
- 1基于长短时神经网络(LSTM)+word2vec的情感分析_lstm神经网络和word
- 2数据中台及数据仓库设计_dwi层
- 3spring常用注解(全)
- 4一文详解什么是RNN(循环神经网络)
- 5Docker基本命令
- 6【Redis系列】深入了解 Redis:一种高性能的内存数据库
- 7[机器学习]利用朴素贝叶斯对商品评价进行分析_anacanda怎么用朴素贝叶斯算法将计算机购买素材进行分析
- 8springboot项目整合百度AI内容审核(文本,图片)_springboot发帖审核
- 9程序获取 | 机器学习/深度学习程序和数据获取方式_机器学习的代码怎么获得
- 10vmware虚拟机克隆CentOS7 出现的网络问题与解决办法_vm克隆的centos7网络很慢
一文搞懂 Transformer 工作原理 !!_transformer原理
赞
踩
文章目录
前言
本文将从单头Attention工作原理、多头Attention工作原理、全连接网络工作原理三个方面,实现一文搞懂Transformer的工作原理。

Transformer工作原理
一、单头Attention工作原理
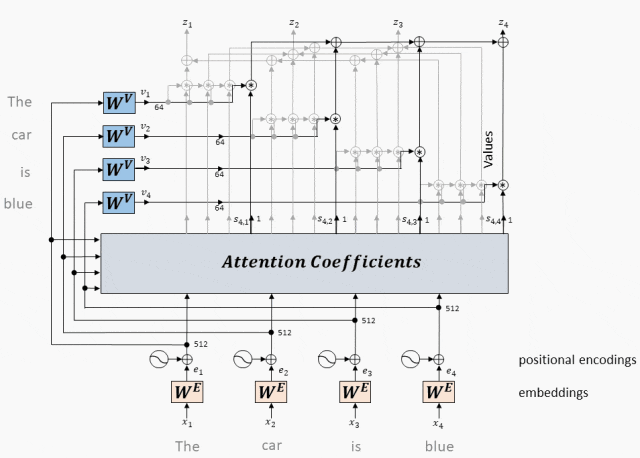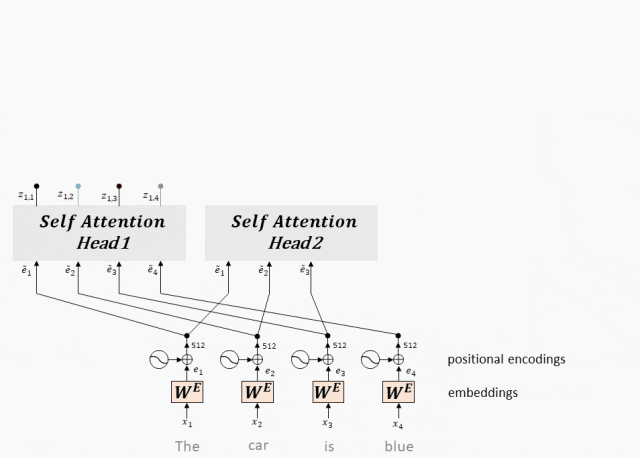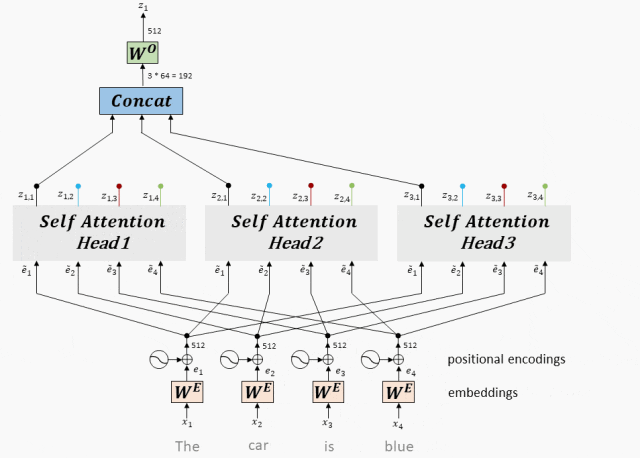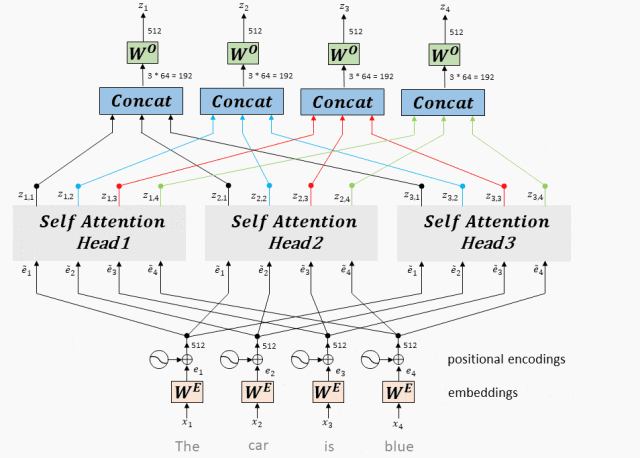
单头Attention(Single-Head Attention):单头注意力是一种注意力机制,它只求一次注意力。在这个过程中,对同样的查询(Q)、键(K)和值(V)求一次注意力,得到一个输出。这种机制允许模型从不同的表示子空间在不同位置关注信息。

Scaled Dot-Product(缩放点积运算)
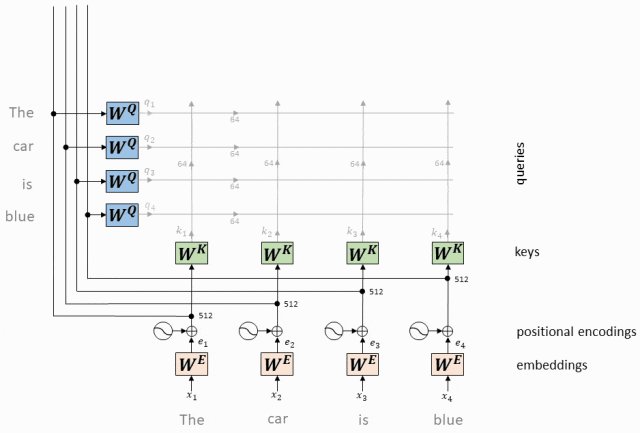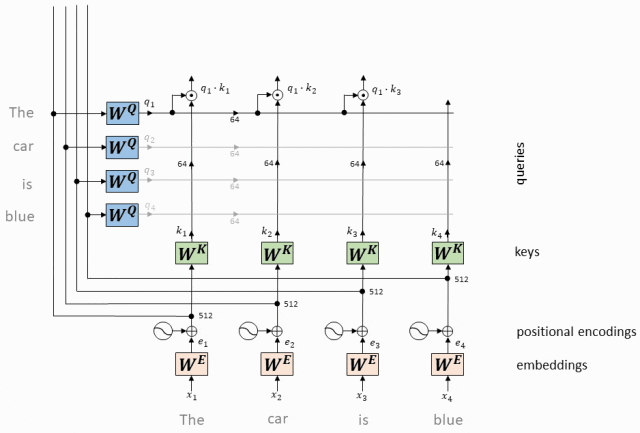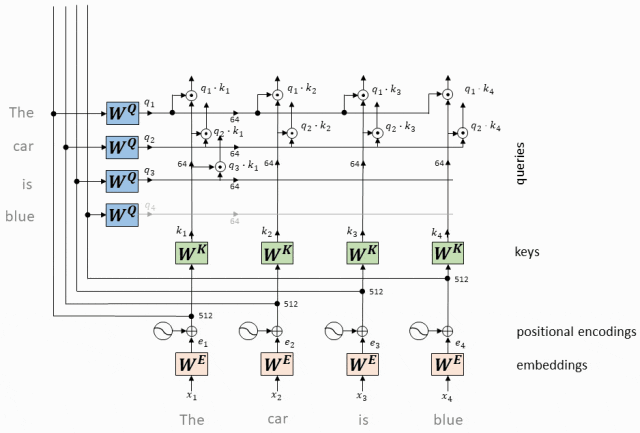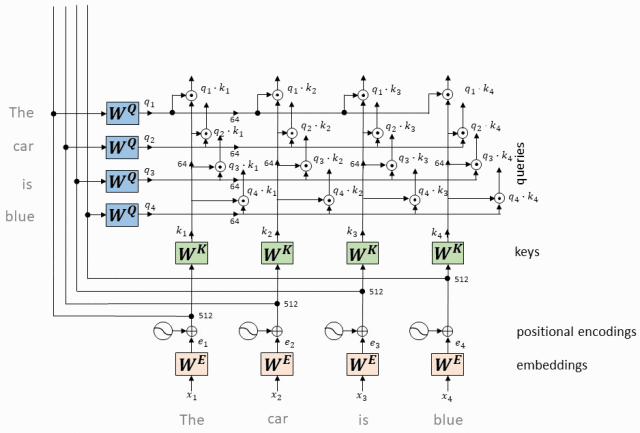
- Query、Key和Value矩阵:
Query矩阵(Q):表示当前的关注点或信息需求,用于与Key矩阵进行匹配。
Key矩阵(K):包含输入序列中各个位置的标识信息,用于被Query矩阵查询匹配。
Value矩阵(V):存储了与Key矩阵相对应的实际值或信息内容,当Query与某个Key匹配时,相应的Value将被用来计算输出。
- 点积计算:
通过计算Query矩阵和Key矩阵之间的点积(即对应元素相乘后求和),来衡量Query与每个Key之间的相似度或匹配程度。
- 缩放因子:
由于点积操作的结果可能非常大,尤其是在输入维度较高的情况下,这可能导致softmax函数在计算注意力权重时进入饱和区。为了避免这个问题,缩放点积注意力引入了一个缩放因子,通常是输入维度的平方根。点积结果除以这个缩放因子,可以使得softmax函数的输入保持在一个合理的范围内。
- Softmax函数:
将缩放后的点积结果输入到softmax函数中,计算每个Key相对于Query的注意力权重。Softmax函数将原始得分转换为概率分布,使得所有Key的注意力权重之和为2。
工作原理:单头Attention通过计算每个token的查询向量与所有token的键向量的点积,并经过softmax归一化得到注意力权重,再将这些权重应用于值向量进行加权求和,从而生成每个token的自注意力输出表示。
- 每个token对应的Query向量与每个token对应的Key向量做点积
