
- 1如何在 Ubuntu 12.04 VPS 上使用 MongoDB 创建分片集群
- 2年入100万的程序员说,看完这些书至少涨薪10万_java程序猿如何年入百万
- 3查看linux jvm使用情况,查看jvm内存使用命令
- 4基于Python+Django的图书馆管理系统(内附源代码+部署教程)_python基于django图书管理系统
- 5Jenkins+Docker 一键自动化部署 SpringBoot 项目_jenkis + docker + springboot
- 6深度学习之基于Vgg16卷积神经网络书法字体风格识别
- 7jsp连接Access接数据库并实现学生信息查询、修改、删除_编写一个查询access数据库的jsp页面。
- 8Python每日笔记07(lambda表达式详解+变量作用域+高阶函数)_lambda函数python使用的参数变量作用域确定
- 9初始化创建一个webpack项目
- 10java计算两个时间差的方法_java计算两个时间相差天数的方法汇总
[学习opencv3] 阅读第十一章_cv::transform
赞
踩
常见的图像变换
仿射变换
仿射变换有两种情况。
第一种,有一个想转化的图像(或感兴趣的区域),例如,平移、缩放、旋转、翻转和错切这五种变换的组合;
第二种,有一系列点,想过要计算转换的结果。
这些情况在概念上相似,但在实际执行方面却有很大差异。对于这些情况,opencv有两个不同的函数。
密集仿射变换函数cv::warpAffine
void cv::warpAffine(
cv::InputArray src, // Input image
cv::OutputArray dst, // Result image
cv::InputArray M, // 2-by-3 transform mtx 2*3转换矩阵
cv::Size dsize, // Destination image size 目标图像大小
int flags = cv::INTER_LINEAR, // Interpolation, inverse 设置插值方法 ,附加选项cv::WARP_INVERSE_MAP允许从dst到src而不是从src到dst的反向转换
int borderMode = cv::BORDER_CONSTANT, // Pixel extrapolation 像素外推的方法
const cv::Scalar& borderValue = cv::Scalar() // For constant borders 边界的值
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
计算仿射映射矩阵的cv::getAffineTransform
cv::Mat cv::getAffineTransform( // Return 2-by-3 matrix 返回2*3矩阵
const cv::Point2f* src, // Coordinates *three* of vertices 3个顶点坐标
const cv::Point2f* dst // Target coords, three vertices 目标坐标,3个顶点
);
- 1
- 2
- 3
- 4
另一种计算映射矩阵的方法cv::getRotationMatrix2D()
cv::Mat cv::getRotationMatrix2D( // Return 2-by-3 matrix
cv::Point2f center // Center of rotation 旋转中心
double angle, // Angle of rotation 旋转角
double scale // Rescale after rotation 在旋转之后重新调节
);
- 1
- 2
- 3
- 4
- 5
cv::transform()用于稀疏仿射变换
cv::warpAffine()是处理密集映射的正确方法。对于稀疏映射(即单个点的列表的映射),最好使用cv::transform()
void cv::transform(
cv::InputArray src, // Input N-by-1 array (Ds channels) Ds 通道的N*1矩阵
cv::OutputArray dst, // Output N-by-1 array (Dd channels) Dd通道的N*1矩阵
cv::InputArray mtx // Transform matrix (Ds-by-Dd) 变换矩阵是Ds * Dd矩阵
);
- 1
- 2
- 3
- 4
- 5
cv::transform()作用于数组中每个点的通道索引。对于当前的问题,我们假设数组本质上是这些多通道对象的大向量(N1或1N)。要记住一个重要事情,变换矩阵相对的是通道索引的索引,而不是大数组的“向量”索引。
cv::invertAffineTransform()用于逆仿射变换
给定2*3矩阵的仿射变换,通常希望能够计算逆变换,它可以用于将所有转换点“放回”它们原来的地方。
void cv::invertAffineTransform(
cv::InputArray M, // Input 2-by-3 matrix
cv::OutputArray iM // Output also a 2-by-3 matrix
);
- 1
- 2
- 3
- 4
透视变换
透视变换包含所有仿射变换
首先指出,即使透视投影完全由单个矩阵指定,投影实际上也不是线性变换,这是因为变换需要通过最终维度(通常为Z)进行划分,从而在过程中失去一个维度。
cv::warpPerspective()用于密集透视变换
密集透视变换使用类似于为密集仿射变换提供的OpenCV函数。区别在于,小但至关重要的映射矩阵现在必须为3*3。

void cv::warpPerspective(
cv::InputArray src, // Input image
cv::OutputArray dst, // Result image
cv::InputArray M, // 3-by-3 transform mtx 3*3的转换矩阵,映射矩阵
cv::Size dsize, // Destination image size 目标图片大小
int flags = cv::INTER_LINEAR, // Interpolation, inverse 选择插值方式
int borderMode = cv::BORDER_CONSTANT, // Extrapolation method 边界外推的方法
const cv::Scalar& borderValue = cv::Scalar() // For constant borders 边界值,常量
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
cv::getPerspectiveTransform()用于计算透视映射矩阵
cv::Mat cv::getPerspectiveTransform( // Return 3-by-3 matrix 返回一个3*3矩阵
const cv::Point2f* src, // Coordinates of *four* vertices 源图像四个顶点的坐标,四个顶点在数组中
const cv::Point2f* dst // Target coords, four vertices 目标图像,四个顶点的坐标,四个顶点在数组中
);
- 1
- 2
- 3
- 4
参数src和参数dst现在是四个点的数组,所以可以独立控制src中的(典型)矩形的一个角如何映射到(通常)dst中的一些菱形。变换完全由四个源点的指定目的地定义。
实现透视变换的例子
#include <opencv2/opencv.hpp> #include <iostream> using namespace std; int main(int argc, char** argv) { if (argc != 2) { cout << "Perspective Warp\nUsage: " << argv[0] << " <imagename>\n" << endl; return -1; } cv::Mat src = cv::imread(argv[1], 1); if (src.empty()) { cout << "Can not load " << argv[1] << endl; return -1; } cv::Point2f srcQuad[] = { cv::Point2f(0,0), cv::Point2f(src.cols - 1,0), cv::Point2f(src.cols - 1,src.rows - 1), cv::Point2f(0,src.rows - 1) }; cv::Point2f dstQuad[] = { cv::Point2f(src.cols*0.05f,src.rows*0.33f), cv::Point2f(src.cols*0.9f,src.rows*0.25f), cv::Point2f(src.cols*0.8f,src.rows*0.9f), cv::Point2f(src.cols*0.2f,src.rows*0.7f) }; cv::Mat warp_mat = cv::getPerspectiveTransform(srcQuad, dstQuad); cv::Mat dst; cv::warpPerspective(src, dst, warp_mat, src.size(), cv::INTER_LINEAR, cv::BORDER_CONSTANT, cv::Scalar()); for (int i = 0; i < 4; i++) { cv::circle(dst, dstQuad[i], 5, cv::Scalar(255, 0, 255), -1, cv::LINE_AA); } double scale = 0.5; cv::Size resize = cv::Size(dst.rows*scale, dst.cols*scale); cv::Mat input_img = cv::Mat(resize,dst.type()); cv::resize(dst, input_img,resize); cv::imshow("Perspective Transform Test", input_img); cv::waitKey(); return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45

cv::perspectiveTransform()用于稀疏透视变换
cv::perspectiveTransform()是一个特殊的函数,可以对点列表执行透视变换。因为cv::transform()被限定于线性运算,所以不能正确的处理透视变换。这是因为这种变换需要由同质表示的第三个坐标( x = f * x / Z , y = f * y / Z )来划分。特殊函数cv::perspectiveTransform()为我们考虑了这个:
void cv::perspectiveTransform(
cv::InputArray src, // Input N-by-1 array (2 or 3 channels) N*1 数组(2或3通道)
cv::OutputArray dst, // Output N-by-1 array (2 or 3 channels) N*1 数组(2或3通道)
cv::InputArray mtx // Transform matrix (3-by-3 or 4-by-4) 转换(映射)矩阵,3*3或4*4。如果矩阵为3*3则投影从二维到二维;如果矩阵是4*4,则投影从三维到三维。
);
- 1
- 2
- 3
- 4
- 5
src和dst参数分别是要变换的源点数组和由变换产生的目标点数组。这些数组应该是两通道或是三通道数组。矩阵mat可以是33或44矩阵。如果矩阵为33则投影从二维到二维;如果矩阵是44,则投影从三维到三维。
透视变换本质上是将嵌入在三维空间中的二维平面上的点映射回到(不同的)二维子空间。可以认为这类似于相机成像的原理。相机采取三维点并将其映射到相机成像器的两个维度。这本质上意味着当源点被认为是“齐次坐标”时的意思。我们通过引入Z维并将所有Z值设置为1,向这些点添加一个维度。然后投影变换从这个空间回到我们输出的二维空间。这是相当繁琐的,你需要一个3*3矩阵来解释如何将一个图像中的点映射到另一个图像中的点。
通用变换
仿射变换和透射变换是一些更为一般的处理过程中特殊的例子。本质上,这两种变换有着相似的特性:它们把源图像的像素从一个地方映射到目标图像的另一个地方。
让opencv实现自己的映射变换。
极坐标映射
cart直角坐标;polar极坐标。
函数cv::cartToPolar()和cv::polarToCart()实现了点阵的直角坐标和极坐标之间的相互转换。
极坐标映射函数、透视变换函数以及仿射变换函数之间,细微的差别:
极坐标映射函数在表示二维向量的时候,只能用一系列一维矩阵,不能用多维矩阵。这个不同源于两个函数的传统用法,而非两者功能上的本质区别。
cv::cartToPolar()用于将直角坐标转换为极坐标
使用函数cv::cartToPolar()将直角坐标转换为极坐标:
void cv::cartToPolar(
cv::InputArray x, // Input single channel x-array 输入单通道X数组
cv::InputArray y, // Input single channel y-array
cv::OutputArray magnitude, // Output single channel mag-array
cv::OutputArray angle, // Output single channel angle-array
bool angleInDegrees = false // Set true for degrees, else radians
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
cv::logPolar()函数
void cv::logPolar(
cv::InputArray src, // Input image
cv::OutputArray dst, // Output image
cv::Point2f center, // Center of transform 对数——极坐标 转换/变换 的中心点(x,y)
double m, // Scale factor 比例因子
int flags = cv::INTER_LINEAR // interpolation and fill modes 标志位,设置插值和填充的方式
| cv::WARP_FILL_OUTLIERS
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
cv::INTER_LINEAR(计算从对数-极坐标系转换为直角坐标系的反向映射)
cv::WARP_FILL_OUTLIERS(填充未定的点)
实现对数极坐标转换的例子:
#include<opencv2/opencv.hpp> #include<iostream> using namespace std; int main(int argc, char** argv) { if (argc != 3) { cout << "LogPolar\nUsage: " << argv[0] << "<inagename> <M value>\n" << "<M value>~30 is usually good enough\n"; return -1; } cv::Mat src = cv::imread(argv[1], 1); if (src.empty()) { cout << "Can not load " << argv[1] << endl; return -1; } double M = atof(argv[2]); cv::Mat dst(src.size(), src.type()), src2(src.size(), src.type()); cv::logPolar( src, dst, cv::Point2f(src.cols*0.5f, src.rows*0.5f), M, cv::INTER_LINEAR | cv::WARP_FILL_OUTLIERS ); cv::logPolar( dst, src2, cv::Point2f(src.cols*0.5f, src.rows*0.5f), M, cv::INTER_LINEAR | cv::WARP_INVERSE_MAP ); double scale = 0.5; cv::Size resize = cv::Size(dst.rows*scale, dst.cols*scale); cv::Mat input_img = cv::Mat(resize, dst.type()); cv::resize(src, input_img, resize); cv::imshow("src img", input_img); cv::resize(dst, input_img, resize); cv::imshow("log-polar", input_img); cv::resize(src2, input_img, resize); cv::imshow("imshow log-polar", input_img); cv::waitKey(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54


任意映射
我们有时想要实现以编程方式插值。这意味着我们要使用一些已知的能够实现映射的算法。另一方面,我们有想要自己实现这种映射。在研究这些能为我们计算(并应用)这些映射方法前,我们先看看其它方法依赖的能够实现这种映射的函数。
函数cv::remap()通常用来纠正校准的立体图像。
cv::remap()用于常规图像重绘
void cv::remap(
cv::InputArray src, // Input image
cv::OutputArray dst, // Output image
cv::InputArray map1, // target x for src pix 源图像上需要重新定位的任意一点的x和y的位置。这样就可以自己制定一般映射。
cv::InputArray map2, // target y for src pix
int interpolation = cv::INTER_LINEAR, // Interpolation, inverse 插值方式
int borderMode = cv::BORDER_CONSTANT, // Extrapolation method 边界外推方式
const cv::Scalar& borderValue = cv::Scalar() // For constant borders 边界常量
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
这些图应与源图像和目标图像保持相同尺寸,并且必须使用一下数据类型之一:CV::S16C2, CV::F32C1, 或 CV::F32C2 (允许使用非整数型数据映射),函数cv::remap()将自动进行插值计算
图像修复
图像经常因噪声造成破损。镜头上可能有灰尘或水渍,旧图象可能有划痕,或者图像的一部分损坏。图像修复是消除这种损坏的一种方式,通过摄取被损坏区域边缘的色彩和纹理,然后传播混合至损坏区域的内部。
图像修复
函数cv::inpaint()源码
void cv::inpaint(
cv::InputArray src, // Input image: 8-bit, 1 or 3 channels 8位,1或3通道图像
cv::InputArray inpaintMask, // 8-bit, 1 channel. Inpaint nonzeros
cv::OutputArray dst, // Result image
double inpaintRadius, // Range to consider around pixel
int flags // Select NS or TELEA 选择修复方式
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
inpaintMask是一个8位,与src大小相同的一维图像,且损坏区域被非零元素标记,inpaintMask的其他像素均被设置为0。
inpaintRadius是每个已渲染像素周围的区域,这一区域将被分解成该像素的结果输出颜色。
去噪
在许多应用中,噪声的主要来源于低光条件的影响。在低光下,数字成像器的增益必须增加,结果,噪声也被放大。这种噪声的特征是随机孤立的像素,看起来太亮或太暗,但在彩色图像中也可能发生变色。
opencv中实现的去噪算法称为“快速非局部均值去噪”(FNLMD)。虽然简单的去噪算法基本上依赖于对其周边的各个像素及逆行平均,但是FNLMD的中心概念是在图像中的其它地方寻找类似的像素,再对其取平均值。在这种情况下,像素被认为是相似的像素,不是因为它的像素或强度相似,而是因为它在环境中是相似的。这里的关键是,许多图像包含重复的结构,因此即使像素被噪声破坏,也会有许多其他类似的像素。
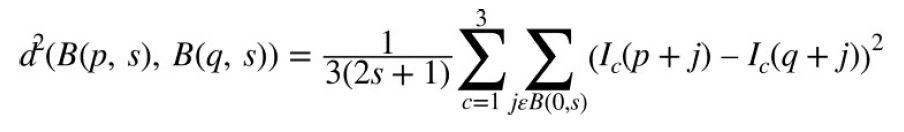
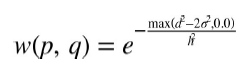
FNLMD基础算法cv::fastNlMeansDenoising()
void cv::fastNlMeansDenoising(
cv::InputArray src, // Input image
cv::OutputArray dst, // Output image
float h = 3, // Weight decay parameter 权重衰减参数
int templateWindowSize = 7, // Size of patches used for comparison 用于比较的补丁大小
int searchWindowSize = 21 // Maximum patch distance to consider 允许范围内补丁的最大值
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
使用templateWindowSize的补丁区域和衰减参数h从输入数组src计算出结果数组dst,并考虑searchWindowSize的距离内的补丁。图像可以是一维、二维或三维,但必须是cv::U8类型。
FNLMD彩色图像算法cv::fastNIMeansDenoisingColor()
void cv::fastNlMeansDenoisingColored(
cv::InputArray src, // Input image
cv::OutputArray dst, // Output image
float h = 3, // Luminosity weight decay parameter 亮度权重衰减参数
float hColor = 3, // Color weight decay parameter 颜色权重衰减参数
int templateWindowSize = 7, // Size of patches used for comparison
int searchWindowSize = 21 // Maximum patch distance to consider
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
FNIMD算法的第二个变体用于彩色图像。它只接受cv::U8C3类型的图像。虽然原则上可能直接将算法或多或少地应用于RGB图像,但实际上,最好将图像转换为不同地颜色空间进行计算。函数cv::fastNIMeansDenoisingColorred()首先将图像转换为LAB颜色空间,然后应用FNLMD算法,然后将结果转换为RGB。其主要优点是在颜色方面实际上有三个衰减参数。然而,在RGB表示中,不太可能将其中任何一个设置为不同地值。但是在LAB空间中,为颜色分量指定不同的衰减参数对于亮度分量是很自然的。函数cv::fastNIMeansDenoisingColorred()可以让你做到这一点。参数h用于亮度衰减参数,而新参数hColor用于颜色通道。一般来说,hColor的值会比h小很多。在大多数情况下,10是一个合适的值。
FNLMD视频图像算法cv::fastNlMeansDenoisingMulti() 和cv::fastNlMeansDenoisingColorMulti()
void cv::fastNlMeansDenoisingMulti( cv::InputArrayOfArrays srcImgs, // Sequence of several images 多副图像的图像数组 cv::OutputArray dst, // Output image int imgToDenoiseIndex, // Index of image to denoise 索引指定要被去噪的图像 int temporalWindowSize, // Num images to use (odd) 去噪中使用的序列中的图像数量(奇数) float h = 3, // Weight decay parameter int templateWindowSize = 7, // Size of comparison patches int searchWindowSize = 21 // Maximum patch distance 最大补丁距离 ); void cv::fastNlMeansDenoisingColoredMulti( cv::InputArrayOfArrays srcImgs, // Sequence of several images cv::OutputArray dst, // Output image int imgToDenoiseIndex, // Index of image to denoise int temporalWindowSize, // Num images to use (odd) float h = 3, // Weight decay param float hColor = 3, // Weight decay param for color int templateWindowSize = 7, // Size of comparison patches int searchWindowSize = 21 // Maximum patch distance );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
第三、第四变体用于顺序图像,例如可能从视频捕获的图像。在顺序图像的情况下,很自然的想象除了当前帧以外的帧可能包含去噪像素的有用信息。在大多数应用中,图像之间的噪声是不会恒定的,而信号可能会相似甚至相同。函数cv::fastNlMeansDenoisingMulti() 和cv::fastNlMeansDenoisingColorMulti()期望一个图像数组srcImage,而不是单个图像。另外,通过参数imgToDenoiseIndex告知函数序列中哪个图像是要被去噪的。最后,必须提供一个时间窗口,指示在去噪中使用的序列中的图像数量。该参数必须为奇数,隐含窗口始终以imgToDenoiseIndex为中心(因此,如果要将imgToDenoiseIndex设置为4并将temporalWindowSize设置为5,那么在去噪中使用的图像将为2,3,4,5和6)
直方图均衡化
采取一些措施尝试扩大图像的动态范围以增加对比度。最常用的技术是直方图均衡。
直方图均衡数学背景是将一个分布(强度值的给定直方图)映射到另一个分布(强度值的更宽和理想的均匀分布)。也就是说,我们希望在新分配中尽可能均匀分布原始分布的y值。事实证明,解决扩展分布值的问题的一个好方法是:重映射函数应该是累积分布函数。
可以使用累积分布函数将原始分布重新映射到均匀分布,只需查看原始分布中的每个y值,并查看在均匀分布中应该进行的位置。对于连续分布 结果将是一个精确的均衡,但是对于数字/离散分布,结果可能很不一致。
cv::equalizeHist()用于对比均衡
opencv将整个过程整合在一个函数中。
void cv::equalizeHist(
const cv::InputArray src, // Input image
cv::OutputArray dst // Result image
);
- 1
- 2
- 3
- 4
源图像必须是8位一维图像。目标图像也是8位一维图像。对于彩色图像,必须分通道逐一处理。

