
- 1CVPR‘24:与任务无关的多模态数据也能提升Transformer性能|港中文&腾讯
- 2关于springboot+vue的excel导入导出_springboot vue实现excel导入导出功能
- 3WRF模型配置_!!! configure.wrf has been removed !!!
- 4DM8到KAFKA数据同步搭建
- 5你应该知道的C语言Cache命中率提升法_c语言 提高cache命中
- 6stream流各种写法_stream 基本写法
- 7分类算法系列⑥:随机森林_基于像素的随机森林分类原理和步骤
- 8力扣75.颜色分类(快速排序法,双指针法)_力扣怎么调用快速排序
- 9用Python写一个学生管理系统(附源码)_python管理系统
- 10NLP实践——LLM生成过程中防止重复循环_logits processor
StNet: Local and Global Spatial-Temporal Modeling for Action Recognition 论文阅读
赞
踩
文章信息:

原文链接:https://ojs.aaai.org/index.php/AAAI/article/view/4855
源码:https://github.com/hyperfraise/Pytorch-StNet/tree/master
发表于:AAAI 2019
Abstract
这篇论文探讨了视频中的空间-时间建模的最有效网络架构。与现有的CNN+RNN或纯粹基于3D卷积的方法不同,我们提出了一种新颖的空间-时间网络(StNet)架构,用于视频中的局部和全局建模。具体而言,StNet将N个连续的视频帧堆叠成一个超级图像,该图像具有3N个通道,并在超级图像上应用2D卷积来捕获局部空间-时间关系。为了建模全局空间-时间结构,我们在局部空间-时间特征图上应用时间卷积。具体来说,StNet提出了一个新颖的时间Xception块,它在视频的特征序列上分别使用通道级和时间级的卷积。在Kinetics数据集上进行的大量实验表明,我们的框架在动作识别方面优于几种最先进的方法,并且可以在识别准确性和模型复杂性之间取得令人满意的权衡。我们进一步展示了学习到的视频表示在UCF101数据集上的泛化性能。
1 Introduction

图1:局部信息足以区分“砌砖”和“砌石”,而全局空间-时间线索对于区分“叠牌”和“飞牌”是必要的。