对于输入序列中的每个token,我们都有一个对应的查询向量(Query Vector,Q)和键向量(Key Vector,K)。
我们计算每个查询向量与所有键向量的点积。
这个步骤是在所有token之间建立关系,表示每个token对其他token的“关注”程度。
QK向量点积运算
- 将上述点积取softmax(得到0~1之间的值,即为Attention权重)
点积的结果需要经过一个softmax函数,确保所有token的注意力权重之和为1。softmax函数将点积结果转换为0到1之间的值,这些值表示了每个token相对于其他所有token的注意力权重。

计算Attention权重
- 计算每个token相对于所有其他token的Attention权重(最终构成一个Attention矩阵)
经过softmax处理后的注意力权重构成了一个Attention矩阵。
这个矩阵的每一行对应一个token,每一列也对应一个token,矩阵中的每个元素表示了对应行token对列token的注意力权重。
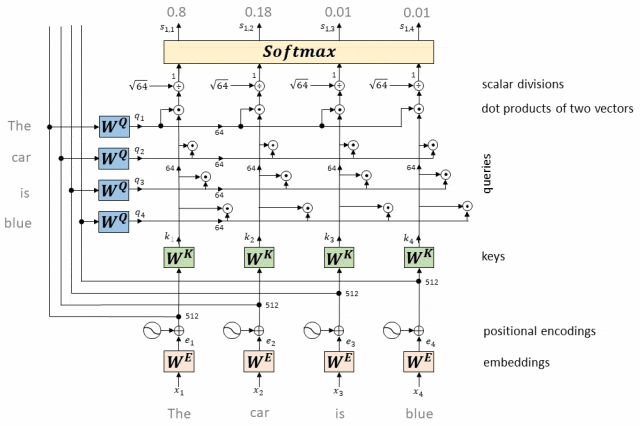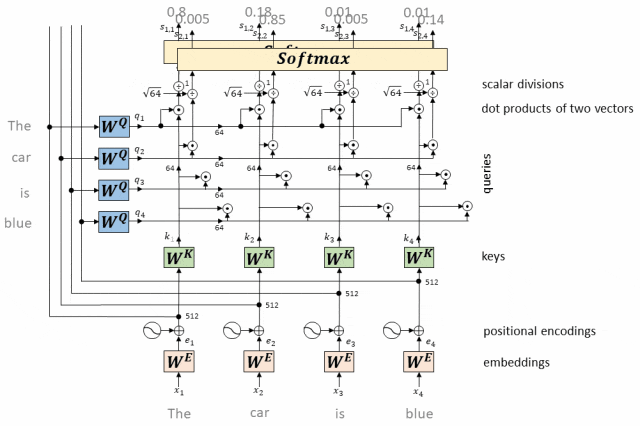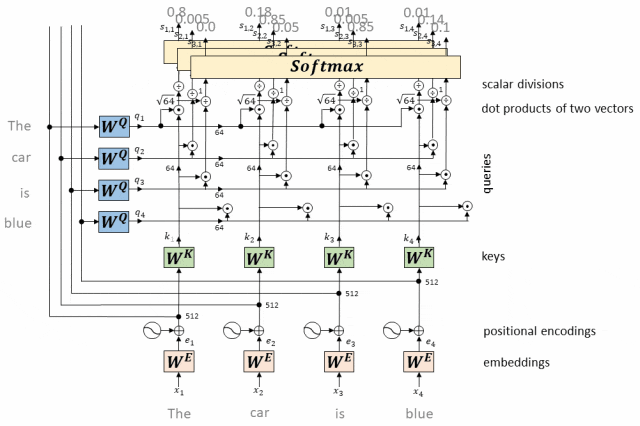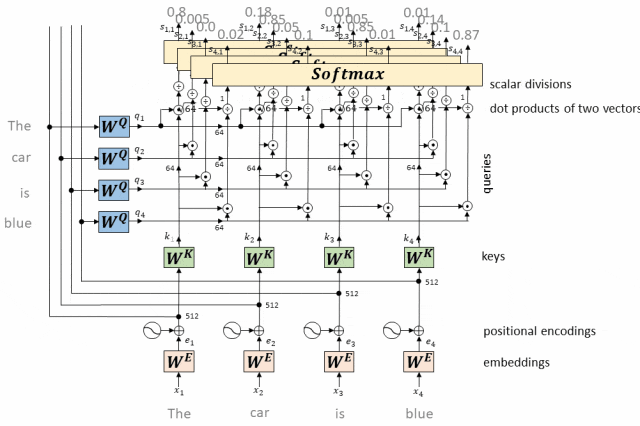
构成Attention矩阵
- 每个token对应的value向量乘以Attention权重,并相加,得到当前token的Self-Attention value向量
使用这个Attention矩阵来加权输入序列中的值向量(Value Vector,V)。
具体来说,对于每个token,我们将其对应的值向量与Attention矩阵中该token所在行的所有权重相乘,并将结果相加。
这个加权求和的结果就是该token经过自注意力机制处理后的输出表示。

