样的,所有的东西都得你自己操心,包括变量放哪,平均梯度什么的。当然好处是你对训练的过程理解的也更透彻了。
tensorflow的models里面有一个使用多GPU的例子,路径为tutorials/image/cifar10/cifar10_multi_gpu_train.py,但它仅仅是一个能运行的demo而已,里面并没有解释枚举代码的含义,更别提为什么写那些代码了,乱的一比。
从网上找出一个能用且好用的例子并不像想象中的简单,我踏遍整个网络,把百度和谷歌中所有相关的文章都看了一遍,觉得还不错的是Multi-GPU Basic,里面用一个小例子对比了单GPU和多GPU的差异。
另外一个用Mnist的例子是这边文章要描述的重点,不过里面仍有一些干扰我们理解的代码,比如那个assign_to_device函数。
其实tensorflow使用多GPU也是非常简单的,无外乎用tf.device("/gpu:0")之类的包起来,但要注意变量存放的位置。
我们也以一个mnist单GPU训练的例子作为开始:
- import tensorflow as tf
- from tensorflow.contrib import slim
- import numpy as np
- from tensorflow.examples.tutorials.mnist import input_data
-
- mnist=input_data.read_data_sets("/tmp/mnist/",one_hot=True)
-
- num_gpus=2
- num_steps=200
- learning_rate=0.001
- batch_size=1024
- display_step=10
-
- num_input=784
- num_classes=10
- def conv_net(x,is_training):
- # "updates_collections": None is very import ,without will only get 0.10
- batch_norm_params = {"is_training": is_training, "decay": 0.9, "updates_collections": None}
- #,'variables_collections': [ tf.GraphKeys.TRAINABLE_VARIABLES ]
- with slim.arg_scope([slim.conv2d, slim.fully_connected],
- activation_fn=tf.nn.relu,
- weights_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.01),
- weights_regularizer=slim.l2_regularizer(0.0005),
- normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params):
- with tf.variable_scope("ConvNet",reuse=tf.AUTO_REUSE):
- x = tf.reshape(x, [-1, 28, 28, 1])
- net = slim.conv2d(x, 6, [5,5], scope="conv_1")
- net = slim.max_pool2d(net, [2, 2],scope="pool_1")
- net = slim.conv2d(net, 12, [5,5], scope="conv_2")
- net = slim.max_pool2d(net, [2, 2], scope="pool_2")
- net = slim.flatten(net, scope="flatten")
- net = slim.fully_connected(net, 100, scope="fc")
- net = slim.dropout(net,is_training=is_training)
- net = slim.fully_connected(net, num_classes, scope="prob", activation_fn=None,normalizer_fn=None)
- return net
- def train_single():
- X = tf.placeholder(tf.float32, [None, num_input])
- Y = tf.placeholder(tf.float32, [None, num_classes])
- logits=conv_net(X,True)
- loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=logits))
- opt=tf.train.AdamOptimizer(learning_rate)
- train_op=opt.minimize(loss)
- logits_test=conv_net(X,False)
- correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(Y, 1))
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- for step in range(1,num_steps+1):
- batch_x, batch_y = mnist.train.next_batch(batch_size)
- sess.run(train_op,feed_dict={X:batch_x,Y:batch_y})
- if step%display_step==0 or step==1:
- loss_value,acc=sess.run([loss,accuracy],feed_dict={X:batch_x,Y:batch_y})
- print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc))
- print("Done")
- print("Testing Accuracy:",np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size],
- Y: mnist.test.labels[i:i + batch_size]}) for i in
- range(0, len(mnist.test.images), batch_size)]))
-
- if __name__ == "__main__":