视频中的动作识别已经引起了计算机视觉和机器学习社区的重视(Karpathy等人,2014年;Wang和Schmid,2013年;Wang、Qiao和Tang,2016年;Simonyan和Zisserman,2014年;Fernando等人,2015年;Wang等人,2016年;Qiu、Yao和Mei,2017年;Carreira和Zisserman,2017年;Shi等人,2017年;Zhang等人,2016年)。录制设备的普及使得我们远远超出了手动处理的能力。因此,开发自动视频理解算法以用于各种应用(如视频推荐、人类行为分析、视频监控等)变得非常重要。在这个任务中,局部和全局信息都很重要,如图1所示。例如,要识别“砌砖”和“砌石”,局部空间信息对于区分砖和石头至关重要;而要分类“叠牌”和“飞牌”,全局空间-时间线索是关键证据。
受深度网络在图像理解任务上取得的可喜成果(Ioffe和Szegedy,2015年;He等人,2016年;Szegedy等人,2017年)的启发,深度学习被应用到视频理解问题中。针对动作识别,主要探索了两个研究方向,即采用CNN+RNN架构进行视频序列建模(Donahue等人,2015年;Yue-Hei Ng等人,2015年),以及纯粹采用基于ConvNet的架构进行视频识别(Simonyan和Zisserman,2014年;Feichtenhofer、Pinz和Wildes,2016年;2017年;Wang等人,2016年;Tran等人,2015年;Carreira和Zisserman,2017年;Qiu、Yao和Mei,2017年)。
尽管取得了相当大的进展,但当前的动作识别方法在动作识别准确性方面仍然落后于人类表现。主要挑战在于从视频中提取具有区分性的空间-时间表示。对于CNN+RNN解决方案,前馈CNN部分用于空间建模,而时序建模部分,即LSTM(Hochreiter和Schmidhuber,1997年)或GRU(Cho等人,2014年),由于其循环架构,使得端到端优化变得非常困难。然而,分别训练CNN和RNN部分对于整合的空间-时间表示学习来说并不是最优的。
用于动作识别的卷积神经网络可以大致分为2D卷积网络和3D卷积网络两类。2D卷积架构(Simonyan和Zisserman,2014年;Wang等人,2016年)从采样的RGB帧中提取外观特征,仅利用局部空间信息而不是局部空间-时间信息。至于时间动态,它们简单地融合了从几个片段中获得的分类分数。虽然对几个片段的分类分数进行平均是直接而有效的,但可能不太有效地捕获时空信息。C3D(Tran等人,2015年)和I3D(Carreira和Zisserman,2017年)是典型的基于3D卷积的方法,它们同时建模了空间和时间结构,并实现了令人满意的识别性能。众所周知,与更深的网络相比,浅层网络在从大规模数据集中学习表示方面表现出较差的能力。当涉及到大规模人类动作识别时,一方面,将浅层2D卷积网络膨胀到它们的3D对应物可能不足以生成有区别的视频描述符;另一方面,深层2D卷积网络的3D版本将导致模型过大以及在训练和推理阶段的计算成本过高。
