- 1Linux系统的 vmware 虚拟机扩展 磁盘容量_vmware 扩展linux磁盘容量
- 2android使用webview上传文件(支持相册和拍照)_android webview 支持打开系统相册和相机并上传文件到网页
- 3SpringBoot-读取自定义配置遇到的一些问题_@configurationproperties获取yml配置路径不对
- 4emqx 配置wss_wss 连接emqx
- 5过年了,尽情地享受《幻兽帕鲁》吧!
- 6NAT相关概念_双向nat
- 7mysql闭自动提交功能_MySQL控制(关闭、打开)自动提交功能
- 8利用shell简单监控网络设备的接口状态发出告警
- 9win10安装软件出现2502的解决办法_win10epic安装错误2502怎么办
- 10阿里巴巴的第二代通义千问可能即将发布:Qwen2相关信息已经提交HuggingFace官方的transformers库
深度学习实战项目(一)-基于cnn和opencv的车牌号识别_opencv 车牌识别 开源
赞
踩
深度学习实战项目(一)-基于cnn和opencv的车牌号识别
网上大部分是关于tensorflow,使用pytorch的比较少,本文也在之前大佬写的代码的基础上,进行了数据集的完善,和代码的优化,效果可比之前的pytorch版本好一点。
数据集
数据集来自github开源的字符数据集:

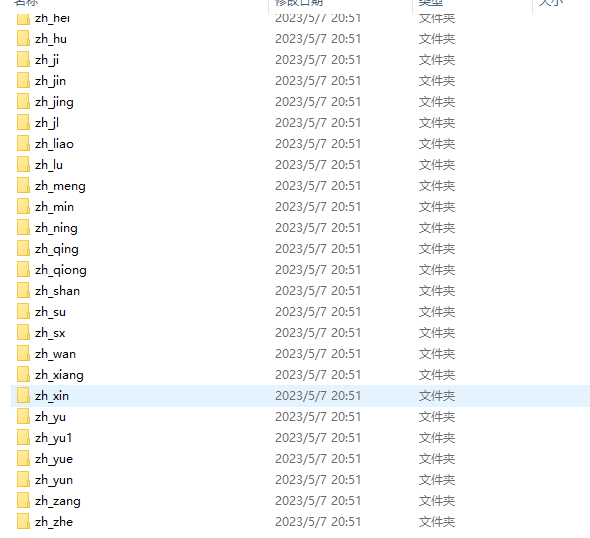
数据集有:0-9,26个字母减去I和O,还有中文字,这里可以看看几张图片:

opencv提取车牌字符
网上开源的方法都差不多,主要分为以下几个步骤:
1.图像预处理
(1)加载原始图片
(2)RGB图片转灰度图:减少数据量
(3)均值模糊:柔化一些小的噪声点
(4)sobel获取垂直边缘:因为车牌垂直边缘比较多
(5)原始图片从RGB转HSV:车牌背景色一般是蓝色或黄色
(6)从sobel处理后的图片找到蓝色或黄色区域:从HSV中取出蓝色、黄色区域,和sobel处理后的图片相乘
(7)二值化:最大类间方差法
(8)闭运算:将车牌垂直的边缘连成一个整体,注意核的尺寸
2.车牌定位
(1)获取轮廓
(2)求得轮廓外接矩形
(3)通过外接矩形的长、宽、长宽比三个值排除一部分非车牌的轮廓
(4)通过背景色进一步排除非车牌区域
这里主要用到漫水填充算法(类似PS的魔术棒),通过在矩形区域生成种子点,种子点的颜色必须是蓝色或黄色,在填充后的掩模上绘制外接矩形,再依次判断这个外接矩形的尺寸是否符合车牌要求,最后再把矩形做仿射变换校准位置。做漫水填充的目的有两个,第一个是预处理的时候车牌轮廓可能有残缺,做完漫水填充后可以把剩余的部分补全,第二个目的是进一步排除非车牌区域。
3.字符分割
水平投影方法:将二值化的车牌图片水平投影到Y轴,得到连续投影最长的一段作为字符区域,因为车牌四周有白色的边缘,这里可以把水平方向上的连续白线过滤掉。
CNN网络搭建与训练
网络设计:
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(3, 64, kernel_size=3, padding=1) self.conv2 = torch.nn.Conv2d(64, 64, kernel_size=3, padding=1) self.conv3 = torch.nn.Conv2d(64, 128, kernel_size=3, padding=1) self.conv4 = torch.nn.Conv2d(128, 128, kernel_size=3, padding=1) self.conv5 = torch.nn.Conv2d(128, 256, kernel_size=3, padding=1) self.conv6 = torch.nn.Conv2d(256, 256, kernel_size=3, padding=1) self.maxpooling = torch.nn.MaxPool2d(2) self.avgpool = torch.nn.AvgPool2d(2) self.globalavgpool = torch.nn.AvgPool2d((5, 5)) self.bn1 = torch.nn.BatchNorm2d(64) self.bn2 = torch.nn.BatchNorm2d(128) self.bn3 = torch.nn.BatchNorm2d(256) self.dropout50 = torch.nn.Dropout(0.5) self.dropout10 = torch.nn.Dropout(0.1) self.fc1 = torch.nn.Linear(256, 67) def forward(self, x): batch_size = x.size(0) x = self.bn1(F.relu(self.conv1(x))) x = self.bn1(F.relu(self.conv2(x))) x = self.maxpooling(x) x = self.dropout10(x) x = self.bn2(F.relu(self.conv3(x))) x = self.bn2(F.relu(self.conv4(x))) x = self.maxpooling(x) x = self.dropout10(x) x = self.bn3(F.relu(self.conv5(x))) x = self.bn3(F.relu(self.conv6(x))) # print(x.size()) x = self.globalavgpool(x) # print(x.size()) x = self.dropout50(x) x = x.view(batch_size, -1) x = self.fc1(x) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
数据预处理:
transform = transforms.Compose(
[
transforms.Resize(size=(20, 20)), # 原本就是 32x40 不需要修改尺寸
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
# transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
]
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
训练函数:
model = Net() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") model.to(device) criterion = torch.nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=LR) def train(epoch, loss_list): running_loss = 0.0 for batch_idx, data in enumerate(new_train_loader, 0): inputs, target = data[0], data[1] inputs, target = inputs.to(device), target.to(device) optimizer.zero_grad() outputs = model(inputs) # print(outputs.shape, target.shape) # print(outputs, target) loss = criterion(outputs, target) loss.backward() optimizer.step() loss_list.append(loss.item()) running_loss += loss.item() if batch_idx % 10 == 9: print(f'[{time_since(start)}] Epoch {epoch}', end='') print('[%d, %5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 10)) running_loss = 0.0 return loss_list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
结果
1.测试集准确率:

2.识别结果:

3.训练损失图
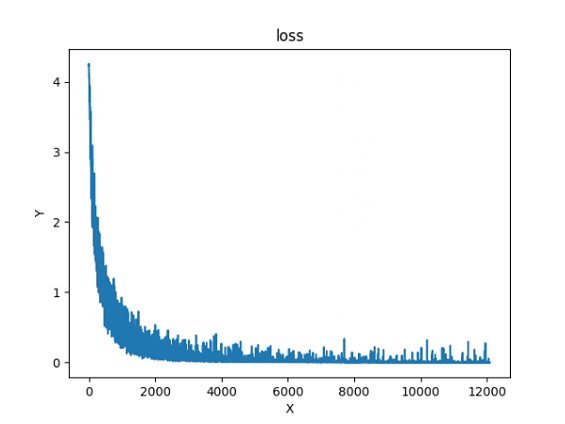
注意
由于是使用传统方法进行车牌提取,容易受到图片环境(颜色,位置,倾斜度等)的影响,所以有些图片会出现提取不到车牌的情况,会导致识别不到车牌。
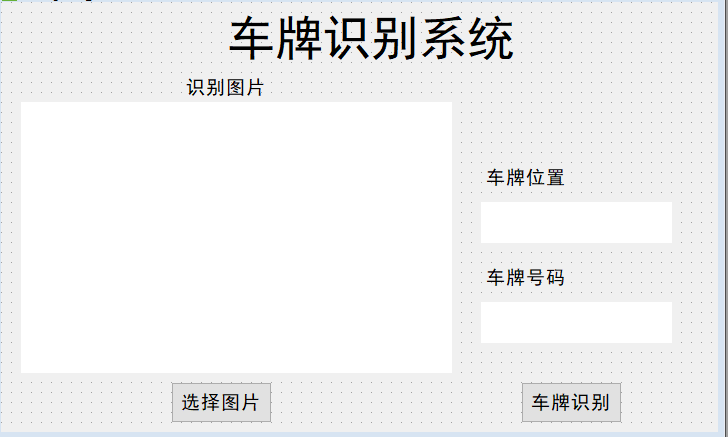
tensorflow版本的界面
在tensorflow版本中,有分类是否是车牌图片的模型,因此提取车牌的成功概率比较大,因此也做了以下界面: