
- 1el-table的使用技巧(ElementUI)_el-table 的 top是什么意思
- 2【大数据Hive】hive 多字段分隔符使用详解_hive数据连接分隔符
- 3sqlserver中的循环遍历(普通循环和游标循环)_sqlserver 循环
- 4出现Error: Could not open client transport with JDBC Uri: jdbc:hive2://node02:10000/;user=root:..怎么办?
- 5生命在于学习——未授权访问漏洞_rabbitmq漏洞
- 6让GPT成为护理专家 - 护士的工作如此简单_usage of gradio.inputs is deprecated, and will not
- 7mysql删除语句-delete_mysqldelete删除语句
- 8【无标题】_大厂机试是acm吗
- 9寒假学习笔记_使用定时器2产生1s的定时,定时器时钟tim_clk为72m。要求不使用预分频寄存器,
- 10智能制造:MES实现自动化、数字化、智能化管理_mes智能化生产
Spark项目的创建
赞
踩
前述概要:本次项目配置环境:IDEA 2021.2.3 Maven 3.8.3
第一步:建立一个Maven项目,创建出文件最原始的目录结构
依次点击File->New->Project
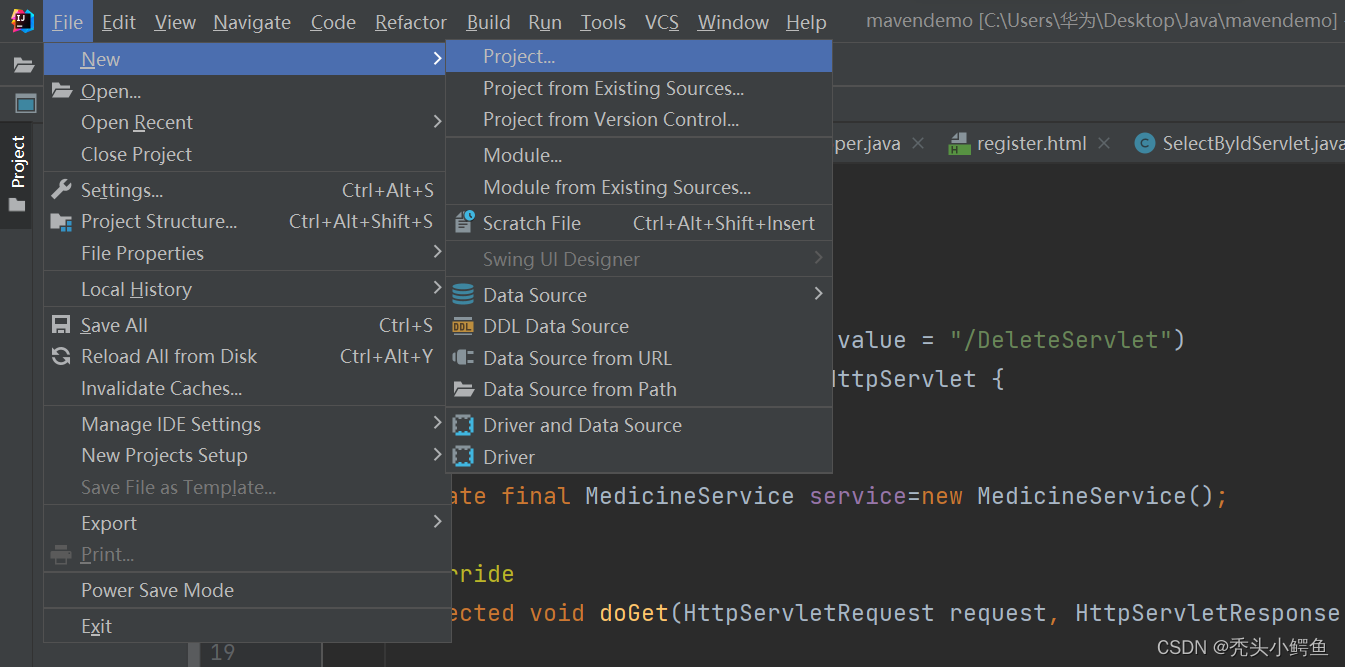
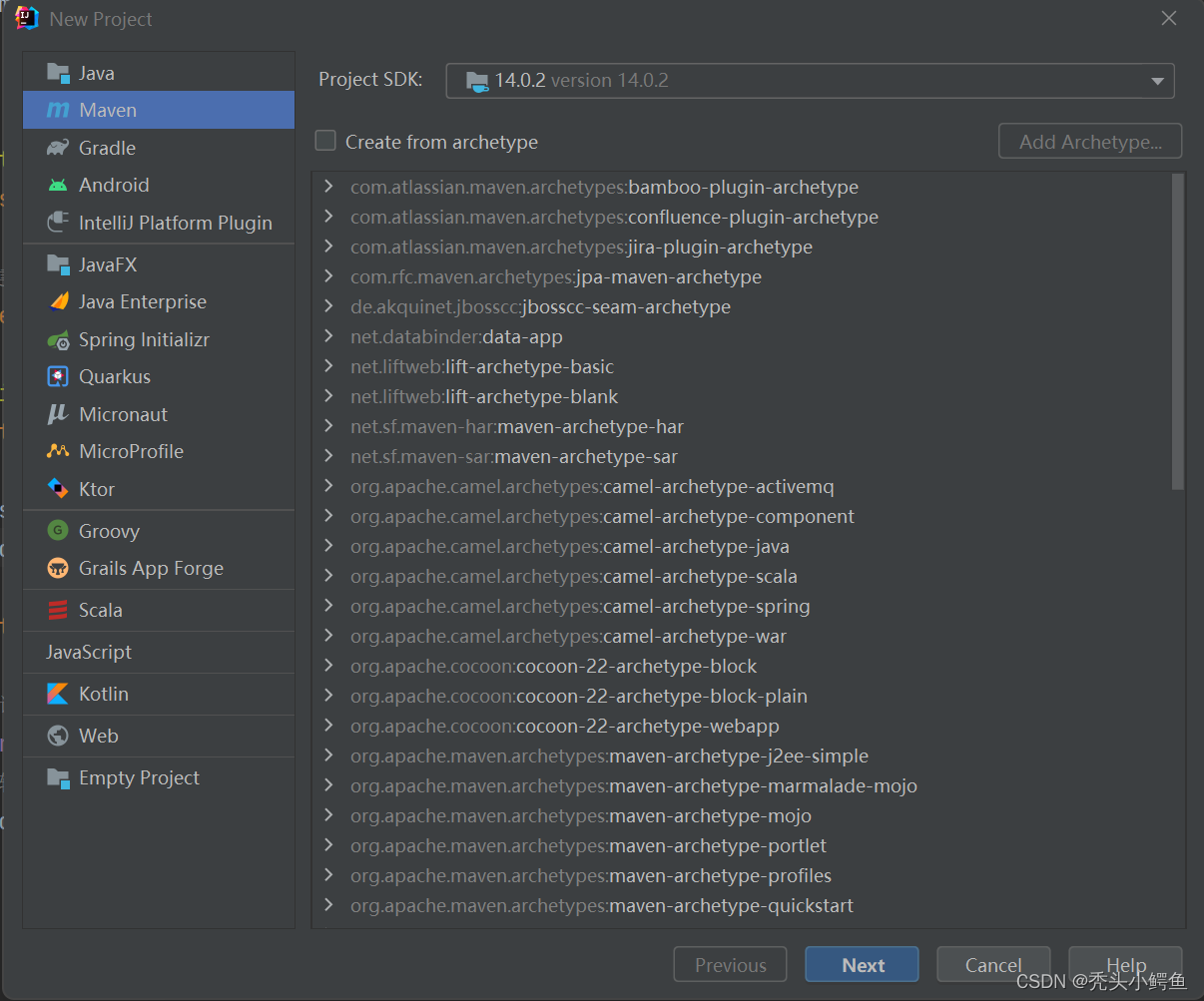
这一步JDK版本,选择14.0.2,然后依次点击Next->“给项目起名字和确定保存路径”->Finish,
(此处注意必须选择jdk14,否则会出现不可检测的错误),如图操作。
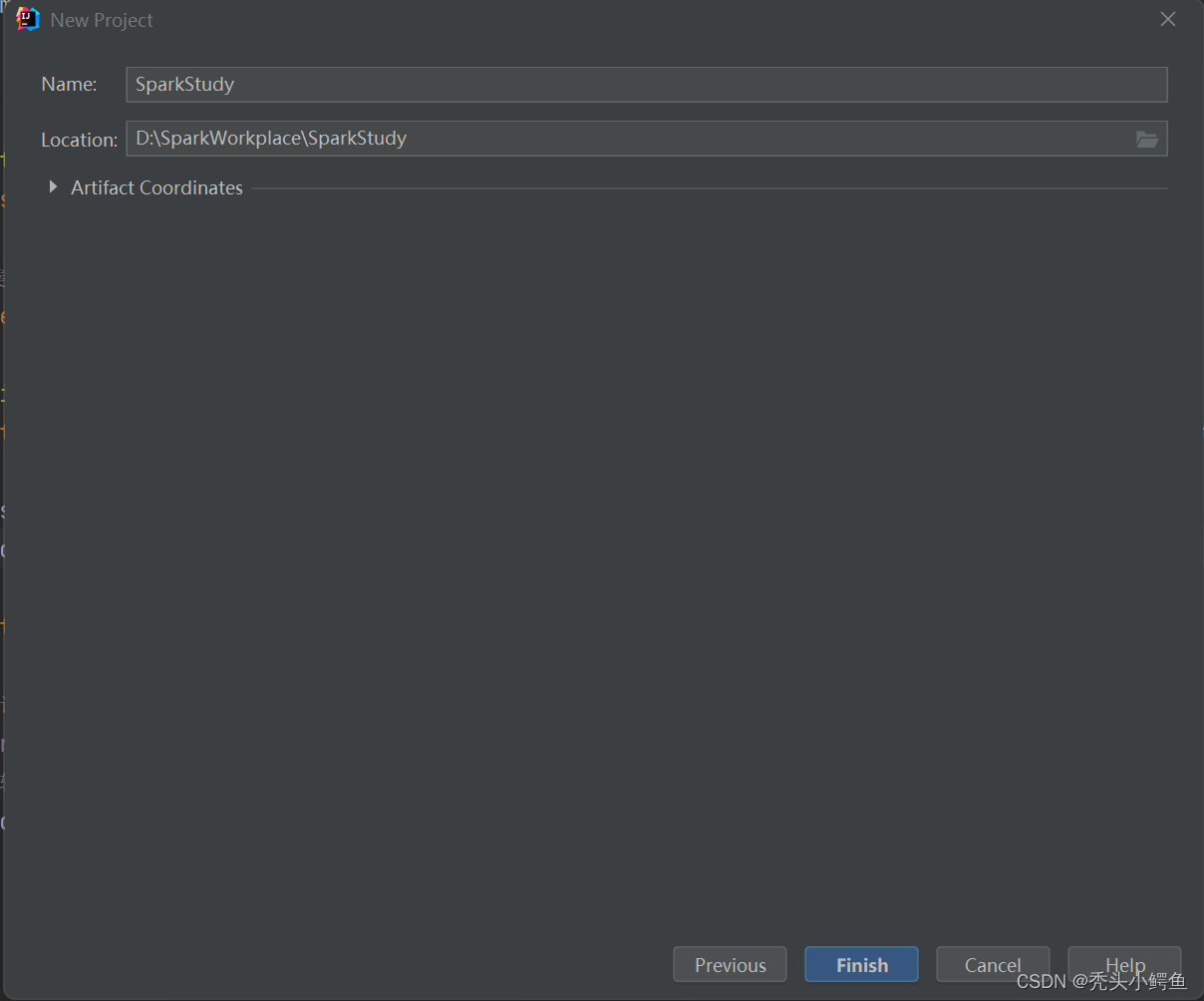
可以看到新建成的文件结构如图所示(左),然后删除src文件,新的文件结构(右)如下。


