
热门标签
热门文章
- 1ModuleNotFoundError: No module named‘ pymysql ‘异常的正确解决方法
- 2一个Boss直聘机器人, 自动回复发简历
- 3毕业设计:基于深度学习的图像分类识别系统 人工智能_深度学习图像识别毕设总体概述
- 4数字逻辑电路复习资料_数字逻辑电路空翻和反转的区别
- 5uniapptabbar的高度是多少_Uniapp-tabbar选择及适配
- 6揭秘爬虫个股投资机会,轻松赚钱!_爬虫炒股有用吗
- 7【无人机编队】基于matlab二阶一致性多无人机协同编队控制(考虑通信半径和碰撞半径)【含Matlab源码 4215期】_多无人机协同任务规划matlab
- 8Dubbo源码(4)-Zookeeper注册中心源码解析_o.a.d.r.zookeeper.zookeeperregistry.unsubscribe -
- 9Adobe Lightroom Classic v13.1 (macOS, Windows) - 桌面照片编辑器_lightroom 13.1
- 10Seagull License Server 9.4 SR3 2781 完美激活(解决不能打印问题)
当前位置: article > 正文
基于Hadoop生态的相关框架与组件的搭建
作者:小小林熬夜学编程 | 2024-05-12 17:29:14
赞
踩
基于Hadoop生态的相关框架与组件的搭建
目录
5、设置 hadoop 的代理用户,以便 root 用户能够远程登录访问Hive
一、前言
本篇文章,着重与Hadoop生态的相关框架与组件的搭建,以及不同框架或组件之间的依赖配置,使读者能够熟悉与掌握Hadoop集群的搭建,对于Hadoop生态有一定的认识。本次搭建三台虚拟机为hadoop01.bgd01、hadoop02.bgd01、hadoop03.bgd01,hadoop01.bgd01为主节点,其中所需的素材,笔者已放入网盘中,有需要的的可自行下载。
关于虚拟机的搭建,可参考笔者之前的系列文章,这里只对虚拟机的一些配置进行描述。
安装包
http://链接: https://pan.baidu.com/s/1WBv0FRS8p8baMmEDf8e6UA?pwd=kk3a 提取码: kk3a
二、linux配置
1、配置网络参数
- 分别在三台虚拟机上修改配置
- 根据实际情况,修改文件的最后6行参数值即可。
- vi /etc/sysconfig/network-scripts/ifcfg-ens33
-
- NAME=ens33
- UUID=f8e4ef31-ed55-4b0a-af1e-90cba2287b72
- DEVICE=ens33
- ONBOOT=yes #是否开机启用
- HWADDR=00:0C:29:B4:C8:38
- BOOTPROTO=static #使用静态IP地址
- IPADDR=192.168.8.121 #IP地址
- PREFIX=24 #子网掩码:255.255.255.0
- GATEWAY=192.168.8.1 #网关
- DNS1=172.16.1.2 #域名服务器1
- DNS2=8.8.8.8 #域名服务器2
-
- 执行如下命令,重启网络服务:
- systemctl restart network

2、永久关闭防火墙
- 执行如下命令关闭防火墙:
- systemctl stop firewalld
-
- 执行如下命令关闭防火墙开机启动:
- systemctl disable firewalld
- 执行命令成功后,会出现如下2行信息。
- Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
- Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
3、添加IP地址配置映射表
- 在第一台虚拟机上打开终端,执行如下命令,编辑文件:
- vi /etc/hosts
- 在文件尾部追加3行,文件内容如下:
-
- 127.0.0.1 localhost localhost.hugs localhost4 localhost4.localdomain4
- ::1 localhost localhost.hugs localhost6 localhost6.localdomain6
- #三台虚拟的IP地址加主机名,按照下面格式
- 192.168.8.121 hadoop01.bgd01
- 192.168.8.122 hadoop02.bgd01
- 192.168.8.123 hadoop03.bgd01
4、SSH免密登录设置
- (1) 利用ssh-keygen生成密钥对。
- 在hadoop01.bgd01上,进入root用户主目录 /root,执行如下命令,生成 .ssh 目录和密匙对及免密登录授权文件:
- 执行如下命令,生成密匙对:
- ssh-keygen -t rsa
-
- 下面是生成密匙对的过程:
- Generating public/private rsa key pair. #提示生成 公/私 密匙对
- Enter file in which to save the key (/root/.ssh/id_rsa): #提示保存私匙的目录路径及文件名,按回车
- Created directory '/root/.ssh'. #在“/root”下创建了“.ssh”目录
- Enter passphrase (empty for no passphrase): #提示输入密码短语,如果不需要,按回车
- Enter same passphrase again: #提示再次输入相同密码短语,如果不需要,按回车
- Your identification has been saved in /root/.ssh/id_rsa. #生成了密匙文件id_rsa
- Your public key has been saved in /root/.ssh/id_rsa.pub. #生成了公匙文件id_rsa.pub
-
- 分别在hadoop02.bgd01、在hadoop03.bgd01上,执行相同的操作,生成密匙对。
-
- (2) 将公钥合并到hadoop01.bgd01上的authorized_keys文件中。
- 分别在hadoop01.bgd01、hadoop02.bgd01、hadoop03.bgd01上执行如下命令:
- ssh-copy-id hadoop01.bgd01
- 出现如下提示时,按#提示操作:
- Are you sure you want to continue connecting (yes/no)? #输入"yes"
- root@hadoop01.hugs's password: #输入hadoop01.hugs的root账号密码
- 这样就完成了对公匙的合并。hadoop01.bgd01的“/root/.ssh”目录下会产生公匙授权文件 authorized_keys。其实该步操作是将三台主机上id_rsa.pub中的内容合并添加到authorized_keys中。
- (3) 实现hadoop01、hadoop02、hadoop03之间的相互免密码登录。
- 在hadoop01上执行如下命令,将hadoop01上的公匙授权文件 authorized_keys 同步分发给hadoop02到hadoop03 :
- scp /root/.ssh/authorized_keys hadoop02.bgd01:/root/.ssh/
- 执行该命令时,会提示输入hadoop02.hugs的root登录密码,输入相应密码即可。
- scp /root/.ssh/authorized_keys hadoop03.bgd01:/root/.ssh/
- 执行该命令时,会提示输入hadoop03.hugs的root登录密码,输入相应密码即可。
- 以后三台主机之间,相互登录其它主机就不需要输入密码了。登录命令如下:
- ssh 主机名称
- (4) 使用ssh命令,测试免密登录。
- 在任意一台主机上执行命令:
- ssh localhost
- 发现不需要输入密码就登录到本地主机了。
- 此时因为我们使用的就是root账户,目标登陆账户也是root,所以登陆之后用户没有变化,会造成没有反应的感觉。
- 然后,输入命令exit退出刚才的SSH,就回到了原先的终端窗口。
- 将上述命令中的localhost换成hadoop01.bgd01、hadoop02.bgd01或hadoop03.bgd01,无需输入密码就可以免密登录相应主机了。
5、配置时间同步
- 安装Chrony
- 在三台主机上在线安装时间同步Chrony
- yum install chrony -y
-
- 启动Chrony服务
- 在三台虚拟机上启动时间同步工具Chrony服务
- systemctl start chronyd
-
- 启动报错
- 可能是下载的版本是最新版,与Linux内核起冲突
- 可以尝试以下指令
- yum -y update
-
- 配置Chrony信息
- vi /etc/chrony.conf
-
- 在主节点,hadoop01.bgd01配置如下
- #不使用网络服务器作为时间同步源
- #server 0.centos.pool.ntp.org iburst
- #server 1.centos.pool.ntp.org iburst
- #server 2.centos.pool.ntp.org iburst
- #server 3.centos.pool.ntp.org iburst
- #添加时间同步器,将主节点的虚拟机作为时间服务同步时间
- #这里填写自己虚拟机的主机名或IP地址
- server hadoop01.bgd01 iburst
-
- # Allow NTP client access from local network.
- #允许192.168.8.0网段的客户端可以与时间服务器同步时间
- allow 192.168.8.0/16
-
- # Serve time even if not synchronized to a time source.
- #即使时间服务器不能获取网络时间,也会将本地时间做为标准时间赋予其他客户端
- local stratum 10
-
- 在另外两台虚拟机hadoop02.bgd01、hadoop03.bgd01配置如下
- #不使用网络服务器作为时间同步源
- #server 0.centos.pool.ntp.org iburst
- #server 1.centos.pool.ntp.org iburst
- #server 2.centos.pool.ntp.org iburst
- #server 3.centos.pool.ntp.org iburst
- #添加时间同步器,将主节点的虚拟机作为时间服务同步时间
- server hadoop01.bgd01 iburst
-
- 重启Chrony服务
- 分别在三台虚拟机重启Chrony服务,使配置生效
- systemctl restart chronyd
-
- 查看时间同步源状态
- chronyc sources -v
-
- 210 Number of sources = 1
-
- .-- Source mode '^' = server, '=' = peer, '#' = local clock.
- / .- Source state '*' = current synced, '+' = combined , '-' = not combined,
- | / '?' = unreachable, 'x' = time may be in error, '~' = time too variable.
