
- 1Polardbx环境搭建_polardbmysql docker
- 2lombok离线安装_lombock disk
- 3Android studio中VideoView播放不了在线视频出现 java.io.FileNotFoundException: No content provider_videoview java.io.filenotfoundexception: no conten
- 4数据结构:6、栈
- 5【框架学习 | 第五篇】SpringMVC(常用注解、获取请求参数、域对象共享数据、拦截器、异常处理、上传/下载文件)
- 6中科大软院linux _la3--基于VS Code的Linux内核调试环境搭建及start_kernel跟踪分析_中科大给linux内核贡献代码
- 7【从零单排Golang】第十四话:使用rate和ratelimit实现限流限速_uber/ratelimit 使用demo
- 8最新基于 R 语言 lavaan 结构方程模型(SEM)实践技术应用
- 9超大量数据,前端树形结构展示_vue-easy-tree
- 10RedisTemplate通用工具类RedisUtils_redistemplateutils
STL标准库与泛型编程(侯捷)笔记4_侯捷stl,hashmap
赞
踩
STL标准库与泛型编程(侯捷)
本文是学习笔记,仅供个人学习使用。如有侵权,请联系删除。
参考链接
Github:STL源码剖析中源码 https://github.com/SilverMaple/STLSourceCodeNote/tree/master
Github:课程ppt和源码 https://github.com/ZachL1/Bilibili-plus
介绍
介绍基于红黑树和hashtable的关联式容器底层原理
关联式容器的底层实现主要分为两类:基于红黑树的实现和基于哈希表(hashtable)的实现。具体地,set 系列和 map 系列的关联式容器在底层实现上有所不同。
-
基于红黑树的实现:
set: 无序集合,存储不重复的元素。元素在集合中按照键值的升序顺序存储,内部通常采用红黑树作为底层数据结构。map: 键值对的有序映射,存储不重复的键值对。键值对按照键的升序顺序存储,内部通常采用红黑树作为底层数据结构。multiset: 无序多重集合,存储允许重复的元素。元素在集合中按照键值的升序顺序存储,内部通常采用红黑树作为底层数据结构。multimap: 键值对的有序多重映射,存储允许多个相同键的键值对。键值对按照键的升序顺序存储,内部通常采用红黑树作为底层数据结构。
-
基于哈希表的实现:
unordered_set: 无序集合,存储不重复的元素。元素在集合中无序存储,内部通常采用哈希表作为底层数据结构。unordered_map: 键值对的无序映射,存储不重复的键值对。键值对无序存储,内部通常采用哈希表作为底层数据结构。unordered_multiset: 无序多重集合,存储允许重复的元素。元素在集合中无序存储,内部通常采用哈希表作为底层数据结构。unordered_multimap: 键值对的无序多重映射,存储允许多个相同键的键值对。键值对无序存储,内部通常采用哈希表作为底层数据结构。
这两种底层实现各有优劣,选择基于红黑树还是哈希表的实现取决于具体的使用场景和需求。红黑树提供了有序性,适合需要有序查找的场合;而哈希表则提供了 O(1) 时间复杂度的平均查找和插入操作,适合需要高效的插入和查找的场合。
20 RB tree 深度探索
红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它在插入和删除操作时通过一系列的颜色变换和旋转来保持树的平衡。这种平衡性质确保了红黑树的查找、插入和删除等基本操作在最坏情况下的时间复杂度为O(log n)。
以下是红黑树的一些关键性质:
-
节点颜色: 每个节点都带有颜色,要么是红色,要么是黑色。
-
根节点和叶子节点: 根节点是黑色的,叶子节点(通常为空节点或哨兵节点)也是黑色的。
-
相邻节点颜色: 不能有两个相邻的红色节点,即红色节点的父节点和子节点都不能是红色的。
-
任意路径黑色节点数相同: 从任意节点到其所有后代叶子节点的简单路径上,经过的黑色节点数目相同。
这些性质保证了红黑树的平衡,使得最长路径不会超过最短路径的两倍,从而保证了对数时间的查找、插入和删除操作。
红黑树通常用于实现关联容器,如C++标准模板库(STL)中的std::map和std::set。在这些容器中,红黑树提供了高效的搜索、插入和删除操作,同时保持树的平衡,确保了良好的性能。
红黑树的平衡性是通过一系列旋转和颜色调整来实现的。这些操作的设计确保了在每次插入或删除后,红黑树的性质仍然得以保持。虽然红黑树的维护可能相对复杂,但由于其高效的性能和保持平衡的特性,它在许多应用中被广泛使用。

rb_tree有5个模板参数,其中key表示key,value表示key和data的整体。展示一下5个模板参数的作用
注意这里的模板参数名称和GNU C++2.9版本名字稍有不同,但是意思是一样的。
// Class rb_tree is not part of the C++ standard. It is provided for
// compatibility with the HP STL.