第二步:对项目进行文件目录配置
主要是添加需要的文件以及对文件进行相关标记
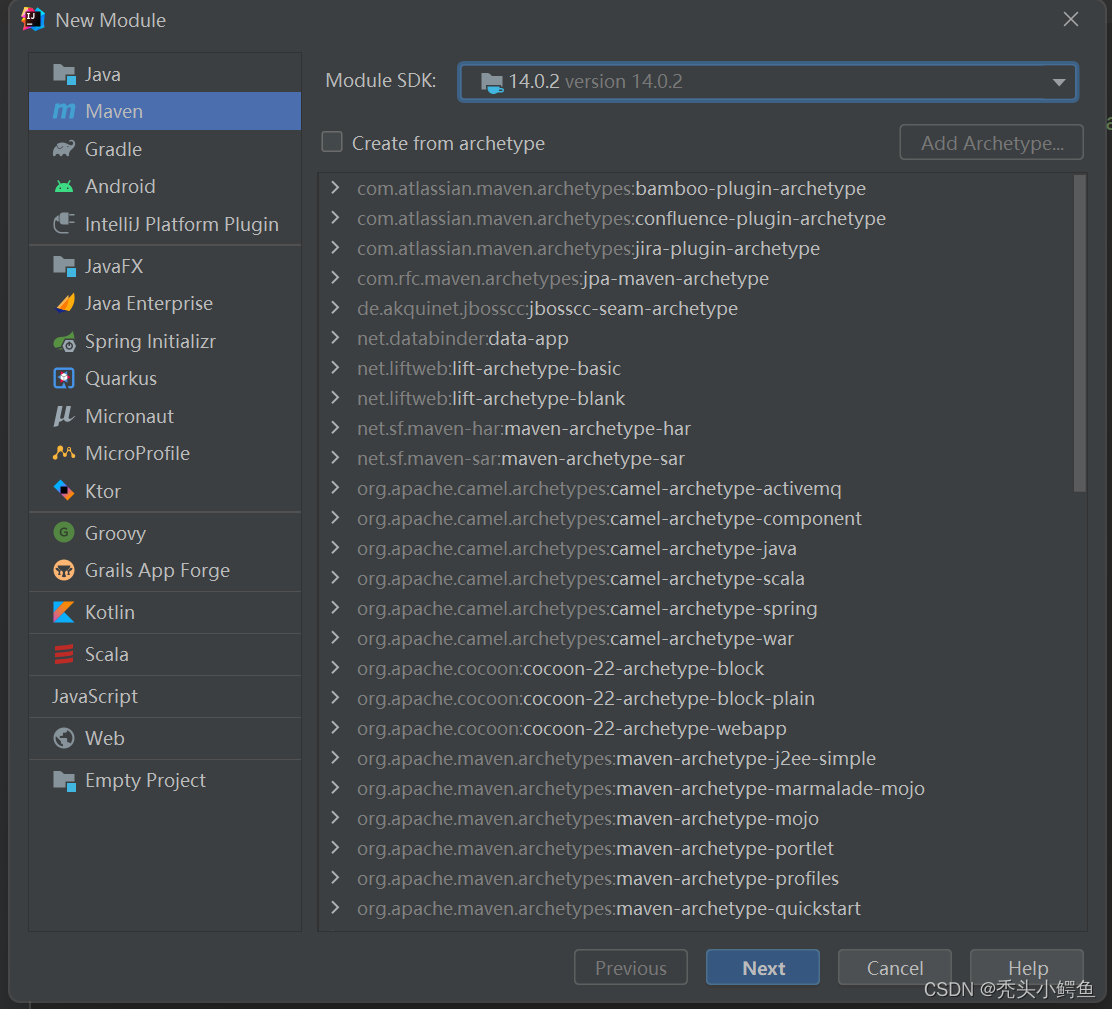
依次点击项目包->New->Module
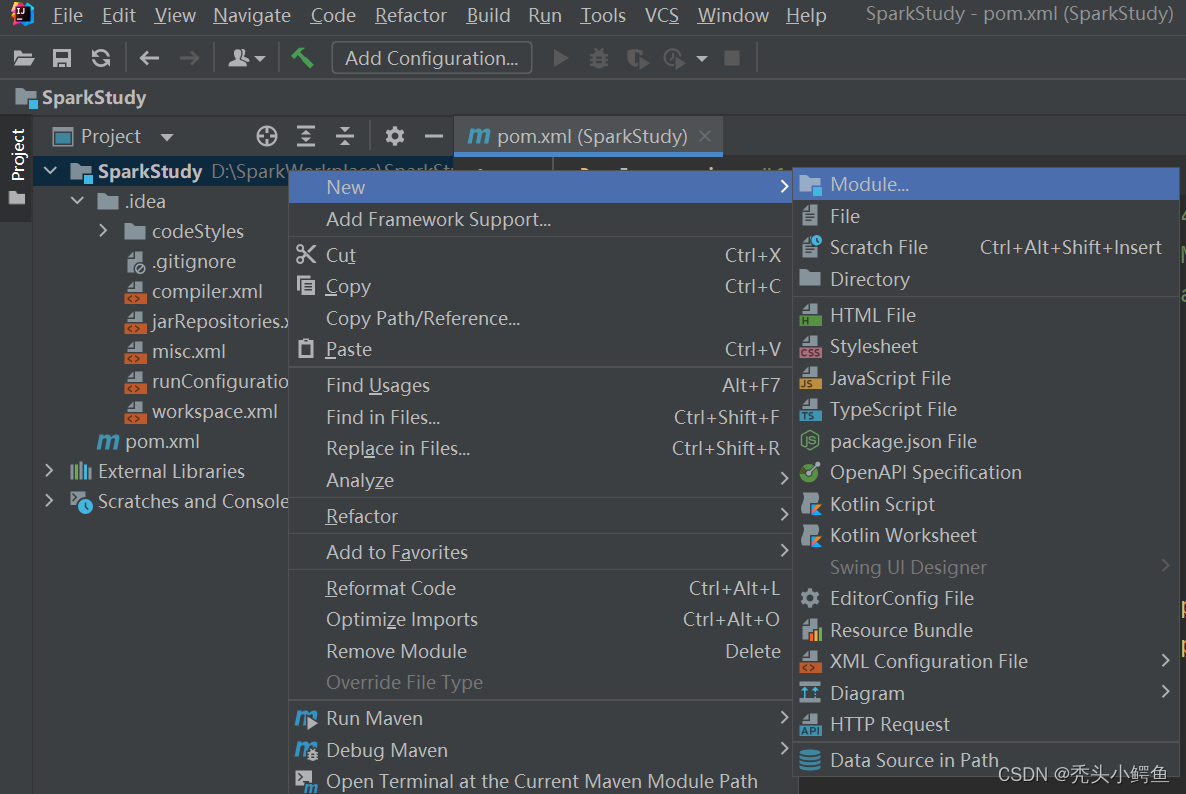
添加Maven模块,注意JDK从始至终都选择14版本,点击Next->“Parent选择SparkStudy”->”确定Parent项目名字和保存路径”->Finish,如图操作。
(此处补充点:Parent项目叫聚合项目,简单理解为创建Maven父项目的过程)
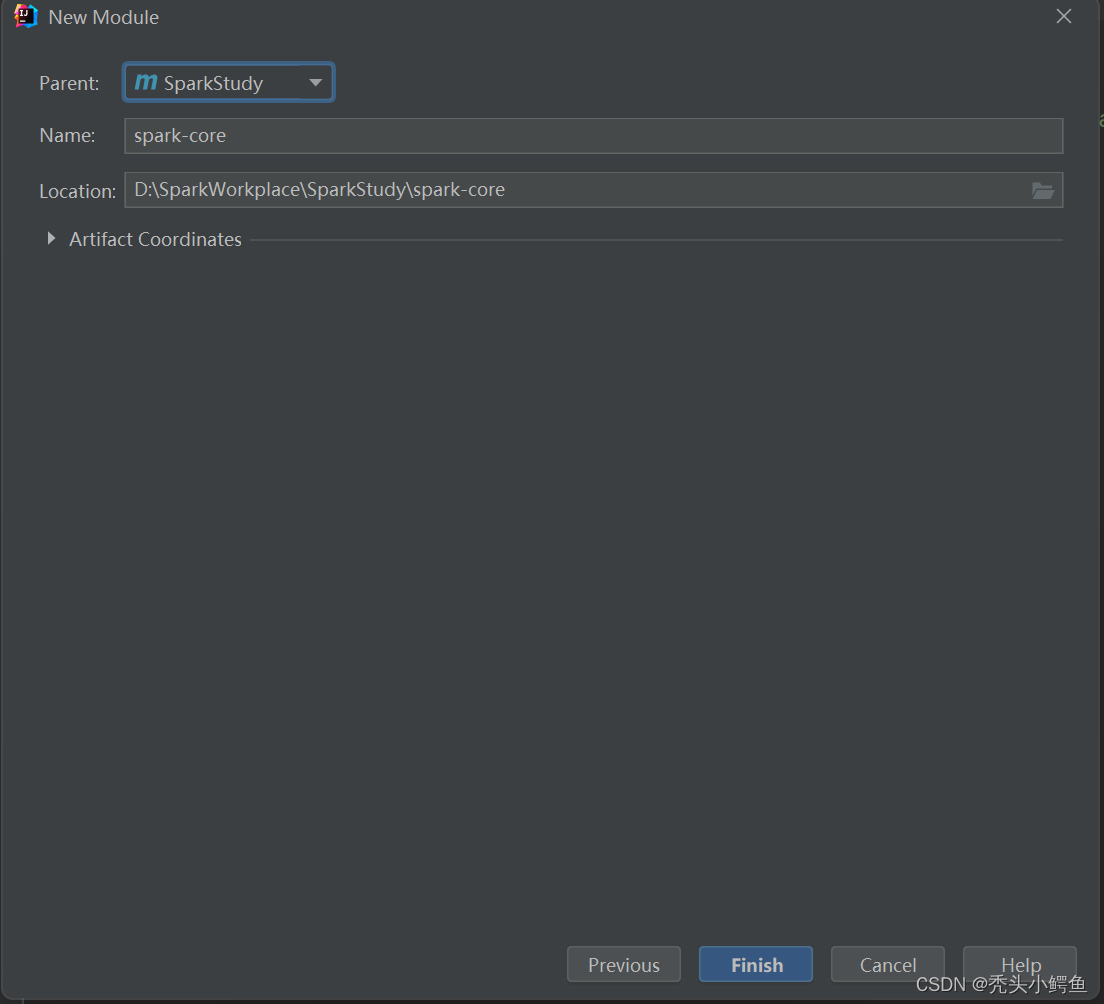
此时项目结构如图所示。

接下来给此时的项目中有关文件添加标记,涉及到两个文件,分别是src/main/java以及src/main/resource,对第一个文件添加Source Root标记,第二个文件添加Resource Root标记。
注意:由于IDEA版本问题,会存在上一步完成后已经对文件有过标记,是IDEA自动生成,此时的文件包长这样,如图,若不是,请完成以下两个步骤。
此时项目结构如图所示,注意与前一张图的区别,文件前图标有所变化。

依次点击java->Mark Directory as->Source Root,如图操作。

依次点击resource->Mark Directory as->Resource Root,如图操作。

第三步:添加Scala插件
由于Spark项目需要特定插件,故此时需要下载一个Plugin,名字叫做Scala。
依次点击File->Setting打开IDEA设置,如图操作。

”搜索plugin”->”搜索Scala“->选择Scala,点击Install->Apply->OK,如图操作。
(注意两个搜索框的位置)

此时开始进行项目结构相关配置,选择File->Project Structure,打开项目结构,如图操作。
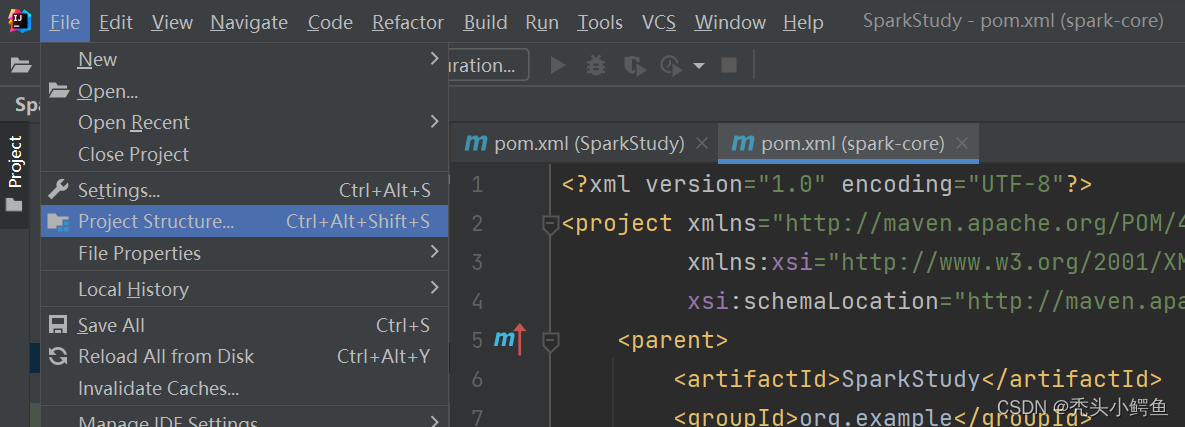
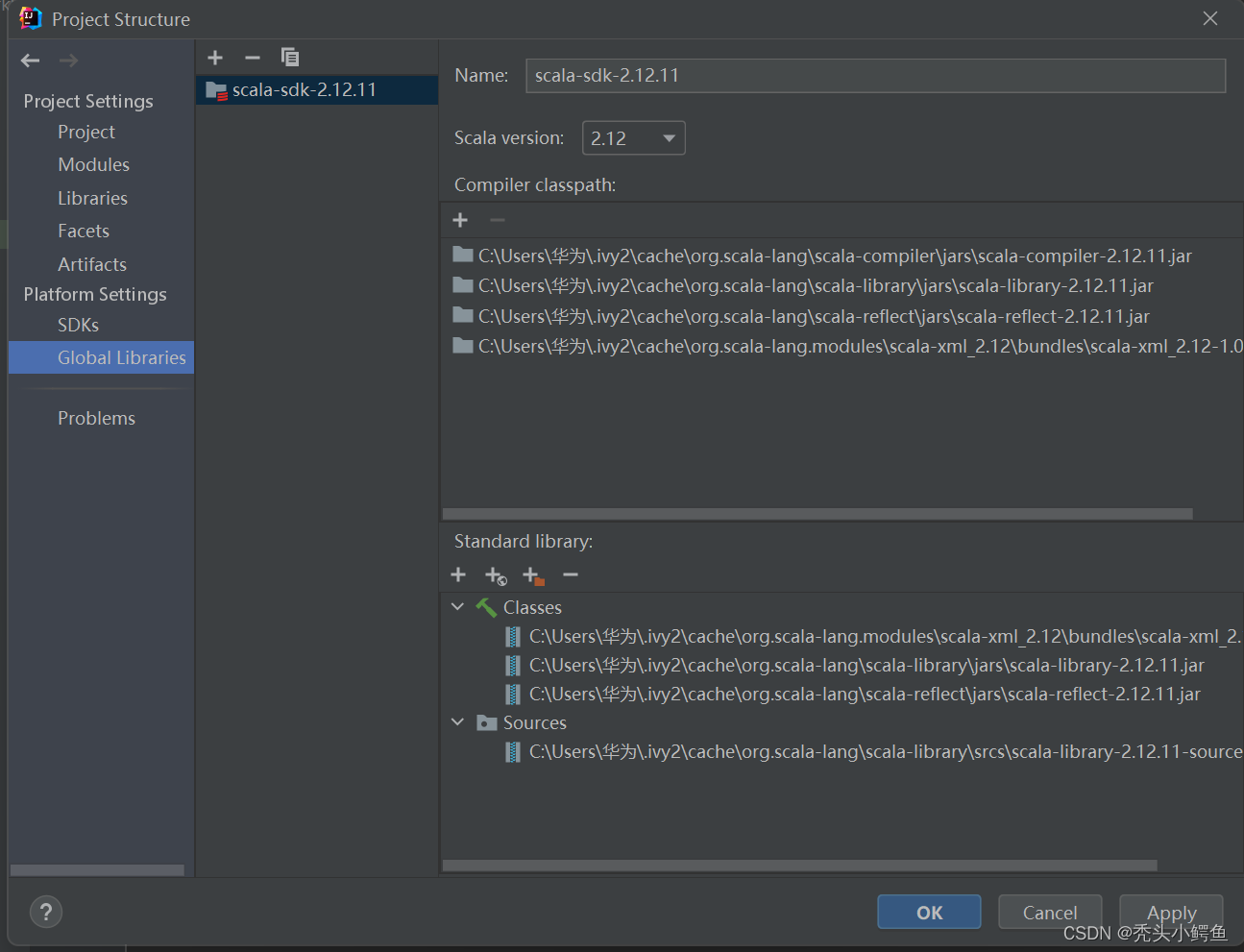
依次点击Global Libraries->“+”->Scala SDK

依次点击Download->“选择2.12.11版本“->OK,等待下载,

下载完成后,选择spark-core->OK
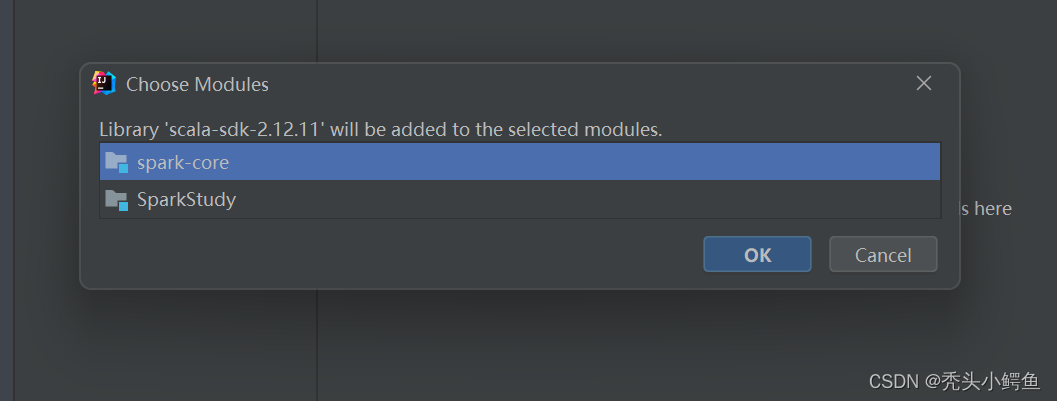
如图是Scala配置好的样子,注意左右版本是否一致,完成后点击Apply->OK。
第四步:添加项目框架支持
选择spark-core,点击Add Framework Support

注意:此处由于IDEA版本问题,出现问题,在添加框架时没有找到Scala,如下图一,此时按照图二进行操作,删除该依赖,然后点击Apply->OK,再回归正题,继续接下来的配置。
(若在配置过程中没有下情况,则可以跳过该步骤)

图一

图二
开始添加框架,依次点击Scala->OK,注意选择版本号必须是2.12.11

第五步:Maven配置Spark依赖
由于项目由两个pom.xml文件,所以注意选择SparkStudy/spark-core/pom.xml,添加以下代码,如图所示。
(首次下载比较慢,需要等待,由于IDEA设置的问题,所以会自动下载,如没有配置过相关设置,则在添加代码后右下角会有弹框,点击import change即可)
<dependencies>
<dependency>
<groupId>org,apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
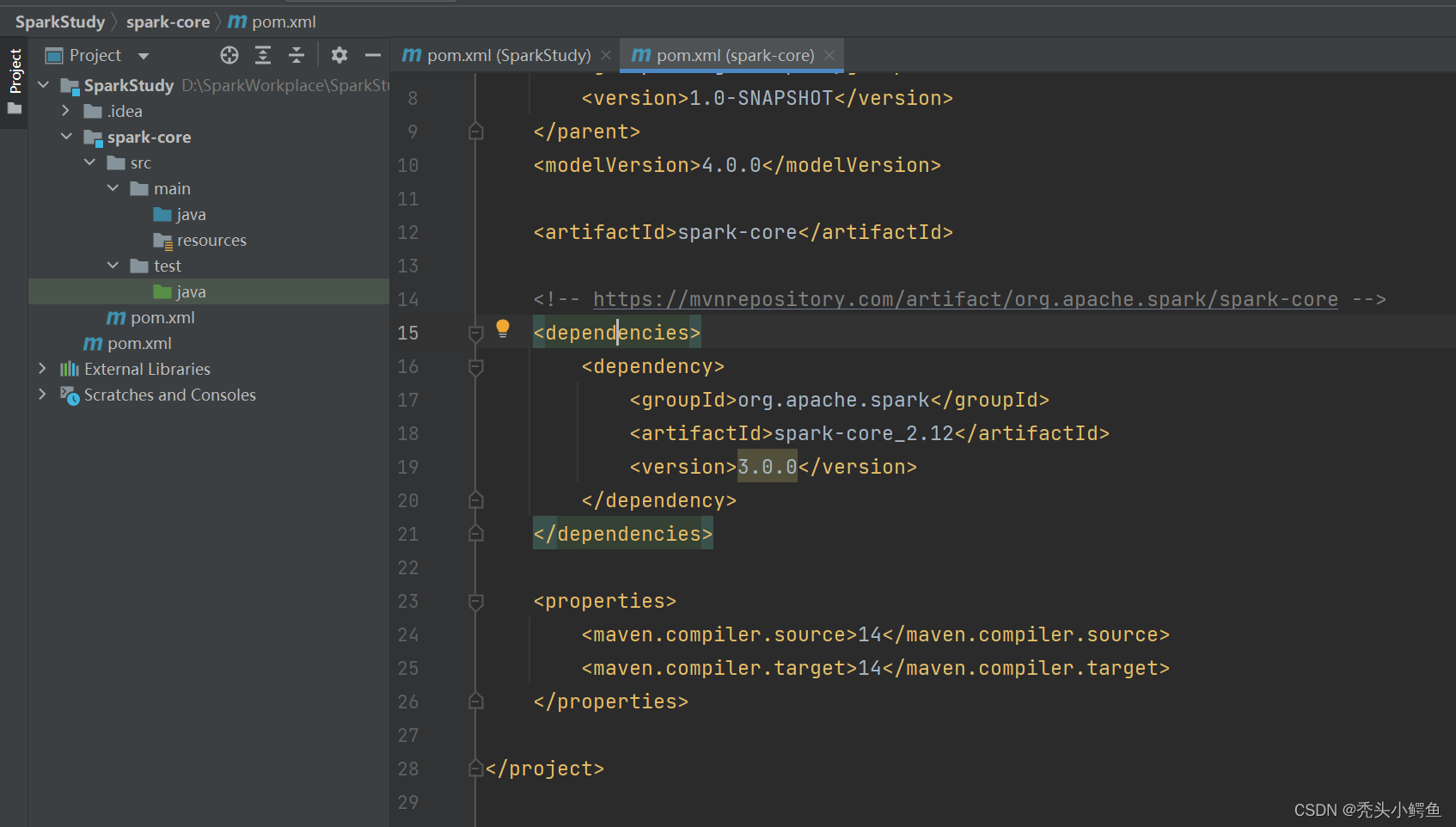
注意:此处如果出现maven找不到对应spark的jar包的情况,可以参考下面的解决方式。
(若此方式无法解决问题需要自行查找解决方案)
maven的配置路径需要一致,如图所示,按照自己存储的位置做出相应更改。

第六步:创建一个class执行并验证
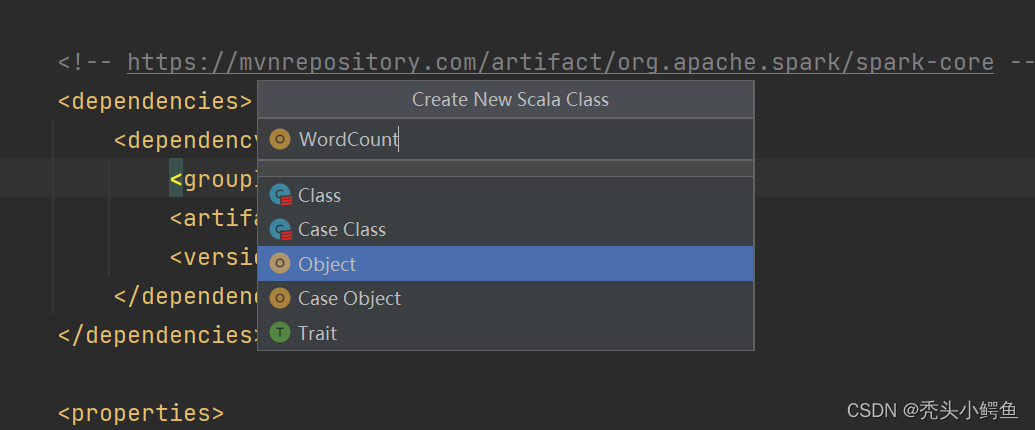
在src/main/java里创建Scala Class,如图操作。

选择Object->输入类名->enter
输入代码,完整代码如下:(代码中路径根据自己的情况进行修改)
- import org.apache.spark.rdd.RDD
- import org.apache.spark.{SparkConf, SparkContext}
- object WordCount {
- def main(args: Array[String]): Unit = {
- //0. 建立和Spark框架的连接,创建 Spark 运行配置对象,获取Spark上下文
- val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
- val sc = new SparkContext(sparkConf)
- //1.读取文件,获取一行一行的数据
- val lines: RDD[String] = sc.textFile("D:\\datas\\1.txt")
- //2. 将一行数据进行拆分,形成一个一个的单词(分词),扁平化,将整体拆成个体的操作
- //“hello world” => hello, world
- val words: RDD[String] = lines.flatMap(_.split(" "))
- //3. 将单词进行结构的转换,方便统计,word => (word, 1)
- val wordToOne: RDD[(String, Int)] = words.map((_, 1))
- //4.将转换后的数据进行分组聚合,相同key的value进行聚合操作,(word,1) => (word, sum)
- val wordToCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
- //5.将转换结果采集到控制台打印出来
- wordToCount.collect().foreach(println)
- //关闭连接
- sc.stop();
- }
- }

然后执行程序,在代码页右键直接点击Run“class”
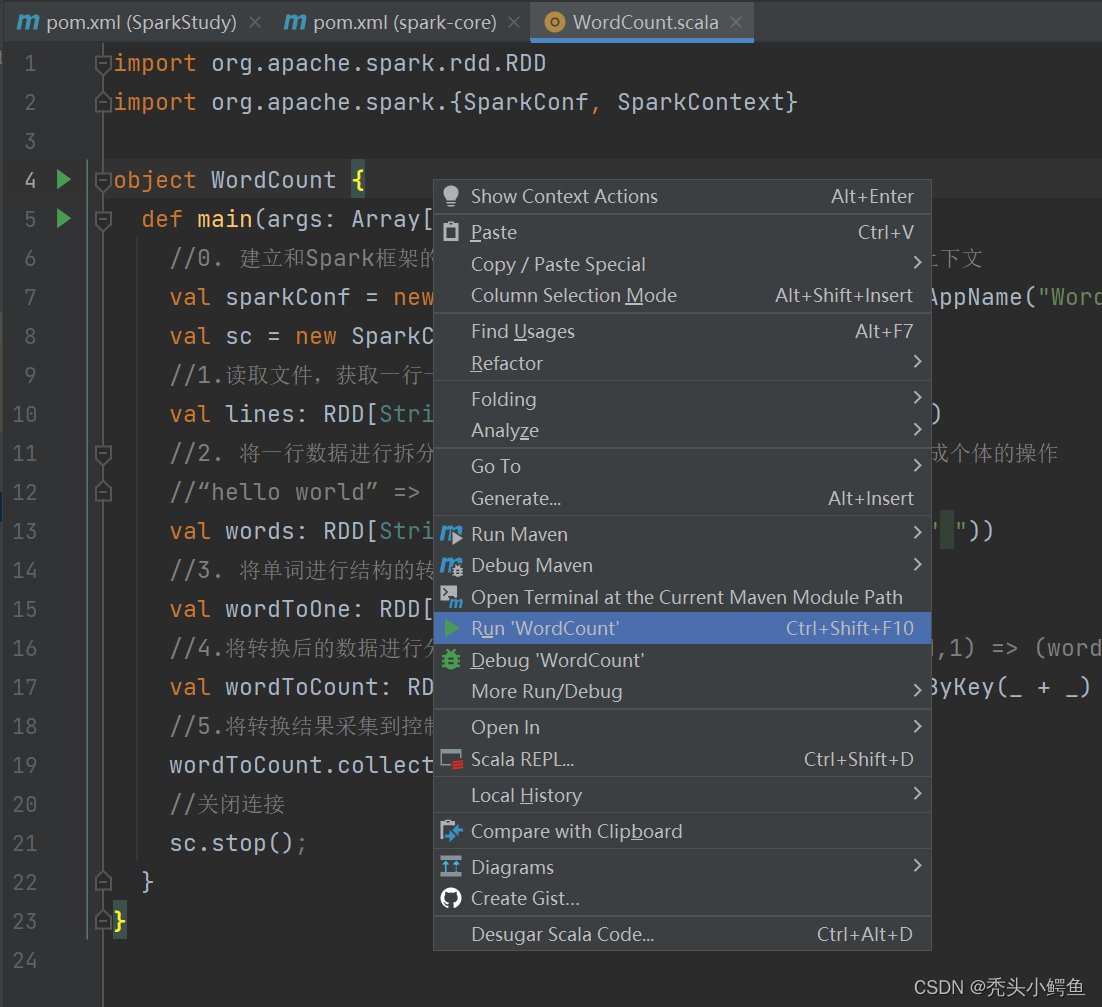
此处会出现错误,查看日志可知缺少环境变量的配置

此处会出现错误,查看日志可知路径出现问题,路径根据自己的情况进行修改

(2)打开编译器
点击Edit Configurations->找到Environment variable点击后面的小图标->点击左上角“+”->
输入变量名和bin文件地址->OK->Apply->OK,如图操作。
注意,一定要点击Apply再点击OK,否则会不生效


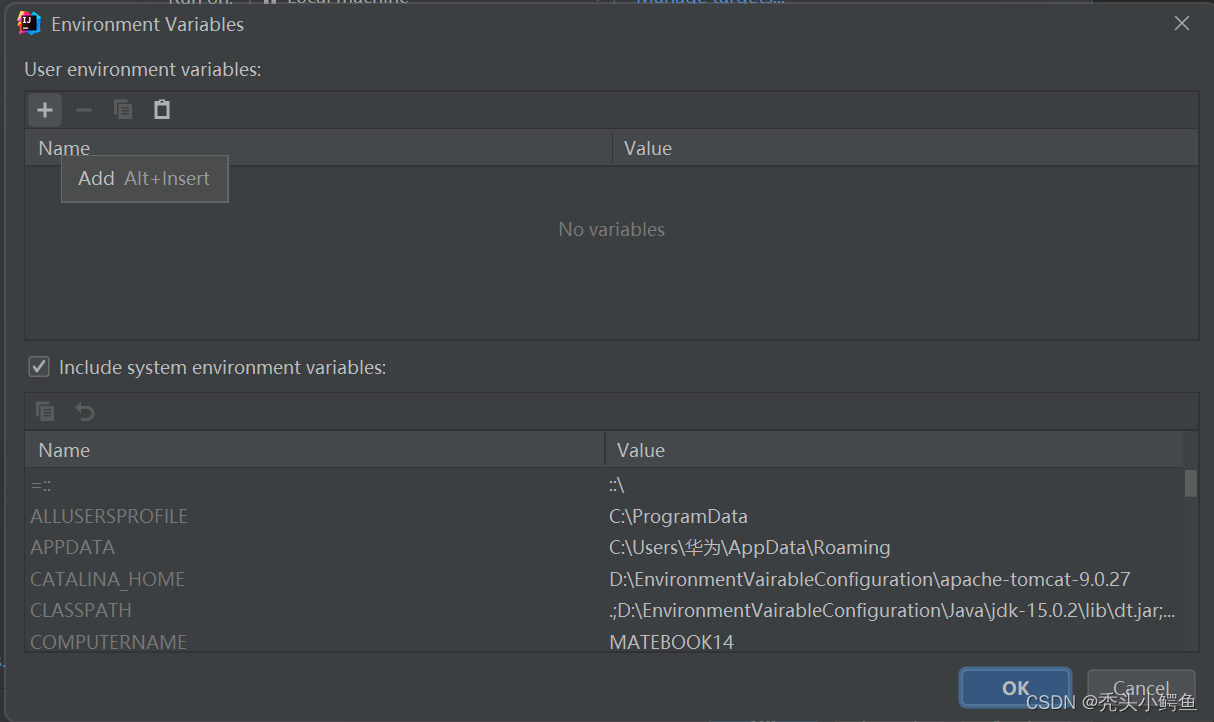
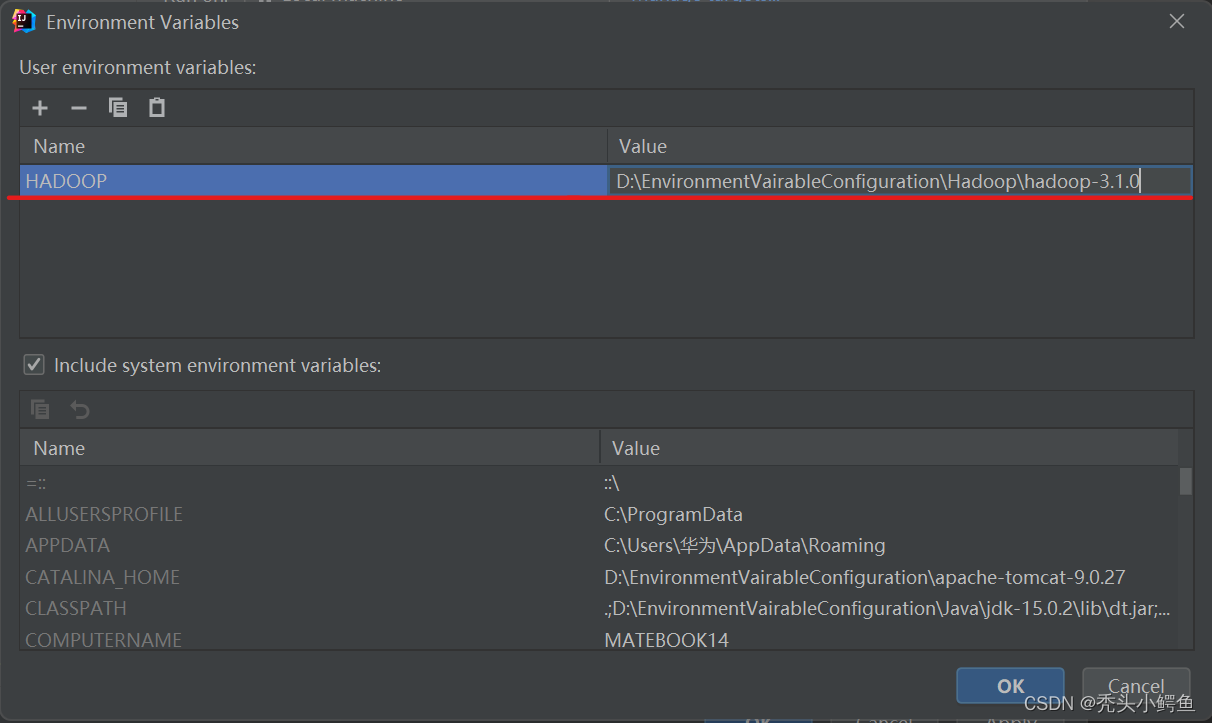
!!!注意,一定要点击Apply再点击OK,否则会不生效!!!
!!!点击顺序依次为OK->Apply->OK !!!
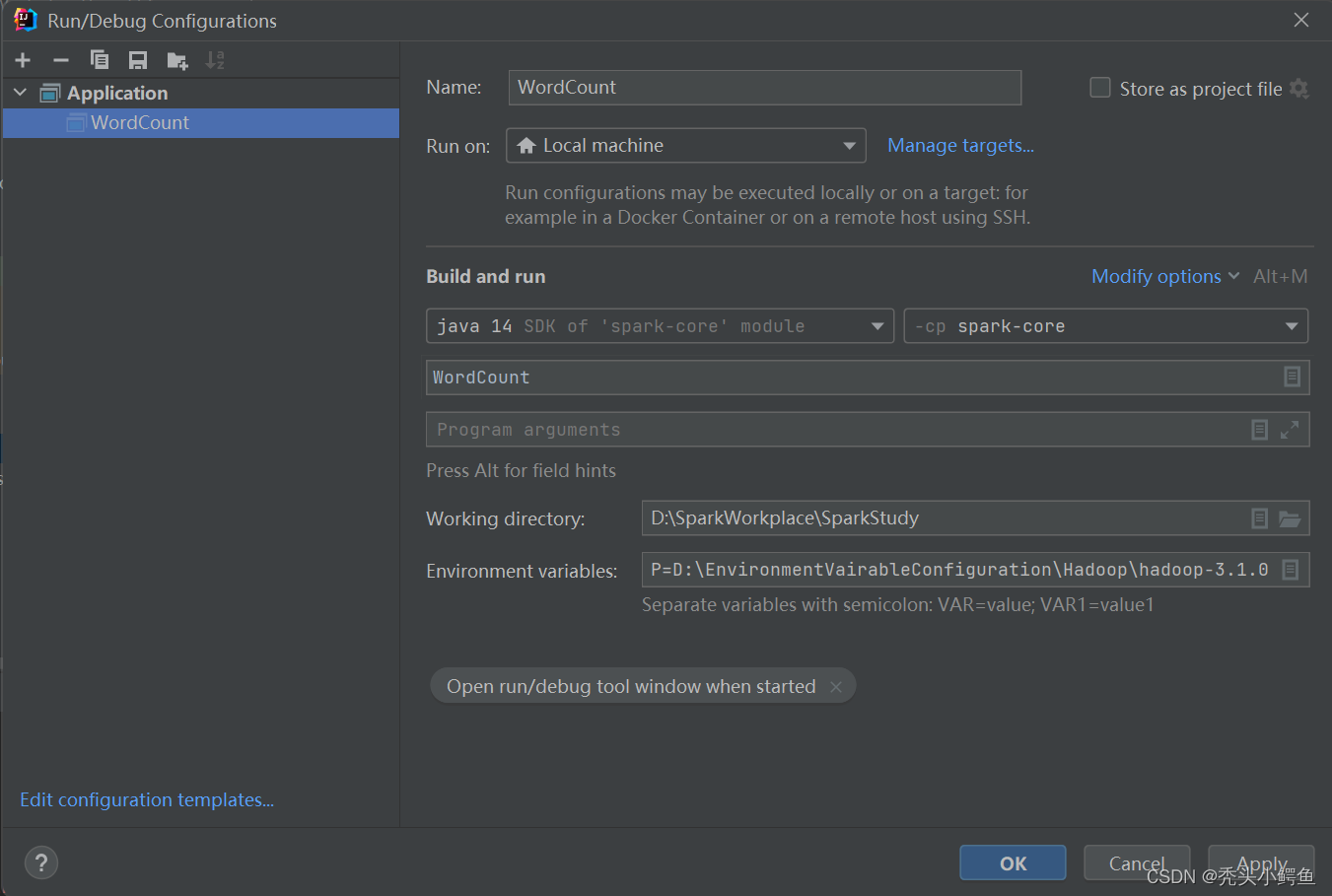
创建两个文本作为test
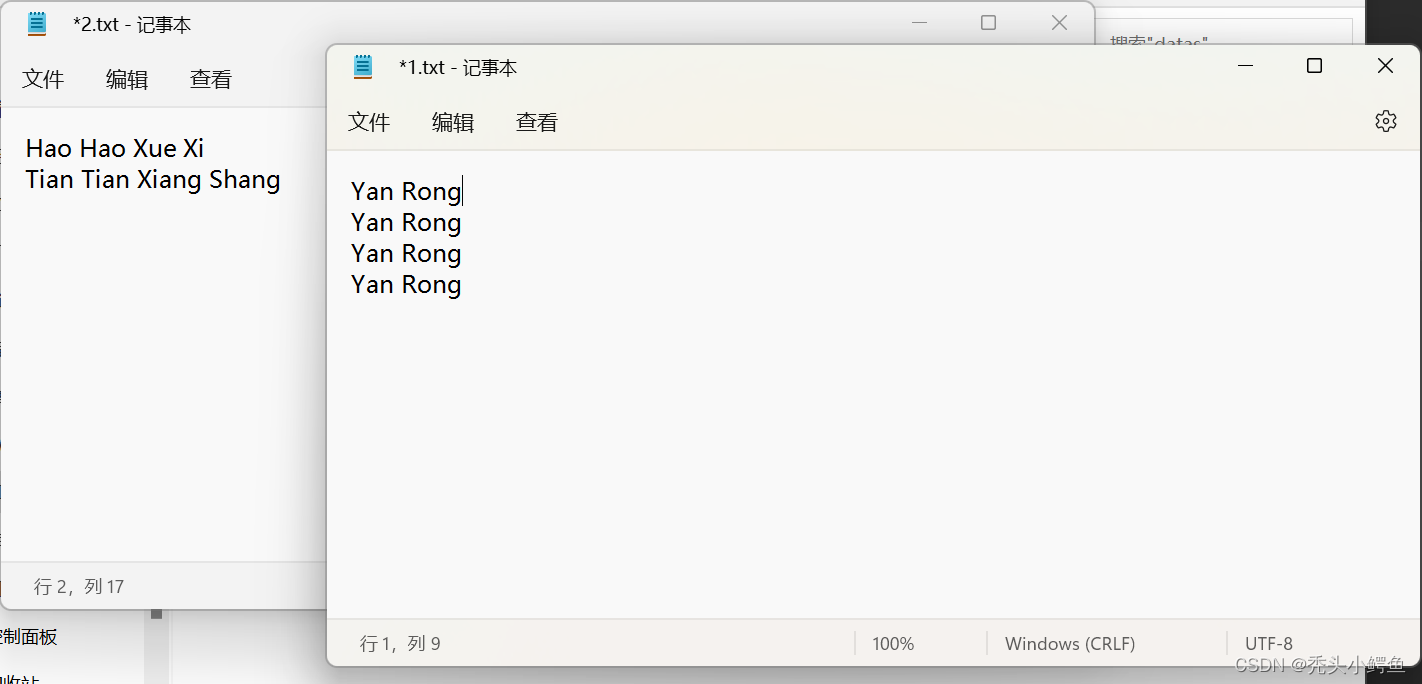
再次执行程序WordCount,查看运行结果。


不同txt执行结果不同,但是每个和预期结果做对照,发现正确,由此,一个简单的Spark项目创建完毕。

