- 1【网络安全】2024年热门网络安全运营工具/方案推荐_网络安全运营产品
- 2【花雕动手做】ASRPRO语音识别(46)---四路继电器的智能控制_asrpro语音模块四路继电器接线
- 3大模型基础理论学习笔记——大模型适配_大模型精确匹配
- 4解密人工智能:KNN | K-均值 | 降维算法 | 梯度Boosting算法 | AdaBoosting算法_adaboost降维
- 5【深度学习】语言模型与注意力机制以及Bert实战指引之一_bert模型注意力机制
- 66-1体育俱乐部I(构造函数)_体育俱乐部i(构造函数)
- 7什么是docker_何为docker
- 81DCNN和CNN的区别?
- 9寄予厚望!2024中科院《预警期刊名单》
- 10OpenCV 4基础篇| OpenCV图像的拼接_opencv 拼接
Prefix-Tuning: Optimizing Continuous Prompts for Generation
赞
踩
参考
Prefix-Tuning: Optimizing Continuous Prompts for Generation 作者小姐姐的讲解
In-context Learning

优点
- 只需为不同任务写下不同的提示,不需要进行任何特定于任务的训练
缺点
-
但不能利用非常大的数据集,如GPT-3有一个有界的上下文窗口,只能处理有限数量的token,所以当我们有一个比上下文窗口长的训练集时,上下文学习不能充分利用该训练集
-
