
论文笔记:CLIP:Learning Transferable Visual Models From Natural Language Supervision详解_clip综述
赞
踩
paper:https://arxiv.org/abs/2103.00020
代码:GitHub - openai/CLIP: Contrastive Language-Image Pretraining
摘要
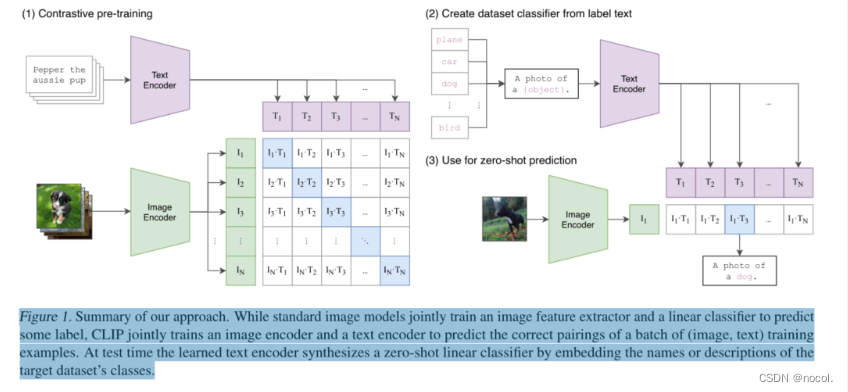
作者提出的CLIP使用的预训练方法:预测哪个标题与哪个图片相配这一简单的预训练任务是一种高效且可扩展的方式,可以在从互联网上收集的4亿对(图片、文本)数据集上从头开始学习SOTA图片表征。在预训练之后,自然语言被用来引用所学的视觉概念(或描述新的概念),使模型能够zero-shot地转移到下游任务中。
该模型可以不费吹灰之力地转移到大多数任务中,并且通常与完全监督的基线竞争,而不需要任何特定的数据集训练。例如,作者在ImageNet的zero-shot中与原始ResNet-50的准确度相当,而不需要使用它所训练的128万个训练实例中的任何一个。
动机
直接从原始文本学习的预训练方法在过去几年中彻底改变了自然语言处理,种种结果表明,在网络规模的文本集合中,现代预训练方法可访问的聚合监督超过了高质量的人群标记的 NLP 数据集。然而,在计算机视觉等其他领域,在 ImageNet 等人工标记的数据集上预训练模型仍然是主流做法。作者提出疑问:直接从网络文本中学习的可扩展预训练方法能否在计算机视觉领域取得类似的突破?
随后作者介绍了一些前人的做法,肯定了他们的贡献同时也指出了其不同的局限性。如:自然语言能够通过其普遍性来表达并监督更广泛的视觉概念。此前方法都使用静态 softmax 分类器来执行预测,并且缺乏动态输出机制。这严重限制了他们的灵活性并限制了他们的“zero-shot”能力。
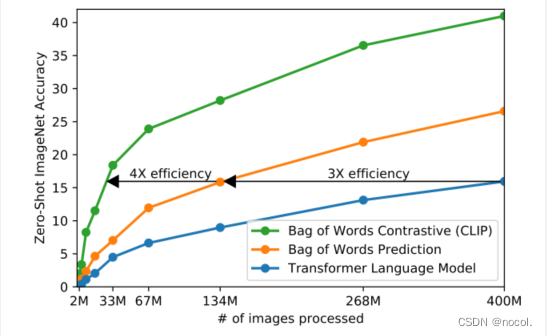
图 2. CLIP 在zero-shot传输方面比我们的图像标题基线更有效。尽管表现力很强,但我们发现基于transformer的语言模型在zero-shot的 ImageNet 分类中相对较弱。在这里,我们看到它的学习速度比预测文本的词袋 (BoW) 编码的基线慢 3 倍 。将预测目标换成 CLIP 的对比目标进一步将效率提高了 4 倍。
方法
自然语言监督
论文方法的核心是从自然语言中包含的监督信息中学习感知的想法。其实这不是一个新想法,而且用于描述该领域工作的术语是多种多样的,甚至看似矛盾的,并且陈述的动机也是是多种多样的。此前很多工作者都引入了从与图像配对的文本中学习视觉表示的方法,但将其方法描述为了无监督、自我监督,弱监督和监督等各种各样。
与其他训练方法相比,从自然语言中学习有几个潜在的优势。与用于图像分类的标准化标签相比,扩展自然语言监督要容易得多,因为它不要求注释采用经典的 "机器学习兼容格式",如经典的1-N多数票 "黄金标签"。相反,在自然语言上工作的方法可以被动地从互联网上大量的文本中的监督中学习。与大多数无监督或自我监督的学习方法相比,从自然语言中学习也有一个重要的优势,那就是它不 "只是 "学习一个表征,而且还将该表征与语言联系起来,从而实现灵活的zero-shot。在以下几个小节中,我们将详细介绍论文所确定的具体方法。
创建一个足够大的数据集
此前同类型的工作主要使用三个数据集:MS-COCO、Visual Genome和YFCC100M。虽然MS-COCO和Visual Genome是高质量的人工标记的数据集,但以现代标准和算力来看,它们的规模仍然很小:大约有10万张训练照片。相比之下,其他计算机视觉系统是在多达35亿张Instagram照片上训练的。YFCC100M有1亿张照片,是一个可能的选择,但每张图片的元数据是稀疏的,而且质量不一。许多图像使用自动生成的文件名,如20160716 113957.JPG作为 "标题",或包含相机曝光设置的 "描述"。经过过滤,只保留有自然语言标题和/或英文描述的图片,数据集缩小了6倍,只有1500万张照片。这与ImageNet的规模大致相同。每个查询包括多达20,000个(图像,文本)对,由此产生的数据集与用于训练GPT-2的WebText数据集的总字数相似。作者把这个数据集称为WebImageText的WIT。
预训练方法
最先进的计算机视觉系统都使用非常大的计算量(本文有过之而无不及)。从自然语言中学习一套开放的视觉概念的任务似乎很艰巨。在作者团队的努力过程中,最终发现训练效率是成功扩展自然语言监督的关键,于是根据这个指标选择了最终的预训练方法。
最初的方法与VirTex类似,从头开始联合训练一个图像CNN和文本transformer,以预测图像的标题。然而遇到了有效扩展这种方法的困难。在图2中显示,一个6300万参数的transformer语言模型,已经使用了其ResNet-50图像编码器的两倍计算量且速度更慢。
最近在图像的对比性表征学习方面的工作发现,对比性目标可以比其同等的预测性目标学到更好的表征。其他工作发现,尽管图像的生成模型可以学习高质量的图像表征,但它们需要的计算量比具有相同性能的对比性模型多一个数量级。注意到这些发现,我们探索训练一个系统来解决潜在的更容易的代理任务,即只预测哪个文本作为一个整体与哪个图像配对,而不是预测该文本的确切字数。
