
- 1pytorch中Sequential( )的使用_pytorch sequential
- 2小程序中遇到的各种重难点(md5加密解密)_微信小程序md5
- 3Spring boot 导出/导入 Excel 步骤
- 4任务5:ChatGPT实体抽取_chat gpt抽取实体
- 5雷达回波模拟仿真(二):相参积累(以LFM为例)matlab_matlab雷达载频f0=10e9; 是十的十次方吗
- 6pycharm控制STM32F103ZET6拍照并上位机接收显示(OV7670、照相机、STM32、TFTLCD)_stm32f103zet6能进行图片传输吗
- 7Qt6.5 LTS发布_qt lts
- 8爱心代码,烟花代码,附带教程,手残党也能学会!!_php爱心的模板代码
- 9Windows下运行sh文件_windows sh start_ranklist_labler.sh
- 10程序员必读:初入职场避坑指南_程序员刚开始找工作避坑
共识算法 --- PBFT、Raft和Paxos_pbft raft
赞
踩
一、Raft共识算法
1、什么是Raft
Raft基于领导者驱动的共识模型,其中将选举一位杰出的领导者(Leader),而该Leader将完全负责管理集群,Leader负责管理Raft集群的所有节点之间的复制日志。
2、Raft的工作流程
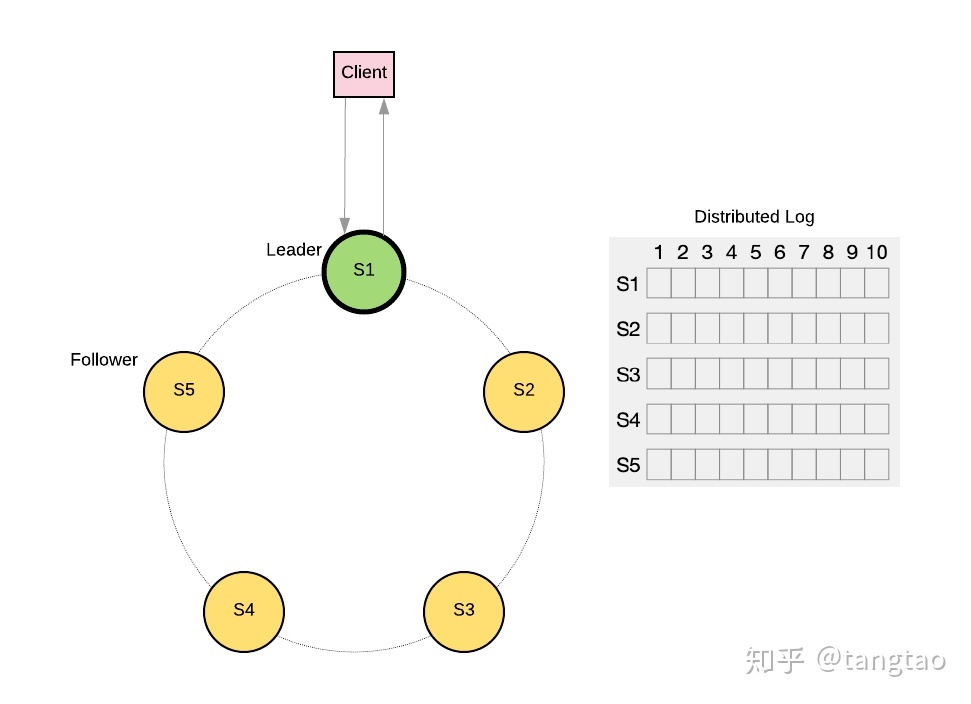
下图中,将在启动过程中选择集群的Leader(S1),并为来自客户端的所有命令/请求提供服务。 Raft集群中的所有节点都维护一个分布式日志(复制日志)以存储和提交由客户端发出的命令(日志条目)。 Leader接受来自客户端的日志条目,并在Raft集群中的所有关注者(S2,S3,S4,S5)之间复制它们。
在Raft集群中,需要满足最少数量的节点才能提供预期的级别共识保证, 这也称为法定人数。 在Raft集群中执行操作所需的最少投票数为 (N / 2 +1),其中N是组中成员总数,即投票至少超过一半,这也就是为什么集群节点通常为奇数的原因。 因此,在上面的示例中,我们至少需要3个节点才能具有共识保证。
如果法定仲裁节点由于任何原因不可用,也就是投票没有超过半数,则此次协商没有达成一致,并且无法提交新日志。
3、Raft的相关应用
数据存储:Tidb/TiKV
日志:阿里巴巴的 DLedger
服务发现:Consul& etcd
集群调度:HashiCorp Nomad
4、Raft的缺陷
只能容纳故障节点(CFT),不容纳作恶节点
顺序投票,只能串行apply,因此高并发场景下性能差
5、Raft中三个子问题
Raft通过解决围绕Leader选举的三个主要子问题,管理分布式日志和算法的安全性功能来解决分布式共识问题。
5.1 Leader选举 (Election)
当我们启动一个新的Raft集群或某个领导者不可用时,将通过集群中所有成员节点之间协商来选举一个新的领导者。 因此,在给定的实例中,Raft集群的节点可以处于以下任何状态: 追随者(Follower),候选人(Candidate)或领导者(Leader)。
5.1.1 节点的三种角色
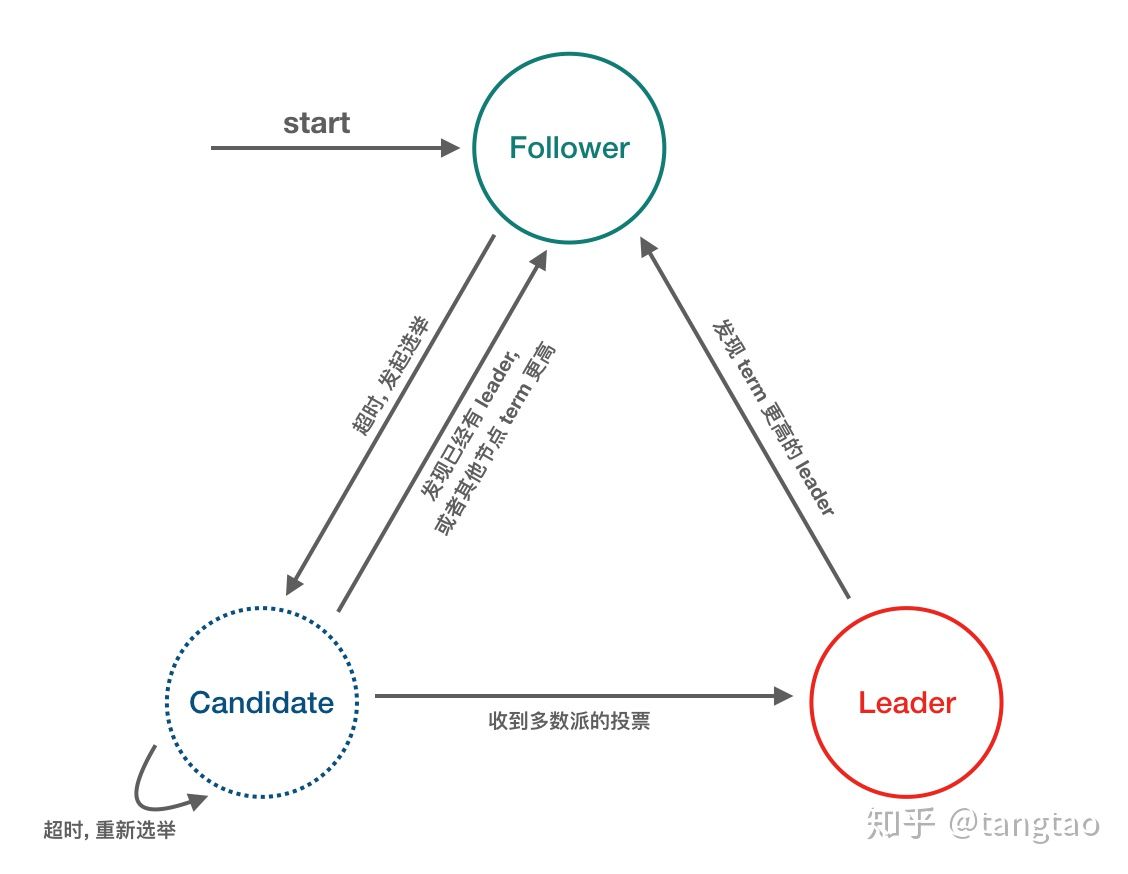
- Follower(跟随者):完全被动,不能发送任何请求,只接受并响应来自 leader 和 candidate 的 message,每个节点启动后的初始状态一定是 follower
- Leader(领导者):处理所有来自客户端的请求,以及复制 log 到所有 followers
- Candidate(候选者):用来竞选一个新 leader (candidate 由 follower 触发超时而来)
系统刚开始启动的时候,所有节点都是follower,在一段时间内如果它们没有收到Leader的心跳信号,follower就会转化为Candidate;
如果某个Candidate节点收到大多数节点的票,则这个Candidate就可以转化为Leader,其余的Candidate节点都会回到Follower状态;
一旦一个Leader发现系统中存在一个Leader节点比自己拥有更高的任期(Term),它就会转换为Follower。
5.1.2 选举过程
Raft使用基于心跳的RPC机制来检测何时开始新的选举。 在正常期间,Leader会定期向所有可用的Follower发送心跳消息(实际中可能把日志和心跳一起发过去)。 因此,其他节点以Follower状态启动,只要它从当前Leader那里收到周期性的心跳,就一直保持在Follower状态。
当Follower达到其超时时间时,它将通过以下方式启动选举程序:
- 增加当前Term,
- 为自己投票,并将“ RequestVote” RPC发送给集群中的所有其他人,这时也就是从Follower转换为Candidate
根据Candidate从集群中其他节点收到的响应,可以得出选举的三个结果。
- 如果大多数节点以“是”投票支持RequestVote请求,则候选人S1赢得选举。
- 在S1等待期间,它可能会从另一个声称是领导者的节点接收AppendEntries RPC。 如果S1的候选Term低于AppendEntries RPC的接收Term,则候选S1放弃并接受另一个节点作为合法领导者。
- 拆分投票方案:当有多个Follower同时成为Candidate时,任何候选人都无法获得多数。 这被称为分裂投票情况。 在这种情况下,每个Candidate都将超时,并且将触发新的选举。
为了最大程度地减少拆分投票的情况,Raft使用了随机选举超时机制,该机制将随机超时值分配给每个节点。
5.2 日志复制 (Log Replication)
共识算法的实现一般是基于复制状态机(Replicated state machines),何为复制状态机:
简单来说:相同的初识状态 + 相同的输入 = 相同的结束状态。不同节点要以相同且确定性的函数来处理输入,而不要引入一下不确定的值,比如本地时间等。使用replicated log是一个很不错的注意,log具有持久化、保序的特点,是大多数分布式系统的基石。
有了Leader之后,客户端所有并发的请求可以在Leader这边形成一个有序的日志(状态)序列,以此来表示这些请求的先后处理顺序。Leader然后将自己的日志序列发送Follower,保持整个系统的全局一致性。注意并不是强一致性,而是最终一致性。
5.2.1 日志结构
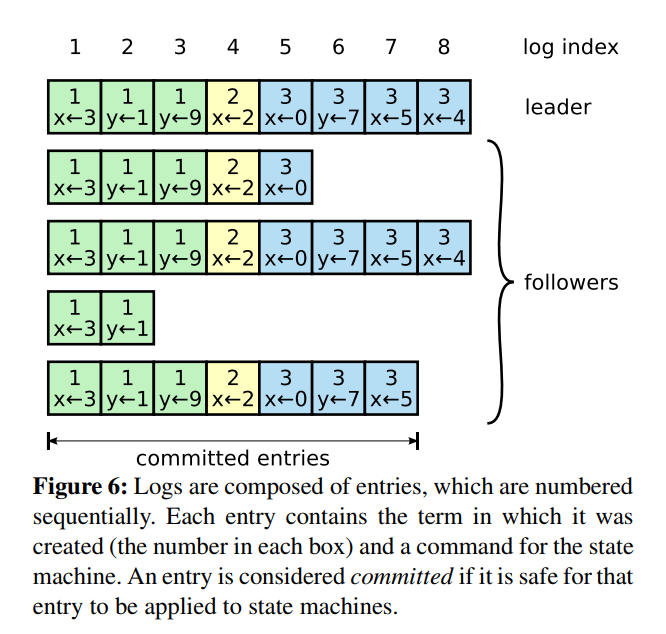
日志由有序编号(log index)的日志条目组成。每个日志条目包含它被创建时的任期号(term),和日志中包含的数据组成,日志包含的数据可以为任何类型,从简单类型到区块链的区块。每个日志条目可以用[ term, index, data]序列对表示,其中term表示任期, index表示索引号,data表示日志数据。
5.2.2 复制过程
Leader尝试在集群中的大多数节点上执行复制命令。 如果复制成功,则将命令提交给集群,并将响应发送回客户端。类似两阶段提交(2PC),不过与2PC的区别在于,leader只需要超过一半节点同意(处于工作状态)即可。
leader、follower都可能crash,那么follower维护的日志与leader相比可能出现以下情况
- 比leader日志少
- 比leader日志多
- 某些位置比leader多,某些日志比leader少(多少是针对某一任期而言)
当出现了leader与follower不一致的情况,leader强制follower复制自己的log,Leader会从后往前试,每次AppendEntries失败后尝试前一个日志条目(递减nextIndex值),直到成功找到每个Follower的日志一致位置点(基于上述的两条保证),然后向后逐条覆盖Followers在该位置之后的条目。所以丢失的或者多出来的条目可能会持续多个任期。
5.3 安全(Safety)
5.3.1 选举权
要求候选人的日志至少与其他节点一样最新。如果不是,则跟随者节点将不投票给候选者。
意味着每个提交的条目都必须存在于这些服务器中的至少一个中。如果候选人的日志至少与该多数日志中的其他日志一样最新,则它将保存所有已提交的条目,避免了日志回滚事件的发生。
5.3.2 选举结果
即任一任期内最多一个leader被选出。这一点非常重要,在一个复制集中任何时刻只能有一个leader。系统中同时有多余一个leader,被称之为脑裂(brain split),这是非常严重的问题,会导致数据的覆盖丢失。在raft中,两点保证了这个属性:
- 一个节点某一任期内最多只能投一票;
- 只有获得majority投票的节点才会成为leader。
因此,某一任期内一定只有一个leader。
6、联合共识
当集群中节点的状态发生变化(集群配置发生变化)时,系统容易受到系统故障。 因此,为防止这种情况,Raft使用了一种称为两阶段的方法来更改集群成员身份。 因此,在这种方法中,集群在实现新的成员身份配置之前首先更改为中间状态(称为联合共识)。 联合共识使系统即使在配置之间进行转换时也可用于响应客户端请求,它的主要目的是提升分布式系统的可用性。
二、PBFT共识算法
1、什么是BFT
bft即拜占庭容错,拜占庭容错技术是一类分布式计算领域的容错技术。拜占庭假设是对现实世界的模型化,由于硬件错误、网络拥塞或中断以及遭到恶意攻击等原因,计算机和网络可能出现不可预料的行为。拜占庭容错技术被设计用来处理这些异常行为,并满足所要解决的问题的规范要求。
拜占庭容错系统:
发生故障的节点被称为拜占庭节点,而正常的节点即为非拜占庭节点。
假设分布式系统拥有n台节点,并假设整个系统拜占庭节点不超过m台(n ≥ 3m + 1),拜占庭容错系统需要满足如下两个条件:
- 所有非拜占庭节点使用相同的输入信息,产生同样的结果。
- 如果输入的信息正确,那么所有非拜占庭节点必须接收这个消息,并计算相应的结果。
另外,拜占庭容错系统需要达成如下两个指标:
- 安全性:任何已经完成的请求都不会被更改,它可以在以后请求看到。
- 活性:可以接受并且执行非拜占庭客户端的请求,不会被任何因素影响而导致非拜占庭客户端的请求不能执行。
原始的拜占庭容错系统由于需要展示其理论上的可行性而缺乏实用性。另外,还需要额外的时钟同步机制支持,算法的复杂度也是随节点增加而指数级增加。
2、什么是PBFT
PBFT即实用拜占庭容错算法,解决了原始拜占庭容错算法效率不高的问题,算法的时间复杂度是O(n^2),使得在实际系统应用中可以解决拜占庭容错问题
3、PBFT算法流程
PBFT是一种状态机副本复制算法,所有的副本在一个视图(view)轮换的过程中操作,主节点通过视图编号以及节点数集合来确定,即:主节点 p = v mod |R|。v:视图编号,|R|节点个数,p:主节点编号。
- REQUEST
客户端c向主节点p发送<REQUEST, o, t, c>请求。o: 请求的具体操作,t: 请求时客户端追加的时间戳,c:客户端标识。REQUEST: 包含消息内容m,以及消息摘要d(m)。客户端对请求进行签名。
- PRE-PREPARE
主节点收到客户端的请求,需要进行以下交验:
a. 客户端请求消息签名是否正确。
非法请求丢弃。正确请求,分配一个编号n,编号n主要用于对客户端的请求进行排序。然后广播一条<<PRE-PREPARE, v, n, d>, m>消息给其他副本节点。v:视图编号,d客户端消息摘要,m消息内容。<PRE-PREPARE, v, n, d>进行主节点签名。n是要在某一个范围区间内的[h, H],具体原因参见垃圾回收章节。
- PREPARE
副本节点i收到主节点的PRE-PREPARE消息,需要进行以下交验:
a. 主节点PRE-PREPARE消息签名是否正确。
b. 当前副本节点是否已经收到了一条在同一v下并且编号也是n,但是签名不同的PRE-PREPARE信息。
c. d与m的摘要是否一致。
d. n是否在区间[h, H]内。
非法请求丢弃。正确请求,副本节点i向其他节点包括主节点发送一条<PREPARE, v, n, d, i>消息, v, n, d, m与上述PRE-PREPARE消息内容相同,i是当前副本节点编号。<PREPARE, v, n, d, i>进行副本节点i的签名。记录PRE-PREPARE和PREPARE消息到log中,用于View Change过程中恢复未完成的请求操作。
- COMMIT
主节点和副本节点收到PREPARE消息,需要进行以下交验:
a. 副本节点PREPARE消息签名是否正确。
b. 当前副本节点是否已经收到了同一视图v下的n。
c. n是否在区间[h, H]内。
d. d是否和当前已收到PRE-PPREPARE中的d相同
非法请求丢弃。如果副本节点i收到了2f+1个验证通过的PREPARE消息,则向其他节点包括主节点发送一条<COMMIT, v, n, d, i>消息,v, n, d, i与上述PREPARE消息内容相同。<COMMIT, v, n, d, i>进行副本节点i的签名。记录COMMIT消息到日志中,用于View Change过程中恢复未完成的请求操作。记录其他副本节点发送的PREPARE消息到log中。
- REPLY
主节点和副本节点收到COMMIT消息,需要进行以下交验:
a. 副本节点COMMIT消息签名是否正确。
b. 当前副本节点是否已经收到了同一视图v下的n。
c. d与m的摘要是否一致。
d. n是否在区间[h, H]内。
非法请求丢弃。如果副本节点i收到了2f+1个验证通过的COMMIT消息,说明当前网络中的大部分节点已经达成共识,运行客户端的请求操作o,并返回<REPLY, v, t, c, i, r>给客户端,r:是请求操作结果,客户端如果收到f+1个相同的REPLY消息,说明客户端发起的请求已经达成全网共识,否则客户端需要判断是否重新发送请求给主节点。记录其他副本节点发送的COMMIT消息到log中。
4、View Change协议
如果主节点作恶,它可能会给不同的请求编上相同的序号,或者不去分配序号,或者让相邻的序号不连续。备份节点应当有职责来主动检查这些序号的合法性。
如果主节点掉线或者作恶不广播客户端的请求,客户端设置超时机制,超时的话,向所有副本节点广播请求消息。副本节点检测出主节点作恶或者下线,发起View Change协议。
View Change协议:
副本节点向其他节点广播<VIEW-CHANGE, v+1, n, C, P, i>消息。n是最新的stable checkpoint的编号,C是2f+1验证过的CheckPoint消息集合,P是当前副本节点未完成的请求的PRE-PREPARE和PREPARE消息集合。
当主节点p = v + 1 mod |R|收到 2f 个有效的VIEW-CHANGE消息后,向其他节点广播<NEW-VIEW, v+1, V, O>消息。V是有效的VIEW-CHANGE消息集合。O是主节点重新发起的未经完成的PRE-PREPARE消息集合。PRE-PREPARE消息集合的选取规则:
-
选取V中最小的stable checkpoint编号min-s,选取V中prepare消息的最大编号max-s。
-
在min-s和max-s之间,如果存在P消息集合,则创建<<PRE-PREPARE, v+1, n, d>, m>消息。否则创建一个空的PRE-PREPARE消息,即:<<PRE-PREPARE, v+1, n, d(null)>, m(null)>, m(null)空消息,d(null)空消息摘要。
副本节点收到主节点的NEW-VIEW消息,验证有效性,有效的话,进入v+1状态,并且开始O中的PRE-PREPARE消息处理流程。
5、垃圾回收
在上述算法流程中,为了确保在View Change的过程中,能够恢复先前的请求,每一个副本节点都记录一些消息到本地的log中,当执行请求后副本节点需要把之前该请求的记录消息清除掉。
最简单的做法是在Reply消息后,再执行一次当前状态的共识同步,这样做的成本比较高,因此可以在执行完多条请求K(例如:100条)后执行一次状态同步。这个状态同步消息就是CheckPoint消息。
副本节点i发送<CheckPoint, n, d, i>给其他节点,n是当前节点所保留的最后一个视图请求编号,d是对当前状态的一个摘要,该CheckPoint消息记录到log中。如果副本节点i收到了2f+1个验证过的CheckPoint消息,则清除先前日志中的消息,并以n作为当前一个stable checkpoint。
这是理想情况,实际上当副本节点i向其他节点发出CheckPoint消息后,其他节点还没有完成K条请求,所以不会立即对i的请求作出响应,它还会按照自己的节奏,向前行进,但此时发出的CheckPoint并未形成stable。
为了防止i的处理请求过快,设置一个上文提到的**高低水位区间[h, H]**来解决这个问题。低水位h等于上一个stable checkpoint的编号,高水位H = h + L,其中L是我们指定的数值,等于checkpoint周期处理请求数K的整数倍,可以设置为L = 2K。当副本节点i处理请求超过高水位H时,此时就会停止脚步,等待stable checkpoint发生变化,再继续前进。
6、pbft的优点
- 系统运转可以脱离币的存在,pbft算法共识各节点由业务的参与方或者监管方组成,安全性与稳定性由业务相关方保证。
- 共识的时延大约在2~5秒钟,基本达到商用实时处理的要求
- 共识效率高,可满足高频交易量的需求
- 适用于联盟链/许可链,应用于区块链的话,不会出现分叉情况
7、pbft的缺点
-
可扩展性差,通讯的复杂度是节点的平方,很难支持大规模网络节点,参与共识的节点数达到100个已经是极限,共识时间约6秒(采用Tendemint共识的Cosmos的数据)
-
不能直接用于公链,因为公链的节点数量很多,无法达成这种巨大的通信量,需要配合其它共识先选出共识节点
-
应用于联盟链需要知道参与共识节点的数量和他们对应的公钥
-
收集不到足够的票数,网络将停止出块
8、PBFT应用场景
在区块链场景中,一般适合于对强一致性有要求的私有链和联盟链场景。例如,在IBM主导的区块链超级账本项目中,PBFT是一个可选的共识协议。在Hyperledger的Fabric项目中,共识模块被设计成可插拔的模块,支持像PBFT、Raft等共识算法。
三、Paxos
1、什么是Paxos
Paxos算法是基于消息传递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一。。
Paxos算法运行在允许宕机故障的异步系统中,不要求可靠的消息传递,可容忍消息丢失、延迟、乱序以及重复。它利用大多数 (Majority) 机制保证了2F+1的容错能力,即2F+1个节点的系统最多允许F个节点同时出现故障。
2、Paxos的工作流程
一个或多个提议进程 (Proposer) 可以发起提案 (Proposal),Paxos算法使所有提案中的某一个提案,在所有进程中达成一致。系统中的多数派同时认可该提案,即达成了一致。最多只针对一个确定的提案达成一致。
2.1 Paxos角色
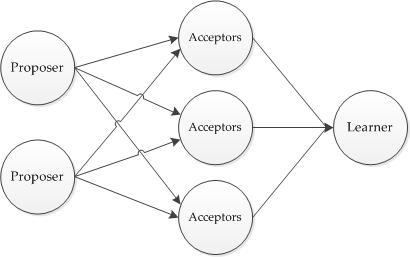
Paxos将系统中的角色分为提议者 (Proposer),决策者 (Acceptor),和最终决策学习者 (Learner):
- Proposer: 提出提案 (Proposal)。Proposal信息包括提案编号 (Proposal ID) 和提议的值 (Value)。
- Acceptor:参与决策,回应Proposers的提案。收到Proposal后可以接受提案,若Proposal获得多数Acceptors的接受,则称该Proposal被批准。
- Learner:不参与决策,从Proposers/Acceptors学习最新达成一致的提案(Value)。
在多副本状态机中,每个副本同时具有Proposer、Acceptor、Learner三种角色。
2.2 决议阶段
Paxos算法通过一个决议分为两个阶段(Learn阶段之前决议已经形成):
- 第一阶段:Prepare阶段。提议者(Proposer)向决策者(Acceptors)发出Prepare请求,决策者(Acceptors)针对收到的Prepare请求进行Promise承诺。
- 第二阶段:Accept阶段。提议者(Proposer)收到多数决策者(Acceptors)承诺的Promise后,向决策者(Acceptors)发出Propose请求,决策者(Acceptors)针对收到的Propose请求进行Accept处理。
- 第三阶段:Learn阶段。提议者(Proposer)在收到多数决策者(Acceptors)的Accept之后,标志着本次Accept成功,决议形成,将形成的决议发送给所有最终决策学习者 (Learner)。
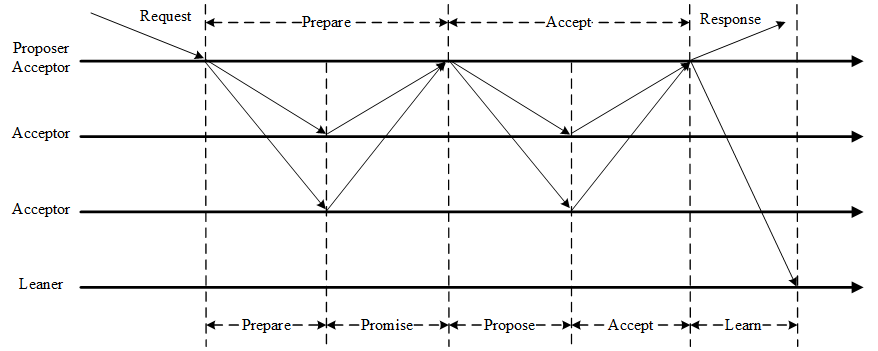
2.3 承诺及应答规则
Paxos算法流程中的每条消息描述如下:
- Prepare: Proposer生成全局唯一且递增的Proposal ID (可使用时间戳加Server ID),向所有Acceptors发送Prepare请求,这里无需携带提案内容,只携带Proposal ID即可。
- Promise: Acceptors收到Prepare请求后,做出“两个承诺,一个应答”。
两个承诺:
-
不再接受Proposal ID小于等于(注意:这里是<= )当前请求的Prepare请求。
-
不再接受Proposal ID小于(注意:这里是< )当前请求的Propose请求。
一个应答:
不违背以前作出的承诺下,回复已经Accept过的提案中Proposal ID最大的那个提案的Value和Proposal ID,没有则返回空值。
- Propose: Proposer 收到多数Acceptors的Promise应答后,从应答中选择Proposal ID最大的提案的Value,作为本次要发起的提案。如果所有应答的提案Value均为空值,则可以自己随意决定提案Value。然后携带当前Proposal ID,向所有Acceptors发送Propose请求。
- Accept: Acceptor收到Propose请求后,在不违背自己之前作出的承诺下,接受并持久化当前Proposal ID和提案Value。
- Learn: Proposer收到多数Acceptors的Accept后,决议形成,将形成的决议发送给所有Learners。
3、Multi-Paxos算法
原始的Paxos算法(Basic Paxos)只能对一个值形成决议,决议的形成至少需要两次网络来回,在高并发情况下可能需要更多的网络来回,极端情况下甚至可能形成活锁。如果想连续确定多个值,Basic Paxos搞不定了。因此Basic Paxos几乎只是用来做理论研究,并不直接应用在实际工程中。
实际应用中几乎都需要连续确定多个值,而且希望能有更高的效率。Multi-Paxos正是为解决此问题而提出。
3.1 Multi-Paxos的改进
Multi-Paxos基于Basic Paxos做了两点改进:
- 针对每一个要确定的值,运行一次Paxos算法实例(Instance),形成决议。每一个Paxos实例使用唯一的Instance ID标识。
- 在所有Proposers中选举一个Leader,由Leader唯一地提交Proposal给Acceptors进行表决。这样没有Proposer竞争,解决了活锁问题。在系统中仅有一个Leader进行Value提交的情况下,Prepare阶段就可以跳过,从而将两阶段变为一阶段,提高效率。
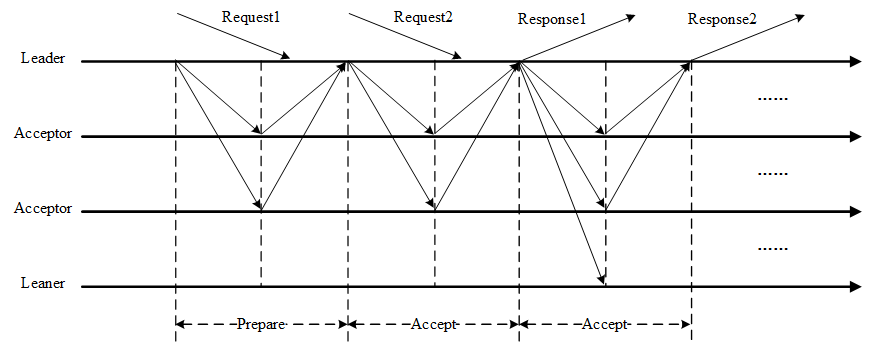
3.2 Multi-Paxos工作流程
Multi-Paxos首先需要选举Leader,Leader的确定也是一次决议的形成,所以可执行一次Basic Paxos实例来选举出一个Leader。选出Leader之后只能由Leader提交Proposal,在Leader宕机之后服务临时不可用,需要重新选举Leader继续服务。在系统中仅有一个Leader进行Proposal提交的情况下,Prepare阶段可以跳过。
Multi-Paxos通过改变Prepare阶段的作用范围至后面Leader提交的所有实例,从而使得Leader的连续提交只需要执行一次Prepare阶段,后续只需要执行Accept阶段,将两阶段变为一阶段,提高了效率。为了区分连续提交的多个实例,每个实例使用一个Instance ID标识,Instance ID由Leader本地递增生成即可。
Multi-Paxos允许有多个自认为是Leader的节点并发提交Proposal而不影响其安全性,这样的场景即退化为Basic Paxos。
3.3 Multi-Paxos的相关应用
-
Chubby和Boxwood均使用Multi-Paxos。
-
ZooKeeper使用的Zab也是Multi-Paxos的变形。
3.4 Paxos算法推导过程
Paxos算法的设计过程就是从正确性开始的,对于分布式一致性问题,很多进程提出(Propose)不同的值,共识算法保证最终只有其中一个值被选定,Safety表述如下:
- 只有被提出(Propose)的值才可能被最终选定(Chosen)。
- 只有一个值会被选定(Chosen)。
- 进程只会获知到已经确认被选定(Chosen)的值。
Paxos以这几条约束作为出发点进行设计,只要算法最终满足这几点,正确性就不需要证明了。Paxos算法中共分为三种参与者:Proposer、Acceptor以及Learner,通常实现中每个进程都同时扮演这三个角色。
Proposers向Acceptors提出Proposal,为了保证最多只有一个值被选定(Chosen),Proposal必须被超过一半的Acceptors所接受(Accept),且每个Acceptor只能接受一个值。
为了保证正常运行(必须有值被接受),所以Paxos算法中:
P1:Acceptor必须接受(Accept)它所收到的第一个Proposal。
先来先服务,合情合理。但这样产生一个问题,如果多个Proposers同时提出Proposal,很可能会导致无法达成一致,因为没有Propopal被超过一半Acceptors的接受,因此,Acceptor必须能够接受多个Proposal,不同的Proposal由不同的编号进行区分,当某个Proposal被超过一半的Acceptors接受后,这个Proposal就被选定了。
既然允许Acceptors接受多个Proposal就有可能出现多个不同值都被最终选定的情况,这违背了Safety要求,为了保证Safety要求,Paxos进一步提出:
P2:如果值为v的Proposal被选定(Chosen),则任何被选定(Chosen)的具有更高编号的Proposal值也一定为v。
只要算法同时满足P1和P2,就保证了Safety。P2是一个比较宽泛的约定,完全没有算法细节,我们对其进一步延伸:
P2a:如果值为v的Proposal被选定(Chosen),则对所有的Acceptors,它们接受(Accept)的任何具有更高编号的Proposal值也一定为v。
如果满足P2a则一定满足P2,显然,因为只有首先被接受才有可能被最终选定。但是P2a依然难以实现,因为acceptor很有可能并不知道之前被选定的Proposal(恰好不在接受它的多数派中),因此进一步延伸:
P2b:如果值为v的Proposal被选定(Chosen),则对所有的Proposer,它们提出的的任何具有更高编号的Proposal值也一定为v。
更进一步的:
P2c:为了提出值为v且编号为n的Proposal,必须存在一个包含超过一半Acceptors的集合S,满足(1) 没有任何S中的Acceptors曾经接受(Accept)过编号比n小的Proposal,或者(2) v和S中的Acceptors所接受过(Accept)的编号最大且小于n的Proposal值一致。
满足P2c即满足P2b即满足P2a即满足P2。至此Paxos提出了Proposer的执行流程,以满足P2c:
- Proposer选择一个新的编号n,向超过一半的Acceptors发送请求消息,Acceptor回复: (a)承诺不会接受编号比n小的proposal,以及(b)它所接受过的编号比n小的最大Proposal(如果有)。该请求称为Prepare请求。
- 如果Proposer收到超过一半Acceptors的回复,它就可以提出Proposal,Proposal的值为收到回复中编号最大的Proposal的值,如果没有这样的值,则可以自由提出任何值。
- 向收到回复的Acceptors发送Accept请求,请求对方接受提出的Proposal。
仔细品味Proposer的执行流程,其完全吻合P2c中的要求,但你可能也发现了,当多个Proposer同时运行时,有可能出现没有任何Proposal可以成功被接受的情况(编号递增的交替完成第一步),这就是Paxos算法的Liveness问题,或者叫“活锁”,论文中建议通过对Proposers引入选主算法选出Distinguished Proposer来全权负责提出Proposal来解决这个问题,但是即使在出现多个Proposers同时提出Proposal的情况时,Paxos算法也可以保证Safety。
接下来看看Acceptors的执行过程,和我们对P2做的事情一样,我们对P1进行延伸:
P1a:Acceptor可以接受(Accept)编号为n的Proposal当且仅当它没有回复过一个具有更大编号的Prepare消息。
易见,P1a包含了P1,对于Acceptors:
- 当收到Prepare请求时,如果其编号n大于之前所收到的Prepare消息,则回复。
- 当收到Accept请求时,仅当它没有回复过一个具有更大编号的Prepare消息,接受该Proposal并回复。
参考链接:
https://blog.miuyun.work/archives/13303764
https://web.stanford.edu/~ouster/cgi-bin/papers/raft-atc14
https://zhuanlan.zhihu.com/p/146204513
https://www.cnblogs.com/xybaby/p/10124083.html
https://www.cnblogs.com/helloworldcode/p/11094099.html
https://blog.csdn.net/jfkidear/article/details/81275974
https://zhuanlan.zhihu.com/p/31780743
https://www.cnblogs.com/linbingdong/p/6253479.html
如有不对,烦请指出,感谢~

