
- 1ViLBERT:视觉语言多模态预训练模型_视觉-语言多模态训练模型
- 2深度之眼Paper带读笔记NLP.11:FASTTEXT.Baseline.06_in this work, we explore ways to scale thesebaseli
- 3matlab accumarray_32个实用matlab编程技巧
- 4【科研新手指南2】「NLP+网安」相关顶级会议&期刊 投稿注意事项+会议等级+DDL+提交格式_ccs投稿须知文件
- 5spring-boog-测试打桩-Mockito_org.mockito.exceptions.base.mockitoexception: chec
- 6Git将当前分支暂存切换到其他分支_如何暂存修改切换分支git
- 7solidity实现智能合约教程(3)-空投合约
- 8上位机图像处理和嵌入式模块部署(qmacvisual寻找圆和寻找直线)
- 930天拿下Rust之错误处理
- 10基于springboot的在线招聘平台设计与实现 毕业设计开题报告_招聘app的设计与实现的选题背景怎么写
【C++】哈希的应用:位图(bitset)和布隆过滤器(bloomfilter)_bitsetbloomfilter
赞
踩
一、位图
1.1 前言(bitset 的提出)
哈希是一种映射的思想。
先来看一道面试题:
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何 快速判断 一个数是否在这40亿个数中。
首先想到的解法可能有这几种:
解法1:遍历40亿个数,O(N)
解法2:先排序,快排 O(Nlog2N),再利用二分查找 O(log2N)
解法3:40亿个数放进 set / unordered_set 中,然后查找 key 在不在。
思考:上面的解法看似可行,实际上有很大的问题:内存消耗太大。同时面试官也不会很满意。
40亿个整数要占用多少空间?大约16GB
- 1GB = 1024 * 1024 * 1024 = 210 * 210 * 210 = 230 (大约是10亿 byte)
- 4GB = 4 * 230 = 232 byte(大约是42亿9九千多万 byte)
- 40亿个 unsigned int 整数 = 40亿 x 4字节 = 160亿字节 = 16 x 10亿字节 ≈ 16GB
这40亿个数据是放在文件中的,要对这40亿个整数进行排序:
难道在内存中开一个16GB空间的数组存放这些数据吗?显然不太现实,内存消耗太大,玩不起。
虽然归并排序可以对文件中的数据做外排序,但是效率很低,磁盘读写速度是很慢的,即使在文件中对40亿个数据排完了序,但是很难去算数据的下标位置,不能进行二分查找,那意义也不大了。
解法三,把数据放进 set / unordered_set 中,因为其底层是链式结构,除了存数据,还要存指针,所以附带的内存消耗更大,需要的空间比 16GB 还要大很多,更不可行。
所以我们一定要从 节省内存的角度 出发去思考,才能更好的解决问题。同时题目要求是:快速判断。
这里是判断一个数在不在数据集中,仔细想一想,也并不需要把这个数存起来,只需要有个标记去 标记某个数在不在 就行了。(就好比统计数组中数字的出现次数,我们用数的数值作为下标,在该下标处存储出现的次数,也并没有把数存下来)
标记一个数在不在,最小的标记单位是比特位(0 / 1),我们用一个比特位标记一个数,这样就节省空间了。
解法4:位图
某个数是否在给定的数据集中,有两种结果:「存在」或「不存在」,刚好是两种状态,那么可以使用一个二进制比特位来代表某个数是否存在的信息,比如二进制比特位为 1 代表存在,为 0 代表不存在。
我们把数据集的所有数用「直接定址法」映射到一张二进制表中,并用二进制值(1 / 0)标记其是否存在,这样每个数都有「唯一的」映射位置,不会出现哈希冲突。如果要判断某个数在不在数据集中时,只需要找到这个数映射到表中的位置,然后查看该位置的比特位为 1 还是 0
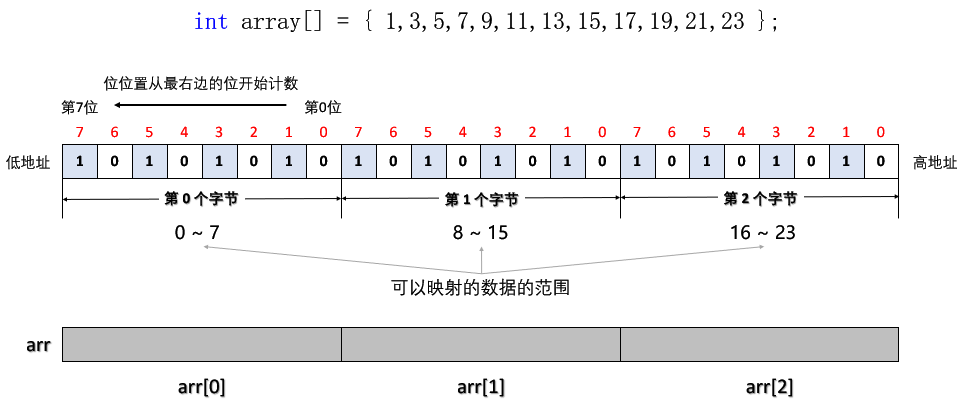
我们是用每个「无符号整数 unsigned int 的值」来映射其哈希位置(比如 25,就映射到第 25 个二进制位):
- 因为 unsigned int 的 取值范围 是 0 ~ 232 - 1,所以一个无符号整数最小值为 0,最大值为 232 - 1(4,294,967,295,42亿9千多万)。
- 所以我们要开有 232 个二进制位的表,才能映射完所有的无符号整数,但实际上只能开到有 232 - 1 个二进制位的表(因为 size_t 最大为
0xffffffff),也就是开 ( 232 - 1 ) / 8 个字节 ≈ 5亿多个字节 ≈ 0.5GB = 512MB 的内存空间。
一个 bit 位标记一个 unsigned int 值,512GB 的内存就可以标记完42亿9千多万个整数的存在状态了,极大的节省了内存。
注意:位图并没有把整个数据集存储起来,而是将所有数映射到哈希表中,在映射的哈希位置上标记这个数在不在。
1.2 位图的概念
面对判断一个数在不在海量数据中的问题,红黑树和哈希表查找效率是挺高的,但是我们光把海量数据存起来够呛,同时红黑树和哈希表附带的内存消耗,所需空间更大,基于这样的原因,提出了位图这种数据结构。
template <size_t N> class bitset;
// 位图存储位(只有两个可能值的元素:0 或 1,真或假,...)
- 1
- 2
位图(bitset)是一种常用的数据结构,常用在给一个很大范围的数,判断其中的一个数是不是在其中。在索引、数据压缩方面有很大的应用。
位图是用数组实现的,数组的每一个元素的每一个二进制位都表示一个数据,0 表示该数据不存在,1 表示该数据存在。
位图最大的特点就是:快、节省空间,因为它不需要存储数据集,只是标记某个数在不在这个数据集中。
1.3 位图的模拟实现
1.3.1 位图的底层结构
如图,我们开一个数组,数组的每个元素是一个 char(8个 bit 位),当然,是一个 int (32个 bit 位)也可以,只是计算数据映射的比特位的方法略有差别。
这个 0 ~ 7 是比特位的编号,比特位的规则就是这样子的,从右到左编号。
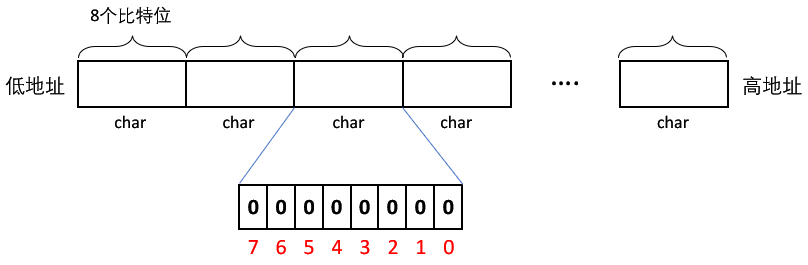
思考:如何计算这个数据映射在数组中第几个 char(字节) 中的第几个比特位上:
- 字节位置 = 数据 / 8,得出 x 映射在第几个 char 中
- 位位置 = 数据 % 8,得出 x 映射在这个 char 中的第几个比特位上
- 注意:如果数组的每个元素是一个 int,改成除以 32 就好了
比如数据 x = 10,则:
- 字节位置 = 10 / 8 = 1,说明 10 映射在第 1 个 char(字节) 中
- 位位置 = 10 % 8 = 2,说明 10 映射在第 1 个 char(字节) 中的第 2 个比特位上
位图的结构:
namespace winter { /* 位图 * N: 非类型模板参数,表示至少需要开N个比特位的存储空间 */ template<size_t N> class bitset { public: /* * 构造有N个比特位的位图,等价于要开N/8个字节(char)的空间 * 为了防止N不是8的整数倍,所以要+1,多开1个字节(char)的空间 */ bitset() { _bits.resize(N / 8 + 1, 0); } // 把数据 x 映射的比特位设置成 1,表示数据 x 存在 void set(size_t x); // 把数据 x 映射的比特位设置成 0,表示数据 x 不存在 void reset(size_t x); // 检测数据 x 映射的比特位是否为 1(即数据 x 是否存在) bool test(size_t x) const; private: vector<char> _bits; // 位数组 }; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
1.3.2 位图的一些成员函数
① 位图的构造
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

