
- 1大数据 DataX-Web 详细安装教程
- 2瑞芯微RK3568调试Android 11的各种方法_rk3568 开发板-安卓系统之uart驱动调试(十一)
- 3Git常用命令submodule
- 4CV常用数据集_bdd-a数据集
- 5ESP8266 固件下载_esp8266固件下载
- 6在嵌入式linux上玩OpenGL_tinygl
- 7python中Tkinter 窗口之输入框和文本框_tkinter文本框和输入框的区别
- 8【c语言】归并排序_归并排序c语言
- 92024-04-14 问AI: 在深度学习中,为什么需要激活函数?
- 10ControlNet on diffusers_inpainting和controlnet
(超详细)YOLOv5训练出结果,如何分析结果的性能分析_yolov5训练结果分析
赞
踩
一、 confusion_matrix
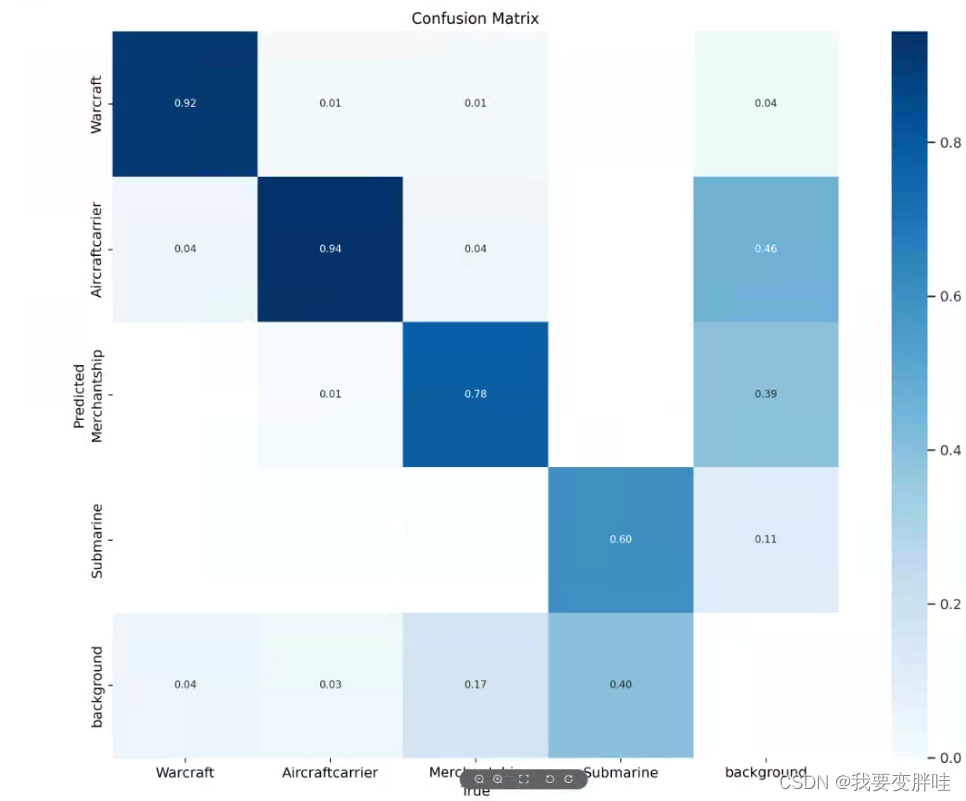
行是预测类别(y轴),列是真实类别(x轴);
矩阵中Aij的含义是:第j个类别被预测为第i个类别的概率;