加权求和Value向量
- 将上述操作应用于每个token
上述操作会应用于输入序列中的每个token,从而得到每个token经过自注意力机制处理后的输出表示。
这些输出表示通常会被送到模型的下一个层进行进一步的处理。

应用于每个token
二、多头Attention工作原理
多头Attention(Multi-Head Attention):多头注意力机制通过并行运行多个Self-Attention层并综合其结果,能够同时捕捉输入序列在不同子空间中的信息,从而增强模型的表达能力。
- Multi-Head Attention实际上是多个并行的Self-Attention层,每个“头”都独立地学习不同的注意力权重。
- 这些“头”的输出随后被合并(通常是拼接后再通过一个线性层),以产生最终的输出表示。
- 通过这种方式,Multi-Head Attention能够同时关注来自输入序列的不同子空间的信息。

Multi-Head Attention
工作原理:多头Attention将每个头得到向量拼接在一起,最后乘一个线性矩阵,得到Multi-Head Attention的输出。
- 输入线性变换:对于输入的Query(查询)、Key(键)和Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。
- 分割多头:经过线性变换后,Query、Key和Value向量被分割成多个头。每个头都会独立地进行注意力计算。
- 缩放点积注意力:在每个头内部,使用缩放点积注意力来计算Query和Key之间的注意力分数。这个分数决定了在生成输出时,模型应该关注Value向量的部分。
- 注意力权重应用:将计算出的注意力权重应用于Value向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。