给定一批N个(图像,文本)配对,CLIP被训练来预测整个批次的N×N个可能的(图像,文本)配对中哪些是正样本,哪些是负样本。基于此,CLIP尝试着通过联合训练图像编码器和文本编码器,使批次中N个真实配对的图像和文本embedding的余弦相似度最大化,从而使不配对的图像文本余弦相似度最小化。
由于作者的预训练数据集的规模很大,过度拟合不是一个主要的问题(四亿张图片哎)。因此训练CLIP的细节被论文简化。我们从头开始训练CLIP,没有用ImageNet的权重初始化图像编码器,也没有用预训练的权重初始化文本编码器。而且不使用表征和对比嵌入空间之间的非线性投影而只使用线性投影。因为CLIP的预训练数据集中的许多(图像,文本)对都只是一个单一的句子。因此还简化了图像转换函数tv。训练过程中唯一使用的数据增量就是从调整后的图像中随机裁剪成正方形。
选择和扩展一个模型
论文为图像编码器考虑了两种不同的架构。对于第一个架构,使用ResNet-50作为图像编码器的基础架构,而且还用注意力机制取代了全局平均池化层。注意力池化层被实现为单层的 "transformer式 "多头QKV注意力。对于第二个架构,论文使用最近推出的ViT,
文本编码器是一个Transformer作为基本规模,我们使用一个63M参数的12层512宽模型,有8个注意头,为了提高计算效率,最大的序列长度被限定为76。

图3类似Numpy的伪代码,用于实现CLIP的核心思想。
训练
论文训练了一系列 5 个 ResNet和 3 个 Vision Transformer。对于 ResNet,我们训练了一个 ResNet-50、一个 ResNet-101,然后是另外 3 个,它们遵循 EfficientNet 样式的模型缩放,并使用 ResNet-50 的大约 4 倍、16 倍和 64 倍的计算。它们分别表示为 RN50x4、RN50x16 和 RN50x64。对于 Vision Transformers,我们训练了 ViT-B/32、ViT-B/16 和 ViT-L/14。我们训练所有模型 32 个 epoch。我们使用 Adam 优化器和解耦权重衰减正则化 应用于所有非增益或偏差的权重,并使用余弦调度 衰减学习率,在训练 1 个 epoch 时,使用网格搜索、随机搜索和手动调整基线 ResNet50 模型的组合来设置初始超参数。使用混合精度 加速训练和节省内存。为了节省额外的内存,使用了梯度检查点 check pointing 、半精度 Adam 统计 和半精度随机舍入文本编码器权重。嵌入相似度的计算也与单个 GPU 分片,仅计算其本地批次嵌入所需的成对相似度子集。
最大的模型RN50x64在592块 V100 GPU上训练了18天的时间,而最大的VIT在256 块V100 上花费了12天。对于 ViT-L/14,我们还以更高的 336 像素分辨率预训练了一个额外的 epoch,以提高类似于 FixRes 的性能。我们将此模型表示为 ViT-L/14@336px。除非另有说明,否则本文中报告为“CLIP”的所有结果均使用我们发现性能最佳的模型。
实验
Zero-Shot
在计算机视觉中,zero-shot学习通常是指在图像分类中泛化到看不见的对象类别的研究,作者提到他们专注于研究零样本迁移作为任务学习的评估,其灵感来自于在 NLP 领域展示任务学习的工作。
CLIP 经过预训练,可以预测图像和文本片段是否在其数据集中配对在一起。为了执行zero-shot分类,作者强调他们重用了此功能。对于每个数据集,使用数据集中所有类的名称作为潜在文本对的集合,并根据 CLIP 预测最可能的(图像、文本)对。更详细地说,首先通过各自的编码器计算图像的特征嵌入和可能文本集的特征嵌入,然后计算这些嵌入的余弦相似度。
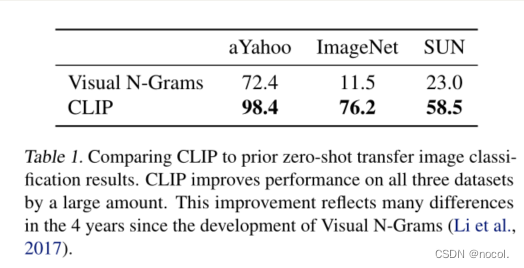
表 1. 将 CLIP 与先前的zero-shot transfer图像分类结果进行比较。 CLIP 大大提高了所有三个数据集的性能。
CLIP 是朝着灵活实用的zero-shot计算机视觉分类器迈出了重要一步。
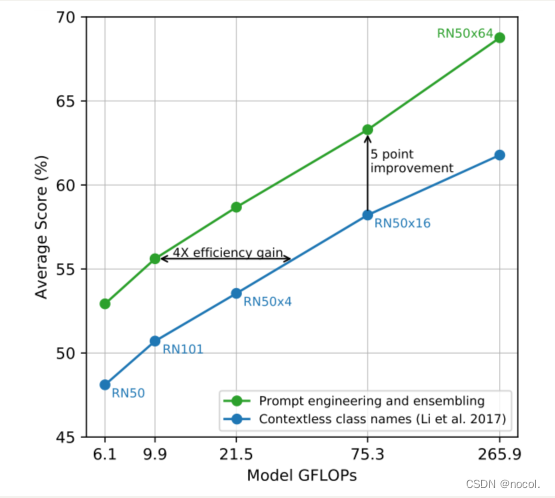
图4. Prompt engineering 和ensembling提高了zero-shot的性能。与使用无上下文的类名的baseline相比,prompt engineering和 ensembling在36个数据集上平均提高了zero-shot分类性能近5个点。这一改进类似于使用baseline zero-shot方法的4倍计算量所带来的收益。
一个常见的问题是多义词。当一个类的名称是提供给CLIP文本编码器的唯一信息时,由于缺乏上下文,它无法区分哪个词的意义。在某些情况下,同一个词的多种含义可能被包括在同一个数据集中的不同类别中!一个例子是在Oxford-IIIT宠物数据集中的类中发现,从上下文来看,word boxer这个词显然是指一种狗的品种,但对于缺乏上下文的文本编码器来说,它也可能是指一种运动员。
我们遇到的另一个问题是,在我们的预训练数据集中,与图像配对的文本只有一个词,这是比较罕见的。通常,文本是一个完整的句子,以某种方式描述图像。为了帮助弥补这一分布差距,我们发现使用提示模板 "一张{标签}的照片。"(“a satellite photo of a {label}.”.)这种方法有助于指定文本是关于图像的内容。这通常比只使用标签文本的基线提高了性能。例如,仅仅使用这个提示就使ImageNet的准确性提高了1.3%,所以,通过为每个任务定制提示文本可以显着提高zero-shot性能。(随后作者在一些数据集上举了一些例证)
论文还试验了将多个zreo-shot分类器集合起来作为提高性能的另一种方式。
这些分类器是通过使用不同的上下文提示来计算的,比如 "A photo of a big {label} "和 "A photo of a small {label}"。我们在嵌入空间而不是概率空间上构建集合。我们观察到,在许多生成的zero-shot分类器中进行合集,可以可靠地提高性能,并将其用于大多数数据集。在ImageNet上,我们集合了80个不同的上下文提示,这比上面讨论的单一默认提示的性能又提高了3.5%。当一起考虑的时候, prompt engineering和ensembling提高了ImageNet的准确率近5%。
我们对CLIP的zero-shot分类器的各种属性进行了研究。作为第一个问题,我们简单地看一下零散分类器的表现如何。为了了解情况,我们与一个简单的现成baseline的性能进行比较:在典型的ResNet-50的特征上拟合一个完全监督的、正则化的、逻辑回归的分类器。在图5中,我们展示了27个数据集的比较。
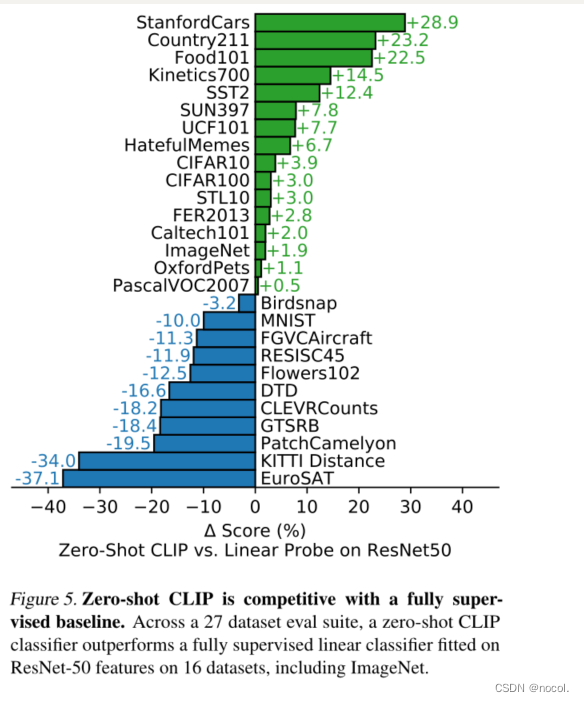
图5 .Zero-shot CLIP与完全监督的baseline有竞争力。在27个数据集的评估套件中,在16个数据集(包括ImageNet)上,Zero-shot CLIP分类器的性能优于以ResNet-50特征为基础的完全监督线性分类器。
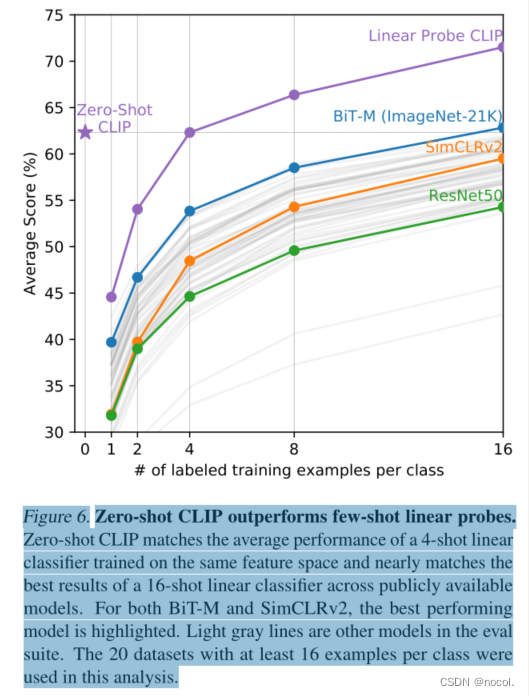
图6. Zero-shot CLIP的性能优于few-shot linear。
Zero-shot CLIP与在相同特征空间上训练的4-shot线性分类器的平均性能相匹配,并几乎与公开可用模型中的16-shot线性分类器的最佳结果相匹配。对于BiT-M和SimCLRv2,性能最好的模型被突出显示。浅灰色线条是评估套件中的其他模型。本分析中使用了20个每类至少有16个例子的数据集。
虽然通过比较zero-shot与完全监督的模型的性能,使CLIP的任务学习能力有了特定的背景,但与few-shot的方法比较是一个更直接的比较,因为zero-shot是其极限。在图6中,我们直观地展示了Zero-shot CLIP在许多图像模型的特征上与few-shot的逻辑回归的比较,包括最好的公开可用的ImageNet模型,自我监督的学习方法,以及CLIP本身。虽然直觉上预计zero-shot的表现会比one-shot的差,但我们发现Zero-shot CLIP在相同的特征空间上与4-shot的逻辑回归的表现相匹配。这可能是由于zero-shot和 few-shot 方法之间的一个重要区别。首先,CLIP的zero-shot分类器是通过自然语言产生的,它允许视觉概念被直接指定("沟通")。相比之下,"正常 "的监督学习必须从训练实例中间接地推断出概念。基于上下文的例子的学习有一个缺点,即许多不同的假设可以与数据一致,特别是在one-shot的情况下。
一张图片往往包含许多不同的视觉概念。尽管一个有能力的学习者能够利用视觉线索和启发式方法,例如假设被演示的概念是图像中的主要对象,但并不能保证。
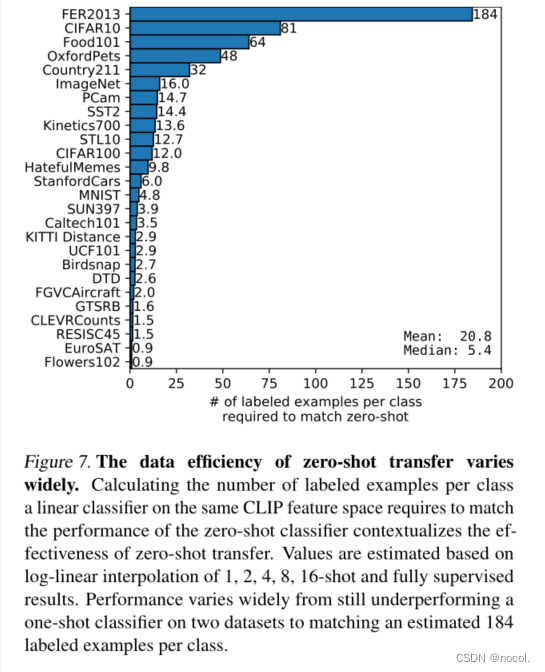
图7. zero-shot transfer的数据效率差异很大。计算同一CLIP特征空间上的线性分类器为匹配zero-shot分类器的性能所需的每类标记实例的数量,使zero-shot transfer的有效性具有背景意义。数值是根据1、2、4、8、16张照片的对数线性插值和完全监督的结果来估计。性能差异很大,从仍然低于两个数据集上的单次分类器的性能,到与每类估计的184个标记的例子相匹配。
除了研究 zero-shot CLIP和few-shot 逻辑回归的平均性能外,我们还研究了个别数据集的性能。在图7中,我们显示了在相同的特征空间上,逻辑回归分类器需要的每类标记的例子数量的估计值,以匹配 zero-shot CLIP的性能。由于 zero-shot CLIP也是一个线性分类器,这估计了在这种情况下zero-shot transfer的有效数据效率。
为了避免训练数以千计的线性分类器,我们根据1、2、4、8、16张照片(可能时)和在每个数据集上训练的完全监督的线性分类器的性能的对数插值来估计有效数据效率。
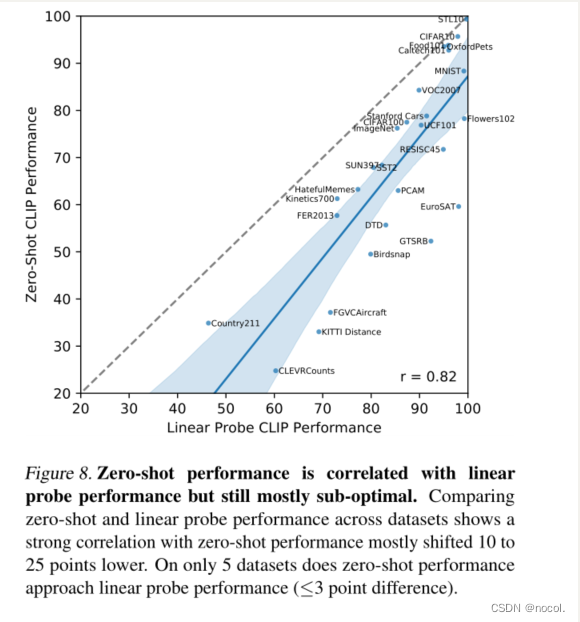
图8. Zero-shot的性能与线性探测的性能相关,但仍然是次优的。对比各数据集的Zero-shot和线性探针性能,发现Zero-shot的性能有很强的关联性,大多低10到25分。只有5个数据集的Zero-shot性能接近线性探测性能(≤3点的差异)。