二、P_curve
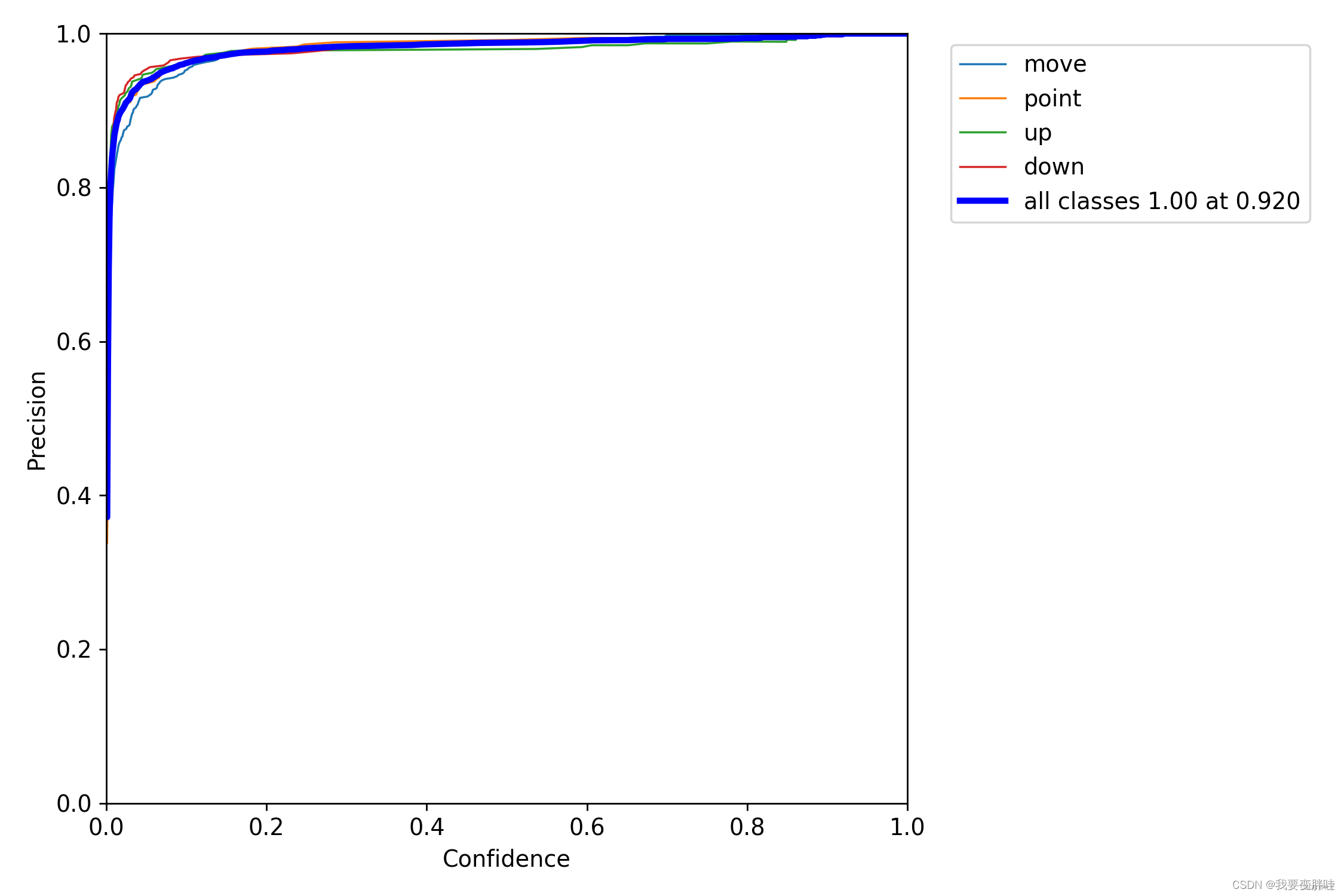
准确率和置信度的关系图。
意思就是,当我设置置信度为某一数值的时候,各个类别识别的准确率。可以看到,当置信度越大的时候,类别检测的越准确。这也很好理解,只有confidence很大,才被判断是某一类别。但也很好想到,这样的话,会漏检一些置信度低的类别。
三、R_curve
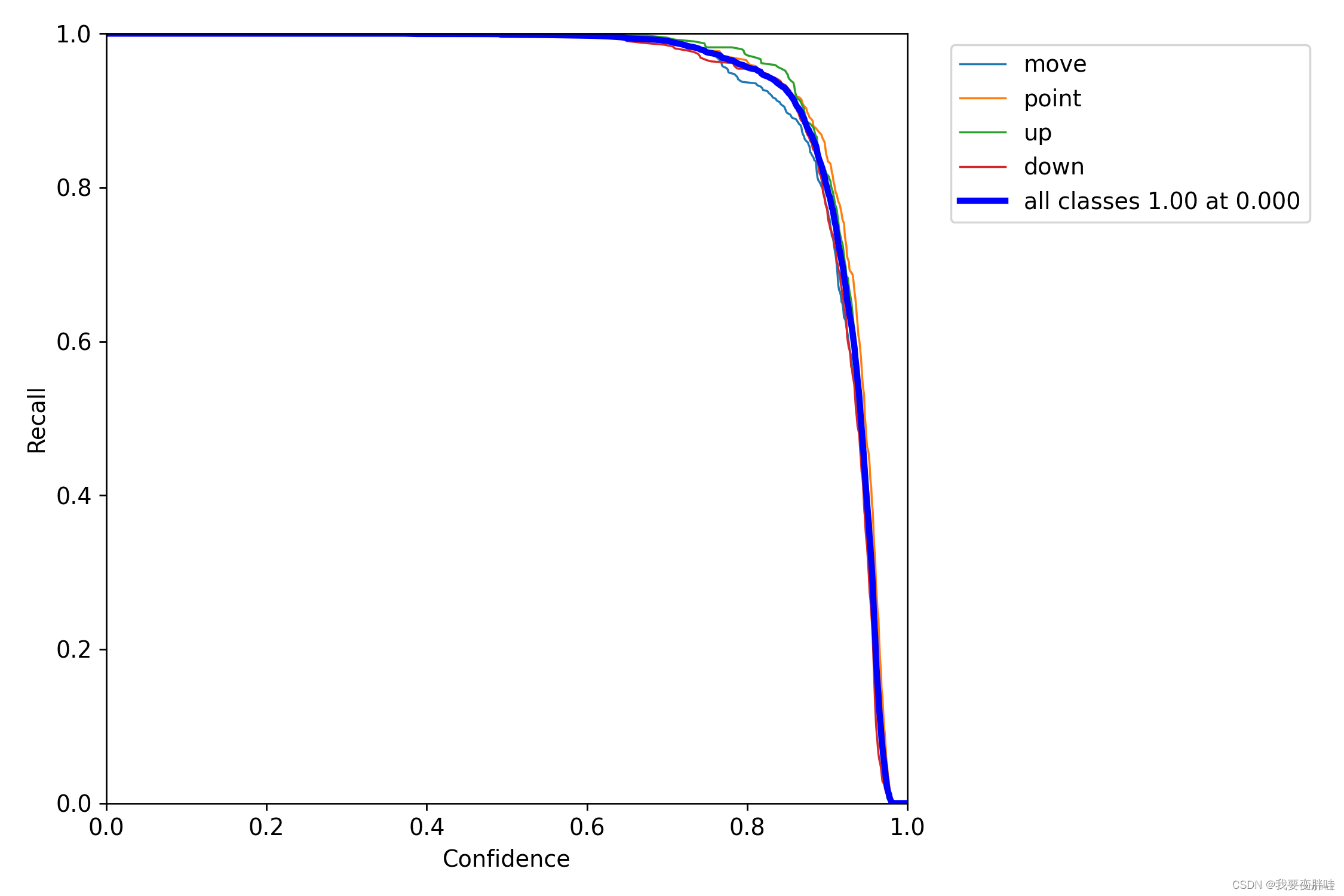
召回率(查全率)和置信度的关系图。
意思就是,当我设置置信度为某一数值的时候,各个类别查全的概率。可以看到,当置信度越小的时候,类别检测的越全面。
四、PR_curve
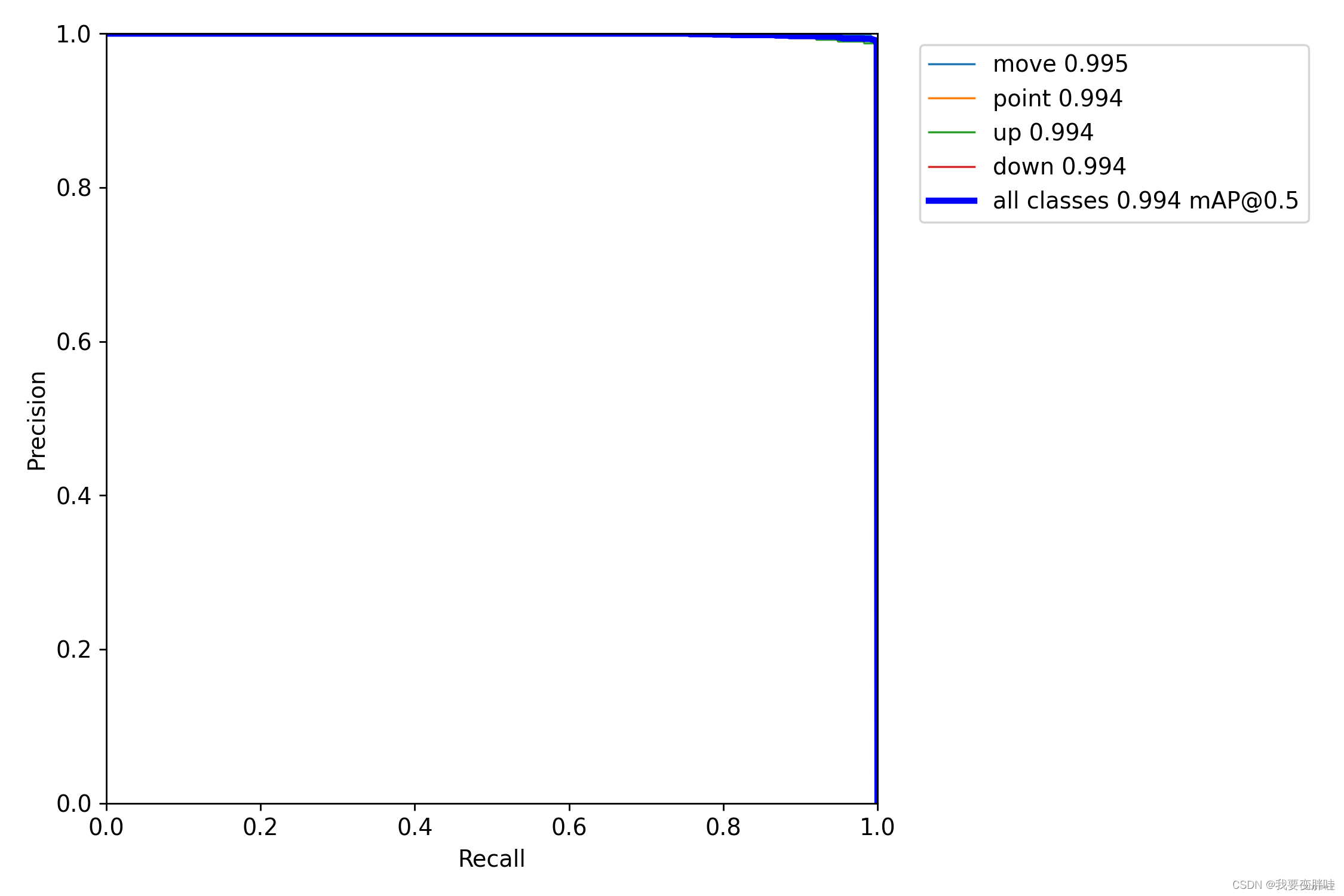
mAP 是 Mean Average Precision 的缩写,即 均值平均精度。可以看到:精度越高,召回率越低。
但我们希望我们的网络,在准确率很高的前提下,尽可能的检测到全部的类别。所以希望我们的曲线接近(1,1)点,即希望mAP曲线的面积尽可能接近1。
五、 F1_curve
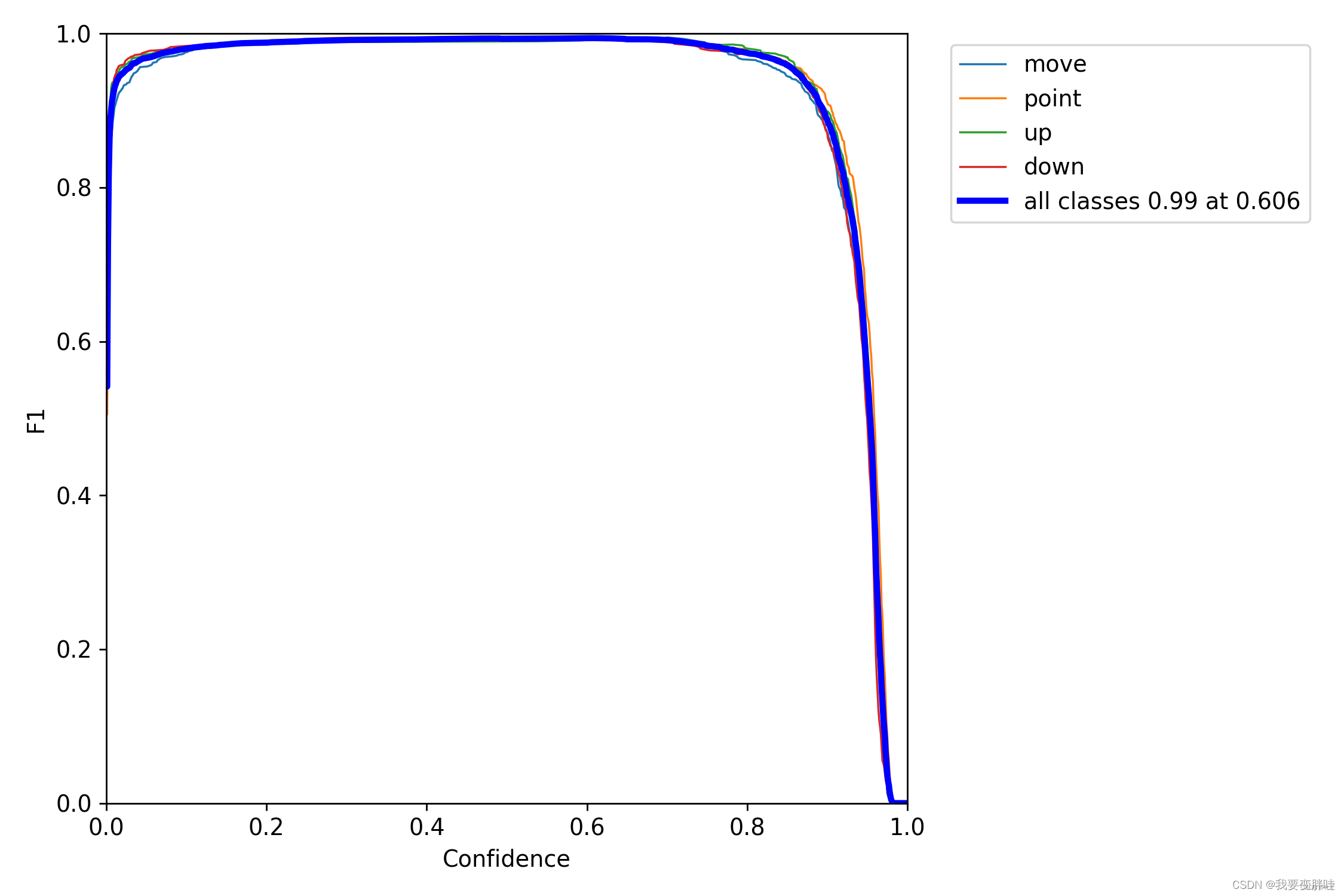
F1分数(F1-score)是分类问题的一个衡量指标。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。
对于某个分类,综合了Precision和Recall的一个判断指标,F1-Score的值是从0到1的,1是最好,0是最差。
六、labels.jpg
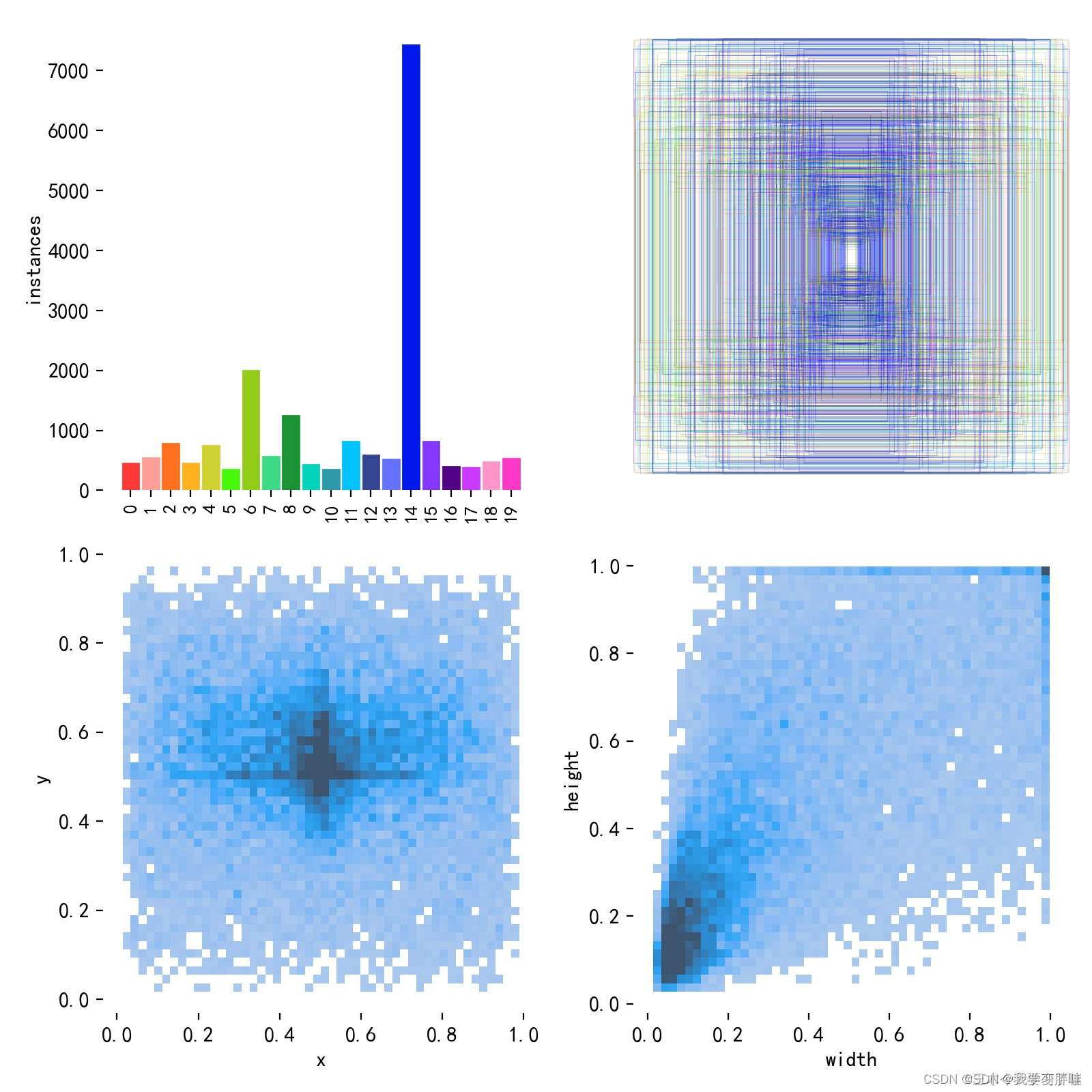
第一个图是训练集得数据量,每个类别有多少个;
第二个图是框的尺寸和数量;
第三个图是中心点相对于整幅图的位置;
第四个图是图中目标相对于整幅图的高宽比例;
七、labels_correlogram.jpg —— 体现中心点横纵坐标以及框的高宽间的关系
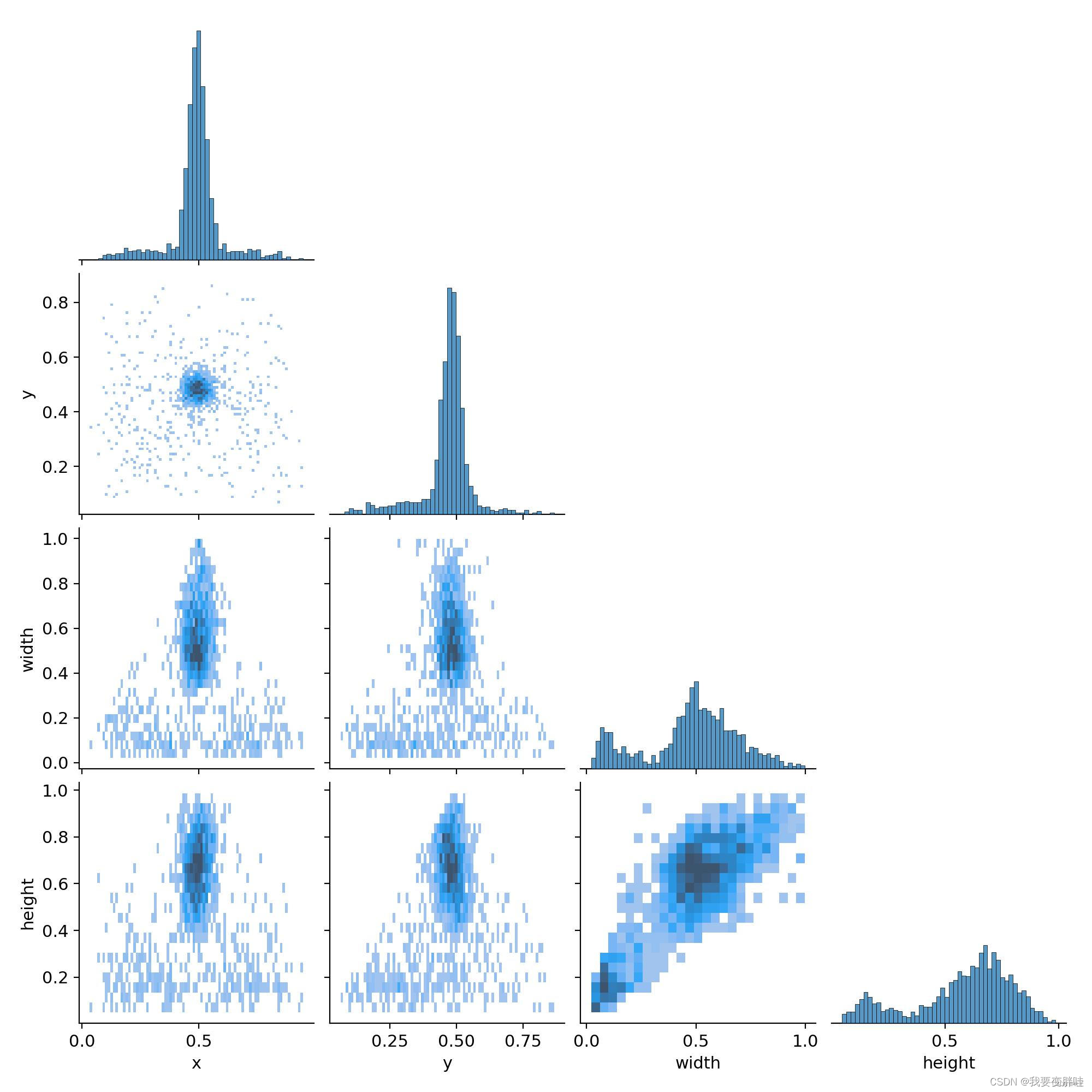
表示中心点坐标x和y,以及框的高宽间的关系。
每一行的最后一幅图代表的是x,y,宽和高的分布情况:
最上面的图(0,0)表明中心点横坐标x的分布情况,可以看到大部分集中在整幅图的中心位置;
(1,1)图表明中心点纵坐标y的分布情况,可以看到大部分集中在整幅图的中心位置;
(2,2)图表明框的宽的分布情况,可以看到大部分框的宽的大小大概是整幅图的宽的一半;
(3,3)图表明框的宽的分布情况,可以看到大部分框的高的大小超过整幅图的高的一半
而其他的图即是寻找这4个变量间的关系
八、result.png —— 结果loss functions

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

