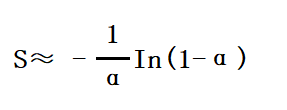- 1程序员必修课--sql思维举重训练
- 2数据库慢sql日志监控等_druid.stat.slowsqlmillis
- 3webview最全面详解(一)了解官方文档
- 4Node.js安装和配置初体验
- 5Hibernate:Caused by: java.lang.ClassNotFoundException: oracle.sql.BLOB
- 6C语言二叉树详解
- 7【云上探索实验室】快速入门AI 编程助手 Amazon CodeWhisperer ——码上学堂领学员招募_亚马逊云科技云上探索实验室
- 8Git-TortoiseGit完整配置流程_tortoisegit 配置流程
- 9推荐一款可私有部署的企业知识分享与团队协同软件_私有化部署 团队协同
- 10GPT1:Improving Language Understanding by Generative Pre-Training
c++数据结构:散列表(哈希)_设散列函数为h(k)=key % 13,散列表的地址空间
赞
踩
记录的存储位置与关键字之间存在对应关系,对应关系———hash函数
Loc(i)=H(keyi)
假设散列函数为H(key)=k
数据为:1 2 5 8 9 6 7

访问的话可以通过下标来访问数据。
优缺点:
- 查找效率高
- 空间效率低
冲突: 不同的关键码映射到同一个散列地址,key≠key2,但H(key1)=H(key2)。
设关键码为(25 21 39 9 23 11) H(k)=k%7
由于H(k)=k%7 ,所以地址编号为0-6
H(25)=25%7=4 H(21)=21%7=0 H(39)=39%7=4 H(9)=9%7=2
H(23)=23%7=2 H(11)=11%7=4

同义词:具有相同函数值的多个关键词
例如:上面的H(25 )H(39) H(11)具有相同的函数值
构造散列函数需要考虑的因素:
- 执行速度
- 关键词长度
- 散列表大小
- 关键词的分布情况
- 查找频率
元素集合的构造特性:
- n个数据原占用n个地址,希望散列表的地址空间尽可能小
- 尽量均匀地存放元素,以避免冲突
构建方法:
- 直接定址法
- 数字分析法
- 平方取中法
- 折叠法
- 除留余数法
- 随机数法
直接定址法:
H(key)=key 或 a*key+b (a和b为常数)
优点:以关键码key的线性函数数值的散列地址,不会发生冲突。
缺点:需要占用连续地址空间,空间效率低
除留余数法:
H(key)=key % p p<=表长
是最简单,也最常用的构造散列函数的方法,但关键的是得到p的值。
处理冲突的方法:
哈希函数可以减少冲突,但不能完全避免。
减少冲突的方法:
- 开放地址法
- 再哈希法
- 链地址法
- 建立一个公共溢出区
一:开放定址法:
有冲突时就去寻找下一个空的散列地址,只要散列表足够强大,空的散列地址总能找到,并将元素存入。
Hi=(H(key)+d)% m i=1,2,3,4...,k(k<=m-1) m为表长
找空的散列地址的方法:
- 线性探测法
- 二次探测法
- 伪随机探测法
线性探测法:
Hi=(H(key)+d)% m d为1,2,...,m-1 (m为散列表长度)
有冲突的话,就找到下一个地址,直到找到空地址存入

二次谈探测法:
Hi=(H(key)+d)% m d为1^2,-1^2,2^2,-2^1,...,q^2
有冲突的话,按照以上规则找到下一个地址,直到找到空地址存入

伪随机法:
Hi=(H(key)+d)% m d为一个随机数(1<=d<m)
二:链地址法:
相同散列地址的记录链成一单链表,m个散列地址就设m个单链表,用一个数组将m个单链表的表头指针存储起来,形成一个动态结构。

优缺点:
- 非同义词不会冲突,无聚集现象
- 链表上节点空间动态申请,更适合于表长不确定的情况
三:再哈希法
Hi=RHi(key) i=1,2,3,4,5,6,...k
RHi均是不同的哈希函数,即在同义词产生地址冲突时计算另一个哈希函数地址,直到冲突不再发生。不易发生聚集,但计算时间较长。
四:建立一个公共溢出区
创建一个溢出表来存放发生冲突的数据
哈希表的查找:
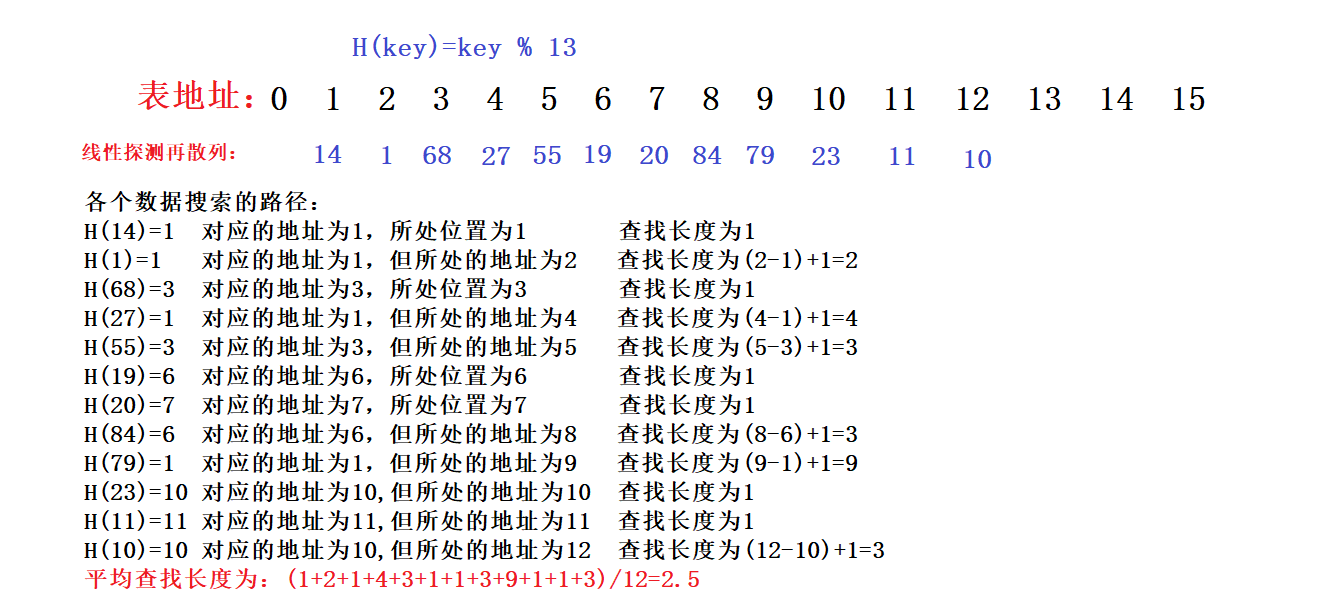
关键字为(19,14,23,1,68,20,84,27,55,11,10,79)
H(key)=key % 13 散列表m=16
线性探测再散列法:
链地址法 :

平均查找长度的比较:
α=表中填入的记录数/哈希表长度
查找成功的平均查找长度:

查找成功的平均查找长度为: