
- 1Mybatis-Plus 开发提速器:mybatis-plus-generator-ui 你确定不了解一下?
- 2C语言算法实验-二叉树_按先序次序输入二叉树中结点的值,空格字符表示空树
- 3利用B站弹幕引擎(Danmaku)轻松实现弹幕功能
- 4circos 中的pattern是做什么用的_circos pattern = solid
- 5【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人_langchain qwen1.5
- 6网络编程(三) ———— Java Socket(UDP/TCP 套接字)_java new socket 是tcp还是udp
- 7解决Oracle的CLOB数据类型大于4000时的数据太大的问题ORA-01704: string literal too long_读取clob大于4000以上的内容
- 8sm2,sm3,sm4国密算法的纯c语言版本,使用于任何嵌入式平台_sm1sm2sm3sm4 c语言代码
- 9elementui添加loading_el-icon-loading
- 10阻止NavigationView推送动画_uwp navigateview 屏蔽迁移动画
AIBigKaldi(四)| Kaldi的特征提取(源码解析)_倒谱均值和方差归一化(cepstrum mean variance normalization,cm
赞
踩
本文来自公众号“AI大道理”。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
准备好了数据,接下来就可以特征提取了。
最常用到的语音特征就是梅尔倒谱系数(Mel-scaleFrequency Cepstral Coefficients,简称MFCC)。
以最简单的YesNo为例。
1 run.sh
特征提取步骤:
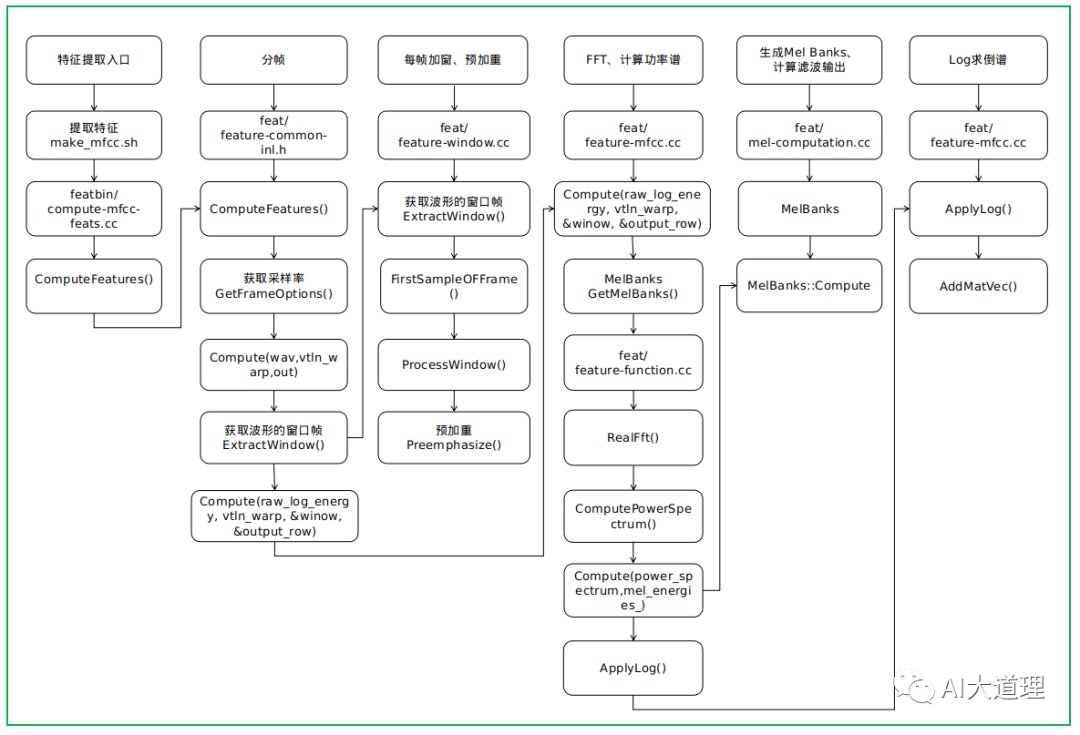
MFCC提取过程包括预处理、快速傅里叶变换、Mei滤波器组、对数运算、离散余弦变换、动态特征提取等步骤。
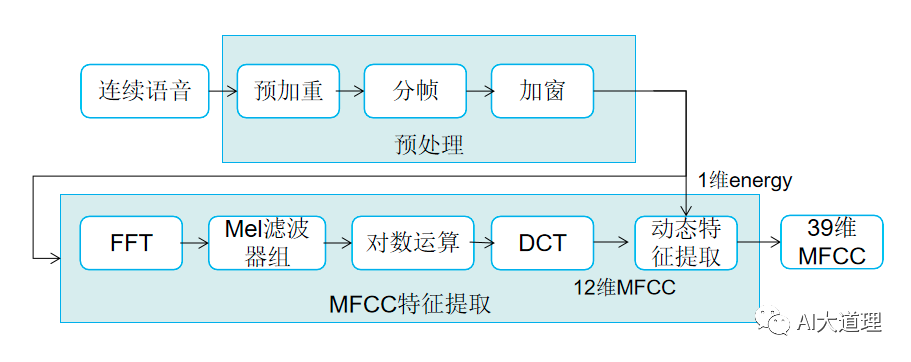
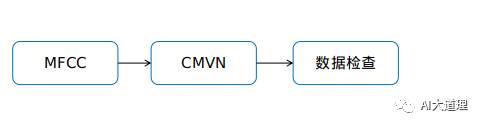
Kaldi在进行MFCC特征提取后使用了谱归一化CMVN使得模型的输入特征趋近正态分布。
run.sh:

其中:

2 特征提取
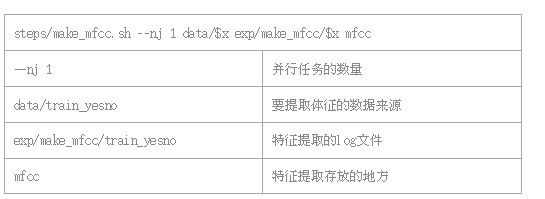
2.1 make_mfcc.sh
功能:
生成mfcc目录存放.scp和.ark特征文件;
生成 exp/make_mfcc目录存放特征提取log文件;
生成data/train_yesno, data/test_yesno里面的cmvn.scp、 feats.scp文件。
make_mfcc.sh会用到conf/mfcc.conf
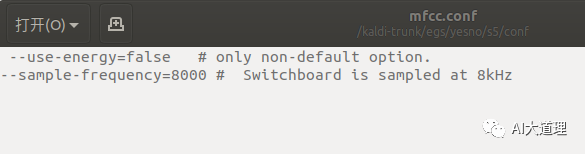
其中采样频率在这里设置,这里为8KHZ。
命令行解析:
源码(部分):
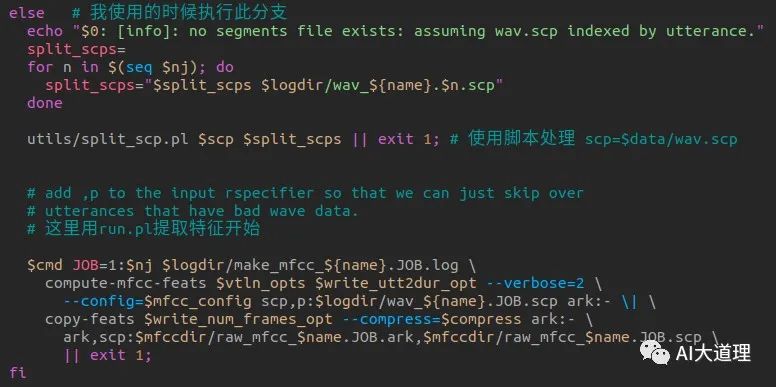
源码解析:
利用Kaldi的compute-mfcc-feats工具计算梅尔倒谱频率特征,然后利用copy-feats工具的参数—compress=true 压缩处理存储为两个文件类型ark和scp。
调用命令行工具compute-mfcc-feats,提取特征,创建feats.ark和feats.scp文件。
用法为:
compute-mfcc-feats [options...] <wav-rspecifier><feats-wspecifier>。
来龙去脉:
3 倒谱均值方差归一化
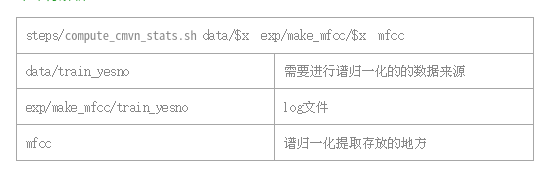
2.2 compute_cmvn_stats.sh
CMCN(Cepstral Mean and Variance Normalization):倒谱均值方差归一化。
功能:
提取声学特征以后,将声学特征从一个空间转变成另一个空间,使得在这个空间下更特征参数更符合某种概率分布,压缩了特征参数值域的动态范围,减少了训练和测试环境的不匹配等。
(这不是必须的,当你在单一环境中进行语音识别时,CMN甚至会恶化你的结果,CMN会倾向于将附加噪声当成信号。)
源头:
CMN(Cepstral Mean Normalisation):倒谱均值归一化。
在语音识别中,我们希望移除通道效应(声道的冲击响应,传播路径,房间环境等等)。
由于任何通道卷积特性的扭曲特性,在倒谱域下都可以变为叠加信号,经过倒谱均值归一化后就消除了通道的影响。
步骤:
-
计算倒谱;
-
从每一帧中减去平均值;
-
相对于减去均值,可以选择性的除以方差来进行CMVN。
CMVN可以恢复特征在时域上的多样性,而这种多样性通常会由于噪声的影响而减弱,这同样可以被视为一种一种减少特征变异性的方法。
通过对MFCC系数的静态量进行归一化,也就是进行CMN或者CMVN可以提高语音识别器的鲁棒性。
命令行解析:
4 数据检查
2.3 fix_data_dir.sh
功能:
该脚本会修复排序错误,并移除那些被指明需要特征数据或标注,但却找不到相应数据的那些发音。
命令行解析:

5 总结
提取了MFCC特征,并进行倒谱均值方差归一化,数据检查无误后就可以进行模型训练了。
首先进行的是单音素模型训练,然后进行三音子模型训练。

下期预告
AIBigKaldi(五)| Kaldi的单音子模型训练
往期精选
AI大语音(十四)——区分性训练
AI大语音(十三)——DNN-HMM
AI大语音(十二)——WFST解码器(下)
AI大语音(十一)——WFST解码器(上)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————