- train_single()
在上面寥寥数行的代码中,我们下载并构建了mnist数据集,通过mnist.train.next_batch(batch_szie)的方式返回一个batch的数据,然后扔进conv_net网络,计算出loss后再使用Adam优化器进行训练,最后测试了其精度。
只需要几分钟,在我的一块1080Ti卡上就能运行完毕,并且得到相当好的结果:
Step:1:2.213318 0.20703125
Step:10:0.46338645 0.88183594
Step:20:0.18729115 0.9550781
Step:30:0.17860937 0.9628906
Step:40:0.11540267 0.97558594
Step:50:0.081396215 0.9824219
Step:60:0.097750194 0.9746094
Step:70:0.060169913 0.984375
Step:80:0.059070613 0.98828125
Step:90:0.060746174 0.9892578
Step:100:0.057775088 0.9892578
Step:110:0.038614694 0.98828125
Step:120:0.0369242 0.9921875
Step:130:0.035249908 0.9941406
Step:140:0.03395287 0.9902344
Step:150:0.03798459 0.98828125
Step:160:0.052775905 0.99121094
Step:170:0.017296169 0.99609375
Step:180:0.026407585 0.9951172
Step:190:0.044104658 0.9941406
Step:200:0.025472593 0.99121094
Done
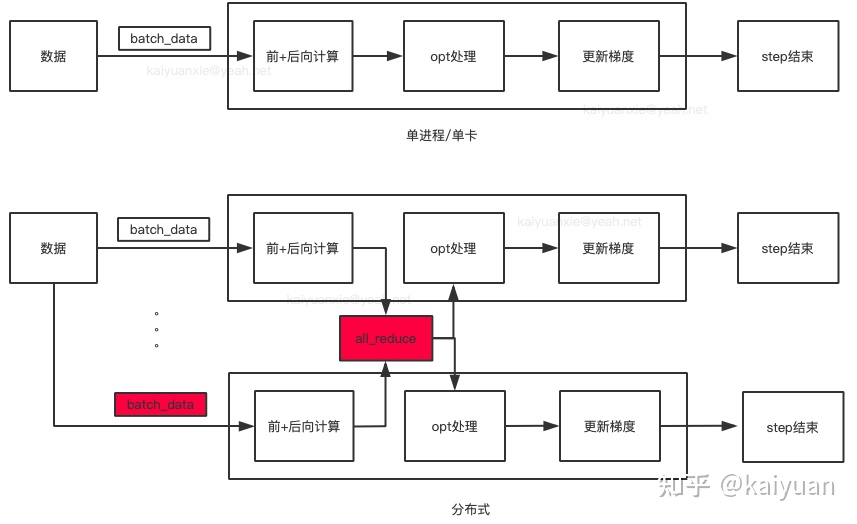
('Testing Accuracy:', 0.99301463)接下来我们将以此为起点,对其进行多GPU化改造。下面的图很好的阐释了整个流程。
多GPU并行可分为模型并行和数据并行两大类,上图展示的是数据并行,这也是我们经常用到的方法,而其中数据并行又可分为同步方式和异步方式两种,由于我们一般都会配置同样的显卡,因此这儿也选择了同步方式,也就是把数据分给不同的卡,等所有的GPU都计算完梯度后进行平均,最后再更新梯度。
首先要改造的就是数据读取部分,由于现在我们有多快卡,每张卡要分到不同的数据,所以在获取batch的时候要把大小改为batch_x,batch_y=mnist.train.next_batch(batch_size*num_gpus),一次取足够的数据保证每块卡都分到batch_size大小的数据。然后我们对取到的数据进行切分,我们以i表示GPU的索引,连续的batch_size大小的数据分给同一块GPU:
- _x=X[i*batch_size:(i+1)*batch_size]
- _y=Y[i*batch_size:(i+1)*batch_size]
由于我们多个GPU上共享同样的图,为了防止名字混乱,最好使用name_scope进行区分,也就是如下的形式:
- for i in range(2):
- with tf.device("/gpu:%d"%i):
- with tf.name_scope("tower_%d"%i):
- _x=X[i*batch_size:(i+1)*batch_size]
- _y=Y[i*batch_size:(i+1)*batch_size]
- logits=conv_net(_x,dropout,reuse_vars,True)
我们需要有个列表存储所有GPU上的梯度,还有就是复用变量,需要在之前定义如下两个值:
- tower_grads=[]
- reuse_vars=False
所有的准备工作都已完成,就可以计算每个GPU上的梯度了
- opt = tf.train.AdamOptimizer(learning_rate)
- loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=_y,logits=logits))
- grads=opt.compute_gradients(loss)
- reuse_vars=True
- tower_grads.append(grads)
这样tower_grads就存储了所有GPU上所有变量的梯度,下面就是计算平均值了,这个是所有见过的函数中唯一一个几乎从没变过的代码:
- def average_gradients(tower_grads):
- average_grads=[]
- for grad_and_vars in zip(*tower_grads):
- grads=[]
- for g,_ in grad_and_vars:
- expend_g=tf.expand_dims(g,0)
- grads.append(expend_g)
- grad=tf.concat(grads,0)
- grad=tf.reduce_mean(grad,0)
- v=grad_and_vars[0][1]
- grad_and_var=(grad,v)
- average_grads.append(grad_and_var)
- return average_grads
tower_grads里面保存的形式是(第一个GPU上的梯度,第二个GPU上的梯度,...第N-1个GPU上的梯度),这里有一点需要注意的是zip(*),它的作用上把上面的那个列表转换成((grad0_gpu0, var0_gpu0), ... , (grad0_gpuN, var0_gpuN))的形式,也就是以列访问的方式,取到的就是某个变量在不同GPU上的值。
最后就是更新梯度了
- grads=average_gradients(tower_grads)
- train_op=opt.apply_gradients(grads)
上面的讲述略有零散,最后我们给个全代码版本方便大家测试:
- import time
- import numpy as np
-
- import tensorflow as tf
- from tensorflow.contrib import slim
- from tensorflow.examples.tutorials.mnist import input_data
-
- mnist = input_data.read_data_sets("mnist/", one_hot=True)
-
- def get_available_gpus():
- """
- code from http://stackoverflow.com/questions/38559755/how-to-get-current-available-gpus-in-tensorflow
- """
- from tensorflow.python.client import device_lib as _device_lib
- local_device_protos = _device_lib.list_local_devices()
- return [x.name for x in local_device_protos if x.device_type == 'GPU']
-
- num_gpus = len(get_available_gpus())
- print("Available GPU Number :"+str(num_gpus))
-
- num_steps = 1000
- learning_rate = 0.001
- batch_size = 1000
- display_step = 10
-
- num_input = 784
- num_classes = 10
-
- def conv_net_with_layers(x,is_training,dropout = 0.75):
- with tf.variable_scope("ConvNet", reuse=tf.AUTO_REUSE):
- x = tf.reshape(x, [-1, 28, 28, 1])
- x = tf.layers.conv2d(x, 12, 5, activation=tf.nn.relu)
- x = tf.layers.max_pooling2d(x, 2, 2)
- x = tf.layers.conv2d(x, 24, 3, activation=tf.nn.relu)
- x = tf.layers.max_pooling2d(x, 2, 2)
- x = tf.layers.flatten(x)
- x = tf.layers.dense(x, 100)
- x = tf.layers.dropout(x, rate=dropout, training=is_training)
- out = tf.layers.dense(x, 10)
- out = tf.nn.softmax(out) if not is_training else out
- return out
-
- def conv_net(x,is_training):
- # "updates_collections": None is very import ,without will only get 0.10
- batch_norm_params = {"is_training": is_training, "decay": 0.9, "updates_collections": None}
- #,'variables_collections': [ tf.GraphKeys.TRAINABLE_VARIABLES ]
- with slim.arg_scope([slim.conv2d, slim.fully_connected],
- activation_fn=tf.nn.relu,
- weights_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.01),
- weights_regularizer=slim.l2_regularizer(0.0005),
- normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params):
- with tf.variable_scope("ConvNet",reuse=tf.AUTO_REUSE):
- x = tf.reshape(x, [-1, 28, 28, 1])
- net = slim.conv2d(x, 6, [5,5], scope="conv_1")
- net = slim.max_pool2d(net, [2, 2],scope="pool_1")
- net = slim.conv2d(net, 12, [5,5], scope="conv_2")
- net = slim.max_pool2d(net, [2, 2], scope="pool_2")
- net = slim.flatten(net, scope="flatten")
- net = slim.fully_connected(net, 100, scope="fc")
- net = slim.dropout(net,is_training=is_training)
- net = slim.fully_connected(net, num_classes, scope="prob", activation_fn=None,normalizer_fn=None)
- return net
-
- def average_gradients(tower_grads):
- average_grads = []
- for grad_and_vars in zip(*tower_grads):
- grads = []
- for g, _ in grad_and_vars:
- expend_g = tf.expand_dims(g, 0)
- grads.append(expend_g)
- grad = tf.concat(grads, 0)
- grad = tf.reduce_mean(grad, 0)
- v = grad_and_vars[0][1]
- grad_and_var = (grad, v)
- average_grads.append(grad_and_var)
- return average_grads
-
- PS_OPS = ['Variable', 'VariableV2', 'AutoReloadVariable']
- def assign_to_device(device, ps_device='/cpu:0'):
- def _assign(op):
- node_def = op if isinstance(op, tf.NodeDef) else op.node_def
- if node_def.op in PS_OPS:
- return "/" + ps_device
- else:
- return device
-
- return _assign
-
- def train():
- with tf.device("/cpu:0"):
- global_step=tf.train.get_or_create_global_step()
- tower_grads = []
- X = tf.placeholder(tf.float32, [None, num_input])
- Y = tf.placeholder(tf.float32, [None, num_classes])
- opt = tf.train.AdamOptimizer(learning_rate)
- with tf.variable_scope(tf.get_variable_scope()):
- for i in range(num_gpus):
- with tf.device(assign_to_device('/gpu:{}'.format(i), ps_device='/cpu:0')):
- _x = X[i * batch_size:(i + 1) * batch_size]
- _y = Y[i * batch_size:(i + 1) * batch_size]
- logits = conv_net(_x, True)
- tf.get_variable_scope().reuse_variables()
- loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=_y, logits=logits))
- grads = opt.compute_gradients(loss)
- tower_grads.append(grads)
- if i == 0:
- logits_test = conv_net(_x, False)
- correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(_y, 1))
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- grads = average_gradients(tower_grads)
- train_op = opt.apply_gradients(grads)
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- for step in range(1, num_steps + 1):
- batch_x, batch_y = mnist.train.next_batch(batch_size * num_gpus)
- ts = time.time()
- sess.run(train_op, feed_dict={X: batch_x, Y: batch_y})
- te = time.time() - ts
- if step % 10 == 0 or step == 1:
- loss_value, acc = sess.run([loss, accuracy], feed_dict={X: batch_x, Y: batch_y})
- print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc)+", %i Examples/sec" % int(len(batch_x)/te))
- print("Done")
- print("Testing Accuracy:",
- np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size],
- Y: mnist.test.labels[i:i + batch_size]}) for i in
- range(0, len(mnist.test.images), batch_size)]))
- def train_single():
- X = tf.placeholder(tf.float32, [None, num_input])
- Y = tf.placeholder(tf.float32, [None, num_classes])
- logits=conv_net(X,True)
- loss=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y,logits=logits))
- opt=tf.train.AdamOptimizer(learning_rate)
- train_op=opt.minimize(loss)
- logits_test=conv_net(X,False)
- correct_prediction = tf.equal(tf.argmax(logits_test, 1), tf.argmax(Y, 1))
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- for step in range(1,num_steps+1):
- batch_x, batch_y = mnist.train.next_batch(batch_size)
- sess.run(train_op,feed_dict={X:batch_x,Y:batch_y})
- if step%display_step==0 or step==1:
- loss_value,acc=sess.run([loss,accuracy],feed_dict={X:batch_x,Y:batch_y})
- print("Step:" + str(step) + ":" + str(loss_value) + " " + str(acc))
- print("Done")
- print("Testing Accuracy:",np.mean([sess.run(accuracy, feed_dict={X: mnist.test.images[i:i + batch_size],
- Y: mnist.test.labels[i:i + batch_size]}) for i in
- range(0, len(mnist.test.images), batch_size)]))
-
- if __name__ == "__main__":
- #train_single()
- train()
如果有多张卡可以再写个脚本控制使用哪张卡
- export CUDA_VISIBLE_DEVICES=1,2
- python train.py
2张P40卡运行结果是11000张每秒,1080Ti应该没这么高.
Step:1:2.1766396 0.116, 621 Examples/sec
Step:10:1.7068547 0.11, 110790 Examples/sec
Step:20:1.3074275 0.108, 115161 Examples/sec
Step:30:0.96290886 0.705, 105871 Examples/sec
Step:40:0.6941168 0.965, 77068 Examples/sec
Step:50:0.51668066 0.972, 105535 Examples/sec
Step:60:0.4247902 0.979, 76964 Examples/sec
Step:70:0.3088946 0.982, 113249 Examples/sec
Step:80:0.29520142 0.975, 106145 Examples/sec
Step:90:0.22964586 0.982, 123244 Examples/sec
Step:100:0.20586261 0.984, 121470 Examples/sec
Step:110:0.19377343 0.98, 107164 Examples/sec
Step:120:0.15911222 0.988, 111632 Examples/sec
Step:130:0.14919634 0.993, 114063 Examples/sec
Step:140:0.14532794 0.989, 104887 Examples/sec
Step:150:0.11892563 0.982, 118091 Examples/sec
Step:160:0.12074805 0.988, 104975 Examples/sec
Step:170:0.10315554 0.994, 115962 Examples/sec
Step:180:0.093983576 0.992, 112892 Examples/sec
Step:190:0.11011183 0.986, 64566 Examples/sec
Step:200:0.10322208 0.991, 111819 Examples/sec
Step:210:0.08808109 0.99, 114969 Examples/sec
Step:220:0.0977648 0.991, 113708 Examples/sec
Step:230:0.084136 0.991, 111556 Examples/sec
Step:240:0.06446432 0.988, 100194 Examples/sec
Step:250:0.083906956 0.992, 112346 Examples/sec
Step:260:0.07458659 0.996, 109128 Examples/sec
Step:270:0.07159772 0.992, 103879 Examples/sec
Step:280:0.072315805 0.991, 114719 Examples/sec
Step:290:0.07115288 0.995, 98594 Examples/sec
Step:300:0.06811921 0.996, 113824 Examples/sec
Step:310:0.05948469 0.995, 110059 Examples/sec
Step:320:0.05909388 0.994, 107389 Examples/sec
Step:330:0.06388393 0.991, 115740 Examples/sec
Step:340:0.060143195 0.995, 107828 Examples/sec
Step:350:0.06259125 0.993, 105719 Examples/sec
Step:360:0.048079446 0.998, 106241 Examples/sec
Step:370:0.055516105 0.992, 88636 Examples/sec
Step:380:0.05334521 0.994, 104553 Examples/sec
Step:390:0.049692582 0.992, 116476 Examples/sec
Step:400:0.05057991 0.988, 114428 Examples/sec
Step:410:0.059688516 0.995, 119381 Examples/sec
Step:420:0.06106449 0.998, 107009 Examples/sec
Step:430:0.039503913 0.995, 109534 Examples/sec
Step:440:0.055380426 0.994, 118504 Examples/sec
Step:450:0.052480474 0.998, 92374 Examples/sec
Step:460:0.0468014 0.994, 90004 Examples/sec
Step:470:0.048530754 0.999, 110791 Examples/sec
Step:480:0.04531612 0.998, 114791 Examples/sec
Step:490:0.042711727 0.995, 104346 Examples/sec
Step:500:0.03920111 0.999, 112827 Examples/sec
Step:510:0.039490122 0.994, 103375 Examples/sec
Step:520:0.03745923 0.994, 112745 Examples/sec
Step:530:0.03280555 0.998, 112980 Examples/sec
Step:540:0.04259963 0.994, 107370 Examples/sec
Step:550:0.0520297 0.998, 104465 Examples/sec
Step:560:0.034253605 0.998, 115819 Examples/sec
Step:570:0.038027 0.998, 112987 Examples/sec
Step:580:0.041231055 0.994, 116084 Examples/sec
Step:590:0.03687844 0.999, 111451 Examples/sec
Step:600:0.0332405 0.998, 115673 Examples/sec
Step:610:0.036619414 0.995, 112974 Examples/sec
Step:620:0.04440185 0.998, 115493 Examples/sec
Step:630:0.048253592 0.999, 109932 Examples/sec
Step:640:0.031658944 0.995, 112453 Examples/sec
Step:650:0.037486266 0.999, 90654 Examples/sec
Step:660:0.03043366 0.996, 108577 Examples/sec
Step:670:0.06595675 0.998, 106592 Examples/sec
Step:680:0.038847264 0.997, 115068 Examples/sec
Step:690:0.024775814 0.997, 96838 Examples/sec
Step:700:0.042397942 0.996, 111197 Examples/sec
Step:710:0.035917144 0.997, 118406 Examples/sec
Step:720:0.030851414 0.998, 119004 Examples/sec
Step:730:0.029090386 0.995, 113134 Examples/sec
Step:740:0.042240147 0.997, 110742 Examples/sec
Step:750:0.035532072 0.997, 114994 Examples/sec
Step:760:0.029552884 0.995, 108149 Examples/sec
Step:770:0.031979892 0.996, 116468 Examples/sec
Step:780:0.029503383 1.0, 109139 Examples/sec
Step:790:0.029520674 0.999, 85157 Examples/sec
Step:800:0.029163884 0.998, 113333 Examples/sec
Step:810:0.031229936 0.999, 114705 Examples/sec
Step:820:0.026513534 0.994, 117439 Examples/sec
Step:830:0.022330025 1.0, 91408 Examples/sec
Step:840:0.03787502 0.999, 104193 Examples/sec
Step:850:0.02762249 0.995, 105391 Examples/sec
Step:860:0.030331183 0.999, 94241 Examples/sec
Step:870:0.03592214 0.997, 114476 Examples/sec
Step:880:0.035410557 0.996, 98076 Examples/sec
Step:890:0.032153483 0.999, 108294 Examples/sec
Step:900:0.03595047 0.997, 113474 Examples/sec
Step:910:0.02451019 0.997, 102980 Examples/sec
Step:920:0.020991776 0.999, 88507 Examples/sec
Step:930:0.02224905 1.0, 113585 Examples/sec
Step:940:0.021890618 0.995, 110424 Examples/sec
Step:950:0.033726 0.999, 100984 Examples/sec
Step:960:0.02129485 1.0, 91108 Examples/sec
Step:970:0.024996046 0.998, 103188 Examples/sec
Step:980:0.023362573 0.998, 101414 Examples/sec
Step:990:0.01828674 0.999, 110736 Examples/sec
Step:1000:0.020012554 0.999, 117903 Examples/sec
Done
('Testing Accuracy:', 0.9905)可以看到GPU都用上了

3张卡的结果是
- Step:1:2.179057 0.107, 670 Examples/sec
- Step:10:1.7062668 0.096, 141376 Examples/sec
- Step:20:1.2686766 0.778, 148170 Examples/sec
- Step:30:0.9272378 0.971, 148117 Examples/sec
- Step:40:0.65561247 0.968, 155900 Examples/sec
- Step:50:0.47599787 0.968, 142524 Examples/sec
- Step:60:0.36575985 0.98, 153030 Examples/sec
- Step:70:0.306964 0.982, 142038 Examples/sec
- Step:80:0.25127885 0.986, 145081 Examples/sec
- Step:90:0.22918189 0.99, 126748 Examples/sec
- Step:100:0.17915334 0.989, 151506 Examples/sec
- Step:110:0.16429098 0.993, 140456 Examples/sec
- Step:120:0.16801016 0.996, 152409 Examples/sec
- Step:130:0.13752642 0.99, 158496 Examples/sec
- Step:140:0.12512513 0.99, 129988 Examples/sec
- Step:150:0.11159173 0.99, 148199 Examples/sec
- Step:160:0.1310471 0.992, 141750 Examples/sec
- Step:170:0.11130922 0.987, 142639 Examples/sec
- Step:180:0.1002218 0.991, 143437 Examples/sec
- Step:190:0.09149876 0.991, 149760 Examples/sec
- Step:200:0.09371435 0.991, 131411 Examples/sec
- Step:210:0.078897856 0.996, 135117 Examples/sec
- Step:220:0.08131534 0.991, 144514 Examples/sec
- Step:230:0.07104218 0.995, 155241 Examples/sec
- Step:240:0.067408994 0.994, 137180 Examples/sec
- Step:250:0.064304866 0.995, 156731 Examples/sec
- Step:260:0.07375712 0.996, 158628 Examples/sec
- Step:270:0.055952944 0.992, 141589 Examples/sec
- Step:280:0.06003693 0.995, 141843 Examples/sec
- Step:290:0.051127683 0.997, 159388 Examples/sec
- Step:300:0.054927547 0.996, 146807 Examples/sec
- Step:310:0.061210938 0.996, 97232 Examples/sec
- Step:320:0.055554442 0.998, 139430 Examples/sec
- Step:330:0.05102199 0.996, 134631 Examples/sec
- Step:340:0.05122229 0.994, 160051 Examples/sec
- Step:350:0.051788285 0.996, 152409 Examples/sec
