
- 1由世界第一个AI软件工程师Devin引发的热潮背后----程序员到底会不会被代替?AI发展至如今是否初衷已变?_国外devin
- 2云原生Docker系列 | Docker私有镜像仓库&公有镜像仓库使用_docker 阿里云镜像仓库
- 3TN2339: 使用 Xcode 命令行构建的常见问题_xcode-select --switch
- 4迁移学习之VGG16和VGG19_vgg19的输出结果是什么
- 5使用免费开源AI平台:OCR识别抖音短视频及网络图片中文字内容(可本地部署)_开源多模态 ocr
- 6一线互联网大厂面试真题系统收录!威力加强版
- 7Codeforces Round 887 Div.3 A~D
- 8基于Python的全国主要城市天气数据可视化大屏系统_动态天气可视化案例
- 9Python库学习(十四):ORM框架-SQLAlchemy_sqlalchemy orm
- 10git子模块使用之git submodule与 git subtree比较_git submodule subtree 对比
进击大数据系列(八)Hadoop 通用计算引擎 Spark
赞
踩
点击下方名片,设为星标!
回复“1024”获取2TB学习资源!
前面介绍了 Hadoop 架构基石 HDFS、统一资源管理和调度平台 YARN、分布式计算框架 MapReduce、数据仓库 Hive等相关的知识点,今天我将详细的为大家介绍 大数据 Hadoop 计算引擎Spark 相关知识,希望大家能够从中收获多多!如有帮助,请点在看、转发支持一波!!!
Spark 概述
Spark 是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。那到底是什么呢?可能很多人还不是太理解,通俗讲就是可以分布式处理大量集数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。 Spark 也拥有十分庞大的生态系统,支持多种框架的集成,有助于将它们扩展到数千台机器。
Spark 也拥有十分庞大的生态系统,支持多种框架的集成,有助于将它们扩展到数千台机器。
为什么使用Spark
Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,而且比MapReduce平均快10倍以上的计算速度;因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
Spark 优势
速度快
基于内存数据处理, 比MR快100个数量级以上(逻辑回归算法测试)
基于硬盘数据处理,比MR快10个数量级以上
易用性
支持Java、 Scala、 Python、 R语言
交互式shell方便开发测试
通用性
一栈式解决方案:批处理、交互式查询、实时流处理、图计算及机器学习
多种运行模式
YARN、 Mesos、 EC2、 Kubernetes、 Standalone(独立模式)、 Local(本地模式)
Spark 5 大核心模块
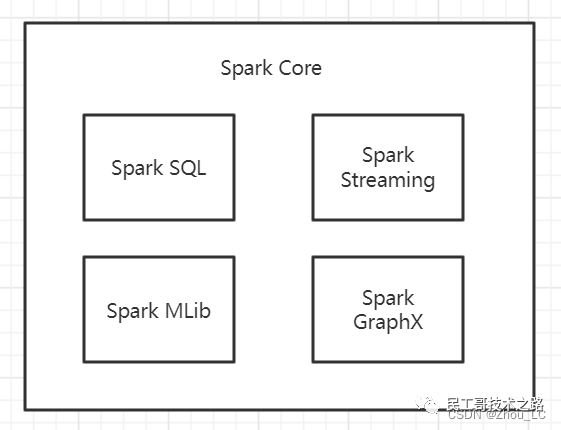
Spark Core
核心组件,分布式计算引擎。包含了 Spark 最核心与基础的功能,为其他 Spark 功能模块提供了核心层的支撑,可类比 Spring 框架中的 Spring Core。
SparkSQL
高性能的基于Hadoop的SQL解决方案。官方文档的介绍如下图,Spark SQL 适用于结构化表和非结构化数据的查询,并且可以在运行时自适配执行计划,支持 ANSI SQL(即标准的结构化查询语言)。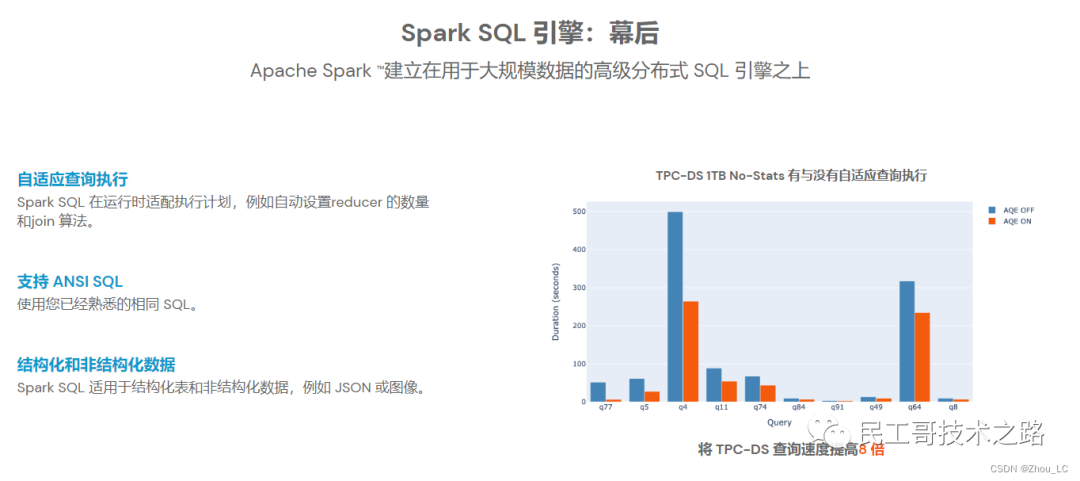
Spark Streaming
可以实现高吞吐量、具备容错机制的准实时流处理系统。是 Spark 平台上针对实时数据进行流式计算的组件,而流式数据指的是实时或接近实时的时效性处理的大数据流,常见的流式数据处理使用Spark、Storm和Samza等框架。
Spark GraphX
分布式图处理框架。是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。
Spark MLlib
构建在Spark_上的分布式机器学习库,是 Spark 面向图计算提供的框架与算法库。
Spark 架构核心组件
Application
说明:建立在Spark.上的用户程序,包括Driver代码和运行在集群各节点Executor中的代码。
Driver program
说明:驱动程序,Application中的main函数并创建SparkContext。
Cluster Manager
说明:在集群(Standalone、 Mesos、YARN) . 上获取资源的外部服务。
Worker Node
说明:集群中任何可以运行Application代码的节点。
Executor
说明:某个Application运行在worker节点上的一个进程 就像jdk的运行环境。
Task
说明:被送到某个Executor上的工作单元。
Job
说明:包含多个Task组成的并行计算,往往由Spark Action触发生成,一个Application中往往会产生多个Job。
Stage
说明:每个Job会被拆分成多组Task,作为一个TaskSet, 其名称为Stage 有一个或多个task任务。
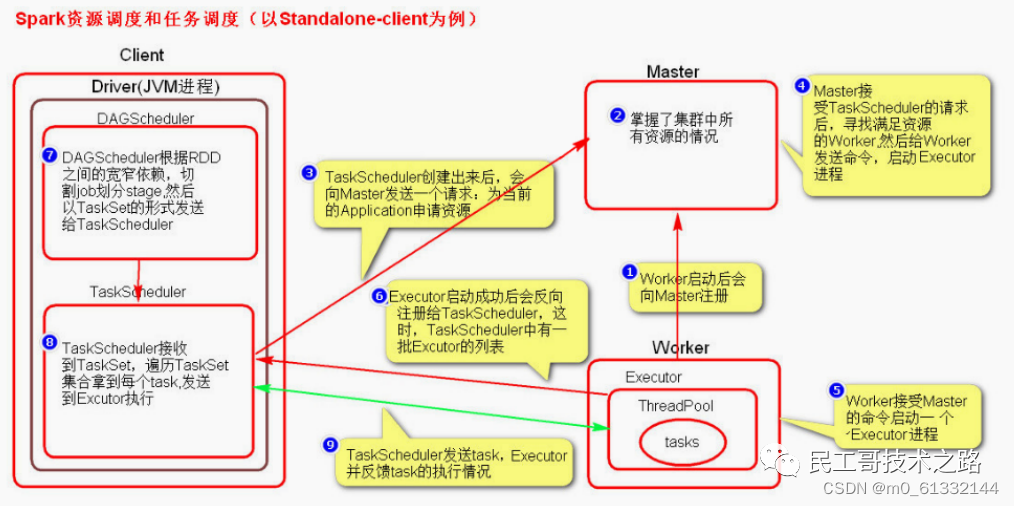
Spark资源调度和任务调度
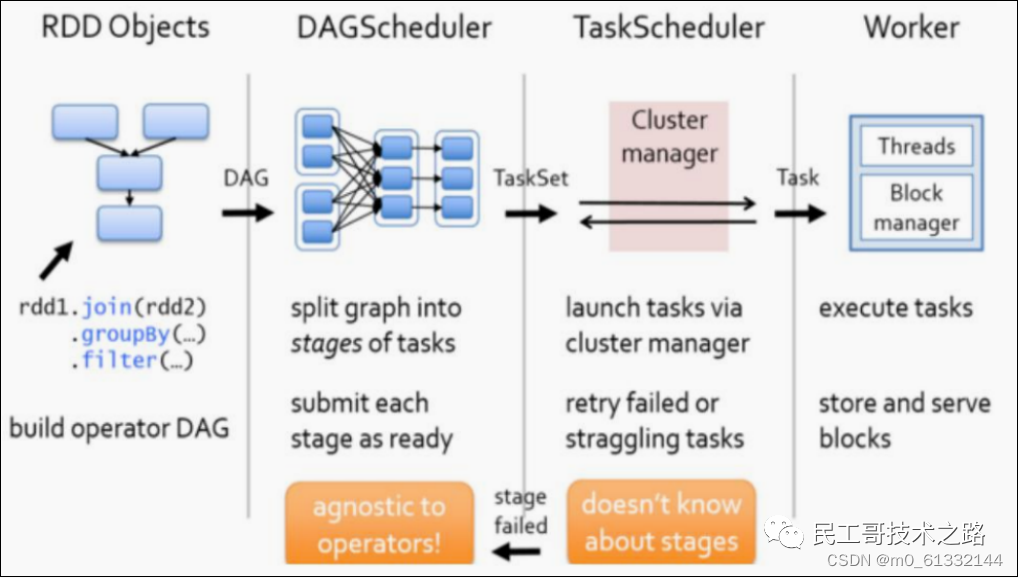
调度流程
启动集群后,Worker 节点会向 Master 节点汇报资源情况,Master 掌握了集群资源情况。当 Spark 提交一个 Application 后,根据 RDD 之间的依赖关系将 Application 形成一个 DAG 有向无环图。
任务提交后,Spark 会在 Driver 端创建两个对象:
DAGScheduler
TaskScheduler
DAGScheduler 是任务调度的高层调度器,是一个对象。DAGScheduler 的主要作用就是将 DAG 根据 RDD 之间的宽窄依赖关系划分为一个个的 Stage ,然后将这些 Stage 以 TaskSet 的形式提交给 TaskScheduler ( TaskScheduler 是任务调度的低层调度器,这里 TaskSet 其实就是一个集合,里面封装的就是一个个的 task 任务,也就是 stage 中 的并行的 task 任务)。
TaskSchedule会遍历 TaskSet 集合,拿到每个 task 后会将 task 发送到 Executor 中去执行(其 实就是发送到 Executor 中的线程池 ThreadPool 去执行)。task 在 Executor 线程池中的运行情况会向 TaskScheduler 反馈,当 task 执行失败时,则由 TaskScheduler 负责重试,将 task 重新发送给 Executor 去执行,默认重试3次。如果重试3次依 然失败,那么这个 task 所在的 stage 就失败了。
stage 失败了则由 DAGScheduler 来负责重试,重新发送 TaskSet 到 TaskScheduler ,Stage 默认重试4次。如果重试4次以后依然失败,那么这个 job 就失败了。job 失败了,Application 就 失败了。TaskScheduler 不仅能重试失败的 task ,还会重试 straggling (落后,缓慢) task( 也就是执 行速度比其他task慢太多的task )。如果有运行缓慢的 task 那么 TaskScheduler 会启动一个新的task 来与这个运行缓慢的 task 执行相同的处理逻辑。两个 task 哪个先执行完,就以哪个 task 的执行结果为准。这就是 Spark 的推测执行机制。在 Spark 中推测执行默认是关闭的。推测执行 可以通过 spark.speculation 属性来配置。
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
流程图解
spark 安装部署
hadoop 安装参考文章:Hadoop 安装实战操作,hdfs 安装参考文章:分布式文件系统 HDFS,YARN 安装参考文章:统一资源管理和调度平台 YARN ,安装完成后,统一启动服务,相关的操作这里不再赘述了。
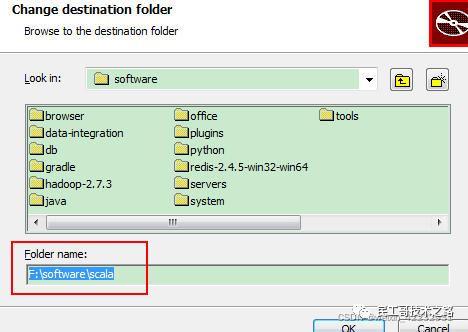
安装 scala
不能安装在带有中文或者空格的目录下面,不然会报错,scala命令找不到。
- 1.安装jdk并配置环境变量
- 2.安装scala,下一步直到结束
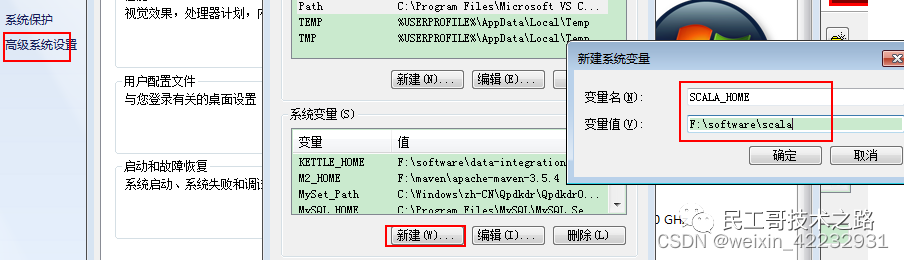
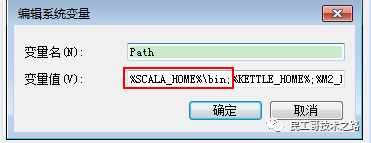
- 3.配置环境变量
-
- SCALA_HOME=F:\software\Scala
- PATH=%SCALA_HOME%\bin
验证
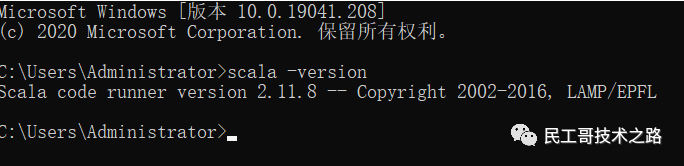 出现上述效果,即scala安装成功。
出现上述效果,即scala安装成功。
windows上安装spark
- 1.解压spark-2.2.0-bin-hadoop2.7.tgz
- 2.执行spark-shell2.cmd
- 3.执行命令:sc.textFile("C:\\real_win10\\data.txt").flatMap(_.split("\\s+")).map((_,1)).reduceByKey(_+_).foreach(println)
- 4. http://10.31.153.47:4040


spark 三种运行模式介绍
Local 模式
Local模式即单机模式,如果在命令语句中不加任何配置,则默认是Local模式,在本地运行。这也是部署、设置最简单的一种模式
安装scala环境
- tar -zxvf scala-2.11.8.tgz -C -C /usr/local/
- mv scala-2.11.8 scala
- export SCALA_HOME=/usr/local/scala
- export PATH=$SCALA_HOME/bin:$PATH
安装local模式
- tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/
- cd /usr/local/
- mv spark-2.4.5-bin-hadoop2.7 spark-local
- bin/spark-shell
local模式提交应用
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master local[2] \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
- 1) --class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
- 2) --master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟CPU 核数量
- 3) spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱
- 们自己打的 jar 包
- 4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
Standalone
Standalone是Spark自身实现的资源调度框架。如果我们只使用Spark进行大数据计算,不使用其他的计算框架(如MapReduce或者Storm)时,就采用Standalone模式。
local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的 独立部署(Standalone)模式。Spark 的Standalone 模式体现了经典的master-slave 模式。
集群规划
解压缩文件(默认三台机器都安装了scala,hadoop)
- tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/
- cd /usr/local/
- mv spark-2.4.5-bin-hadoop2.7 spark-standalone
修改配置文件
进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves。
mv slaves.template slaves修改 slaves 文件,添加work 节点
- zrclass01
- zrclass02
- zrclass03
修改 spark-env.sh.template 文件名为 spark-env.sh。
mv spark-env.sh.template spark-env.sh修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点。
- export JAVA_HOME=/usr/local/jdk
- SPARK_MASTER_HOST=zrclass01
- SPARK_MASTER_PORT=7077
注意:7077 端口,相当于hadoop3 内部通信的 8020 端口,此处的端口需要确认自己的Hadoop 配置。
分发 spark-standalone 目录
- scp -r spark-standalone zrclass02:$PWD
- scp -r spark-standalone zrclass03:$PWD