这表明CLIP在连接基础表征和任务学习与zero-shot transfer方面是相对一致的。然而,zero-shot CLIP只在5个数据集上接近完全监督的性能。STL10, CIFAR10, Food101, OxfordPets和Caltech101。在所有5个数据集上,zero-shot的准确性和完全监督的准确性都超过90%。这表明,对于其基础表征也是高质量的任务,CLIP可能更有效地进行zero-shot transfer。预测zero-shot 性能作为完全监督性能函数的线性回归模型的斜率估计,完全监督性能每提高1%,zero-shot性能就提高1.28%。然而,第95百分位数的置信区间仍然包括小于1的值(0.93-1.79)。
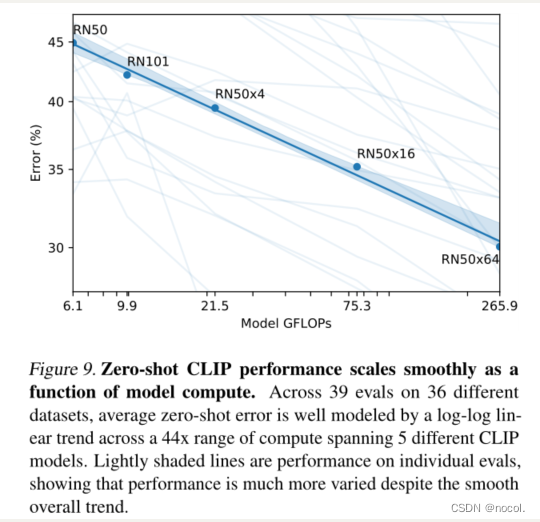
图9.Zero-shot CLIP性能作为模型计算的一个函数平滑地扩展。在36个不同数据集的39次演练中,在跨越5个不同CLIP模型的44倍计算范围内,平均zero-shot误差被一个对数线性趋势很好地模拟。浅色阴影线是个别演练的性能,表明尽管总体趋势平稳,但性能变化更大。
到目前为止,GPT系列模型已经证明了在训练计算量增加1000倍的情况下,zero-shot 的性能有了持续的改善。在图9中,我们检查了CLIP的zero-shot 性能是否遵循类似的缩放模式。我们绘制了5个ResNet CLIP模型在36个不同数据集上的39次评估的平均错误率,并发现在模型计算量增加44倍的情况下,CLIP有一个类似的对数线性扩展趋势。虽然整体趋势是平稳的,但我们发现单个评估的性能可能会更嘈杂。
表征学习
我们在上一节广泛地分析了CLIP通过zero-shot transfer的任务学习能力,但研究一个模型的表征学习能力更为普遍。存在许多评估表征质量的方法,以及对一个 "理想的 "表征应该有什么属性的分歧。在从模型中提取的表征上拟合一个线性分类器,并测量其在各种数据集上的表现是一种常见的方法。
另一种方法是测量模型的端到端微调的性能。这增加了灵活性,之前的工作已经令人信服地证明,在大多数图像分类数据集上,微调的性能优于线性分类。
虽然微调的高性能促使我们出于实际原因对其进行研究,但我们仍然选择基于线性分类器的评估,原因有几个。我们的工作重点是开发一种高性能的任务和数据集无关的预训练方法。微调,因为它在微调阶段使表征适应每个数据集,可以补偿并可能掩盖在预训练阶段学习一般和稳健表征的失败。线性分类器,由于其有限的灵活性,反而突出了这些失败,并在开发过程中提供明确的反馈。对于CLIP来说,训练有监督的线性分类器有一个额外的好处,那就是与用于其zero-shot 分类器的方法非常相似。最后,我们的目标是将CLIP与许多任务中的一套全面的现有模型进行比较。在27个不同的数据集上研究66个不同的模型需要调整1782个不同的评价。微调打开了一个更大的设计和超参数空间,这使得它很难公平地评估和计算成本,以比较一组不同的技术,正如在其他大规模的实证研究中所讨论的那样。相比之下,线性分类器需要最小的超参数调整,并且有标准化的实现和评估程序。
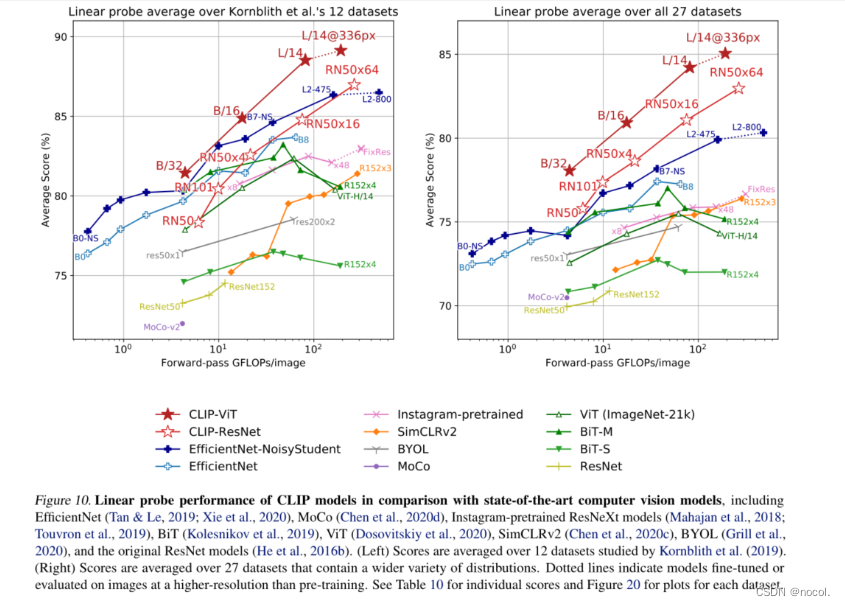
图10 .与最先进的计算机视觉模型相比,CLIP模型的线性探测性能
(左图)分数是12个数据集的平均分。
(右图)分数是27个数据集的平均值,这些数据集包含更多的分布。虚线表示对模型进行了微调或在比训练前更高的分辨率的图像上进行了评估。
图10总结了我们的发现。为了尽量减少可能引起确认或报告偏见的选择效应,我们首先研究了12个数据集评估套件的性能。虽然小型CLIP模型,如ResNet-50和ResNet-101的表现优于在ImageNet-1K上训练的其他ResNets(BiT-S和原版),但它们的表现低于在ImageNet-21K(BiTM)上训练的ResNets。这些小的CLIP模型在类似的计算要求下也不如EfficientNet系列的模型。然而,用CLIP训练的模型可以很好地扩展,我们训练的最大的模型(ResNet-50x64)在总分和计算效率上都略微超过了表现最好的现有模型(一个Noisy Student EfficientNet-L2)。我们还发现,CLIP vision transformers的计算效率比CLIP ResNets高约3倍,这使我们能够在计算预算内达到更高的整体性能。所以在足够大的数据集上训练时,vision transformers比convnets更有计算效率。我们最好的整体模型是ViT-L/14,它在我们的数据集上以更高的分辨率336像素进行微调,并增加了1个epoch。这个模型比整个评估套件中的最佳现有模型平均高出2.6%
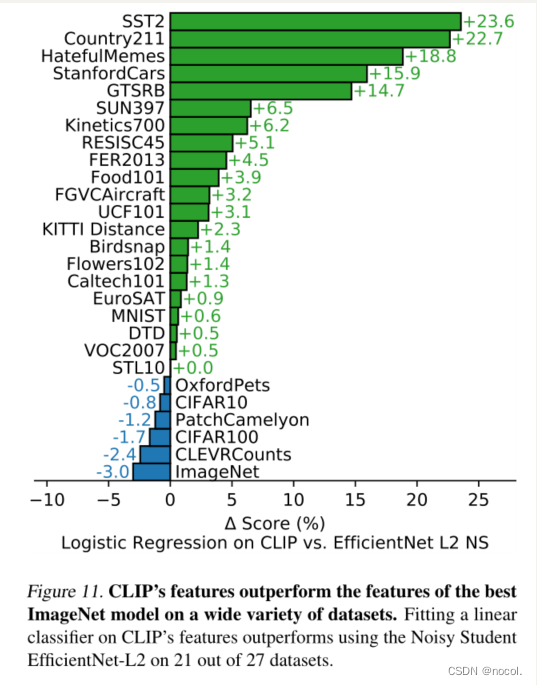
图11. 在各种各样的数据集上,CLIP的特征优于最佳ImageNet模型的特征。在27个数据集中的21个上,对CLIP的特征进行线性分类器的拟合优于使用Noisy Student EfficientNet-L2。