考虑到上述问题,我们提出了我们的新颖空间-时间网络(StNet)来解决大规模动作识别问题。首先,我们通过在由N个连续视频帧组成的3N通道超级图像上应用2D卷积来考虑局部空间-时间关系。因此,与在N个图像上进行3D卷积相比,局部空间-时间信息可以更有效地编码。其次,StNet在超级图像的特征图上插入时间卷积,以捕获它们之间的时间关系。局部空间-时间建模后接时间卷积可以逐步建立全局空间-时间关系,并且具有轻量级和计算友好的特点。第三,在StNet中,我们进一步使用我们提出的时间Xception块(TXB)而不是对几个片段的分数进行平均来编码时间动态。受到可分离的深度卷积的启发(Chollet,2017年),TXB以独立的通道级和时间级的1D卷积方式编码时间动态,以获得更小的模型尺寸和更高的计算效率。最后,TXB是基于卷积而不是循环架构的,因此可以轻松通过随机梯度下降(SGD)进行端到端的优化。
我们在新发布的大规模动作识别数据集Kinetics(Kay等人,2017年)上评估了提出的StNet框架。实验结果表明,StNet优于几种最先进的基于2D和3D卷积的解决方案,同时从FLOP数量的角度获得了更好的效率,并在识别准确性方面比其3D CNN对应物更有效。此外,我们将StNet学习到的表示转移到UCF101(Soomro、Zamir和Shah,2012年)数据集上,以验证其泛化能力。
2 Related Work
在文献中,基于视频的动作识别解决方案可以分为两类:使用手工特征的动作识别和使用深度卷积网络的动作识别。为了开发有效的空间-时间表示,研究人员提出了许多手工特征,如HOG3D(Klaser、Marszałek和Schmid,2008年)、SIFT3D(Scovanner、Ali和Shah,2007年)、MBH(Dalal、Triggs和Schmid,2006年)。目前,改进的密集轨迹(Wang和Schmid,2013年)是手工特征中的最先进方法。尽管其表现良好,但这种手工特征设计用于局部空间-时间描述,难以捕获语义级别的概念。由于引入深度卷积神经网络取得了巨大进展,基于ConvNet的动作识别方法已经实现了比传统手工特征方法更高的准确性。至于利用CNN进行基于视频的动作识别,存在以下两个研究方向:
Encoding CNN Features:CNN通常用于从视频帧中提取空间特征,然后使用循环神经网络或特征编码方法对提取的特征序列进行建模。在LRCN(Donahue等人,2015年)中,视频帧的CNN特征被馈送到LSTM网络进行动作分类。ShuttleNet(Shi等人,2017年)引入了生物学启发的反馈连接来模拟空间CNN描述符的长期依赖关系。TLE(Diba、Sharma和Van Gool,2017年)提出了捕捉视频片段之间交互作用的时间线性编码,并将这些交互作用编码成紧凑的表示形式。类似地,VLAD(Arandjelovic等人,2016年;Girdhar等人,2017年)和AttentionClusters(Long等人,2018年)已被提出用于局部特征集成。
ConvNet as Recognizer:首次尝试使用深度卷积网络进行动作识别是由Karpathy等人(Karpathy et al. 2014年)完成的。尽管Karpathy等人(Karpathy et al. 2014年)在动作识别方面取得了强大的结果,但融合了基于RGB的空间流和基于光流的时间流的预测分数的双流ConvNet(Simonyan和Zisserman 2014年)在性能上取得了显著改进。STResNet(Feichtenhofer、Pinz和Wildes 2016年)在(Simonyan和Zisserman 2014年)的两个流之间引入了残差连接,并展示了结果上的巨大优势。为了建模视频的长期时间结构,提出了Temporal Segment Network(TSN)(Wang等人,2016年),通过稀疏时间采样策略实现了有效的视频级监督,并进一步提升了基于ConvNet的动作识别器的性能。
观察到2D卷积网络不能直接利用动作的时间模式,因此空间-时间建模技术被更加显式地引入。C3D(Tran等人,2015年)将3D卷积滤波器应用于视频中以学习空间-时间特征。与2D卷积网络相比,C3D具有更多的参数,要获得良好的收敛性要困难得多。为了克服这一困难,T-ResNet(Feichtenhofer、Pinz和Wildes,2017年)在空间卷积网络的层之间注入了时间快捷连接,以摆脱3D卷积。I3D(Carreira和Zisserman,2017年)通过将传统的2D卷积网络架构扩展为3D卷积网络,同时从视频中学习空间-时间表示。P3D(Qiu、Yao和Mei,2017年)将3D卷积滤波器解耦为2D空间卷积滤波器,后跟1D时间卷积滤波器。最近,有许多框架提出了改进3D卷积的方法(Zolfaghari、Singh和Brox,2018年;Wang等人,2018a年;Xie等人,2018年;Tran等人,2018年;Wang等人,2018b年;Chen等人,2018年)。我们的工作不同之处在于,通过对局部空间-时间特征图进行时间卷积逐渐建模空间-时间关系。
3 Proposed Approach
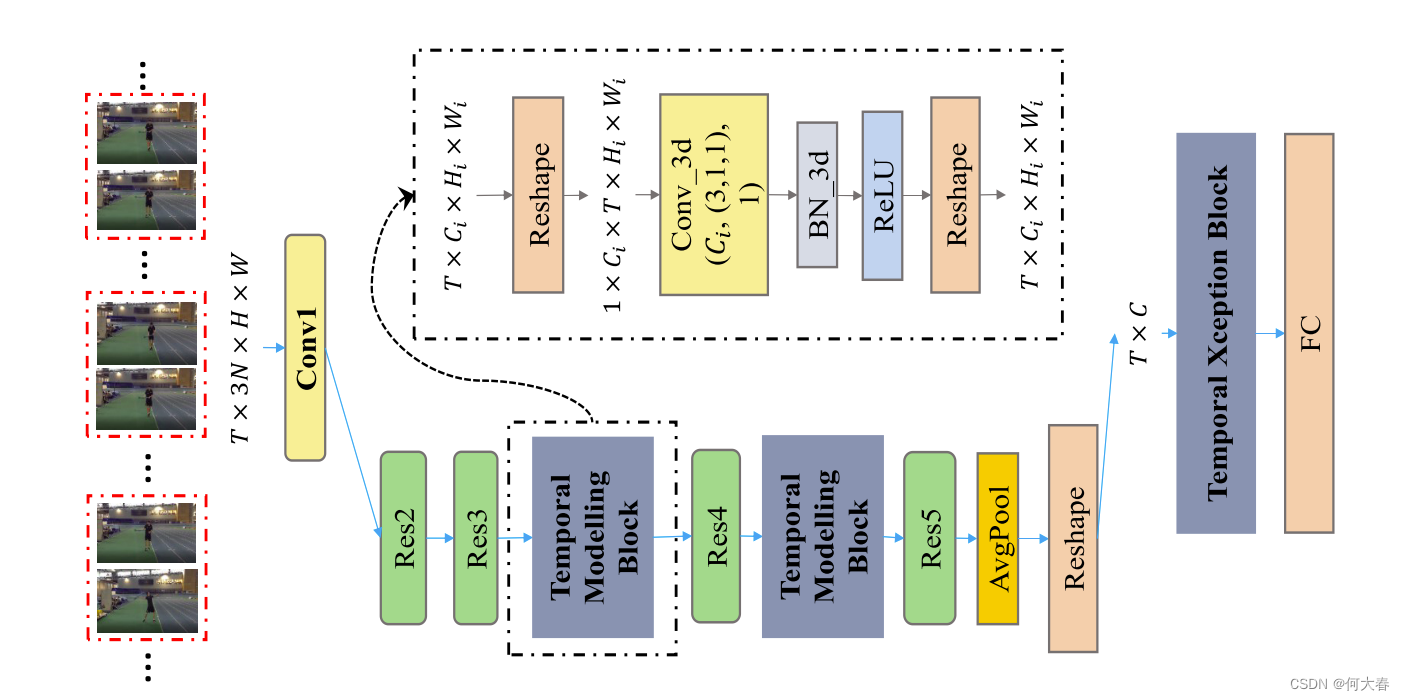
图2:基于ResNet(He等人,2016年)骨干构建StNet的示意图。StNet的输入是一个 T × 3 N × H × W T\times3N\times H\times W T×3N×H×W张量。局部空间-时间模式通过2D卷积进行建模。3D卷积被插入到Res3和Res4块之后,用于长期时间动态建模。3D卷积的设置(# 输出通道数,(时间核大小,高度核大小,宽度核大小),# 组)是 ( C i , ( 3 , 1 , 1 ) , 1 ) (C_i,(3,1,1),1) (Ci,(3,1,1),1)。
提出的StNet可以从现有的最先进的2D卷积网络框架中构建,例如ResNet(He等人,2016年)、InceptionResNet(Szegedy等人,2017年)等等。以ResNet为例,图2说明了我们如何从现有的2D卷积网络构建StNet。从其他2D卷积网络框架(如InceptionResNetV2(Szegedy等人,2017年)、ResNeXt(Xie等人,2017年)和SENet(Hu、Shen和Sun,2018年))构建StNet类似。因此,我们在这里不详细说明所有这些细节。
Super-Image:受TSN(Wang等人,2016年)启发,我们选择通过对时间片段进行采样来建模长期的时间动态,而不是输入整个视频序列。与TSN的一个不同之处在于,我们对T个时间段进行采样,每个时间段由N个连续的RGB帧组成,而不是单个帧。这N帧在通道维度上堆叠以形成一个超级图像,因此网络的输入是大小为T×3N×H×W的张量。超级图像不仅包含由单个帧表示的局部空间外观信息,还包含这些连续视频帧之间的局部时间依赖关系。为了共同建模其中的局部空间-时间关系,并且节省模型权重和计算成本,我们在每个T个超级图像上利用2D卷积(其输入通道大小为3N)。具体来说,局部空间-时间相关性由ResNet的Conv1、Res2和Res3块内的2D卷积核建模,如图2所示。在我们当前的设置中,N被设置为5。在训练阶段,除了第一个卷积层外,2D卷积块的权重可以直接从ImageNet预训练的骨干2D卷积模型中初始化。Conv1的权重可以按照I3D(Carreira和Zisserman,2017年)中作者的做法进行初始化。
Temporal Modeling Block:应用在T个超级图像上的2D卷积产生了T个局部空间-时间特征图。构建采样的T个超级图像的全局空间-时间表示对于理解整个视频至关重要。具体而言,我们选择在Res3块和Res4块之后插入两个时间建模块。这些时间建模块被设计用于捕获视频序列中的长期时间动态,它们可以通过利用Conv3d-BN3d-ReLU的架构轻松实现。值得注意的是,现有的2D卷积网络框架已经足够强大,可以用于空间建模,因此我们将3D卷积的空间卷积核大小都设置为1,以节省计算成本,而将时间卷积核的大小经验性地设置为3。在Res3块和Res4块之后应用两个时间卷积层的计算成本增加非常有限,但能够有效地逐步捕获全局空间-时间相关性。在时间建模块中,Conv3d层的权重初始设置为 1 / ( 3 × C i ) 1/(3×C_i) 1/(3×Ci),其中 C i C_i Ci表示输入通道的大小,偏置设置为0。BN3d被初始化为一个恒等映射。
Temporal Xception Block:我们的时间Xception块是为了在特征序列中进行高效的时间建模并以端到端的方式进行简单优化而设计的。我们选择时间卷积来捕获时间关系,而不是循环架构,主要是为了端到端训练的目的。与普通的1D卷积不同,后者同时捕获通道维和时间维信息,我们将通道维和时间维的计算分开,以提高计算效率。时间Xception架构如图3(a)所示。特征序列被视为一个
T
×
C
i
n
T×C_{in}
T×Cin的张量,这个张量是通过从T个超级图像的特征图上进行全局平均池化得到的。然后,沿着通道维度应用1D批量归一化(Ioffe和Szegedy,2015年)来处理已知的协方差偏移问题,输出信号是V。
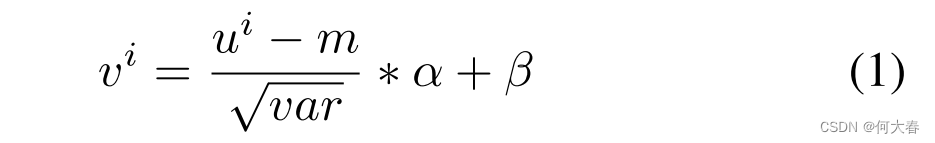
其中,
v
i
v^i
vi和
u
i
u^i
ui分别表示输出信号和输入信号的第
i
i
i行;
α
\alpha
α和
β
\beta
β是可训练参数,
m
m
m和
v
a
r
var
var是输入小批量数据的累积运行均值和方差。为了建模时间关系,沿着时间维度的卷积应用于
V
V
V。我们将时间卷积分解为单独的通道维和时间维的1D卷积。从技术上讲,对于通道维的1D卷积,时间核大小设置为3,并且核的数量和组数设置为与输入通道数相同。在这种情况下,每个核在单个通道内沿时间维进行卷积。对于时间维的1D卷积,我们将核的大小和组数都设置为1,这样时间维的卷积核可以在每个时间步上跨越沿着通道维的所有元素进行操作。形式上,通道维和时间维的卷积可以分别描述为方程2和方程3。
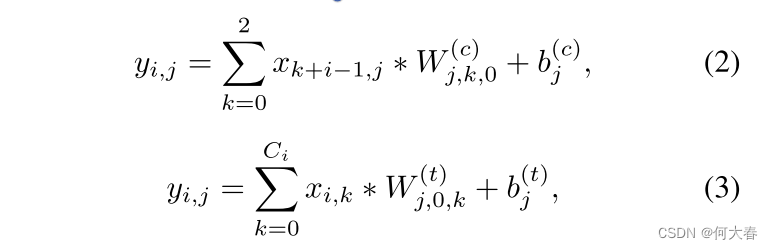
其中,
x
∈
R
T
×
C
i
x\in \mathbb{R}^{T\times C^i}
x∈RT×Ci 是长度为
T
T
T的输入
C
i
C_i
Ci维特征序列,
y
∈
R
T
×
C
o
y\in \mathbb{R}^{T\times C_o}
y∈RT×Co 表示输出特征序列,
y
i
,
j
y_{i,j}
yi,j是第
i
i
i个特征的第
j
j
j个通道的值,*表示乘法。在方程2中,
W
(
c
)
∈
R
C
o
×
3
×
1
W^{(c)}\in \mathbb{R}^{C_o\times 3\times 1}
W(c)∈RCo×3×1 表示通道维卷积核,其参数为(#核,核大小,#组)=(
C
o
C_o
Co,3,
C
i
C_i
Ci)。在方程3中,
W
(
t
)
∈
R
C
o
×
1
×
C
i
W^{(t)}\in \mathbb{R}^{C_o\times 1\times C_i}
W(t)∈RCo×1×Ci 表示时间维卷积核,其参数为(#核,核大小,#组)=(
C
o
C_o
Co,1,1)。
b
b
b表示偏置。本文中,
C
o
C_o
Co被设定为1024。单独通道和时间维卷积的直观示意图可以在图3(b)中找到。
如图3(a)所示,与(He等人,2016年)的瓶颈设计类似,时间Xception块有一个长支路和一个短支路。短支路是一个单一的1D时间维卷积,其核大小和组大小都为1。因此,短支路具有1的时间感受野。与此同时,长支路包含两个通道维1D卷积层,因此具有5的时间感受野。直觉是,融合具有不同时间感受野大小的支路有助于更好地建模时间动态。时间Xception块的输出特征被送入沿时间维度的1D最大池化层,池化后的输出被用作空间-时间聚合描述符进行分类。
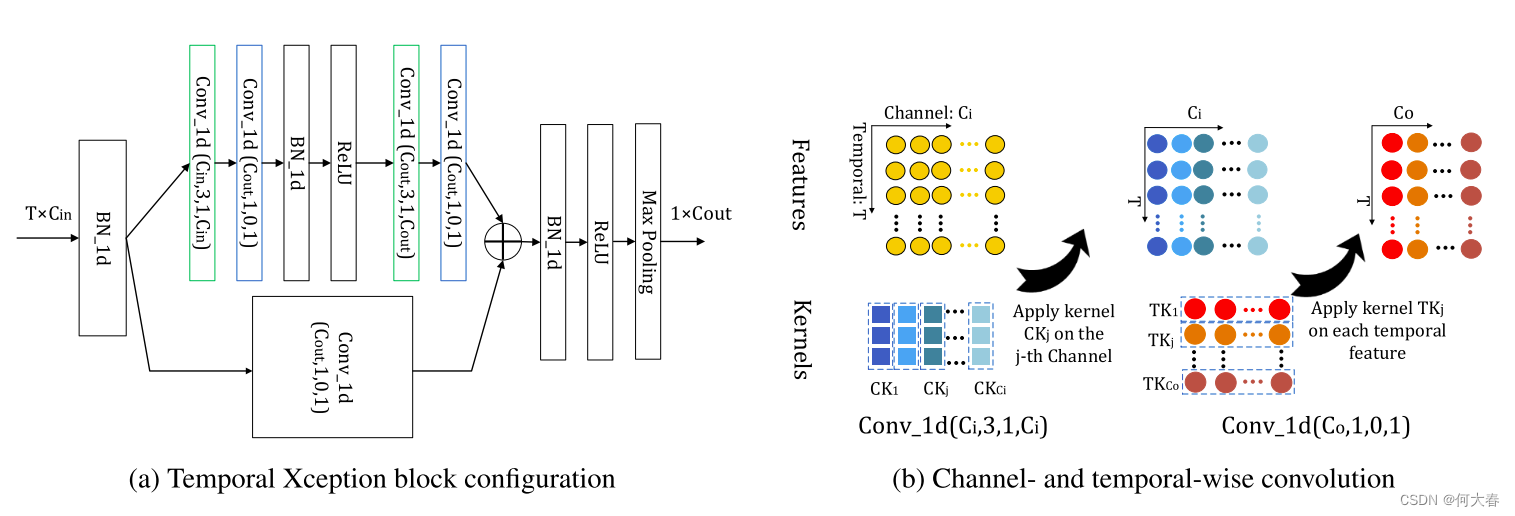
图3:时间Xception块(TXB)。我们提出的时间Xception块的详细配置如(a)所示。括号中的参数表示1D卷积的(#核,核大小,填充,#组)配置。绿色块表示通道维1D卷积,蓝色块表示时间维1D卷积。 (b)描述了通道维和时间维的1D卷积。TXB的输入是视频的特征序列,表示为一个 T × C i n T\times C_{in} T×Cin的张量。通道维1D卷积的每个核只沿着一个通道的时间维进行应用。时间维1D卷积核在每个时间步上跨越所有通道进行卷积。
4 Experiments
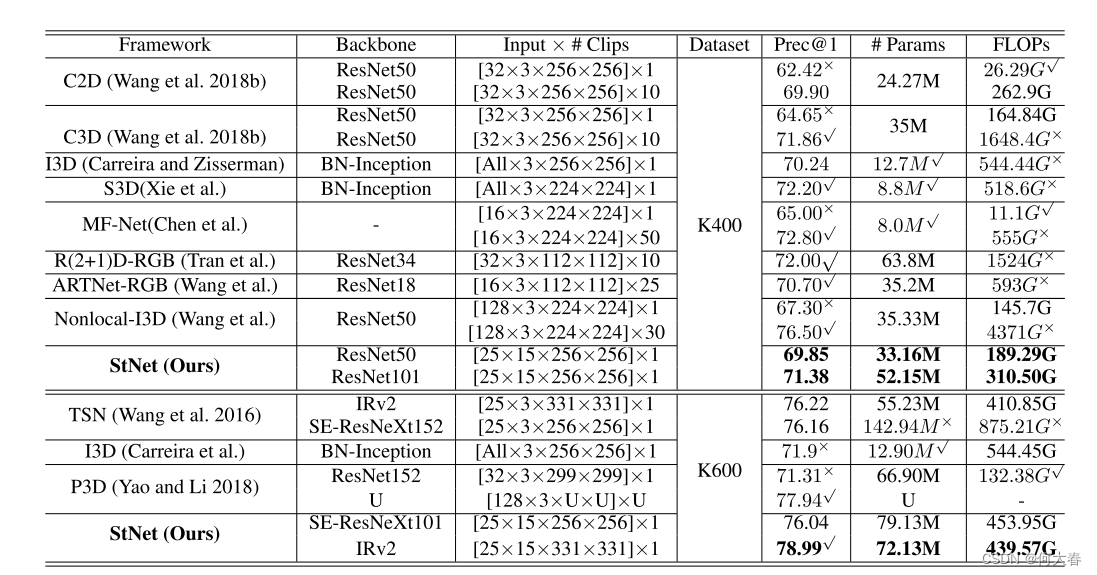
5 Conclusion
在本文中,我们提出了StNet,用于联合局部和全局空间-时间建模,以解决视频动作识别问题。通过在采样的超级图像上应用2D卷积来对局部空间-时间信息进行建模,同时通过对超级图像的局部空间-时间特征图进行时间卷积来编码全局时间交互。此外,我们提出了一个时间Xception块来增强建模时间动态的能力。这样的设计选择使得我们的模型在训练和推理阶段都相对轻量级和计算效率高。因此,它允许使用最强大的2D CNN在大规模数据集上实例化StNet,并提高最终的动作识别准确性。在大规模动作识别基准Kinetics上进行了大量实验证实了StNet的有效性。此外,在Kinetics数据集上训练的StNet在UCF101数据集上展现出了相当好的迁移学习能力。