- || .- xxxx [ yyyy ] +/- zzzz
- || Reachability register (octal) -. | xxxx = adjusted offset,
- || Log2(Polling interval) --. | | yyyy = measured offset,
- || \ | | zzzz = estimated error.
- || | | \
- MS Name/IP address Stratum Poll Reach LastRx Last sample
- ===============================================================================
- ^* hadoop01.bgd01 11 7 377 227 +30us[ +40us] +/- 8251us
三、准备工作
- 在根目录“/”下创建3个目录
- /export/data/ :存放数据类文件
- /export/servers/ :存放服务类文件
- /export/software/ :存放安装包文件
-
- 将所有压缩包上传到/export/software/目录下
- 预备工作-在主机hadoop01.bgd01上安装上传文件工具rz软件
- yum install lrzsz -y
-
- rz
四、jdk安装
- 用tar命令将jdk安装到 /export/servers/ 目录下。
- tar -zvxf jdk-8u161-linux-x64.tar.gz -C /export/servers/
-
- 为简便起见,进入/export/servers/目录,执行如下指令重命名“jdk1.8.0_161”为“jdk”:
- mv jdk1.8.0_333/ jdk
-
- 在/etc/profile文件中配置 JDK 系统环境变量(如果不是使用root用户登录,使用 sudo vim /etc/profile 命令打开
-
- export JAVA_HOME=/export/servers/jdk
- export PATH=$JAVA_HOME/bin:$PATH
- export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
-
- 保存后退出。然后执行 "source /etc/profile"指令使配置文件生效。
- 使用如下命令验证JDK安装是否成功,如果成功,会出现版本等信息。
- java -version
五、Zookeeper集群部署
- 安装Zookeeper
- 执行解压命令:
- tar -zvxf apache-zookeeper-3.4.10-bin.tar.gz -C /export/servers/
-
- /export/servers/下会出现 apache-zookeeper-3.4.10-bin 目录
-
- 修改安装目录名称 apache-zookeeper-3.4.10-bin 为 zookeeper
- mv /export/servers/apache-zookeeper-3.4.10-bin /export/servers/zookeeper
-
- 配置环境变量
- 在/etc/profile文件中配置Zookeeper环境变量。执行如下命令:
- vi /etc/profile
- 添加如下2行:
- export ZK_HOME=/export/servers/zookeeper
- export PATH=$PATH:$ZK_HOME/bin
-
- 保存后退出。
- 执行如下命令,使配置文件生效:
- source /etc/profile
-
- 配置Zookeeper的相关参数
- 修改Zookeeper的配置文件
- 进入Zookeeper配置目录:
- cd /export/servers/zookeeper/conf
-
- 执行如下命令,复制文件
- cp zoo_sample.cfg zoo.cfg
-
- 编辑文件 zoo.cfg
- vi zoo.cfg
-
- 将行 “dataDir=/tmp/zookeeper” 修改为:
- dataDir=/export/data/zookeeper/zkdata
- dataLogDir=/export/data/zookeeper/zklog
-
- 在文件末尾添加如下几行:
- #配置Zookeeper集群的服务其编号及对应的主机名、通信端口号(心跳端口号)和选举端口号
- server.1=hadoop01.bgd01:2888:3888
- server.2=hadoop02.bgd01:2888:3888
- server.3=hadoop03.bgd01:2888:3888
- 保存后退出。
-
- 创建myid文件
- 创建目录 /export/data/zookeeper/zkdata、/export/data/zookeeper/zklog
- mkdir -p /export/data/zookeeper/zkdata
- mkdir -p /export/data/zookeeper/zklog
-
- 进入 /export/data/zookeeper/zkdata 目录
- cd /export/data/zookeeper/zkdata
-
- 执行如下命令,创建myid文件(服务器hadoop01对应编号1、服务器hadoop02对应编号2、服务器hadoop03对应编号3):
- echo 1 > myid
-
- 将配置文件分发到其他虚拟机
- scp -r /export/servers/ hadoop02.bgd01:/export/
- scp -r /export/servers/ hadoop03.bgd01:/export/
-
- scp -r /export/data/ hadoop02.bgd01:/export/
- scp -r /export/data/ hadoop03.bgd01:/export/
-
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop03.bgd01:/etc/
-
- 分别在hadoop02.bgd01、hadoop03.bgd01执行以下命令对myid进行修改
- vi /export/data/zookeeper/zkdata/myid
- 其中hadoop02.bgd01配置为2,hadoop03.bgd01配置为3
-
- 然后执行在三台虚拟机"source /etc/profile"指令使配置文件生效。
-
- 测试
- 在三台虚拟机上启动Zookeeper集群
- zkServer.sh start
-
- 查看集群的状态
- zkServer.sh status
-
- hadoop01
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Mode: follower
-
- hadoop02
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Mode: leader
-
- hadoop03
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Mode: follower
-
- 关闭集群
- zkServer.sh stop
1、Zookeeper集群启动脚本编写
- 在Zookeeper的bin目录下创建三个脚本,分别为start-zkServer.sh、stop-zkServer.sh、status-zkServer.sh
-
- 启动集群
- start-zkServer.sh
- 内容如下
- #! /bin/sh
- for host in hadoop01.bgd01 hadoop02.bgd01 hadoop03.bgd01
- do
- ssh $host "source /etc/profile;zkServer.sh start"
- echo "$host zk is running"
- done
- 保存退出
-
- 关闭集群
- stop-zkServer.sh
- 内容如下
- #! /bin/sh
- for host in hadoop01.bgd01 hadoop02.bgd01 hadoop03.bgd01
- do
- ssh $host "source /etc/profile;zkServer.sh stop"
- echo "$host zk is stopping"
- done
- 保存退出
-
- 查看集群状态
- status-zkServer.sh
- 内容如下
- #! /bin/sh
- for host in hadoop01.bgd01 hadoop02.bgd01 hadoop03.bgd01
- do
- ssh $host "source /etc/profile;zkServer.sh status"
- echo "$host zk is status"
- done
- 保存退出
- 因为之前在安装zookeeper的时候,已经将bin目录添加进环境变量中,这里可以在任何目录下执行Shell脚本
-
- 操作如下
- sh start-zkServer.sh
-
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Starting zookeeper ... STARTED
- hadoop01.bgd01 zk is running
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Starting zookeeper ... STARTED
- hadoop02.bgd01 zk is running
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Starting zookeeper ... STARTED
- hadoop03.bgd01 zk is running
-
- sh status-zkServer.sh
-
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Mode: follower
- hadoop01.bgd01 zk is status
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Mode: leader
- hadoop02.bgd01 zk is status
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Mode: follower
- hadoop03.bgd01 zk is status
-
- sh stop-zkServer.sh
-
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Stopping zookeeper ... STOPPED
- hadoop01.bgd01 zk is stopping
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Stopping zookeeper ... STOPPED
- hadoop02.bgd01 zk is stopping
- ZooKeeper JMX enabled by default
- Using config: /export/servers/zookeeper/bin/../conf/zoo.cfg
- Stopping zookeeper ... STOPPED
- hadoop03.bgd01 zk is stopping
六、Hadoop高可用集群部署
1、安装配置
- 用tar命令将hadoop安装到 /export/servers/ 目录下
- tar -zxvf /export/software/hadoop-2.7.4.tar.gz -C /export/servers/
-
- 在/etc/profile文件中, 配置 Hadoop 系统环境变量
- 执行如下命令:
- vi /etc/profile
- 添加如下2行:
- export HADOOP_HOME=/export/servers/hadoop-2.7.4
- export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 保存后退出。
- 执行如下命令,使配置文件生效:
- source /etc/profile
-
- 使用如下命令验证hadoop安装是否成功,如果成功,会出现版本等信息。
- hadoop version
2、修改配置文件
cd /export/servers/hadoop-2.7.4/etc/hadoop/(1) 修改 hadoop-env.sh 文件
- vi hadoop-env.sh
- #将这一行该成自己jdl安装的路径
- export JAVA_HOME=/export/servers/jdk
(2)修改 core-site.xml 文件
- <!-- 指定HDFS的nameservice为ns1,需要和hdfs-site.xml中的保持一致 -->
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://ns1</value>
- </property>
-
- <!-- 指定hadoop临时目录 -->
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/export/servers/hadoop-2.7.4/tmpha</value> #为了便于同伪分布和分布式集群之间切换
- </property>
-
- <!-- 指定用于ZKFailoverController故障自动恢复的Zookeeper服务器地址,用逗号分隔 -->
- <property>
- <name>ha.zookeeper.quorum</name>
- <value>hadoop01.bgd01:2181,hadoop02.bgd01:2181,hadoop03.bgd01:2181</value>
- </property>
-
- <!-- 指定 Zookeeper 集群服务器的 Host:Port 列表 -->
- <property>
- <name>hadoop.zk.address</name>
- <value>hadoop01.bgd01:2181,hadoop02.bgd01:2181,hadoop03.bgd01:2181</value>
- </property>
-
- <!-- 指定 用于ZK故障恢复存储信息的ZooKeeper znode -->
- <property>
- <name>ha.zookeeper.parent-znode</name>
- <value>/hadoop-ha</value>
- </property>
(3) 修改 hdfs-site.xml 文件
- <!-- 指定HDFS的副本数量 -->
- <property>
- <name>dfs.replication</name>
- <value>3</value>
- </property>
-
- <!-- 设置NameNode节点数据存放目录 -->
- <property>
- <name>dfs.namenode.name.dir</name>
- <value>/export/data/hadoop/namenode</value>
- </property>
-
- <!-- 设置DataNode节点数据存放目录 -->
- <property>
- <name>dfs.datanode.data.dir</name>
- <value>/export/data/hadoop/datanode</value>
- </property>
-
- <!-- 开启webHDFS -->
- <property>
- <name>dfs.webhdfs.enabled</name>
- <value>true</value>
- </property>
-
- <!-- 指定HDFS的nameservice为ns1,需要和core-site.xml中的保持一致 -->
- <property>
- <name>dfs.nameservices</name>
- <value>ns1</value>
- </property>
-
- <!-- ns1下面有两个NameNode,分别是nn1,nn2 -->
- <property>
- <name>dfs.ha.namenodes.ns1</name>
- <value>nn1,nn2</value>
- </property>
-
- <!-- nn1的RPC通信地址 -->
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn1</name>
- <value>hadoop01.bgd01:9000</value>
- </property>
-
- <!-- nn1的http通信地址,配置NameNode节点的Web页面访问地址 -->
- <property>
- <name>dfs.namenode.http-address.ns1.nn1</name>
- <value>hadoop01.bgd01:50070</value>
- </property>
-
- <!-- nn2的RPC通信地址 -->
- <property>
- <name>dfs.namenode.rpc-address.ns1.nn2</name>
- <value>hadoop02.bgd01:9000</value>
- </property>
-
- <!-- nn2的http通信地址,配置NameNode节点的Web页面访问地址 -->
- <property>
- <name>dfs.namenode.http-address.ns1.nn2</name>
- <value>hadoop02.bgd01:50070</value>
- </property>
-
- <!-- 指定NameNode的共享edits元数据在JournalNode上的存放位置,一般配置奇数个,以适应zk选举 -->
- <property>
- <name>dfs.namenode.shared.edits.dir</name>
- <value>qjournal://hadoop01.bgd01:8485;hadoop02.bgd01:8485;hadoop03.bgd01:8485/ns1</value>
- </property>
-
- <!-- 指定JournalNode在本地磁盘存放数据的位置 ,JournalName用于存放元数据和状态信息的目录 -->
- <property>
- <name>dfs.journalnode.edits.dir</name>
- <value>/export/data/hadoop/journaldata</value>
- </property>
-
- <property>
- <name>ipc.client.connect.max.retries</name>
- <value>30</value>ide
- </property>
-
- <!-- 开启NameNode失败自动重启 -->
- <property>
- <name>dfs.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
-
- <!-- 配置失败自动切换实现方式 ,客户端与NameNode通讯的地址 -->
- <property>
- <name>dfs.client.failover.proxy.provider.ns1</name>
- <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
- </property>
-
- <!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行,解决HA脑裂问题 -->
- <property>
- <name>dfs.ha.fencing.methods</name>
- <value>
- sshfence
- shell(/bin/true)
- </value>
- </property>
-
- <!-- 使用sshfence隔离机制时需要ssh免密登录,上述属性ssh通讯使用的秘钥文件 -->
- <property>
- <name>dfs.ha.fencing.ssh.private-key-files</name>
- <value>/root/.ssh/id_rsa</value>
- </property>
-
- <!-- 配置sshfence隔离机制连接超时时间 -->
- <property>
- <name>dfs.ha.fencing.ssh.connect-timeout</name>
- <value>3000</value>
- </property>
(4) 修改 mapred-site.xml 文件
- 先将mapred-site.xml.template 复制到 mapred-site.xml
- <configuration>
- <!-- 指定MapReduce运行时框架,这里指定在YARN上,默认是local -->
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- </configuration>
(5) 修改 yarn-site.xml 文件
- <property>
- <!-- 该节点上nodemanager可用的物理内存总量,默认是8192M,如果节点内存不够8GB,则需要调整,
- 否则NodeManager进程无法启动或者启动后自动结束 -->
- <name>yarn.scheduler.maximum-allocation-mb</name>
- <value>8192</value>
- </property>
-
- <property>
- <!-- 资源管理器中可分配的内存 -->
- <name>yarn.nodemanager.resource.memory-mb</name>
- <value>8192</value>
- </property>
-
- <property>
- <!-- NodeManager 可以分配的CPU核数 -->
- <name>yarn.nodemanager.resource.cpu-vcores</name>
- <value>8</value>
- </property>
-
- <!-- 开启resourcemanager高可用 -->
- <property>
- <name>yarn.resourcemanager.ha.enabled</name>
- <value>true</value>
- </property>
-
- <!-- 指定resourcemanager的cluster id -->
- <property>
- <name>yarn.resourcemanager.cluster-id</name>
- <value>yrc</value>
- </property>
-
- <!-- 指定resourcemanager的名字 -->
- <property>
- <name>yarn.resourcemanager.ha.rm-ids</name>
- <value>rm1,rm2</value>
- </property>
-
- <!-- 分别指定resourcemanager的地址 -->
- <property>
- <name>yarn.resourcemanager.hostname.rm1</name>
- <value>hadoop01.bgd01</value>
- </property>
- <property>
- <name>yarn.resourcemanager.hostname.rm2</name>
- <value>hadoop02.bgd01</value>
- </property>
-
- <!-- 指定 Zookeeper 集群服务器的 Host:Port 列表 -->
- <property>
- <name>yarn.resourcemanager.zk-address</name>
- <value>hadoop01.bgd01:2181,hadoop02.bgd01:2181,hadoop03.bgd01:2181</value>
- </property>
-
- <!-- 开启自动恢复功能 -->
- <property>
- <name>yarn.resourcemanager.recovery.enabled</name>
- <value>true</value>
- </property>
-
- <!-- 开启故障自动转移 -->
- <property>
- <name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
- <value>true</value>
- </property>
-
- <!-- 指定rm的web访问地址的 -->
- <property>
- <name>yarn.resourcemanager.webapp.address.rm1</name>
- <value>${yarn.resourcemanager.hostname}:8088</value>
- </property>
-
- <property>
- <name>yarn.resourcemanager.webapp.address.rm2</name>
- <value>${yarn.resourcemanager.hostname}:8088</value>
- </property>
-
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
-
- <!-- ResourceManager存储信息的方式,在HA机制下用Zookeeper作为存储介质 -->
- <property>
- <name>yarn.resourcemanager.store.class</name>
- <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
- </property>
-
- <!-- 开启YARN日志 -->
- <property>
- <name>yarn.log-aggregation-enable</name>
- <value>true</value>
- </property>
(6)修改 slaves 文件
- hadoop01.bgd01
- hadoop02.bgd01
- hadoop03.bgd01
(7)分发节点
- scp -r /export/servers/hadoop-2.7.4 hadoop02.bgd01:/export/servers/
- scp -r /export/servers/hadoop-2.7.4 hadoop03.bgd01:/export/servers/
-
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop02.bgd01:/etc/
-
- 执行完上述命令后,还需在hadoop02、hadoop03上分别执行"source /etc/profile"指令立即刷新配置文件。
3、启用Hadoop高可用集群
- 1、启动集群各个节点上的Zookeeper服务
- zkServer.sh start
-
- 2、启动集群各个节点监控NameNode的管理日志的JournalNode
- hadoop-daemons.sh start journalnode
- 注:只需在第一次初始化启动集群时运行一次。以后每次启动集群,journalnode会在步骤 5、start-dfs.sh中启动。
-
- 3、在hadoop01格式化NameNode,并将格式化后的目录复制到hadoop02中
- hdfs namenode -format
- (执行格式化指令后必须出现 successfulluy formatted 才表示格式化成功。)
- scp -r /export/data/hadoop hadoop02.bgd01:/export/data/
-
- 4、在hadoop01格式化ZKFC
- hdfs zkfc -formatZK
-
- 5、在Hadoop01上启动所有HDFS服务进程
- start-dfs.sh
-
- 6、在Hadoop01上启动所有YARN服务进程
- start-yarn.sh
-
- 7、查看服务进程
- 集群启动后,如果正常,执行命令
- JPS
- 查看进程。
- hadoop01上可以查看到如下进程:
- NameNode
- DFSZKFailoverController
- ResourceManager
- DataNode
- Jps
- JournalNode
- NodeManager
- QuorumPeerMain
-
- hadoop02上可以查看到如下进程:
- NameNode
- DFSZKFailoverController
- DataNode
- Jps
- JournalNode
- NodeManager
- QuorumPeerMain
-
- hadoop03上可以查看到如下进程:
- DataNode
- Jps
- JournalNode
- NodeManager
- QuorumPeerMain
-
- 在浏览器中查看和管理集群。
- 1、Hadoop状态查看
- http://hadoop01.bgd01:50070/dfshealth.html
-
- 2、HDFS状态查看
- http://hadoop01.bgd01:50070/explorer.html
-
- 3、YARN状态查看
- http://hadoop01.bgd01:8088/cluster
-
- 六、关闭Hadoop集群
- 1、在Hadoop01上关闭所有YARN服务进程
- stop-yarn.sh
-
- 2、在Hadoop01上关闭所有HDFS服务进程
- stop-dfs.sh
-
- 3、在集群各个节点上的关闭Zookeeper服务
- zkServer.sh stop
七、Spark高可用集群部署
1、安装部署
- 解压Spark压缩包到/export/servers/目录下,并进行重名命名
- tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /export/servers/
- mv /export/servers/spark-2.3.2-bin-hadoop2.7 /export/servers/spark
-
- 配置环境变量
- vi /etc/profile
- export SPARK_HOME=/export/servers/spark
- export PATH=$PATH:$SPARK_HOME/bin
-
- 使环境变量生效
- source /etc/profile
2、配置文件
- 进入Spark安装目录conf/目录下,进行相关配置
- cd /export/servers/spark/conf/
(1) 配置spark-env.sh
- 复制spark-env.sh.template文件,重命名为spark-env.sh
- cp spark-env.sh.template spark-env.sh
-
- 进入spark-env.sh,添加如下配置
- vi spark-env.sh
-
- #Java的安装路径
- export JAVA_HOME=/export/servers/jdk
- #Hadoop配置文件的路径
- export HADOOP_CONF_DIR=/export/servers/hadoop-2.7.4/etc/hadoop/
- #Spark高可用配置
- #设置Zookeeper去启动备用Master模式
- #spark.deploy.recoveryMode:设置Zookeeper去启动备用Master模式
- #spark.deploy.zookeeper.url:指定Zookeeper的Server地址
- #spark.deploy.zookeeper.dir:保存集群元数据信息的文件和目录
- export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
- -Dspark.deploy.zookeeper.url=hadoop01.bgd01:2181,hadoop02.bgd01:2181,hadoop03.bgd01:2181
- -Dspark.deploy.zookeeper.dir=/spark"
- #Spark主节点的端口号
- export SPARK_MASTER_PORT=7077
- #工作(Worker)节点能给予Executor的内存大小
- export SPARK_WORKER_MEMORY=512m
- #每个节点可以使用的内核数
- export SPARK_WORKER_CORES=1
- #每个Executor的内存大小
- export SPARK_EXECUTOR_MEMORY=512m
- #Executor的内核数
- export SPARK_EXECUTOR_CORES=1
- #每个Worker进程数
- export SPARK_WORKER_INSTANCES=1
(2) 配置Workers文件
- 复制workers.template文件,重命名为 workers,删除原有内容,添加如下配置
- cp slaves.template slaves
- vi slaves
-
- #每行代表一个子节点主机名
- hadoop02.bgd01
- hadoop03.bgd01
(3)配置spark-defaults.conf文件
- 复制spark-defaults.conf.template文件,重命名为spark-defaults.conf,添加如下配置
- cp spark-defaults.conf.template spark-defaults.conf
- vi spark-defaults.conf
-
- #Spark主节点所在机器及端口号,默认写法是spark://
- spark.master spark://hadoop01.bgd01:7077
- #是否打开任务日志功能,默认为flase,即不打开
- spark.eventLog.enabled true
- #任务日志默认存放位置,配置为一个HDFS路径即可
- spark.eventLog.dir hdfs://ns1/spark-logs
- #存放历史应用日志文件的目录
- spark.history.fs.logDirectory hdfs://ns1/spark-logs
注意事项
- 这里需要注意,hadoop的各个端口号的区别:
- 8020是默认rpc的端口号,一般用于IDE远程使用Hadoop集群,是程序和程序之间的连接。
- 9000端口:是HDFS默认的端口号,提供文件系统的端口供client角色寻找namenode角色的端口号,是进程之间的调用。
- 但是在core-site.xml文件的配置当中,如果hdfs://ns1:9000改为hdfs://ns1,则默认端口号为8020
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://ns1:9000</value>
- </property>
-
- 50070:namenode提供给操作者使用Web访问的端口号,是操作者和程序之间的端口号
- <property>
- <name>dfs.namenode.http-address.mycluster.nn1</name>
- <value>hadoop01.bgd01:50070</value>
- </property>
-
- 50090:secondarynamenode的端口号,这个也是Web访问的端口号
- <property>
- <name>dfs.namenode.secondary.http-address</name>
- <value>hadoop02.bgd01:50090</value>
- </property>
-
- hdfs有下面几种角色:namenode,datanode,secondarynamenode,client等
3、分发文件
- scp -r /export/servers/spark hadoop02.bgd01:/export/servers/
- scp -r /export/servers/spark hadoop03.bgd01:/export/servers/
-
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop03.bgd01:/etc/
-
- 在各个节点刷新环境变量
- source /etc/profile
4、启动Spark HA集群
- 启动前在hdfs上创建Spark的日志目录
- hadoop fs -mkdir /spark-logs
- hadoop fs -ls /
- drwxr-xr-x - root supergroup 0 2023-03-02 23:21 /spark-logs
-
- 启动Zookeeper服务
- 这里使用脚本一键启动
- sh start-zkServer.sh
-
- 启动Spark集群
- 在hadoop01主节点使用一键启动脚本启动
- /export/servers/spark/sbin/start-all.sh
-
- 单独启动Master节点
- 在hadoop02节点上再次启动Master服务
- /export/servers/spark/sbin/start-master.sh
-
- 通过访问http://hadoop02.bgd01:8080可以查看Master节点的状态
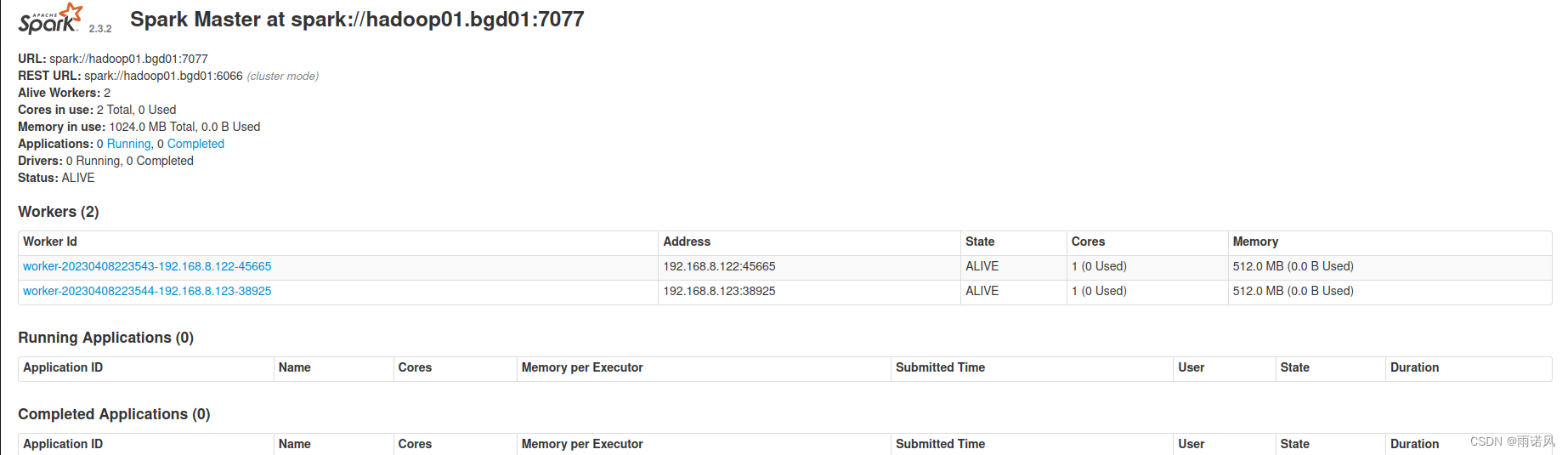
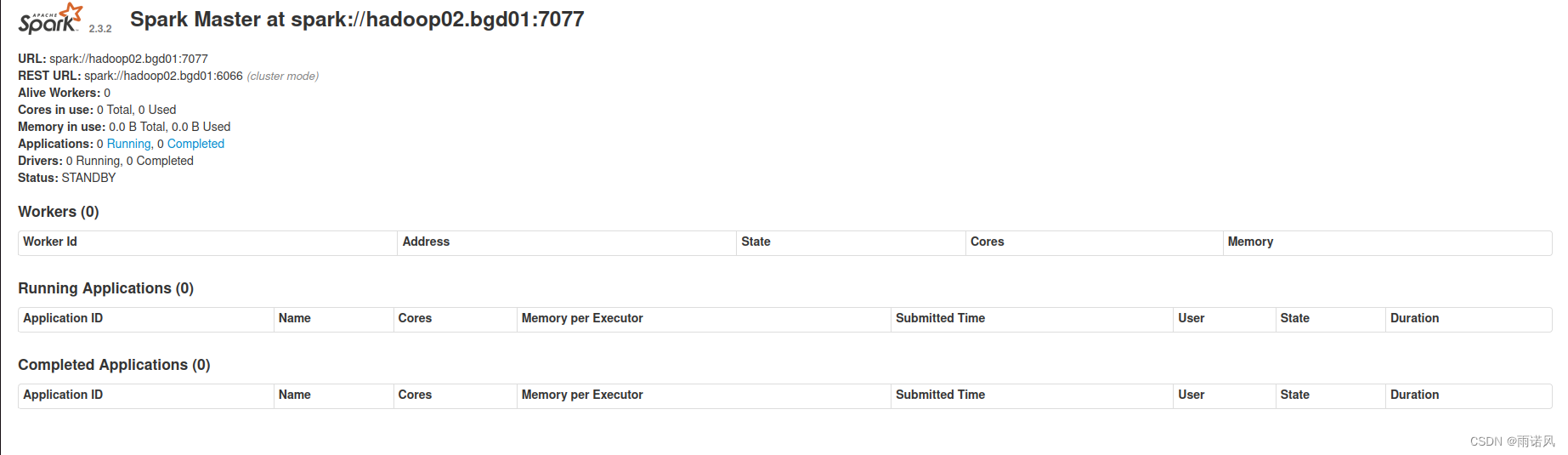
脚本编写
- 由于spark与hadoop的启动指令相似,这里提供一个简单的脚本
-
- 在spark的bin目录下编辑两个Shell的脚本,名为start-spark.sh和stop-spark.sh
-
- start-spark.sh
- 内容如下
- #! /bin/sh
- for host in hadoop01.bgd01
- do
- ssh $host "source /etc/profile;/export/servers/spark/sbin/start-all.sh"
- echo "$host Spark is running"
- done
-
- stop-spark.sh
- 内容如下
- #! /bin/sh
- for host in hadoop01.bgd01
- do
- ssh $host "source /etc/profile;/export/servers/spark/sbin/stop-all.sh"
- echo "$host Spark is stopping"
- done
5、Scala安装
- 将scala-2.12.15.tgz解压至/export/servers目录下,并重命名
- tar -zxvf scala-2.11.12.tgz -C /export/servers/
- cd /export/servers/
- mv scala-2.11.12 scala
-
- 配置环境变量
- vi /etc/profile
- export SCALA_HOME=/export/servers/scala
- export PATH=$PATH:$SCALA_HOME/bin
- source /etc/profile
-
- 运行
- scala
-
- 退出
- :quit
-
- scala体验
- scala> 3*3+3
- res0: Int = 12
-
- scala> :paste
- // Entering paste mode (ctrl-D to finish)
-
- object add{
- def addInt(a:Int,b:Int):Int={
- var sum:Int=0
- sum=a+b
- return sum
- }
- }
-
- // Exiting paste mode, now interpreting.
-
- defined object add
-
- scala> import add.addInt;
- import add.addInt
-
- scala> addInt(2,3);
- res2: Int = 5
八、Hbase高可用集群部署
1、安装配置
- 将Hbase压缩包解压至/export/servers目录上,并重命名
- cd /export/software
- tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers/
- mv /export/servers/hbase-1.2.1 /export/servers/hbase
-
- 配置环境变量
- vi /etc/profile
- export HBASE_HOME=/export/servers/hbase
- export PATH=$PATH:$HBASE_HOME/bin
-
- 刷新环境变量,使配置生效
- source /etc/profile
2、文件配置
- 修改Hbase配置文件
- cd /export/servers/hbase/conf/
(1)修改hbase-site.xml文件
- vi hbase-site.xml
-
- <configuration>
- <property>
- <name>hbase.cluster.distributed</name>
- <value>true</value>
- </property>
- <property>
- <name>hbase.tmp.dir</name>
- <value>/export/data/hbasedata</value>
- </property>
- <property>
- <name>hbase.master.maxclockskew</name>
- <value>180000</value>
- </property>
- <!-- 指定hbase在HDFS上存储的路径 -->
- <property>
- <name>hbase.rootdir</name>
- <value>hdfs://ns1/hbase</value>
- </property>
- <property>
- <name>hbase.zookeeper.property.dataDir</name>
- <value>/export/data/zookeeper/zkdata</value>
- </property>
- <!-- 指定zookeeper地址,多个用","分隔 -->
- <property>
- <name>hbase.zookeeper.quorum</name>
- <value>hadoop01.bgd01:2181,hadoop02.bgd01:2181,hadoop03.bgd01:2181</value>
- </property>
- <property>
- <name>hbase.unsafe.stream.capability.enforce</name>
- <value>false</value>
- </property>
- <!-- 指定hbase访问端口 -->
- <property>
- <name>hbase.master.info.port</name>
- <value>16010</value>
- </property>
- </configuration>
-
- 创建hbase的日志存储目录
- mkdir -p /export/data/hbasedata
(2)修改hbase-env.sh文件
- vi hbase-env.sh
- #配置jdk环境变量
- export JAVA_HOME=/export/servers/jdk
- #配置hbase使用外部环境变量
- export HBASE_MANAGES_ZK=false
(3) 修改regionservers文件
- hadoop02.bgd01
- hadoop03.bgd01
(4)配置备用HMaster
- vi backup-masters
-
- hadoop02.bgd01
- hadoop03.bgd01
(5)复制hadoop配置文件
- 将Hadoop的配置文件复制到Hbase的conf/目录下
- cd /export/servers/hadoop-2.10.1/etc/hadoop/
- cp -r core-site.xml hdfs-site.xml /export/servers/hbase/conf/
(6) 修改hbase-env.sh文件
- 在hadoop-env.sh里添加以下内容,方便后续hadoop加载hbase的jar包
-
- export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/export/servers/hbase/lib/*
-
- 执行hadoop classpath,可以看到以及导入了hbase的jar包
- /export/servers/hadoop-2.7.4/etc/hadoop:/export/servers/hadoop-2.7.4/share/hadoop/common/lib/*:/export/servers/hadoop-2.7.4/share/hadoop/common/*:/export/servers/hadoop-2.7.4/share/hadoop/hdfs:/export/servers/hadoop-2.7.4/share/hadoop/hdfs/lib/*:/export/servers/hadoop-2.7.4/share/hadoop/hdfs/*:/export/servers/hadoop-2.7.4/share/hadoop/yarn/lib/*:/export/servers/hadoop-2.7.4/share/hadoop/yarn/*:/export/servers/hadoop-2.7.4/share/hadoop/mapreduce/lib/*:/export/servers/hadoop-2.7.4/share/hadoop/mapreduce/*:/export/servers/hadoop-2.7.4/contrib/capacity-scheduler/*.jar:/export/servers/hbase/lib/*
3、分发文件
- scp -r /export/servers/hbase hadoop02.bgd01:/export/servers/
- scp -r /export/servers/hbase hadoop03.bgd01:/export/servers/
-
- scp -r /export/data/hbasedata hadoop02.bgd01:/export/data/
- scp -r /export/data/hbasedata hadoop03.bgd01:/export/data/
-
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop03.bgd01:/etc/
-
- 在hadoop02、hadoop03上刷新环境变量
- source /etc/profile
4、启动集群
- 启动zookeeper集群
- sh shart-zkServer.sh
-
- 启动hadoop集群
- start-all.sh
-
- 启动hbase集群
- start-hbase.sh
-
- 查看进程
- hadoop01
- 10370 HMaster
- 9603 DFSZKFailoverController
- 10502 HRegionServer
- 9272 DataNode
- 10874 Jps
- 9884 NodeManager
- 9165 NameNode
- 9773 ResourceManager
- 5807 QuorumPeerMain
- 9471 JournalNode
-
- hadoop02
- 6098 HMaster
- 5716 JournalNode
- 3957 QuorumPeerMain
- 5621 DataNode
- 5783 DFSZKFailoverController
- 5928 NodeManager
- 6235 Jps
- 5548 NameNode
-
- hadoop03
- 3472 QuorumPeerMain
- 4421 Jps
- [root@hadoop03 ~]# jps
- 3472 QuorumPeerMain
- 4688 NodeManager
- 4976 Jps
- 4849 HMaster
- 4587 JournalNode
- 4492 DataNode
-
- 登录Hbase的Web界面
- http://hadoop01.bgd01:16010
5、Phoenix安装
- 解压
- tar -zxvf apache-phoenix-4.14.1-HBase-1.2-bin.tar.gz -C /export/servers/
-
- 重命名
- mv /export/servers/apache-phoenix-4.14.1-HBase-1.2-bin /export/servers/phoenix
-
- 配置环境变量
- vi /etc/profile
- export PHOENIX_HOME=/export/servers/phoenix
- export PATH=$PATH:$PHOENIX_HOME/bin
-
- 刷新
- source /etc/profile
-
- 分发至其他节点
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop03.bgd01:/etc/
-
- source /etc/profile
-
-
- 将phoenix下的所有jar包复制到hbase的lib目录下
- cp /export/servers/phoenix/phoenix-*.jar /export/servers/hbase/lib/
-
- 分发jar包至hbase的每个节点
- cd /export/servers/hbase/lib/
-
- scp phoenix-*.jar hadoop02.bgd01:$PWD
- scp phoenix-*.jar hadoop03.bgd01:$PWD
-
- 修改配置文件
- vi /export/servers/hbase/conf/hbase-site.xml
-
- # 添加以下内容
- <!-- 支持HBase命名空间映射 -->
- <property>
- <name>phoenix.schema.isNamespaceMappingEnabled</name>
- <value>true</value>
- </property>
-
- <!-- 支持索引预写日期编程 -->
- <property>
- <name>hbase.regionserver.wal.code</name>
- <value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCode</value>
- </property>
-
- 启动
- cd /export/servers/phoenix/bin/
- ./sqlline.py hadoop01.bgd01:2181
- 这里需要注意,hadoop01.bgd01:2181是主机名或IP地址加上zookeeper的端口号
-
- 退出!quit
-
- 将配置分发到其他节点
- scp -r /export/servers/hbase/conf/hbase-site.xml hadoop02.bgd01:/export/servers/hbase/conf/
-
- scp -r /export/servers/hbase/conf/hbase-site.xml hadoop03.bgd01:/export/servers/hbase/conf/
-
- 将配置后的hbase-site.xml拷贝到phoenix的bin目录下
九、Kafa集群部署
1、安装配置
- 解压
- tar -zxvf kafka_2.11-2.0.0.tgz -C /export/servers/
-
- 重命名
- mv /export/servers/kafka_2.11-2.0.0 /export/servers/kafka
-
- 配置环境变量
- vi /etc/profile
- export KAFKA_HOME=/export/servers/kafka
- export PATH=$PATH:$KAFKA_HOME/bin
-
- 刷新环境变量,使配置生效
- source /etc/profile
2、修改配置文件
cd /export/servers/kafka/config/(1)修改server.properties配置文件
- vi server.properties
-
- #broker的全局唯一编号,不能重复
- broker.id=0
- #用来监听链接的端口,producer或consumer将在此端口建立连接
- port=9092
- #处理网络请求的线程数量
- num.network.threads=3
- #用来处理磁盘I/O的现成数量
- num.io.threads=8
- #发送套接字的缓冲区大小
- socket.send.buffer.bytes-102400#接受套接字的缓冲区大小
- socket.receive.buffer.bytes=102400
- #请求套接字的缓冲区大小
- socket.request.max.bytes104857600
- #kafka运行日志存放的路径
- log.dirs=/export/data/kafka/
- #topic在当前broker上的分片个数
- num.partitions=2
- #用来恢复和清理data下数据的线程数量
- num.recovery.threads.per.data.dir=1
- #segment文件保留的最长时间,超时将被删除
- log.retention.hours=1
- #滚动生成新的segment文件的最大时间
- log.roll.hours=1
- #日志文件中每个sement的大小,默认为1GB
- log.segment.bytes=1073741824
- #周期性检查文件大小的时间
- log.retention.check.interval.ms=300000
- #日志清理是否打开
- log.cleaner.enable=true
- #broker需要使用zookeeper保存meta数据
- zokeeperconnect=hadoop01.bgd01:2181,hadoop02.bgd01:2181,hadoop03.bgd01:218133 zookeeper链接超时时间
- zokeeper.connection.timeout.ms=6000
- #partionbuffer中,消息的条数达到阈值时,将触发flush磁盘操作
- log.flush.interval.messages=10000
- #消息缓冲的时间,达到阈值时,将触发flush到磁盘的操作
- log.flush.interval.ms=3000
- #删除topic
- delete.topic.enable=true
- #设置本机IP
- host.name=hadoop01.bgd01
-
-
- 创建存放kafka日志的目录
- mkdir -p /export/data/kafkadata
3、分发节点
- scp -r /export/servers/kafka/ hadoop02.bgd01:/export/servers/
- scp -r /export/servers/kafka/ hadoop02.bgd01:/export/servers/
-
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop03.bgd01:/etc/
-
- scp -r /export/data/kafkadata/ hadoop02.bgd01:/export/data/
- scp -r /export/data/kafkadata/ hadoop03.bgd01:/export/data/
-
- 分别在hadoop02和hadoop03的server.properties进行修改
- hadoop02
- broker.id=1
-
- hadoop03
- broker.id=2
-
- 在hadoop02、hadoop03上刷新环境变量
- source /etc/profile
4、启动集群
- 在kafka的根部录下启动集群,这里需要注意启动的终端不能关闭,一旦关闭kafka服务就会停止,可以克隆一个会话可能打开新的终端,查看进程
- bin/kafka-server-start.sh config/server.properties
-
- jps
- 10370 HMaster
- 9603 DFSZKFailoverController
- 12116 Kafka
- 10502 HRegionServer
- 9272 DataNode
- 12536 Jps
- 9884 NodeManager
- 9165 NameNode
- 9773 ResourceManager
- 5807 QuorumPeerMain
- 9471 JournalNode
十、Hive数据仓库部署
1、安装配置
- 解压
- tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /export/servers/
-
- 重命名
- mv /export/servers/apache-hive-1.2.1-bin /export/servers/hive
-
- 配置环境变量
- vi /etc/profile
- export HIVE_HOME=/export/servers/hive
- export PATH=$PATH:$HIVE_HOME/bin
-
- 刷新环境变量
- source /etc/profile
-
- 复制 mysql 数据库的 JDBC 驱动包到 /export/servers/hive/lib 下
- mysql-connector-java-8.0.20.jar
2、Mysql安装和配置
- 查看本地的数据库
- rpm -qa | grep mariadb
-
- yum install mariadb-server
- yum install mariadb-devel
- yum install mariadb -y
-
- rpm -qa | grep mariadb
- 出现这四个
- mariadb-5.5.68-1.el7.x86_64
- mariadb-server-5.5.68-1.el7.x86_64
- mariadb-libs-5.5.68-1.el7.x86_64
- mariadb-devel-5.5.68-1.el7.x86_64
-
- 设置开机启动
- systemctl enable mariadb
- 启动数据库
- systemctl start mariadb
- 查看数据库状态
- systemctl status mariadb
- 打开数据库
- mysql
-
- mysql>use mysql;
- mysql>update user set Password=PASSWORD('123456') where user='root';
- mysql>grant all PRIVILEGES on *.* to 'root'@'% ' identified by '123456' with grant option;
- mysql>FLUSH PRIVILEGES;
- mysql>quit
-
- 修改密码后,数据库的登录命令如下:
- mysql -uroot -p123456
-
3、修改配置文件
cd /export/servers/hive/conf(1)修改hive-env.sh文件
- 复制文件
- cp hive-env.sh.template hive-env.sh
-
- 修改hive-env.sh配置文件,添加Hadoop环境变量,具体内容如下:
- export JAVA_HOME=/export/servers/jdk
- export HADOOP_HOME=/export/servers/hadoop-2.7.4
- #由于部署 Hadoop 时已经配置了全局 Hadoop 环境变量,因此可以不设置上面2行参数。
-
- export HIVE_HOME=/export/servers/hive
- export HIVE_CONF_DIR=/export/servers/hive/conf
- export HIVE_AUX_JARS_PATH=/export/servers/hive/lib
(2)修改hive-site.xml文件
- vi hive-site.xml
-
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://hadoop01.bgd01:3306/hive?createDatabaseIfNotExist=true</value>
- <description>JDBC connect string for a JDBC metastore</description>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.cj.jdbc.Driver</value>
- <description>Driver class name for a JDBC metastore</description>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- <description>Username to use against metastore database</description>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>123456</value>
- <description>password to use against metastore database</description>
- </property>
-
- <property>
- <name>hive.execution.engine</name>
- <value>mr</value>
- <description>
- Expects one of [mr, tez, spark].
- Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
- remains the default engine for historical reasons, it is itself a historical engine
- and is deprecated in Hive 2 line. It may be removed without further warning.
- </description>
- </property>
(3)初始化数据仓库hive
- 在hive根目录下,执行如下命令进行初始化:
- bin/schematool -dbType mysql -initSchema
-
- 出现如下信息表示安装正常:
- Metastore connection URL: jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=TRUE
- Metastore Connection Driver : com.mysql.cj.jdbc.Driver
- Metastore connection User: root
- Starting metastore schema initialization to 2.3.0
- Initialization script hive-schema-2.3.0.mysql.sql
- Initialization script completed
- schemaTool completed
注意事项
- ls: 无法访问/export/servers/spark/lib/spark-assembly-*.jar: 没有那个文件或目录
- Metastore connection URL: jdbc:mysql://hadoop01.hugs:3306/hive?createDatabaseIfNotExist=true
- Metastore Connection Driver : com.mysql.cj.jdbc.Driver
- Metastore connection User: root
- org.apache.hadoop.hive.metastore.HiveMetaException: Failed to load driver
- *** schemaTool failed ***
-
- 这里是因为spark更新后,原来文件存放路径变更,需要在hive的bin目录下对hive文件进行修改
- cd /export/servers/hive/bin/
- cp -r hive hive.xml
- vi hive
-
- 找到以下这个位置,进行编辑
- # add Spark assembly jar to the classpath
- if [[ -n "$SPARK_HOME" ]]
- then
- sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`
- CLASSPATH="${CLASSPATH}:${sparkAssemblyPath}"
- fi
-
- 将“sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`”修改成以下内容
- sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`
- 退出保存
4、分发文件
- 1. 将 hadoop01 上安装的 Hive 程序分别复制到hadoop02、hadoop03服务器上
- scp -r /export/servers/hive/ hadoop02.bgd01:/export/servers/
- scp -r /export/servers/hive/ hadoop03.bgd01:/export/servers/
-
- 2. 同步全局环境配置文件
- scp /etc/profile hadoop02.bgd01:/etc/
- scp /etc/profile hadoop03.bgd01:/etc/
-
- 在hadoop02、hadoop03上刷新环境变量
- source /etc/profile
5、设置 hadoop 的代理用户,以便 root 用户能够远程登录访问Hive
- 修改Hadoop配置文件 core-site.xml
-
- <!-- 设置 hadoop 的代理用户-->
- <property>
- <!--表示代理用户的组所属-->
- <name>hadoop.proxyuser.root.groups</name>
- <value>*</value>
- </property>
-
- <property>
- <!--表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群-->
- <name>hadoop.proxyuser.root.hosts</name>
- <value>*</value>
- </property>
6、Hive启动
- 本地CLI方式
- 启动Hive
- 执行如下命令:
- hive
- 显示如下:
- hive>
-
- 退出
- hive>exit;
- hive>quit;
-
- 查看数据仓库中的数据库
- hive>show databases;
-
- 查看数据仓库中的表
- hive>show tables;
-
- 查看数据仓库中的内置函数
- hive>show functions;
-
- 清屏
- hive>!clear
-
- 远程服务模式
- 在hadoop01上启动 Hiveserver2服务
- hiveserver2
-
- 注意, 执行上述命令后, 没有任何显示. 但是,重新打开一个终端,用jps查询,会多出一个RunJar进程.
-
- 在hadoop02服务器的Hive安装包下, 执行远程连接命令连接到 Hive数据仓库服务器
- (如果只有一台服务器,可以在本地打开另外一个终端进行操作演示)
- //输入远程连接命令
- bin/beeline
- //出现如下显示信息
- Beeline version 2.3.9 by Apache Hive
- beeline>
-
- //如下输入连接协议
- beeline> !connect jdbc:hive2://hadoop01.bgd01:10000
- //显示正在连接信息
- Connecting to jdbc:hive2://hadoop01.bgd01:10000
-
- //根据提示输入 Hive服务器 hadoop01 的用户名和密码
- Enter username for jdbc:hive2://hadoop01.bgd01:10000: root
- Enter password for jdbc:hive2://hadoop01.bgd01:10000: ********
- //显示已经连接到Hive服务器
- Connected to: Apache Hive (version 2.3.9)
- Driver: Hive JDBC (version 2.3.9)
- Transaction isolation: TRANSACTION_REPEATABLE_READ
- 0: jdbc:hive2://hadoop01.bgd01:10000>
-
- 操作数据仓库
- 现在可以像 CLI方式一样操作数据仓库命令.
- 查看数据仓库中的数据库
- 0: jdbc:hive2://hadoop01.bgd01:10000> show databases;
-
-
- 查看数据仓库中的表
- 0: jdbc:hive2://hadoop01.bgd01:10000> show tables;
-
- 查看数据仓库中的内置函数
- hive>show functions;
-
- 退出
- 0: jdbc:hive2://hadoop01.bgd01:10000>!exit
- 或
- 0: jdbc:hive2://hadoop01.bgd01:10000>!quit
十一、Sqoop数据转移工具部署
1、安装配置
- 解压安装
- tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /export/servers/
-
- 重命名为
- mv /export/servers/sqoop-1.4.6.bin__hadoop-2.0.4-alpha /export/servers/sqoop
-
- 复制hive的相关jar包
- cp $HIVE_HOME/lib/hive-common-1.2.2.jar /export/servers/sqoop-1.4.7/lib
- cp $HIVE_HOME/lib/hive-shims*.jar /export/servers/sqoop-1.4.7/lib
-
- 重命名生成 sqoop-env.sh 配置文件,添加Hadoop环境变量
- cd /export/servers/sqoop-1.4.7/conf
- mv sqoop-env.sh.template sqoop-env.sh
-
- 添加环境变量
- vi /etc/profile
- 添加如下2行:
- export SQOOP_HOME=/export/servers/sqoop
- export PATH=$PATH:$SQOOP_HOME/bin
-
- 刷新环境变量
- source /etc/profile
2、修改文件配置
(1)修改sqoop-env.sh文件
- cd /export/servers/conf
- cp sqoop-env.sh.template sqoop-env.sh
-
- 修改sqoop-env.sh配置文件,添加Hadoop环境变量,具体内容如下:
- export HADOOP_COMMON_HOME=/export/servers/hadoop-2.7.4
- export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.7.4
- export HIVE_HOME=/export/servers/hive
- export ZOOKEEPER_HOME=/export/servers/zookeeper
- export ZOOCFGDIR=/export/servers/zookeeper/conf
-
- 复制 mysql 数据库的 JDBC 驱动包到 /export/servers/sqoop/lib 下
- mysql-connector-java-8.0.20.jar
-
- 验证安装是否成功
- sqoop version
3、分发文件
- scp -r /export/servers/sqoop/ hadoop02.bgd01:/export/servers/
- scp -r /export/servers/sqoop/ hadoop03.bgd01:/export/servers/
-
- scp -r /etc/profile hadoop02.bgd01:/etc/
- scp -r /etc/profile hadoop03.bgd01:/etc/
-
- 在hadoop02、hadoop03上刷新环境变量
- source /etc/profile
十二、Flume日志采集系统部署
1、安装配置
- 解压
- 进入目录/export/software/,执行命令
- tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /export/servers/
-
- 将安装目录apache-flume-1.8.0-bin 重命名为flume
- 进入目录/export/servers/,执行命令
- mv apache-flume-1.8.0-bin flume
2、文件配置
- 配置Flume环境
- 1、配置 flume-env.sh
- cd /export/servers/flume/conf
- cp flume-env.sh.template flume-env.sh
-
- vi flume-env.sh #编辑文件,增加如下行
- export JAVA_HOME=/export/servers/jdk
-
- 2、配置 /etc/profile
- vi /etc/profile #编辑文件,增加如下行
- export FLUME_HOME=/export/servers/flume
- export PATH=$PATH:$FLUME_HOME/bin
3、分发文件
- 在hadoop01上,将Flume同步到hadoop02、hadoop03上
- scp -r /export/servers/flume hadoop02.bgd01:/export/servers/
- scp -r /export/servers/flume hadoop03.bgd01:/export/servers/
-
- scp /etc/profile hadoop02.bgd01:/etc/profile
- scp /etc/profile hadoop03.bgd01:/etc/profile
-
- 分别在hadoop02、hadoop03上执行如下命令,立即刷新配置
- source /etc/profile
十三、Azkban工作流管理器部署
1、解压安装
- 在/export/software目录下对 Azkaban 的源文件进行解压
- tar -zxvf azkaban-3.50.0.tar.gz
-
- 进入解压后的Azkaban目录,进行编译
- cd azkaban-3.50.0
- ./gradlew build -x test
-
- 这里需要注意,上述指令会跳过 Azkaban 源文件的测试类部分进行自动编译构建(使用 ./gradlew mild 指令会对整个源文件全部进行编译),整个过程需要联网,如果网络不好会非常耗时连接中断时需要多次重试。执行上述指令进行编译,经过一段时间后必须看到 BUILD SUCCESSFUL 信息才可确定 Azkaban 源文件编译成功,
-
- 编译成功后 压缩包在各个组件的build/distributions目录里:
- azkaban-db/build/distributions
- azkaban-web-server/build/distributions
- azkaban-exec-server/build/distributions
- azkaban-solo-server/build/distributions
-
- 分别在/export/servers/ 目录下创建 azkaban 子目录
- mkdir -p /export/servers/azkaban
-
- 解压安装包
- 执行如下命令,将上面4个安装包解压到 /export/servers/azkaban/ 目录下
- cd /export/servers/azkaban/
-
- tar -zxvf /export/software/azkaban-3.50.0/azkaban-db/build/distributions/azkaban-db-0.1.0-SNAPSHOT.tar.gz -C ./
-
- tar -zxvf /export/software/azkaban-3.50.0/azkaban-web-server/build/distributions/azkaban-web-server-0.1.0-SNAPSHOT.tar.gz -C ./
-
- tar -zxvf /export/software/azkaban-3.50.0/azkaban-exec-server/build/distributions/azkaban-exec-server-0.1.0-SNAPSHOT.tar.gz -C ./
-
- tar -zxvf /export/software/azkaban-3.50.0/azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C ./
-
- 修改目录名称
- 为了以后操作方便,将解压安装包产生的4个目录名字中的版本号去掉。
- mv azkaban-db-0.1.0-SNAPSHOT azkaban-db
- mv azkaban-solo-server-0.1.0-SNAPSHOT azkaban-solo-server
- mv azkaban-exec-server-0.1.0-SNAPSHOT azkaban-exec-server
- mv azkaban-web-server-0.1.0-SNAPSHOT azkaban-web-server
2、数据库配置
- 创建Azkaban数据库及用户
- mysql -uroot -p123456
- MariaDB>CREATE DATABASE azkaban;
-
- Azkaban数据库表初始化
- 连接azkaban数据库
- MariaDB>use azkaban;
-
- 创建数据库表
- MariaDB[azkaban]>source /export/servers/azkaban/azkaban-db/create-all-sql-0.1.0-SNAPSHOT.sql;
-
- 显示创建的所有对象
- MariaDB[azkaban]>show tables
-
- 这时可以看到刚才创建的所有azkaban数据库表。
-
- 退出数据库
- MariaDB[azkaban]>quit
3、Azkaban Web 服务配置
(1)SSL创建
- 在目录 /export/servers/azkaban/azkaban-web-server 下执行如下命令,生成 SSL 密匙库文件
- keytool -keystore keystore -alias jetty -genkey -keyalg RSA
-
- 输入密钥库口令: 123456
- 再次输入新口令: 123456
- 您的名字与姓氏是什么?
- [Unknown]: 回车
- 您的组织单位名称是什么?
- [Unknown]: 回车
- 您的组织名称是什么?
- [Unknown]: 回车
- 您所在的城市或区域名称是什么?
- [Unknown]: 回车
- 您所在的省/市/自治区名称是什么?
- [Unknown]: 回车
- 该单位的双字母国家/地区代码是什么?
- [Unknown]: cn
- CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown是否正确?
- [否]: 是
-
- 输入 <jetty> 的密钥口令
- (如果和密钥库口令相同, 按回车):
-
- Warning:
- JKS 密钥库使用专用格式。建议使用 "keytool -importkeystore -srckeystore keystore -destkeystore keystore -deststoretype pkcs12" 迁移到行业标准格式 PKCS12。
(2)Azkaban Web 服务器配置
- 进入azkaban-web-server目录
- cd /export/servers/azkaban/azkaban-web-server
-
- 创建子目录 extlib、logs
- mkdir extlib
- mkdir logs
-
- 复制子目录 plugins、conf
- cp -r /export/servers/azkaban/azkaban-solo-server/plugins ./
- cp -r /export/servers/azkaban/azkaban-solo-server/conf ./
(3)配置azkaban.properties
- cd /export/servers/azkaban/azkaban-web-server/conf
- vi azkaban.properties
-
- # Azkaban Personalization Settings
- azkaban.name=Test
- azkaban.label=My Local Azkaban
- azkaban.color=#FF3601
- azkaban.default.servlet.path=/index
- web.resource.dir=/export/servers/azkaban/azkaban-web-server/web/
- default.timezone.id=Asia/Shanghai
- # Azkaban UserManager class
- user.manager.class=azkaban.user.XmlUserManager
- user.manager.xml.file=/export/servers/azkaban/azkaban-web-server/conf/azkaban-users.xml
- # Loader for projects
- executor.global.properties=/export/servers/azkaban/azkaban-web-server/conf/global.properties
- azkaban.project.dir=projects
- database.type=MariaDB
- mysql.port=3306
- mysql.host=192.168.8.201
- mysql.database=azkaban
- mysql.user=root
- mysql.password=123456
- mysql.numconnections=100
- h2.path=./h2
- h2.create.tables=true
- # Velocity dev mode
- velocity.dev.mode=false
- # Azkaban Jetty server properties.
- jetty.use.ssl=true
- jetty.maxThreads=25
- jetty.port=8081
- jetty.ssl.port=8443
- jetty.keystore=keystore
- jetty.password=123456
- jetty.keypassword=123456
- jetty.truststore=keystore
- jetty.trustpassword=123456
- # Azkaban Executor settings
- executor.port=12321
- # mail settings
- mail.sender=
- mail.host=
- # User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
- # enduser -> myazkabanhost:443 -> proxy -> localhost:8081
- # when this parameters set then these parameters are used to generate email links.
- # if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
- # azkaban.webserver.external_hostname=myazkabanhost.com
- # azkaban.webserver.external_ssl_port=443
- # azkaban.webserver.external_port=8081
- job.failure.email=
- job.success.email=
- lockdown.create.projects=false
- cache.directory=cache
- # JMX stats
- jetty.connector.stats=true
- executor.connector.stats=true
- # Azkaban plugin settings
- azkaban.jobtype.plugin.dir=/export/servers/azkaban/azkaban-web-server/plugins/jobtypes
(4)配置azkaban-users.xml
- <azkaban-users>
- <user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
- <user password="metrics" roles="metrics" username="metrics"/>
- <user password="admin" roles="metrics,admin" username="admin"/>
- <role name="admin" permissions="ADMIN"/>
- <role name="metrics" permissions="METRICS"/>
- </azkaban-users>
(5)配置log4j.properties
- vi log4j.properties
-
- 具体配置如下
- log4j.rootLogger=INFO, Console
- log4j.logger.azkaban=INFO, server
- log4j.appender.server=org.apache.log4j.RollingFileAppender
- log4j.appender.server.layout=org.apache.log4j.PatternLayout
- log4j.appender.server.File=logs/azkaban-webserver.log
- log4j.appender.server.layout.ConversionPattern=%d{yyyy/MM/dd HH:mm:ss.SSS Z} %5p [%c{1}] [%t] [Azkaban] %m%n
- log4j.appender.server.MaxFileSize=102400MB
- log4j.appender.server.MaxBackupIndex=2
- log4j.appender.Console=org.apache.log4j.ConsoleAppender
- log4j.appender.Console.layout=org.apache.log4j.PatternLayout
- log4j.appender.Console.layout.ConversionPattern=%d{yyyy/MM/dd HH:mm:ss.SSS Z} %5p [%c{1}] [%t] [Azkaban] %m%n
4、azkaban-exec-server配置
- 创建子目录 logs
- mkdir logs
-
- 这里可以从刚配置好azkaban-web-server下将conf、plugins、extlib拷贝过来
- cd /export/servers/azkaban/azkaban-exec-server/
-
- cp -r /export/servers/azkaban/azkaban-web-server/conf/ ./
- cp -r /export/servers/azkaban/azkaban-web-server/plugins/ ./
- cp -r /export/servers/azkaban/azkaban-web-server/extlib/ ./
-
- 配置azkaban.properties
- cd /export/servers/azkaban/azkaban-exec-server/conf
- vi azkaban.properties
-
- 这里只需要将jetty移除,参照以下代码
- # Azkaban Jetty server properties.
- jetty.use.ssl=false
- jetty.maxThreads=25
- jetty.port=8081
-
- 然后在末尾添加以下代码
- # Azkaban Executor settings
- executor.port=12321
- executor.maxThreads=50
- executor.flow.threads=30
- azkaban.executor.runtimeProps.override.eager=false
-
-
- 完整配置如下
- # Azkaban Personalization Settings
- azkaban.name=Test
- azkaban.label=My Local Azkaban
- azkaban.color=#FF3601
- azkaban.default.servlet.path=/index
- web.resource.dir=/export/servers/azkaban/azkaban-web-server/web/
- default.timezone.id=Asia/Shanghai
- # Azkaban UserManager class
- user.manager.class=azkaban.user.XmlUserManager
- user.manager.xml.file=/export/servers/azkaban/azkaban-exec-server/conf/azkaban-users.xml
- # Loader for projects
- executor.global.properties=/export/servers/azkaban/azkaban-exec-server/conf/global.properties
- azkaban.project.dir=projects
- database.type=MariaDB
- mysql.port=3306
- mysql.host=localhost
- mysql.database=azkaban
- mysql.user=root
- mysql.password=123456
- mysql.numconnections=100
- # Velocity dev mode
- velocity.dev.mode=false
- # Azkaban Jetty server properties.
- jetty.use.ssl=false
- jetty.maxThreads=25
- jetty.port=8081
- # Azkaban Executor settings
- executor.port=12321
- # mail settings
- mail.sender=
- mail.host=
- # User facing web server configurations used to construct the user facing server URLs. They are useful when there is a reverse proxy between Azkaban web servers and users.
- # enduser -> myazkabanhost:443 -> proxy -> localhost:8081
- # when this parameters set then these parameters are used to generate email links.
- # if these parameters are not set then jetty.hostname, and jetty.port(if ssl configured jetty.ssl.port) are used.
- # azkaban.webserver.external_hostname=myazkabanhost.com
- # azkaban.webserver.external_ssl_port=443
- # azkaban.webserver.external_port=8081
- job.failure.email=
- job.success.email=
- lockdown.create.projects=false
- cache.directory=cache
- # JMX stats
- jetty.connector.stats=true
- executor.connector.stats=true
- # Azkaban plugin settings
- azkaban.jobtype.plugin.dir=/export/servers/azkaban/azkaban-exec-server/plugins/jobtypes
- # Azkaban Executor settings
- executor.port=12321
- executor.maxThreads=50
- executor.flow.threads=30
- azkaban.executor.runtimeProps.override.eager=false
5、Azkzban启动测试
- 启动azkaban-exec-server
- cd /export/servers/azkaban/azkaban-exec-server
- 启动
- bin/start-exec.sh
- 关闭
- bin/shutdown-exec.sh
-
- 启动azkaban-web-server
- cd /export/servers/azkaban/azkaban-web-server
- 启动
- bin/start-web.sh
- 关闭
- bin/shutdown-web.sh
-
- 访问Azkaban UI
- https://localhost:8443/
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小小林熬夜学编程/article/detail/559990
推荐阅读
相关标签