我们必须手动提出提示,这些手动编写的提示可能不是最佳的
-
GPT-3不能很好的推广到较小的模型
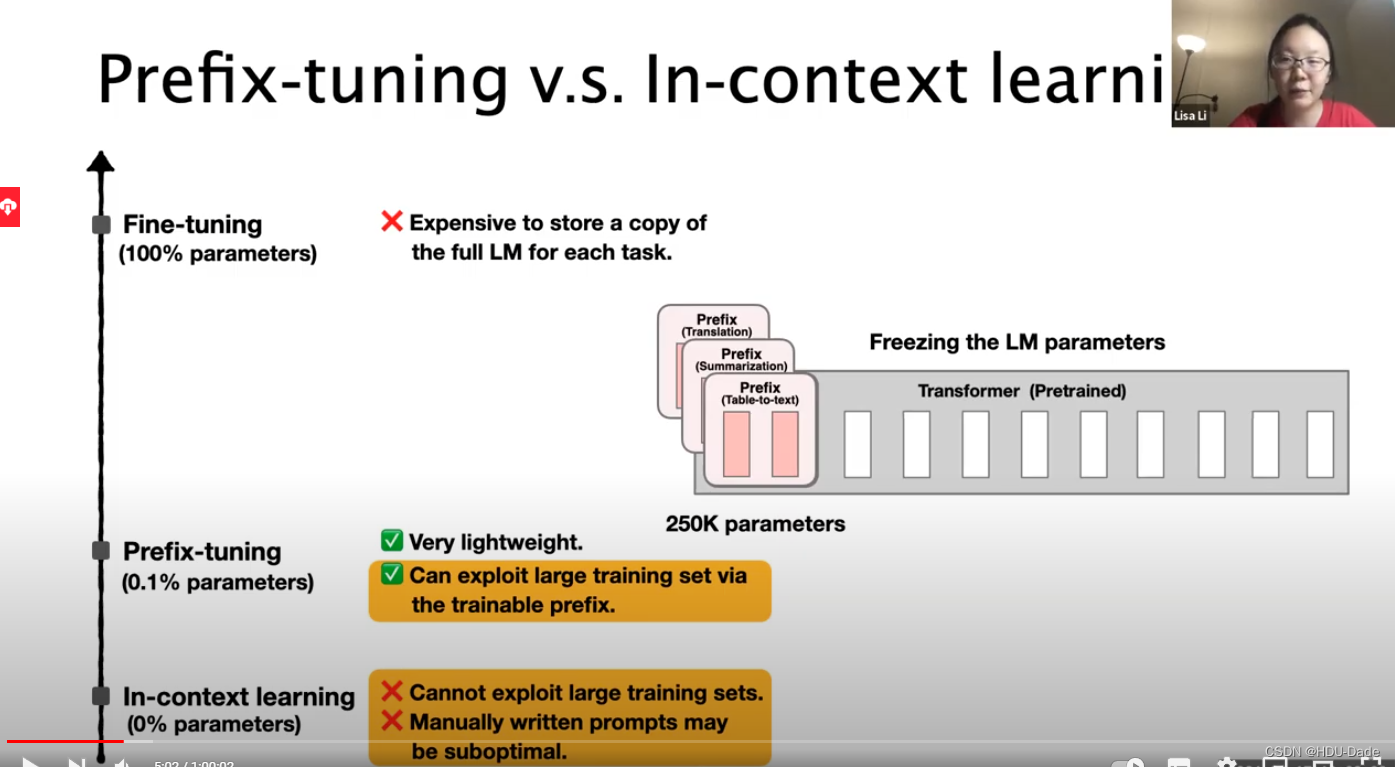
Prefix-tuning
-
冻结预训练语言模型,只优化前缀,对每个任务只存储这个非常小的前缀。随任务数量增加,开销非常小
-
前缀可训练。不必手动指定
-
上下文学习是一个独特的框架,仅适用于大模型。前缀学习可将prompt推广到较小模型
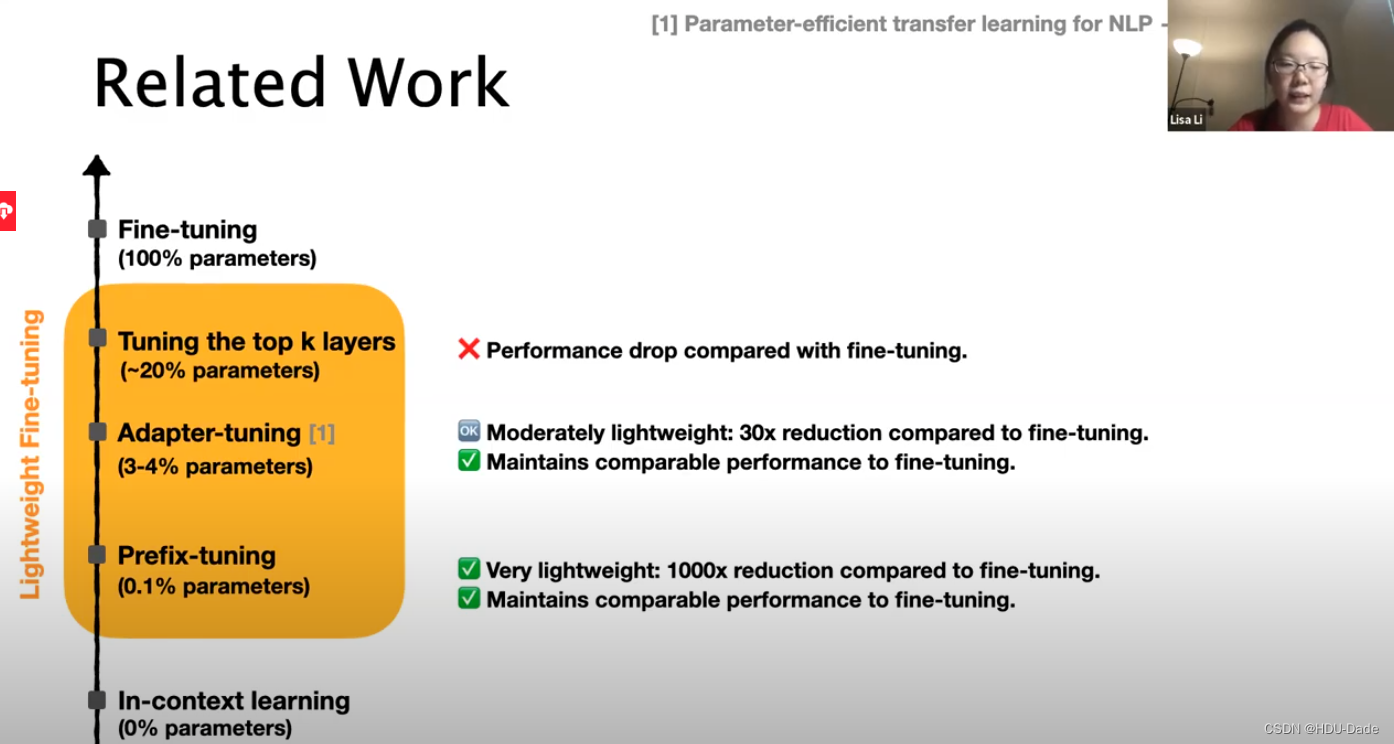
Related Work
-
Tuning the top k layers
调整top k层是大型微调模型常见做法。通常k等于1或2。调整参数量为20%是因为还要调整包含很多参数的语言模型头 -
Adapter-tuning (也称轻量化微调)
为下游任务调整语言模型的另一种参数有效方法,冻结预训练参数,并在LM的每一层之间添加了一些可训练的mlp层
Prefix-tuning-intuition

优化为离散指令
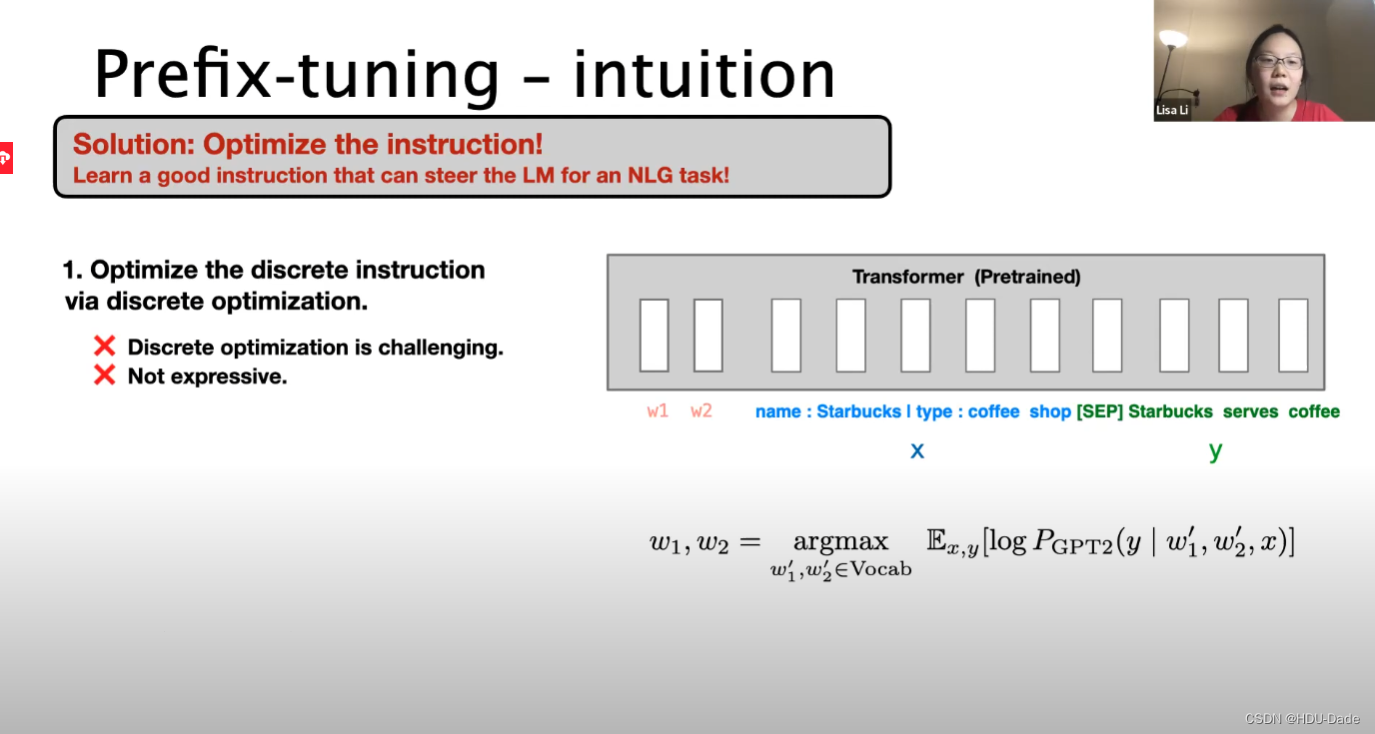 优化为连续词嵌入
优化为连续词嵌入
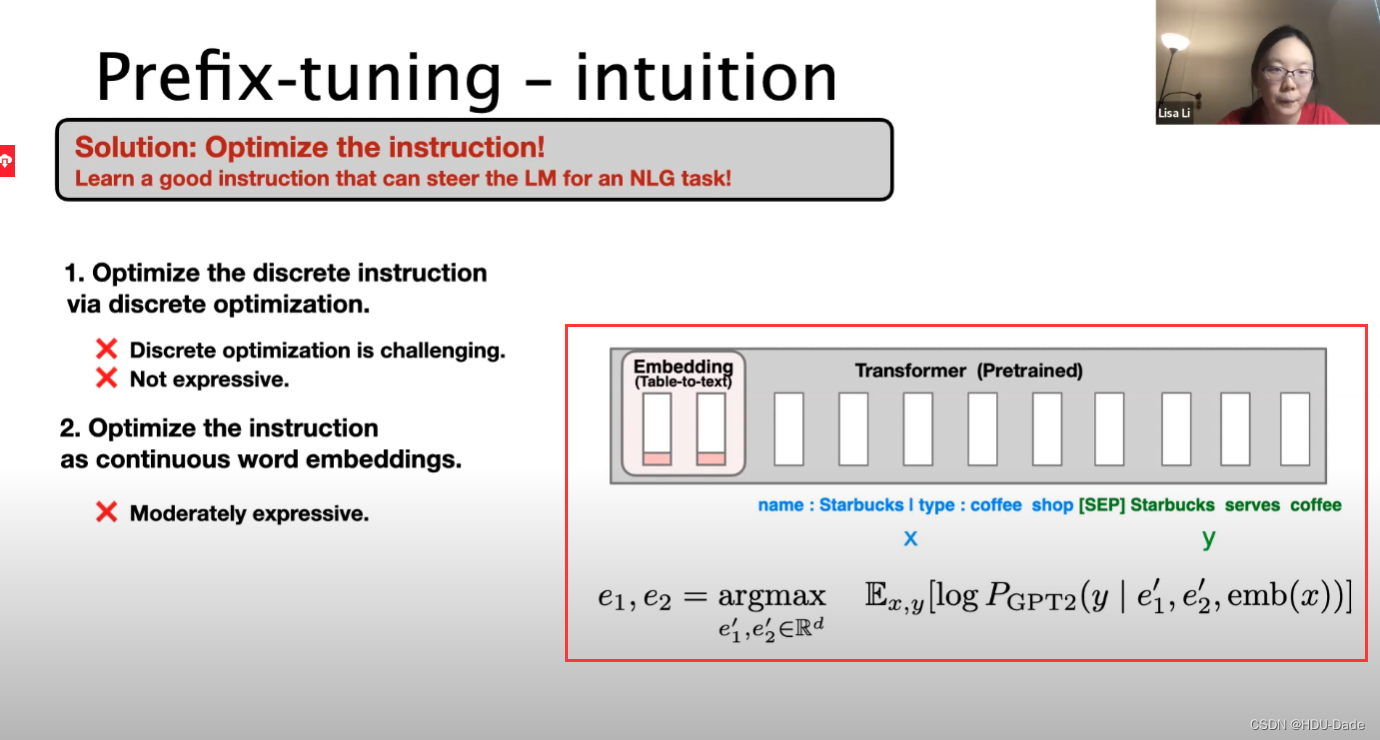
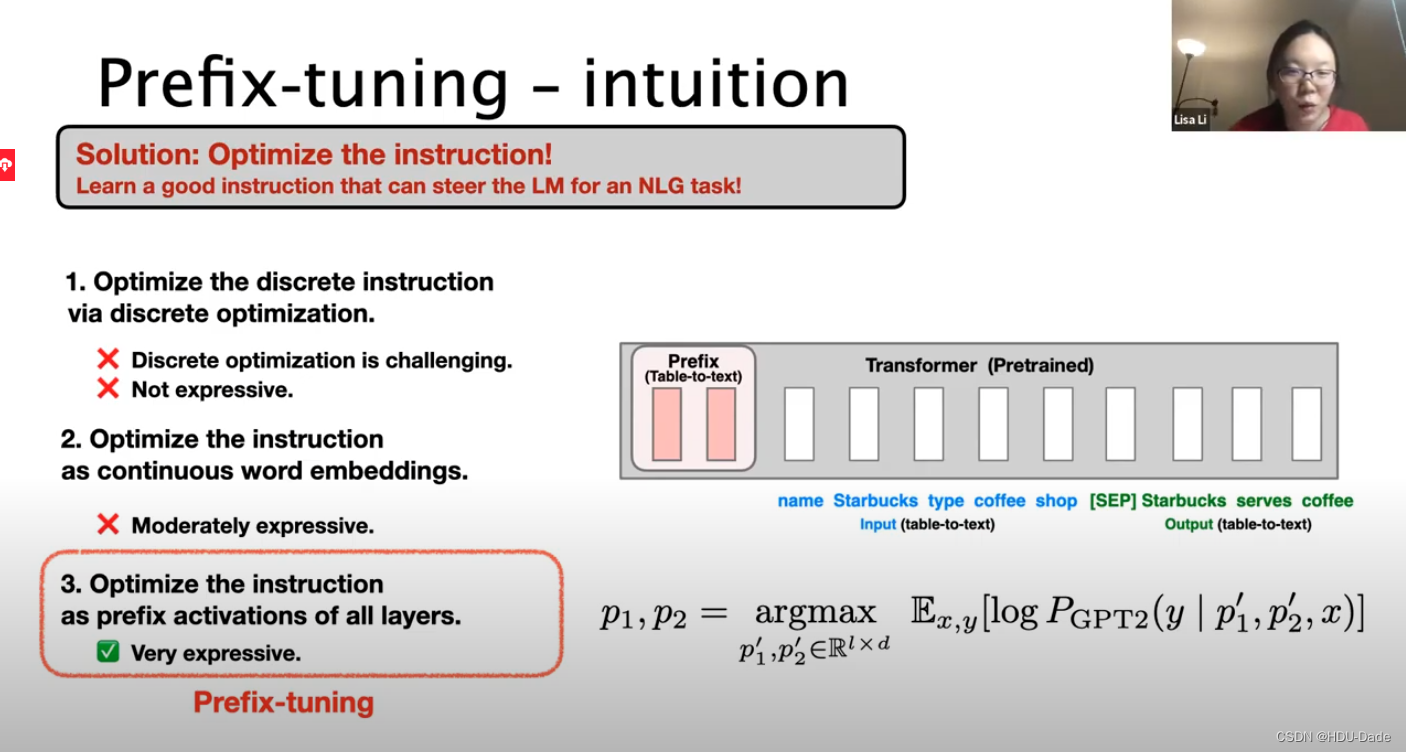
优化所有层的前缀激活
Fine-tuning
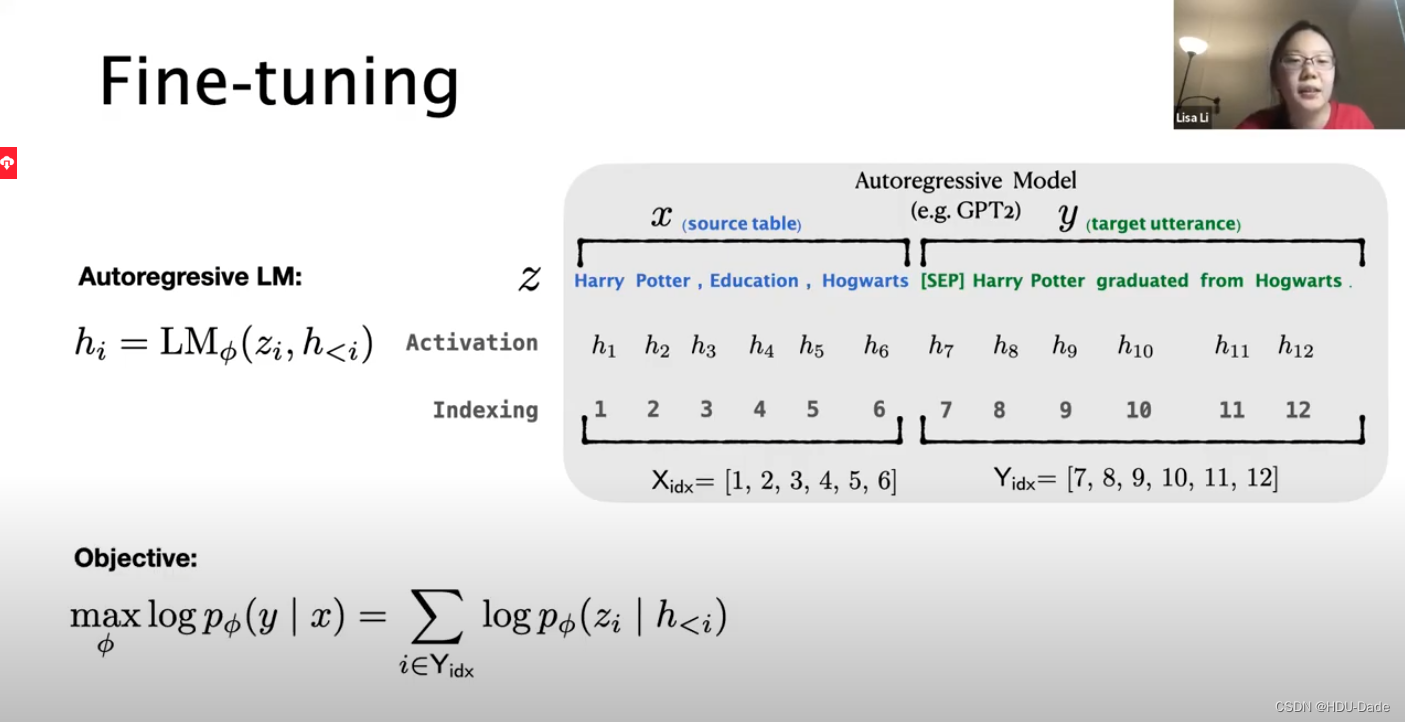
连接x和y以获得z,通过Autoregresive LM,在每个时间步计算激活向量
h
i
h_i
hi,因此
h
i
h_i
hi通过做上下文的激活和时间布
i
i
i的输入来计算
目标为每次生成
y
y
y中的每个标记的对数概率之和

任务:
table-to-text任务:输入
X
X
X 表示一个线性的表格,输出
Y
Y
Y 表示一个短文本;
-
自回归模型:在某一时刻 i i i,Transformer的每一层的隐状态向量拼接起来之后用于预测下一个词;
-
整体采用encoder-to-decoder架构;
可以将token优化为连续词嵌入,而不是优化离散标记,其效果将向上传播到所有 Transformer 激活层,然后向右传播到后续标记。 这比需要匹配真实单词嵌入的离散提示更具表现力。 同时,这不如干预所有激活层的表现力,这避免了长期依赖并包括更多可调参数。 因此,Prefix-Tuning优化了前缀部分对应的所有层参数。
-
添加一个prefix,自回归模型表示为 z = [ p r e f i x ; x ; y ] z=[prefix;x;y] z=[prefix;x;y],encoder decoder模型表示为 z = [ p r e f i x ; x ; p r e f i x ′ ; y ] ; z=[prefix;x;prefix′ ;y]; z=[prefix;x;prefix′;y];
-
输入部分 p r e f i x , x , y prefix, x, y prefix,x,y的position id分别记作 P i d x , X i d x 和 Y i d x P_{idx},X_{idx}和Y_{idx} Pidx,Xidx和Yidx
-
prefix-tuning初始化一个可训练的矩阵,记作 P θ ∈ R ∣ P i d x ∣ × d i m ( h i ) P_\theta\in\mathbb{R}^{|P_{idx}|\times dim(h_i)} Pθ∈R∣Pidx∣×dim(hi)
它的维度是前缀×激活向量的维度 -
h i h_i hi用于存储prefix parameters:
-
处于前缀部分token,参数选择设计的训练矩阵
-
而其他部分的token,参数则固定且为预训练语言模型的参数。
-
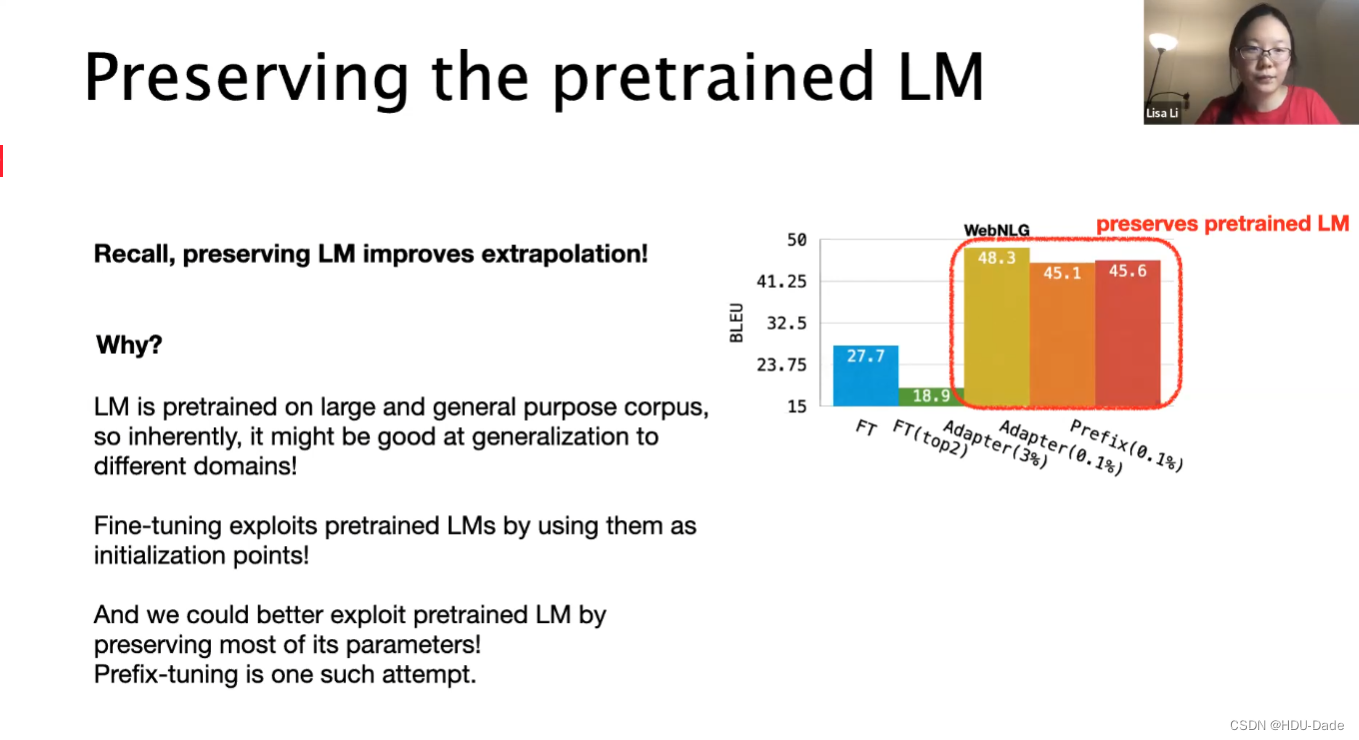
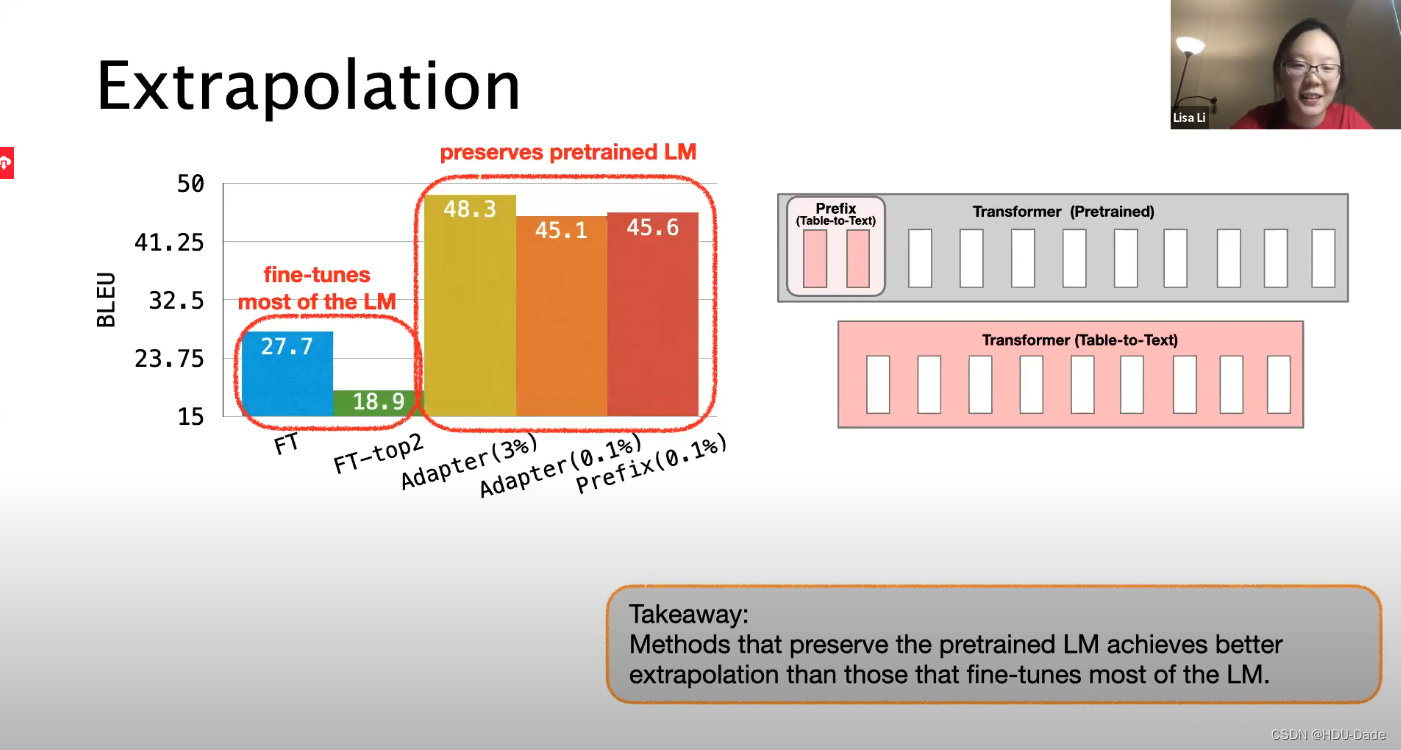
Result(table-to-text)

table-to-text
prefix的性能比adapt和fine-tuneing更好


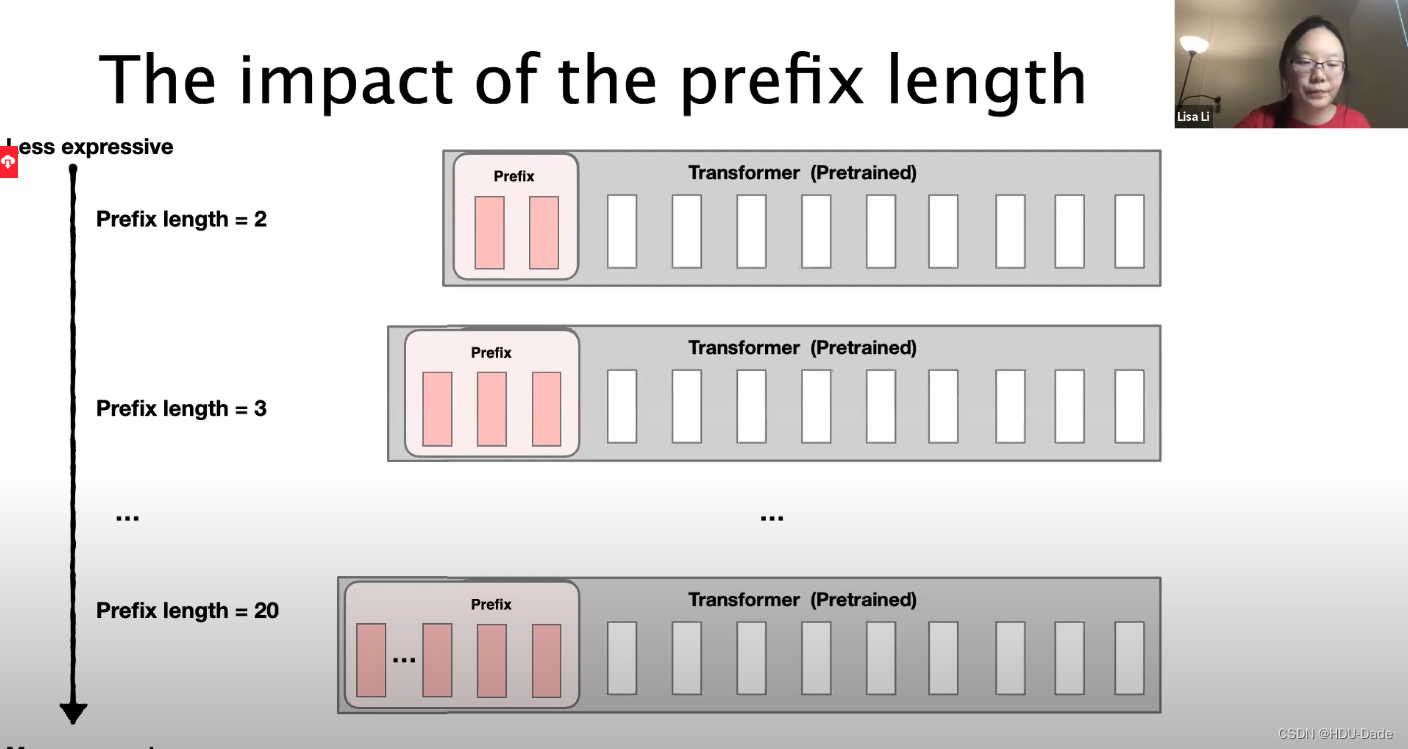
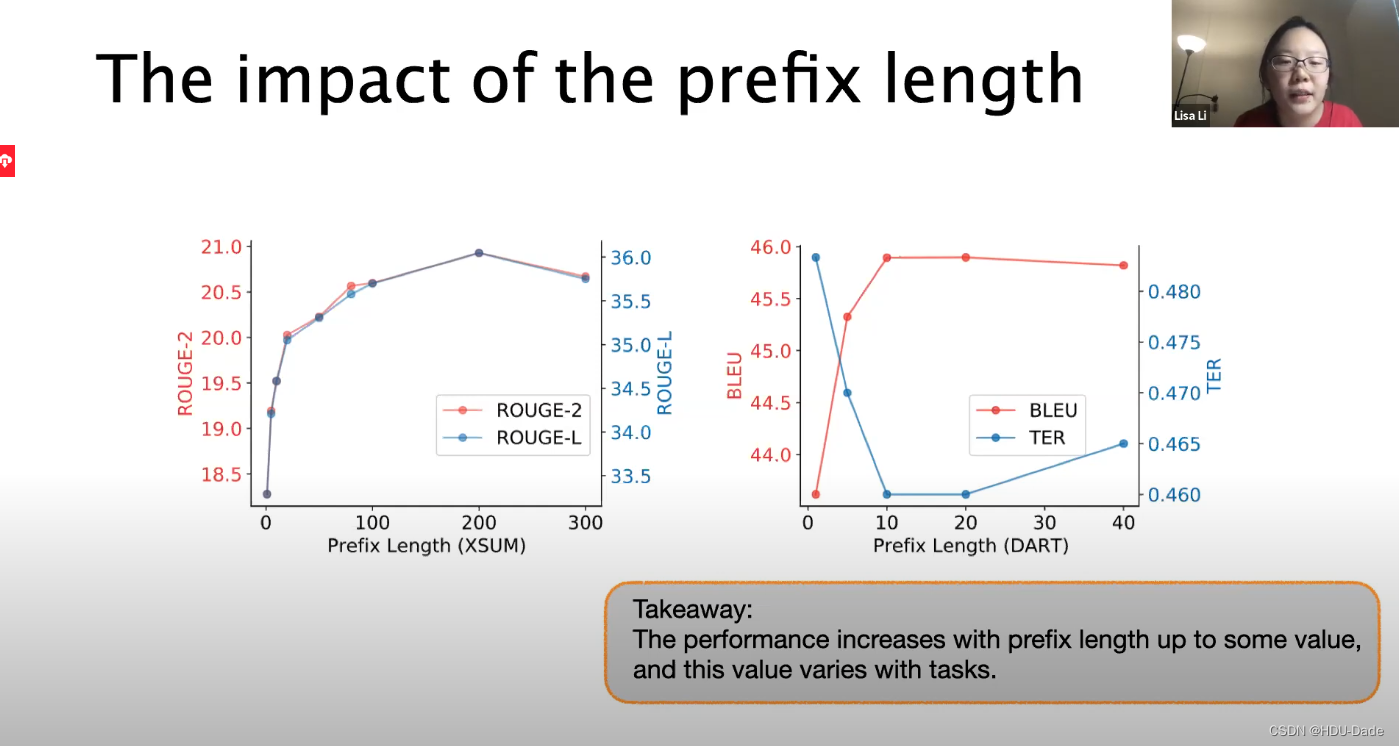
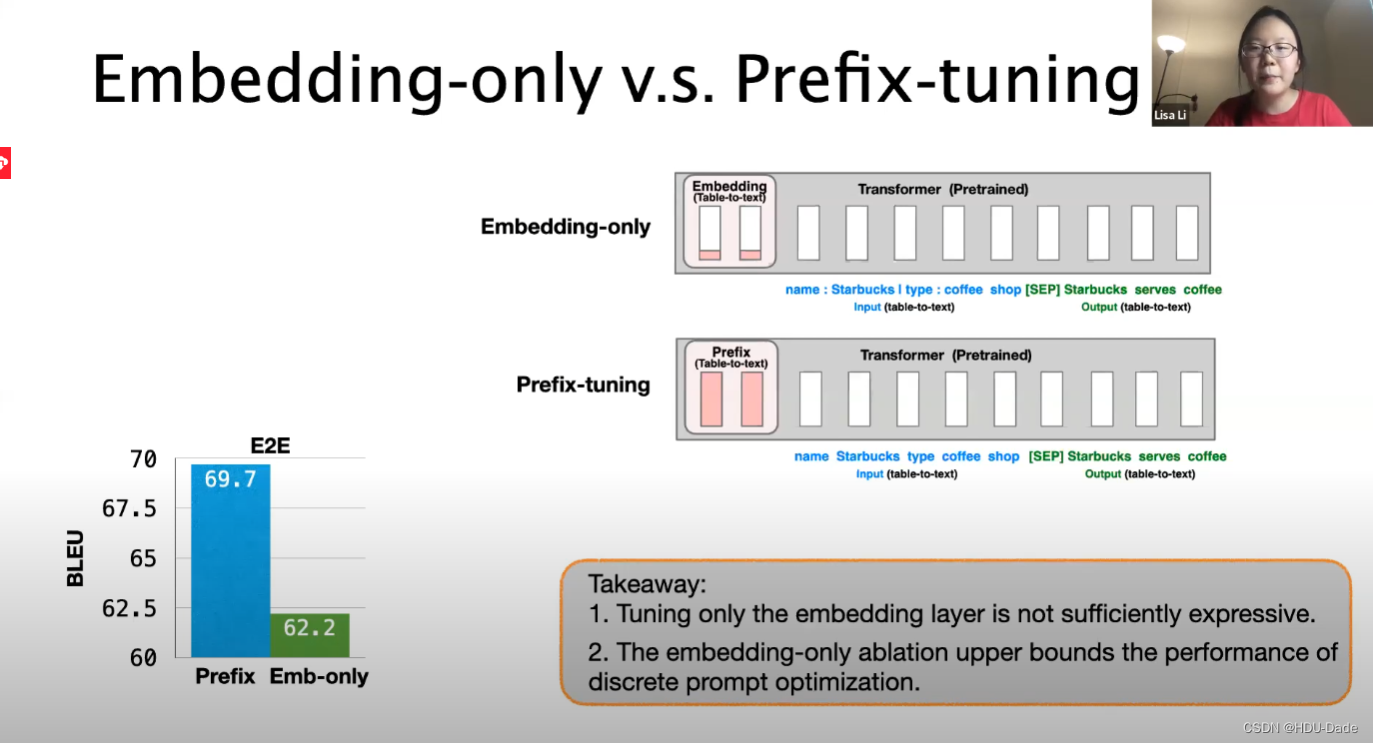
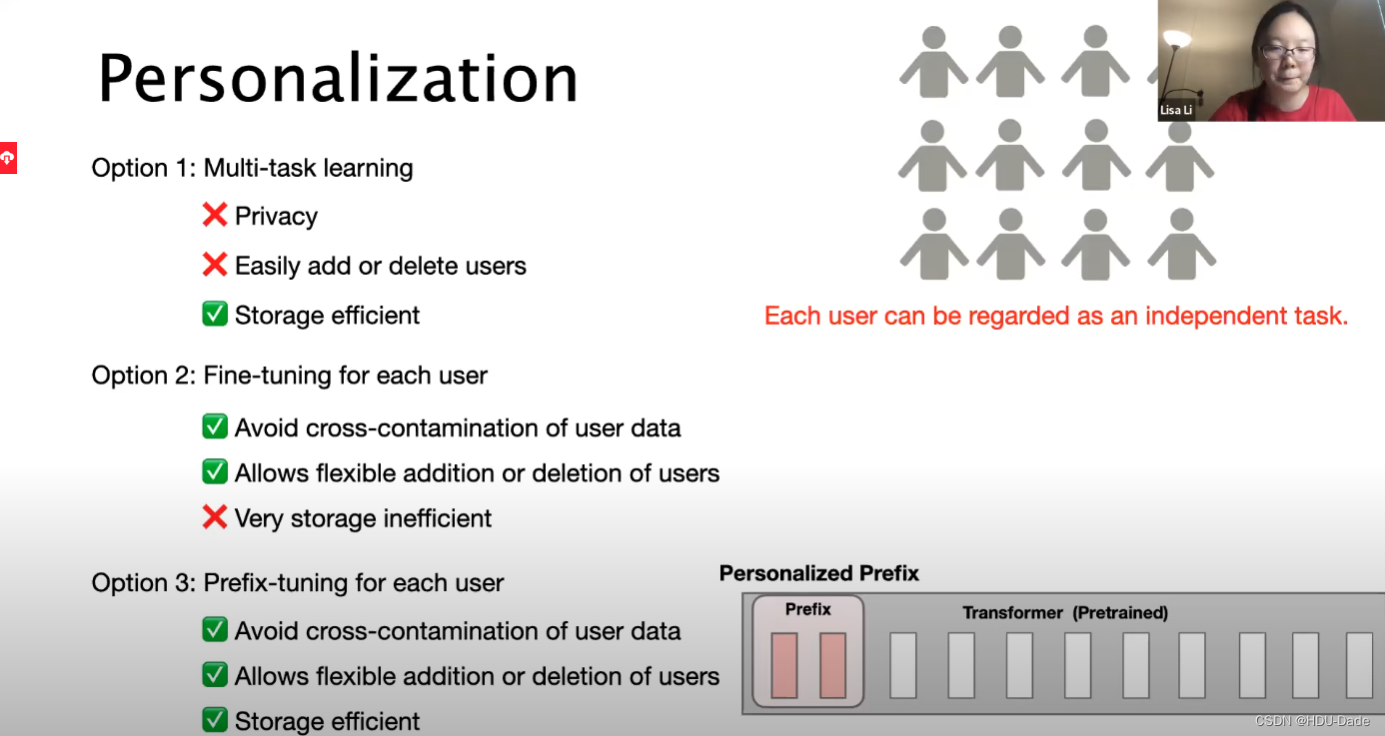
Application:Personalization