除了上面的总体分析,我们在图11中直观地显示了最佳CLIP模型和我们评估套件中的最佳模型在所有27个数据集上的每一个数据集的性能差异。在27个数据集中的21个数据集上,CLIP胜过了Noisy Student EfficientNet-L2。在需要OCR(SST2和HatefulMemes),地理定位和场景识别(Country211,SUN397),以及视频中的活动识别(Kinetics700和UCF101)的任务上,CLIP的提升最大。此外,CLIP在细粒度的汽车和交通标志识别方面也做得更好(Stanford Cars和GTSRB)。这可能反映了ImageNet中过于狭窄的监督问题。像GTSRB上14.7%的改进结果可能表明ImageNet-1K的一个问题,它对所有的交通和街道标志只有一个标签。这可能会鼓励监督下的表征折叠类内细节,并损害细粒度的下游任务的准确性。如前所述,CLIP在几个数据集上的表现仍然低于EfficientNet。不足为奇的是,相对于CLIP来说,EfficientNet做得最好的数据集是它的训练对象ImageNet。在低分辨率的数据集上,如CIFAR10和CIFAR100,EffcientNet的表现也略优于CLIP。我们怀疑可能是由于CLIP缺乏基于尺度的数据增强。
迁移稳健性
2015年,有消息称深度学习模型在ImageNet测试集上的表现超过了人类。然而,随后几年的研究一再发现,这些模型仍然会犯很多简单的错误,测试这些系统的新baseline经常发现它们的性能比ImageNet的准确性和人类的准确性都低很多。是什么原因导致了这种差异?人们提出并研究了许多想法。最后提出的解释的一个共同主题是,深度学习模型非常善于寻找在其训练数据集中保持的相关性和模式,从而提高分布式性能。然而,这些关联和模式中有许多实际上是虚假的,对其他分布不成立,并导致其他数据集上的性能大幅下降。我们要提醒的是,到目前为止,这些研究大多将其评估限制在ImageNet上训练的模型。
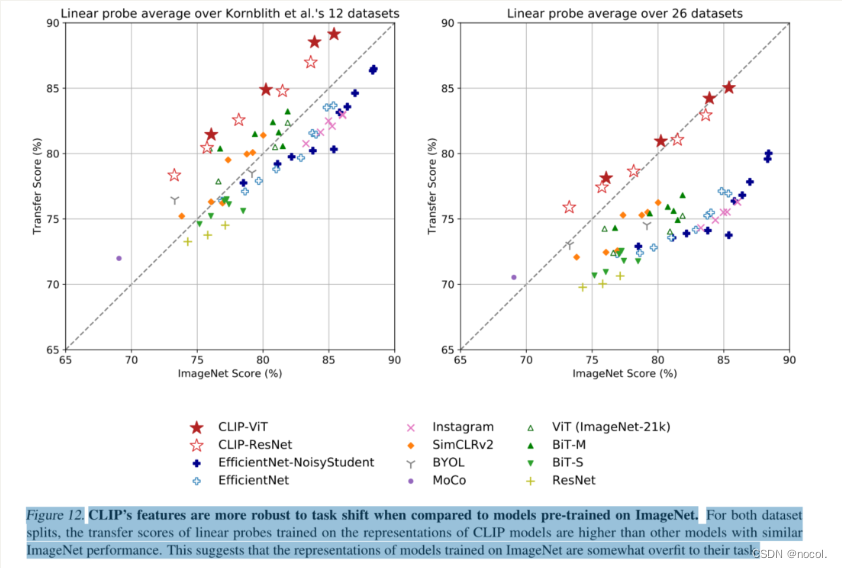
图12. 与在ImageNet上预训练的模型相比,CLIP的特征对任务转移更稳定。对于两个数据集的分割,在CLIP模型的表征上训练的线性探针的转移分数比其他具有类似ImageNet性能的模型要高。这表明,在ImageNet上训练的模型的表征在某种程度上与它们的任务过度拟合。
训练或适应ImageNet数据集的分布是观察到的鲁棒性差距的原因吗?直观地说,一个zero-shot模型不应该能够利用只在特定分布上成立的虚假的相关性或模式,因为它没有在该分布上进行训练。因此,我们有理由期待zero-shot模型具有更高的有效鲁棒性。在图13中,我们比较了zero-shot CLIP与现有ImageNet模型在自然分布转变上的表现。所有的zero-shot CLIP模型都将有效鲁棒性提高了一大截,并将ImageNet准确性和分布转移下的准确性之间的差距减少了75%。
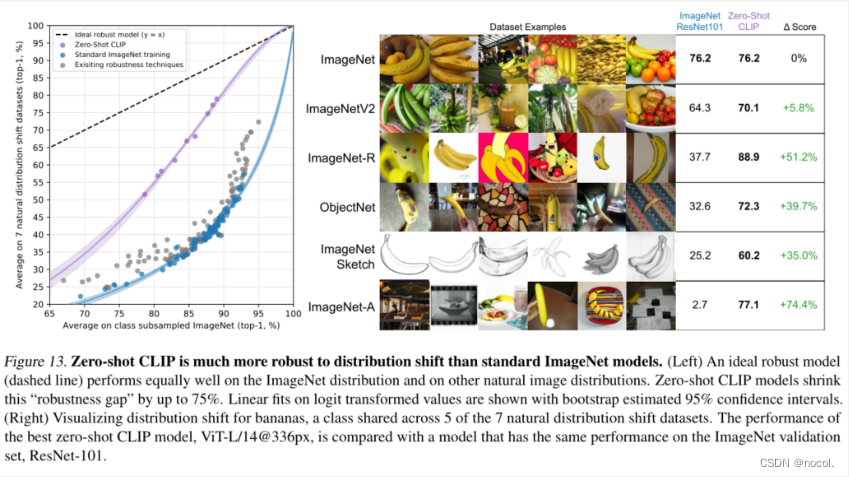
图13. 与标准ImageNet模型相比,Zero-shot CLIP对分布偏移更为稳健。(左图)一个理想的鲁棒性模型(虚线)在ImageNet分布和其他自然图像分布上表现得同样好。Zero-shot CLIP模型将这种 "鲁棒性差距 "缩小了75%。对数转换值的线性拟合显示了自举法估计的95%置信区间。
(右图)可视化香蕉的分布转变,这是7个自然分布转变数据集中的5个共享的类别。最好的零拍CLIP模型ViT-L/14@336px的性能,与在ImageNet验证集ResNet-101上具有相同性能的模型进行了比较。
虽然zero-shot CLIP提高了有效的鲁棒性,但图14显示,在完全监督的情况下,这种好处几乎完全消失。为了更好地理解这种差异,我们调查了有效鲁棒性在从zero-shot到完全监督的连续过程中是如何变化的。在图15中,我们将0-shot、1-shot、2-shot、4-shot...、128-shot和完全监督的逻辑回归分类器在最佳CLIP模型的特征上的表现可视化。我们看到,虽然few-shot模型也显示出比现有模型更高的有效鲁棒性,但随着训练数据的增加,这种好处也会逐渐消失,对于完全监督的模型来说,这种好处大部分(尽管不是完全)消失了。此外,zero-shot CLIP明显比具有同等ImageNet性能的few-shot模型更稳健。CLIP明显比具有同等ImageNet性能的few-shot模型更稳健。
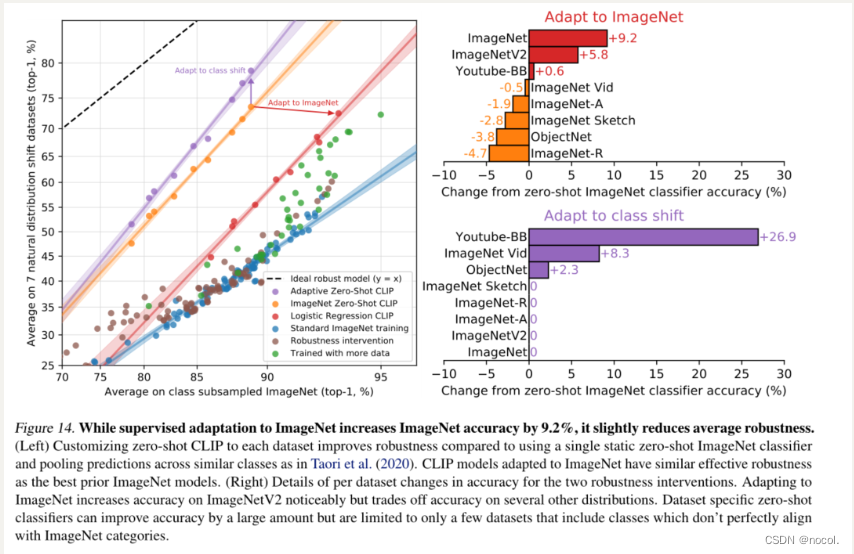
图14. 虽然对ImageNet的监督适应性增加了9.2%的ImageNet准确性,但它略微降低了平均鲁棒性。
(左图)与使用单一的静态zero-shot ImageNet分类器和汇集类似类别的预测相比,为每个数据集定制的zreo-shot CLIP提高了鲁棒性。适应于ImageNet的CLIP模型具有与之前最好的ImageNet模型类似的有效鲁棒性。(右图)两个鲁棒性干预措施的每个数据集的准确性变化细节。适应ImageNet明显增加了ImageNetV2的准确性,但在其他几个分布上牺牲了准确性。数据集特定的zero-shot分类器可以大量提高准确率,但只限于少数数据集,包括与ImageNet类别不完全一致的类别。