template <class _Key, class _Value, class _KeyOfValue, class _Compare,
class _Alloc = __STL_DEFAULT_ALLOCATOR(_Value) >
struct rb_tree : public _Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc>
{
typedef _Rb_tree<_Key, _Value, _KeyOfValue, _Compare, _Alloc> _Base;
typedef typename _Base::allocator_type allocator_type;
rb_tree(const _Compare& __comp = _Compare(),
const allocator_type& __a = allocator_type())
: _Base(__comp, __a) {}
~rb_tree() {}
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在这段代码中,模板参数 _Key、_Value、_KeyOfValue、_Compare、_Alloc 分别用于定义一个红黑树的模板类 rb_tree。以下是这五个模板参数的作用:
-
_Key:- 表示红黑树节点的键(key)的类型。这是用来比较和排序节点的关键信息。
-
_Value:- 表示红黑树节点存储的值(value,这里value表示key和data的整体)的类型。每个节点包含一个键和一个值(data)。
-
_KeyOfValue:- 是一个函数对象,用于从节点值中提取键。在红黑树中,节点的键是用来进行比较和排序的。通过
_KeyOfValue,可以从节点的值中提取键,以确保正确的比较和排序。
- 是一个函数对象,用于从节点值中提取键。在红黑树中,节点的键是用来进行比较和排序的。通过
-
_Compare:- 是一个比较函数对象,用于定义节点之间的顺序关系。它用来比较节点的键值,从而实现红黑树的有序性。
-
_Alloc:- 是一个分配器类型,用于管理红黑树节点的内存分配和释放。默认情况下,使用
_Value类型的默认分配器__STL_DEFAULT_ALLOCATOR(_Value)。
- 是一个分配器类型,用于管理红黑树节点的内存分配和释放。默认情况下,使用
这些模板参数允许用户在使用红黑树时灵活地指定节点的键值类型、存储的值类型、键值提取方式、比较方式以及内存分配器。通过使用模板参数,可以实现通用性,使红黑树适用于各种不同的键值类型和使用场景。在实例化 rb_tree 类时,用户可以根据实际需求提供适当的模板参数。
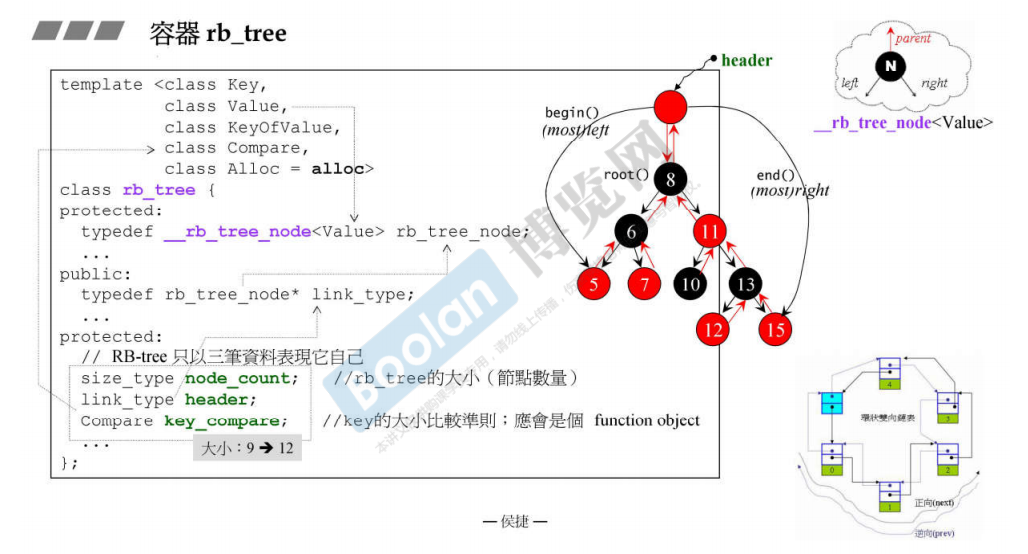
下图中可以看到红黑树这个类rb_tree中的数据有三个:node_count, header, key_compare
template<class Key, class Value, class KeyOfValue, class Compare, class Alloc = alloc>
class rb_tree {
protected:
typedef __rb_tree_node<Value> rb_tree_node;
...
public:
typedef rb_tree_node* link_type;
...
protected:
size_type node_count; // rb_tree的大小(节点数量)
link_type header;
Compare key_compare; // key的大小比较准则
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
下面是对成员变量header的介绍:
在这段代码中,header 是红黑树中的一个成员变量,它的类型是 link_type,而 link_type 又被定义为 rb_tree_node*。这里的 header 通常用来表示红黑树的头部节点。
红黑树是一种二叉搜索树,它的节点被分为红色和黑色,并且有一些平衡性质。为了简化算法的实现,通常在红黑树的根节点(root)上添加一个额外的节点,称为头部节点。这个头部节点不包含实际的数据,其左子节点指向红黑树的最小节点,右子节点指向红黑树的最大节点,父节点为空(或者指向红黑树的根节点),并且颜色为黑色。
在你的代码中,header 就是用来表示这个头部节点的指针。它提供了方便的访问红黑树的最小、最大节点等信息,同时也使得算法实现更加简洁,因为不需要特殊处理根节点的情况。
简而言之,header 是红黑树的一个关键节点,它用于简化算法实现,提供对树的一些特殊节点(如最小节点、最大节点)的直接访问。
下面代码是摘录自源代码,并且进行了注释:
struct _Rb_tree_node_base { typedef _Rb_tree_Color_type _Color_type; // 节点颜色类型 // 基本指针类型,指向节点的父节点、左子节点和右子节点 typedef _Rb_tree_node_base* _Base_ptr; _Color_type _M_color; // 节点颜色 _Base_ptr _M_parent; // 指向父节点的指针 _Base_ptr _M_left; // 指向左子节点的指针 _Base_ptr _M_right; // 指向右子节点的指针 // 静态成员函数,返回以给定节点为根的子树的最小节点 static _Base_ptr _S_minimum(_Base_ptr __x) { while (__x->_M_left != 0) __x = __x->_M_left; return __x; } // 静态成员函数,返回以给定节点为根的子树的最大节点 static _Base_ptr _S_maximum(_Base_ptr __x) { while (__x->_M_right != 0) __x = __x->_M_right; return __x; } }; // 带有值域的红黑树节点结构,继承自基本节点结构 template <class _Value> struct _Rb_tree_node : public _Rb_tree_node_base { // 链接类型,指向具有相同值类型的节点 typedef _Rb_tree_node<_Value>* _Link_type; _Value _M_value_field; // 节点的值域 };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
红黑树的使用:输入传入5个模板参数,由于最后一个模板参数有默认值,所以可以不传,只传4个参数。
cout << "sizeof(_Rb_tree<...>)= " << sizeof(_Rb_tree<int,int,_Identity<int>,less<int>>) << endl; //24
- 1
这里第四个参数为std里面默认的less比较函数对象,我们进入源码看一下具体实现细节:里面重载了operator()
template<typename _Tp>
struct less : public binary_function<_Tp, _Tp, bool>
{
_GLIBCXX14_CONSTEXPR
bool
operator()(const _Tp& __x, const _Tp& __y) const
{ return __x < __y; }
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里_Identity的作用:
在C++中,_Identity 通常是一个简单的函数对象,也被称为标识函数对象或身份函数对象。其作用是返回传入的值本身,即 operator() 返回其参数。
对应下图中的identity
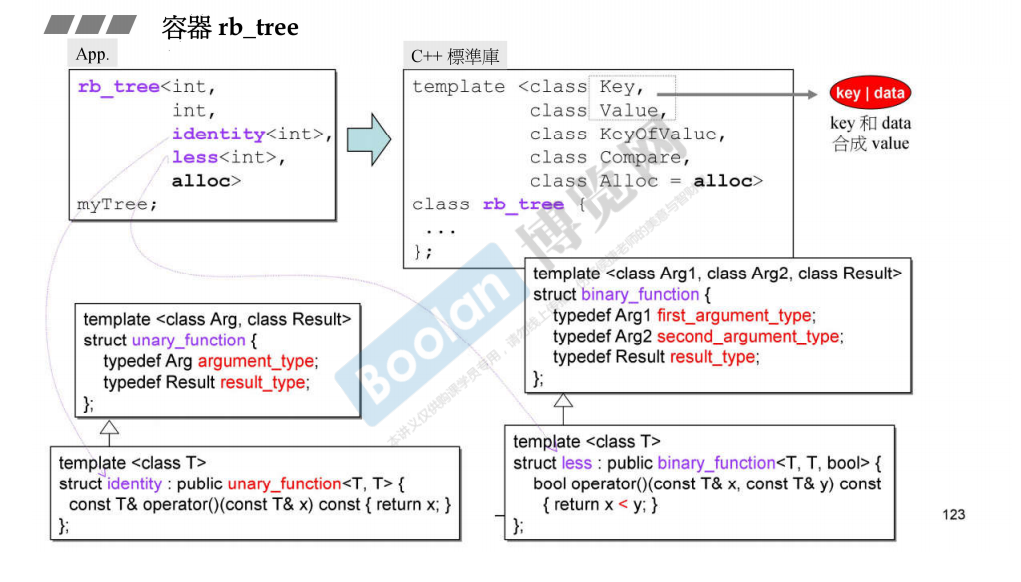
上图中identity的作用
下面是直接可运行的测试红黑树的代码,可以复制粘贴使用:
// 修改自侯捷的代码 #include <set> #include <functional> #include <iostream> using namespace std; namespace jj31 { void test_Rb_tree() { //G2.9 vs. G4.9 : //rb_tree => _Rb_tree, //identity<> => _Identity<> //insert_unique() => _M_insert_unique() //insert_equal() => _M_insert_equal() cout << "\ntest_Rb_tree().......... \n"; _Rb_tree<int, int, _Identity<int>, less<int>> itree; cout << itree.empty() << endl; //1 cout << itree.size() << endl; //0 itree._M_insert_unique(3); itree._M_insert_unique(8); itree._M_insert_unique(5); itree._M_insert_unique(9); itree._M_insert_unique(13); itree._M_insert_unique(5); //no effect, since using insert_unique(). cout << itree.empty() << endl; //0 cout << itree.size() << endl; //5 cout << itree.count(5) << endl; //1 itree._M_insert_equal(5); itree._M_insert_equal(5); cout << itree.size() << endl; //7, since using insert_equal(). cout << itree.count(5) << endl; //3 } } int main(int argc, char** argv) { jj31::test_Rb_tree(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
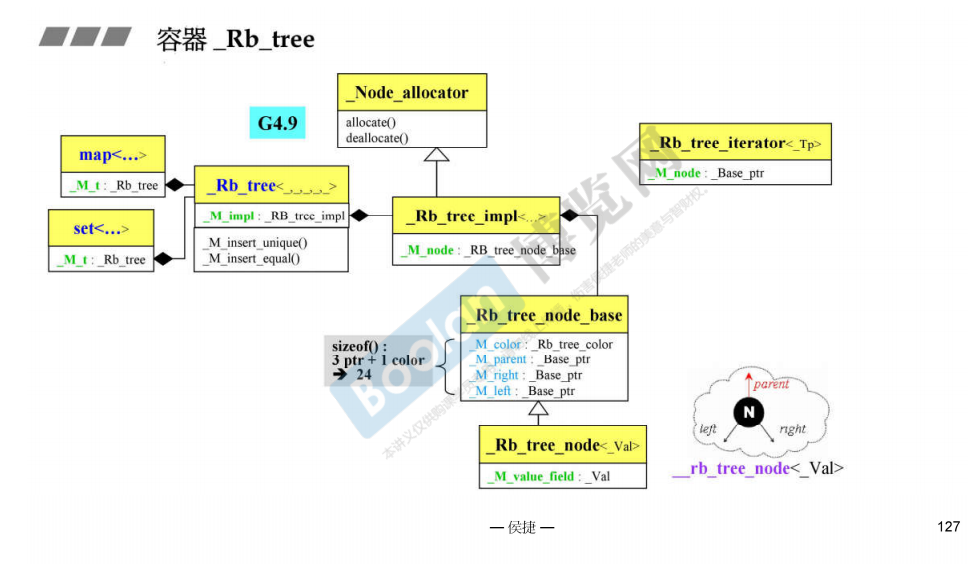
_Rb_tree容器的类结构
设计模式中的handle和body,把接口和实现分离
类的组织结构如下:map和set 它俩has a rb_tree,rb_tree 它has a rb_tree_impl, 它has a rb_tree_node_base。这里的has a表示composition组合(下图中的黑色菱形)
补充红黑树的右旋,源代码如下:
// 红黑树右旋操作 inline void _Rb_tree_rotate_right(_Rb_tree_node_base* __x, _Rb_tree_node_base*& __root) { // 将 __x 的左子节点设为 __y _Rb_tree_node_base* __y = __x->_M_left; // 将 __y 的右子节点设为 __x 的左子节点 __x->_M_left = __y->_M_right; // 如果 __y 的右子节点非空,则将其右子节点的父节点设为 __x if (__y->_M_right != 0) __y->_M_right->_M_parent = __x; // 将 __y 的父节点设为 __x 的父节点 __y->_M_parent = __x->_M_parent; // 如果 __x 是根节点,则将 __y 设为新的根节点 if (__x == __root) __root = __y; // 如果 __x 是其父节点的右子节点,则将 __y 设为 __x 父节点的右子节点 else if (__x == __x->_M_parent->_M_right) __x->_M_parent->_M_right = __y; // 如果 __x 是其父节点的左子节点,则将 __y 设为 __x 父节点的左子节点 else __x->_M_parent->_M_left = __y; // 将 __x 设为 __y 的右子节点 __y->_M_right = __x; // 将 __y 设为 __x 的父节点 __x->_M_parent = __y; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
还有_Rb_tree_rebalance,_Rb_tree_rebalance_for_erase等具体实现,这里不列举。
21 set、multiset深度探索
容器set和multiset
std::set 和 std::multiset 是 C++ 标准库中的关联容器,它们都基于红黑树实现。它们的主要区别在于元素的唯一性:
-
std::set:
- 所有元素的键(key)都是唯一的,即集合中不允许存在相同的元素。
- 插入相同的元素会被容器拒绝(被忽略)。
-
std::multiset:
- 允许集合中存在相同的元素,即元素的键可以重复。
- 插入相同的元素是允许的,所有相同的元素都被插入到容器中。
下面是一个简单的示例来说明两者之间的区别:
#include <iostream> #include <set> #include <unordered_set> int main() { // 使用 std::set std::set<int> uniqueSet; uniqueSet.insert(1); uniqueSet.insert(2); uniqueSet.insert(1); // 重复元素,被忽略 std::cout << "std::set elements: "; for (const auto& elem : uniqueSet) { std::cout << elem << " "; } std::cout << "\n"; // 使用 std::multiset std::multiset<int> multiSet; multiSet.insert(1); multiSet.insert(2); multiSet.insert(1); // 允许重复元素 std::cout << "std::multiset elements: "; for (const auto& elem : multiSet) { std::cout << elem << " "; } std::cout << "\n"; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
上述代码中,std::set 中的重复元素被忽略,而 std::multiset 中允许存在重复元素。选择使用哪一个取决于你的需求,如果需要保持元素的唯一性,使用 std::set;如果允许重复元素,使用 std::multiset。
这里实现的原理是什么呢?
set元素的key必须唯一,因为它insert()调用的是红黑树的insert_unique();
multiset元素的key可以重复,因为它insert()调用的是红黑树的insert_equal()。

set和multiset对迭代器的支持:
std::set 和 std::multiset 都支持迭代器,通过迭代器可以遍历容器中的元素。以下是一个简单的示例,演示了如何使用迭代器遍历这两个容器:
#include <iostream> #include <set> int main() { // 使用 std::set std::set<int> uniqueSet; uniqueSet.insert(1); uniqueSet.insert(2); uniqueSet.insert(3); // 使用迭代器遍历 std::set std::cout << "std::set elements: "; for (auto it = uniqueSet.begin(); it != uniqueSet.end(); ++it) { std::cout << *it << " "; } std::cout << "\n"; // 使用 std::multiset std::multiset<int> multiSet; multiSet.insert(1); multiSet.insert(2); multiSet.insert(1); // 使用迭代器遍历 std::multiset std::cout << "std::multiset elements: "; for (auto it = multiSet.begin(); it != multiSet.end(); ++it) { std::cout << *it << " "; } std::cout << "\n"; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
上述代码中,使用 begin() 函数获取容器的起始迭代器,使用 end() 函数获取容器的结束迭代器,然后通过迭代器遍历容器中的元素。注意,std::multiset 中存在重复元素,因此迭代器会遍历所有相同的元素。
容器set
有三个模板参数,
template <class _Key, class _Compare, class _Alloc> class set { public: // typedefs: typedef _Key key_type; typedef _Key value_type; typedef _Compare key_compare; typedef _Compare value_compare; private: typedef _Rb_tree<key_type, value_type, _Identity<value_type>, key_compare, _Alloc> _Rep_type; // 红黑树 _Rep_type _M_t; // red-black tree representing set public: typedef typename _Rep_type::const_pointer pointer; typedef typename _Rep_type::const_pointer const_pointer; typedef typename _Rep_type::const_reference reference; typedef typename _Rep_type::const_reference const_reference; typedef typename _Rep_type::const_iterator iterator; // 这里iterator是const iterator,这种迭代器不允许改内容 typedef typename _Rep_type::const_iterator const_iterator; typedef typename _Rep_type::const_reverse_iterator reverse_iterator; typedef typename _Rep_type::const_reverse_iterator const_reverse_iterator; typedef typename _Rep_type::size_type size_type; typedef typename _Rep_type::difference_type difference_type; typedef typename _Rep_type::allocator_type allocator_type; ... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27