启动集群
在主节点zrclass01上执行:
sbin/start-all.sh- ================zrclass01================
- 3330 Jps
- 3238 Worker
- 3163 Master
- ================zrclass02================
- 2966 Jps
- 2908 Worker
- ================zrclass03================
- 2978 Worker
- 3036 Jps
standalone提交应用
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://linux1:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
- 1) --class 表示要执行程序的主类
- 2) --master spark://linux1:7077 独立部署模式,连接到Spark 集群
- 3) spark-examples_2.12-3.0.0.jar 运行类所在的 jar 包
- 4) 数字 10 表示程序的入口参数,用于设定当前应用的任务数量
执行任务时,会产生多个 Java 进程。执行任务时,默认采用服务器集群节点的总核数,每个节点内存 1024M。
配置历史服务
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以 ,开发时都配置历史服务器记录任务运行情况。
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf。
mv spark-defaults.conf.template spark-defaults.conf修改 spark-default.conf 文件,配置日志存储路径。
- spark.eventLog.enabled true
- spark.eventLog.dir hdfs://zrclass01:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的directory 目录需要提前存在。
- sbin/start-dfs.sh
- hadoop fs -mkdir /directory
修改 spark-env.sh 文件, 添加日志配置
- export SPARK_HISTORY_OPTS="
- -Dspark.history.ui.port=18080
- -Dspark.history.fs.logDirectory=hdfs://zrclass01:8020/directory
- -Dspark.history.retainedApplications=30"
参数说明
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
分发配置文件
- scp conf zrclass02:$PWD
- scp conf zrclass03:$PWD
重新启动集群和历史服务
- sbin/start-all.sh
- sbin/start-history-server.sh
重新执行任务
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://linux1:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
查看历史服务
查看历史服务:http://zrclass01:18080高可用配置
所谓的高可用是因为当前集群中的 Master 节点只有一个,所以会存在单点故障问题。所以为了解决单点故障问题,需要在集群中配置多个 Master 节点,一旦处于活动状态的 Master 发生故障时,由备用 Master 提供服务,保证作业可以继续执行。这里的高可用一般采用 Zookeeper 设置。 停止集群
停止集群
sbin/stop-all.sh启动Zookeeper
zkServer.sh start修改 spark-env.sh 文件添加如下配置
- 注释如下内容:
- #SPARK_MASTER_HOST=linux1
- #SPARK_MASTER_PORT=7077
- 添加如下内容:
- #Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自
- 定义,访问 UI 监控页面时请注意
- SPARK_MASTER_WEBUI_PORT=8989
- export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
- -Dspark.deploy.zookeeper.url=zrclass01,zrclass02,zrclass03
- -Dspark.deploy.zookeeper.dir=/spark"
分发配置文件
- scp conf zrclass02:$PWD
- scp conf zrclass03:$PWD
启动集群
sbin/start-all.sh启动 zrclass02的单独 Master 节点,此时 zrclass02节点 Master 状态处于备用状态
- #webui地址:zrclass02:8989
-
- [root@zrclass02 spark-standalone]# sbin/start-master.sh
提交应用到高可用集群
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master spark://linux1:7077,linux2:7077 \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
停止 zrclass01的 Master 资源监控进程。
查看 zrclass02的 Master 资源监控 Web UI,稍等一段时间后,zrclass02 节点的 Master 状态提升为活动状态。
zrclass02:8989Yarn模式
独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这 种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主 要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。所以接下来我们来学习在强大的Yarn 环境 下 Spark 是如何工作的(其实是因为在国内工作中,Yarn 使用的非常多)。
解压缩文件(默认三台机器都安装了scala,hadoop)
- tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /usr/local/
- cd /usr/local/
- mv spark-2.4.5-bin-hadoop2.7 spark-yarn
修改配置文件
- 修改 hadoop 配置文件/usr/local/hadoop/etc/hadoop/yarn-site.xml, 并分发
- <!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
- 是 true -->
- <property>
- <name>yarn.nodemanager.pmem-check-enabled</name>
- <value>false</value>
- </property>
- <!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
- 是 true -->
- <property>
- <name>yarn.nodemanager.vmem-check-enabled</name>
- <value>false</value>
- </property>
修改 conf/spark-env.sh,添加 JAVA_HOME 和 YARN_CONF_DIR 配置
- mv spark-env.sh.template spark-env.sh
-
- export JAVA_HOME=/usr/local/jdk
- YARN_CONF_DIR=/usr/local/hadoop/etc/hadoop
启动HDFS 以及YARN集群
提交应用
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master yarn \
- --deploy-mode cluster \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
查看 http://zrclass02:8088 页面,点击History,查看历史页面。更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
配置历史服务
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以 ,开发时都配置历史服务器记录任务运行情况。
