
- 1Unicode字符列表(超完整)_unicode字符大全
- 2主题模型LDA教程:一致性得分coherence score方法对比(umass、c_v、uci)_coherence一致性可视化图表讲解
- 3批量视频剪辑新选择:一键式按照指定秒数分割视频并轻松提取视频中的音频,让视频处理更高效!
- 4MySQL 5.6 复制介绍
- 5新知实验室__TRTC使用WebSDK和UI集成的小程序组TUICalling 实现Web和小程序端的拨打电话
- 6Vue全局指令/局部指令过滤el-input的值【特殊字符/手机号/网址等】_el-input 过滤
- 7轻松搭建llama3Web 交互界面 - Ollama + Open WebUI_ollama3
- 8Verilog-程序设计语句-三种建模方式_verilog tran
- 9Java参数传递传值还是传引用以及全局变量的使用问题_java通过形参传入的对象,赋值给一个全局的对象,当全局的对象销毁时,传入的形参会
- 10(Docker)学习 Dockerfile 一篇文章就够了_从头开始学dockerfile
LORA模型原理详解+分层控制使用
赞
踩

一、前言
LoRA模型全称是:Low-Rank Adaptation of Large Language Models,可以理解为Stable-Diffusion中的一个插件,仅需要少量的数据就可以进行训练的一种模型。在生成图片时,LoRA模型会与大模型结合使用,从而实现对输出图片结果的调整。假如一张图片是由背景,服饰,脸型,躯干,姿态等等组成,我们可以训练LORA模型对这些进行微调,在大模型的基础上微调成自己想要的图片。
简单理解就是大模型基础上额外增加一些训练层,在冻住大模型的基础上,训练lora模型。
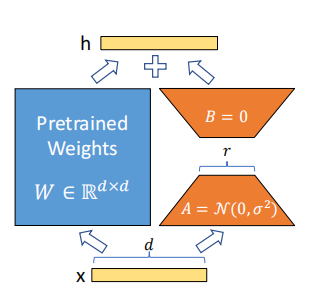
尽其实LoRA最开始是为大型语言模型提出的,但这种技术也可以应用在其他地方。在Stable Diffusion微调的情况下,LoRA可以应用于与描述它们的提示相关的图像表示之间的交叉注意力层。LoRA微调的优点包括:(论文)
- 训练速度更快
- 计算需求更低
- 训练权重更小,因为原始模型被冻结,我们注入新的可训练层,可以将新层的权重保存为一个约3MB大小的文件,比UNet模型的原始大小小了近一千倍。
现在的LORA模型根据网络层数不同一般为144M,72M,36M
二、使用(lora分层控制)
1.安装插件
https://github.com/hako-mikan/sd-webui-lora-block-weight
安装方法就不介绍了,扩展界面安装,压缩包解压放到扩展目录,git clone,都行
如果想要充分利用lora模型,分层控制是必须的
lora模型一共17层组成,第一层为开关,其他16层分别控制着lora的人物背景姿态服装,有时候lora效果很好但是有一些背景服装想要更改,加上提示词发现效果不大,降低lora权重又使图片不符合预期,分层控制就排上大用场了,把服装权重降到0,提示词就可轻松换装,对与不同lora叠加使用也有了更好的效果,相信你的小脑袋已经有了很多想法了,服饰,背景,脸分别采用不同lora模型,也不用担心模型的叠加使人物崩坏了。
2,打开webui
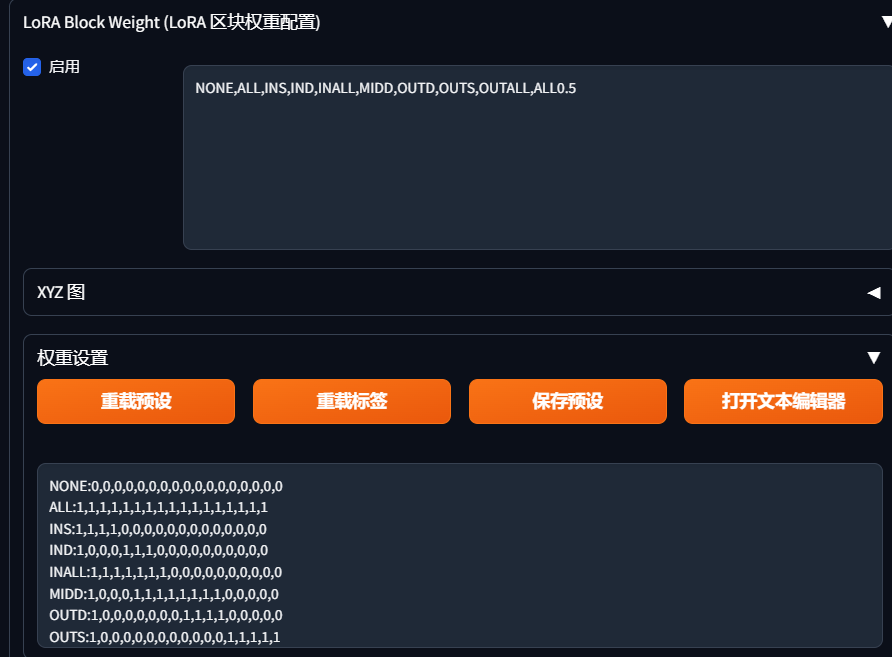

我自己使用了,效果还行,使用如下,例如去除lora服装效果
<lora:tianfeng_cutegirls5:1:1,1,1,1,1,1,0,1,1,1,0,1,1,1,1,1,1>,
:1,1,1,1,1,1,0,1,1,1,0,1,1,1,1,1,1 是自己加入的,分别是17层,第一层必须是1
- 1
- 2
再去除脸型
<lora:tianfeng_cutegirls5:1:1,1,1,1,1,1,0,1,0,0,0,1,1,1,1,1,1>
- 1
图片不放了,多少有点不雅,反正效果没问题,这里我做实验了,没问题
好了,到此结束吧!