22 map、multimap深度探索
std::map 和 std::multimap 是 C++ 标准库中的关联容器,它们都基于红黑树实现,用于存储键值对。它们的主要区别在于元素的唯一性:
-
std::map:
- 所有元素的键(key)都是唯一的,即地图中不允许存在相同的键。
- 插入相同的键会导致已存在的元素被替换。
-
std::multimap:
- 允许存在相同的键,即键可以重复。
- 插入相同的键是允许的,所有相同的键都会被插入到容器中。
以下是一个简单的示例,说明两者之间的区别:
#include <iostream> #include <map> #include <unordered_map> int main() { // 使用 std::map std::map<int, std::string> uniqueMap; uniqueMap[1] = "One"; uniqueMap[2] = "Two"; uniqueMap[1] = "New One"; // 替换已存在的键值对 std::cout << "std::map elements: "; for (const auto& elem : uniqueMap) { std::cout << "{" << elem.first << ": " << elem.second << "} "; } std::cout << "\n"; // 使用 std::multimap std::multimap<int, std::string> multiMap; multiMap.insert({1, "One"}); multiMap.insert({2, "Two"}); multiMap.insert({1, "Another One"}); // 允许重复键 std::cout << "std::multimap elements: "; for (const auto& elem : multiMap) { std::cout << "{" << elem.first << ": " << elem.second << "} "; } std::cout << "\n"; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
在上述代码中,std::map 中的重复键会导致已存在的元素被替换,而 std::multimap 中允许存在相同的键,插入相同的键会添加新的键值对。选择使用哪一个取决于你的需求,如果需要保持键的唯一性,使用 std::map;如果允许重复键,使用 std::multimap。

容器map
set不允许改变元素,是通过把迭代器指定为const iterator来做的;map不需要修改key,是通过指定key为 const类型来做的。
template <class _Key, class _Tp, class _Compare, class _Alloc> class map { public: // typedefs: typedef _Key key_type; typedef _Tp data_type; typedef _Tp mapped_type; typedef pair<const _Key, _Tp> value_type; // 这里_Key被指定为const,不能被修改 typedef _Compare key_compare; private: typedef _Rb_tree<key_type, value_type, _Select1st<value_type>, key_compare, _Alloc> _Rep_type; _Rep_type _M_t; // red-black tree representing map public: typedef typename _Rep_type::pointer pointer; typedef typename _Rep_type::const_pointer const_pointer; typedef typename _Rep_type::reference reference; typedef typename _Rep_type::const_reference const_reference; typedef typename _Rep_type::iterator iterator; typedef typename _Rep_type::const_iterator const_iterator; typedef typename _Rep_type::reverse_iterator reverse_iterator; typedef typename _Rep_type::const_reverse_iterator const_reverse_iterator;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
下面的select1st取出key
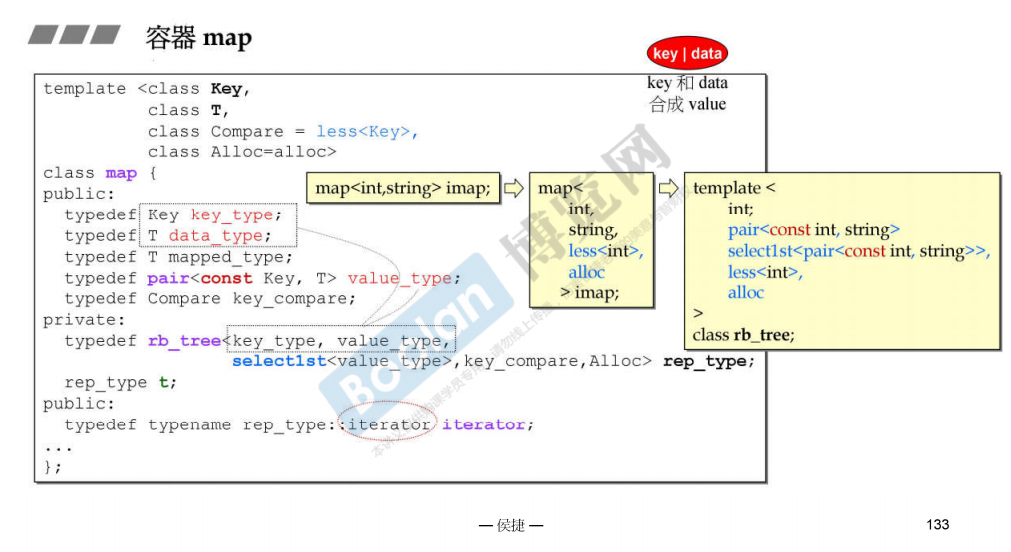
下图展示了select1st的实现,它是一个functor,函数对象。功能是取出pair中的第一个元素

multimap不允许使用[]插入,但是map允许使用[]插入
这句话指的是在 C++ 的 std::map 和 std::multimap 中使用 operator[] 进行元素插入的差异。
-
std::map:对于
std::map,使用operator[]可以进行元素的插入。如果键不存在于map中,operator[]会插入一个具有给定键的新元素,并返回对应的值的引用。如果键已经存在,它将返回已存在键的值的引用,不会插入新元素。如果需要插入或修改元素,operator[]是一种方便的方式。#include <iostream> #include <map> int main() { std::map<int, std::string> myMap; // 使用 operator[] 插入元素 myMap[1] = "One"; myMap[2] = "Two"; // 输出 map 的元素 for (const auto& elem : myMap) { std::cout << "{" << elem.first << ": " << elem.second << "} "; } std::cout << "\n"; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
-
std::multimap:相反,对于
std::multimap,operator[]不允许进行元素的插入。这是因为multimap允许存在相同的键,而operator[]无法确定是应该插入新元素还是返回已存在键的值。#include <iostream> #include <map> int main() { std::multimap<int, std::string> myMultiMap; // 以下行将导致编译错误,因为 operator[] 不允许插入新元素 // myMultiMap[1] = "One"; // myMultiMap[2] = "Two"; // 可以使用 insert 插入元素 myMultiMap.insert({1, "One"}); myMultiMap.insert({2, "Two"}); myMultiMap.insert({1, "Another One"}); // 允许插入相同的键 // 输出 multimap 的元素 for (const auto& elem : myMultiMap) { std::cout << "{" << elem.first << ": " << elem.second << "} "; } std::cout << "\n"; return 0; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
总的来说,使用 operator[] 进行插入操作在 std::map 中是允许的,但在 std::multimap 中是不允许的。在 std::multimap 中插入元素通常使用 insert 函数。
map中的[] 操作符的实现如下,里面先调用lower_bound进行查找,然后再insert元素

23 hashtable深度探索(上)
容器hashtable
容器 hashtable 指的是哈希表,它是一种常见的数据结构,用于实现关联容器,如 C++ 标准库中的 std::unordered_map 和 std::unordered_set。
哈希表的基本思想是将键(key)通过哈希函数映射到一个固定范围的索引,然后在该索引处存储对应的值(或者链表、二叉树等数据结构)。这样可以在期望的常数时间内(平均情况下)进行插入、删除和查找操作。
在 C++ 标准库中,std::unordered_map 是使用哈希表实现的关联容器,用于存储键值对。std::unordered_set 是存储唯一元素的集合,同样使用哈希表实现。这些容器允许在平均情况下以常数时间执行插入、删除和查找操作,但在最坏情况下可能会有更高的时间复杂度,具体取决于哈希函数的质量和冲突处理的方法。
哈希表的实现通常涉及以下关键点:
-
哈希函数(Hash Function): 将键映射到索引的函数。良好的哈希函数应该尽可能均匀地分布键,以减少冲突的发生。
-
冲突处理(Collision Resolution): 当两个不同的键被映射到相同的索引时,发生冲突。冲突处理的方法包括链地址法、开放地址法等。
-
负载因子(Load Factor): 哈希表中实际元素个数与桶的数量之比。负载因子的选择会影响哈希表的性能,通常需要在保持高效性能和减少冲突之间进行权衡。
哈希表是一种高效的数据结构,特别适用于需要频繁插入、删除和查找操作的场景。
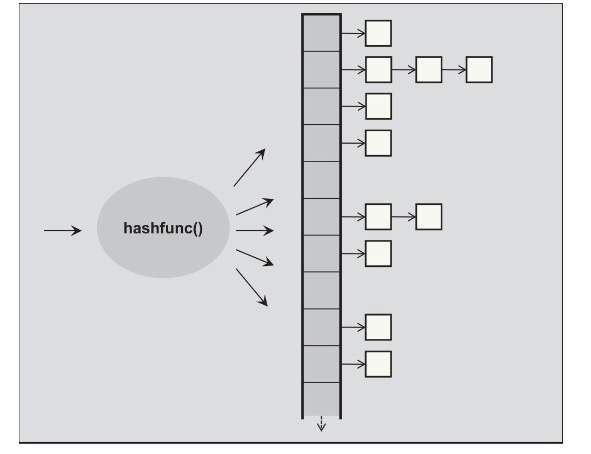
在哈希表中,桶(bucket)和链表(linked list)是两个重要的概念,它们用于解决哈希冲突。
-
桶(Bucket):
- 定义: 桶是哈希表中的一个存储位置,通常是一个数组,每个元素称为一个桶。
- 作用: 哈希表中的每个桶对应一个哈希值,桶的数量通常是一个固定的值,决定了哈希表的大小。元素通过哈希函数映射到具体的桶。
-
链表(Linked List):
- 定义: 链表是一种数据结构,可以存储多个元素,每个元素包含一个值和一个指向下一个元素的指针。
- 作用: 当多个键被映射到同一个桶时,就会发生哈希冲突。为了解决冲突,每个桶可以使用链表来存储具有相同哈希值的键值对。这样,当发生冲突时,新的元素可以被添加到该桶对应的链表中。
在哈希表中,使用链表来处理冲突的方法被称为“链地址法”(Chaining)。具体来说,每个桶维护一个链表,当冲突发生时,新元素会被添加到链表中。如果多个元素映射到同一个桶,它们就形成了一个链表。这样,相同哈希值的元素可以在同一个桶中找到。
在 C++ 标准库的 std::unordered_map 和 std::unordered_set 中,通常就是通过链地址法来处理哈希冲突的。如果链表变得太长,可能会导致性能下降,因此一些实现还会在链表变得过长时转换为更复杂的数据结构,比如红黑树,以提高查找效率。这样的优化称为“链表到树的转化”(List to Tree Conversion)或“桶的再哈希”(Bucket Rehashing)。
下图中,上方的hashtable中桶的个数为53(编号为0到52),然后当桶放完之后,比如达到54个元素之后,就要扩充桶的数量。
Rehashing(再哈希) 是哈希表中的一个重要操作,它涉及调整哈希表的大小,通常是为了保持哈希表的负载因子在一个合适的范围内。负载因子是指哈希表中实际元素个数与桶的数量之比。
当负载因子过大时,哈希冲突的概率会增加,从而导致查找、插入和删除操作的效率下降。为了避免这种情况,当负载因子达到某个阈值时,哈希表就会执行 rehashing 操作。
Rehashing 的主要步骤包括:
-
创建新的桶数组: 首先,创建一个新的桶数组,通常将桶的数量调整为原来的两倍(或其他倍数)。
-
遍历旧桶数组: 将原有的键值对重新映射到新的桶数组中。这通常涉及到重新计算键的哈希值,并将键值对插入到新的桶中。由于桶的数量发生了改变,新的哈希函数可能也会不同。
-
释放旧桶数组: 释放原来的桶数组的内存空间。
Rehashing 的好处包括:
-
维护负载因子: 通过调整桶的数量,可以保持哈希表的负载因子在一个适当的范围内,提高哈希表的性能。
-
减少哈希冲突: 重新分配桶的位置,有助于减少键值对之间的哈希冲突。
-
适应变化: 当元素的数量发生变化时,rehashing 使哈希表能够适应新的负载情况,从而保持高效性能。
在 C++ 标准库中,std::unordered_map 和 std::unordered_set 等容器在内部通常会自动执行 rehashing 操作,以确保哈希表的性能。 Rehashing 的触发条件和实现方式可能因不同的实现而异,但通常是在负载因子超过某个阈值时触发的。
下面是常用的桶的大小的值
// Note: assumes long is at least 32 bits.