综合来看,这些结果表明,最近向大规模任务和数据集不可知的预训练的转变,结合在广泛的评估套件上对zero-shot和 fewshot baseline的重新定位,促进了更强大的系统的发展,并提供了更准确的性能评估。我们很想知道,在NLP领域的zero-shot模型,如GPT系列,是否也有同样的结果。虽然此前有人研究报告说,预训练提高了情感分析的相对鲁棒性,而在对自然分布转变下的问题回答模型的鲁棒性的研究发现,迄今为止几乎没有证据表明有效的鲁棒性改进。有趣的是,人类从平均54%的性能上升到76%,每类只需一个训练例子,而额外的训练例子的边际收益是最小的。准确率从零到一shot的提高,几乎完全是在人类不确定的图像上。这表明,人类 "知道他们不知道什么",并且能够根据一个例子更新他们对最不确定的图像的预设。鉴于此,似乎虽然CLIP是一个有前途的训练策略,用于zero-shot性能(图5),并且在自然分布转移的测试中表现良好(图13),但人类如何从几个例子中学习和本文中的几拍方法之间存在很大的差异。
与人工表现的比较
CLIP与人类的表现和人类的学习相比如何?为了更好地了解人类在与CLIP类似的评估环境中的表现,我们在我们的一项任务中评估了人类。我们想了解人类在这些任务中的zero-shot 性能有多强,以及如果向他们展示一个或两个图像样本,人类的性能会有多大提高。这可以帮助我们比较人类和CLIP的任务难度,并确定他们之间的相关性和差异。
我们让五个不同的人看了牛津大学IIT宠物数据集测试部分的3669张图片中的每一张,并选择37种猫或狗的品种与图片最匹配(如果他们完全不确定,则选择 "我不知道")。在zero-shot实验中,人类没有得到任何品种的例子,并被要求在没有互联网搜索的情况下,尽其所能为它们贴上标签。在one-shot实验中,人类被给予每个品种的一个样本图像,在 two-shot实验中,他们被给予每个品种的两个样本图像。在STL-10数据集上,人类的准确率高达94%,以及在注意力检查图像子集上97-100%的准确率增加了我们对人类工作者的信任。因为这些对CLIP的几次评估没有有效地利用先验知识,而人类却做到了,我们推测,找到一种方法将先验知识适当地整合到几次学习中是对CLIP进行算法改进的重要步骤。
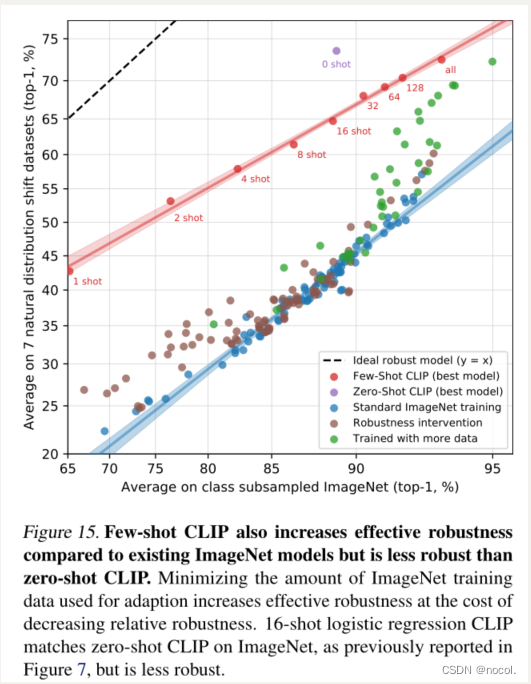
图15. 与现有的ImageNet模型相比,Few-shot CLIP也增加了有效鲁棒性,但比零次CLIP的鲁棒性差。尽量减少用于适应的ImageNet训练数据量增加了有效鲁棒性,但代价是减少了相对鲁棒性。16-shot逻辑回归CLIP与ImageNet上的zero-shot CLIP相匹配,正如之前在图7中报告的那样,但鲁棒性较差。
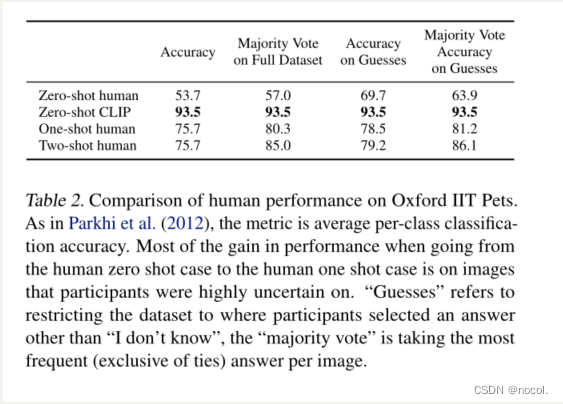
表2. 人类对Oxford IIT Pets的表现比较。
指标是平均每类分类准确率。从人类的zero-shot案例到人类的one-shot案例,大部分的性能提升是在参与者高度不确定的图像上。"猜测 "指的是将数据集限制在参与者选择 "我不知道 "以外的答案,"多数票 "指的是在每张图片上选择最频繁(不包括平局)的答案。**
如果我们把人类的准确度与CLIP的zero-shot准确度作对比(图16),我们看到对CLIP来说最难的问题对人类来说也很难。在错误一致的情况下,我们的假设是,这至少是由于两个因素:数据集中的噪音(包括错误的标签图像)和非分布图像对人类和模型来说都是困难的。
数据重叠分析
在一个非常大的互联网数据集上进行预训练的一个问题是与下游评估的无意重叠。这一点很重要,因为在最坏的情况下,一个评估数据集的完整副本可能会泄漏到预训练数据集中,并使评估作为一个有意义的泛化测试失效。防止这种情况的一个办法是在训练模型之前识别并删除所有重复的数据。
虽然这能保证报告真实的保持性能,但它需要提前了解模型可能被评估的所有可能的数据。这有一个缺点,就是限制了基准测试和分析的范围。增加一个新的评估将需要昂贵的重新训练,或者由于重叠而有可能报告一个未被量化的好处。
相反,我们记录了发生了多少重叠,以及由于这些重叠导致的性能变化。为了做到这一点,我们使用以下程序:
1)对于每个评估数据集,我们在其例子上运行一个重复检测器。然后,我们手动检查发现的近邻,并设置一个每个数据集的阈值,以保持高精确度,同时最大限度地提高召回率。使用这个阈值,我们创建了两个新的子集,即Overlap(包含所有与训练实例相似度高于阈值的实例)和Clean(包含所有训练实例与低于这个阈值的例子)。我们将未经修改的完整数据集表示为All,供参考。从中我们首先记录数据污染的程度,即Overlap中的例子数量与All的大小之比。
2)然后,我们计算CLIP RN50x64在三个分片上的zero-shot精度,并报告All - Clean作为我们的主要指标。这是由于污染造成的准确性的差异。如果是正数,它是我们对数据集上整体报告的准确性被过度拟合到重叠数据而膨胀的程度的估计。
3)重叠量通常很小,所以我们还进行了二项式显著性检验,我们用Clean上的准确性作为无效假设,并计算Overlap子集的单尾(更大)P值。我们还计算了Dirty上99.5%的Clopper-Pearson置信区间作为另一个检查。
我们在数据集创建日期之后的新数据保证没有重合(ObjectNet和Hateful Memes)。这表明我们的检测器具有较低的假阳性率,这很重要,因为假阳性会低估我们分析中污染的影响。重叠率的中位数为2.2%,平均重叠率为3.2%。由于这种少量的重叠,总体准确率很少有超过0.1%的偏移,只有7个数据集超过这个阈值。其中,只有2个在Bonferroni校正后有统计学意义。在Birdsnap上检测到的最大改进只有0.6%,其重叠度为12.1%,位居第二。最大的重叠是Country211,为21.5%。这是由于它是由YFCC100M构建的,而我们的预训练数据集包含一个过滤的子集。尽管有这么大的重叠,Country211的准确性只增加了0.2%。这可能是因为伴随着一个例子的训练文本往往与下游评估的具体任务无关。Country211测量的是地理定位能力,但检查这些重复的训练文本后发现,它们往往没有提到图片的位置。
我们意识到我们的分析有两个潜在的问题。
首先,我们的检测器并不完美。虽然它在代理训练任务上达到了接近100%的准确率,而且人工检查+阈值调整的结果是非常高的精度,在发现的最近邻居中具有良好的召回率,但我们无法在4亿个例子中切实检查其召回率。
我们分析的另一个潜在干扰因素是,基础数据分布可能会在Overlap和Clean子集之间转移。例如,在Kinetics-700上,许多 "重叠 "实际上都是黑色过渡帧。这就解释了为什么Kinetics-700在Overlap上有明显的20%的准确性下降。我们怀疑可能存在更微妙的分布变化。我们在CIFAR-100上注意到的一个可能性是,由于其图像的分辨率很低,许多重复是小物体的假阳性,如鸟或飞机。准确度的变化可能是由于重复物的类别分布或难度的变化。不幸的是,这些分布和难度的变化也可能掩盖了过度拟合的影响。
局限性
迁移能力
CLIP 仍有许多限制。其中一些在各个部分中作为分析的一部分进行了讨论,在这里来总结和收集这些问题。
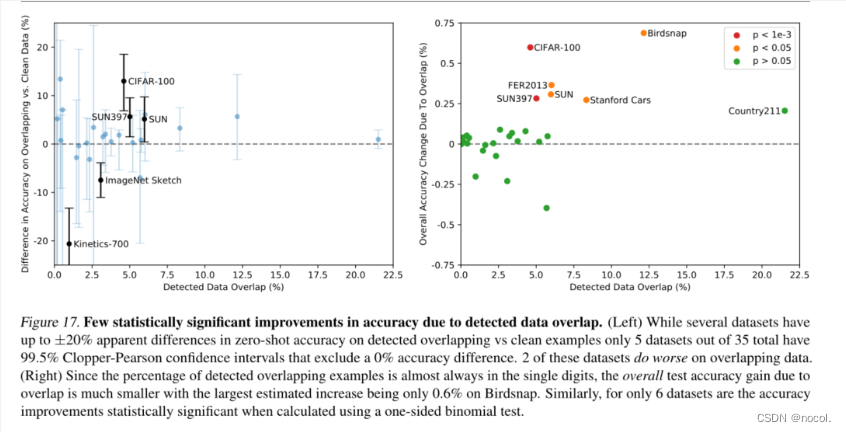
图 17. 由于检测到的数据重叠准确性几乎没有显著提高。 (左)虽然几个数据集在检测到的重叠样本和干净样本上的zero-shot精度有高达 ±20% 的明显差异,但总共 35 个数据集中只有 5 个具有 99.5% 的 Clopper-Pearson 置信区间,排除了 0% 的精度差异。其中 2 个数据集在重叠数据上表现更差。
(右)由于检测到的重叠示例的百分比几乎总是在个位数,因此由于重叠导致的整体测试准确度增益要小得多,在 Birdsnap 上估计的最大增幅仅为 0.6%。同样,当使用单边二项式检验计算时,只有 6 个数据集的准确性提高具有统计学意义。
首先仍然需要大量工作来提高 CLIP 的task learning和迁移能力。虽然缩放迄今为止稳步提高了性能并提出了持续改进的途径,但我们估计zero-shot CLIP 需要大约 1000 倍的计算增加才能达到整体最先进的性能。使用当前的硬件进行训练是不可行的。有必要进一步研究提高 CLIP 的计算和数据效率。CLIP 的zero-shot性能在几种任务上仍然很弱。与特定任务模型相比,CLIP 在几种类型的细粒度分类(例如区分汽车模型、花卉种类和飞机变体)上的性能较差。 CLIP 还努力完成更抽象和系统的任务,例如计算图像中对象的数量。最后,对于不太可能包含在 CLIP 预训练数据集中的新任务,例如对照片中到最近汽车的距离进行分类,CLIP 的性能几乎就是随机的(太差或根本不稳定)。
也就是说,zero-shot CLIP 可以很好地推广到许多自然图像分布,但我们观察到,zero-shot CLIP 仍然不能很好地推广到真正训练数据集分布以外的数据。
尽管 CLIP 可以为各种任务和数据集灵活地生成zero-shot分类器,但 CLIP 仍然仅限于从给定zero-shot分类器中的那些概念中进行选择。与真正灵活的方法(如可以生成新颖输出的图像字幕)相比,这是一个重大限制。另外发现图像标题基线的计算效率远低于 CLIP。一个值得尝试的简单想法是联合训练对比和生成目标,希望将 CLIP 的效率与字幕模型的灵活性相结合。作为另一种选择,可以在推理时对给定图像的许多自然语言解释执行搜索,类似于 Learning with Latent Language Andreas et al (2017) 中提出的方法。
未来方向
CLIP 也没有解决深度学习的低数据效率问题。相反,CLIP 通过使用可以扩展到数亿个训练示例的监督源来进行补偿。如果在 CLIP 模型训练期间看到的每张图像都以每秒一张的速度呈现,则需要 405 年的时间来遍历在 32 个训练时期看到的 128 亿张图像。将 CLIP 与自监督 和自训练 方法相结合是一个很有前途的方向,因为它们被证明能够比标准监督学习提高数据效率。
数据集
我们的方法有几个显著的局限性。尽管我们专注于zero-shot迁移,但我们反复查询完整验证集的性能以指导 CLIP 的开发。这些验证集通常有数千个示例,这对于真正的zero-shot场景是不现实的。在半监督学习领域也提出了类似的担忧。另一个潜在问题是我们对评估数据集的选择。虽然我们将 Kornblith 等人的 12 个数据集评估套件作为标准化集合报告了结果,但我们的主要结果使用了 27 个数据集的一些随意组装的集合,这些数据集无疑与 CLIP 的开发和功能共同适应。创建一个新的任务baseline,明确设计用于评估广泛的zero-shot传输能力,而不是重新使用现有的监督数据集,将有助于解决这些问题。
CLIP 是在与互联网上的图像配对的文本上进行训练的。这些图像-文本对未经过滤和整理,导致 CLIP 模型学习许多社会偏见。
few-shot
虽然我们在整个工作中强调,通过自然语言指定图像分类器是一个灵活和通用的界面,但它也有自己的局限性。许多复杂的任务和视觉概念可能很难仅仅通过文本来指定。不可否认,实际的训练例子是有用的,但CLIP并没有直接对少数照片的性能进行优化。在我们的工作中,我们回落到在CLIP的特征之上拟合线性分类器。这导致了在从0-shot过渡到few-shot设置时性能的反直觉的下降。正如第4节所讨论的,这与人类的表现明显不同,人类的表现显示出从零到一个shot设置的大幅增加。未来的工作需要开发结合CLIP强大的zero-shot性能和高效的few-shot学习的方法。(参考我的另一篇关于few-shot微调CLIP的博客:《论文笔记:Tip-Adapter: Training-free CLIP-Adapter for Better Vision-Language Modeling详解》)
广泛影响
由于它有能力执行任意的图像分类任务,CLIP具有广泛的能力。人们可以给它猫和狗的图像,要求它对猫进行分类,或者给它在百货公司拍摄的图像,要求它对偷窃者进行分类--这是一项具有重大社会影响的任务。像任何图像分类系统一样,CLIP的性能和目的适用性需要被评估,其更广泛的影响也需要被分析。
我们对CLIP在零拍摄环境中的研究表明,该模型对广泛适用的任务,如图像检索或搜索,显示出重大的前景。例如,它可以在一个数据库中找到相关的图像,或者相关的文本,给定一个图像。此外,相对容易的引导CLIP走向定制的应用,很少或没有额外的数据或训练,可以释放出各种我们今天很难设想的新应用,就像过去几年大型语言模型所发生的那样。
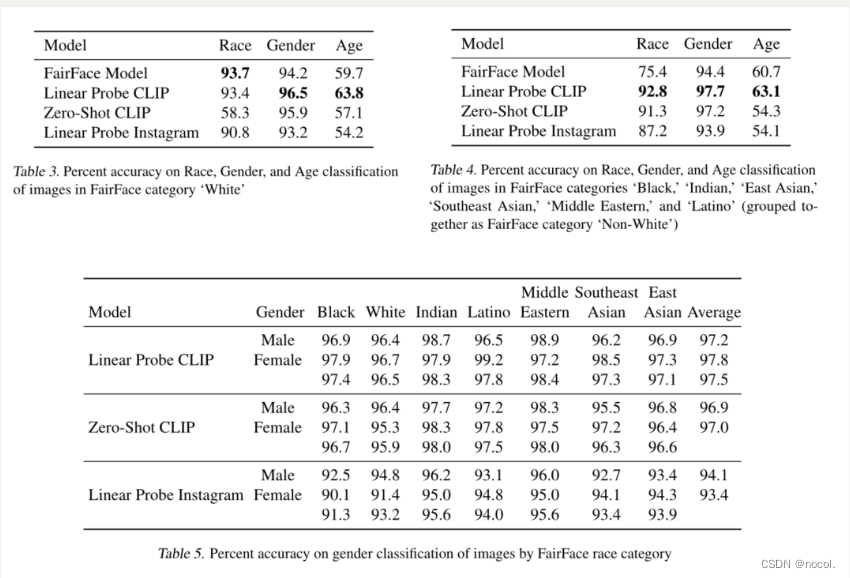
表3. 在FairFace类别 "White "中对图像进行种族、性别和年龄分类的准确百分比
表4. 在FairFace类别 "黑人"、"印度人"、"东亚人"、"东南亚人"、"中东人 "和 "拉丁裔"(归入FairFace类别 "非白人")的图像的种族、性别和年龄分类的准确百分比
表5. 按FairFace种族类别对图像进行性别分类的准确性百分比
偏见问题
算法决定、训练数据以及关于如何定义类和分类的选择都可以促成和放大使用人工智能系统所产生的社会偏见和不平等。
在这一节中,我们对CLIP中的一些偏见进行了初步分析,使用Buolamwini & Gebru(2018)和K¨arkk¨ainen & Joo(2019)中概述的偏见探测器。我们还进行了探索性的偏见研究,旨在找到模型中偏见的具体例子。
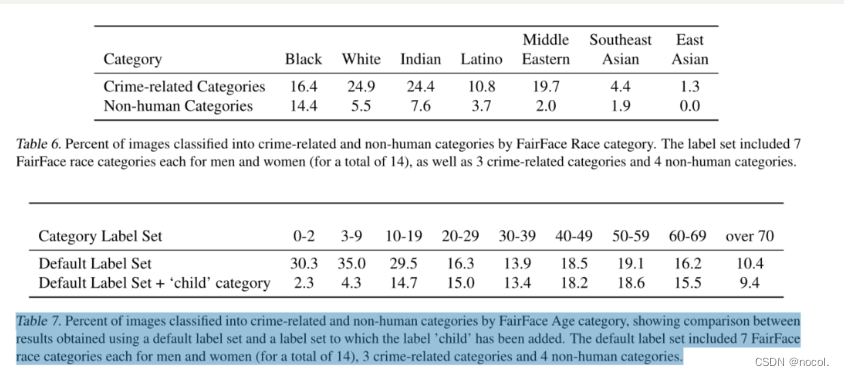
表7. 按FairFace年龄类别归入犯罪相关和非人类类别的图像百分比,显示了使用默认标签集和添加了 "儿童 "标签的标签集的结果对比。默认标签集包括男性和女性各7个FairFace种族类别(共14个),3个犯罪相关类别和4个非人类类别。
虽然LR CLIP在FairFace基准数据集上取得了比Linear Probe Instagram模型更高的准确性,用于按交叉类别对图像进行性别、种族和年龄分类,但基准上的准确性只提供了算法公平性的一个近似值,在现实世界的背景下,往往不能作为公平性的有意义的措施。即使一个模型在不同的子群体上有较高的准确性和较低的性能差异,这并不意味着它的影响差异会较低。例如,对代表性不足的群体有较高的表现,可能会被公司用来证明他们使用面部识别的合理性,然后部署它的方式,对人口群体产生不成比例的影响。我们使用面部分类基准来探测偏见,并不是要暗示面部分类是一项没有问题的任务,也不是要赞同在部署的情况下使用种族、年龄或性别分类。
(接下来是论文中作者对各种社会偏见做的调查和研究......)
感兴趣的读者可以去阅读论文第七章7. Broader Impacts,这里不再详解
这些实验并不全面。它们说明了由类的设计和其他偏见来源引起的潜在问题,并旨在引发探究。
结论
任何利用书面、口语、签名或任何其他形式的人类语言作为其训练信号的模型都可以说是使用自然语言作为监督的来源。这是一个公认的极其广泛的领域,涵盖了分布式语义学领域的大部分工作,包括主题模型、单词、句子和段落向量,以及语言模型。
我们研究了是否有可能将NLP中任务无关的网络规模预训练的成功转移到另一个领域。我们发现,采用这个公式的结果是在计算机视觉领域出现了类似的行为,并讨论了这个研究方向的社会意义。为了优化他们的训练目标,CLIP模型在预训练期间学习执行各种各样的任务。然后,这种任务学习可以通过自然语言的提示来实现对许多现有数据集的zero-shot转移。在足够的规模下,这种方法的性能可以与特定任务的监督模型竞争,尽管仍有很大的改进空间。
关于CLIP的综述见 clip预训练模型综述

