
- 1华为云安装tomcat后配置安全组并且开放8080端口依然无法访问解决_华为云开放8080端口
- 2Java泛型详解_java 泛型单例
- 3ue中的代码运行,中文字符显示乱码,如何处理。_ue怎么完全显示字符
- 4docker部署可执行jar包_docker部署jar包
- 5检测一切,分割一切,生成一切!最强计算机视觉应用Grounded-SAM_groundingsegmentai
- 6控制el-table的列显示隐藏_el-table设置某列不显示
- 7使用IDEA从git拉取分支
- 8hadoop的介绍以及发展历史_hadoop的起源与发展简史
- 9【Github】Github里处理别人向你提交的pull requests
- 10内网渗透基石篇-- 隐藏通信隧道技术(上)_网络隧道
头歌-机器学习 第1次实验 Python机器学习软件包Scikit-Learn的学习与运用
赞
踩
第1关:使用scikit-learn导入数据集
scikit-learn包括一些标准数据集,不需要从外部下载,可直接导入使用,比如与分类问题相关的Iris数据集和digits手写图像数据集,与回归问题相关的波士顿房价数据集。 以下列举一些简单的数据集,括号内表示对应的问题是分类还是回归:
#加载并返回波士顿房价数据集(回归)load_boston([return_X_y])#加载并返回iris数据集(分类)load_iris([return_X_y])#加载并返回糖尿病数据集(回归)load_diabetes([return_X_y])#加载并返回数字数据集(分类)load_digits([n_class, return_X_y])#加载并返回linnerud数据集(多分类)load_linnerud([return_X_y])
这些标准数据集采用类字典的对象格式存储,比如.data表示原始数据,是一个(n_samples,n_features)二维数组,通过.shape可以得到二维数组大小,.target表示存储数据类别即标签。
下面我们将利用datasets加载数据集digits作为示例,如下图所示:

在命令行输入python进入python终端,>>>表示python终端提示符,输入python命令即可执行。y.[:5]表示标签的前5个数据。
本关任务
本关任务是使用scikit-learn的datasets模块导入iris数据集,并打印前5条原数据、前5条数据标签及原数据的数组大小。 即编程实现step1/importData.py 的getIrisData()函数:
from sklearn import datasetsdef getIrisData():'''导入Iris数据集返回值:X - 前5条训练特征数据y - 前5条训练数据类别X_shape - 训练特征数据的二维数组大小'''#初始化X = []y = []X_shape = ()# 请在此添加实现代码 ##********** Begin *********##********** End **********#return X,y,X_shape
测试说明
本关的测试文件是step1/testImportData.py该代码负责对你的实现代码进行测试,注意step1/testImportData.py 不能被修改,该测试代码具体如下:
import importDataX,y,X_shape = importData.getIrisData()print(X)print(y)print(X_shape)
测试函数将直接调用step1/importData.py 的getIrisData()得到实际输出,平台通过比较预期输出与实际输出来判断createSVMmodel函数是否实现正确。
- from sklearn import datasets
- def getIrisData():
-
- '''
- 导入Iris数据集
- 返回值:
- X - 前5条训练特征数据
- y - 前5条训练数据类别
- X_shape - 训练特征数据的二维数组大小
- '''
- #初始化
- X = []
- y = []
- X_shape = ()
-
- # 请在此添加实现代码 #
- #********** Begin *********#
- iris = datasets.load_iris()
- X = iris.data[:5]
- y = iris.target[:5]
- X_shape = iris.data.shape
-
- #********** End **********#
-
- return X,y,X_shape
第2关:数据预处理 — 标准化
本关任务
在前一关卡,我们已经学会了使用sklearn导入数据,然而原始数据总是比较杂乱、不规整的,直接加载至模型中训练会影响预测效果。本关卡,将学会使用sklearn对导入的数据进行预处理。
相关知识
原始数据存在的几个问题:不一致、重复、含噪声、维度高。数据挖掘中,数据预处理包含数据清洗、数据集成、数据变换和数据归约几种方法,在这里不过多叙述预处理方法细节,接下来将简单介绍如何通过调用sklearn中的模块进行数据预处理。
sklearn.preprocessing 模块提供很多公共的方法,将原始不规整的数据转化为更适合分类器的具有代表性的数据。一般说来,使用标准化后的数据集训练学习模型具有更好的效果。
数据标准化的方法有很多种,常用的有“最小—最大标准化”、“Z-score标准化”等等。经过上述标准化处理,各属性值都处于同一个数量级别上,可以进行综合数据分析。
Z-score 标准化 这种方法基于原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。将A的原始值x使用Z-score标准化到x'。
Z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况,其公式为:新数据=(原数据-均值)/标准差
sklearn.preprocessing.scale函数,可以直接将给定数据进行标准化。

标准化处理后数据的均值和方差:

sklearn.preprocessing.StandardScaler类实现了Transformer接口,可以保存训练数据中的参数(均值mean_、缩放比例scale_),并能将其应用到测试数据的标准化转换中。

将标准化转换器应用到新的测试数据:

min-max 标准化
min-max标准化方法是对原始数据进行线性变换。设minA和maxA分别为属性A的最小值和最大值,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x',其公式为:新数据=(原数据-极小值)/(极大值-极小值)
sklearn.preprocessing.MinMaxScaler将属性缩放到一个指定的最大和最小值(通常是1-0)之间。
MinMaxScaler中可以通过设置参数feature_range=(min, max)指定最大最小区间。其具体的计算公式为:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))X_scaled = X_std * (max - min) + min

将标准化缩放应用到新的测试数据:

编程要求
本关任务希望对于California housing数据集进行标准化转换。 代码中已通过fetch_california_housing函数加载好了数据集,California housing数据集包含8个特征,分别是['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude'],可通过dataset.feature_names访问数据具体的特征名称,通过在上一关卡的学习,相信大家对于原始数据的查看应该比较熟练了,在这里不过多说明。