enum { __stl_num_primes = 28 };
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

下面是从hashtable的源代码中摘录的代码
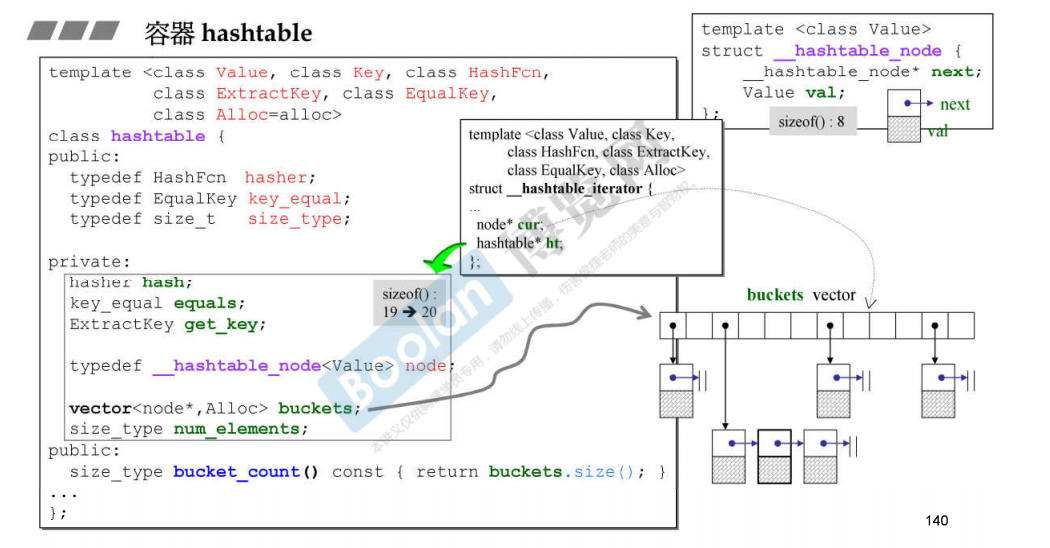
template <class _Val, class _Key, class _HashFcn, class _ExtractKey, class _EqualKey, class _Alloc> class hashtable { public: typedef _Key key_type; typedef _Val value_type; typedef _HashFcn hasher; typedef _EqualKey key_equal; typedef size_t size_type; typedef ptrdiff_t difference_type; typedef value_type* pointer; typedef const value_type* const_pointer; typedef value_type& reference; typedef const value_type& const_reference; hasher hash_funct() const { return _M_hash; } key_equal key_eq() const { return _M_equals; } private: typedef _Hashtable_node<_Val> _Node; private: // 3个函数对象 hasher _M_hash; key_equal _M_equals; _ExtractKey _M_get_key; //buckets桶的实现是用的vector vector<_Node*,_Alloc> _M_buckets; size_type _M_num_elements; // 记录元素个数 ... } template <class _Val> struct _Hashtable_node // 上面所说每个桶所串起来的链表节点 { _Hashtable_node* _M_next; _Val _M_val; };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
对六个模板参数的解释:
-
_Val:- 含义: 表示哈希表中存储的值的类型。
- 用途: 哈希表存储的是键值对,
_Val表示键值对中的值的类型。
-
_Key:- 含义: 表示哈希表中存储的键的类型。
- 用途: 哈希表存储的是键值对,
_Key表示键值对中的键的类型。
-
_HashFcn:- 含义: 表示哈希函数的类型。
- 用途:
_HashFcn指定了计算键的哈希值的方法,它是一个函数对象(函数或函数指针),用于将键转换为哈希值。
-
_ExtractKey:- 含义: 表示从键值对中提取键的方法的类型。
- 用途:
_ExtractKey是一个函数对象,用于从键值对中提取键,它定义了哈希表如何获取键值对中的键。
-
_EqualKey:- 含义: 表示键的相等比较方法的类型。
- 用途:
_EqualKey是一个函数对象,用于判断两个键是否相等,它定义了哈希表中键的相等性比较。
-
_Alloc:- 含义: 表示用于分配内存的分配器的类型。
- 用途:
_Alloc指定了哈希表内存的分配方式,它是一个分配器类模板,用于管理哈希表的内存分配和释放。
总体而言,这些模板参数定义了哈希表的基本特性,包括存储的键值对的类型、哈希函数、键的提取方法、键的相等比较方法以及内存分配器。通过提供不同的类型,可以实现不同类型的哈希表,适应不同的使用场景。
看一下hashtable的迭代器,有两个元素_M_cur和_M_ht
struct _Hashtable_iterator { typedef hashtable<_Val,_Key,_HashFcn,_ExtractKey,_EqualKey,_Alloc> _Hashtable; typedef _Hashtable_iterator<_Val, _Key, _HashFcn, _ExtractKey, _EqualKey, _Alloc> iterator; typedef _Hashtable_const_iterator<_Val, _Key, _HashFcn, _ExtractKey, _EqualKey, _Alloc> const_iterator; typedef _Hashtable_node<_Val> _Node; typedef forward_iterator_tag iterator_category; typedef _Val value_type; typedef ptrdiff_t difference_type; typedef size_t size_type; typedef _Val& reference; typedef _Val* pointer; _Node* _M_cur; // 指向具体的node,就是具体的元素 _Hashtable* _M_ht; //指向hashtable本身,就是指向具体的桶buchet _Hashtable_iterator(_Node* __n, _Hashtable* __tab) : _M_cur(__n), _M_ht(__tab) {} _Hashtable_iterator() {} reference operator*() const { return _M_cur->_M_val; } #ifndef __SGI_STL_NO_ARROW_OPERATOR pointer operator->() const { return &(operator*()); } #endif /* __SGI_STL_NO_ARROW_OPERATOR */ iterator& operator++(); iterator operator++(int); bool operator==(const iterator& __it) const { return _M_cur == __it._M_cur; } bool operator!=(const iterator& __it) const { return _M_cur != __it._M_cur; } };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
对上述代码的解释:
这段代码是 hashtable 的迭代器 _Hashtable_iterator 的定义。对于哈希表而言,其迭代器的设计通常涉及遍历桶(buckets)和桶中元素的过程。
-
_Node* _M_cur;:_M_cur是指向具体元素的节点_Node的指针。在哈希表中,每个桶都是一个链表或其他数据结构,_M_cur指向链表中的某个节点,即具体的元素。
-
_Hashtable* _M_ht;:_M_ht是指向哈希表本身的指针。它用于指示当前迭代器所属的哈希表,即指向具体的桶数组。
-
iterator& operator++();:operator++是前缀递增运算符,用于将迭代器指向下一个元素。在哈希表的迭代器中,这通常意味着移动到当前桶链表的下一个节点。
-
iterator operator++(int);:operator++(int)是后缀递增运算符。它返回当前迭代器的副本,并将原始迭代器移动到下一个元素。同样,对于哈希表,这通常意味着移动到当前桶链表的下一个节点。
-
bool operator==(const iterator& __it) const和bool operator!=(const iterator& __it) const:- 用于比较两个迭代器是否相等。在哈希表的迭代器中,相等通常表示两个迭代器指向相同的元素。