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf修改 spark-default.conf 文件,配置日志存储路径
- spark.eventLog.enabled true
- spark.eventLog.dir hdfs://zrclass01:8020/directory
注意:需要启动 hadoop 集群,HDFS 上的directory 目录需要提前存在。
- sbin/start-dfs.sh
- hadoop fs -mkdir /directory
修改 spark-env.sh 文件, 添加日志配置
- export SPARK_HISTORY_OPTS="
- -Dspark.history.ui.port=18080
- -Dspark.history.fs.logDirectory=hdfs://zrclass01:8020/directory
- -Dspark.history.retainedApplications=30"
参数说明
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
修改 spark-defaults.conf
- spark.yarn.historyServer.address=zrclass01:18080
- spark.history.ui.port=18080
重新启动集群和历史服务
- sbin/start-all.sh
- sbin/start-history-server.sh
重新执行任务
- bin/spark-submit \
- --class org.apache.spark.examples.SparkPi \
- --master yarn \
- --deploy-mode client \
- ./examples/jars/spark-examples_2.12-3.0.0.jar \
- 10
查看webui
Web页面查看日志:http://zrclass02:8088
Spark SQL
DataFrame
可以简单的理解DataFrame为RDD+schema元信息
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似传统数据库的二维表格
DataFrame带有schema元信息,DataFrame所表示的数据集每一列都有名称和类型,DataFrame可以从很多数据源构建对象,如已存在的RDD、结构化文件、外部数据库、Hive表。
RDD可以把内部元素当成java对象,DataFrame内部是一个个Row对象,表示一行行数据
左侧的
RDD[Person]虽然以Person为类型参数,但Spark框架本身不了解Person类的内部结构。右侧的DataFrame却提供了详细的结构信息,DataFrame多了数据的结构信息,即schema。
DataSet
DataSet是分布式的数据集合,DataSet提供了强类型支持,在RDD的每行数据加了类型约束
Dataset是在spark1.6中新添加的接口。它集中了RDD的优点(强类型和可以使用强大的lambda函数)以及使用了sparkSQL优化的执行引擎。
DataFrame(在2.X之后)实际上是DataSet的一个特例,即对Dataset的元素为Row时起了一个别名
DSL操作
action
show以表格的形式在输出中展示 jdbcDF 中的数据,类似于
select * from spark_sql_test的功能。功能
first 获取第一行记录
head 获取第一行记录, head(n: Int) 获取前n行记录
take(n: Int) 获取前n行数据
takeAsList(n: Int) 获取前n行数据,并以 List 的形式展现
show只显示前20条记录
show(numRows: Int) 显示 numRows 条
show(truncate: Boolean) 是否最多只显示20个字符,默认为 true 。
show(numRows: Int, truncate: Boolean) 综合前面的显示记录条数,以及对过长字符串的显示格式。
collect方法会将 jdbcDF 中的所有数据都获取到,并返回一个 Array 对象。
collectAsList:获取所有数据到List
describe(cols: String*):获取指定字段的统计信息
first, head, take, takeAsList:获取若干行记录
查询
where(conditionExpr: String)
SQL语言中where关键字后的条件,可以用 and 和 or 。得到DataFrame类型的返回结果。
filter:根据字段进行筛选
得到DataFrame类型的返回结果。和 where 使用条件相同
select:获取指定字段值
根据传入的 String 类型字段名,获取指定字段的值,以DataFrame类型返回
selectExpr :可以对指定字段进行特殊处理
可以直接对指定字段调用UDF函数,或者指定别名等。传入 String 类型参数,得到DataFrame对象。
col:获取指定字段
只能获取一个字段,返回对象为Column类型。
apply:获取指定字段
只能获取一个字段,返回对象为Column类型
drop:去除指定字段,保留其他字段
返回一个新的DataFrame对象,其中不包含去除的字段,一次只能去除一个字段。
Limit
limit方法获取指定DataFrame的前n行记录,得到一个新的DataFrame对象。
排序
orderBy 和 sort :按指定字段排序,默认为升序
按指定字段排序。加个 - 表示降序排序。sort 和 orderBy 使用方法相同
- jdbcDF.orderBy(- jdbcDF("c4")).show(false)
- jdbcDF.orderBy(jdbcDF("c4").desc).show(false)
sortWithinPartitions
和上面的 sort 方法功能类似,区别在于 sortWithinPartitions 方法返回的是按Partition排好序的DataFrame对象。
组函数
groupBy :根据字段进行 group by 操作
groupBy 方法有两种调用方式,可以传入 String 类型的字段名,也可传入 Column 类型的对象。
cube 和 rollup :group by的扩展
功能类似于 SQL 中的 group by cube/rollup。
groupedData对象
该方法得到的是 GroupedData 类型对象,在 GroupedData 的API中提供了 group by 之后的操作。
去重
distinct :返回一个不包含重复记录的DataFrame
返回当前DataFrame中不重复的Row记录。该方法和接下来的 dropDuplicates() 方法不传入指定字段时的结果相同。
dropDuplicates :根据指定字段去重
根据指定字段去重。类似于 select distinct a, b 操作。
聚合
聚合操作调用的是 agg 方法,该方法有多种调用方式。一般与 groupBy 方法配合使用。
以下示例其中最简单直观的一种用法,对 id 字段求最大值,对 c4 字段求和。
jdbcDF.agg("id" -> "max", "c4" -> "sum")
Union
unionAll 方法:对两个DataFrame进行组合 ,类似于 SQL 中的 UNION ALL 操作。
Join
笛卡尔积
joinDF1.join(joinDF2)
using一个字段形式
下面这种join类似于
a join b using column1的形式,需要两个DataFrame中有相同的一个列名joinDF1.join(joinDF2, "id")using 多个字段形式
上面这种 using 一个字段的情况外,还可以 using 多个字段
save
save可以将data数据保存到指定的区域
dataFrame.write.format("json").mode(SaveMode.Overwrite).save()更多关于大数据 Hadoop系列的学习文章,请参阅:进击大数据系列,本系列持续更新中。
参考链接:https://blog.csdn.net/zp17834994071/article/
details/107650820 https://blog.csdn.net/wudidahuanggua
/article/details/127149855 https://blog.csdn.net/weixin_
42232931/article/details/123758752
读者专属技术群
构建高质量的技术交流社群,欢迎从事后端开发、运维技术进群(备注岗位),相互帮助,一起进步!请文明发言,主要以技术交流、内推、行业探讨为主。
广告人士勿入,切勿轻信私聊,防止被骗

推荐阅读 点击标题可跳转

PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!