本次任务只对California housing数据集中的两个特征进行操作,分别是第一个特征MedInc,其数据服从长尾分布;第6个特征AveOccup,数据中包含大量离群点。
本关具体分成为几个子任务: 1.使用MinMaxScaler对特征数据X进行标准化转换,并返回转换后的特征数据的前5条。 要补充的代码块如下:
def getMinMaxScalerValue():'''对特征数据X进行MinMaxScaler标准化转换,并返回转换后的数据前5条返回值:X_first5 - 数据列表'''X_first5 = []# 请在此添加实现代码 ## ********** Begin *********## ********** End **********#return X_first5
2.使用scale对目标数据y进行标准化转换,并返回转换后的前5条数据。 要补充的代码块如下:
def getScaleValue():'''对目标数据y进行简单scale标准化转换,并返回转换后的数据前5条返回值:y_first5 - 数据列表'''y_first5 = []# 请在此添加实现代码 ## ********** Begin *********## ********** End **********#return y_first5
3.使用StandardScaler对特征数据X的进行标准化转换,并返回转换后的均值和缩放比例值。 要补充的代码块如下:
def getStandardScalerValue():'''对特征数据X进行StandardScaler标准化转换,并返回转换后的数据均值和缩放比例返回值:X_mean - 均值X_scale - 缩放比例值'''X_mean = NoneX_scale = None# 请在此添加实现代码 ##********** Begin *********##********** End **********#return X_mean,X_scale
测试说明
本关卡的测试数据来自./step4/testDataPreprocess.py文件,平台将比对您所编写函数的返回值与正确的数值,只有所有数据全部计算正确才能进入下一关。
- from sklearn.preprocessing import MinMaxScaler
- from sklearn.preprocessing import scale
- from sklearn.preprocessing import StandardScaler
- from sklearn.datasets import fetch_california_housing
- '''Data descrption:The data contains 20,640 observations on 9 variables.This dataset contains
- the average house value as target variableand the following input variables (features):
- average income,housing average age, average rooms, average bedrooms, population,
- average occupation, latitude, and longitude in that order.
- dataset : dict-like object with the following attributes:
- dataset.data : ndarray, shape [20640, 8]
- Each row corresponding to the 8 feature values in order.
- dataset.target : numpy array of shape (20640,)
- Each value corresponds to the average house value in units of 100,000.
- dataset.feature_names : array of length 8
- Array of ordered feature names used in the dataset.
- dataset.DESCR : string
- Description of the California housing dataset.'''
- dataset = fetch_california_housing("./step4/")
- X_full, y = dataset.data, dataset.target
- #抽取其中两个特征数据
- X = X_full[:, [0, 5]]
-
- def getMinMaxScalerValue():
- '''
- 对特征数据X进行MinMaxScaler标准化转换,并返回转换后的数据前5条
- 返回值:
- X_first5 - 数据列表
- '''
- X_first5 = []
- # 请在此添加实现代码 #
- # ********** Begin *********#
- min_max_scaler = MinMaxScaler()
- X_minmax = min_max_scaler.fit_transform(X)
- X_first5 = X_minmax[:5]
- # ********** End **********#
- return X_first5
- def getScaleValue():
- '''
- 对目标数据y进行简单scale标准化转换,并返回转换后的数据前5条
- 返回值:
- y_first5 - 数据列表
- '''
- y_first5 = []
- # 请在此添加实现代码 #
- # ********** Begin *********#
- y_scaled = scale(y)
- y_first5 = y_scaled[:5]
- # ********** End **********#
- return y_first5
- def getStandardScalerValue():
- '''
- 对特征数据X进行StandardScaler标准化转换,并返回转换后的数据均值和缩放比例
- 返回值:
- X_mean - 均值
- X_scale - 缩放比例值
- '''
- X_mean = None
- X_scale = None
- # 请在此添加实现代码 #
- #********** Begin *********#
- scaler = StandardScaler().fit(X)
- X_mean = scaler.mean_
- X_scale = scaler.scale_
- #********** End **********#
- return X_mean,X_scale
第3关:文本数据特征提取
本关任务
在前一关卡,我们已经学会了数据集标准化处理,标准化一般主要针对数值型数据。对于文本数据,我们无法直接将原始文本作为训练数据,需通过特征提取将其转化为特征向量。本关卡,将学习提取文本数据特征的基本操作。
相关知识
文本分析是机器学习算法的一个主要应用领域。文本分析的原始数据无法直接输入算法,因为大部分学习算法期望的输入是固定长度的数值特征向量,而不是可变长的文本数据。
为了解决这个问题,sklearn提供了一些实用工具用最常见的方式从文本内容中抽取数值特征。比如说:
- 分词(tokenizing),对句子分词后,为每一个词(token)分配的一个整型id,通常用空格和标点符号作为分词的分割符。
- 计数(counting),计算在某个词在文本中的出现频率。
- 归一化权重(nomalizating and weighting), 降低在大多数样本/文档中都出现的词的权重。
在文本特征提取中,特征和样本的定义如下:
- 将每个词出现的频率作为特征。
- 将给定文档中所有词的出现频率所构成的向量看做一个样本。
因此,整个语料库可以看做一个矩阵,矩阵的每行代表一个文档,每列代表一个分词。我们将文档集合转化为数值特征向量的过程称为向量化。这一整套策略被称为词袋模型,用词频描述文档,完全忽略词在文档中出现的相对位置信息。
sklearn中文本数据特征提取的方法
CountVectorizer模块实现了分词和计数,该方法包含许多参数,如下图所示,打印了其默认的参数值。

常见参数:
input : 指定输入格式
tokenizer : 指定分词器
stop_words : 指定停止词,比如当设置 stop_words="english"时,将会使用内建的英语停用词列表
max_df : 设置最大词频,若为浮点数且范围在[0,1]之间,则表示频率,若为整数则表示频数
min_df : 设置最小词频
max_features: 设置最大的特征数量
vocabulary: 指定语料库,即指定词和特征索引间的映射关系表
属性:
vocabulary_ : 字典类型,返回词和特征索引间的映射关系表
#得到词汇映射表vocab = vectorizer.vocabulary_#字典结构,返回特征值‘document’对应的下标索引vectorizer.vocabulary_.get('document')
stop_words_ : set集合,停止词集合
方法:
fit(raw_documents[, y]) : 从原文本数据得到词汇-特征索引间的映射关系
transform(raw_documents) : 将原文本集合转换为特征矩阵
fit_transform(raw_documents[, y]): 结合fit和transform方法,返回特征矩阵,如下图所示

build_analyzer() :返回预处理和分词的引用
下图表示对“This is a text document to analyze.”进行分词并验证结果

get_feature_names() :返回特征索引id对应的特征名字(下标对应的某个词)
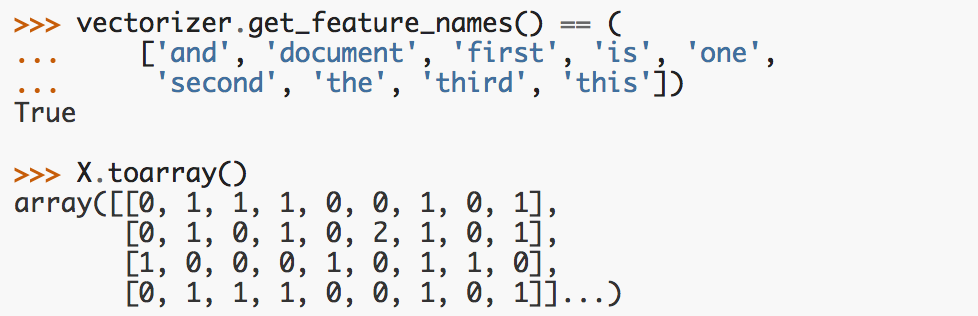
将向量化转换器应用到新的测试数据:

注意:transform函数的返回结果是一个矩阵(sparse matrix),为了更好的表示数据,采用toarray()将数据转化为numpy数组,注意接下来的编程任务中也要转化为一个数组。
在文本语料库中,一些词非常常见(例如,英文中的“the”,“a”,“is”),但是有用信息含量不高。如果我们将词频直接输入分类器,那些频繁出现的词会掩盖那些很少出现但是更有意义的词,将达不到比较好的预期效果。为了重新计算特征的计数权重,通常都会进行TFIDF转换。
TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数。IDF反文档频率(Inverse Document Frequency)是指如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。
sklearn中的TfidfVectorizer模块,实现了TFIDF思想。该模块的参数、属性及方法与CountVectorizer类似,可参考CountVectorizer的调用方式。
编程要求
本关任务,希望分别使用CountVectorizer和TfidfVectorizer对新闻文本数据进行特征提取,并验证提取是否正确。
数据介绍:
采用fetch_20newsgroups("./",subset='train', categories=categories)函数加载对应目录的新闻数据,subset='train'指定采用的是该数据的训练集,categories 指定新闻目录,具体的函数调用可参考官方文档fetch_20newsgroups。X是一个string数组,包含857个新闻文档。
本关具体分成为几个子任务:
1.使用CountVectorizer方法提取新闻数据的特征向量,返回词汇表大小和前五条特征向量
要补充的代码块如下:
def transfer2CountVector():'''使用CountVectorizer方法提取特征向量,返回词汇表大小和前五条特征向量返回值:vocab_len - 标量,词汇表大小tokenizer_list - 数组,对测试字符串test_str进行分词后的结果'''vocab_len = 0test_str = "what's your favorite programming language?"tokenizer_list = []# 请在此添加实现代码 ## ********** Begin *********## ********** End **********#return vocab_len,tokenizer_list
2.使用TfidfVectorizer方法得到新闻数据的词汇-特征向量映射关系,指定使用内建的英文停止词列表作为停止词,并且词出现的最小频数等于2。然后将向量化转换器应用到新的测试数据。
def transfer2TfidfVector():'''使用TfidfVectorizer方法提取特征向量,并将向量化转换器应用到新的测试数据TfidfVectorizer()方法的参数设置:min_df = 2,stop_words="english"test_data - 需要转换的原数据返回值:transfer_test_data - 二维数组ndarray'''test_data = ['Once again, to not believe in God is different than saying....... where is your evidence for that "god is" is meaningful at some level?\n Benedikt\n']transfer_test_data = None# 请在此添加实现代码 ## ********** Begin *********## ********** End **********#return transfer_test_data
测试说明
本关卡的测试数据来自./step5/testTextFeatureExt\fraction.py文件,平台将比对您所编写函数的返回值与正确的数值,只有所有数据全部计算正确才能进入下一关。
- from sklearn.datasets import fetch_20newsgroups
- from sklearn.feature_extraction.text import CountVectorizer
- from sklearn.feature_extraction.text import TfidfVectorizer
-
- categories = [
- 'alt.atheism',
- 'talk.religion.misc',
- ]
-
- # 加载对应目录的新闻数据,包含857个文档
- data = fetch_20newsgroups("./step5/",subset='train', categories=categories)
- X = data.data
-
- def transfer2CountVector():
- '''
- 使用CountVectorizer方法提取特征向量,返回词汇表大小和前五条特征向量
- 返回值:
- vocab_len - 标量,词汇表大小
- tokenizer_list - 数组,对测试字符串test_str进行分词后的结果
- '''
- vocab_len = 0
- test_str = "what's your favorite programming language?"