- 拼接和线性变换:将所有头的加权输出拼接在一起,然后通过一个线性变换得到最终的Multi-Head Attention输出。
拼接和线性变换
三、全连接网络工作原理
前馈网络(Feed-Forward Network):Transformer模型中,前馈网络用于将输入的词向量映射到输出的词向量,以提取更丰富的语义信息。前馈网络通常包括几个线性变换和非线性激活函数,以及一个残差连接和一个层归一化操作。
- Encoder编码器:
Transformer中的编码器部分一共N个相同的编码器层组成。
每个编码器层都有两个子层,即多头注意力层(Multi-Head Attention)层和前馈神经网络(Feed-Forward Network)。
在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。

Encoder(编码器)架构
- Decoder解码器:
Transformer中的解码器部分同样一共N个相同的解码器层组成。
每个解码器层都有三个子层,掩蔽自注意力层(Masked Self-Attention)、Encoder-Decoder注意力层、前馈神经网络(Feed-Forward Network)。
同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。

Decoder(解码器)结构
工作原理:Multi-Head Attention的输出,经过残差和norm之后进入一个两层全连接网络。
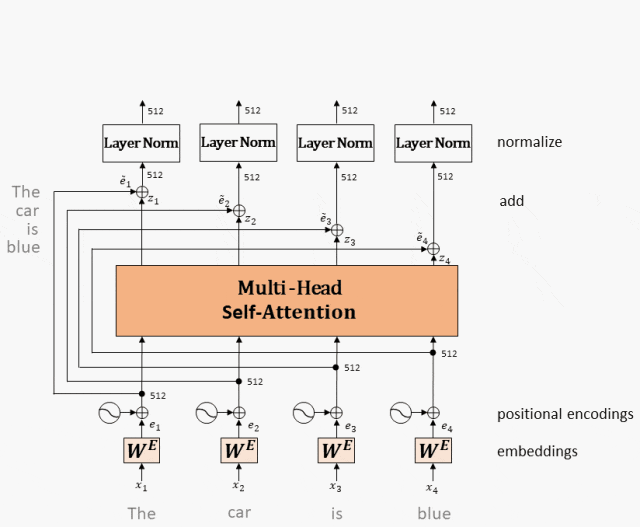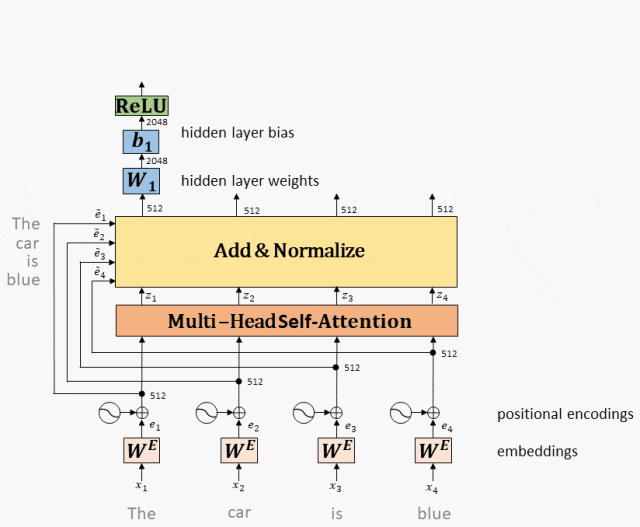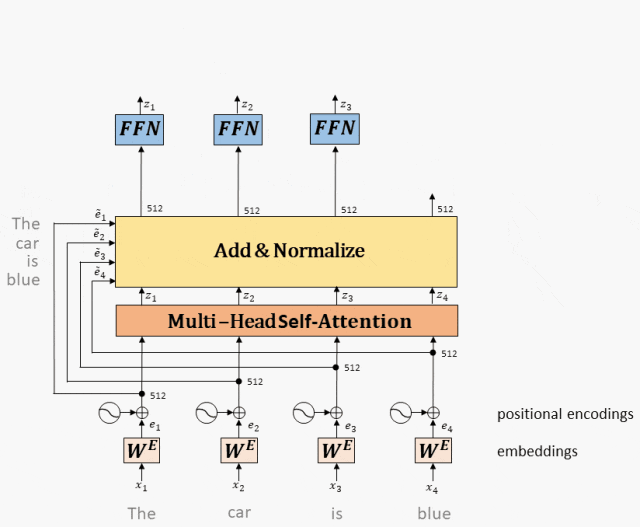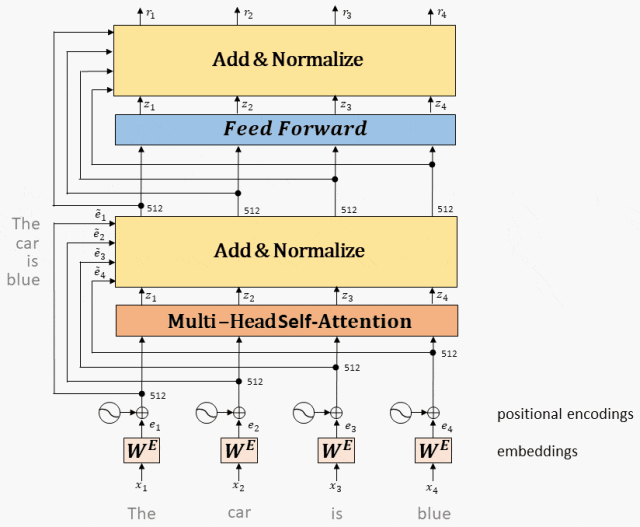
全连接网络
参考:架构师带你玩转AI