哈希表的迭代器并不一定按桶从小到大的顺序排列。它们的遍历顺序可能会受到哈希表内部桶的分布、哈希函数等因素的影响。具体而言,哈希表迭代器可能会按照桶的索引从小到大的顺序进行遍历,但在每个桶内,元素的顺序可能不同。由于哈希表的设计目的是提高查找效率,而不是有序存储元素,因此迭代器的顺序不一定是严格有序的。
24 hashtable深度探索(下)
下面讲一下hashtable具体怎么用,具体的6个模板参数怎么指定,如下图所示。
// 模板参数 template <class _Val, class _Key, class _HashFcn, class _ExtractKey, class _EqualKey, class _Alloc> // 具体指定为: hashtable<const char*, const char*, hash<const char*>, identity<const char*> eqstr, alloc> ht<50, hash<const char*>(), eqstr()); ht.insert_unique("kiwi"); ht.insert_unique("plum"); ht.insert_unique("apple"); struct eqstr{ bool operator()(const char* s1, const char* s2) const { return strcmp(s1, s2) == 0;} }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
解释与注释:
-
_Val:- 模板参数中:
_Val是哈希表中存储的值的类型。 - 具体指定为:
const char*,表示存储的值为字符串指针。
- 模板参数中:
-
_Key:- 模板参数中:
_Key是哈希表中存储的键的类型。 - 具体指定为:
const char*,表示键的类型为字符串指针。
- 模板参数中:
-
_HashFcn:- 模板参数中:
_HashFcn是哈希函数的类型。 - 具体指定为:
hash<const char*>,表示使用hash函数对象来计算字符串指针的哈希值。
- 模板参数中:
-
_ExtractKey:- 模板参数中:
_ExtractKey是从键值对中提取键的方法的类型。 - 具体指定为:
identity<const char*>,表示使用identity函数对象来提取字符串指针作为键。
- 模板参数中:
-
_EqualKey:- 模板参数中:
_EqualKey是键的相等比较方法的类型。 - 具体指定为:
eqstr,表示使用自定义的比较函数对象eqstr来判断两个键是否相等。
- 模板参数中:
-
_Alloc:- 模板参数中:
_Alloc是用于分配内存的分配器的类型。 - 具体指定为:
alloc,表示使用标准分配器alloc。
- 模板参数中:
-
哈希表实例化:
ht<50, hash<const char*>(), eqstr()表示具体实例化了哈希表对象ht。- 指定了哈希表的桶数量为 50,使用
hash<const char*>计算哈希值,以及使用eqstr进行键的相等性比较。
-
插入元素:
ht.insert_unique("kiwi")、ht.insert_unique("plum")、ht.insert_unique("apple")分别插入了字符串 “kiwi”、“plum”、“apple”。
-
比较函数对象定义:
struct eqstr定义了一个比较函数对象,用于在哈希表中比较字符串指针的相等性。

介绍hash function

在C++中,对 operator() 的重载允许对象实例被像函数一样调用,这使得对象可以表现得像函数一样。通过重载 operator(),你可以将一个类实例的行为定义为可调用的,就像调用函数一样。这种特性在C++中常常被称为“函数对象”或“仿函数”。
作用和意义:
-
可调用性: 通过重载
operator(),你可以将对象实例看作可调用的实体,就像函数一样。这样的对象可以被像函数一样调用,而不必使用函数调用运算符()。 -
状态保持: 函数对象可以保持状态,因为它们可以有成员变量。这使得函数对象能够在调用之间保持状态信息。
-
灵活性: 函数对象可以像普通函数一样传递给其他函数,也可以作为函数对象的成员传递给其他对象。
具体的使用示例:
#include <iostream> // 示例:函数对象类,重载了operator(),用于比较两个整数的大小 struct CompareIntegers { bool operator()(int a, int b) const { return a < b; } }; int main() { // 使用函数对象进行比较 CompareIntegers compare; int x = 5, y = 10; // 通过函数对象比较两个整数 bool result = compare(x, y); // 输出结果 std::cout << "Is x less than y? " << std::boolalpha << result << std::endl; return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在上面的示例中,CompareIntegers 是一个函数对象类,它重载了 operator(),用于比较两个整数的大小。通过实例化 CompareIntegers 类,并调用 operator(),可以像函数一样比较两个整数的大小。这种方式比传递函数指针更灵活,因为函数对象可以保持状态,并且可以轻松地通过类的成员传递额外的参数。函数对象在STL中的算法、容器等地方经常被使用。
下面是一种hash
inline size_t __stl_hash_string(const char* __s)
{
unsigned long __h = 0;
for ( ; *__s; ++__s)
__h = 5*__h + *__s;
return size_t(__h);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

25 hash set、hash multiset, hash map、hash multimap概念
视频缺失
26 unordered容器概念
在C++的标准库中,unordered_set、unordered_multiset、unordered_map、unordered_multimap 分别对应哈希集合、哈希多重集合、哈希映射以及哈希多重映射。以下是它们的概念和特点:
-
unordered_set:- 概念: 无序集合,存储不重复的元素,内部使用哈希表实现。
- 特点: 元素无序存储,插入、删除、查找操作的平均时间复杂度为 O(1)。
-
unordered_multiset:- 概念: 无序多重集合,存储允许重复的元素,内部使用哈希表实现。
- 特点: 元素无序存储,插入、删除、查找操作的平均时间复杂度为 O(1)。
-
unordered_map:- 概念: 无序映射,存储键值对,内部使用哈希表实现。
- 特点: 键值对无序存储,通过键进行查找、插入、删除的平均时间复杂度为 O(1)。
-
unordered_multimap:- 概念: 无序多重映射,存储允许多个相同键的键值对,内部使用哈希表实现。
- 特点: 键值对无序存储,通过键进行查找、插入、删除的平均时间复杂度为 O(1)。
这些容器是C++11及更高版本引入的,它们在使用时不保证元素的顺序,而是通过哈希表提供快速的查找性能。每个元素被映射到哈希表的一个桶中,这使得查找操作的时间复杂度较低。然而,由于使用哈希表,它们不提供元素的有序性。如果需要有序性,应考虑使用 std::set、std::multiset、std::map、std::multimap。

后记
完成容器底层的学习。本文主要记录基于红黑树的容器和基于hashtable的容器。