- tokenizer_list = []
-
- # 请在此添加实现代码 #
- # ********** Begin *********#
- vectorizer = CountVectorizer()
- vectorizer.fit_transform(X)
-
- vocab = vectorizer.vocabulary_
- vocab_len = len(vocab)
-
- analyze = vectorizer.build_analyzer()
- tokenizer_list = analyze(test_str)
- # ********** End **********#
- return vocab_len,tokenizer_list
-
- def transfer2TfidfVector():
- '''
- 使用TfidfVectorizer方法提取特征向量,并将向量化转换器应用到新的测试数据
- TfidfVectorizer()方法的参数设置:
- min_df = 2,stop_words="english"
- test_data - 需要转换的原数据
-
- 返回值:
- transfer_test_data - 二维数组ndarray
- '''
- test_data = ['Once again, to not believe in God is different than saying\n>I BELIEVE that God does not exist. I still maintain the position, even\n>after reading the FAQs, that strong atheism requires faith.\n>\n \nNo it in the way it is usually used. In my view, you are saying here that\ndriving a car requires faith that the car drives.\n \nFor me it is a conclusion, and I have no more faith in it than I have in the\npremises and the argument used.\n \n \n>But first let me say the following.\n>We might have a language problem here - in regards to "faith" and\n>"existence". I, as a Christian, maintain that God does not exist.\n>To exist means to have being in space and time. God does not HAVE\n>being - God IS Being. Kierkegaard once said that God does not\n>exist, He is eternal. With this said, I feel it\'s rather pointless\n>to debate the so called "existence" of God - and that is not what\n>I\'m doing here. I believe that God is the source and ground of\n>being. When you say that "god does not exist", I also accept this\n>statement - but we obviously mean two different things by it. However,\n>in what follows I will use the phrase "the existence of God" in it\'s\n>\'usual sense\' - and this is the sense that I think you are using it.\n>I would like a clarification upon what you mean by "the existence of\n>God".\n>\n \nNo, that\'s a word game. The term god is used in a different way usually.\nWhen you use a different definition it is your thing, but until it is\ncommonly accepted you would have to say the way I define god is ... and\nthat does not exist, it is existence itself, so I say it does not exist.\n \nInterestingly, there are those who say that "existence exists" is one of\nthe indubitable statements possible.\n \nFurther, saying god is existence is either a waste of time, existence is\nalready used and there is no need to replace it by god, or you are implying\nmore with it, in which case your definition and your argument so far\nare incomplete, making it a fallacy.\n \n \n(Deletion)\n>One can never prove that God does or does not exist. When you say\n>that you believe God does not exist, and that this is an opinion\n>"based upon observation", I will have to ask "what observtions are\n>you refering to?" There are NO observations - pro or con - that\n>are valid here in establishing a POSITIVE belief.\n(Deletion)\n \nWhere does that follow? Aren\'t observations based on the assumption\nthat something exists?\n \nAnd wouldn\'t you say there is a level of definition that the assumption\n"god is" is meaningful. If not, I would reject that concept anyway.\n \nSo, where is your evidence for that "god is" is meaningful at some level?\n Benedikt\n']
- transfer_test_data = None
-
- # 请在此添加实现代码 #
- # ********** Begin *********#
- tfidf_vertor = TfidfVectorizer(min_df=2, stop_words="english")
- tfidf_vertor.fit(X)
- transfer_test_data = tfidf_vertor.transform(test_data).toarray()
- # ********** End **********#
- return transfer_test_data
第4关:使用scikit-learn分类器SVM对digits数据分类
本关必读
在scikit-learn中,对于分类问题的估计器是一个实现了fit(X, y) 和predict(T)方法的Python对象。估计器的实例很多,例如实现了支持向量分类的类sklearn.svm.svc。估计器的结构可以通过初始化模型时设置的参数决定,但目前,我们将估计器看做一个黑盒子,先不关心具体的参数设置。 digits数据集中包含大量的数字图片,如下图所示,我们希望给定其中的一张图片,能识别图中代表的数字,这是一个分类问题,数字0…9代表十个分类,目标是希望能正确估计图中样本属于哪一个数字类别。

Digits数据集可以通过以下命令导入:
from sklearn import datasetsdigits = datasets.load_digits()
digits的原始图像采用一个(8,8)的二维数组表示,如下图所示:
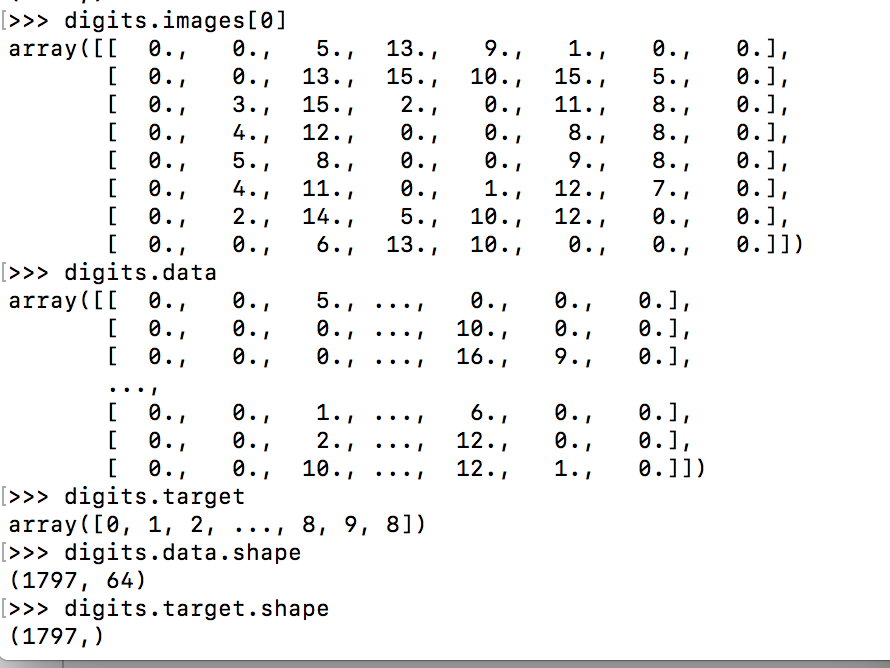
可以通过digits.data查看图片数据表示,行表示样本数量,列表示样本特征(将(8,8)的矩阵压缩成一行,可以从digits.data.shape的列数为64维看出,);digits.target给出digits数据集的真实值,即我们要学习的每个数字图像对应的数字。
本关任务
本关要求采用scikit-learn中的svm模型训练一个对digits数据集进行分类的模型。训练集是digits数据集的前半部分数据,测试集是digits数据集的后半部分数据。
# 使用前一半的数据集作为训练数据,后一半数据集作为测试数据train_data,train_target = data[:n_samples // 2],digits.target[:n_samples // 2]test_data,test_target = data[n_samples // 2:],digits.target[n_samples // 2:]
希望通过训练集训练出分类模型,对于测试集数据能正确预测出图片对应的数字(0…9)。 本关需编程实现step2/digitsClassification.py 的createModelandPredict()函数创建分类模型并预测:
def createModelandPredict():'''创建分类模型并对测试数据预测返回值:predicted - 测试数据预测分类值'''predicted = None# 请在此添加实现代码 ##********** Begin *********##********** End **********#return predicted
predicted 是模型对测试数据的预测值,该函数会返回预测值并在测试文件中检测是否正确。 另外,step2/digitsClassification.py代码中包含两个显示样本图像的函数分别是show4TrainImage()和show4TestImage(),分别用来显示训练集的前4张图像,和模型预测值的前4张图像,大家可以通过在本机python环境调用这两个函数直观查看原始样本集,并且验证预测是否正确,如下图所示:


拓展(本次不需要实现): 从预测集的图像可以看出,并不是完全预测正确,这一点是很正常的,说明使用默认的svc训练模型的无法完全将测试集正确分类,可以通过调整模型的参数使分类更准确,大家可以尝试下设置参数gamma=0.001重新训练模型并预测看是否准确。
测试说明
本关的测试文件是step2/testDigitsClassification.py该代码负责对你的实现代码进行测试,注意step2/testDigitsClassification.py 不能被修改,该测试代码具体如下:
import digitsClassificationpred = digitsClassification.createModelandPredict()print(pred[:10])