- Step:360:0.054135885 0.997, 154759 Examples/sec
- Step:370:0.04857871 1.0, 147189 Examples/sec
- Step:380:0.042754006 0.996, 157209 Examples/sec
- Step:390:0.05325425 0.996, 126875 Examples/sec
- Step:400:0.043767564 0.999, 120157 Examples/sec
- Step:410:0.047820356 0.998, 100016 Examples/sec
- Step:420:0.051720724 0.995, 144982 Examples/sec
- Step:430:0.043360747 0.997, 158319 Examples/sec
- Step:440:0.046220083 0.998, 152247 Examples/sec
- Step:450:0.037443012 0.995, 155151 Examples/sec
- Step:460:0.050876223 0.997, 143905 Examples/sec
- Step:470:0.032471355 0.994, 149866 Examples/sec
- Step:480:0.045263004 0.997, 140482 Examples/sec
- Step:490:0.034160487 0.995, 141570 Examples/sec
- Step:500:0.030636476 0.998, 153334 Examples/sec
- Step:510:0.045699067 0.996, 156739 Examples/sec
- Step:520:0.04088615 0.996, 148404 Examples/sec
- Step:530:0.03515271 0.996, 153562 Examples/sec
- Step:540:0.04923905 0.997, 149201 Examples/sec
- Step:550:0.036611143 0.999, 161986 Examples/sec
- Step:560:0.03948523 0.999, 153555 Examples/sec
- Step:570:0.03261486 1.0, 143280 Examples/sec
- Step:580:0.03132392 0.996, 147485 Examples/sec
- Step:590:0.028181665 0.999, 146192 Examples/sec
- Step:600:0.029216608 0.995, 139217 Examples/sec
- Step:610:0.03249147 1.0, 83259 Examples/sec
- Step:620:0.027980506 1.0, 149910 Examples/sec
- Step:630:0.03392176 0.998, 143637 Examples/sec
- Step:640:0.028756693 0.996, 153641 Examples/sec
- Step:650:0.028903412 0.998, 156755 Examples/sec
- Step:660:0.025848372 0.998, 147413 Examples/sec
- Step:670:0.025913578 0.999, 154043 Examples/sec
- Step:680:0.022729458 1.0, 142619 Examples/sec
- Step:690:0.024153437 1.0, 140713 Examples/sec
- Step:700:0.03487912 0.998, 140109 Examples/sec
- Step:710:0.022364754 1.0, 157761 Examples/sec
- Step:720:0.027861439 0.998, 149252 Examples/sec
- Step:730:0.03808964 0.995, 150950 Examples/sec
- Step:740:0.028235001 0.998, 109777 Examples/sec
- Step:750:0.032191362 0.996, 152431 Examples/sec
- Step:760:0.026349701 0.998, 143054 Examples/sec
- Step:770:0.028729456 0.998, 136668 Examples/sec
- Step:780:0.023419091 0.998, 146491 Examples/sec
- Step:790:0.02524747 0.999, 147123 Examples/sec
- Step:800:0.027681384 0.997, 153830 Examples/sec
- Step:810:0.028965648 0.995, 134126 Examples/sec
- Step:820:0.029119791 0.999, 164267 Examples/sec
- Step:830:0.025585957 0.998, 150867 Examples/sec
- Step:840:0.022538008 0.996, 144564 Examples/sec
- Step:850:0.020086333 1.0, 126722 Examples/sec
- Step:860:0.018601429 0.998, 148083 Examples/sec
- Step:870:0.022610024 0.999, 148215 Examples/sec
- Step:880:0.023980075 0.999, 142158 Examples/sec
- Step:890:0.021728482 1.0, 141817 Examples/sec
- Step:900:0.024781082 1.0, 131342 Examples/sec
- Step:910:0.020408696 1.0, 151883 Examples/sec
- Step:920:0.024134735 1.0, 149686 Examples/sec
- Step:930:0.021143986 0.997, 135287 Examples/sec
- Step:940:0.019966785 0.997, 166511 Examples/sec
- Step:950:0.020217327 1.0, 151224 Examples/sec
- Step:960:0.020376345 0.999, 158303 Examples/sec
- Step:970:0.021457171 1.0, 166639 Examples/sec
- Step:980:0.021513645 0.999, 134776 Examples/sec
- Step:990:0.023288745 0.999, 144921 Examples/sec
- Step:1000:0.019848049 1.0, 154942 Examples/sec
- Done
- ('Testing Accuracy:', 0.992)

