
- 1python爬取高德地图道路交通状态数据代码_高德路网数据爬取
- 2【安路FPGA】从流水灯入门安路开发环境_安路cpld ip怎么用 csdn
- 3**office2016下安装mathtype报错:The MathType DLL cannot be found.Please reinstall Math
- 4问卷星使用入门指南:编程实现问卷星自动化_问卷调查软件可以插入代码吗
- 5SQL INSERT INTO TABLE SELECT指定插入字段的新用法
- 6NLTK和jieba这两个python的自然语言包(HMM,rnn,sigmoid
- 7fabirc的get或者put抛出的paramiko.ssh_exception.SSHException: Channel closed.
- 8基于STM32的人体心率血氧无线检测系统设计(一)_esp8266-01s max30102
- 9Rstudio devtools.install_github()下载失败解决_r语言devtools下载不了
- 10人工智能之产生式系统_产生式系统py
机器学习和深度学习--李宏毅(笔记与个人理解)Day17
赞
踩
Day 17Convolutional Neyral Network (CNN)
卷积神经网络一般都用在image 上面比较多一些,所以课程的例子大多数也都是image
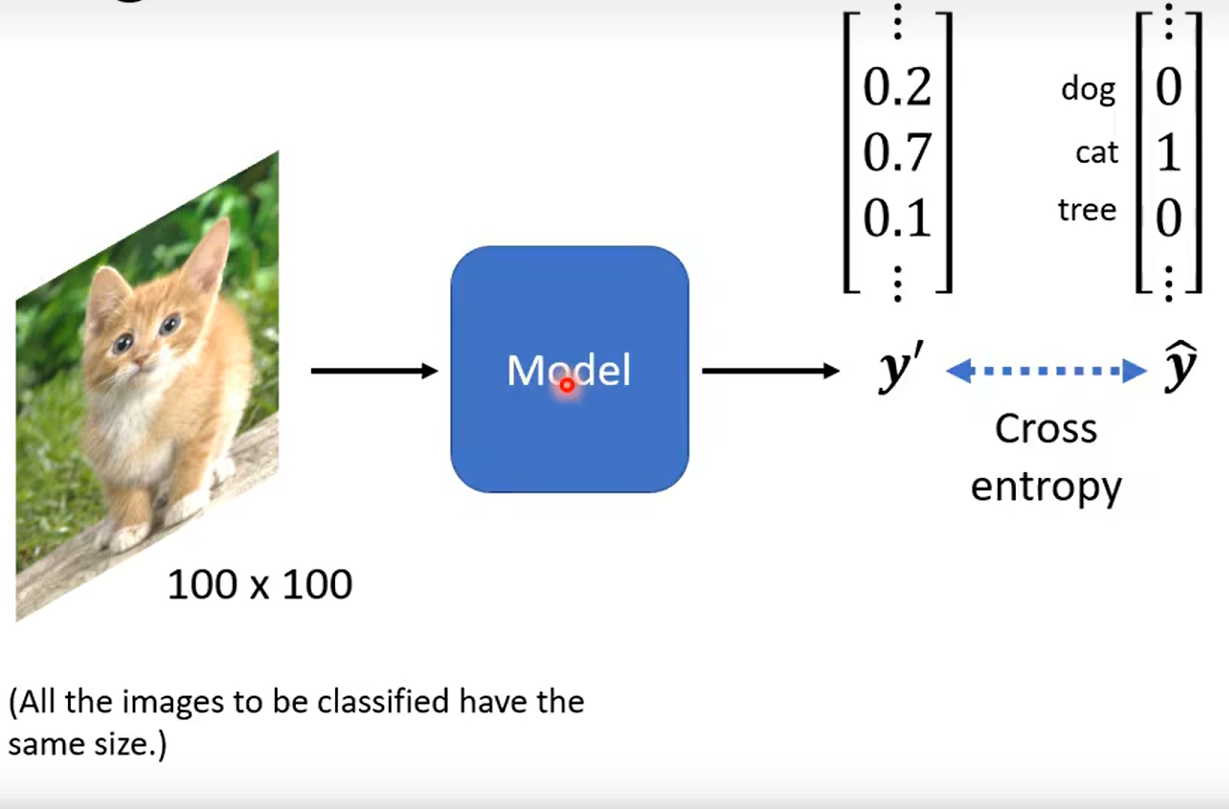
Image Classification
the same size
how about for pc?

这里对于tensor 张量这个概念,我还是比较奇怪,在我认为一个矩阵也可以表示三维的空间;为什么引入tensor这个概念;
听完那个课程我悟了,tensor作为多维数组来说,更具有高维空间的特性;就拿上面的图片举例子,extremely case 我们取一维向量来表示(铺开),这样就会丢失一些空间的信息,例如绿色的格子和蓝色的某个格子其实是垂直的,仅仅相差一个垂直距离,但是展开为一根棍就很难找到这种关联
向量中某一个格子的数值表示该种颜色的强度
好了我猜你紧接着就要说,啊啊啊这个什么weight 太大了,更新一次太麻烦啦巴拉巴拉的
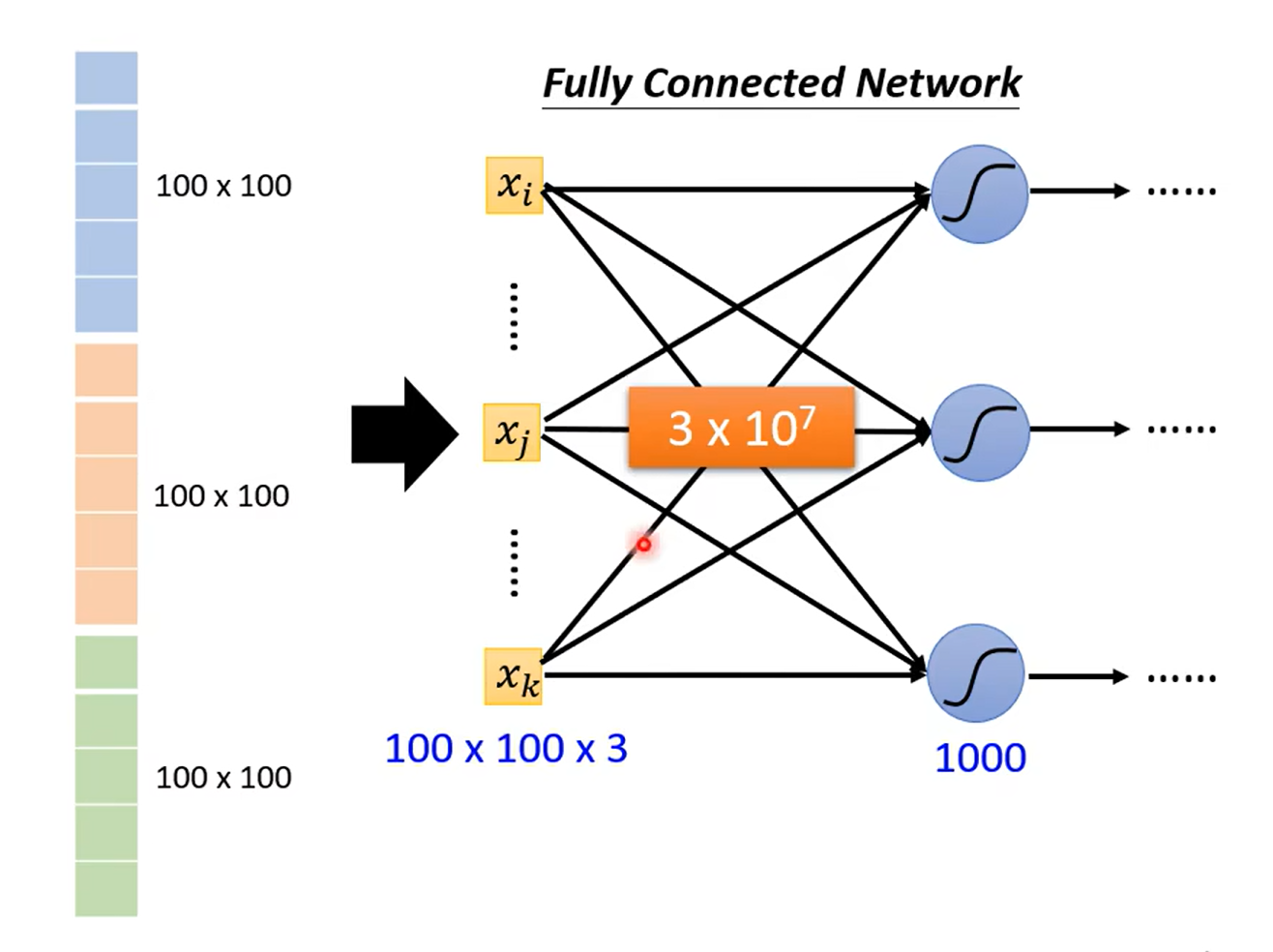
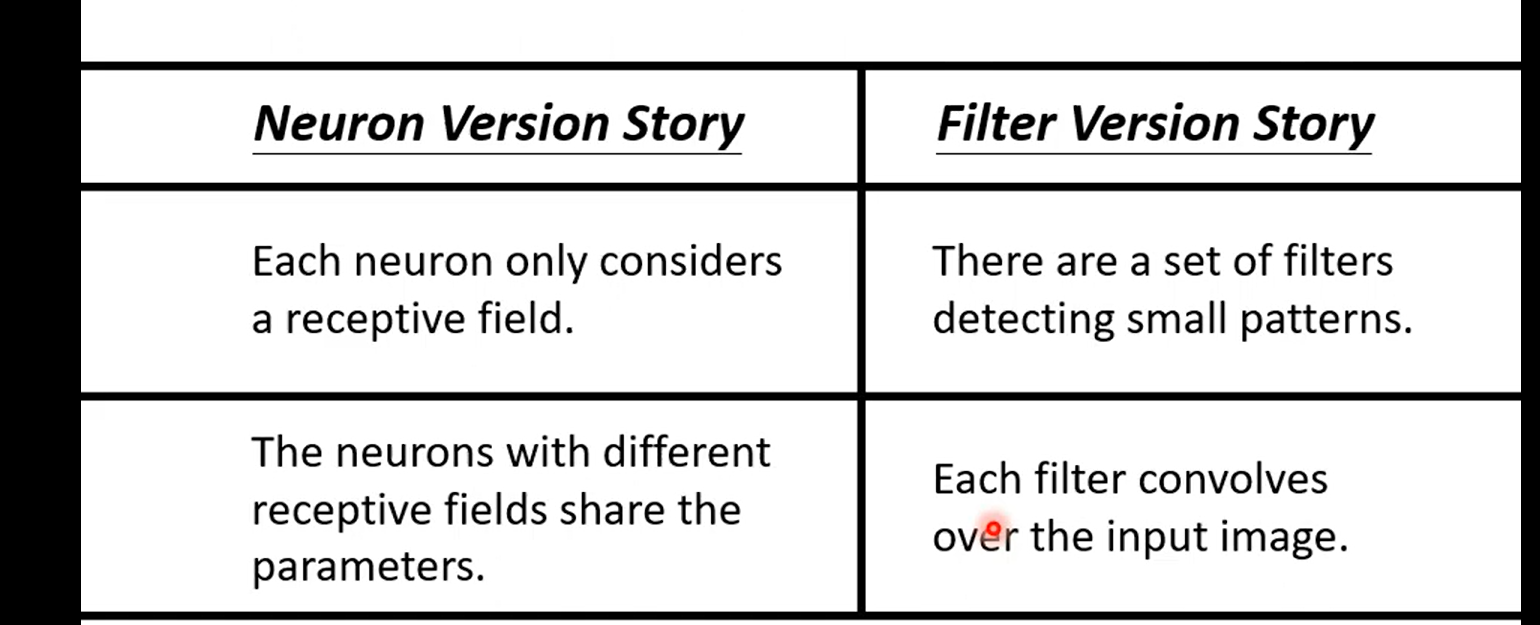
Do we need “fully connected” in image processing ?
so we need some observations
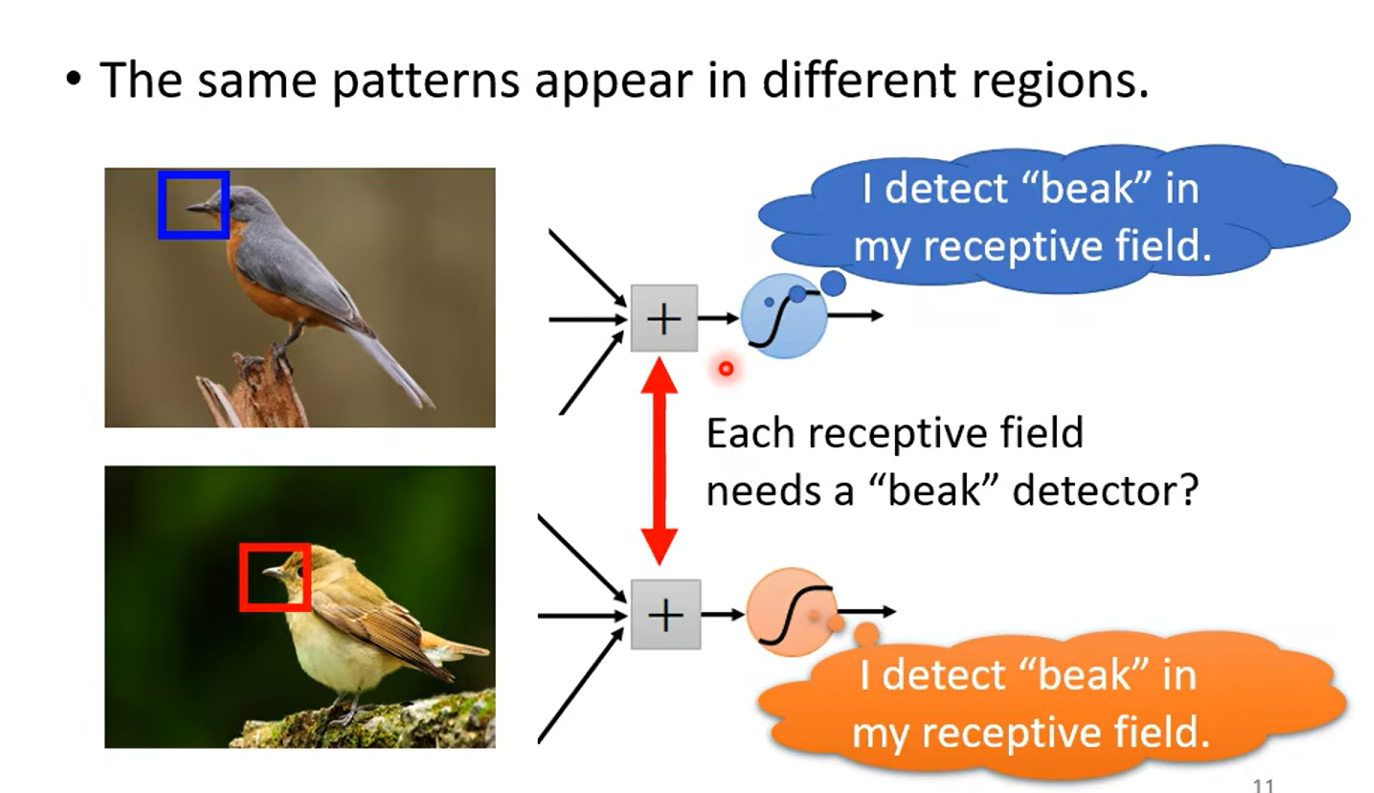
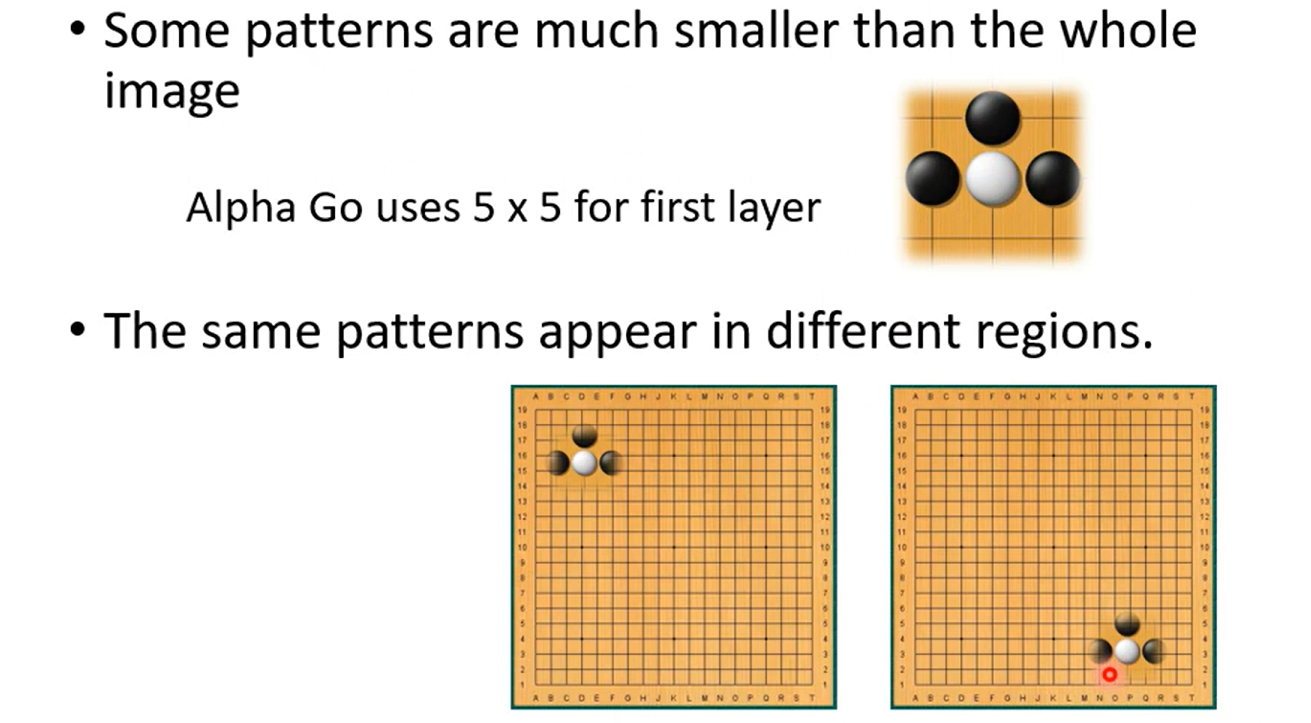
Obervation1
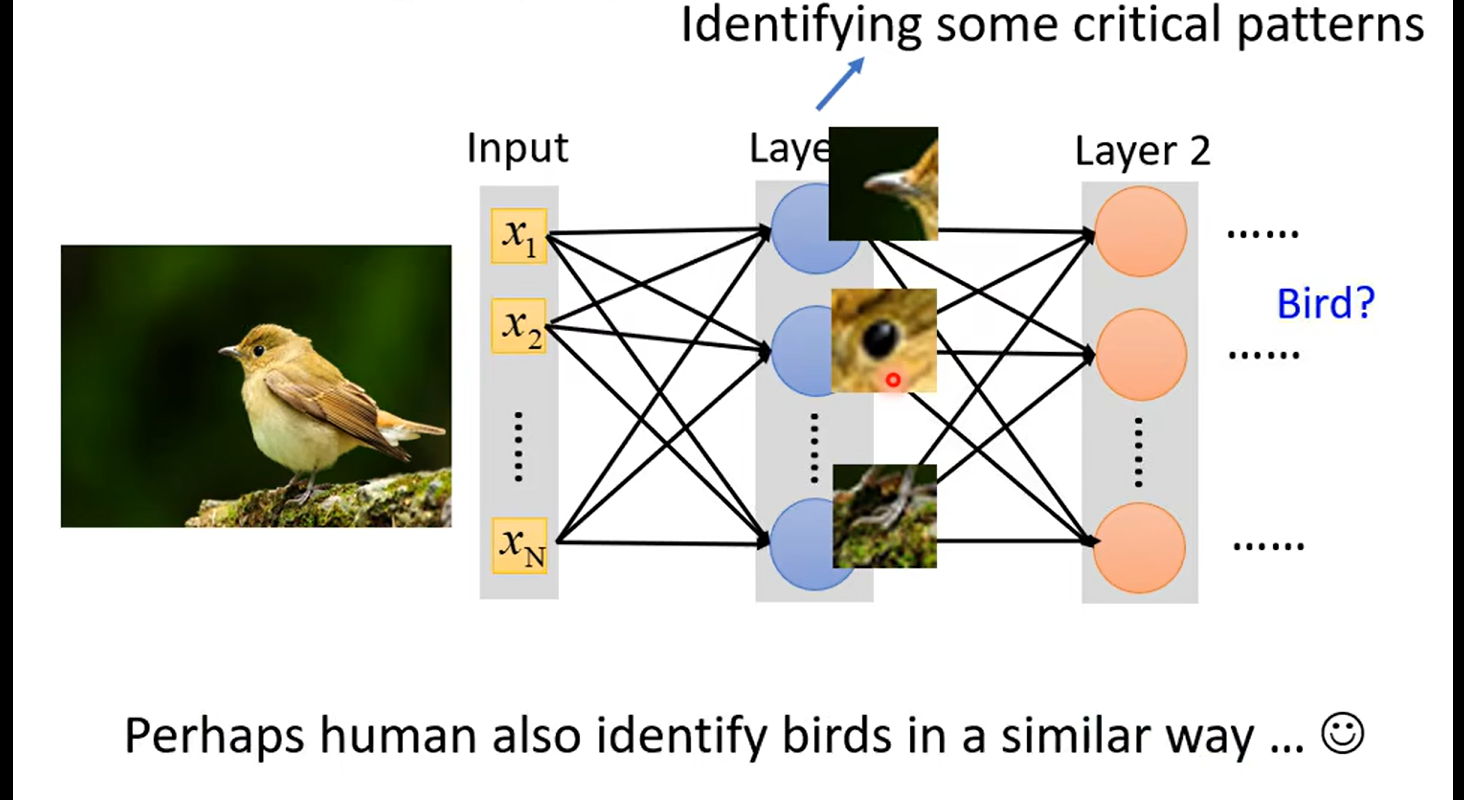
so not whole image ,but some patterns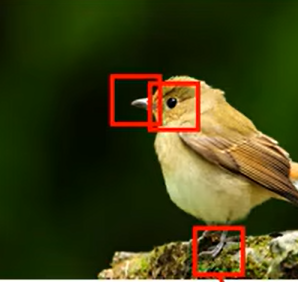
Simplification 1
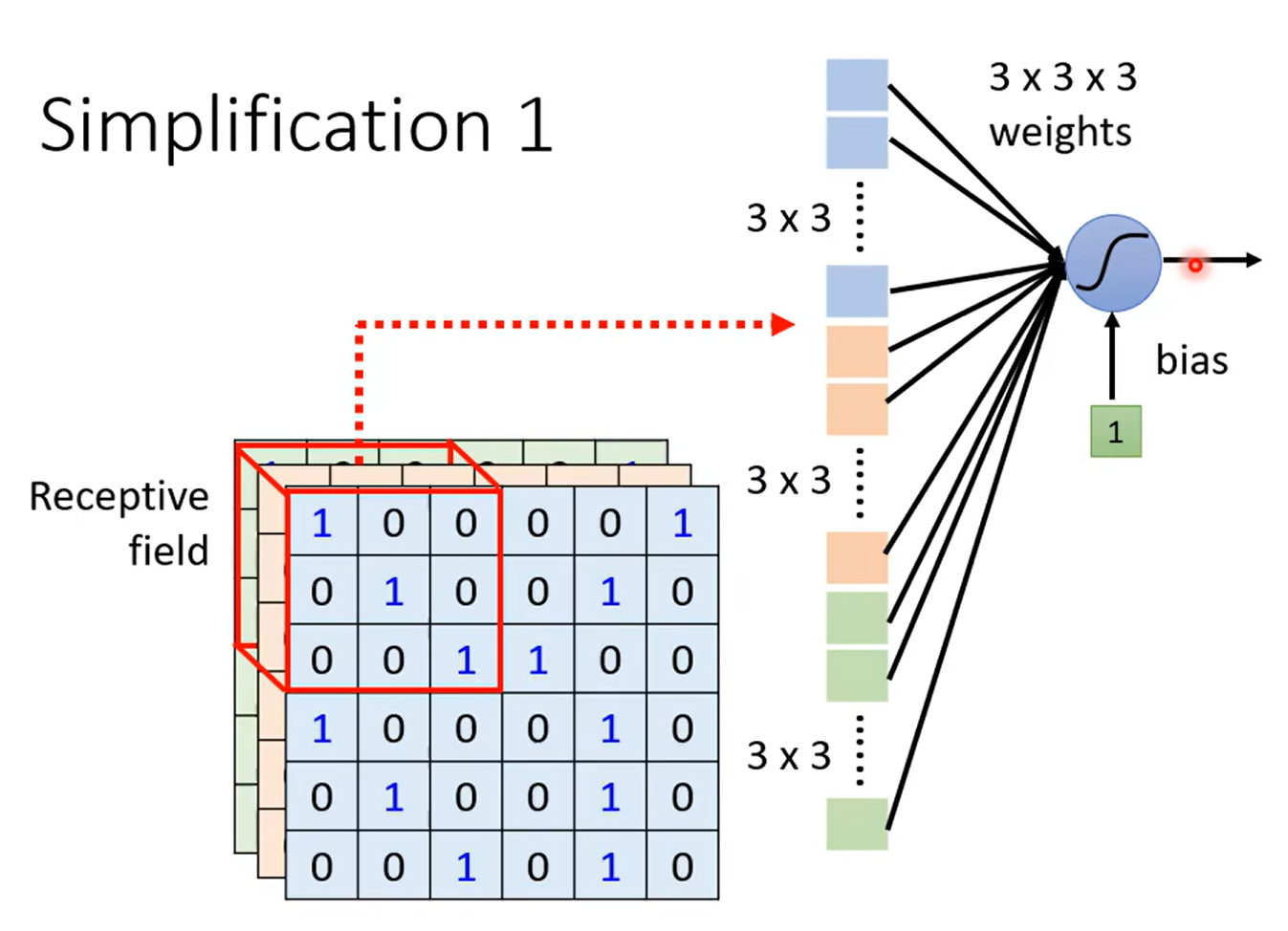



Typical Setting
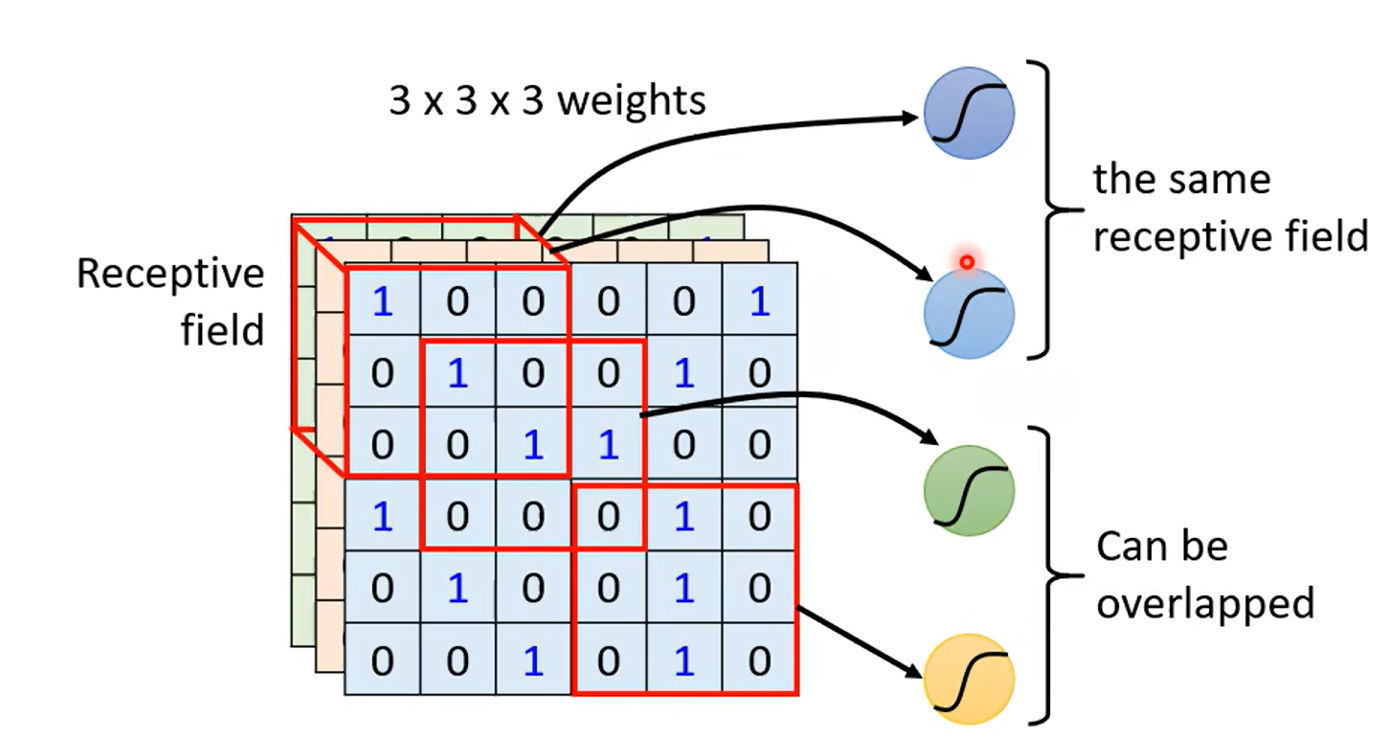
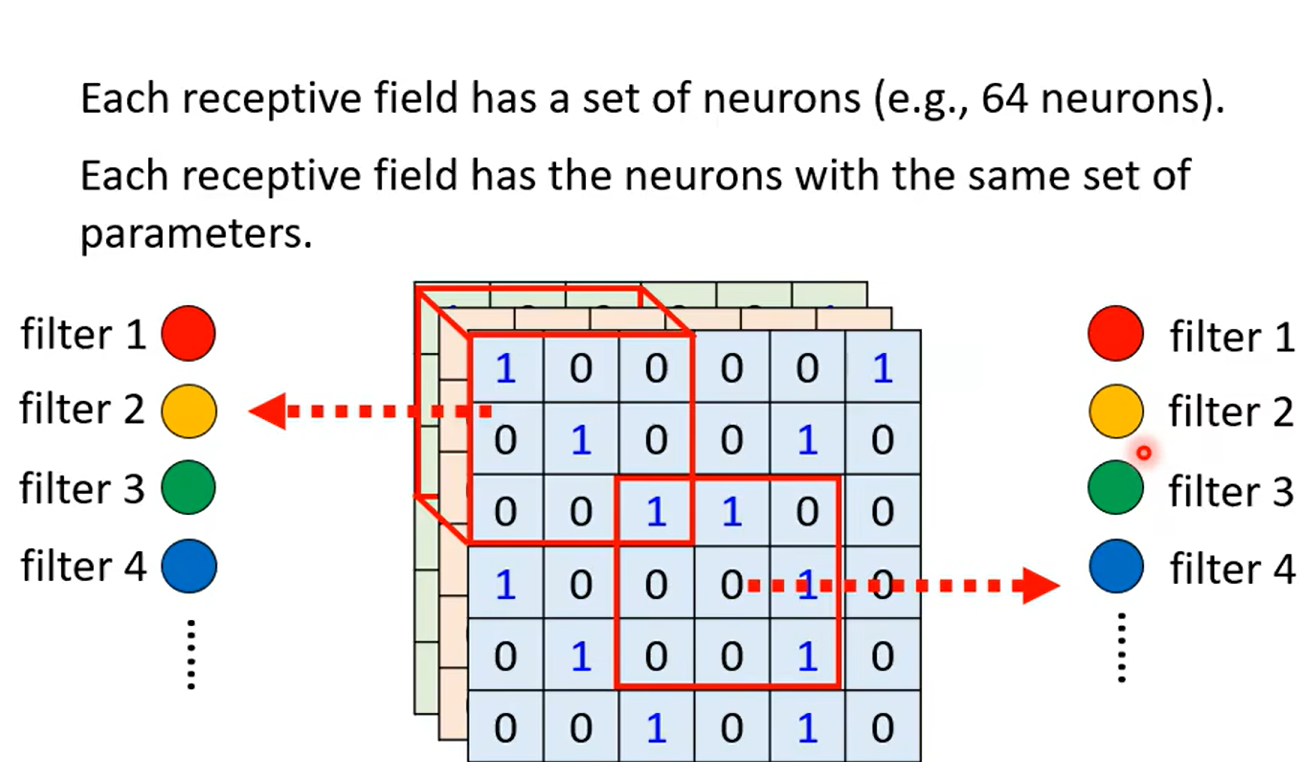
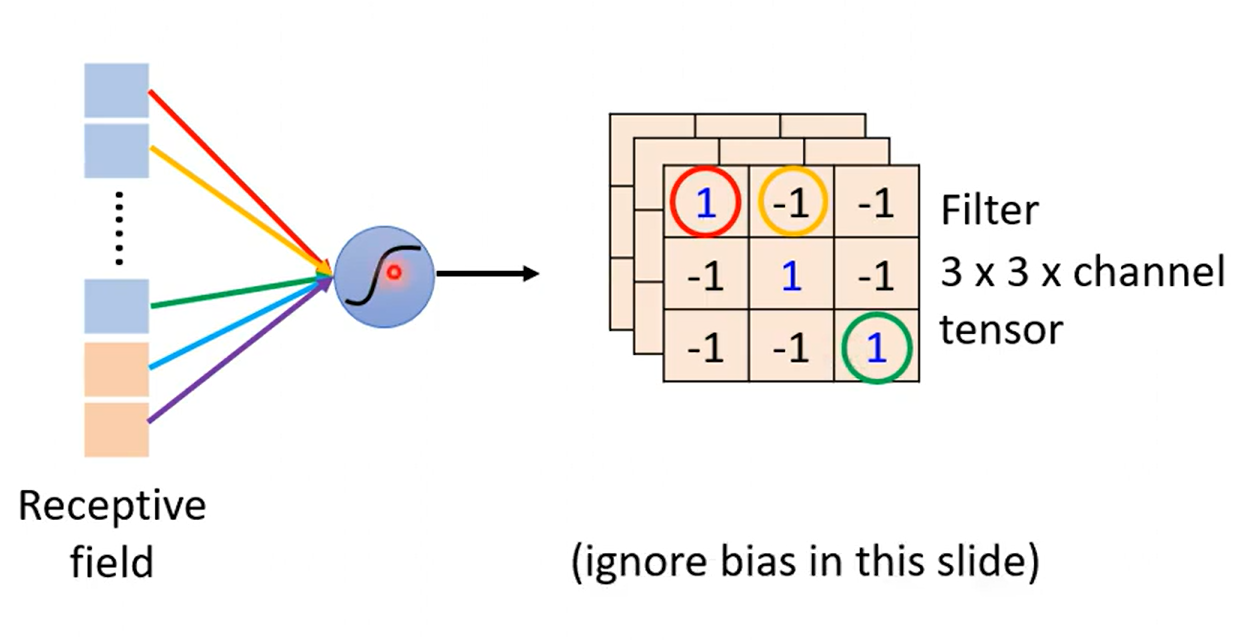
Obervation 2
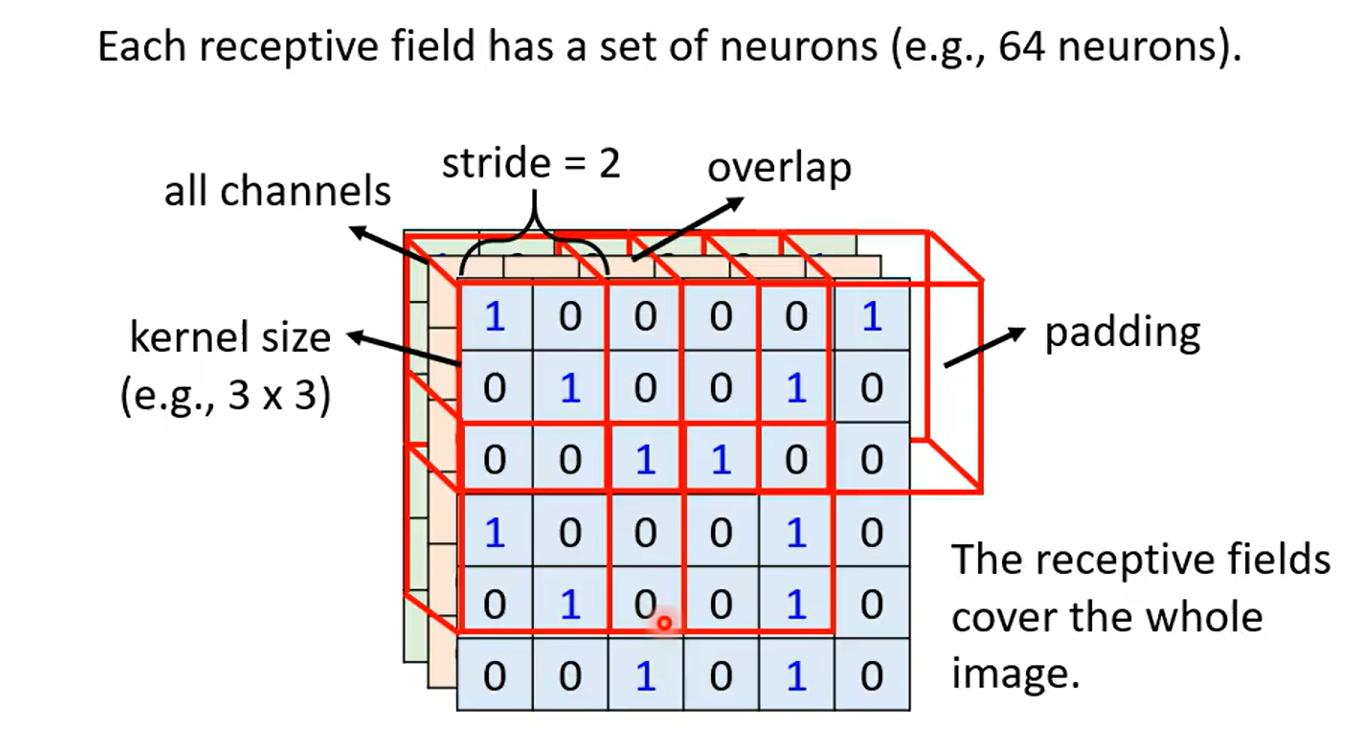
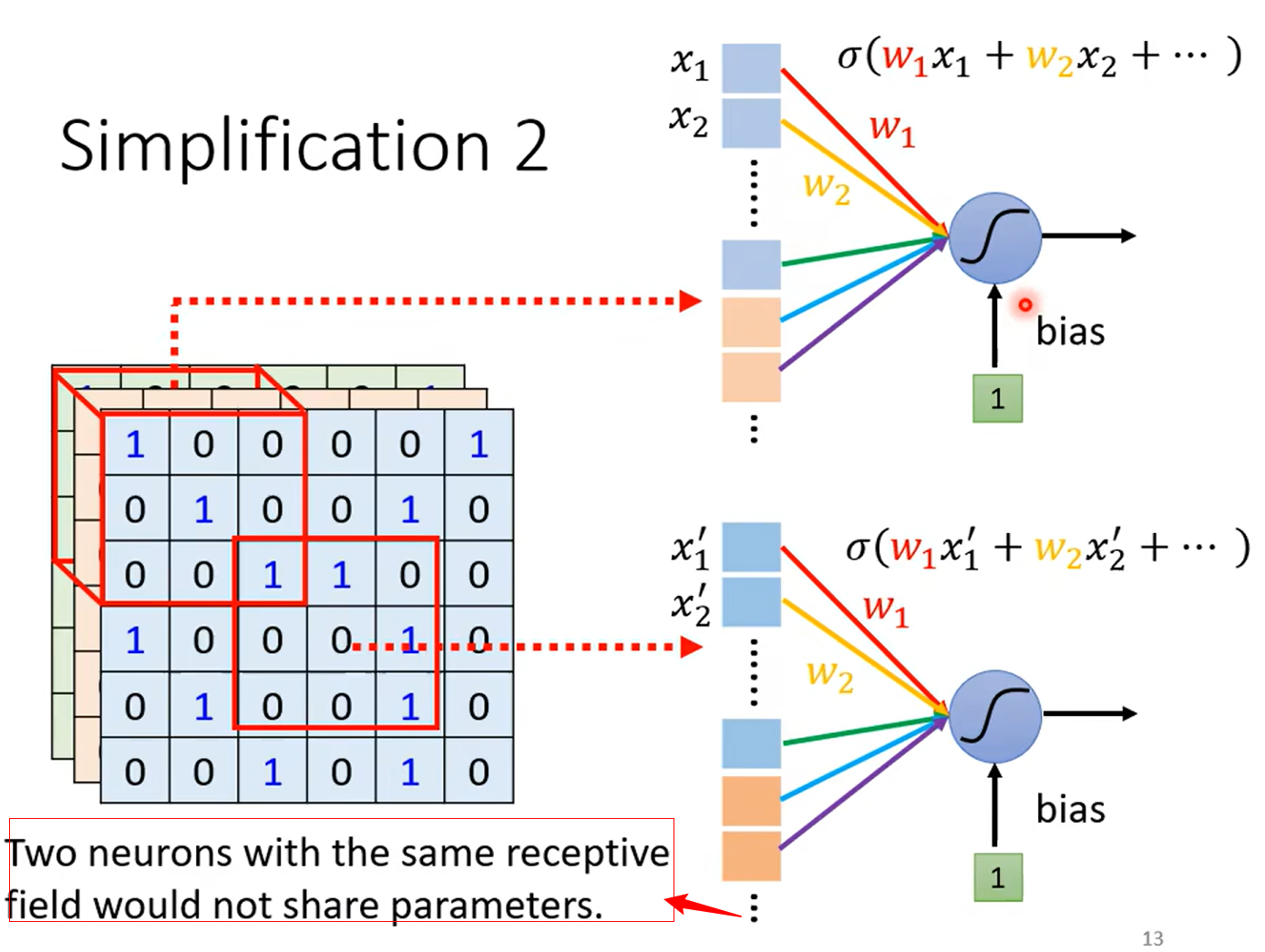
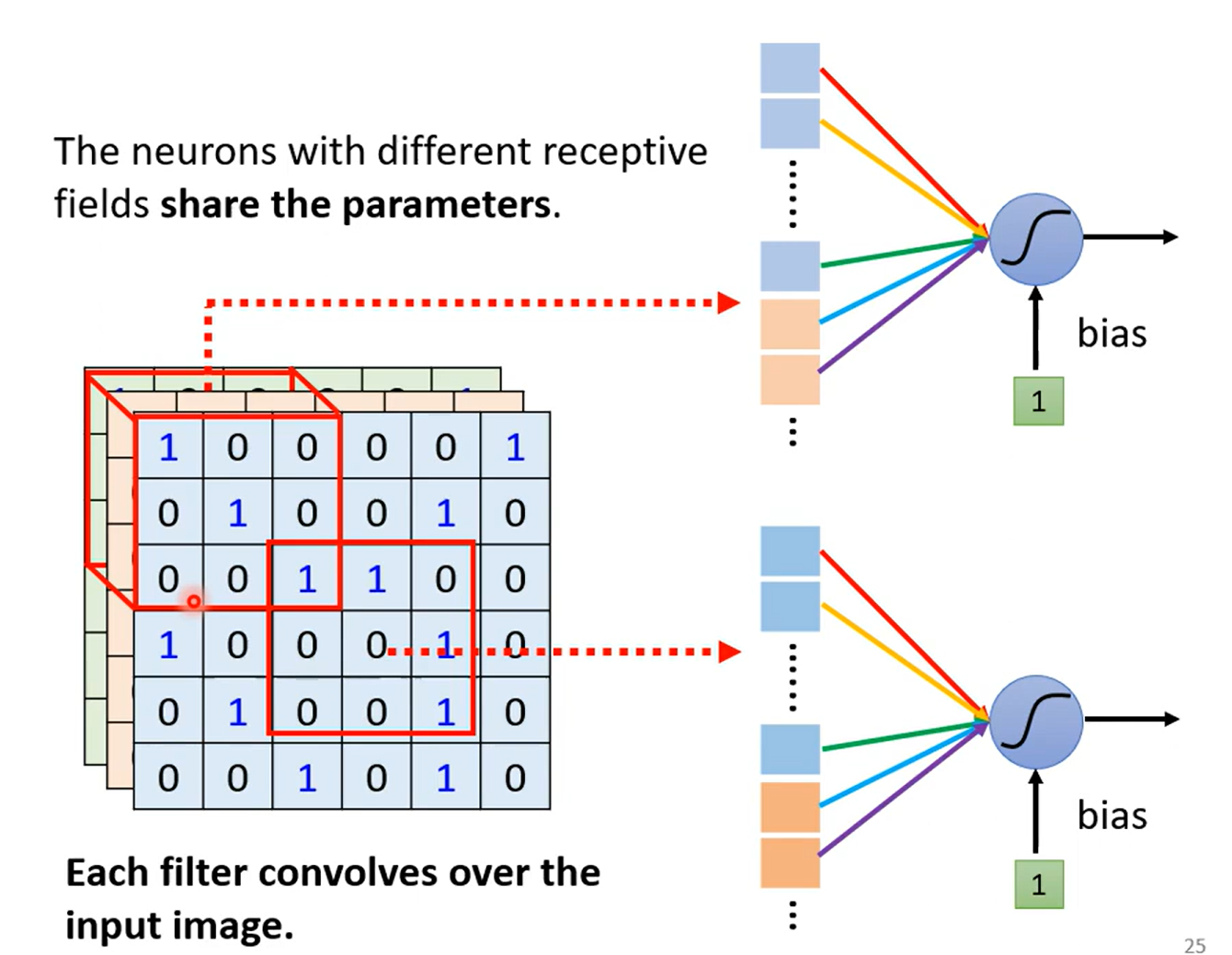
Simplification 2 sharing parameters
Typical
有了两种简化的方式了,我们来总结一下我们学到了什么
CNN 的model 的bias比较大
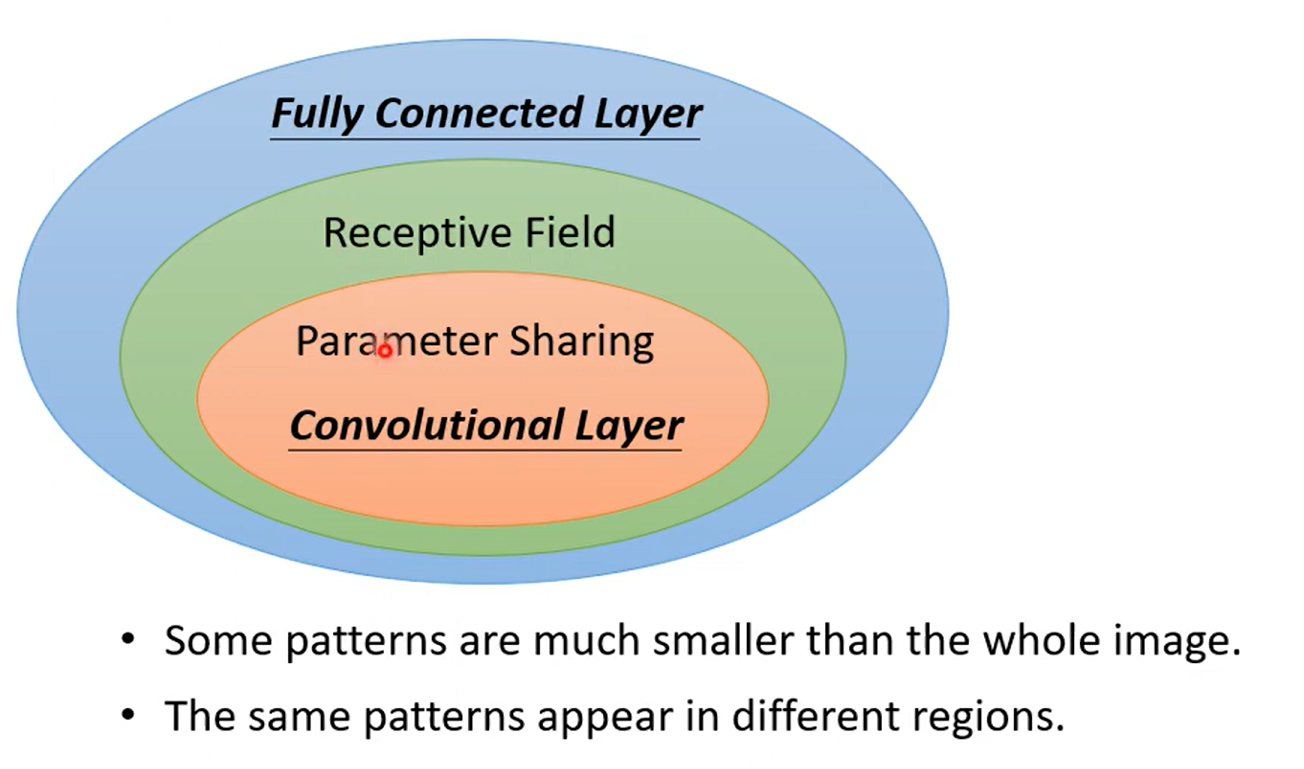
Fully connected Layer jack of all trades master of none
Another Story
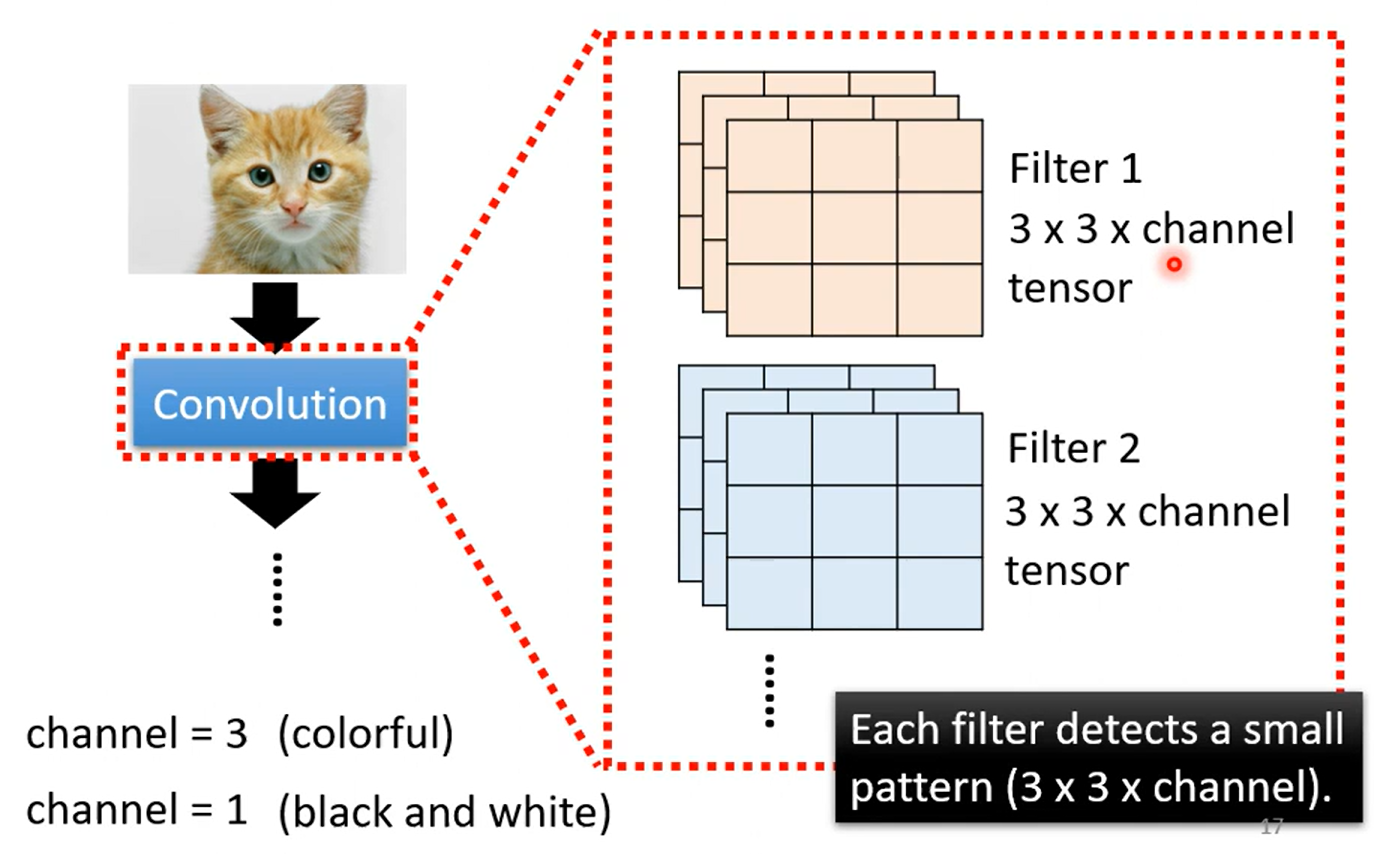
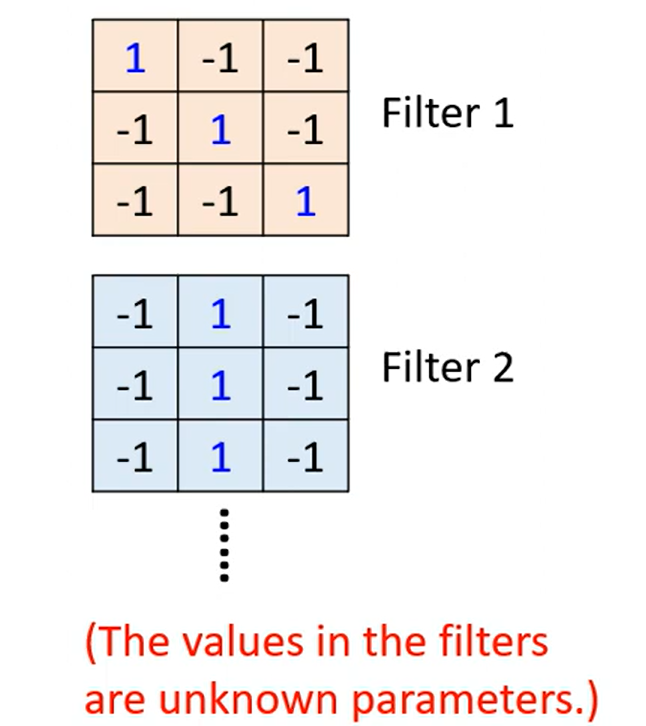
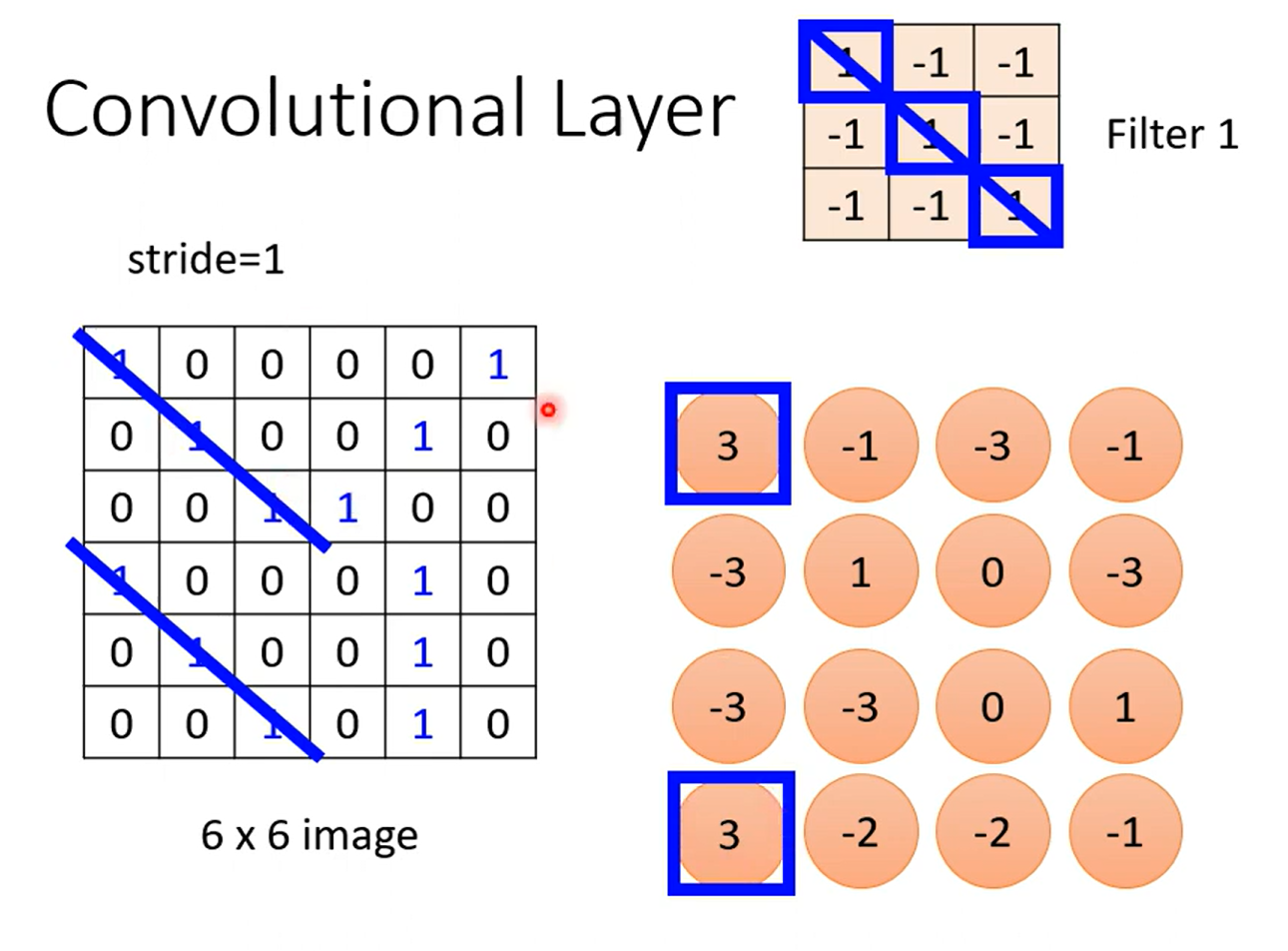

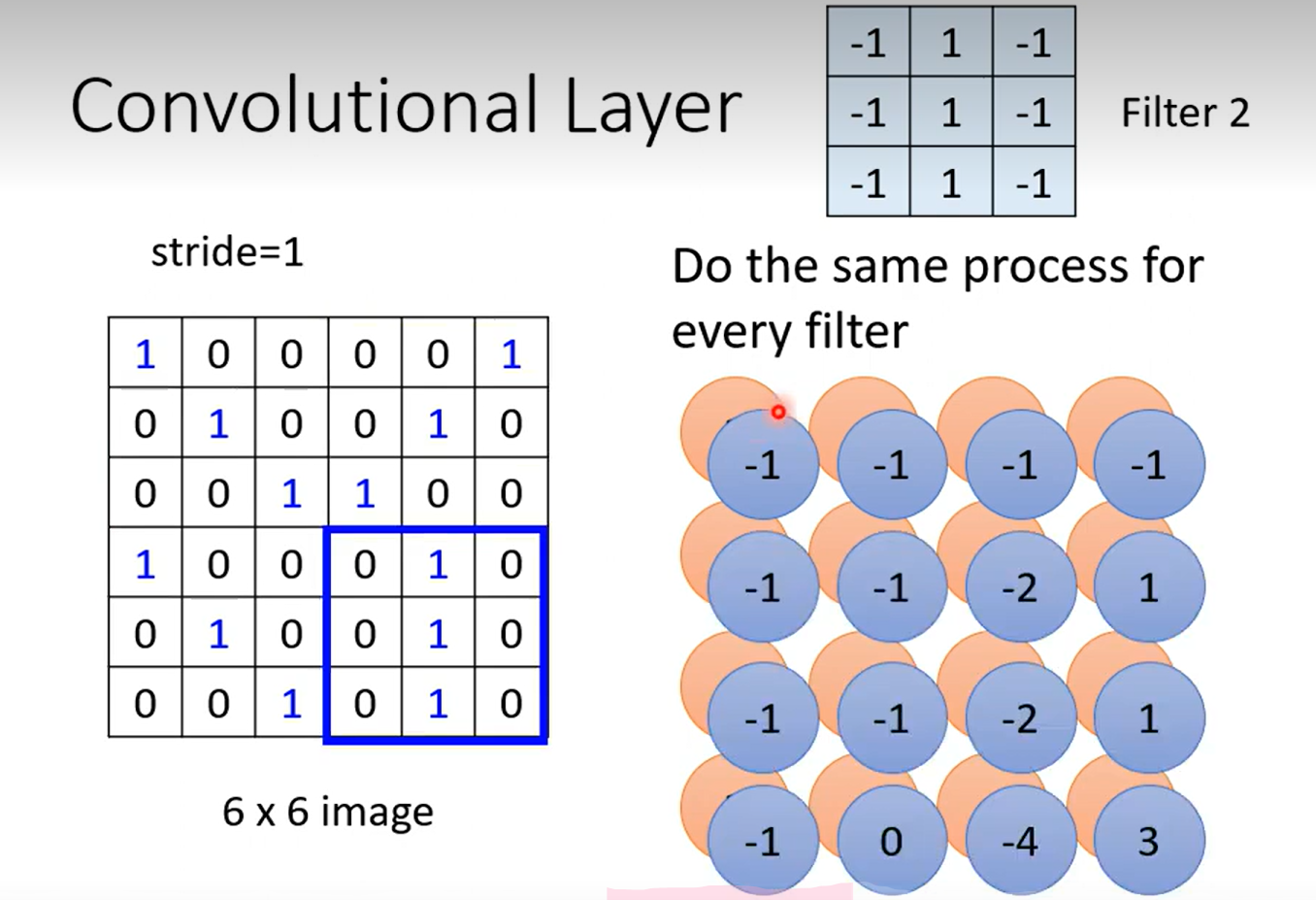
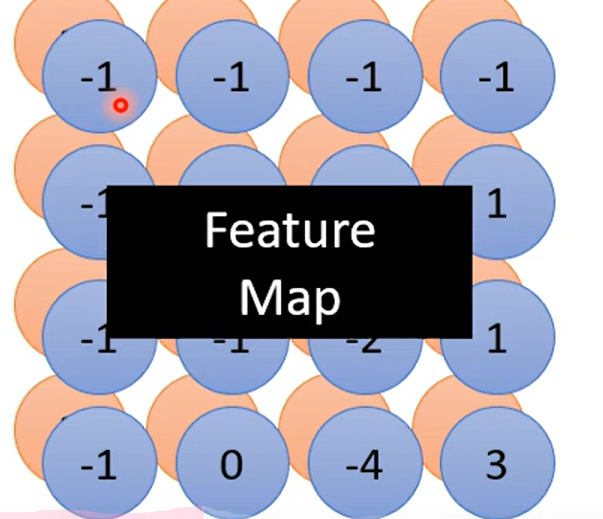
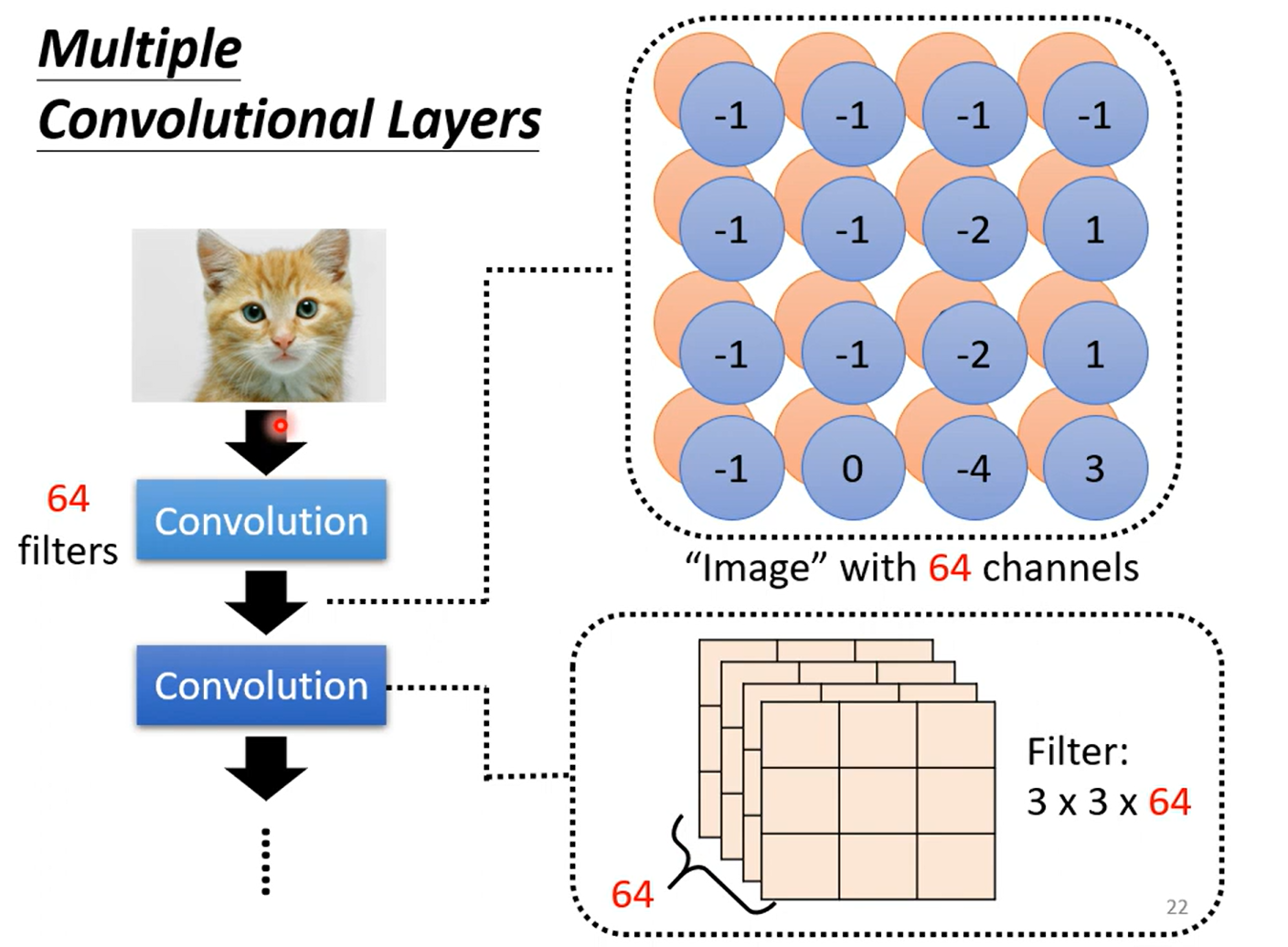
这张ppt好好理解一下, 理解不了的话我给你讲讲:
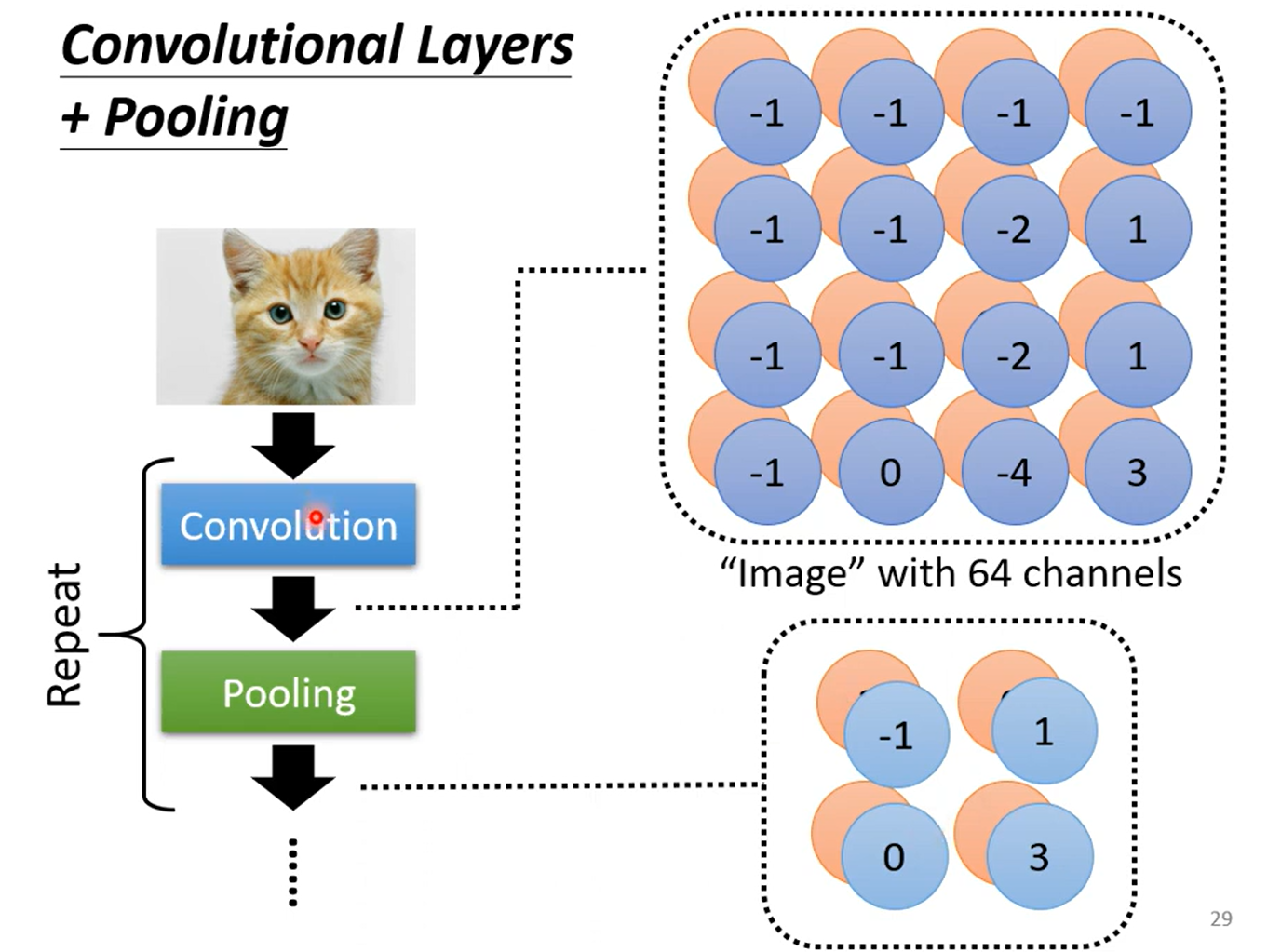
首先按照Convolution 分为上下两个 part 哈,上面那个是由64个fitter (高度/厚度 =1, 因为原始图像的channel =1 是黑白图像,这里我们考虑typical的情况) 分别对原image做卷积得到的;每一个高度可以作为一个feature Map;ok ,然后我们知道 RGB 其实也是一个图像的三个channel 三个 feature Map;那么我们自然而然的认为这个厚度为64的feature map 叠起来的厚吐司 也是一个64channel 的图像;迭代为原始图像,那么下一次进行卷积的时候我们就需要64个厚度为64的fitter,也就是下面的两个64 的不同含义~ ok,打完收工
一个问题,如果fitter 一直等于 3*3 会不会严重丢失全局信息?为什么?
- 我认为和stride有关,一直有重叠
- 更直接的解释 从 3 * 3 到 5 * 5
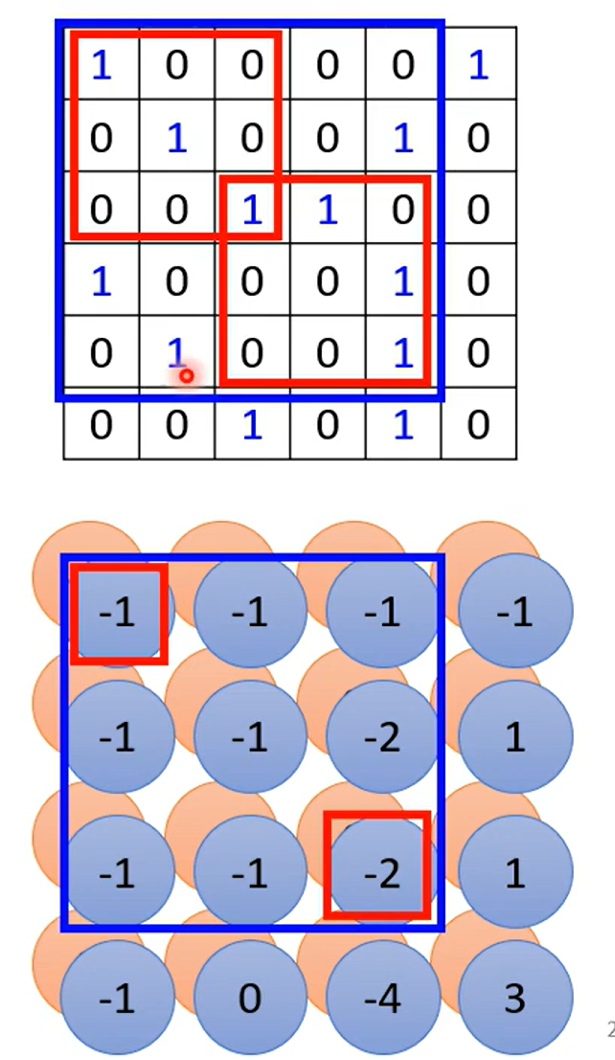
殊途同归
boy 聪明的,比较颜色就好~ 要学会适度自学哦
Observation 3

Simpification 3(Pooling)
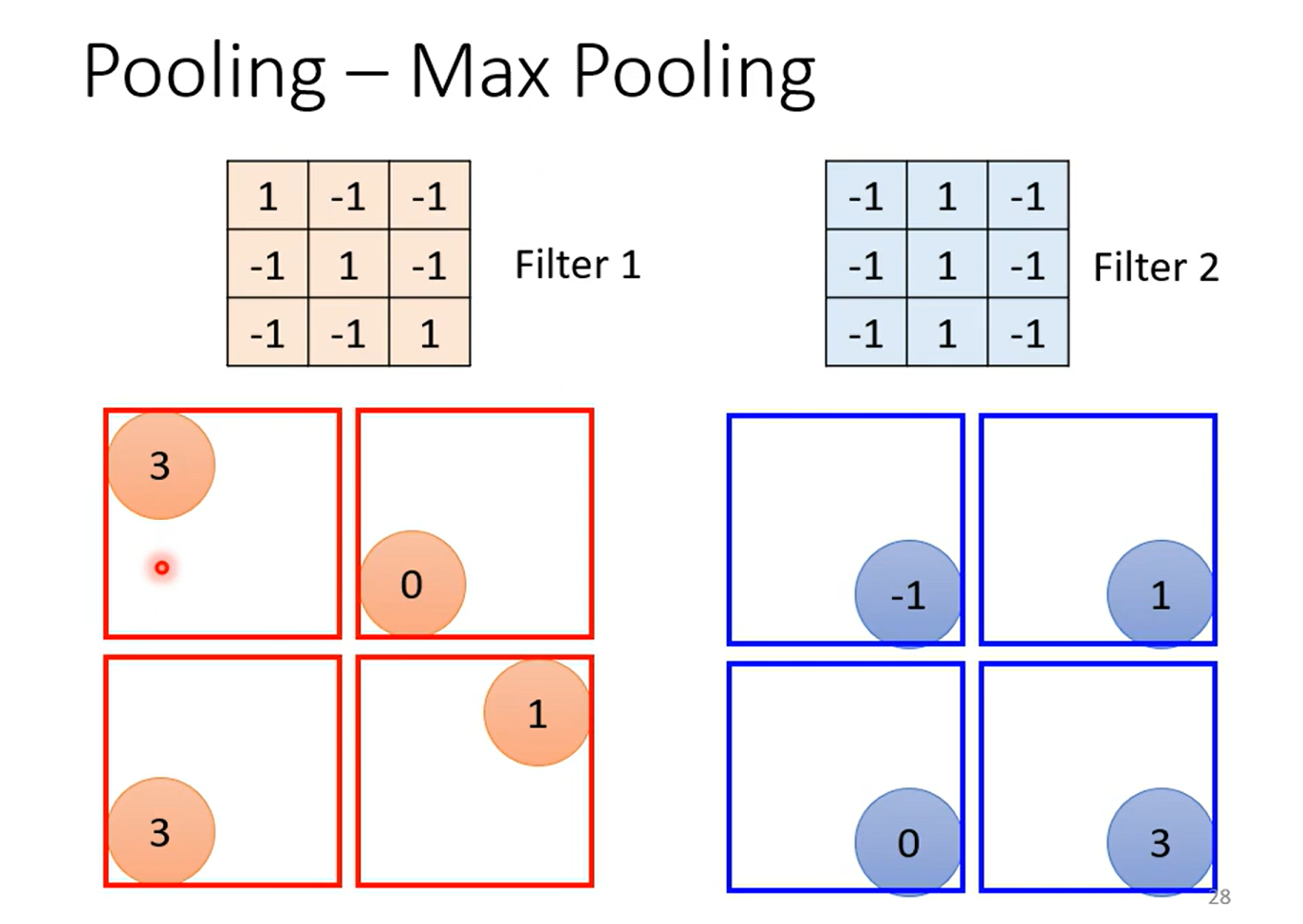
subSampling 会丢失一定的信息,随着 计算机上升,下采样逐渐式微
The whole CNN……
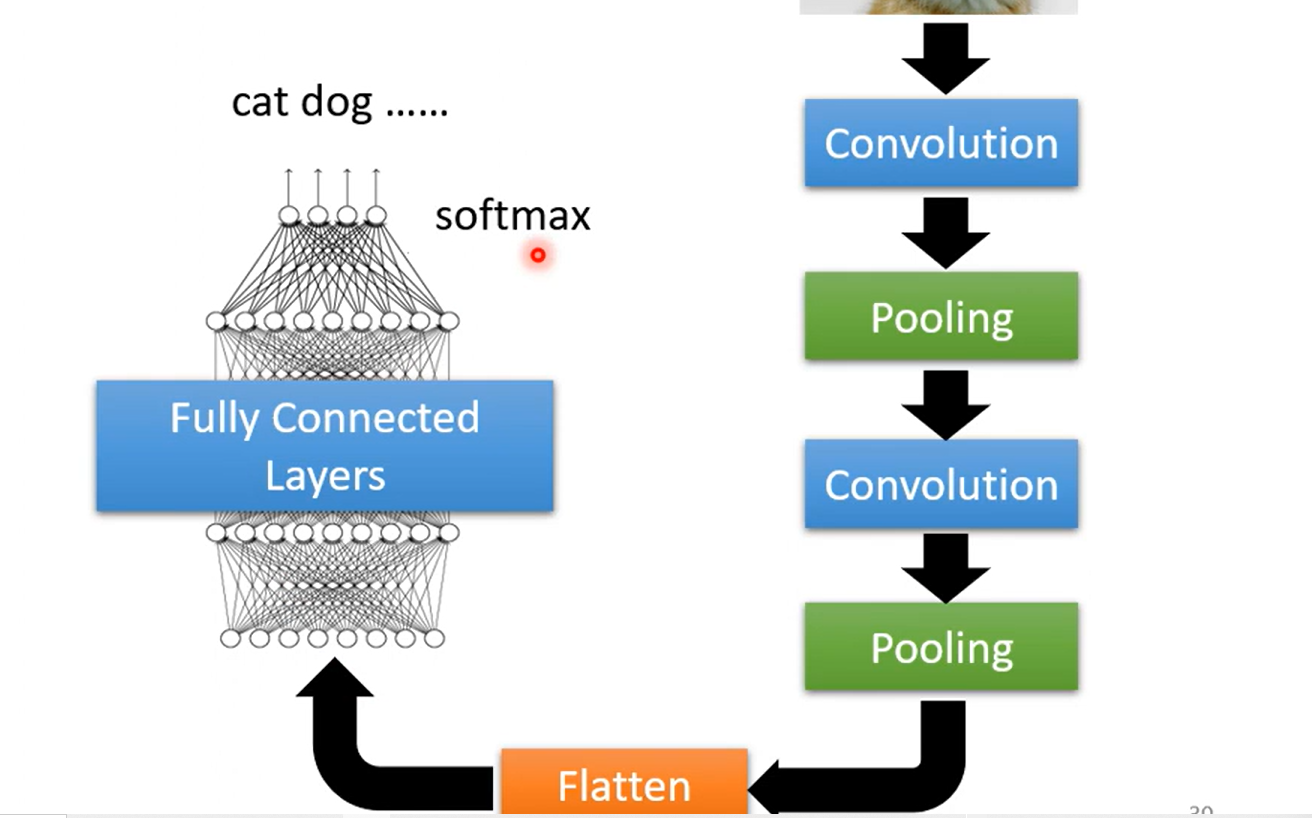
Flatten 拉直
Application-- 阿尔法狗
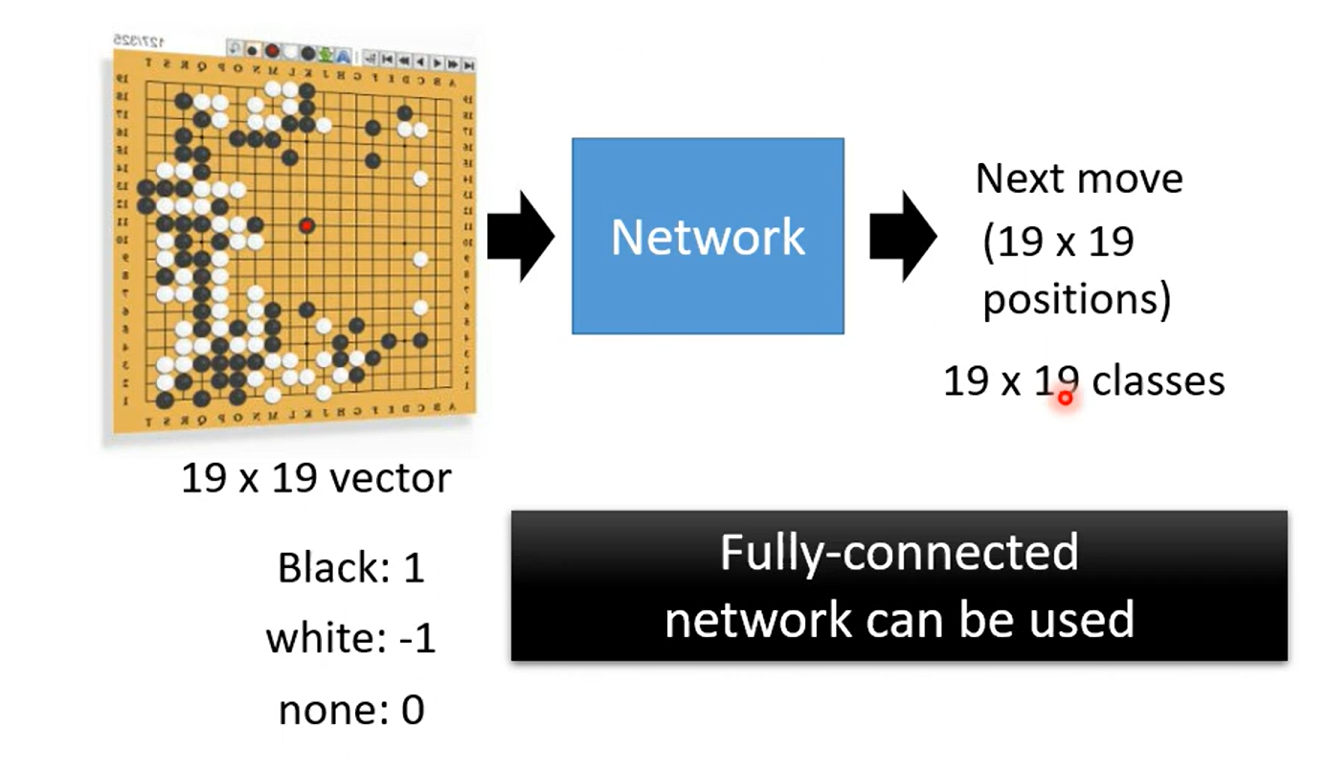
so why CNN?
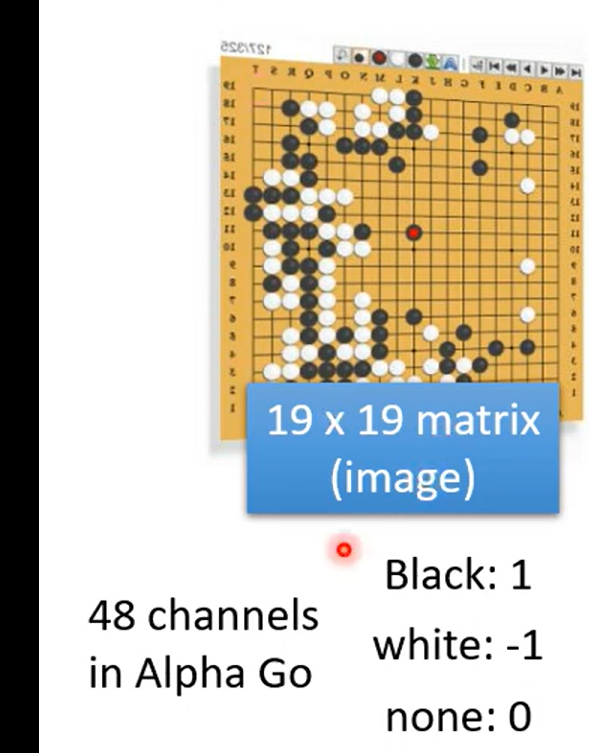
当成一个图片,然后48个channel 表示该点处的48种情况


more thinking :
CNN 好像没有办法处理影响放大缩小,或者反转的情况;so we need data augmentation ;
Spatial Transformer Layer