测试函数将直接调用step2/createModelandPredict.py 的createModelandPredict()得到实际输出,即分类模型的预测值,平台通过比较预期输出与实际输出的前10个值来判断createModelandPredict函数是否实现正确。
- import matplotlib.pyplot as plt
- # 导入数据集,分类器相关包
- from sklearn import datasets, svm, metrics
-
- # 导入digits数据集
- digits = datasets.load_digits()
- n_samples = len(digits.data)
- data = digits.data
-
- # 使用前一半的数据集作为训练数据,后一半数据集作为测试数据
- train_data,train_target = data[:n_samples // 2],digits.target[:n_samples // 2]
- test_data,test_target = data[n_samples // 2:],digits.target[n_samples // 2:]
-
- def createModelandPredict():
- '''
- 创建分类模型并对测试数据预测
- 返回值:
- predicted - 测试数据预测分类值
- '''
- predicted = None
- # 请在此添加实现代码 #
- #********** Begin *********#
- classifier = svm.SVC()
- classifier.fit(train_data,train_target)
- predicted = classifier.predict(test_data)
- #********** End **********#
- return predicted
第5关:模型持久化
本关必读
当数据量很大的时候,训练一个模型需要消耗很大的时间成本,每次都重新训练模型预测是非常冗余且没有必要的,我们可以将训练模型存储下来,每当要预测新数据的时候只需加载该模型。
训练模型的持久化需要调用python的内建模块pickle,pickle可以用来将python对象转化为字节流存储至磁盘,也可以逆向操作将磁盘上的字节流恢复为python对象。pickle的常用函数包括:
#将对象obj写到文件file中pickle.dump(obj, file[, protocol])#从文件file读取数据流并将其重建返回原始对象pickle.load(file)
关于pickle的详细使用可以参考官方文档:11.1. pickle — Python object serialization — Python 2.7.18 documentation
python 文件操作:
open(路径+文件名,读写模式)
读写模式:
r:只读;
r+:读写;
w:新建(会覆盖原有文件);
a:追加;
b:二进制文件;
示例:
#打开本地file文件,并开启写模式fw=open('file', 'wb')#向file文件中写入‘hello,world’fw.write('hello,world')#打开file文件并读取其中内容fw=open('file', 'rb')fw.read()
‘wb’,'rb'分别表示以二进制流的方式进行写入和读取。 ####本关任务 本关在上一关的基础上,希望将分类模型存储下来,当需要预测数据时加载该模型返回预测值。
本关需编程实现step3/dumpClassificationModel.py 的dumpModel()函数存储分类模型,并且实现loadModel()函数来加载存储模型对预测数据分类,分类模型的实现在createModel()函数中:
# 导入数据集,分类器相关包from sklearn import datasets, svm, metricsimport pickle# 导入digits数据集digits = datasets.load_digits()n_samples = len(digits.data)data = digits.data# 使用前一半的数据集作为训练数据,后一半数据集作为测试数据train_data,train_target = data[:n_samples // 2],digits.target[:n_samples // 2]test_data,test_target = data[n_samples // 2:],digits.target[n_samples // 2:]def createModel():classifier = svm.SVC()classifier.fit(train_data,train_target)return classifierlocal_file = 'dumpfile'def dumpModel():'''存储分类模型'''clf = createModel()# 请在此添加实现代码 ##********** Begin *********##********** End **********#def loadModel():'''加载模型,并使用模型对测试数据进行预测,返回预测值返回值:predicted - 模型预测值'''predicted = None# 请在此添加实现代码 ##********** Begin *********##********** End **********#return predicted
实现提示:
local_file对应即将存储在平台的文件的名称。dumpModel()函数中首先需要打开local_file文件,并开启写入模式,再使用pickle模块将模型存储下来,loadModel()函数中也需要先打开local_file文件,开启读取模式,再使用pickle将local_file文件中存储的模型load至模型变量中,再使用该模型预测。
测试说明
本关的测试文件是step3/testDigitsClassification.py该代码负责对你的实现代码进行测试,注意该测试不能被修改,该测试代码具体如下:
import dumpClassificationModelimport osdumpClassificationModel.dumpModel()if os.path.exists('dumpfile'):print("dump success")else:print("dump fail")predicted = dumpClassificationModel.loadModel()print(predicted[:10])
测试函数将直接调用step3/dumpClassificationModel.py 的dumpModel()存储模型,并检测平台是否存在该文件,然后调用loadModel()函数得到模型实际预测值,平台通过比较预期输出与实际输出的前10个值来判断成功加载模型并预测。
- # 导入数据集,分类器相关包
- from sklearn import datasets, svm, metrics
- import pickle
- # 导入digits数据集
- digits = datasets.load_digits()
- n_samples = len(digits.data)
- data = digits.data
- # 使用前一半的数据集作为训练数据,后一半数据集作为测试数据
- train_data,train_target = data[:n_samples // 2],digits.target[:n_samples // 2]
- test_data,test_target = data[n_samples // 2:],digits.target[n_samples // 2:]
- def createModel():
- classifier = svm.SVC()
- classifier.fit(train_data,train_target)
- return classifier
- local_file = 'dumpfile'
- def dumpModel():
- clf = createModel()
- # 请在此处补全模型存储语句
- f_model=open(local_file,'wb')
- pickle.dump(clf,f_model)
- def loadModel():
- predicted = None
- # 请在此处补全模型加载语句,并对预测数据分类返回预测值
- f_model = open(local_file, 'rb')
- clf = pickle.loads(f_model.read())
- predicted = clf.predict(test_data)
- return predicted
第6关:模型评估-量化预测效果
本关任务
在前面的关卡,我们已经学会了如果使用sklearn训练分类模型,那如何评估模型的分类效果?本关卡将学会使用sklearn的模型度量方法,来量化预测结果。
相关知识
sklearn中有三种不同的API来评估模型的预测质量:
-
Estimator score method :在评估器(比如一个分类模型)中有
score函数提供默认的评估标准,比如支持向量机sklearn.svm.SVC中的score函数通过计算预测准确率来评估模型,如下图所示。
-
Scoring parameter:cross-validation的模型评估工具比如model_selection.GridSearchCV,可通过设置类的参数
scoring来指定评估模型,如下图所示。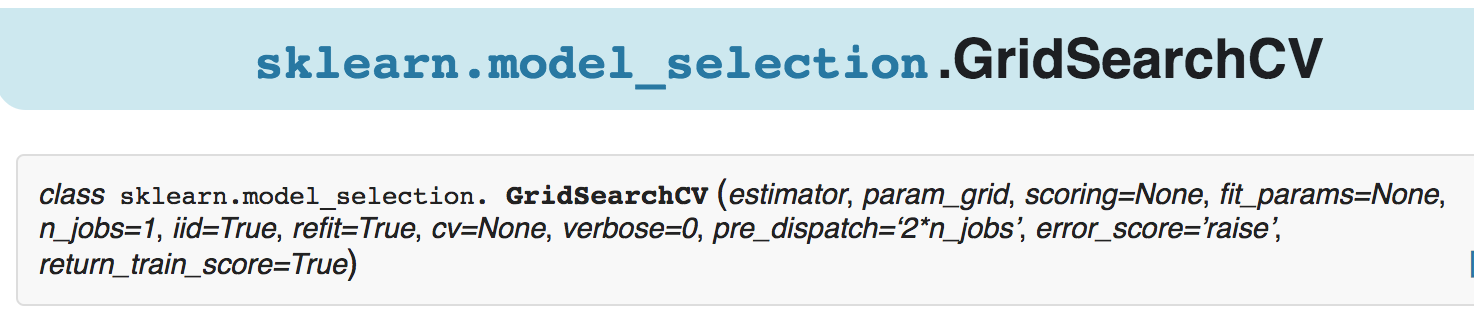
-
Metric functions: metrics模块实现了一些函数,用来评估预测误差,并且针对不同的目标(分类、回归或聚类问题等)有不同的评估类,具体如下图所示。
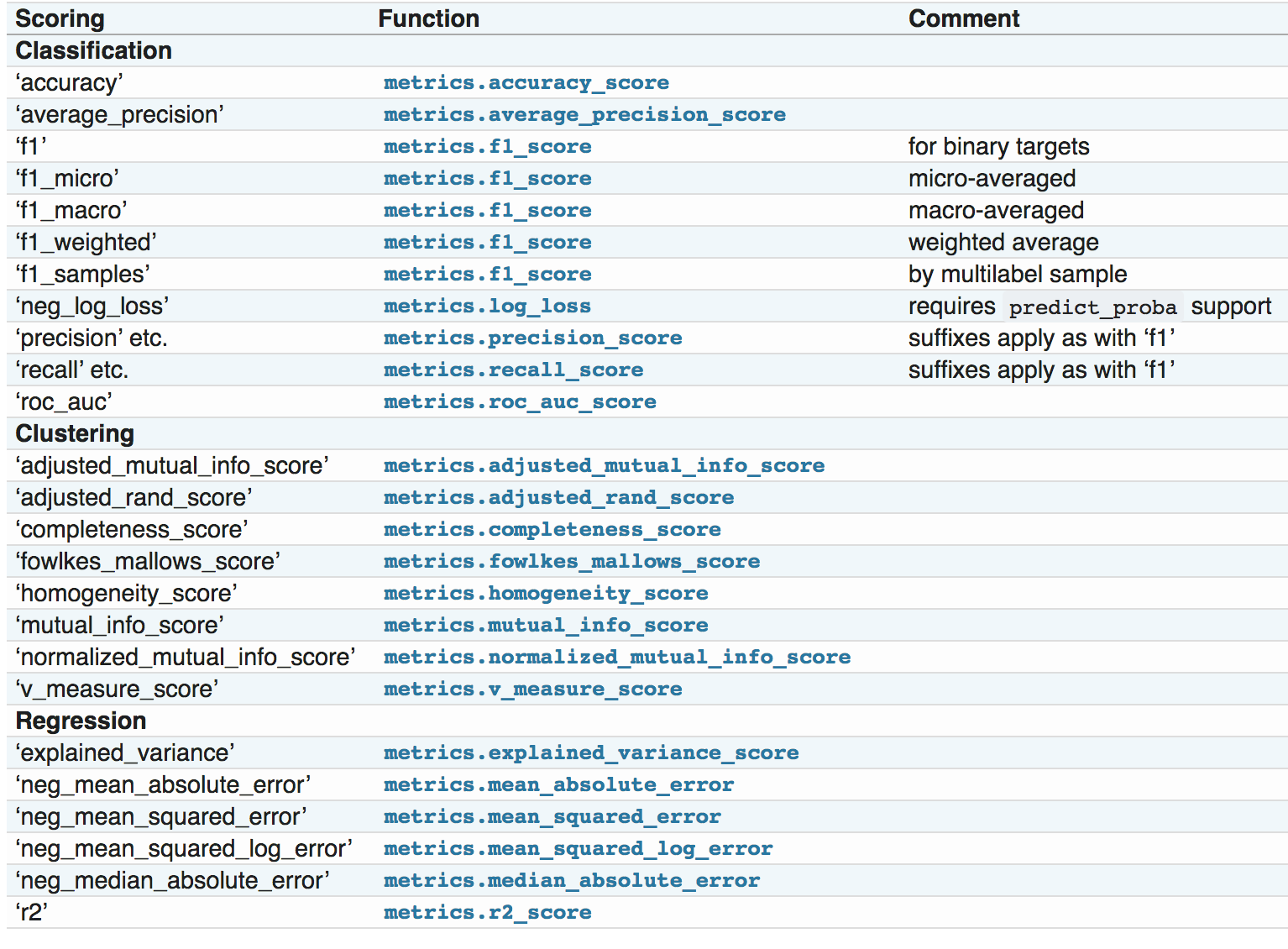
前两种评估方法可以在具体的评估器和交叉验证工具中设置,在这里不过多讨论。我们主要关注metrics模块,旨在让同学们学会如何使用常见的指标对分类结果分析评价。
sklearn.metrics的详细使用可参考官方文档,以下将简单介绍几种常用的评价指标。
-
accu\fracy_score(y_true, y_pred, normalize=True, sample_weight=None)
计算分类精度,示例如下图所示:
其中
normalize=True时返回正确分类的比例,设为False时返回正确分类的样本个数。 -
recall_score(y_true, y_pred, labels=None, pos_label=1, average=’binary’, sample_weight=None) 返回模型分类的召回率,示例如下图所示:

参数:
y_true:实际值
y_pred:预测值
pos_label: 仅当average=’binary’时该参数才有效,即仅对二分类有效。参数的值为正类标签或负类标签,指定计算的是正类还是负类
average:当涉及到二分类/多分类/多标签等不同的问题时,可以通过设置该参数指定计算方式,可取的值包括[None, ‘binary’ (default), ‘micro’, ‘macro’, ‘samples’, ‘weighted’]。 -
f1_score、precision_score的使用方式和recall_score类似。
-
confusion_matrix
计算混淆矩阵,示例如下图所示: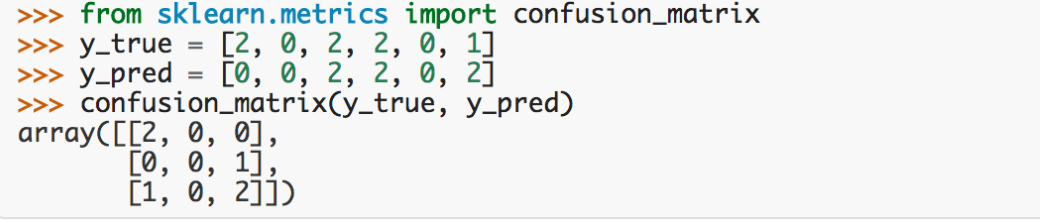
-
classification_report
该函数建立了一份文本报告展示主要的分类度量指标,比如准确率、召回率、f1值等。示例如下图所示: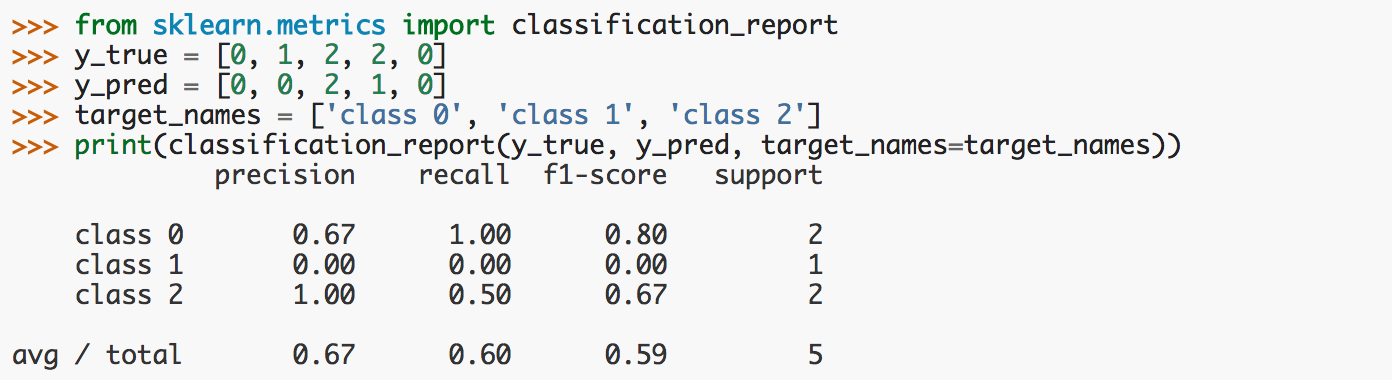
-
precision_recall_fscore_support
为每个类别计算准确率、召回率、f值、support值,示例如下图所示: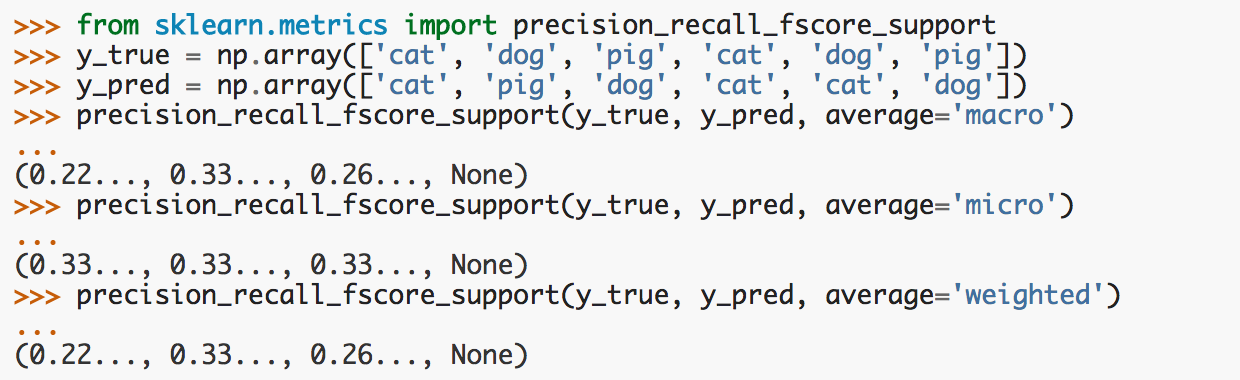
编程要求
本次任务希望对二分类和多分类模型进行评估,本关具体分成为两个子任务:
1.评估二分类模型:训练数据集为二类别数据,通过构建简单的svm模型(初始化模型在代码中已给出),对测试数据进行预测,并返回模型正确分类的样本个数、正类的预测准确率、正类的召回率、正类的f值。该样本数据中y = {1,-1},1表示正类,-1表示负类。
要补充的代码块如下:
def bin_evaluation(X_train, y_train, X_test, y_test):'''评估二分类模型:param X_train: 训练数据集:param y_train: 训练集类别:param X_test: 测试数据集:param y_test: 测试集实际类别:return:correct_num - 正确分类的样本个数prec - 正类的准确率recall - 正类的召回率f_score - 正类的f值'''classifier = LinearSVC()correct_num, prec, recall, fscore = None, None, None, None# 请在此添加实现代码 ## ********** Begin *********## ********** End **********#
2.评估多分类模型:数据集为多类别数据,通过构建简单的svm模型(初始化模型在代码中已给出),对测试数据进行预测,并返回模型的精度、准确率和f值。其中准确率和f值的计算方式设定为‘macro’。
要补充的代码块如下:
def multi_evaluation(X_train,y_train,X_test,y_test):'''评估多分类模型:param X_train: 训练数据集:param y_train: 训练集类别:param X_test: 测试数据集:param y_test: 测试集实际类别:return:acc - 模型的精度prec - 准确率f_score - f值'''#初始化acc,prec,f_score = None,None,Noneclassifier = SVC(kernel='linear')# 请在此添加实现代码 ## ********** Begin *********## ********** End **********#
测试说明
本关卡的测试数据来自./step6/testMetrics.py文件,平台将比对您所编写函数的返回值与正确的数值,只有所有数据全部计算正确才能进入下一关。
- from sklearn.metrics import recall_score,accuracy_score,precision_score,f1_score,precision_recall_fscore_support
- from sklearn.svm import LinearSVC,SVC
- def bin_evaluation(X_train, y_train, X_test, y_test):
- '''
- 评估二分类模型
- :param X_train: 训练数据集
- :param y_train: 训练集类别
- :param X_test: 测试数据集
- :param y_test: 测试集实际类别
- :return:
- correct_num - 正确分类的样本个数
- prec - 正类的准确率
- recall - 正类的召回率
- f_score - 正类的f值
- '''
- classifier = LinearSVC()
- correct_num, prec, recall, fscore = None, None, None, None
- # 请在此添加实现代码 #
- # ********** Begin *********#
- #训练分类器
- classifier.fit(X_train,y_train)
-
- #使用分类器
- y_predicted = classifier.predict(X_test)
-
- #测试分类器
-
- correct_num = accuracy_score(y_test,y_predicted,normalize=False)
- prec = precision_score(y_test,y_predicted)
- recall = recall_score(y_test,y_predicted,average ='binary')
- fscore = f1_score(y_test,y_predicted)
-
- return correct_num,prec,recall,fscore
-
- # ********** End **********#
- def multi_evaluation(X_train,y_train,X_test,y_test):
- '''
- 评估多分类模型
- :param X_train: 训练数据集
- :param y_train: 训练集类别
- :param X_test: 测试数据集
- :param y_test: 测试集实际类别
- :return:
- acc - 模型的精度
- prec - 准确率
- f_score - f值
- '''
- #初始化
- acc,prec,f_score = None,None,None
- classifier = SVC(kernel='linear')
- # 请在此添加实现代码 #
- # ********** Begin *********#
- #训练分类器
- classifier.fit(X_train,y_train)
-
- #使用分类器
- y_predicted = classifier.predict(X_test)
-
- #测试分类器
-
- acc = accuracy_score(y_test,y_predicted)
- prec = precision_score(y_test,y_predicted,average ='macro')
- f_score = f1_score(y_test,y_predicted,average ='macro')
-
- return acc,prec,f_score
- # ********** End **********#

