- 1Python中的运算符_py中运算符
- 2【开关电源四】电源拓扑之Cuk、Sepic、Zeta_cuk电路
- 3微信客户端登陆多个账号详细教程_ctrl加什么登录多个微信号
- 4Redis Pipelining 底层原理分析及实践
- 5错题记录-华为海思
- 63060显卡下CUDA+CUDNN+Paddle安装的血泪史_3060 cuda
- 7使用OpenAI Whipser开源模型实现长音频转录并结合GPT模型做文本翻译_开源语yin转文本
- 8gin实现event stream_gin stream
- 9如何判断模型是否训练过拟合?解决措施是什么?_如何判断模型是否过拟合
- 10如何使用OpenCV进行图像读取和显示?_使用opencv库读取图片并显示
面试二十二、跳表SkipLists
赞
踩
跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn)。快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集(见右边的示意图)。一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。
一张跳跃列表的示意图。每个带有箭头的框表示一个指针, 而每行是一个稀疏子序列的链表;底部的编号框(黄色)表示有序的数据序列。查找从顶部最稀疏的子序列向下进行, 直至需要查找的元素在该层两个相邻的元素中间。
跳表的演化过程
对于单链表来说,即使数据是已经排好序的,想要查询其中的一个数据,只能从头开始遍历链表,这样效率很低,时间复杂度很高,是 O(n)。
那我们有没有什么办法来提高查询的效率呢?我们可以为链表建立一个“索引”,这样查找起来就会更快,如下图所示,我们在原始链表的基础上,每两个结点提取一个结点建立索引,我们把抽取出来的结点叫做索引层或者索引,down 表示指向原始链表结点的指针。
现在如果我们想查找一个数据,比如说 15,我们首先在索引层遍历,当我们遍历到索引层中值为 14 的结点时,我们发现下一个结点的值为 17,所以我们要找的 15 肯定在这两个结点之间。这时我们就通过 14 结点的 down 指针,回到原始链表,然后继续遍历,这个时候我们只需要再遍历两个结点,就能找到我们想要的数据。好我们从头看一下,整个过程我们一共遍历了 7 个结点就找到我们想要的值,如果没有建立索引层,而是用原始链表的话,我们需要遍历 10 个结点。
通过这个例子我们可以看出来,通过建立一个索引层,我们查找一个基点需要遍历的次数变少了,也就是查询的效率提高了。
那么如果我们给索引层再加一层索引呢?遍历的结点会不会更少呢,效率会不会更高呢?我们试试就知道了。
现在我们再来查找 15,我们从第二级索引开始,最后找到 15,一共遍历了 6 个结点,果然效率更高。
当然,因为我们举的这个例子数据量很小,所以效率提升的不是特别明显,如果数据量非常大的时候,我们多建立几层索引,效率提升的将会非常的明显,感兴趣的可以自己试一下,这里我们就不举例子了。
这种通过对链表加多级索引的机构,就是跳表了。
跳表具体有多快
通过上边的例子我们知道,跳表的查询效率比链表高,那具体高多少呢?下面我们一起来看一下。
衡量一个算法的效率我们可以用时间复杂度,这里我们也用时间复杂度来比较一下链表和跳表。前面我们已经讲过了,链表的查询的时间复杂度为 O(n),那跳表的呢?
如果一个链表有 n 个结点,如果每两个结点抽取出一个结点建立索引的话,那么第一级索引的结点数大约就是 n/2,第二级索引的结点数大约为 n/4,以此类推第 m 级索引的节点数大约为 n/(2^m)。
假如一共有 m 级索引,第 m 级的结点数为两个,通过上边我们找到的规律,那么得出 n/(2^m)=2,从而求得 m=log(n)-1。如果加上原始链表,那么整个跳表的高度就是 log(n)。我们在查询跳表的时候,如果每一层都需要遍历 k 个结点,那么最终的时间复杂度就为 O(k*log(n))。
那这个 k 值为多少呢,按照我们每两个结点提取一个基点建立索引的情况,我们每一级最多需要遍历两个个结点,所以 k=2。为什么每一层最多遍历两个结点呢?
因为我们是每两个结点提取一个结点建立索引,最高一级索引只有两个结点,然后下一层索引比上一层索引两个结点之间增加了一个结点,也就是上一层索引两结点的中值,看到这里是不是想起来我们前边讲过的二分查找,每次我们只需要判断要找的值在不在当前结点和下一个结点之间即可。
跳表是用空间来换时间
跳表的效率比链表高了,但是跳表需要额外存储多级索引,所以需要的更多的内存空间。
跳表的空间复杂度分析并不难,如果一个链表有 n 个结点,如果每两个结点抽取出一个结点建立索引的话,那么第一级索引的结点数大约就是 n/2,第二级索引的结点数大约为 n/4,以此类推第 m 级索引的节点数大约为 n/(2^m),我们可以看出来这是一个等比数列。
这几级索引的结点总和就是 n/2+n/4+n/8…+8+4+2=n-2,所以跳表的空间复杂度为 o(n)。
那么我们有没有办法减少索引所占的内存空间呢?可以的,我们可以每三个结点抽取一个索引,或者没五个结点抽取一个索引。这样索引结点的数量减少了,所占的空间也就少了。
跳表的插入和删除
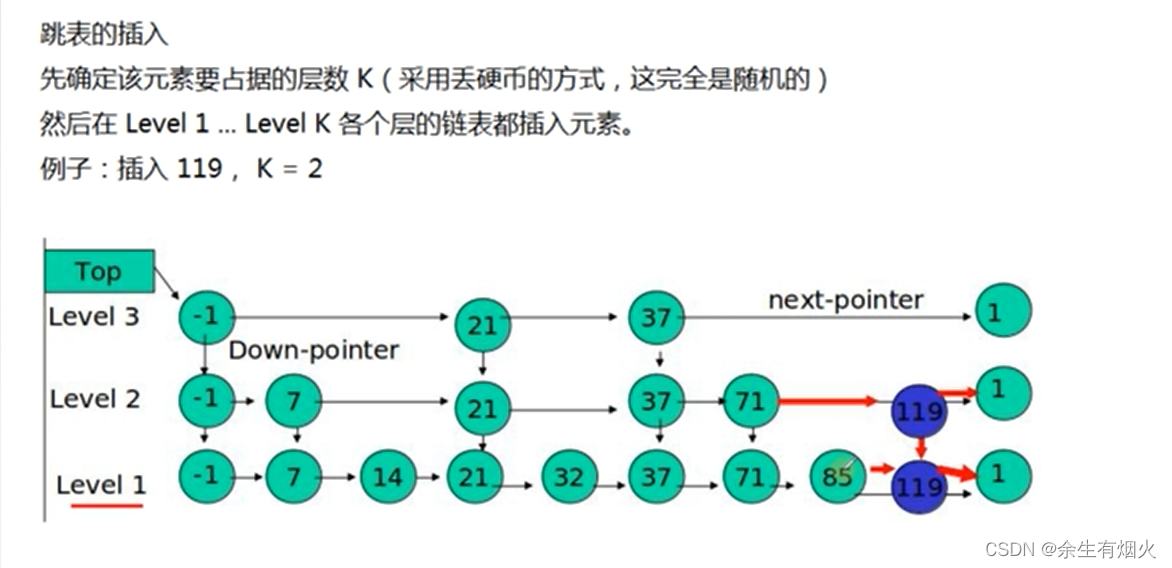
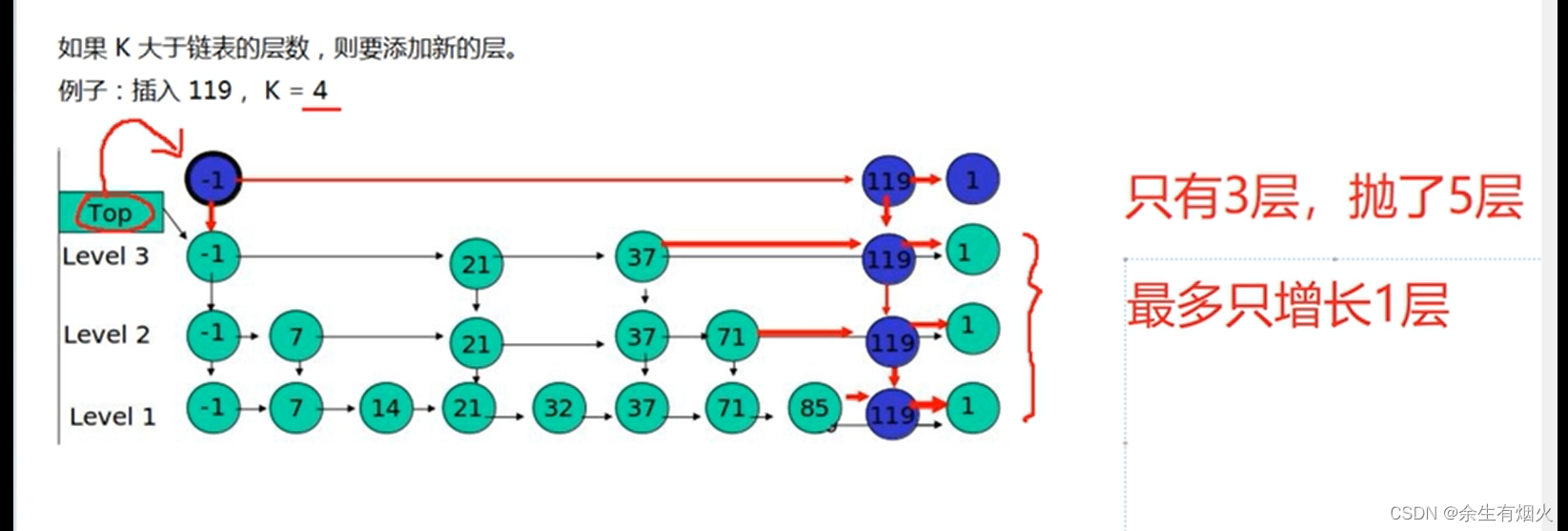

我们想要为跳表插入或者删除数据,我们首先需要找到插入或者删除的位置,然后执行插入或删除操作,前边我们已经知道了,跳表的查询的时间复杂度为 O(logn),因为找到位置之后插入和删除的时间复杂度很低,为 O(1),所以最终插入和删除的时间复杂度也为 O(longn)。
我么通过图看一下插入的过程。
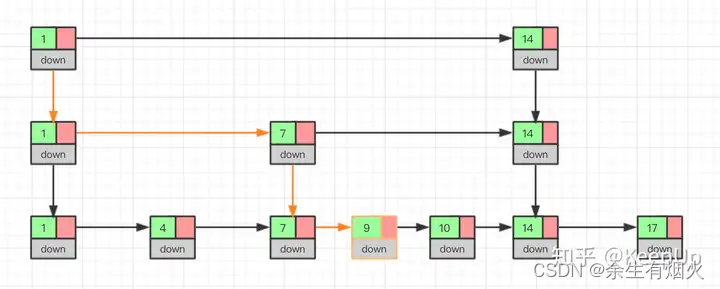
删除操作的话,如果这个结点在索引中也有出现,我们除了要删除原始链表中的结点,还要删除索引中的。因为单链表中的删除操作需要拿到要删除结点的前驱结点,然后通过指针操作完成删除。所以在查找要删除的结点的时候,一定要获取前驱结点。当然,如果我们用的是双向链表,就不需要考虑这个问题了。
如果我们不停的向跳表中插入元素,就可能会造成两个索引点之间的结点过多的情况。结点过多的话,我们建立索引的优势也就没有了。所以我们需要维护索引与原始链表的大小平衡,也就是结点增多了,索引也相应增加,避免出现两个索引之间结点过多的情况,查找效率降低。
跳表是通过一个随机函数来维护这个平衡的,当我们向跳表中插入数据的的时候,我们可以选择同时把这个数据插入到索引里,那我们插入到哪一级的索引呢,这就需要随机函数,来决定我们插入到哪一级的索引中。
这样可以很有效的防止跳表退化,而造成效率变低。
AVL、红黑树、SkipList的区别
AVL树、红黑树和跳跃表(Skiplist)都是用于实现有序集合的数据结构,它们在不同的应用场景下具有各自的优点和缺点。
AVL树:
优点:
- 严格的平衡性:AVL树在每次插入或删除操作后都会尽量保持平衡,确保树的高度始终保持在较小的范围内,因此查询操作的时间复杂度比较稳定,为 O(log n)。
- 简单的实现:AVL树相对于红黑树来说,平衡调整的规则更为简单,实现起来相对容易。
缺点:
- 插入和删除操作可能需要进行多次旋转:由于AVL树要求严格的平衡,插入和删除操作可能需要进行多次旋转操作,导致性能开销较大。
- 频繁的平衡调整:频繁的插入和删除操作会导致频繁的平衡调整,降低了操作的效率。
AVL是一种高度平衡的二叉树,所以通常的结果是,维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而实际的应用不多, 更多的地方是用追求局部而不是非常严格整体平衡的红黑树。当然,如果场景中对插入删除不频繁,只是对查找特别有要求,AVL还是优于红黑的。
AVL树:平衡二叉树,一般是用平衡因子差值决定并通过旋转来实现,左右子树树高差不超过1,那么和红黑树比较它是严格的平衡二叉树,平衡条件非常严格(树高差只有1), 只要插入或删除不满足上面的条件就要通过旋转来保持平衡。由于旋转是非常耗费时间的。我们可以推出AVL树适合用于插入删除次数比较少,但查找多的情况。
红黑树:
优点:
- 平衡性较好:虽然不像AVL树那样严格保持平衡,但红黑树通过一系列的规则保证了树的大致平衡,使得查询操作的时间复杂度也是 O(log n)。
- 插入和删除操作相对较快:相比于AVL树,红黑树的插入和删除操作通常需要更少的平衡调整操作,因此性能上可能更好一些。
缺点:
- 实现复杂:相比于AVL树,红黑树的实现更为复杂,需要处理不同的情况,并且调整规则相对更加难以理解。
- 不严格的平衡性:虽然红黑树保证了树的大致平衡,但相比AVL树来说,树的高度可能更高一些,因此查询操作的性能略低于AVL树。
- 红黑树:平衡二叉树,通过对任何一条从根到叶子的简单路径上各个节点的颜色进行约束,确保没有一条路径会比其他路径长2倍,因而是近似平衡的。 所以相对于严格要求平衡的AVL树来说,它的旋转保持平衡次数较少。用于搜索时,插入删除次数多的情况下我们就用红黑树来取代AVL。
跳跃表(Skiplist):
优点:
- 简单的实现:跳跃表的实现相对于AVL树和红黑树来说更为简单,不需要复杂的平衡调整操作。
- 平均时间复杂度较低:跳跃表在插入、删除和查找操作的平均时间复杂度都是 O(log n),虽然不如AVL树和红黑树那样严格保持平衡,但在实际应用中性能仍然较好。
缺点:
- 需要额外的空间:跳跃表需要额外的空间来维护索引,相比于AVL树和红黑树可能会占用更多的内存空间。
在server端,对并发和性能有要求的情况下,如何选择合适的数据结构(这里是跳跃表和红黑树)。 如果单纯比较性能,跳跃表和红黑树可以说相差不大,但是加上并发的环境就不一样了, 如果要更新数据,跳跃表需要更新的部分就比较少,锁的东西也就比较少,所以不同线程争锁的代价就相对少了, 而红黑树有个平衡的过程,牵涉到大量的节点,争锁的代价也就相对较高了。性能也就不如前者了。 在并发环境下skiplist有另外一个优势,红黑树在插入和删除的时候可能需要做一些rebalance的操作,这样的操作可能会涉及到整个树的其他部分, 而skiplist的操作显然更加局部性一些,锁需要盯住的节点更少,因此在这样的情况下性能好一些。
跳表的一个缺点是耗内存(因为要重复分层存节点),可以调参数来降低内存消耗,和那些平衡树结构达到差不多。
-
简单的实现: 跳跃表的实现相对于红黑树来说更为简单。它不需要像红黑树那样复杂的平衡调整操作,而是通过添加多层索引来实现快速的查找,因此实现起来更加容易。
-
插入和删除操作更简单: 跳跃表的插入和删除操作相对于红黑树来说更简单直观。插入一个节点只需要在底层链表中插入即可,并且可以根据一定的策略决定是否在更高层插入索引节点,而不需要进行复杂的平衡调整。
-
平均时间复杂度相近: 跳跃表在插入、删除和查找操作的平均时间复杂度都是 O(log n),而红黑树的平均时间复杂度也是 O(log n),因此在实际应用中性能相近。但是在某些特定情况下,跳跃表可能会比红黑树稍微快一些。
-
更适合高并发环境: 跳跃表的简单结构使得它更适合在高并发环境下使用。由于不需要进行复杂的平衡调整操作,跳跃表的并发插入和删除操作可能更容易实现,并且不容易出现竞争条件。